
近日,我们非常高兴地发布了最新的姿态检测模型 MoveNet,并在 TensorFlow.js 中推出了新的姿态检测 API。MoveNet 是一个超快速和准确的模型,能够检测出身体的 17 个关键点。这个模型在 TF Hub 上提供了两种变体,即 Lightning 和 Thunder。Lightning 用于延迟关键型应用,而 Thunder 用于需要高精度的应用。在大多数现代台式机、笔记本电脑和手机上,这两种模型都比实时要快(30+FPS),这对于实时性的健身、运动和健康应用都是至关重要的。通过在浏览器中使用 TensorFlow.js 在客户端完全运行模型,无需调用服务器,也无需在初始页面加载之后安装任何依赖关系,就可以实现这一点。

MoveNet 可以通过快速运动和非典型姿势来追踪关键点
在过去的五年里,人体姿势追踪技术有了很大进展,但在许多场景中仍未得到广泛应用。那是因为人们更加关注与让姿势模型变得更大、更准确,而不是为了让它们能够迅速部署到任何地方。对于 MoveNet 来说,我们的任务是设计并优化一个模型,在保持尽可能少的推理时间的同时,利用先进架构的最佳方面。这样的模型可以在不同的姿势、环境和硬件设置中提供准确的关键点。
为了解 MoveNet 是否有助于解锁患者的远程医疗,我们与数字健康和性能公司 IncludeHealth 进行了合作。IncludeHealth 开发了一个交互式网络应用程序,指导患者在自己舒适的家中(使用手机、平板电脑或笔记本电脑)完成各种日常操作。这些程序是由物理治疗师以数字方式设定的,用来检验平衡、力量和活动范围。
这项服务需要一个基于网络和本地运行的隐私姿势模型,它能提供高帧率下的精确关键点,然后用来量化和定量分析人体姿势和运动。一种典型的现成检测器,对于肩部外展或全身下蹲等简单动作来说是足够的,而更为复杂的姿势,比如坐姿膝盖伸展或仰卧姿势(躺下),甚至对于针对错误数据进行训练的最先进的检测器来说,也会带来麻烦。

传统探测器(上图) 和 MoveNet(下图) 在高难度姿势下的对比
我们为 IncludeHealth 提供了早期版本的 MoveNet,可以通过新的 pose-detection API 进行访问。这个模型是通过健身、舞蹈和瑜伽姿势训练得到的(详细信息见下面的训练数据集)。IncludeHealth 在其应用程序中集成了这个模型,并用 MoveNet 和其他可用的姿势检测器做了基准测试:
“MoveNet 模式注入了强大的组合,提供治疗所需的速度和准确性。在其他模式相互交换时,这种独特的平衡使得下一代护理服务得以展开。在这个过程中,谷歌团队是一个杰出的合作伙伴。”
—— Ryan Eder,IncludeHealth 公司的创始人兼首席执行官。
作为下一步,IncludeHealth 将与医院系统、保险机构等合作,将传统的护理和培训延伸到实体医院之外。

在浏览器中运行的 IncludeHealth 演示应用程序,使用由 MoveNet 和 TensorFlow.js 支持的关键点估计对平衡和运动进行量化
安装
有两种方法来使用 MoveNet 和新的姿势检测 api:
通过 NPM:
import * as poseDetection from '@tensorflow-models/pose-detection';通过脚本标记:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script><script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script><script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script><script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script>一旦包安装完毕,只需要按照以下几个步骤就可以开始使用:
// Create a detector.const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet);探测器默认使用“Lightning”版本;要选择“Thunder”版本,请按以下方式创建探测器:
// Create a detector.const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet, {modelType: poseDetection.movenet.modelType.SINGLEPOSE_THUNDER});``````null// Pass in a video stream to the model to detect poses.const video = document.getElementById('video');const poses = await detector.estimatePoses(video);每个姿势包含 17 个关键点,有绝对的 X、Y 坐标、置信度分数和名称:
console.log(poses[0].keypoints);// Outputs:// [// {x: 230, y: 220, score: 0.9, name: "nose"},// {x: 212, y: 190, score: 0.8, name: "left_eye"},// ...// ]有关 API 的更多细节,请参考 README 文件。
深入 MoveNet
MoveNet 是一种自下而上的估计模型,利用热图精确定位人体的关键点。这个架构包括两个部分:一个特征提取器和一组预测头。预测方案松散地遵循 CenterNet,但变化明显,提高了速度和准确性。所有的模型都是用 TensorFlow 对象检测 API 进行训练。
在 MoveNet 中,特征提取器是 MobileNetV2,与 特征金字塔网络(feature pyramid network,FPN)一起提供高分辨率(输出跨度为 4)、语义丰富的特征图输出。该特征提取器具有四个预测头,负责密集地预测 A:
人体中心热图:预测人体实例的几何中心。
关键点回归域:预测个体用来对关键点进行分组的所有关键点。
人体关键点热图:预测所有关键点的位置,不依赖于人体实例。
二维每关键点偏移域:预测从每个输出特征图像素到每个关键点的精确子像素位置的局部偏移量。
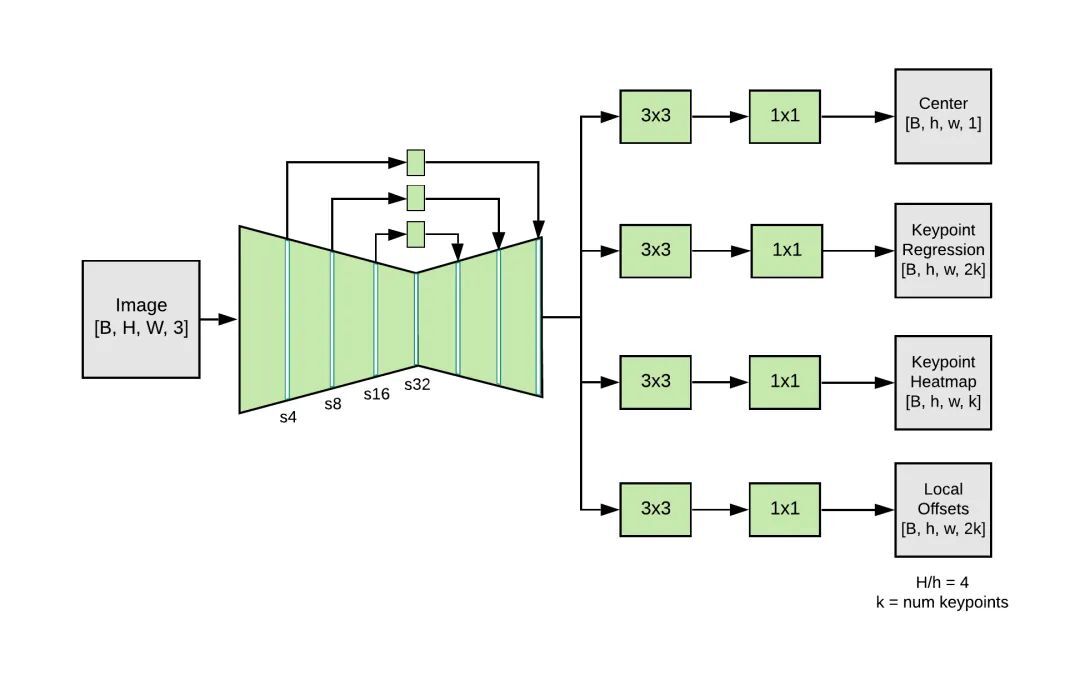
MoveNet 架构
虽然这些预测是并行计算的,但是考虑一下下面的操作次序,我们就能了解这个模型是如何工作的:
步骤一:人体中心热图用来识别框架中所有个体的中心,定义为所有属于一个人体的关键点的算术平均值。选取最大分值点(由与帧中心的反距离加权)。
步骤二:从与对象中心相对应的像素切片,通过关键点回归,得到人体的初始关键点集。因为这是一个必须在不同规模下操作的非中心预测,所以回归关键点的质量并不会很精确。
步骤三:关键点热图中的每个像素都要乘以一个权重,这个权重与对应的回归关键点的距离成反比。这样就保证了我们不接受来自背景人群的关键点,因为它们通常不在回归关键点的附近,因此会有较低的结果分数。
步骤四:通过检索每个关键点通道中的最大热图值的坐标,选择关键点预测的最终集合。再在这些坐标上添加局部二维偏移预测值,以获得精确的估计。请看下图,其中演示了这四个步骤。

MoveNet 后处理步骤
训练数据集
MoveNet 是在两个数据集上训练的:COCO 和一个名为 Active 的谷歌内部数据集。虽然 COCO 是检测的基准数据集 —— 由于其场景和规模的多样性 —— 但它并不适合于健身和舞蹈应用,因为它们的姿态具有挑战性,动作也很模糊。Active 通过在 YouTube 上的瑜伽、健身和舞蹈视频中标注关键点(采用了 COCO 的 17 个身体关键点标准)而产生。在训练时,每段视频不要超过三帧,以促进场景和个体的多样性。
对于 Active 验证数据集的评估表明,与仅使用 COCO 训练的相同架构相比,性能得到了显著提高。这并不令人惊讶,因为 COCO 通常不会表现出极端的个人姿态(比如瑜伽,俯卧撑,倒立等等)。
想知道更多关于数据集和 MoveNet 在不同类别中的表现的信息,请参阅 模型卡。

