
在我们生活的两极世界中,技术、开源软件和知识被自由共享,但同时防止攻击者对专有技术进行逆向工程的需求也在不断增长。有时候,技术盗窃甚至可能危及世界和平,比如伊朗人对美国中央情报局的绝密技术进行了逆向工程,开发出了一种新的攻击无人机。代码混淆是保护数据不受入侵者侵害的众多措施中的一种,虽然它可能不会带来世界和平,但至少可以给你带来一些安心。
背景介绍
在高端和复杂的技术方面,伊朗从来没有占过上风——禁运和制裁没有给伊朗留下任何技术优势,除了创造力。伊朗人找到了最有创意的方法来试图保持领先地位。为了证明我们的观点,这里有一个有趣的故事——2011 年,伊朗人利用简单的信号干扰劫持了一架美国超级机密无人机RQ170哨兵,这是中情局使用的最先进的情报收集无人机。伊朗人“只”花了几年时间就对“哨兵”进行了逆向工程,并获得了良好的回报——他们基于“哨兵”的技术生产出了Shahed 191 Saegheh,并在最近卖给了俄罗斯。
程序员、技术供应商和政府可以做些什么来保证他们的技术的安全性,不被那些想要对有价值的技术进行逆向工程的恶意攻击者窃取?
保证程序或技术的安全,就像保证你的房子不被窃贼偷窃一样——考虑到在大多数情况下,没有人能保证你的房子是 100%安全的,所以你拥有的贵重物品越多,采取的保护措施也就越多。保护源代码也是如此——我们希望防止未经授权的人访问我们应用程序的逻辑、提取数据、克隆、重新分发、重新打包我们的代码,或利用漏洞。
把针藏在干草堆里
最好的安全专家会告诉你,保护知识产权从来没有简单、单一的解决方案,建立一个良好的保护屏障总是需要采用综合的措施、保护层和方法。在本文中,我们将关注源代码保护中的一个小层面——代码混淆。
混淆处理是一种强大的安全保护措施,但它常常被忽视,或至少被误解。代码混淆可以让代码变得难以理解,可以阻止未经授权的人轻易地反编译或反汇编它。代码混淆让代码变得不可能(或几乎不可能)被人类阅读或解析。因此,代码混淆是一种很好的保护措施,可用于保持源代码的专有性和保护我们的知识产权。
为了更好地解释代码混淆的概念,我们将以“沃尔多在哪里”为例。沃尔多是一个著名的插图角色,总是穿着红白条纹衬衫,戴着帽子,戴着黑框眼镜。在一张插图中有几十甚至几百个人正在做着各种有趣的事情,图中充满了情景、人物、物体和事件,我们要做的是在图中找到沃尔多。这并不总是很容易,甚至可能需要一些时间来分析插图,但最后总是会找到沃尔多,这多亏了他那独特的形象。
现在想象一下,如果没有沃尔多他那标志性的条纹衬衫、帽子和眼镜——相反,他每次都穿不同的衬衫、戴不同的帽子和假发,有时候甚至会打扮成女人,那么找到他有多容易?可能几乎找不到。

图 1. 想象一下,在没有沃尔多标志性的条纹衬衫、眼镜和帽子的情况下找到沃尔多。他将穿着普通的衣服,并戴着口罩。
