
JDK 21 的发布将备受瞩目的新特性,Java 虚拟线程引入了普遍可用状态。此特性标志着 Java 开发人员在更好地处理应用程序中的并行性方面取得了重大进步。Java 虚拟线程特性的一些目标包括:
轻量级、可扩展且用户友好的并发模型
高效利用系统资源
“大幅减少编写、维护和观察高吞吐量并发应用程序的工作量”(JEP425)
虚拟线程引起了 Java 开发社区的极大兴趣,一些应用程序框架社区,例如 Open Liberty(一个开源、模块化、云原生的 Java 应用程序运行时)也对此非常关注。作为 Liberty 性能工程团队的成员,我们评估了这项新的 Java 特性是否可以为我们的用户带来好处,甚至可能取代 Liberty 应用程序运行时自己现在使用的线程池逻辑。至少,我们希望更好地了解虚拟线程技术及其性能,以便我们能够为 Liberty 用户提供明智的指导。
本文报告了我们的一系列研究成果,包括:
Java 虚拟线程实现概述。
当前的 Liberty 线程池技术概述。
一些性能指标的评估,包括一些意外的观察结果。
我们的研究摘要。
Java 虚拟线程
虚拟线程最初在 JDK 19 中引入,在 JDK 20 中得到增强,并在 JDK 21 中最终确定(如 JDK 增强提案 (JEP) 444 中所述)。
过去,Java 开发人员使用“每个请求一个线程”的模型来实现应用程序,其中每个请求在其生命周期内由专用线程处理。这些线程(称为平台线程)被实现为操作系统线程(OS 线程)的包装器。但是,OS 线程会使用大量系统内存并由 OS 层调度,随着越来越多的线程被部署,这可能会导致扩展问题。
虚拟线程的主要动机之一是保持每个请求一个线程模型的简单性,同时避免专用 OS 线程的高成本。虚拟线程在一开始会将每个线程创建为 Java 堆上的一个轻量级对象,并仅在需要时才会使用 OS 线程,这样就能尽可能减少上述问题。这种 OS 线程的“共享”机制可以更好地利用系统资源。理论上讲,这对虚拟线程来说是一个优势:开发人员现在可以在单个 JVM 中高效地使用“数百万个线程”。
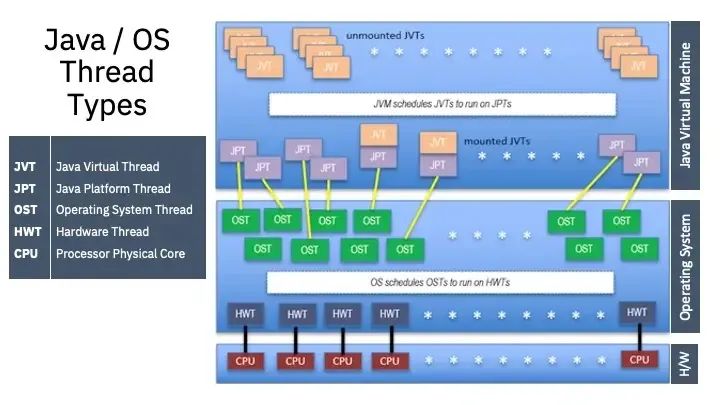
下图显示了 Java 虚拟线程和 OS 线程之间的多对一关系,然后这些 OS 线程被安排在 CPU 级别运行。
Open Liberty 的自主线程池
Open Liberty 的共享线程池方法也尽可能降低了专用操作系统线程的高成本。Liberty 使用共享线程(称为“Liberty 线程池”)来执行应用程序业务逻辑函数,并为 I/O 函数分配单独的线程。此外,Liberty 线程池具有自适应性,且可自主调整大小(如这篇 文章 所述)。对于大多数用例,用户无需进行额外调整,但可以配置最小和最大池的大小。