来自 Active 关键点数据集的图像
优化
尽管为了使 MoveNet 成为高质量的检测器,在架构设计、后处理逻辑和数据选择方面做了很多工作,但是在推理速度上也给予了同样的重视。第一,选择 MobileNetV2 的瓶颈层作为 FPN 的横向连接。与此类似,每个预测头中的卷积过滤器的数量也会大幅度减少,以加速特征图的输出。整个网络使用了深度可分离卷积,只有第一个 MobileNetV2 层除外。
反复分析后, MoveNet 发现并移除特别慢的操作。比如,我们将 tf.math.argmax 替换为 tf.math.top_k,因为它的执行速度更快,并且能够满足单人使用的设置。
为保证快速执行 TensorFlow.js,所有模型输出都被封装为单个输出张量,因此只有一次从 GPU 下载到 CPU。
可能最显著的加速是 192x192 的输入用于模型 (Thunder 为 256x256)。为消除分辨率偏低的问题,我们采用基于前一帧检测结果的智能剪裁算法。这样,模型就可以把它的注意力和资源集中在主要的对象上,而非背景上。
时间域滤波
对于高帧速率的摄像机流操作,可以平滑估计关键点。Lightning 和 Thunder 都将强大的非线性滤波应用于传入的关键点预测流。这个滤波器能同时抑制来自模型的高频噪音(即抖动)和异常值,同时保持高速运动时的高带宽吞吐量。这样可以使关键点变得平滑,在所有情况下都有最小的延迟。
MoveNet 浏览器性能
为对 MoveNet 的推理速度进行量化,该模型在多个设备上进行了基准测试。在使用 WebGL 的 GPU 和 WebAssembly(WASM)上测量了模型的延迟(用 FPS 表示),后者通常是低端或无 GPU 设备的后端。
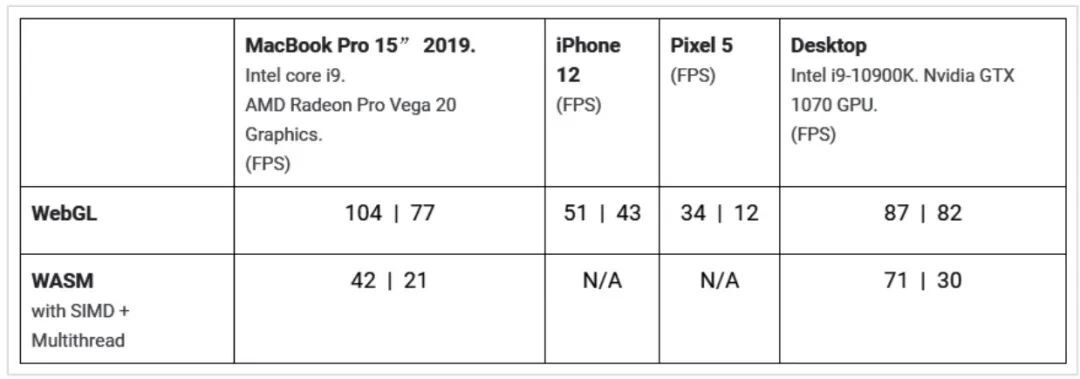
不同设备和 TF.js 后端的 MoveNet 推理速度。每个单元格中的第一个数字是 Lightning 的,第二个数字是 Thunder 的
TF.js 不断优化其后端,以加速模型在所有支持设备上的执行。这里,我们应用了几种技术来帮助模型实现这一性能,例如为深度可分离卷积实现 打包 WebGL 内核,以及改善移动版本的 Chrome 浏览器的 GL 调度。
要在你的设备上看到模型的 FPS,请尝试我们的演示。你可以在演示界面上切换模型类型和后端,以查看哪些适合你的设备。
未来展望
接下来,我们要把 Lightning 和 Thunder 的模式扩展到多人领域,这样开发者们就可以在相机场景中支持多人应用了。
同时我们也打算加速 TensorFlow.js 的后端,让模型执行得更快。通过重复的基准测试和后端优化可以做到这一点。
作者介绍:
Ronny Votel,关注工程学、机器学习、计算机视觉、数据分析、软件设计等等。
Na Li,谷歌高级软件工程师,目前在谷歌大脑工作,为机器学习开发一些东西,可用 Web 技术、JavaScript、WebGL、WebAsm 等在浏览器中运行。也是一位经验丰富的全栈工程师。本科毕业于中国上海交通大学。
原文链接:




