欢迎阅读新一期的数据库内核杂谈。近期,一类新型的数据库,vector database (或者 vector-based database,向量数据库)火了,比如Pinecone,Pinecone 最近还完成一笔新的融资。也不乏一些关系型数据库往向量数据库转型或提供 vector 相关功能(如SingleStoreDB)。受到关注的原因就是向量数据库对于 AI 和机器学习系统,特别是在这波大模型热潮中,可以发挥非常重要的作用。对于 LLM(large language model)应用,通常文本会被转换成向量 vector embedding(VE)来存储。向量数据库就是专门用来存储这类语义向量,并提供针对 VE 的高效查询操作。内核杂谈也紧跟潮流,开启一个新系列,让我们一起来学习向量数据库 vector database 吧。
什么是 Vector Embedding(VE)
典型的数据应用场景下,我们会使用关系型数据库用结构化的数据来存储和描述一个对象实体。比如,我们可以用一张 student 表(id, name, class, ...)来描述学生实体。在人工智能,或者机器学习领域,要处理的对象的 property(对应到关系型数据库中的 column)会非常多且复杂。举个例子,我们希望构建一个预测模型来预测一个房子的房价,要考量的因素就很多了:地区,建筑年份,大小,房间数,周围环境等。在机器学习领域,构建对象的 property 叫做特征工程,feature engineeirng(插一句题外话,特征工程是影响模型准确性很关键的 factor,不亚于对模型本身的改造)。但对于一些非结构化数据,比如自然语言处理中的文本、视觉的图片、视频或者音频,就很难做人工 feature engineering,更别说再转换成结构化的 column 形式了。
于是,科学家们发明了 Embedding,将一个对象表达成一个 N 维的向量([0.3, 0.2, 4.3, ...])。从人工智能领域的门外汉角度,我来试着解释一下这个 N 维向量是如何生成的,以及为什么这个 N 维向量就可以是这个对象的 feature engineering。
在一个典型的深度神经网络里,前置的神经网络通常用来学习低维度的 feature,随着神经网络 layer 的深入,不断把低维度的 feature 组合起来,形成更高维度的 feature。最终,神经网络通常将某个数据归类到某个 output(比如一个 classification 分类模型)。神经网络的最后一层 layer 通常是全连接层或者 softmax 层,将高维信息映射到最终的分类结果。而 Embedding 的计算逻辑就是,把这最后一层敲掉(chop off),直接输出倒数第二层的 output,得到的结果就是一个 N 维的向量。所以,这边的 N 是被定义的(取决于模型的倒数第二层)。举个例子,常见的 Word2Vec 的 embedding size 在 200 到 300,如果你用最新的 OpenAI 的 embedding API(模型是 text-embedding-ada-002),输出的 embedding size 是 1536。但这 1536 个维度,每个维度分别代表什么含义,是不具备解释性的。或者说,每个维度不能用人类的理解来解释,但对机器和这个模型是有意义的。用机器学习的术语,就是将对象投射到一个低维度的空间(虽然,我觉得 1536 看着像一个高维空间,感觉越说越像三体)。
那这个 VE 计算出来有什么用呢? 首先,它提供了一个复杂对象的数学表达形式(N 维向量),且这个向量记录了这个对象的高维语义信息。这句话解释起来就有些抽象了:不同对象的语义相似度,可以对应到这两个向量在向量空间的相似度。一图胜千言,用下面这张图来解释一下。
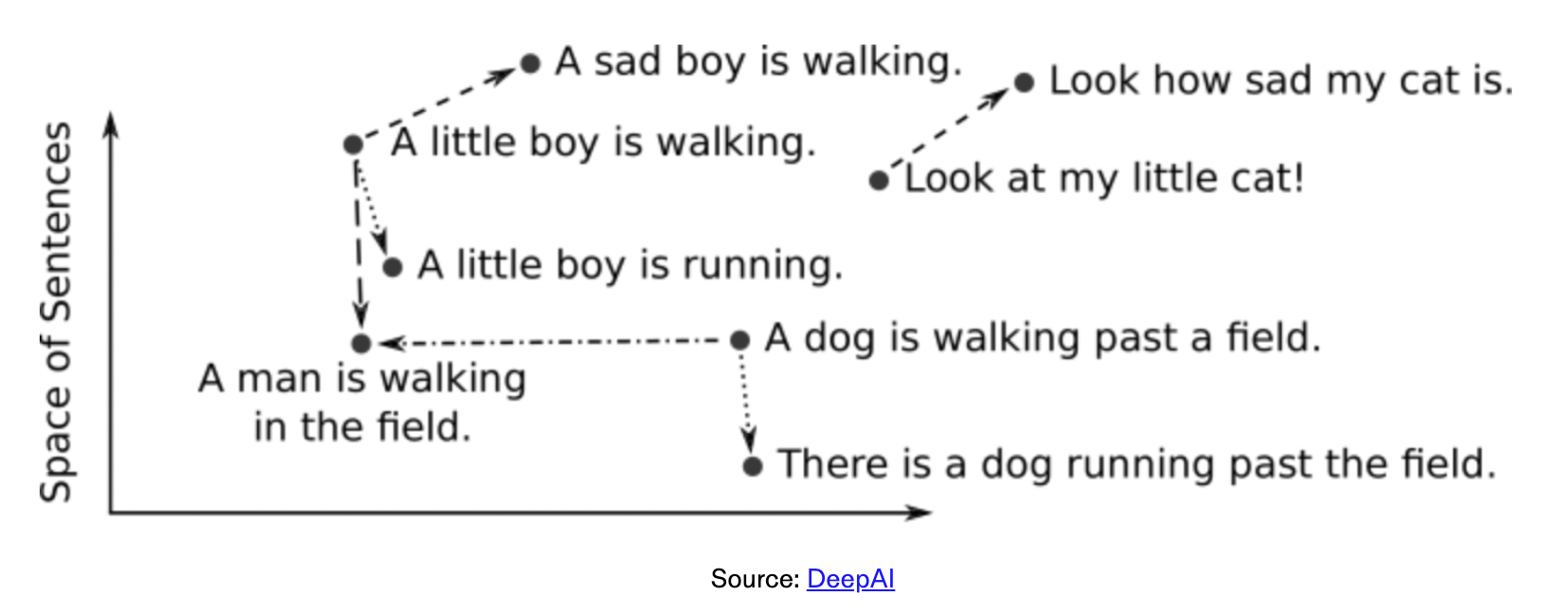
首先,这是一个高维的 VE(我们只是画在二维平面上)。两个向量的距离,比如 a little boy is walking 和 a sad boy is walking,这个距离和另一对向量,look how sad my cat is, 和 look at my little cat 的距离应该是非常接近。这就是语义相似度。另一个很常见的例子是,国王和王后的距离与男人和女人的距离非常接近。常见的向量的相似度计算方法是 Cosine Similarity 余弦相似度(https://en.wikipedia.org/wiki/Cosine_similarity)。
读者可能会问,好神奇啊,为什么这个向量就能包含语义信息,且能体现不同对象的相似度呢?因为,这是一个后验事实:这个神经网络是用了大量被 label 过的数据训练以后得到的结果。即,这个分类模型,经过大量数据训练,预测结果已经很准确了。那去掉最后分类层的 embedding 也可以被认为是保留了高纬度的语义信息。即,如果语义信息没有被保留,那分类结果就不会这么准确。
Embedding 的实际应用
如上段所示,VE 提供了一种机器能够理解和处理的方式来描述原本非常复杂的对象。并且,VE 保留了高维度的语义信息:不同的对象投影在一个向量空间里面,就可以通过数学计算来找到相似性,similarity search(如上述示例所示)。实际情况中,绝大部分的应用都是基于寻找相似性的。下面是一些常见的应用介绍:
1)推荐系统:推荐系统可以将用户和购买的物品都生成 VE,并通过相似性来推荐新物品。
2)搜索系统:搜索和推荐类似,可以将查询生成 VE,再去通过 VE 搜索相似的结果。
3)异常检测:VE 可以用于检测数据中的异常模式或异常点。例如,在信用卡欺诈检测中,每个交易都可以用 VE 来描述。与正常交易明显不同的交易可能被标记为欺诈行为。
4)自然语言理解和语音识别:在 Google 翻译,或者语音助手(SIRI,Alexa 等),文本和文字音频都是通过 VE 的形式输入到系统中做语义理解。相关应用有:机器翻译、情感分析、命名对象识别等。我自己通过 OpenAI 的 embedding 做了情感分析(sentiment analysis):给一个评价(比如针对某个产品或者餐厅),判断是好评还是差评,下文会给出 demo 代码。
Play With Embedding
接下来,咱们实操一下如何使用 embedding。下面是我基于 OpenAI 的 Embedding API(https://platform.openai.com/docs/guides/embeddings)写的 demo 代码。

代码非常简单,我们通过调用 OpenAI 的 get_embedding 方法获得文本"The food is awesome!"的 embedding,并打印结果。

可以看到,OpenAI 的 embedding size 是 1536,也试着打印出来一部分 vector,虽然这部分的 vector 不具备任何解释性。
接下来,我们用 embedding 来做 sentiment analysis(情感分析)。我的做法比较粗糙:首先创建两个 anchor embedding 来代表 positive review 和 negative review;给定一个具体的 review,分别求这个 review embedding 和上面两个 embedding 的 cosine similarity 再做差值。按照 cosine similarity, 如果两个 embedding 的夹角更小(更相似),它们的值应该更接近 1,也更大。因此,分别求出和 positive embedding 和 negative embedding 的值后相减,如果>0 就是 positive 的,反之这是 negative 的。
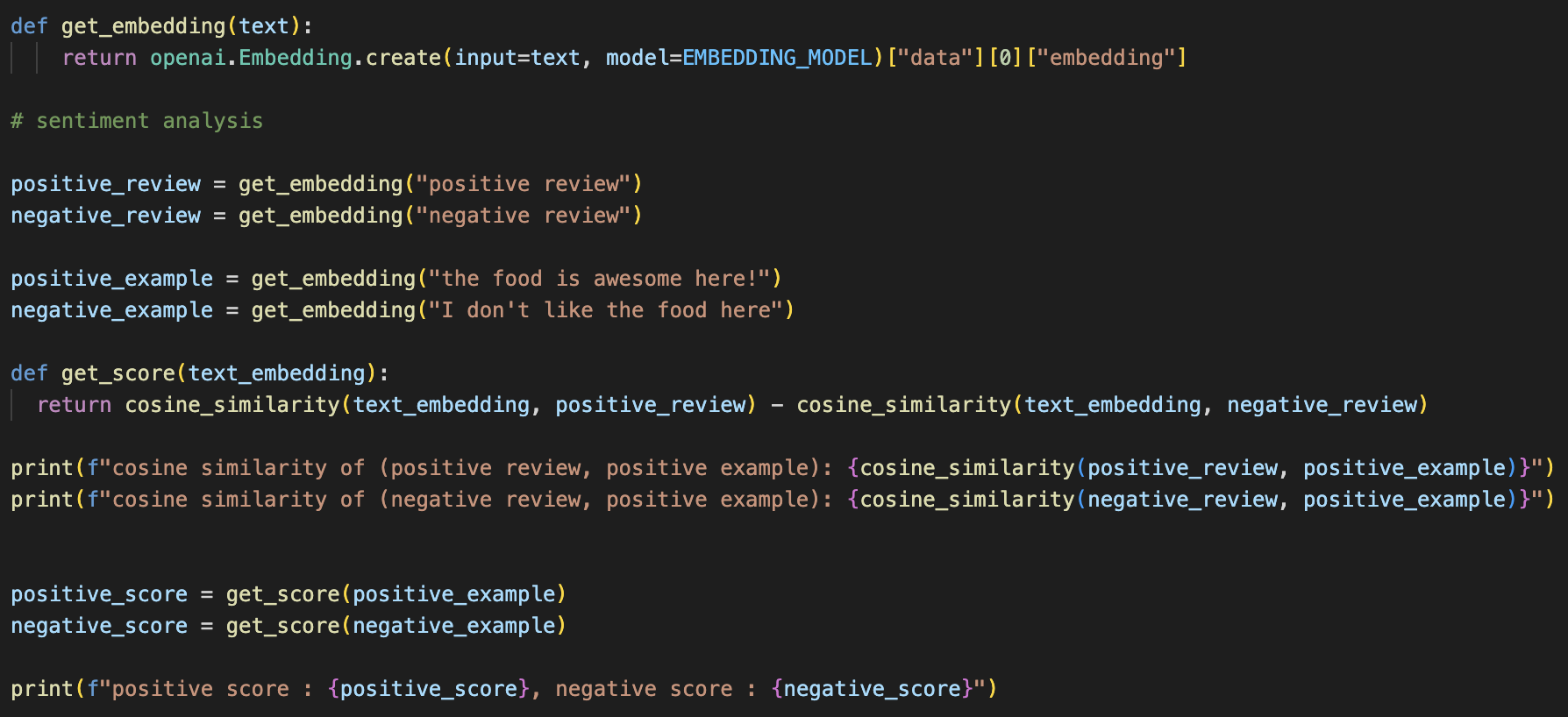
这段代码的输出如下:

可以看到"the food is awesome here"的得分是正值,而"I don't like the food here"是负值。当然,我觉得,这边的 anchor 可以选两个更好的锚定 embedding,结果应该会更好。
总结 &预告
咱们花了一整期介绍什么是 vector embedding,以及为什么需要 vector embedding。有了这些背景,终于可以引出为什么需要 vector database(向量数据库)了。向量数据库旨在提供一种原生的,更高效的对 vector embedding 的使用(无论是从存储,或者是查询的角度)。相比于传统的关系型数据库,向量数据库的挑战在于,如何能够存储下成千上亿个 VE,并提供类似于相似度查询,聚类查询等基于 VE 的操作,同时,也需要具备典型数据库的功能。下一期,我们继续。感谢阅读!
内核杂谈微信群和知识星球
如果觉得有收获,也愿意请我喝杯咖啡的话,可以在爱发电平台打赏我:https://afdian.net/a/zzzgu/plan
目前我有全职工作,求打赏完全是出于可以让我分泌更多的多巴胺(任何非工作收入都算天降之财!)。重要的话说三遍:请完全出于自愿打赏(如果你是学生,请务必不要打赏)!请完全出于自愿打赏(如果你是学生,请务必不要打赏)!请完全出于自愿打赏(如果你是学生,请务必不要打赏)!
内核杂谈有个微信群,大家会在上面讨论数据库相关话题。目前群人数超过 400 人啦,所以不能分享群名片加入。可以添加我的微信(zhongxiangu)或者是内核杂谈编辑的微信(wyp_34358),请备注:内核杂谈。
除了数据库内核的专题 blog,我还会 push 自己分享每天看到的有趣的 IT 新闻,放在我的知识星球里(免费的,为爱发电),欢迎加入。