
Bert 模型网络结构较深,参数量庞大,将 Bert 模型部署成在线服务在实时性和吞吐上面临巨大挑战。本文主要介绍 360 搜索将 Bert 模型部署成在线服务的过程中碰到的一些困难以及做的工程方面的优化。
背景
在 360 搜索场景下对在线 Bert 服务的延迟和吞吐有极高的要求。经过前期的调研探索和试验,将 Bert 模型做成在线服务主要有以下 3 个挑战:
模型参数量巨大。12 层 Bert 模型有超过 1 亿参数量,相比于其他语义模型计算量高很多。
推理时间长。经验证,12 层 Bert 模型在 CPU 上延迟约为 200ms,在 GPU 上未经优化的推理延迟为 80ms,在搜索这个场景下如此性能是不可接受的。
推理计算量大,需要的资源多。经过压测验证,单个机房需要几百张 GPU 卡才能承接全部的线上流量,投入的成本远高于预期收益。
基于以上几个困难点,我们前期调研了 TF-Serving、OnnxRuntime、TorchJIT、TensorRT 等几个热门的推理框架,在比较了是否支持量化、是否需要预处理、是否支持变长、稳定性和性能以及社区活跃度等几个维度后,最终选用了 Nvidia 开源的 TensorRT。确定了框架选型之后,我们针对 Bert 在线服务做了几个不同层面的优化。
Bert 在线服务优化
框架层面提供的优化
TensorRT 推理框架本身提供的优化有:
层间融合和张量融合。本质是通过减少核函数调用次数来提高 GPU 利用率。
Kernel 自动调优。TensorRT 会在目标 GPU 卡上选择最优的层和并行优化算法,保证最优性能。
多流执行。通过共享权重的方式并行处理多条任务流,优化显存。
动态申请 Tensor 显存。当 Tensor 使用时再真正申请显存,显著提高显存利用率。
模型量化。在保证精度的情况下大幅提升模型的吞吐,同时降低推理延迟。
知识蒸馏
12 层 Bert 模型的线上延迟不能满足性能要求,我们将其蒸馏至 6 层的轻量级小模型。做完知识蒸馏后,在降低计算量的同时也保证了预测效果,6 层模型可以达到 12 层模型精度的 99%。经过试验验证,Bert 模型层数和在线服务的性能呈正相关的关系,6 层模型 TP99 指标相对于 12 层模型性能提升 1 倍。
FP16 量化
在 Bert 模型结构中,大部分 Tensor 都是 fp32 精度,但是在推理时不需要反向传播,此时可以降低精度,在保证模型效果的基础上大幅提高模型的吞吐。经过 FP16 量化之后,模型推理延迟变为原先 1/3 的同时,吞吐提升为原先的 3 倍,此时显存占用也为原先模型的 1/2。但是相比较原先模型,fp16 量化后的模型在万分位后有损失,在 360 搜索的场景下经过验证,量化后的模型对最终效果几乎无影响。权衡之下,量化后的收益远大于损失。
流水优化
开发完在线服务后压测过程中,观察到一种现象:无论压测请求压到多高,GPU 利用率会达到一个瓶颈,维持在 80%左右。此时继续增大压力,GPU 利用率依然没有升高,延迟反而不断增大。
