
两个月三连发,通义千问又开源了。
9 月 25 日,阿里云开源通义千问 140 亿参数模型 Qwen-14B 及其对话模型 Qwen-14B-Chat,支持免费商用。在多项权威评测中,Qwen-14B 的性能表现超越同等规模模型,部分指标甚至接近 Llama2-70B。此前阿里云于 8 月开源了通义千问 70 亿参数基座模型 Qwen-7B,先后冲上 HuggingFace、GitHub 的 Trending 榜单。短短一个多月,累计下载量就突破 100 万,开源社区出现了约 50 个基于 Qwen 的模型。
多个知名工具和框架都集成了 Qwen,如支持用大模型搭建 WebUI、API 以及微调的工具 FastChat、量化模型框架 AutoGPTQ、大模型部署和推理框架 LMDeploy、大模型微调框架 XTuner 等等。
据了解,此次开源的 Qwen-14B 是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过 3 万亿 Token,使模型具备更强大的推理、认知、规划和记忆能力。Qwen-14B 最大支持 8k 的上下文窗口长度。
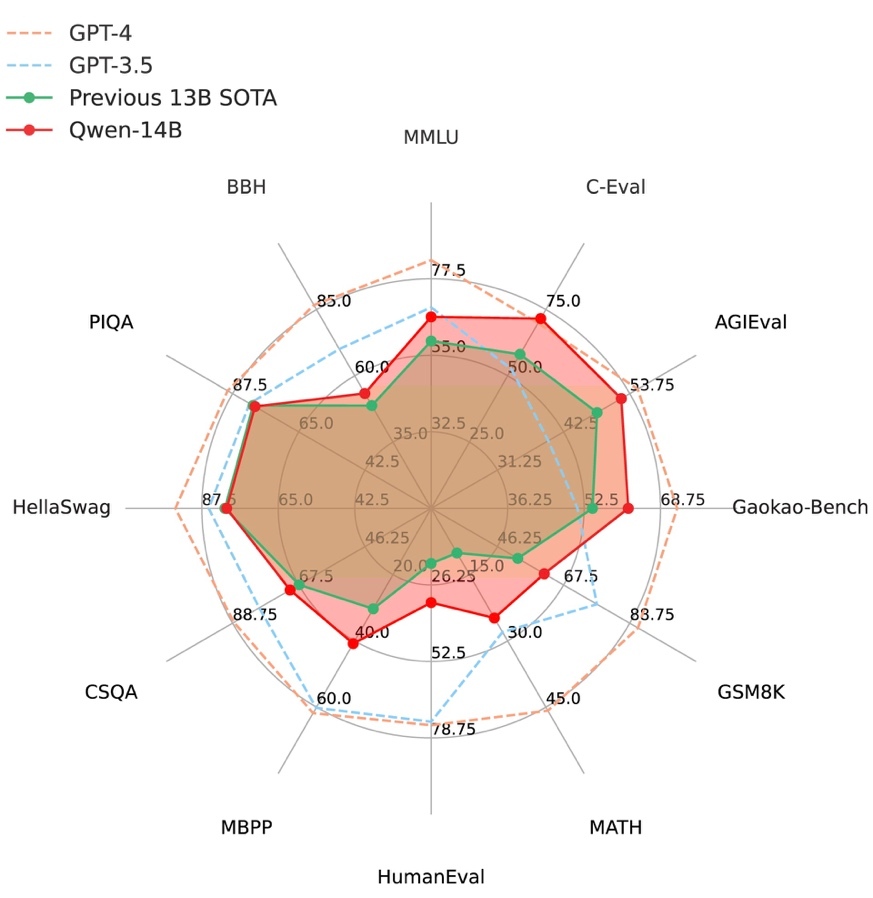
图 1:Qwen-14B 在十二个权威测评中全方位超越同规模 SOTA 大模型
而 Qwen-14B-Chat 则是在基座模型上经过精细 SFT 得到的对话模型。借助基座模型强大的性能,Qwen-14B-Chat 生成内容的准确度大幅提升,也更符合人类偏好,内容创作上的想象力和丰富度也有显著扩展。
Qwen 拥有出色的工具调用能力,能让开发者更快地构建基于 Qwen 的 Agent(智能体)。开发者可用简单指令教会 Qwen 使用复杂工具,比如使用 Code Interpreter 工具执行 Python 代码以进行复杂的数学计算数据分析、图表绘制等;还能开发具有多文档问答、长文写作等能力的“高级数字助理”。
百亿以内参数级别大语言模型是目前开发者进行应用开发和迭代的主流选择, Qwen-14B 进一步提高了小尺寸模型的性能上限,从众多同尺寸模型中冲出重围,在 MMLU、C-Eval、GSM8K、MATH、GaoKao-Bench 等 12 个权威测评中取得最优成绩,超越所有测评中的 SOTA(State-Of-The-Art)大模型,也全面超越 Llama 2-13B,比起 Llama 2 的 34B、70B 模型也并不逊色。与此同时,Qwen-7B 也全新升级,核心指标最高提升 22.5%。
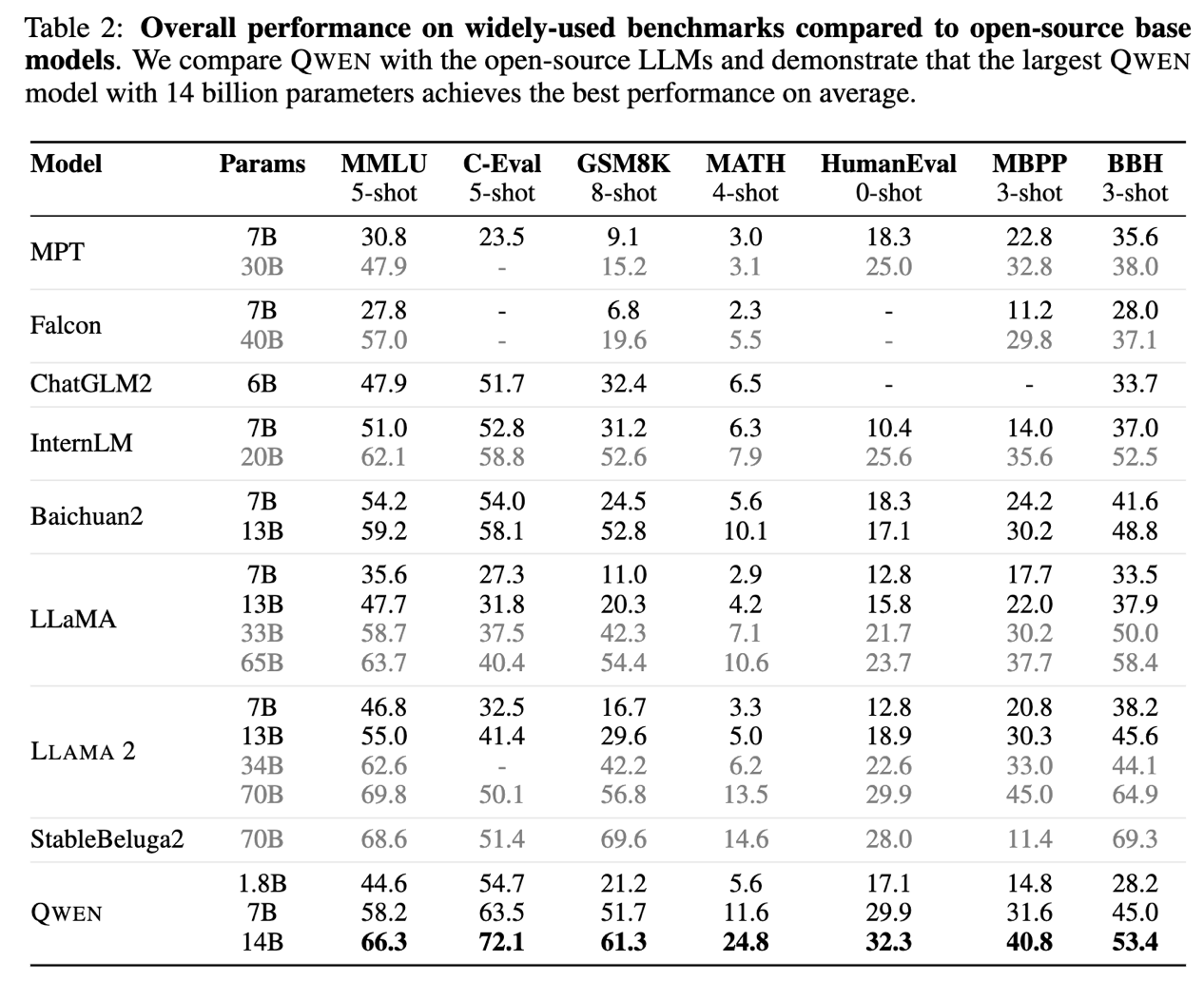
图 2:Qwen-14B 性能超越同尺寸模型
据 InfoQ 向通义千问研发团队了解,Qwen-14B 之所以能较上一代 Qwen-7B 获得显著的性能提升,主要有三方面原因。
在数据集构建方面:
研发团队使用了多达 3 万亿 token 的大规模预训练数据集,覆盖了各个领域和千行百业的知识,包含多个语种的语言,还有代码数据。在此基础之上,研发团队做了较为精细的数据处理,包括大规模数据去重、垃圾文本过滤、以及提升高质量数据比例等。
在模型结构设计和训练方法方面:
模型结构方面,研发团队此前做了一系列前期实验验证模型结构设计对效果的影响,整体而言,Google 的 PaLM、Meta 的 LLaMA 的大多数技术选择都是效果较好的,包括 SwiGLU 的激活函数设计、ROPE 的位置编码等,在 Qwen 的结构设计中也都采用了。
通义千问团队专门针对词表做了优化,词表大小超过 15 万,具有较好的编码效率,也就是说,相比其他 tokenizer 能用更少的 token 表示更大量的信息,意味着更加节省的 token 数,或者说更低的成本。
此外,通义千问团队重点针对长序列数据建模做了优化,采用当前最有效的策路,包括但不限于 Dynamnic NTK、Log-N attention scaling、window attention 等,并做了一些细节的调整保证长序列数据上,模型表现效果更稳定。当前模型能够适配井取得稳定表现的序列长度也达到了 8192。
研发团队成员向 InfoQ 表示:“大模型训练其实没有太多复杂的技巧,更多是经过大量尝试与迭代,找到较好的训练参数,达到训练稳定性、训练效果和训练效率的最优平衡,包括但不限于优化器的配置、模型并行的配置等。”
在外接工具能力方面:
此前开源的 Qwen-7B 已经展现出了出色的工具使用能力,只需通过文本描述即可理解并使用未经训练的新工具,可用于各种 Agent 应用。这次开源的新模型进一步增强了 Agent 能力,在使用复杂工具时的可靠性有了显著提升。
例如,Qwen-14B 可以熟练地使用 Code Interpreter 工具执行 Python 代码,进行复杂的数学计算、数据分析和数据图表绘制。同时,Qwen-14B 的规划和记忆能力也得到了提升,在执行多文档问答和长文写作等任务时表现更加可靠。
为了实现这一效果,研发团队主要做了两方面的优化。首先,在微调样本方面进行优化,通过建立更全面的自动评估基准,主动发现了之前 Qwen 表现不稳定的情況,并针对性地使用 Self-Instruct 方法扩充了高质量的微调样本。其次,底座预训练模型的能力得到了提升,带来了更强的理解和代码能力。
即日起,用户可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问和调用 Qwen-14B 和 Qwen-14B-Chat。阿里云为用户提供包括模型训练、推理、部署、精调等在内的全方位服务。
据了解,当前国内已有多个月活过亿的应用接入通义千问,大量中小企业、科研机构和个人开发者都在基于通义千问开发专属大模型或应用产品,如阿里系的淘宝、钉钉、未来精灵,以及外部的科研机构、创业企业。
钉钉是最早接入通义千问的应用之一。4 月 18 日,钉钉发布了一条“斜杠”, 接入千问大模型后,通过输入“/”即可在钉钉唤起 AI 能力,涵盖群聊、文档、视频会议及应用开发等场景。
在群聊中,新入群者无需爬楼,在对话框输入钉钉斜杠“/”即可自动整理群聊要点,快速了解上下文,并生成待办、预约日程。还可以用“/”在群聊中创作文案、表情包等;在钉钉文档中,“/”可以是用户的创意助理,帮助写文案、生成海报。在视频会议中,“/”也是会议助理,能一键生成讨论要点、会议结论、待办事项等;“/”还可用自然语言或拍照生成应用,并以钉钉酷应用的形式在群聊内使用。比如,公司行政人员需要统计午餐的订餐份数,只需要在群聊对话框中输入“/”和需求,几秒钟后一个订餐统计小程序就会展现在群聊中。
在过去 100 多天里,钉钉正逐渐实现全面智能化,已经有 17 条产品线、55 个场景完成了智能化再造,包含钉钉 IM 群聊、酷应用、低代码、钉钉会议、Teambition、闪记、邮箱、钉钉文档、表格、脑图、白板、知识库等,覆盖多模态内容生成、摘要提取、应用开发等。
浙江大学联合高等教育出版社基于 Qwen-7B 开发了智海-三乐教育垂直大模型,已在全国 12 所高校应用,可提供智能问答、试题生成、学习导航、教学评估等能力,模型已在阿里云灵积平台对外提供服务,一行代码即可调用;浙江有鹿机器人科技有限公司在路面清洁机器人中集成了 Qwen-7B,使机器人能以自然语言与用户进行实时交互,理解用户提出的需求,将用户的高层指令进行分析和拆解,做高层的逻辑分析和任务规划,完成清洁任务。
阿里云 CTO 周靖人表示,阿里云将持续拥抱开源开放,推动中国大模型生态建设。阿里云笃信开源开放的力量,率先开源自研大模型,希望让大模型技术更快触达中小企业和个人开发者。
附相关链接:
魔搭社区模型地址:
https://www.modelscope.cn/models/qwen/Qwen-14B-Chat/summary
https://www.modelscope.cn/models/qwen/Qwen-14B/summary
Qwen 论文地址:
https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
GitHub:
https://github.com/QwenLM/Qwen
HuggingFace:
https://huggingface.co/Qwen/Qwen-14B
https://huggingface.co/Qwen/Qwen-14B-Chat




