
导读:自从 2011 年被捐献给 Apache 基金会到现在,Kafka 项目已经走过了七个年头。作为一个优秀的分布式消息系统,Kafka 已经被许多企业采用并成为其大数据架构中不可或缺的一部分。但 Kafka 的野心明显不止于此。从去年 11 月推出 KSQL,到今年 7 月发布 2.0 版本增加诸多新特性,无不是在宣告:Kafka 已经不再只是分布式消息队列,而是集成了分发、存储和计算的“流式数据平台”。与此同时,竞争对手的崛起也给 Kafka 的未来带来了新的变数。在今年 9 月 InfoWorld 发布的最佳开源数据库与数据分析平台奖中,大数据新秀 Pulsar 首次获奖,而在获奖点评中明确提到“Pulsar 旨在取代 Apache Kafka 多年的主宰地位”。
借 Kafka 七周年之际,InfoQ 策划了技术专题《Kafka 的七年之痒》。我们认为,现在是回顾 Kafka 发展历程、展望消息系统未来方向的最佳时刻。Kafka 一路走来都踩了哪些坑?2.0 新特性到底是否好用?为什么 Kafka 要转向流式数据平台,它又有何优势?除了新崛起的竞争对手,Kafka 还面临哪些挑战?我们将在专题系列文章中对这些问题进行探讨。
本文是《Kafka 的七年之痒》专题系列文章的第一篇,整理自王国璋老师在 QCon 2018 上海站的演讲。 从最早的“分布式消息系统”,到现在集成了分发、存储和计算的“流式数据平台”,Kafka 经历了哪些挑战?又经过了什么样的演进变化?Kafka 社区踩过哪些“坑”?本文将为你一一道来。

我今天分享的主题是,我们是一路如何把 Kafka 从 0.7 到 1.0 版本演变到流数据平台的,以及在这一过程中有哪些经验教训。今天的演讲主要分两个部分,上半部分按照时间线跟大家回顾一下 Kafka 从 0.7 进化到 1.0、直至 1.1、2.0 的一些主要特性,下半部分是我个人的总结体会和经验教训。
Kafka 的小历史

尝试
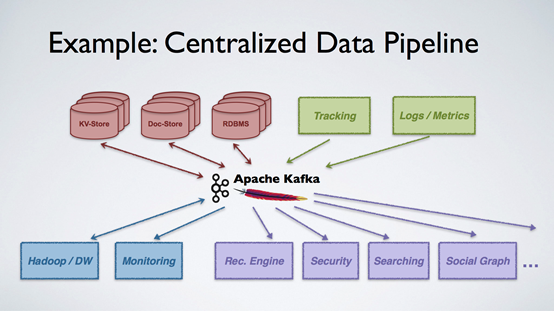
Kafka 是 2010 年左右在 LinkedIn 研发的一套流数据处理平台。当时 LinkedIn 也和很多大的互联网公司一样,分很多的组,有很多的产品,每天收集非常多的数据。这些数据都是实时生成的,比如用户活跃度、日志,我们有各种各样的产品来利用这些数据,数据的产生者和消费者之间采用点对点的数据传输,在运维方面非常耗费人力和物力。所以我们需要一个集中式的数据通道,所有的人都只跟这个数据通道进行交互,不再点对点地传输数据。
从 2010 年开始,我们开始做这方面的尝试,包括消息系统和 MQ 系统。但是后来发现,所有这些 MQ 系统都有两个比较通用的缺陷:一是当消费者出现,无法及时消费的时候,数据就会丢掉;二是可延展性问题,MQ 系统很难很好地配合数据的波峰或波谷。
所以 2010 年我们开始自己开发 Kafka。它的设计理念非常简单,就是一个以 append-only 日志作为核心的数据存储结构。简单来说,就是我们把数据以日志的方式进行组织,所有对于日志的写操作,都提交在日志的最末端,对日志也只能是顺序读取。Kafka 的日志存储是持久化到磁盘上的,虽然普遍感觉上 HDD 非常慢,但其实如果能够把所有的读和写都按照顺序来进行操作,会发现它几乎可以媲美内存的随机访问。另外,我们直接使用文件系统的缓存,如果你读取的基本上是在日志最尾端,那么绝大可能性只会访问到这个文件系统的缓存,而不需落盘。所以它的速度非常快。
接下来要做的是如何做到规模上的可延展性,我们把所有的数据以 Topic 为单位来组织,每个 Topic 可以被分片,存储在不同的服务器上。数据的发布和订阅都基于 Topic,数据更新时,消费端的客户端会自动把它们从服务器上拉取下来。基于 Partition 的扩容会变得非常简单,增加 Partition,然后把它们放在新加入的服务器上,就可以保证 Topic 不断扩容。
0.7 版本,进入 Apache 孵化器