与 Web 服务器(例如使用虚拟线程实现的 Helidon Web 服务器)不同,像 Liberty 这样的应用程序运行时不仅仅是建立一个 I/O 连接,然后就长时间处于空闲状态。在 Liberty 上运行的应用程序通常会执行大量业务逻辑,这需要 CPU 资源。Liberty 部署通常不会使用数千或数百万个线程,因为 CPU 资源被几百个线程(或更少)就完全消耗殆尽了,尤其是在仅分配了几个甚至不到一个 CPU 的容器或 pod 中更容易耗尽。
性能测试
我们的评估主要集中在 Liberty 客户常用的用例和配置上。我们使用现有的基准测试应用程序来对比 Liberty 的线程池和虚拟线程的相对性能。这些基准测试应用程序使用了 REST 和 MicroProfile,并在事务期间执行一些基本的业务逻辑。
我们的目标是模拟再现“如果我们用虚拟线程替换 Liberty 中的自主线程池,大多数 Liberty 用户将看到的内容”。因此,我们的评估主要集中在有 10 到 100 个线程的配置上。但我们还扩展了评估范围,对比了 Liberty 的线程池和具有几千个线程的虚拟线程的行为,因为可以使用许多线程来运行是虚拟线程宣传的优势。
为了评估一个执行虚拟线程卸载和挂载操作的用例,我们使用了一个模拟网银应用程序,该应用程序向一个远程系统生成请求,后者在可配置的延迟后做出响应。响应被延迟意味着被测系统中的线程在 I/O 上被阻止,并且在一段时间内未被 CPU 使用。此应用程序生成的工作类型允许在事务中途卸载虚拟线程,然后在远程系统回复后重新挂载(即允许共享操作系统线程)。
测试用例环境
我们使用 Eclipse Temurin(带有 HotSpot JVM 的 OpenJDK)和 IBM Semeru Runtimes(带有 OpenJ9 JVM 的 OpenJDK)运行了这些性能测试。我们观察到 Liberty 的线程池和虚拟线程在这两个 JDK 上的性能差异相似。除非另有说明,否则下面显示的结果是在运行 Liberty 23.0.0.10 GA 和 Temurin 21.0.1_12 版本时生成的。
免责声明:我们对虚拟线程的评估重点在于,如果使用上述“每个请求一个线程”模型实现的虚拟线程来替换自主线程池,Liberty 用户是否会获得性能优势。在阅读测试用例时要牢记这一点,因为对于那些没有像 Liberty 那样的自调整线程池的应用程序运行时,结果可能会完全不同。
测试案例 1:CPU 吞吐量
目标:评估 CPU 吞吐量,以发现使用虚拟线程与 Liberty 线程池相比是否存在性能损失。
结果:对于某些配置,使用虚拟线程时负载的吞吐量比使用 Liberty 线程池时低 10-40%。
对于此测试,我们运行了几个 CPU 密集型应用程序,并对比了在给定数量的 CPU 上分别使用虚拟线程与 Liberty 线程池运行,各自可以完成多少事务每秒(TPS)。我们使用 Apache JMeter 来驱动各种负载,以使小型系统达到越来越高的 CPU 利用率水平。
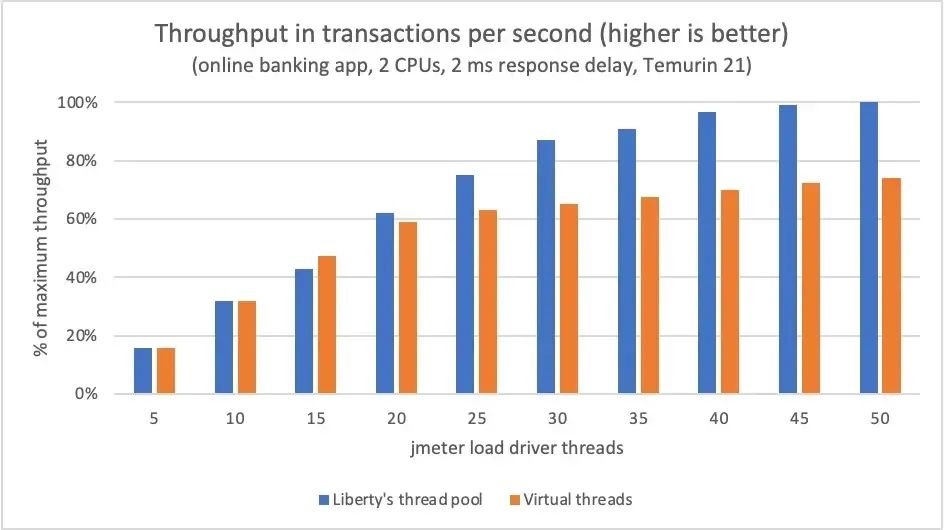