同样,当我们在进行代码混淆时,我们通过一种难以被理解的方式隐藏程序的代码、流程和功能的一部分——我们掩盖它们,“扭曲”、打乱、重命名、修改、隐藏、转换它们,甚至注入一些垃圾信息。
好的代码混淆通常会使用所有这些方法,让混淆过的代码与原始的、未混淆的源代码难以区分。生成的代码看起来像是那么回事,这样会迷惑攻击者,并让逆向工程变得难以实施。
但需要注意的是,与其他安全措施一样,代码混淆并不是 100%保证安全,但如果处理得当,它可以尽可能接近保证 100%的安全,特别是如果结合采取其他安全措施的话。
混淆不等于加密
混淆和加密经常被误认为是同一个东西,其实它们并不是,所以区分二者是很重要的。混淆和加密是两个不同的概念,二者之间不能相互取代——如果说它们之间有什么联系的话,它们是相互补充的。
在加密时,我们将信息转换成隐藏信息真实含义的密码。在进行混淆处理时,信息将保持原样,只是以一种模糊的格式呈现出来,因为我们将其复杂性提高到不可能(或几乎不可能)被理解或解析的程度。
强大的加密机制是一种强大的安全措施,但我们必须记住,不管是什么锁,在某个时刻总是会被打开。任何被加密的东西都必须先解密才能使用,这就像打开了堡垒的门——不管它有多么坚固,这仍然是它的一个薄弱点。混淆的优势在这里就体现出来了——在进行混淆时,我们不加密,我们只是将代码隐藏起来,使它们变得不那么显而易见。混淆就像把针藏在干草堆里——如果做得好,攻击者需要花超出常规时间和资源来找到你的“针”。
根据我们多年来作为程序员和代码混淆布道师的经验,我们发现代码混淆有点像英国脱欧——专家们要么完全支持,要么强烈反对。然而,要保证安全性,总是需要结合使用多种方法——如果一种方法失败,另一种方法仍然可以发挥作用——这也就是为什么说混淆和加密是很好的组合。混淆应该总是排在最后,也就是说,在添加了加密层并全面调试了程序之后,接下来就是混淆了。
尽管本文关注的是如何创建字符串混淆工具,但必须指出的是,在现实生活中,商业混淆工具混淆的不仅仅是字符串,它们也混淆函数、API 调用、变量、库、值等等。
不让你看见我
大公司会对敏感软件进行混淆处理。例如,微软的 Windows补丁卫士就进行了全面的混淆,实际上不可能被逆向工程。如果你是一名程序员,可能不会有那些大公司所使用的花哨的安全工具,但这并不意味着你就不能使用一些简单而实用的措施来保护自己的代码。混淆字符串就是一种很好的方法,一方面不需要使用昂贵而复杂的混淆工具,另一方面可以让代码变得难以理解。
事实上,如果你使用十六进制编辑器或 Notepad 打开一个典型的可执行文件,你可能会在二进制数据中发现许多字符串,这些字符串揭示了商业机密、IP 地址或其他信息(如图 2 所示),所有这些都以字符串的形式出现,但你其实不想泄露这些信息。
