
作者|曾祥华 北京航空航天大学 博士生
本文介绍来自北京航空航天大学彭浩老师团队发表在 NeurlPS 2024 上的一篇文章“Effective Exploration Based on the Structural Information Principles”。为了解决当前基于传统信息论的探索方法由于忽略状态 - 动作空间内在结构而导致效率低下的问题,作者提出了一种基于结构信息原理的探索框架,即 SI2E。SI2E 通过定义结构互信息,提出一种新的状态动作表征原则,捕捉状态 - 动作对之间的动态关系,构建最优编码树。通过分析状态 - 动作对之间的价值差异,定义策略条件结构熵,构造内在奖励机制,实现对于状态 - 动作空间更为有效的覆盖。在 MiniGrid、MetaWorld 和 DeepMind Control Suite 等测试环境中,SI2E 在最终性能与采样效率等方面的表现遥遥领先,最大提升幅度分别达到了 37.63% 和 60.25%。
论文名称:Effective Exploration Based on the Structural Information Principles
引 言
在强化学习(RL)领域,智能体探索和利用行为之间平衡至关重要,尤其在高维度观测和稀疏奖励的场景中。最近,基于传统信息论的探索方法在自监督设置中最大化对于状态空间与动作空间的覆盖,以优化智能体策略并减轻次优结果的风险。然而,上述方法存在两个挑战,目前尚未解决:
挑战 1:传统最大熵策略容易受到价值分布影响,导致偏向于低值状态的不平衡探索
为减轻这一问题,该团队引入了以策略值为条件的高维结构熵。基于对状态 - 动作对的价值估计解析层次化社区结构,并依据智能体探索行为定义内在奖励,构建奖励塑形机制,在最大化整个状态 - 动作空间的覆盖的基础上,避免对于低值社区的无效覆盖。
挑战 2:当前的结构信息研究存在单一变量限制,并未涉及对多变量之间的关系建模
在这项工作中,作者提出了结构互信息的概念,首次实现对于多变量之间结构相似性的度量,进一步提出对于状态 - 动作对的表征原则,在捕捉环境动态信息的同时,避免无效的观测干扰。
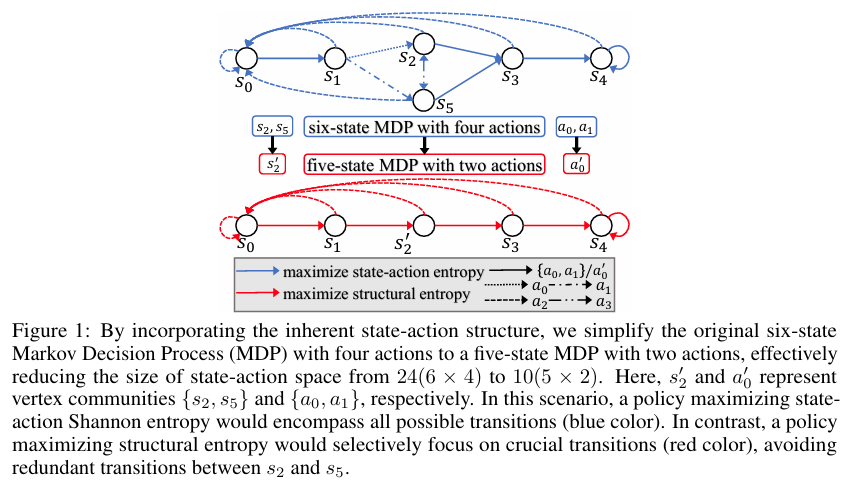
图 1 说明了一个简单的六状态马尔可夫决策过程 (MDP),其中包含四个动作。如图例所示,蓝线和红线的不同密度代表不同的动作,导致状态转换,旨在返回初始状态。实线特别表示动作和。状态和之间的转换被视为冗余,因为它们不利于实现有效返回的主要目标。因此,状态 - 动作对和具有较低的策略值。最大化状态 - 动作香农熵的策略将涵盖所有可能的转换(蓝色)。相反,整合固有状态 - 动作空间结构的最大熵策略会将这些冗余的状态 - 动作对划分为顶点子社区,并最小化该子社区的熵以避免不必要地访问它。同时,它最大化了状态 - 动作熵,从而最大限度地覆盖了更有可能在简化的五状态 MDP 中促成期望结果的转换(红色)。
结构互信息
该团队解决了现有结构信息原理中普遍存在的单变量约束,并引入了结构互信息的概念,以便在 SI2E 框架内进行后续的状态 - 动作表示学习。
给定随机变量对,,构造一个带权无向二分图来表示和变量间的联合分布,同时限制该图上的编码树为二层近似二叉结构,并得到最优的近似二叉树:
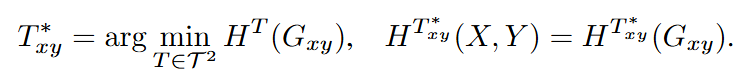
最优近似二叉树中的每个中间节点对应一个包含单一顶点与单一顶点的子集,从而在变量与之间建立一个一一匹配结构。对于中从左到右排序的第个中间节点标记为,在对应的子集中和顶点分别被标记为和。
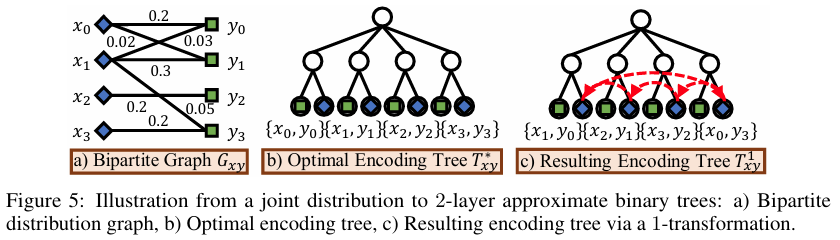
为了准确定义结构互信息,需要考虑不同划分结构下两个变量的联合熵。作者引入一个应用于的 - 转换算子,以系统地遍历这些变量的所有潜在一对一匹配结构,从而提供对于结构相似性的全面度量。给定一个整数参数,该算子生成一个新的二层近似二叉树。
下图给出了一个对于上述过程的直观解释。
结构互信息定义:
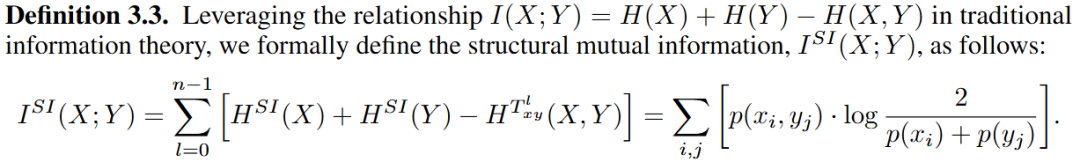
结构互信息与传统互信息之间的关系:
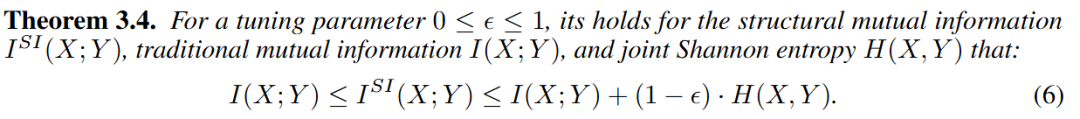
SI2E 框架设计
所提出 SI2E 框架的详细设计如下图所示,主要包含状态动作表征与智能体探索模块。
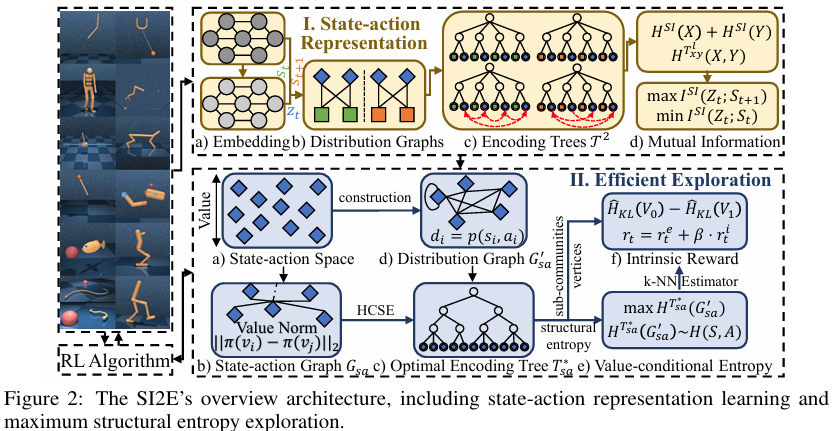
状态动作表征
结构互信息原理
为了有效地学习与环境动态信息相关的状态 - 动作表示,作者提出了一种创新的表征原则,该原则最大化了与后续状态的结构互信息,并最小化了与当前状态的结构互信息。
在该阶段,作者利用编码器和将当前观察值和表示为状态和,并生成对于元组的潜在表示。通过构建无向二部图和,作者分析与当前状态和随后状态的联合分布。通过计算互信息和,作者基于信息瓶颈 (IB),提出了一种表征原则,旨在最小化同时最大化。当与之间的联合分布呈一一对应时,它们的互信息达到最大值,这表明每个值都有唯一值与之对应,反之亦然。因此,结构互信息可以被认为是获取动态相关状态 - 行为表示的理想学习目标。
表征学习目标
在研究中,由于直接最小化存在计算挑战,作者提出了一个变分上界,将最小化转化为最小化和。通过利用一个可行的解码器来近似的边缘分布,得出了的一个上界。同时,为了降低条件熵,作者引入了一个预测目标,通过解码器来近似条件概率。同时,为了有效优化,作者最大化其下界。通过使用一个替代解码器来近似条件概率,得到了的一个下界。
最大结构熵探索
作者设计了一个独特的内在奖励机制,以解决传统熵策略中对低价值状态的不平衡探索的挑战。具体来说,基于策略函数生成了状态 - 动作空间的层次化社区结构,并依据智能体访问概率定义价值条件结构熵,实现更为有效的最大化覆盖探索。
分层状态 - 动作结构
作者从智能体与环境的交互历史中提取状态 - 动作对,形成一个完整的图,其中反映了智能体策略引起的价值关系。在这个图中,任意两个顶点和通过一条无向边连接,其权重由状态 - 动作对和的策略值差异确定。通过最小化图的二维结构熵,生成了二层最优编码树。该树描述了状态 - 动作顶点之间的分层社区结构,根节点涵盖所有顶点,每个中间节点对应于一个子社区,其中的顶点共享相似的策略值。
值条件结构熵
为了衡量智能体探索在状态 - 动作空间中的覆盖程度,作者构建了一个额外的分布图,与原图共享相同的顶点集。对于所有状态 - 动作对,给定正的访问概率,作者证明了该加权、无向、连通图的存在性,其中每个顶点的度数与其访问概率成正比。
在图中,状态 - 动作顶点集合为,状态 - 动作子社区集合为。与这些集合的访问概率分布相关联的香农熵分别表示为和 (),其中等同于整个状态 - 动作空间的香农熵。在二层状态 - 动作社区内,定义了的结构熵。理论证明了结构熵和香农熵之间存在如下关系:
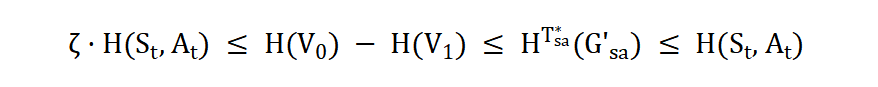
其中,是的一个变分下界。因此,在确保整个状态 - 动作空间最大覆盖的同时,缓解了状态 - 动作子社区之间不均匀覆盖的问题。通过识别智能体策略引起的分层状态 - 动作结构,SI2E 实现了更为有效的最大覆盖探索,确保了其探索优势。
评估和内在奖励
在面对直接获取访问概率的不可行性时,作者研究采用了 k-NN 熵估计器来估计条件结构熵下界,以评估状态 - 动作空间的覆盖程度。通过使用这个估计器得到的结果,可以定义内在奖励,并结合外部任务奖励,训练强化学习智能体来解决目标任务。
实验与评估
为了验证该框架的性能优势,作者在 MiniGrid、MetaWorld 和 DMControl 等环境中进行了一系列综合性的对比实验。
MiniGrid 实验对比
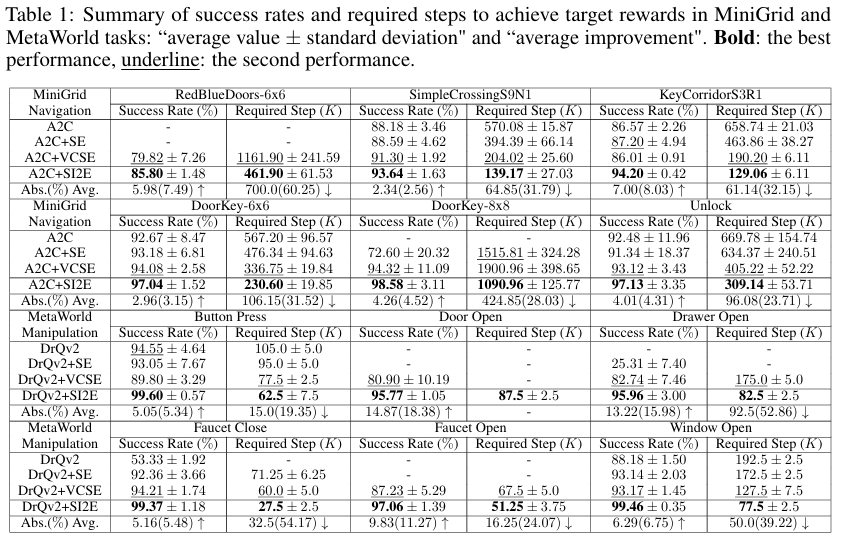
在 MiniGrid 基准测试中,作者评估了 SI2E 在导航任务中的表现,这些任务旨在在稀疏奖励环境中实现目标。该设置是部分可观察的,智能体接收到周围网格的 7×7×3 嵌入而不是整个网格环境。作者采用 A2C 智能体作为基准,并将香农熵和基于价值的状态熵(VCSE)作为对比。实验结果显示,在各种导航任务中,包括带障碍物的导航、长期导航以及带障碍物的长期导航,如表 1 所示,SI2E 在最终性能和样本效率方面表现出显著改善。
MetaWorld 实验对比
作者进一步在 MetaWorld 基准测试中的视觉操作任务上评估 SI2E 框架,该基准测试由于其庞大的状态空间而提出了探索性挑战。作者选择 DrQv2 算法作为基础 RL 方法。采用相同的摄像头配置,并将奖励标准化为 1。同时,表 1 中总结了所有探索方法在六个 MetaWorld 任务中的成功率和所需步骤,从而证明了 SI2E 的性能优势。
DMControl 实验对比
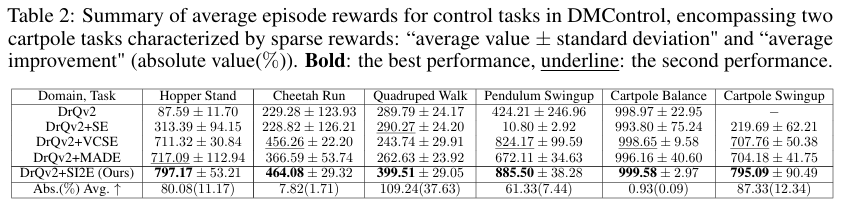