在一个示例中,我们以短暂的 2 毫秒延迟运行网银应用程序,以便对每个单独的任务执行虚拟线程功能(在 OS 线程上挂载 / 卸载 / 重新挂载),同时应用程序整体仍然占用大量 CPU 资源。负载逐渐增加,在每个负载级别运行足够长的时间(150 秒)以获得稳定的平均吞吐量测量值。
在低负载水平下,网银应用程序的虚拟线程吞吐量大致等于 Liberty 的线程池吞吐量(见图),虚拟线程使用的 CPU 稍多(未显示 CPU 利用率)。随着负载的增加,使用虚拟线程的每秒事务量逐渐落后于 Liberty 的线程池。
我们预计虚拟线程在这种 CPU 密集型应用程序中可能会稍微慢一些,因为虚拟线程不会让代码比在传统 Java 平台线程上跑得更快,而且虚拟线程有一些开销,包括:
挂载和卸载:虚拟线程挂载在一个平台线程上,以在阻塞点和执行完成时运行和卸载。此外,每次挂载或卸载操作都会发出 JVM 工具接口(JVMTI)通知。这些操作很轻量,但并非零成本。
垃圾收集:每次交易都会创建和丢弃一个虚拟线程对象,并产生分配和垃圾收集成本。
线程链接上下文丢失:Liberty 使用 ThreadLocal 变量在请求之间共享公共信息。换成虚拟线程后这种方法带来的效率提升就没了,因为 ThreadLocal 会随虚拟线程一起消失。作为该项目的一部分,我们将主要的 ThreadLocal 用例转换为其他非线程链接共享机制,但仍存在一些影响较小的实例。
但是,CPU 分析表明,这些可能存在的虚拟线程开销都不足以解释观察到的吞吐量差异。我们将在后面的“虚拟线程性能方面的意外发现”部分讨论其他可能的原因。
对于在少量 CPU 上运行 CPU 密集型应用程序(Liberty 的典型用例)的情况,与在 Liberty 线程池中的常规 Java 平台线程上运行相同代码相比,虚拟线程并没有使 Java 代码的执行速度更快。
测试用例 2:加速时间
目标:量化虚拟线程与 Liberty 线程池相比达到完全吞吐量的速度。
结果:当突然施加一个重负载时,在虚拟线程上运行的应用程序达到最大吞吐量的速度明显快于在 Liberty 线程池上运行的应用程序。
虚拟线程使用的简单模型是每个任务都有自己的(虚拟)线程来运行,因此我们的 Liberty 虚拟线程原型启动了一个新的虚拟线程来执行从负载驱动程序收到的每个任务。也就是说,使用虚拟线程时每个任务都会立即有一个线程运行,而使用 Liberty 的线程池时,任务可能必须等待线程可用。
为了充分测试这种情况,我们需要运行一个具有足够长响应延迟的网银应用程序,以使数千个同时发生的事务让 CPU 饱和。此负载需要数千个线程来处理事务,不管是基于每个事务的虚拟线程还是 Liberty 线程池中的传统 Java 平台线程都要这么多。
处理 Liberty 线程池中的数千个线程
我们发现 Liberty 线程池在几千个线程的情况下运行良好。由于各种虚拟线程讨论中都提到了使用许多平台线程的问题,因此我们一直在寻找 Liberty 线程池中出现问题的迹象。例如,在处理几千个线程时,它可能变得不稳定,或者出现其他“线程过多”问题的迹象。不过我们没有看到此类问题。
相反,我们发现 Liberty 线程池的吞吐量实际上比虚拟线程略快(2-3%)。Liberty 线程池的 CPU 使用率降低了约 10%,而 Liberty 线程池的每 CPU 事务利用率提高了 12-15%(主要是由于自主控制的设计决定了 Liberty 的线程池大小)。Liberty 线程池的自主控制机制允许池在负载需要时增长到数千个线程,同时保持稳定运行。
使用 Liberty 线程池与虚拟线程的加速时间对比
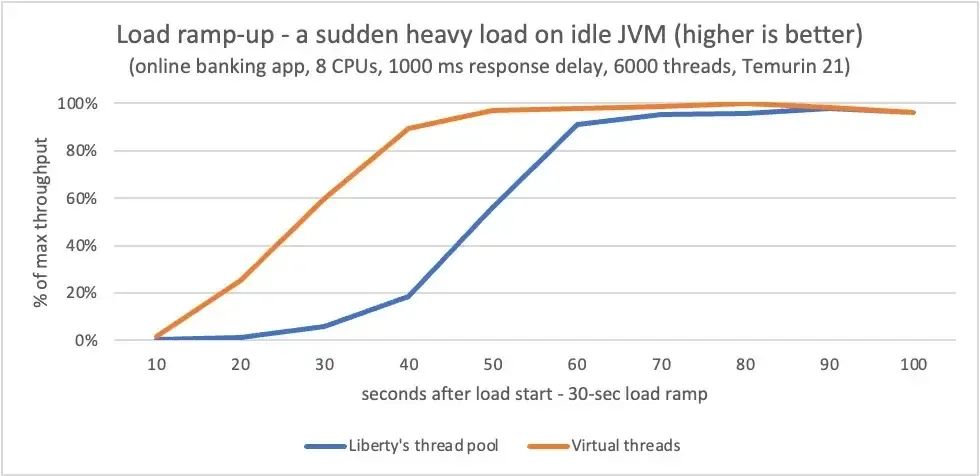
在扩展评估中,虚拟线程从低负载到满负荷的加速时间非常快。Liberty 线程池的加速速度较慢,因为它会根据观察到的吞吐量逐渐调整;Liberty 线程池以 1500 毫秒的间隔决定是增大、缩小还是保持相同的池大小,所以需要数十分钟才能逐渐决定它应添加更多线程来处理所提供的负载。
作为此次测试的结果,我们修改了 Liberty 线程池的自主性,以便在有更多空闲 CPU 资源可用,且 Liberty 线程池请求队列较深时更积极地扩大线程池。使用这个修复程序(Open Liberty 23.0.0.10 及更高版本中 提供)后,当在 Liberty 线程池上运行的网银应用程序突然受到重负载(超过 30 秒)时,这个应用程序现在达到峰值吞吐量的速度只比虚拟线程上运行的情况慢了 20-30 秒(而不是几十分钟),即使负载需要空闲 JVM 上约 6000 个线程(见图)时也会这么快。虚拟线程原型的启动速度依旧更快,因为它在每个请求到达时都会提供一个新的虚拟线程,但虚拟线程和 Liberty 线程池之间的加速差异已大大缩小。
测试案例 3:内存占用
目标:评测 Java 进程在恒定负载下使用了多少内存,对比虚拟线程和 Liberty 线程池的结果。
结果:虚拟线程的每线程占用空间较小,但这一优势在需要几百个线程的配置中只产生了相对较小的直接影响,并且可能会被 JVM 中其他内存占用的影响所抵消。
虚拟线程比传统平台线程使用了更少的内存(Java 进程大小),因为它们不需要专用的后备 OS 线程。这个测试案例测量了虚拟线程的这种每线程内存优势如何影响典型 Liberty 负载级别下的 JVM 总内存使用量。我们发现了一组相当复杂的结果。
我们预期使用虚拟线程运行的负载使用的内存始终少于使用 Liberty 线程池运行相同负载时使用的内存。但我们却发现,有时虚拟线程配置使用的内存较少,但有时使用的内存较多。
出现这种变化是因为线程实现以外的其他因素也会影响 Java 进程的内存使用量。在我们的测试中,对内存使用变化产生重大影响的一个元素是 DirectByteBuffers(DBB),它是 Java 网络基础架构的一部分。(有关 Direct ByteBuffers 的背景信息,请参阅 ByteBuffer API。)
