
HubSpot 采用在多个 Kafka 主题(称为泳道,swimlanes)上为同一生产者路由消息的方式,避免了消费者群组滞后的积压,并且能够优先处理实时流量。通过自动和手动相结合的方式探测流量峰值,该公司能够确保大多数消费者的工作流能够在无延迟的情况下执行。
HubSpot 提供了一个业务流程的自动化平台,其核心采用工作流引擎来推动操作(action)的执行。该平台可以处理数百万个活动的工作流,每天执行数亿个操作,每秒执行数万个操作。

工作流引擎概览(来源:HubSpot 工程博客)
大部分处理都是异步触发的,使用 Apache Kafka 进行传递,从而实现了操作的源 / 触发器与执行组件之间的解耦。该平台使用了许多 Kafka 主题,负责传递来自各种源的操作数据。使用消息代理的潜在问题在于,如果消息发布得太快,而消费者无法及时处理,等待处理的消息就会积压,这就是所谓的消费者滞后(consumer lag)。
HubSpot 的工程主管 Angus Gibbs 描述了确保近实时处理消息所面临的挑战:
如果在主题上突然出现大量消息,我们就必须处理积压的消息。我们可以扩展消费者实例的数量,但这会增加基础设施成本;我们可以添加自动扩展,但增加新的实例需要时间,而客户通常希望工作流能够以接近实时的方式进行处理。团队认识到,他们需要解决的问题是对所有相同类型或相同来源的消息使用了相同的主题。考虑到该平台被许多客户使用,如果某一个或一小部分客户开始产生大量消息,那么所有的流量均会延迟,所有客户的用户体验都会受到影响。
为了解决这个问题,开发人员选择使用多个主题,他们将其称为泳道(swimlanes),并为每个泳道配置专用的消费者池。应用这种模式的最简单方式是使用两个主题:一个负责实时的流量,一个负责溢出的(overflow)流量。这两个泳道以完全相同的方式处理流量,但是每个主题都有独立的消费者滞后,通过在两者之间适当地路由消息,可以确保实时泳道避免出现任何的(或明显的)延迟。
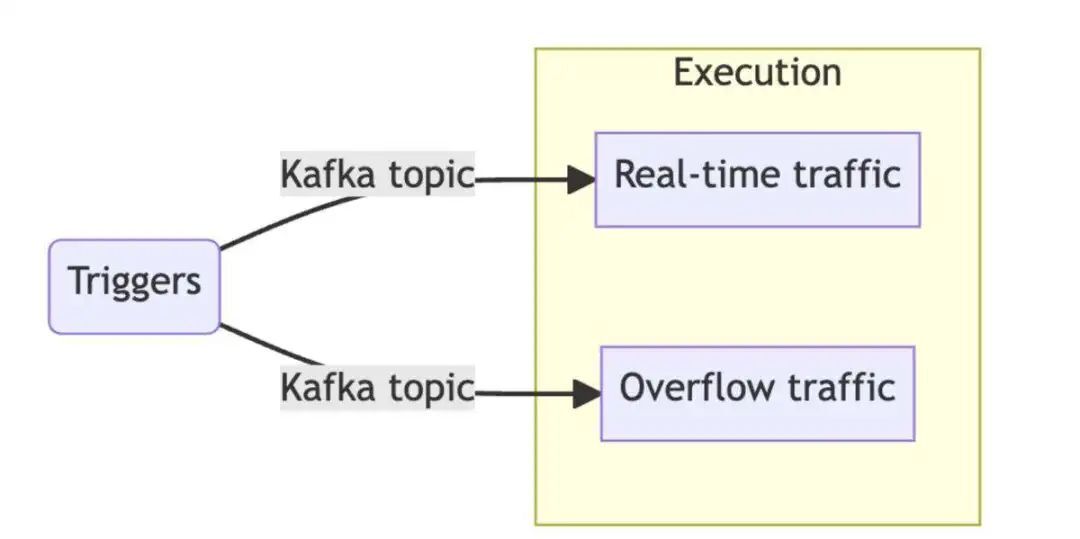
Kafka 泳道(来源:HubSpot 工程博客)
如果可能的话,系统会从发布的消息中提取元数据,基于此在泳道之间实现消息的自动路由。例如,批量导入所产生的消息可以在消息模式中明确标记出这种操作类型,这样路由逻辑就可以轻松地将这些操作发布到溢出泳道。此外,开发人员还引入了按客户配置来限制流量的功能,并且能够根据报文消费者的最大吞吐量指标设置适当的阈值。
决定如何在泳道之间路由消息的另一个角度是查看操作的执行时间。实际操作将被路由到一个泳道,而慢速操作将被路由到另一个泳道。这一点对 HubSpot 平台尤为重要,因为客户可以创建执行任意 Node 或 Python 代码的自定义操作。
最后,该团队还开发了将特定客户的所有流量手动路由到专用泳道的方法,以防来自客户的流量意外地在主(实时或快速)泳道上造成滞后,而此时自动路由机制均未启动。这样,在团队排查延迟原因时,就对流量进行隔离了。
原文链接:
https://www.infoq.com/news/2023/11/hubspot-apache-kafka-swimlanes/




