
本文作者网易数帆云网络数据面负责人汪翰林,在工作中从事服务网格的网络数据面性能优化,发现其中的网络性能优化的原理具有相通性。本文对通用的网络性能优化方法做出了总结,包括服务网格及网络性能优化分析、网络性能优化技术介绍、网络性能优化思路三个方面,并列举了实际案例进行进一步诠释,供大家在实际做性能优化时参考。
前段时间,团队一直在做服务网格的网络数据面性能优化,发现其中的网络性能优化的原理是相通的,所以就想着总结一些通用的网络性能优化方法,供大家在实际做性能优化时参考。
服务网格及网络性能优化分析
业务微服务化之后,为了提升微服务的治理能力,通常会引入一个业务无侵入的sidecar代理来提供微服务的流控、熔断、升级等服务治理能力。sidecar 会转发所有微服务的出口和入口流量,但这样会导致网络路径增加两跳,整个路径拉长,相应地时延也会增加。
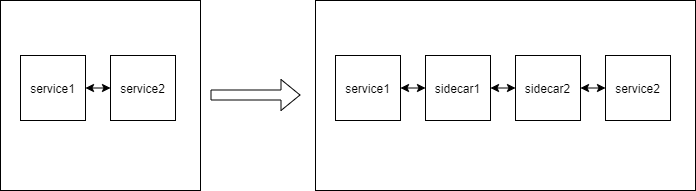
引入的时延主要分为 sidecar 业务处理时延以及网络收发时延。广义上的网络性能优化应该是端到端的时延优化,既包括处理时延优化,也包括网络收发时延优化。我们这里主要讨论狭义的网络性能优化,仅包括网络收发的时延优化。
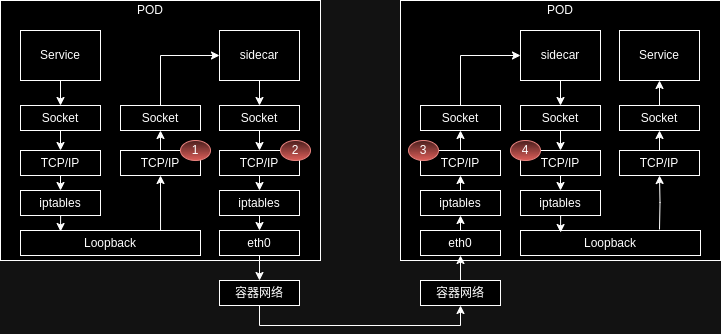
如果打开网络传输的链路,sidecar 额外引入了 Service 到 sidecar 以及 sidecar 到 sidecar 的链路,网络时延的增加主要是因为链路中多经过的四次内核态 TCP/IP 协议栈的开销。
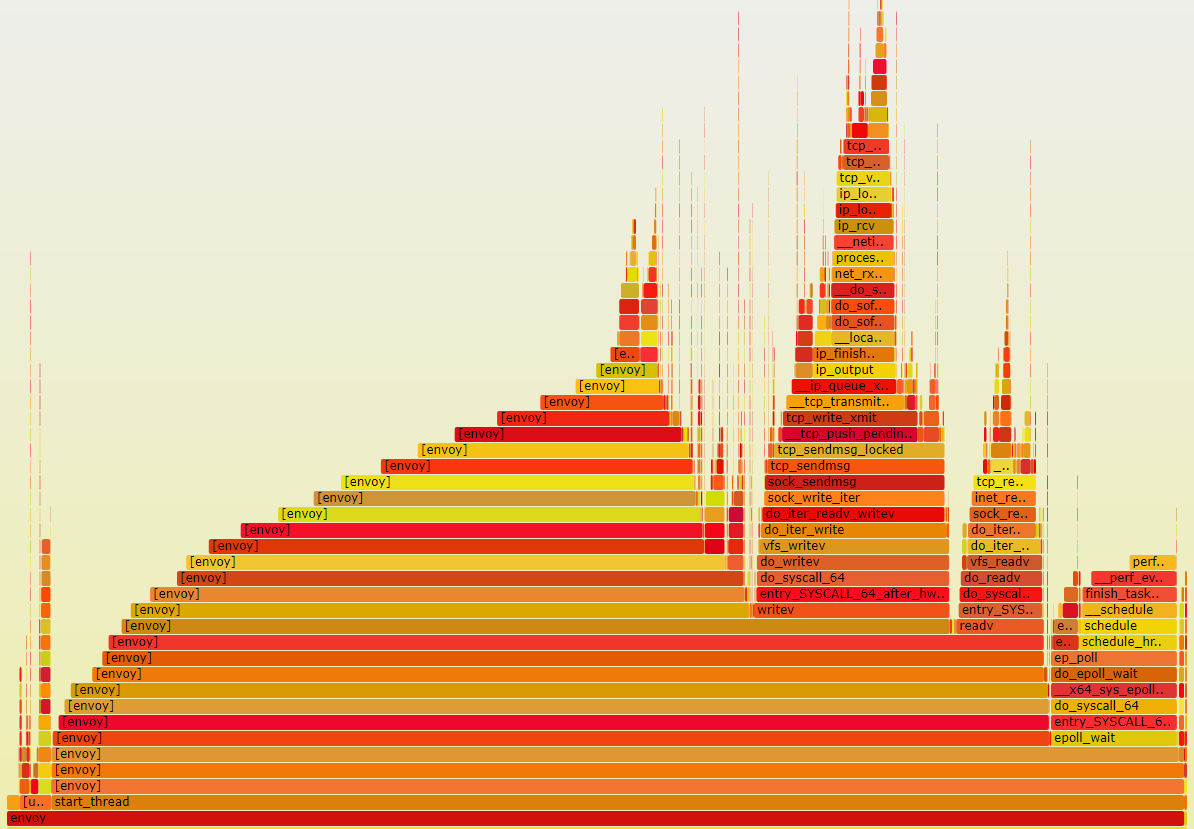
我们通过 perf 火焰图分析了 sidecar 应用 Envoy 的 CPU 占用,发现内核态协议栈的 CPU 占比近 50%,而剩下的 50% CPU 主要消耗在 Envoy 本身处理逻辑上。可见,网络时延的优化的重点也就是对内核态协议栈的优化。
网络性能优化技术
我们先来看一下针对内核态协议栈的网络性能优化技术,注意这里特指针对内核态协议栈的优化,因为网络性能优化的思路还有很多,我们会在后面章节提到。
针对内核态协议栈的优化主要思路是 kernel bypass,即让报文不经过内核态协议栈或者不经过完整的内核态协议栈,通过缩短网络路径来达到性能优化的目的。目前主要用到的技术包括 eBPF、用户态协议栈以及 RDMA。
eBPF
eBPF(extended Berkeley Packet Filter)是一个内核技术,可以在不需要重新编译内核的情况下,通过一种安全的、可编程的方式扩展内核的功能。eBPF 的主要功能是在内核层面进行安全、高效的网络数据包过滤和处理,以及在运行时对系统进行监控和调试。eBPF 可以通过独立的用户空间程序来编写和加载,这些程序可以安全地与内核交互,而不会影响内核的稳定性和安全性。
简单来说,目前的内核协议栈处理流程的代码中预留了很多 hook 点,用户态编写的程序编译成 eBPF 字节码之后可以注册到这些 hook 点,之后内核处理报文到 hook 点时就会调用这些预编译好的字节码程序完成特定的功能。这样我们就可以控制内核针对报文的处理流程,结合 eBPF 的 redirect 能力可以将报文直接转发到对应的网络设备或者 socket,从而做到 kernel bypass。
这里不得不提两类 hook 点:XDP 和 socket。XDP hook 是网卡收到报文后最早的 hook 点,可以实现在网络驱动程序中拦截和处理报文。而 socket hook 可以拦截连接建立、收发的报文,是应用层处理报文最早的 hook 点。
不过,eBPF 程序终究还是运行在内核态,应用层进行网络报文传输时还是避免不了内核态和用户态的上下文切换开销。对于可以完全运行在内核态的应用,如安全检测、负载均衡等场景则可以避免这个开销。
用户态协议栈
顾名思义,用户态协议栈是将协议栈的实现卸载到用户态来实现。卸载到用户态实现会带来几个好处:一是避免用户态和内核态的上下文切换;二是根据需要定制和精简协议栈的实现;三是调测和运维也会更加方便。
报文卸载到用户态通常采用 DPDK 或者 AF_XDP 的方法。DPDK 是 Intel 主导的开源项目,目前主流网卡都支持,成熟且性能高,不过对于虚拟口(如 veth 口)的支持不够好,在容器化场景受限。AF_XDP 是基于 eBPF 的报文卸载技术,可以实现在网卡驱动层针对报文拦截并卸载到用户态,对于物理网口或者虚拟口的兼容性好,性能相比于 DPDK 稍差。
用户态协议栈通常需要开发适配层来兼容 socket 接口,拦截 socket 调用并分发到用户态协议栈处理,这样应用层可以做到无需修改代码,完全无感知。
RDMA