DirectByteBuffers 是一个由两部分组成的结构,堆上有一个小型 Java 引用对象,本机或堆外区域中有一个大小可变(通常大得多)的内存区域。Java 引用对象在不再被需要后会被释放并被垃圾收集,之后其关联的本机内存被清除。如果 DirectByteBuffers 引用对象存活的时间足够长,足以提升到老年代区域(在典型的 Java 代际 GC 模型中),则本机内存分配将保留到全局 GC 为止。由于全局 GC(按设计)不会频繁发生,因此这种分配和保留模式可能会导致 Java 进程占用空间比活动运行时使用量大得多。
注意:此测试是在最小堆大小较小和最大堆大小相对较大的情况下运行的。这是为了使堆内存使用的变化成为明显影响 JVM 总内存使用量的因素之一。
在某些情况下,使用虚拟线程运行的负载比使用 Liberty 线程池的相同负载占用更多内存,我们发现这种差异归因于 DirectByteBuffers 保留机制。这并不表示虚拟线程存在问题:DirectByteBuffers 内存保留多长时间取决于几个因素的相互作用,包括事务持续时间、Java 堆 nursery 大小和保有权提升时间。我们可以使用略有不同的配置或微调来运行相同的测试,让虚拟线程使用的内存少于 Liberty 的线程池,这种差异也来自 DirectByteBuffers 保留机制。
例如,负载略微增加 10% 会导致在 Liberty 线程池上运行的网银应用程序使用的内存减少 25%,同时让在虚拟线程上运行的同一应用程序使用的内存增加 185%(见图)。
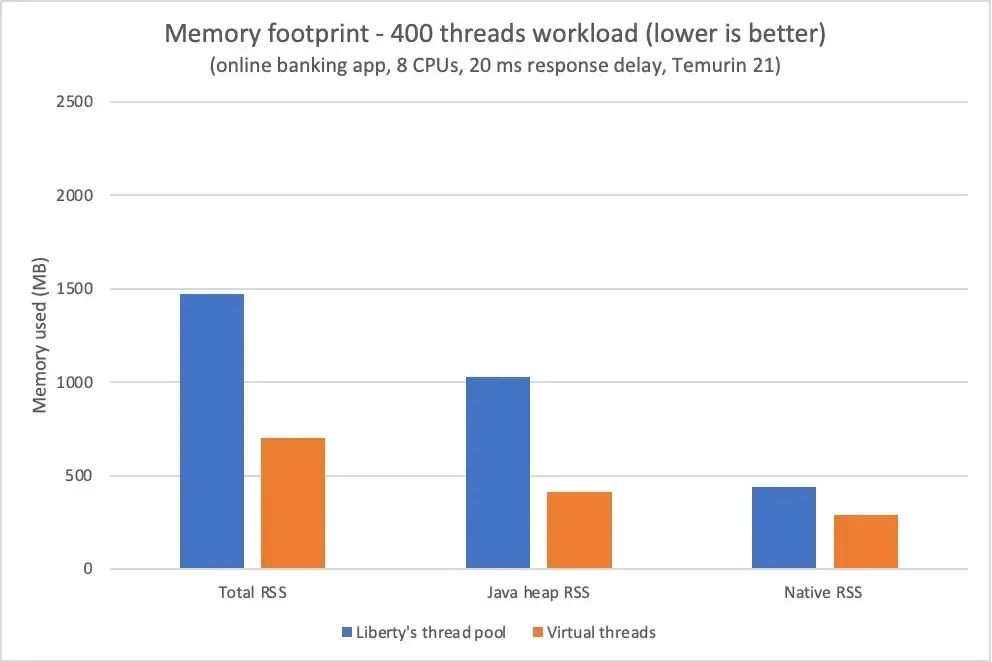
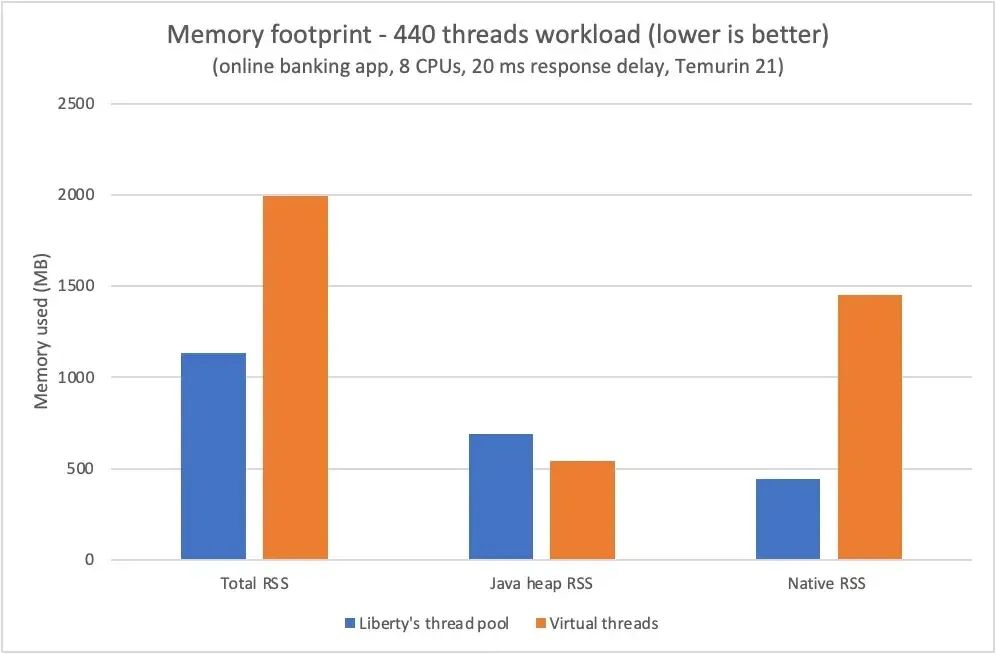
尽量不让每个虚拟线程都使用操作系统线程可以显著减少本机内存,但与应用程序运行时使用的其他内存相比,这部分内存可能相对较小。在只需要几百个线程的配置中,使用虚拟线程减少的本机内存可能会被其他难以预测的影响所抵消,例如 Java 堆的增长速度和释放相关本机内存的垃圾收集的及时性,DirectByteBuffers 就是一种情况。
在性能改进领域中,口头禅 YMMV(“您的结果可能会有所不同”)是众所周知的规律。一些虚拟线程的用户会看到系统的总内存使用量减少,而另一些用户会看到使用量增加。这些内存使用量的变化中,只有相对较小的一部分可归因于虚拟线程。
虚拟线程性能方面的意外发现
我们在调查虚拟线程的过程中使用我们的基准测试应用程序进行了许多实验,改变了 CPU 数量、负载量、远程延迟(对于网银应用程序)、堆大小等参数。这些实验产生了一些非常意外的结果,这些结果与前面的部分不太吻合。
具体来说,在两个 CPU 上运行短时间任务时,我们有时会发现虚拟线程的性能非常差。我们将其原因定位到了 Linux 内核调度程序与 Java 的 ForkJoinPool 线程管理交互的机制上。较新版本的 Linux 内核调度程序改变了与 ForkJoinPool 的交互方式,但我们依旧看到了虚拟线程的性能表现不佳的状况,只是方式不同。虚拟线程用户可能会遇到类似的问题,这一点值得注意,升级到较新的 Linux 内核只会改变行为而不是修复它。
在此测试中,我们使用了我们的 MicroProfile 基准测试应用程序 mp-ping,它对一个 REST 服务执行一个简单的“ping”操作。负载驱动程序在 Liberty 上运行的 mp-ping 应用程序上点击 REST URL,并立即收到“ping”响应(0.05-0.10 毫秒)。
在虚拟线程上运行时吞吐量低且 CPU 利用率低
我们发现,在虚拟线程上的 2-CPU 配置上运行短时间任务(mp-ping)产生的吞吐量比在 Liberty 的线程池上运行时低得多,并且 CPU 利用率也相应较低。虚拟线程上的吞吐量低至 Liberty 线程池吞吐量的 50-55%,如下图所示。
持续时间较长的任务(最长 1 毫秒)也存在性能不佳的情况,使用更多 CPU 时,情况会好一些,只是不那么严重。
我们在几个 Linux 内核级别不一样的不同硬件平台上都使用虚拟线程重现了吞吐量低和 CPU 利用率低的问题,以确保该行为不是初始测试系统上某些怪癖造成的。我们还创建了一个简单的独立应用程序,可以生成一些在可配置的时间段内耗尽 CPU 的任务,结果它在虚拟线程中表现出了类似的低吞吐量和低 CPU 利用率行为,因此性能不佳不是由 Liberty 造成的。
ForkJoinPool 和 Linux 内核调度程序
我们对虚拟线程性能不佳的根因进行调查后发现,Java 的 ForkJoinPool(它管理支撑虚拟线程的平台线程)在有大量工作可做时会将其中一个平台线程停放 10-13 毫秒。当一个平台线程停放时,虚拟线程无法及时运行,导致了我们观察到的低吞吐量和低 CPU 利用率。
进一步的调查表明 Linux 线程调度程序存在问题:程序追踪显示 ForkJoinPool 代码中进行了调用以取消停放的平台线程,但这并没有立即取消停放操作。我们得出结论,性能不佳是由 Linux 线程调度程序和 ForkJoinPool 工作线程管理之间的交互引起的。这种交互对 Liberty 的线程池来说不是问题,因为它不使用 ForkJoinPool 来管理平台线程。
我们尝试了可用的 ForkJoinPool 调优选项、Linux 调度程序调优选项以及对 ForkJoinPool 实现的各种修改,取得了一些小的性能改进,但并没有显著缩小与 Liberty 线程池性能的差距。
注意:我们的调查表明,对于我们在 4.18 Linux 内核中发现的虚拟线程问题,使用 2 个 CPU 运行可能是最糟糕的情况。在具有 1 个 CPU 或 4 个或更多 CPU 的测试系统上运行相同的负载时,性能问题仍然存在,但不那么突出。
运行虚拟线程时吞吐量低且 CPU 使用率高
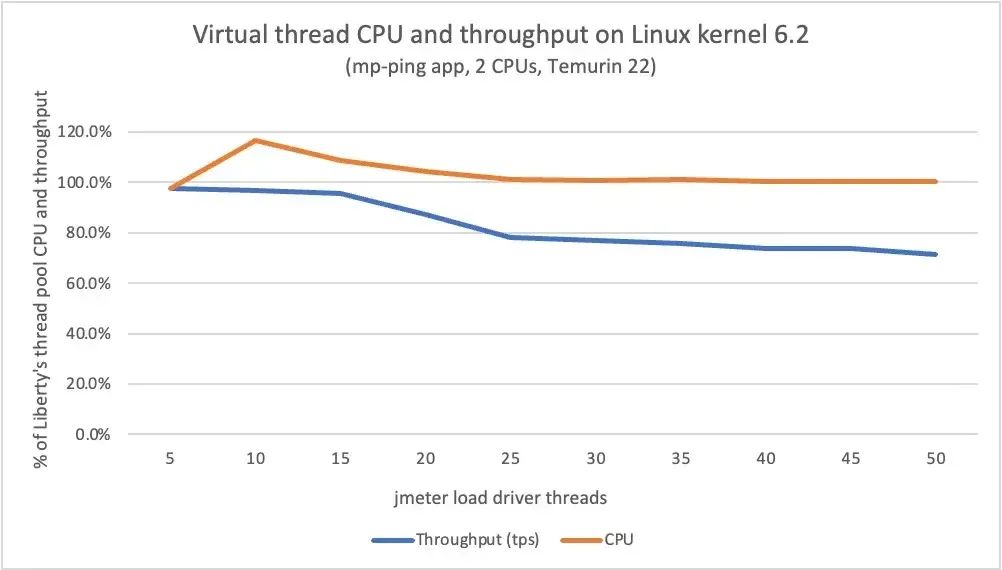