大概不到一年之后, Kafka 就进入了 Apache 孵化器,并且发布了第一个开源的版本 0.7.0。最主要的两个特征就是压缩以及 MirrorMaker,也就是跨集群之间的数据拷贝。
关于压缩,我们是按纯字节组织数据的,也就是说在 0.7.0 版本里面的偏移量是基于字节的。当一个发布者客户端积攒了很多数据,要一次性发布的时候,所有这些数据会被打包成为一个大的 Wrapper message,它可能会包含很多真正的 Message。Wrapper message 其实会存储的所有这些 Message 是加在一起的总的数据偏移量,比如每个 message 是 100,那么总偏移量就是 300。压缩,就是要让它的字节数变少。举个例子,比方说压缩之前是 300 字节,压缩后变成了 50 字节。
但这样的做法,数据的消费端提交这个偏移量的时候,它就只能提交在这些大的、压缩过的 Wrapper message 的边界上。比如,消费一个大的 Message 的时候,这个 Message 里面有一百条数据,只有把这一百条数据全部都消费完以后,才能提交准确的偏移量。原因在于,这个偏移量是压缩过后的偏移量,中途停止或者失败的话,无法提交一个中间的偏移量。这是我们当时用物理的字节作为偏移量的一个弊端,这对于用户来说不够灵活。但它的好处是,服务器不需要知道任何关于这个数据的元数据,它是 bytes-in-bytes-out,而所有的逻辑都是在客户端的。度量结果显示,服务器端的 CPU 利用率基本上不到 10%,而网络 99.9% 的时间都是满的,也就是说我们基本上完全利用了所有的网络带宽。
在 2010 年的时候,我们基本上所有的 Traffic 和 Logging Data 都已经通过 Kafka 来传输了,这是 Kafka 当时在领英的第一个用户,也可以说是第一个使用场景。
0.8 版本,高可用性
在 2012 年的时候,Kafka 就正式从孵化器里面毕业,成为了 Apache 的顶级项目。同时,我们发布了 0.8.0。日后来看,它是一个将 Kafka 区别于非常多其他流数据平台的版本。因为我们在 0.8.0 里面加入了高可用性,也就是基于备份的一个高可用性的特性。
在之前,一个服务器端失败了,会导致这个服务器端所存的流数据在恢复之前无法再被取得,更有甚者,这些流数据永远丢失了。这也是为什么在 0.7 版本的时候,当时最大的使用场景是 Logging Data 以及 User Data,这些 Data 丢了就丢了,对于公司影响不是那么大。但是,如果要保存重要的数据,每条价值几美元,没有高可用性是不合适的,所以在 0.8 版本里面我们提出要增加这样一个特性。
这里我简单讲一下 Kafka 0.8 的 replication。每一个 Topic 都被分片 partition,每个 partition 会被备份到多台机器上。我们把每个 partition 叫做一个 replica,至于 Partition 的 replica 置放,基本上是一个简单的轮询。比如,Topic1 的第一个 Partition 被分配到 123,第二个 Partition 被分配到 231 等等。每一个 Group 里,有一个 Partition 会成为 Leader,这个 Leader 来进行所有读写请求的操作。也就是说,当客户端发布信息、读取信息的时候,都是和这个 leader 交互,并且 Leader 负责把已经发布的数据再备份到其他的 replica 上。
2011 年的时候呢,我们看了很多备份、管理数据的协议,提出了一个理念:对于流数据,我们希望基于简单的协议做数据备份,而备份之间的管理要基于复杂的协议。当时很多产品都是以同一套协议来做两件事情。所以,在 0.8 版本里面,相当于我们自己开发了一套数据备份协议。
我们当时提出了一个叫做 ISR,或者叫做实时备份列表的机制。我们把所有的备份分为已同步和未同步的备份。已同步的备份指,Leader 所有的 Data 在 replica 里面都有;未同步的很简单,由于可能比较慢,或者备份还不完整,也许有些数据在 Leader 上面有,但是在 replica 上没有。Leader 可以通过来管理这样的一个列表来做到实时的修改。同时,发布者发布信息的时候,可以要求备份方式。
我们在 0.8 中通过一个控制器来做到备份的灵活处理,它主要包括三点:第一点就是通过 Zookeeper 来监测每一个服务器是否还在运转,当需要选择新的 Leader 甚至 RSR 时,这个控制器可以进行 Leader 的选举,最后把这个 Leader 上新的数据发布到所有 broker 上。当时我们做了很多测试,所有的客户、所有的服务器端都跟 Zookeeper 进行直接交互的话,那么 Zookeeper 的压力会非常大。而这个控制器就起到一个在 Zookeeper 跟其他服务器之间协同的角色,也就是说只有控制器需要跟 Zookeeper 之间进行大量的交互,当它得到了一些新的元数据的更新以后,再把这些数据发布到其他所有的 broker 上。
在 2012 年的时候,Kafka 就已经在 LinkedIn 公司内部完成了对所有在线流数据的传输整合,不仅对 LinkedIn 内部,对整个业界也产生了很大的影响。由于这个高可用性的特性,Kafka 脱颖而出,成为了当时整合流数据传输的集中式通道的更好选择。
在 0.8 版本里我们还更新了消息的数据结构,把数据偏移量改成了按逻辑的,每条信息的数据偏移量就是 1,不管消息有多大。当压缩和解压缩时,你就需要知道压缩过后的数据里包含了多少小数据,可以通过增加偏移量来增加大数据的偏移量。举个例子,第一个大的数据,压缩包里面包含了三个小数据,它们本身的偏移量是 012,那么包压缩的偏移量就是 2,也就是最后那个数据所对应的逻辑偏移量。当下一个消息被发布的时候,再根据已有的偏移量和压缩的数据重新计算偏移量。所以在 0.8 里,已经逐渐将系统性能压力向 CPU 转移,要花一些 CPU 来做解压缩、重新压缩、偏移量的计算,以及由于加了数据的备份,CPU 占用率在当时已经不再是 10% 了。
0.9 版本,配额和安全性
2014 年,我们成立了 Confluent,是当时 LinkedIn Kafka 的几个技术核心人员离开公司成立的基于 Kafka 的流数据平台公司。同年,发布了 0.8.2 和 0.9.0,在 0.9.0 这个版本里面,加入了两个非常重要的特性,配额和安全性。
当 Kafka 集群不断变大、使用场景不断增多的时候,多租户之间的影响就会非常显著,一个人可以影响其他所有用户。当时,有一个员工写的客户端,当获取元数据失败时会一直发请求,并部署到了几十台机器上,结果就影响了所有的其他用户。所以我们在 0.9 里第一个要加的重大机制就是配额,限定每一个 user 能够用多大的流量跟 Kafka 交互。如果你超过配额,Kafka broker 就故意延迟你的请求,使一个 User 不会影响别人。这就是 0.9 的配额机制。
另一个很重要的机制是安全性,我们现在都知道安全性很大的三个方面就是授权、认证、加密。授权、认证说的直白一点,就是谁能干什么,这个谁就是认证,能干什么就是授权。那么认证在 Kafka 0.9 版本里面,我们用的是 SSL 认证。认证是一个一次性的过程,也就是说当一个新的客户端,第一次和服务器端建立连接的时候,会通过 SSL 进行一次认证。但是授权,读、写、修改或者管理操作的时候,每一次都需要做我们所谓的授权检查。
当然了,这些授权和认证其实对我们的性能是有一定影响的。正如刚刚我提到的 Kafka 本身的高性能来自于几点,一是用日志作为文件存储系统;二是利用文件系统作为缓存;三是我们当时采用了 Java 7 中新加入的零拷贝机制,原来将数据从磁盘写入网卡需要经过四次拷贝,有了零拷贝机制能够省去其中从用户端到内核端的数据拷贝过程。但我们加了安全机制,除了认证和授权以外,还做了数据加密,即使别人恶意窃听了你的网卡,也不能得到真正的数据。由于这些中间处理,就不能使用零拷贝机制直接把网卡数据写入磁盘了,最后只能放弃了 Java 7 里新加的零拷贝机制。
好在在 Java 11 对 TLS 做了重大的性能改革。我们自己做的基准测试显示,在 0.9 版本如果加入了加密和 SSL,Kafka 的性能可能会有 20% 甚至 23% 左右的影响。后来我们到了 Kafka 0.10、0.11 以后,用了 Java 11,性能只会受到最多 9% 的影响。
在 0.9 版本里面加了授权和认证以后,就发现了一个非常新的使用场景,就是用 Kafka 来作为数据库、多数据中心数据复制的骨干,当拷贝元数据从一个数据中心到另外一个数据中心的时候,很多人开始使用 Kafka 来拷贝数据捕获。因为我们加入了配额和安全性,很多用户开始敢于把数据敏感、安全性敏感、延迟性敏感的使用场景放到 Kafka 集群上。
另外一个非常重要的新特性,就是基于消息 Key 的清理。在 0.8 版本以前,Kafka 仅以时间或者数据大小来清理,可以配置为数据存四天,过期一天的数据就自动清理掉。但数据其实是以 Key 作为标识的,所以数据清理的时候,应该是以 Key 作为核心,而不是通过时间。即使 7 天之内没有被更新过,也不代表它就应该被清理掉。
由于这些特性的加入,现在 CPU 上要做压缩、解压缩、加密、解密、备份间的协调等操作,所以对 CPU 的消耗逐渐加大了,但网络带宽一直不变。
0.10 版本,更细粒度的时间戳
0.10 版本里,我们又加入了一个非常重要的特性,就是时间戳,除了语义上的增强,也是对于 CPU 损耗的优化。在 0.9 版本或者更老的版本里面,对于时间的概念是非常粗粒度的,每一个分片是一个文件,所有 record 仅以这个文件的时间作为基准,也就是说 record 在语义上的时间被认为是一样的。那么当需要依据时间进行回溯时,无法得到非常确切的偏移量。在 0.10 版本里面,对每一个 record 会打一个具体的时间戳,发布端生成一个新的 record 时可以打一个时间戳,这样可以有细粒度的时间管理,并且可以基于偏移量进行快速的数据查找,找到所要的时间戳。
这样首先可以做到更细粒度的 log rolling/log retention;第二,很多基于时间上的操作的准确性大大提升。每个时间戳可以有两种语义,第一种是发布的时候在客户端可以盖一个时间戳;第二种客户端不盖,交由 broker,当它收到 record,append 到日志上时盖一个时间戳。区别在于,append time 一定是顺序的,而 create time 会是乱序的,因为会有很多 producer 同时盖时间戳,发布到 partition 上。这是时间戳语义上的增强。
在性能上也有一个好处,在盖时间戳的同时,把偏移量位移从绝对位移改成相对位移,当一个压缩包里面有位移的时候,只需要记录相对位移,把相对位移加上绝对的基础位移,就可以计算出绝对位移。它的好处是 0.10 版本的 producer 进来的时候,不需要做解压缩,但如果你是 0.9 和更老的版本请求进来的时候,还需要做一步解压缩和 up conversion。测试表明,这一改进使 CPU 的占有率大大降低。
Kafka Streams 是在 0.10 里面加入的,它是一个流处理的平台,或者叫它是流处理的一个库。它是基于发布端和消费端的处理平台,它能够做到的是 Event-at-a-time、Stateful,并且支持像 Windowing 这样的操作,支持 Highly scalable、distributed、fault tolerant。所有这些都很大程度上利用了 Kafka broker,也就是服务器端本身的延展性和高可用性。因为 Kafka Streams 是一个库,也就是说,你不只是在很大的集群上,甚至在笔记本电脑上、黑莓上都可以安装它来进行流处理的计算。而且你所要做的很简单,只要把它作为你应用的 dependency 进行编程就可以了。用 Kafka Streams 编好流处理应用的时候,可以用各种方法来部署和监控。你可以只把它作为一个很普通的 Java 应用,或者用 Docker 也可以,任何地点、任何时候、任何方式均可。这就是我们的设计初衷,如果你的集群管理已经有自己的一套成熟工具,不需要再为了用 Kafka Streams 而进行一些调整。
简单来说,Kafka Streams 所做的就是从 Kafka 的 Topic 里实时地抓取数据。这个数据会通过用户所写拓扑结构,把所有的 record 实时进行 transform 之后,最终再写回到 Kafka 里面,是个很简单的流数据处理。那么它怎么做延展性呢?也很简单,当用户写好一个拓扑结构以后,可以在多个机器,或者多个容器、多个虚拟机、甚至是多个 CPU 上面,部署多个应用,当应用同时进行的时候,会利用 Kafka 自动地划分每一个不同的应用所抓取的不同 partition 的数据。
Kafka Streams 是基于 Kafka 流处理的一个库。如果流处理操作平台不在 Kafka 上,怎么把数据先写到 Kafka,再用 Kafka Streams 呢?可以利用 Kafka Connect,它是一个 Kafka 的 ingress、egress 框架。元数据可以是一个数据库,也可以是 Web Server,可以是各种各样不同的数据节点,它可以通过 Kafka Connect 实时把数据导入到 Kafka 数据流里面,也可以通过 Kafka Connect 把 Kafka 的流数据实时导出到最终的终端上。Kafka Connect 本身是一个框架,我们欢迎所有人参与贡献。到目前为止,我们已经有了 45 个以上基于不同系统的 Kafka Connect 可以自动被下载和使用,其中开源社区、合作伙伴做了很多的贡献。未来,我也希望能够看到更多来自于国内的同学参与到 Kafka Connect 框架的贡献中。
1.0 & 1.1 版本,Exactly-Once 与运维性提升
大家共同的指标,是我们要做到 Exactly-Once 才发布 1.0 版本,这才能使 Kafka 作为一个成熟的流数据平台持续发展。
什么是 Exactly-Once?非 Exactly-Once 是指由于网络延迟或其他各种原因,导致消息重复发送甚至重复处理。那么直白来说 Exactly-Once 的定义,就是从应用的角度来说,当发生了错误,希望做到每一个接收到的 record,处理结果会被反映到它的处理状态中,一次且仅有一次,也就是 Exactly-Once。
那么在 0.11 以及之前的版本里面,Kafka 的用户普遍是如何保证 Exactly-Once 的呢?很简单,就是基于 Kafka 的 At-Least-Once 加上去重,把处理过的 record 记录下来,发现重复处理时就把它扔掉。这样做的复杂性在于,对于一个机构或者一个公司,实时操作系统不只是一个应用,可以是多个应用,每一个 output record 可能就是下一个应用的 input record,那么做去重的时候,需要在每一个阶段都做去重,这样一是成本高,二是运维难度大。
所以在 0.11 里面,我们给两个基础的 Building blocks 来做 Exactly-Once。第一点是幂等性,意味着对于同一个 partition data 的多次发布,Kafka broker 端就可以做到自动去重;第二点是 Transactions,当在一个事务下发布多条信息到多个 topic partition 时,我们可以使它以原子性的方式被完成。基于这一点,我们在 Kafka Connect 和 Kafka Streams 上面就加入了简单的 Exactly-Once 机制,也就是一个配置。以 Kafka Streams 为例,只要配置一个 config,就可以使 processing 从 At-Least-Once 变成 Exactly-Once。
在 0.11 以后,我们更加关注运维能力,因为大家反馈了很多这方面的问题。比如 Controller shut down,想要关闭一个 broker 的时候,需要一个很长很复杂的过程,需要通知所有 broker,完成所有相关操作,并完成相关记录,才能完成整个 shut down 的过程。在这个过程中,需要发送很多次请求,对元数据进行多次修改,这对于延迟性有很多的要求,使这个过程变得很缓慢,是当时普遍存在的一个问题。所以在 1.0 和 1.1 版本,我们进行了一次重写,进行了大面积的优化。在 1.0 版本,在五个 broker node 的集群下,要进行一次 Controller shutdown,10k partition per brocker 的规模,需要 6 分钟的时间,而在 1.1 版本里只需要 3 秒钟,而 Controller failover 的延迟也从 28 秒降到了 14 秒。除了 Controller,我们在 1.1 里对运维性、进化性也做了很多工作。
未来愿景

- Global Kafka:就是 Kafka 对于多数据中心的原生支持,我们想做到一个 Kafka 集群可以部署在多个数据中心。这需要 Kafka 能够做到更好的延展性、更便捷的可运维性等。
- Infinite Kafka:目前 Kafka 的用户都是配置存储 4 到 7 天或者最多一个月的数据,但越来越多的用户想在 Kafka 存储过去更久的流数据,但是同时不会因为长时效的数据流而导致数据拷贝或者迁移的时候造成大量延迟。这同时也意味着 Kafka 需要有更好的云架构兼容性。
经验教训
构建可进化的系统
Kafka 作为一个流处理平台,是一个不断进化的平台,也就是说,你不能把 Kafka Shut down 来进行更新,只能一边用一边更新。
我们在 0.8 版本里面改了数据格式,但是并没有一个非常好的升级补丁。当时很多人的做法是通过数据复制器把 0.7 版本的数据同步复制到 0.8 版本的集群里,也就说在很长一段时间内,需要同时运维 0.7 版本和 0.8 版本的 Kafka 集群,只有当 0.7 版本的所有客户端全部转移到 0.8 版本以后,才能关闭 0.7 版本的客户端。这是一个非常痛苦和漫长的过程。所以我们现在认为,当你需要构建一个可以长时间使用并且永远不下线的系统时,在线可进化性是最重要的特性。
要做到一个能够实现百分之百在线可进化的系统,首先要提供一个简单的升级过程,其次能让所有的用户自主地、只通过阅读文档或者协议更新文件,就能做到在线升级。
只有能被度量的问题才能得到最终解决
如果想要知道,每一个发布的 record,是否最终通过了所有的 Kafka 集群,通过了所有的 Tier,最终到了消费端,并且到每个 Tier 的时候耗费了多少时间,只有对 Kafka 进行全方位的观测和监测,才能知道哪里出现了问题,需要在哪里进行优化,需要在哪里进行改进。
API 保持不变
新版本发布后,所有 API 就再也不能变了。举个例子,Kafka1481 是社区贡献的一个特性,我们所有的度量是用下划线作为分隔符,由于在很多系统中下滑线是不被允许的字符,我们就把下划线改成了单杠,在当时我们没有想太多,就把合并到主干里了。结果,所有的度量板都变成白屏了。因为度量名中的分隔符从下划线变成单杠,所有的度量项全都抓不到了。
所以我们每次设计 API 的时候,都要想清楚,到底这些 API 应该怎么设计,每次做一个更新的时候,我们都要想,这个更新有没有可能对用户造成一些没有想到的影响。
服务需要把关
一个坏用户可以影响所有人。Kafka 进化到 1.0 版本以后,更多的人开始在云上使用 Kafka,对安全性、多租户的特性提出了更高的要求,包括端到端的加密、ACL/RBAC。除了安全性以外,在配额方面也有更多新的要求,不仅要有流量的限制,还有 CPU 的限制。
生态系统是关键
生态系统对一个开源社区来说是非常重要的。举个例子,当时我们在 0.8.2 版本里面把所有的贡献直接放到了 Kafka 里面,但是之后发现,与其把所有的代码、组件都放到一个 repo 里面,不如构建一个原生态的生态系统,比方说容器的支持、语言的支持,大家可以在官网上找到跟这些相关的所有生态系统的链接。
构建一个开源产品或者开源项目的时候,要做的并不是把所有的组件或者所有的贡献都放在同一个项目里面,而应该构建一个繁荣的开源生态系统,所有人都可以基于核心组件做不同组件的开发。不同组件的开发维护周期也不一样,不需要跟 Kafka 核心组件同步更新或者同步维护。
结语
我们讲了这么多,到底什么是 Kafka?
最早的时候,我们说 Kafka 是一个可扩展的订阅发布的消息系统;2013 年的时候,我们说 Kafka 是一个实时数据通道;2015 年的时候,我们说 Kafka 是一个分布式的备份 Log,同年,我们提出了 Kafka Architecture,是针对 Lamda Architecture 提出的一个新的框架,我们认为 Kafka 是一个统一数据集成堆栈。
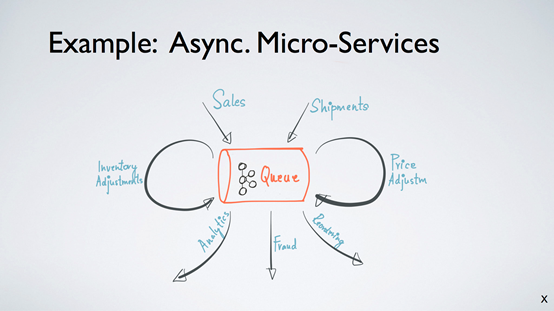
以微服务为例,什么是微服务?我们在构建一个架构的时候,每一个小组、每一个模块只需要负责自己的生态和逻辑,而它跟所有其他小组或模块的交互,都可以通过一个异步的流处理平台来传输。形象一点说,可以把每一个应用看作流水线上的一个工人,它从流水线的上端取得一个任务,处理之后把结果发布到流水线的下端,而它的下端可能是下一个应用的流水线的上端,每一个应用之间只需要通过这样一个异步的流水线来协作,每个应用升级、运维、开发都是不需要进行对偶或者重构的,可以做到完全异步,这就是 Async Micro-Services 的核心。Kafka 在这样一个架构下被很多应用作为异步的流式消息框的不二之选。
我们对于 Kafka 有这么多不同的理解,那么 Kafka 到底是什么?我的答案是,以上皆是。
最早的时候,我们说 Kafka 是一个订阅消息系统,但是从 0.7 版本一直升级到 1.0,或者说现在的 2.0 版本以后,Kafka 已经进化成为一个流处理平台。这个平台不光是流数据的发布,还能涵盖流处理的存储、处理、镜像、备份等等,所有的用户都可以在上面进行各种各样的实时流数据处理的应用的开发以及维护。这是我想要说的关键的一点。
最后再提一下 Kafka 现在在全世界的应用情况。今年上半年,我们做过一个统计,在福布斯 500 强公司里面,大概有 35% 的公司都在使用 Kafka。具体到不同的行业,全世界前 10 大旅行公司中有 6 个在使用 Kafka,全世界最大的 10 个银行有 7 个在用 Kafka,最大的 10 个保险公司有 8 个在用 Kafka,最大的 10 个通讯公司中有 9 个在用 Kafka。
可以看到,虽然 Kafka 在 2010 年发布 0.7 版本的时候还是一个由互联网公司提出来的流数据的数据通道,但是发展到今天,它已经横跨了非常多的领域,在非常多的平台上被用来做各种不同的事情,但其中有一个核心,就是这些事情都是针对实时流数据的处理。
作者介绍
王国璋,Apache Kafka PMC,Kafka Streams 作者。分别于复旦大学计算机系和美国康奈尔大学计算机系取得学士和博士学位,主要研究方向为数据库管理和分布式数据系统。现就职于 Confluent,任流数据处理系统架构师和技术负责人。此前曾就职于 LinkedIn 数据架构组任高级工程师,主要负责实时数据处理平台,包括 Apache Kafka 和 Apache Samza 系统的开发与维护。
另外,文末推荐 InfoQ 编辑策划的《Kafka 设计解析》系列文章。链接如下:
Kafka 设计解析(一):Kafka 背景及架构介绍
Kafka 设计解析(二):Kafka High Availability (上)
Kafka 设计解析(三):Kafka High Availability (下)
Kafka 设计解析(四):Kafka Consumer 解析
Kafka 设计解析(五):Kafka Benchmark
Kafka 设计解析(六):Kafka 高性能关键技术解析
Kafka 设计解析(七):流式计算的新贵 Kafka Stream
Kafka 设计解析(八):Kafka 事务机制与 Exactly Once 语义实现原理