RDMA (Remote Direct Memory Access)是一种高性能、低延迟的网络通信技术,它能够让计算机之间直接访问彼此内存中的数据,从而避免了传统网络通信中的数据拷贝和 CPU 参与的过程。所以,RDMA 是一项软硬结合的网络性能优化技术,将网络传输卸载到 RDMA 硬件网卡中实现,提升性能的同时可以将 CPU 节省出来给应用使用。
RDMA 的实现技术分为 InfiniBand、RoCE 和 iWARP。InfiniBand 是最早的实现方式,需要专门的硬件网卡和 InfiniBand 交换机配合组网,和以太网不兼容,成本高但性能最好。RoCE 基于以太网传输 RDMA 报文,使用 UDP 封装报文,通常需要组建基于 PFC/ECN 的无损网络,否则丢包会导致性能劣化严重,总体性能较好,RoCE 的主要代表是英伟达的 Mellanox 网卡。iWARP 基于 TCP,网络适应性好,但性能最差,代表是 Intel 网卡。
RDMA 对外提供 ibverbs 编程接口,和 socket 接口还是有较大区别,不过直接基于此进行应用代码改造理论上性能收益最大。Mellanox 网卡在此基础上封装了 UCX 接口,还是不能做到完全兼容 socket 接口。由 Intel 和阿里主导的 SMC-R 可以实现 socket 接口的完全兼容,由于封装后只能支持报文接收的中断模式而不支持 polling 模式,会导致性能有损失,底层只能适配 RoCE,无法兼容 iWARP。
网络性能优化思路
性能优化是一个端到端的系统性工程,遵循二八原则,即 80%的性能损耗在 20%的处理流程上。所以优化前还是需要分析下导致 80%性能损耗的 20%的处理流程到底在哪儿,是应用本身的处理逻辑还是网络传输层面。通常我们可以先使用性能分析工具(如 perf)做一下分析,确定瓶颈点。即使确定是网络传输的瓶颈,我们也可以先从硬件配置和组网层面进行分析:
1. 网卡带宽是否受限?如 10G 更换 25G 或者 100G 网卡
2. 是否跨机房访问?
3. 是否经过网关?网关是否有瓶颈?
4. 物理网络设备是否有瓶颈?
5. 是否经过虚拟网络?虚拟网络是否有瓶颈?
另外,我们也可以检查下内核参数配置,如网卡多队列配置,收发队列大小配置,连接跟踪配置等。
如果以上检查后发现还是满足不了要求,网络传输依旧是瓶颈,就可以考虑使用针对内核态协议栈的性能优化技术。那么 eBPF/用户态协议栈/RDMA 技术我们如何来选择呢?
从性能上来说,RDMA>用户态协议栈>eBPF。
RDMA 综合成本和性能,RoCE 用的最多,不过 RoCE 目前受限于无损网络,组网会有限制,通常限制在一个机房甚至一个 ToR 下。
用户态协议栈因为协议栈的定制实现,没有内核态协议栈的功能全面,所以应用的兼容性需要 case by case 的去做验证测试,比较适合于针对服务端的已知应用(如 Redis/Nginx/Envoy 等)的性能加速,而不太适合于作为一个通用的协议栈提供给所有应用使用。
eBPF 类似于给内核打补丁,哪里性能不好就可以打上一个补丁,适合于小的性能优化点的修修补补。
实际案例
服务网格
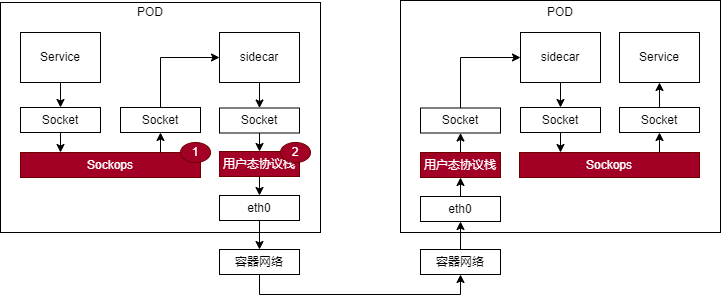
服务网格实际优化时结合了 eBPF Sockops 和用户态协议栈技术。
eBPF Sockops 注册了连接建立的 hook 点,将五元组信息保存到 sockmap 表中,后续报文发送可以直接查询 sockmap 表后 redirect 到对端 socket,这样就 bypass 了内核协议栈。eBPF Sockops 适用于 Service 和 sidecar 之间链路的加速,因为 Service 端应用的多样性不太适合使用用户态协议栈加速,而服务器内部进程间通信也不太适合 RDMA 加速。
用户态协议栈用来加速 sidecar 和 sidecar 之间的通信链路,可以 bypass 掉 sidecar 之间通信的内核协议栈。因为 sidecar 之间通信的链路不一定能组建无损网络,RDMA 加速不太合适。
当前用户态协议栈我们支持性能优先模式和兼容优先模式。性能优先模式中,底层通过 DPDK 进行报文卸载,适用于物理口或者虚拟 VF 口的场景,容器化场景也可以对接 SRIOV 的容器网络。兼容优先模式中,底层通过 AF_XDP 进行报文卸载,适用于虚拟 veth 口的场景,可以支持目前主流的容器网络场景。
另外,用户态协议栈在实际使用过程中可能会面临双栈的需求,即需要同时支持用户态协议栈和内核态协议栈。服务网格加速场景中 sidecar 和 Service 之间通信虽然通过 eBPF 进行了加速,但本质上还是走内核。所以用户态协议栈也需要支持根据路由配置来确定报文走内核态还是用户态协议栈。

图中是兼容优先模式最终加速的效果。时延有 35-40%的降低,其中用户态协议栈贡献 30%左右,eBPF 贡献 8%左右。
存储
Curve 存储是网易自研开源的分布式存储服务。在 Curve 块存储的开发及优化过程中,我们发现作为分布式系统,客户端需要通过网络和存储节点通信,存储节点之间也需要网络通信来完成多副本之间的一致性协商过程。在传统的 TCP/IP 网络协议栈中,网络数据包需要在用户态/内核态之间进行拷贝、TCP/IP 协议的层层解析和处理,消耗了大量的 CPU 和内存带宽。所以我们引入 RDMA 的 RoCE v2 技术来优化这部分的网络性能,存储组网相对可控,交换机进行 PFC/ECN 的无损网络配置,结合网卡的 DCQCN 拥塞控制算法可以实现基于无损网络的 RDMA 组网。
在实际的适配过程中,使用 UCX 接口来加速客户端和存储节点以及存储节点之间的的 RPC 通信,这样可以降低整体的开发难度及对业务代码的侵入修改。为了保证可靠且高效的 RDMA 报文传输,一方面,我们与交换机厂商进行密切沟通,分析并摸索建立了一套适合于系统的 ECN+PFC 配置方式;另一方面我们与网卡厂商共同分析网卡 DCQCN 拥塞控制参数对 RDMA 流量传输的影响,最终得出最适宜的网卡参数配置。
加速的效果:
1. 在单深度 4K 随机写场景下,平均延迟降低 35%;4K 随机读,平均延迟降低 57%;
2. 与杭研云原生数据 BosonDB 完成对接测试和上线。在数据库比较关注的 16K 随机/顺序写中,IOPS 提升至少 25%。
总结
随着云计算,大数据和 AI 等技术的不断发展,大量的计算资源之间的交互越来越频繁,对网络的要求也越来越高,臃肿的内核协议栈处理逐渐成为网络传输的瓶颈所在。本文介绍几种内核协议栈的优化技术、相关的应用场景以及实际的优化案例,供大家参考。
作者简介:
汪翰林,网易数帆高级技术专家,云网络数据面负责人。近 20 年软件架构、设计和研发经验,曾就职于华三和华为,主持多个安全、视频监控、大数据和云计算等技术领域的产品设计和研发工作。目前在网易数帆专注于高性能网络技术预研和产品化落地,带领团队完成 VPC 网络/容器网络/服务网格/存储/P4 网关等多个场景下的高性能网络套件在网易集团内部落地以及商业化输出工作。