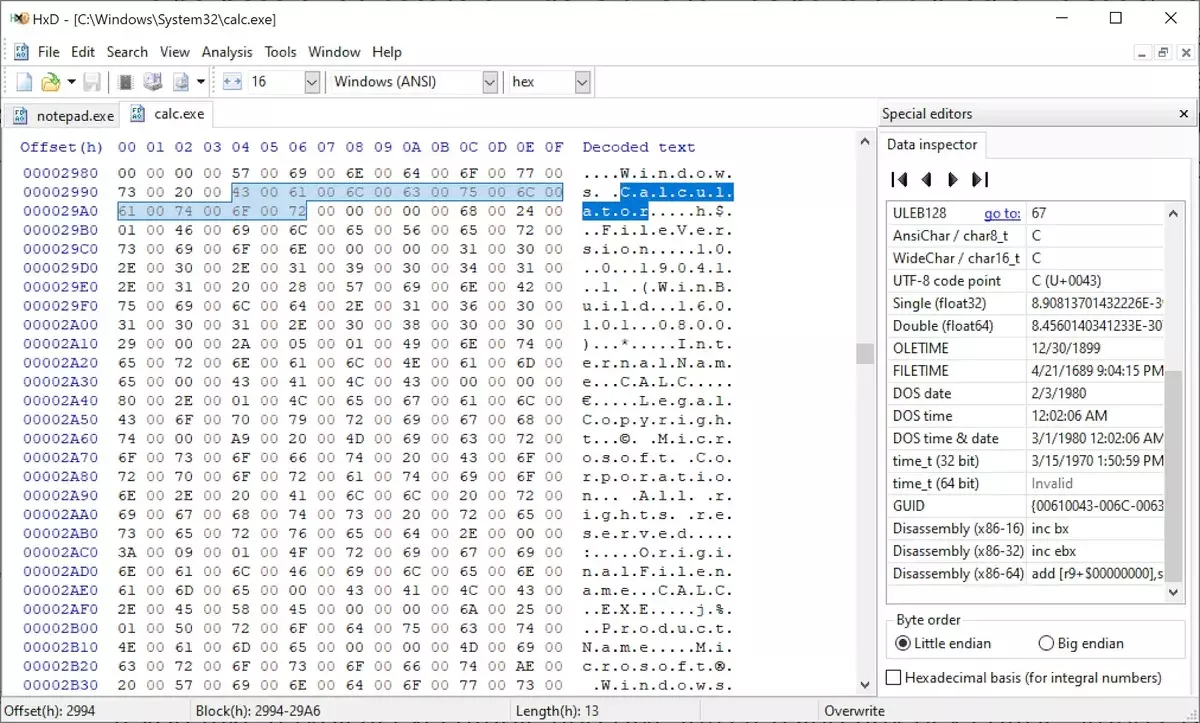
图 2. 如果我们使用十六进制编辑器打开一个 exe 文件,可以找到一些字符串,这可能会给出很多信息,被攻击者利用。在这张图中,我们可以看到字符串"calculator"。
现在,假设你的软件连接到远程服务器,你保存了正在使用的 IP,并且不希望它被泄露。你可以通过混淆的方式隐藏敏感数据。当然,数据只在可执行文件层面得到隐藏,一旦与远程服务器通信,嗅探工具将显示 IP 以及发送和接收的任何内容——因此我们还是要考虑到这一点。我们需要指出的是,有很多方法可以同时隐藏 IP 和数据,甚至不被嗅探工具(如 Wireshark)发现,不过这是另外一个主题了。
字符串混淆的背后
混淆代码的方法不止一种,因为混淆可以在多个级别或层面上实现——语义结构、词法结构、控制流、API 调用等等。为了实现健壮的安全性,我们必须同时使用几种技术。由于本文的重点是字符串混淆,所以我们将探究四种子方法。
随机性的重要性
说到随机数,我们可以想象一台彩票机:机器的底部是旋转桨,让球在腔体内随机旋转,然后把球从管子里射出去,这意味着每个球都是随机挑选的。
你可能会问:为什么我们要在代码里使用随机元素?答案是,解码混淆数据的方法之一是检查事物的逻辑顺序,一旦我们将这个顺序随机化,就很难猜测到混淆的数据是什么。
最大的问题是:计算机程序能否在没有任何隐藏逻辑的情况下生成真实的随机数,并让随机数变得不那么随机?毕竟,计算机程序没有旋转桨,不会射出球,它们只是在计算机上运行的人造程序。
例如,C++提供了
一位名叫Arvid Gerstmann的企业家开发了他自己的随机数生成器,它更加的随机。在《学习 C++》一书中,我们使用这个库开发了一个迷你字符串混淆工具。
像洗牌一样搅乱它们
在进行混淆时,我们会搅乱各种元素,如字符串、函数等,因此它们的顺序将(几乎)是随机的,如果有人试图破解你的代码就变得更难。我们可以搅乱过程想象成洗牌,让它们按照随机的顺序混合在一起。我们对将要生成的函数做同样的处理。
洗牌就是随机地(或几乎随机地)改变一些元素的顺序,使得攻击者更难分析和逆向工程我们的代码。解码混淆数据的方法之一是检查逻辑顺序以及何时搅乱的顺序,但混淆数据的顺序是很难被猜测到的。当然,我们的目的不是改变行为代码,只是打乱单独模块里的元素。
用公式替换值
另一种混淆方法是用不同类型的公式随机地替换值,如 x=z-y 或 z=y+z。假设我们有一个值 72,我们可以用 100-28 或 61+11 替换这个值。当公式为 x=z-y 时,我们需要 z 是随机的,但大于 y。换句话说,我们将把这个随机生成的公式插入到生成的源代码中,而不是使用原始值。