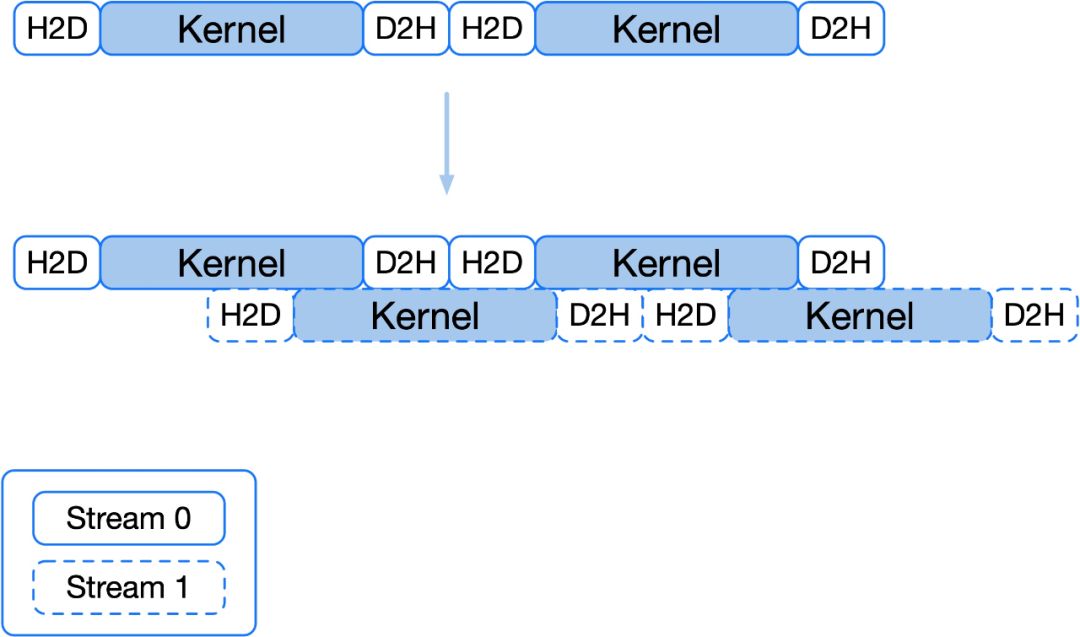
上图中 H2D 和 D2H 分别表示从内存往显存中拷贝数据和从显存往内存中拷贝数据,Kernel 表示正在执行核函数。线上请求推理时所做的三个动作为首先将请求数据由内存拷贝至显存,然后 GPU 发起核函数调用做推理计算,最后将计算结果由显存拷贝至内存。GPU 真正执行计算的部分是执行核函数的部分(上图中蓝色部分),数据拷贝时 GPU 是空闲的(上图中白色部分),此时无论压测压力多大 GPU 都会有空闲时间,因此利用率不会压满。
解决上述问题的一个方法是增加一条 Stream,使得两条 Stream 的核函数计算部分可以交替执行,增加 GPU 有效工作时间占比,GPU 利用率可以压到 98%以上。Stream 可以理解为任务队列,H2D 可以理解为一次任务,多增加一条 Stream 不会增加额外的显存占用,多条 Stream 是共享模型权重的。
运行架构
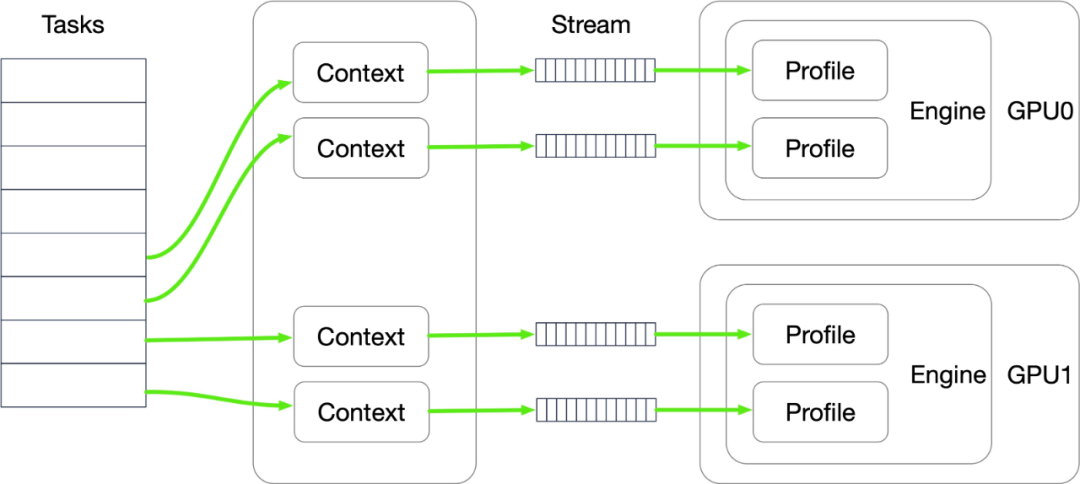
上图描述了一个占有 2 张 GPU 卡的单个 Bert 服务进程的运行架构。从左至右依次解释出现的名词,task 表示待处理的预测请求,context 用来存储这条请求的上下文信息,stream 表示任务流,profile 描述了模型输入的限制(比如限制输入的最大 batch size),engine 是 TensorRT 将原始模型编译优化后的模型。每张 GPU 卡上加载一个模型,每个模型会有 2 条 Stream 共享模型权重对外提供预测服务。
每当 Bert 服务收到来自客户端的预测请求,这个请求将会被放入任务队列。上图线程池中的 4 个工作线程每当空闲时会从任务队列中取出一条预测任务,保存好上下文信息后便将请求数据通过 Stream 拷贝到显存,GPU 调用核函数做完推理后再将结果通过 Stream 传回到内存,此时工作线程将结果存入指定位置后通知上层,一条完整的请求预测流程就完成了。
缓存优化
在搜索场景下,当天的搜索内容会有一部分热词出现,加上缓存可以有效减轻一部分计算量。在搜索系统加入请求级别的缓存之后,平均缓存命中率可达 35%,极大地缓解了 Bert 在线服务的压力。
动态 sequence length
最开始的在线服务是采用输入维度固定的方式,即输入 shape 的最后一个维度为离线统计出现过的最大 sequence 长度,经过线上小流量验证并且统计线上请求之后,发现线上请求长度超过 70 的 sequence 占比不到 10%。于是我们采取了动态 sequence 长度的优化方式,即采用一个请求 batch 中长度最长的 sequence 为输入长度,对其余的 sequence 做补零操作,经过这一优化线上性能提升 7%。
Bert 在线服务探索
做完上述优化后在测试以及小流量验证的过程中,我们也碰到了一些问题,分享给大家。