前两节中描述的测试主要针对 Linux 内核 4.18,这是 Red Hat Enterprise Linux(RHEL)8 中当前可用的内核。当我们在较新的 Linux 内核 5.14(RHEL 9)和内核 6.2(Ubuntu 22.04)上运行相同的测试时,我们发现虚拟线程的性能问题又不一样了。
使用较新的 Linux 内核时,在虚拟线程上运行 mp-ping 应用程序产生的吞吐量仍然比在 Liberty 的线程池上略低,但 CPU 利用率却更高了。随着负载的增加,虚拟线程的吞吐量比 Liberty 线程池的吞吐量低 20-30%,如下图所示。
这些结果表明,对于某些负载,虚拟线程可能存在不同的性能问题,具体取决于 Linux 内核级别。
对产生这些行为的原因的后续调查
我们与 OpenJDK 社区成员讨论了这些发现,并继续与他们一起调查和测试修改。两个图表中显示的运行结果都使用了 Temurin 22 的最新夜间版本,以利用 ForkJoinPool 的最新版本(目前正在修订中),看看 ForkJoinPool 修订版是否纠正了我们最初在 Temurin 21 中观察到的问题(但事实并非如此)。
需要进一步调查才能完全确定根本原因和解决方案,我们正在积极与 OpenJDK 社区合作。我们要感谢 Doug Lea(Java 并发工作的领导者和 ForkJoinPool 类的作者)和 OpenJDK 社区中的其他网友在我们调查这些虚拟线程性能问题时提供的帮助。我们在此报告这些问题,这样虚拟线程用户在遇到类似问题(具体取决于他们的用例)时就有心理准备了。
对于有兴趣重现“虚拟线程性能方面的意外发现”中所述问题的读者,我们在一个 GitHub 库 中提供了包含指引的 README。
总结和结论
我们使用一些代表 Liberty 典型客户用例的简单应用程序调查了虚拟线程的性能表现,在三个主要性能领域中:
吞吐量:在我们尝试的应用程序中,虚拟线程的性能比 Liberty 的线程池差。根据 CPU 数量、任务持续时间、Linux 内核级别和 Linux 调度程序的不同,我们在不同级别观察到了这种糟糕的性能。
加速:当负载突然到来,且任务持续时间较长,需要许多线程时,虚拟线程比 Liberty 的线程池更快地达到满吞吐量,但这种优势很快就会消失。
内存占用:在需要几百个线程的配置中,虚拟线程较小的每线程内存占用的优势相对较小,并且可能被 JVM 中其他内存占用的影响所抵消。
此外,我们惊讶地发现,在某些用例中,程序在虚拟线程上运行时存在性能问题。我们将这个问题追溯到了 Linux 内核调度程序与 Java 的 ForkJoinPool 线程管理之间的交互机制上。即使使用较新版本的内核,这个问题仍然存在,尽管方式有所不同。
在对比了 Liberty 现有的线程管理与新的 Java 虚拟线程特性后,我们发现现有的 Liberty 线程池在中等高(1000 个线程)并发级别下为 Liberty(以及在 Liberty 上运行的任何应用程序)提供了相当或通常更好的性能。虽然与 Liberty 的线程池相比,虚拟线程可以在更高的并发级别上体现出优势,但需要正确的条件、高任务延迟、大量 CPU 或这些因素的组合。
Java 应用程序开发人员仍可以在运行在 Liberty 上的应用程序中使用虚拟线程,但我们决定暂时不用虚拟线程替换 Liberty 线程池。如前文所述,在很多用例中,虚拟线程可能非常有用,可以简化多线程应用程序的开发工作。但如上所述,开发人员在某些类型的应用程序中也应该注意一些问题。通过在本文中分享我们的经验,我们希望 Java 开发人员能够更好地了解是否以及何时在自己的应用程序中实现虚拟线程。
作者介绍
Gary DeVal 是 IBM RTP 实验室的一名性能工程师,负责 Liberty 和 Java 性能领域。Gary 的重点研究领域包括 Liberty 线程池自主机制、Java 垃圾收集和 Liberty 启动性能,他是对 IBM 内部和外部 Liberty 用户提出的性能问题的主要负责人。在加入 IBM 之前,Gary 曾在电信行业从事软件开发、系统工程和产品规划等工作。
Vijay Sundaresan 是 IBM 多伦多实验室的性能架构师,负责 Java 运行时性能。过去二十年来,Vijay 的技术背景和专长涉及性能分析、编译和虚拟机技术、Java SE 和 Java EE 规范以及硬件优化。Vijay 是 Eclipse OpenJ9 JVM 以及 Eclipse OMR 开源项目的原始架构师之一。作为麦吉尔大学的研究生,Vijay 还为 Soot 字节码分析框架做出了贡献。
Rich Hagarty 是 IBM 的软件开发人员和开发者倡导者,目前专注于 Java 和开源相关技术。Rich 的办公地点位于德克萨斯州奥斯汀,过去 7 年来一直活跃于开发者倡导社区,致力于云计算和 AI 技术。他创建了许多学习路径、代码模式、文章和视频,所有这些都是为了帮助开发人员了解和使用 IBM 服务,例如 Watson Discovery 和 Assistant、IBM Cloud Paks 以及 Red Hat OpenShift 容器安全和部署。在加入 IBM 之前,Rich 曾在惠普工作,在那里他开发了硬件设备管理软件以及开源解决方案。Rich 的热情是与开发人员互动并分享新的和令人兴奋的技术。
Laura Cowen 是 IBM Java 产品的技术编辑和技术内容策略师,包括开源项目 Open Liberty。她曾担任过可用性研究员、技术作家、用户体验设计师和开发者倡导者。她拥有实验心理学学士学位、人机交互硕士学位,最近还获得了环境心理学博士学位。多年来,Laura 一直是广受欢迎的 Ubuntu Podcast 的常驻主持人,也是 OggCamp 的创始人和组织者,OggCamp 是一个英国社区非会议,主题是开源软件和开放文化。她在英国温彻斯特的 IBM Hursley 工作。
原文链接:
https://www.infoq.com/articles/java-virtual-threads-a-case-study/