图 3 显示了当我们插入随机公式时,混淆的代码是什么样子的。

图 3. 使用不同类型的公式(如 x=z-y 或 z=y+z)随机地替换值。
添加“垃圾”数据
隐藏代码内容的另一种方法是在真实数据中随机地添加垃圾数据,这样会让解析和反向工程变得更加困难。举个例子,我们假设 result 是一个以 NULL 结尾的数组——我们把 NULL 放在字符串的末尾,垃圾放在 NULL 后面。使用这个方法的混淆字符串看起来像这样:
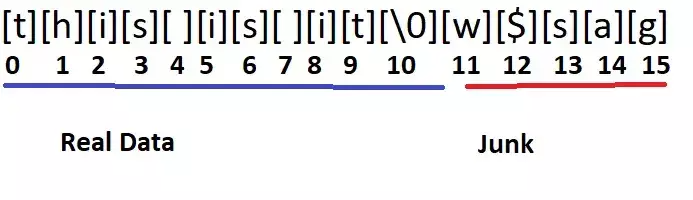
result[12] = L’$’;result[0] = L’t’;result[5] = L’5’;
现在,假设我们以随机顺序分配真实字符和垃圾字符,那么我们可能从 char[12]开始,然后是[0],然后是[5],并以此类推,这使得理解这个过程和结果变得更加困难。
记住:混淆代码的效果取决于它最薄弱的环节。我们要经常测试它们,试着去反向工程它们。反向工程难度越大,混淆的效果就越强。
提示:混淆的代码很难维护和更新。因此,建议在部署新版本之前,先维护好非混淆的版本,然后对其进行混淆处理。
在讨论了代码混淆背后的一些一般性概念之后,在下一小节中,我们将介绍一款名为 Tiny Obfuscate 的字符串混淆工具,它有两种工作模式:即时模式和项目模式。
Tiny Obfuscate
Tiny Obfuscate是 Michael Haephrati 使用 C++开发的一款 Windows 应用程序,最初是在Code Project的一篇文章中作为一个概念证明示例,它可以用来将给定的字符串转换为生成这个字符串的代码行。
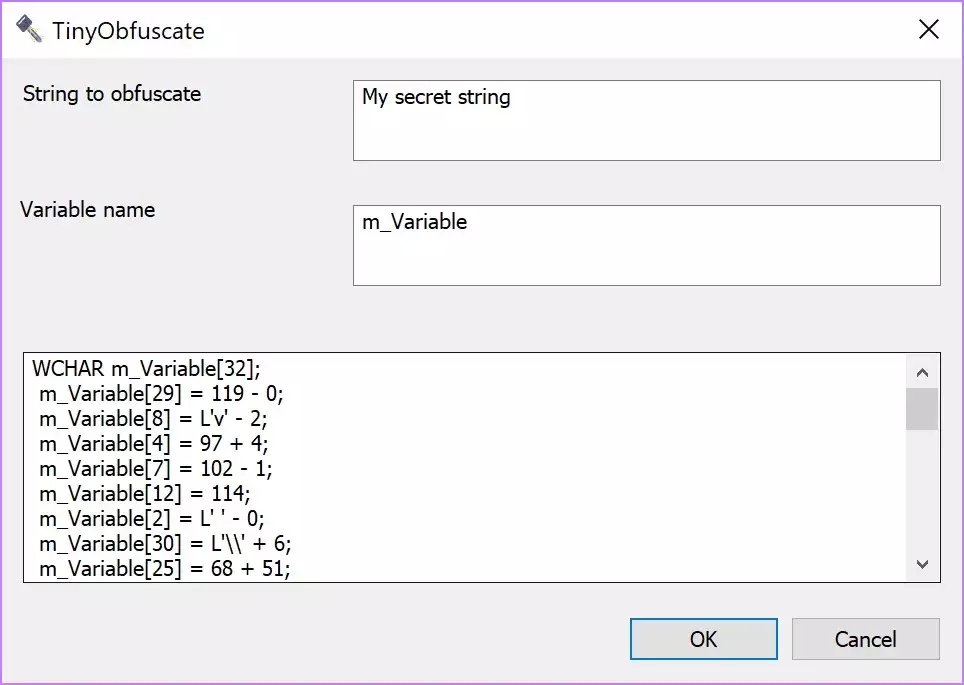
图 4. Tiny Obfuscate 最初的界面
你输入字符串和变量名,就会生成代码行,你可以将它们复制到程序中并替换原来的字符串。
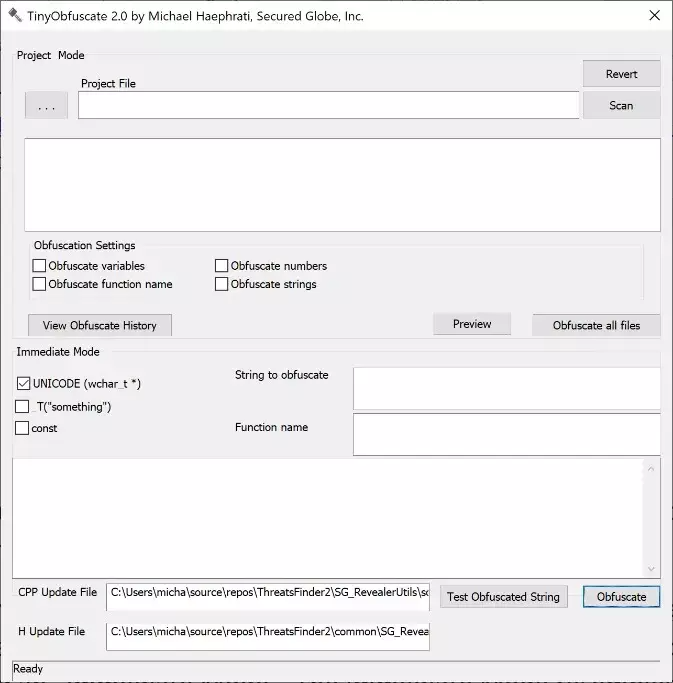
图 5. Tiny Obfuscate 高级付费版的界面
一些商业产品使用了更高级版本的 Tiny Obfuscate。高级版有“项目模式”和“即时模式”。即时模式类似于文章中使用的原始版本,但有更多的功能:
用户可以选择字符串的类型(UNICODE 或宽字符、常量等)。
混淆的代码被封装在生成的新函数中。
可选:在没有检查是否已经有一个函数混淆了给定字符串之前将函数代码和原型被插入到给定的.cpp 和.h 文件中。
函数调用被复制到剪贴板(如果给定字符串之前被混淆了,可以是新生成的函数,也可以是现有的函数),因此用户可以直接粘贴它,而不是粘贴给定的字符串。
自动测试生成的函数,验证它是否会返回给定的字符串。