模型动态加载导致延迟升高
在搜索场景下,有一个多版本模型热加载的需求。开发完上线后观测到一个现象,在热加载新模型的时候,会出现 TP99 升高的现象,后来经过定位分析找到了原因。
在 Bert 在线服务做预测的时候,会有一个将模型输入数据从内存拷贝到显存的操作。而 Bert 服务动态加载模型的时候,也会有一个将模型权重数据从内存拷贝到显存的动作,拷贝模型到显存的时候占据了 PCI 总线,这时候预测请求数据从内存拷贝到显存就会受到影响,从而 TP99 就会升高。模型权重拷贝持续约几秒的时间,此时 TP95 正常,经统计仅有几条请求会有延迟升高,对业务基本无影响。
精度震荡
在前期开发过程中,我们观测到相同的 sequence 输入模型,在不同的 batch size 下返回的结果总是不尽相同,而是在某一固定的区间内震荡,例如返回的结果总是介于 0.93-0.95 之间且不固定。这个现象在 TensorRT 7.1.3.4 下稳定复现,后与 Nvidia 的同事沟通反馈,在 7.2.2.3 这个版本下已经修复。
显存占用
单个 Bert 模型仅占用几百 MB 的显存,但是上了多版本模型的功能后,Bert 在线服务有可能加载 5-8 个模型,如果处理不好有可能会出现 OOM 的问题。目前我们的处理手段是如果因显存不够而无法正常加载模型,仅仅会提示模型加载失败不会影响正常服务。加载一个新的模型的显存占用量是可以提前判断出来的,主要依据有 3 个:
模型本身的权重。模型本身的权重是需要占用显存的,占用显存的大小约等于模型在磁盘上的文件大小。
模型推理时需要的一些上下文信息。此部分显存占用分为两部分,一部分是保存上下文的持久化信息,包括输入输出数据占用的显存。另一部分是推理时占用的中间信息,中间信息显存占用一般不会超过模型权重大小。
CUDA 运行时也耗费一些显存,但这些显存占用是固定的。
总结与展望
经过前期框架调研验证,模型优化,工程架构优化以及部署探索过程后,最终 Bert 在线服务在 360 搜索场景下正式上线了。目前经过优化后的 6 层模型单张 T4 卡每秒可计算 1500 条 qt,线上高峰期 TP99 为 13ms。工程方面 Bert 在线服务稳定性和性能得到了保障的基础上,业务效果上相较于 baseline 也取得了可观的收益。
我们后续会持续探索推进 Bert 在 360 的应用落地,目前在搜索场景下工程方面还有一些亟需优化点:
目前 Bert 服务还是物理机部署,存在升级扩容困难、容灾差以及资源浪费的问题,我们正在推进 Bert K8S 化部署进程。
当前 Bert 的训练、蒸馏、数据和模型管理以及部署各个工作模块比较分散,我们在做的一个工作是把这些模块慢慢集成到公司内部的机器学习平台中,做到模型训练,数据管理,模型管理,服务部署升级,AB 实验的平台化和流程化,缩短上线周期,提高工作效率。
本文转载自:360 技术(ID:qihoo_tech)