此外,该团队在 DMControl 套件中的连续控制任务中对 SI2E 框架进行了评估,同样选用了 DrQv2 算法作为基础智能体,该算法基于像素观察进行操作。为了更全面地比较,引入了 MADE 作为状态 - 动作探索基线。通过评估六个连续控制任务中所有探索方法的表现并记录在表 2 中,观察结果显示,SI2E 显著提高了每个 DMControl 任务的平均集奖励。
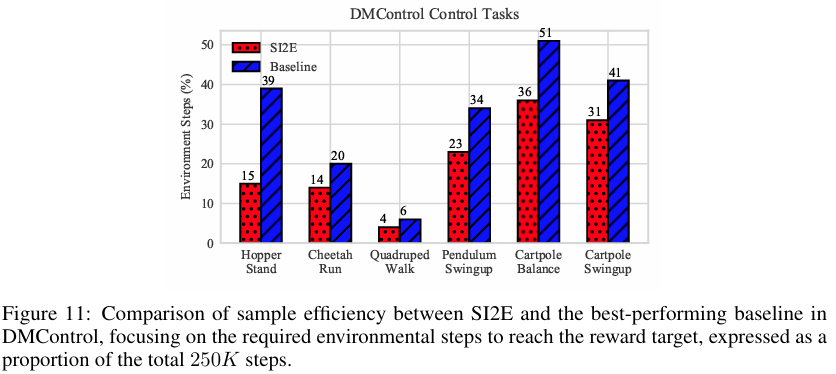
下图中对比了 SI2E 和最佳基线的样本效率。这些结果不仅展示了 SI2E 在获取与动态相关的状态 - 动作表示方面的有效性,还突显了其激励智能体探索状态 - 动作空间的潜力。
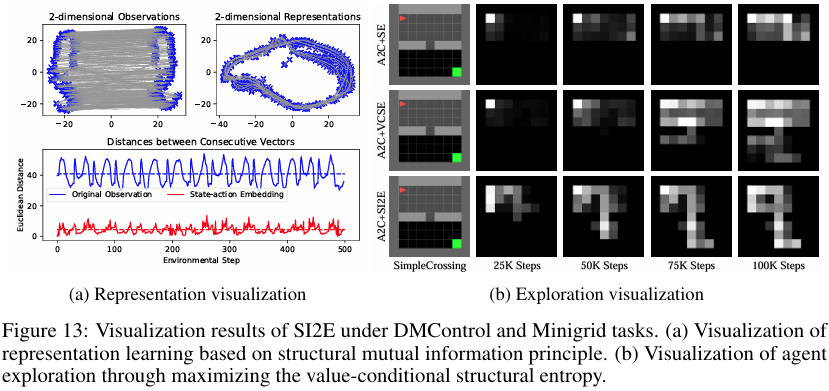
为了更好地理解 SI2E 框架的合理性和优势,下图提供了 SI2E 表征结果与探索行为的可视化实验:(a) 基于结构互信息原理的表示学习可视化,(b) 通过最大化价值条件结构熵实现智能体探索的可视化。
消融实验
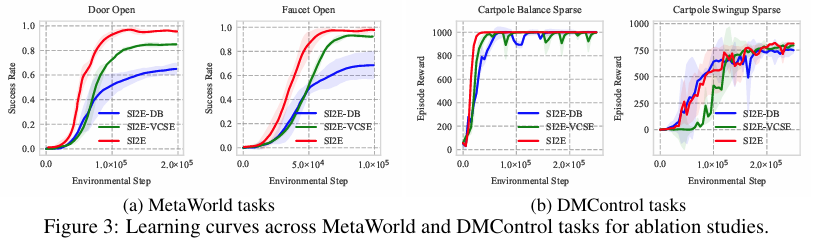
通过对 MetaWorld 和 DMControl 任务进行消融实验,作者专注于研究 SI2E 框架中嵌入原则和内在奖励机制这两个关键组成部分的影响。关注了两个不同变体:(i) SI2E-DB,利用 DB 瓶颈来学习状态 - 动作表示,(ii) SI2E-VCSE,采用最先进的 VCSE 方法来计算内在奖励。结果显示,如下图所示,SI2E 在最终性能和样本效率方面均优于所有变体,这表明这些关键组件在赋予 SI2E 卓越能力方面起着重要作用。
结论及展望
作者提出了一种基于结构信息原理的新型智能体探索框架 SI2E。该框架定义了结构互信息,以有效捕获与环境动态相关的状态 - 动作表示。它最大化了以价值为条件的高维结构熵,以增强对于整个状态 - 动作空间更为有效的覆盖。同时,建立了 SI2E 与传统信息论探索方法之间的理论联系,凸显了该框架的合理性和优势。通过广泛的对比评估,与最先进的探索方法相比,SI2E 显著提高了最终性能和取样效率。作者未来的工作包括扩展编码树的高度和实验环境的范围。作者的目标是让 SI2E 在强化学习中保持一个强大和适应性强的工具,特别适合高维和稀疏奖励的环境。
篇幅原因,我们在本文中省略了诸多细节,更多细节可以在论文中找到。