处理各种控制字符和转义字符,如\n、\t、%s、%d 等等。
自动添加注释,方便跟踪被混淆的原始字符串以及什么时候被混淆的。
示例
我们用下面的例子来测试字符串混淆是如何工作的。假设我们有下面这行代码。
wprintf(L"The result is %d", result);
现在,我们想要混淆这个符串,在本例中就是“The result is %d”。我们将这个字符串输入到即时模式的“String to obfuscate”输入框中。

然后按下“Enter”,就会看到下面这样的弹出框。
同时会出现下面的代码(并插入到项目的源文件和头文件中)。

在项目模式下,我们可以选择 Visual Studio 解决方案或项目,浏览所有源文件,选择要混淆的内容(变量、函数名、数值和字符串),预览结果,然后检查混淆的项目,并交互式地选择和取消每个元素,以获得最佳的混淆结果。
Tiny Obfuscate 高级版会生成并维护一个 sqlite3 数据库,记录所做的事情,并可以恢复到原始版本,以及撤消所做的任何操作。
结论
在本文中,我们介绍了代码混淆的概念,主要是关于字符串混淆。如果你想要深入了解,可以参考我们的《学习C++》(ISBN 9781617298509,作者Michael Haephrati和Ruth Haephrati,由 Manning 出版社出版)一书。在这本书中,我们向初学者教授 C++编程语言的基础知识,并逐步帮助他们建立技能,开发出最终的项目:创建一个紧凑而强大的字符串混淆处理工具。
作者简介:
Michael Haephrati 是 Secured Globe 公司的联合创始人兼首席执行官,他与他的妻子 Ruth Haephrati 于 2008 年成立了这家公司。Michael 是一位音乐作曲家、发明家,也是一位专门从事软件开发和信息安全的专家。凭借超过 30 年的经验,Michael 形成了一个独特的视角,将技术和创新结合起来,十分注重终端用户体验。多年来,Michael 为不同的客户领导开发了创新项目和技术。他是《学习C++》一书的作者,该书由 Manning 出版社出版。
Ruth Haephrati 是 Secured Globe 公司的联合创始人兼首席执行官,她与她的丈夫 Michael Haephrati 于 2008 年共同创立了这家公司。Ruth 是一名作家、演讲者、企业家、网络安全和网络取证专家。在过去的 25 年里,Ruth 一直在一些领先的公司工作,比如微软和 IBM,她既是一名顾问,也是一名 C++程序员。她最近参与了为一个国际客户开发先进反恶意软件技术的工作。在业余时间,Ruth 是一名插画家、画家、野生动物摄影师和世界旅行家。
原文链接:




