
基于机器学习(ML)的推荐系统早已不是什么新鲜概念,但开发这类系统仍是一项需要投入大量资源的任务。无论是训练与推理期间的数据管理,还是运营具备可扩展性的机器学习实时 API 端点,都着实令人头痛。Amazon Personalize 将 Amazon.com 过去二十多年来使用的同一套机器学习技术体系交付至您手中,轻松将复杂的个性化功能引入到您的应用程序,且无需任何机器学习专业知识。当前,来自零售、媒体与娱乐、游戏、旅游乃至酒店等行业的无数客户都在使用 Amazon Personalize 为用户提供个性化的内容推荐服务。在 Amazon Personalize 的帮助下,您可以实现一系列常见用例,包括为用户提供个性化商品推荐、显示相似商品以及根据用户喜好对商品进行重新排序等。
Amazon Personalize 能够自动使用您的用户-项目交互数据进行机器学习模型训练,并提供 API 以检索面向任意用户的个性化推荐结果。很多朋友都抱有这样的疑问:我们该如何将 Amazon Personalize 生成的推荐结果,与现有推荐系统进行性能比较呢?为了解答这个问题,我们将在本文中介绍如何使用 Amazon Personalize 执行 A/B 测试,这是一种用于对不同推荐策略进行有效性比较的常用技术。
大家可以在AWS管理控制台上,或者通过 Amazon Personalize API 快速创建一套实时推荐系统,具体操作步骤如下:
导入您的历史用户-项目交互数据。
根据实际用例,使用 Amazon Personalize 机器学习算法(也被称为recipes)启动一项训练作业。
部署一个由 Amazon Personalize 托管的实时推荐端点(亦被称为campaign)。
通过将事件流传递至附加在 Amazon Personalize 部署当中的 event tracker,实现对新用户-项目交互的实时记录。
下图展示了 Amazon Personalize 具体管理的各项任务。
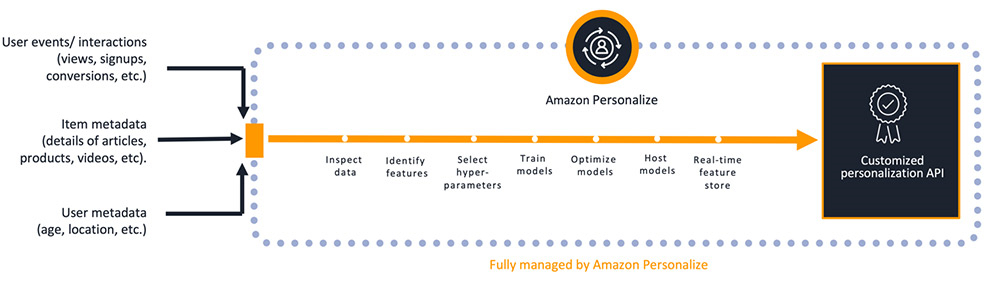
指标概述
我们可以通过离线和在线指标对机器学习推荐系统的性能加以衡量。离线指标用于查看修改超参数与模型训练算法后的实际效果,可以根据历史数据计算得出。在线指标则是对用户与实时环境中的实时推荐进行互动时,观察到的实际效果。
Amazon Personalize 使用由历史数据中的测试数据集生成离线指标。这些指标能够展示模型如何根据历史数据生成新的推荐。下图展示了 Amazon Personalize 在训练过程中对数据进行拆分的简单示例。
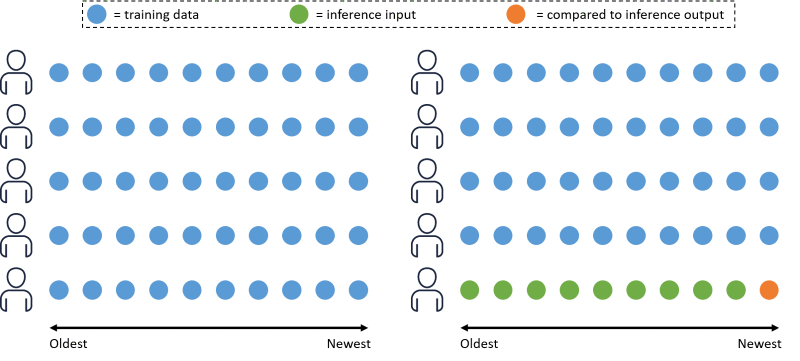
我们假定使用一套包含 10 位用户的训练数据集,每位用户分别进行了 10 次交互。交互通过圆圈进行表示,并根据时间戳从最早到最新进行排序。在此示例中,Amazon Personalize 将使用 90%的用户交互数据(蓝色圆圈)进行模型训练,另外 10%则用于模型评估。对于评估数据子集中的用户,其交互数据中又有 90%(绿色圆圈)作为已训练模型的输入,而其余 10%的数据(橙色圆圈)则与输出进行比较以验证模型推荐结果的质量。比较的结果通过评估指标进行展示。
Amazon Personalize 将生成以下指标:
Coverage(覆盖率) – 此项指标适合展示推荐项目覆盖到全部库存项目中的比例(百分比形式)。
Mean reciprocal rank at 25 (前 25 项中平均排名倒数) – 这项指标主要适合指示单一排名最高的推荐结果。
Normalized discounted cumulative gain at K (K 项标准化折现累计收益) – 折现累计收益是一种衡量排名质量的方法,主要关注推荐结果的顺序。
Precision at K (精度) – 此项指标主要用于衡量前 K 项推荐的精度,具体产生了怎样的用户宣传效果。
关于 Amazon Personalize 如何计算这些指标的更多详细信息,请参阅评估解决方案版本。
离线指标能够有效表示我们的超参数与数据特征,如何根据历史数据中的模式影响模型的预测性能。要探寻 Amazon Personalize 推荐结果对您业务指标(例如点击率、转化率或收入)产生影响的经验性证据,您应该在实时环境中对推荐结果进行测试,并将其实际展示在客户面前。这方面测试非常重要,因为此类业务指标的哪怕一点微小改进,都有可能推动客户参与度、满意度以及业务产出(例如收入)的显著增长。
在以下内容中,我们将提出一种实验方法论与参考架构,供大家借此确定以随机方式向用户提供多种推荐策略(例如 Amazon Personalize 与现有推荐系统)的实现方法,并以科学合理的方式(A/B 测试)衡量二者之间的性能差异。
实验方法
通过多项实验收集到的数据,将帮助您根据业务指标衡量 Amazon Personalize 推荐结果的实际效果。下图说明了我们建议遵循的实验方法。
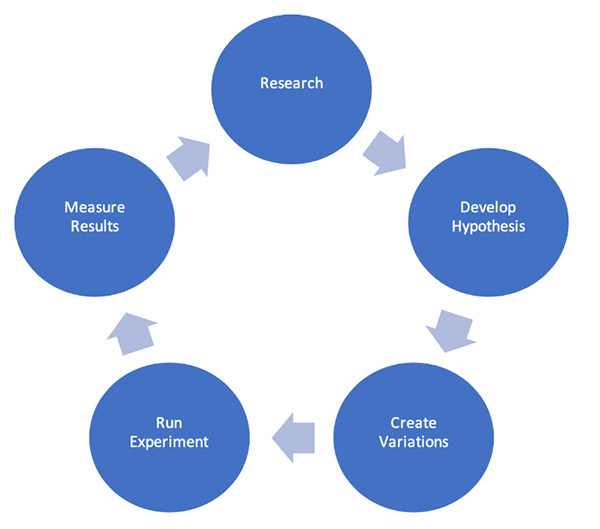
整个流程包含五个步骤:
研究 ——具体提出的问题以及指标改进定义,完全基于您在实验开始之前收集到的数据。例如在浏览历史数据之后,大家可能会希望了解为什么购物车中的商品长期“吃灰”,或者向潜在客户展示的广告为何无人问津。
提出假设 ——根据研究阶段收集到的数据进行观察,建立一个关于变更与效果的基本假设。请注意,这些假设必须可以量化,例如通过在购物车页面上展示 Amazon Personalize campaign 提供的用户个性化推荐,令购物车的平均结算金额提升了 10%。
根据假设创建变量 ——实验的变量调整将以您当前评估的假设行为为基础。与现有基于规则的推荐系统相比,您可以将新创建的 Amazon Personalize campaign 视为实验的变量。
运行实验 ——您可以使用多种技术测试您的推荐系统;本文重点介绍 A/B 测试方法。实验期间收集到的指标数据将可用于验证基本假设是否有效。例如,在将 Amazon Personalize 推荐结果添加至购物车页面一个月之后,购物车的平均结算金额与继续使用原有推荐系统的购物车平均结算金额相比增长了 10%。
衡量结果 ——在此步骤中,我们需要确定新系统是否带来了具有统计学意义的改进,并从中选择效果最佳的变量。购物车平均结算金额的增长,到底是用户测试集中随机性带来的结果,还是受到全新 Amazon Personalize campaign 的切实推动?
对您的 Amazon Personalize 部署进行 A/B 测试
下面的架构展示了两项 Amazon Personalize campaign 之间基于微服务的 A/B 测试实验示例。其中一项 campaign 使用 Amazon Personalize 提供的推荐 recipe 训练而成,另一项则由该 recipe 的变体训练得来。Amazon Personalize 提供多种预先定义的机器学习算法(recipes);其中基于 HRNN 的 recipe 能够帮助您为用户生成个性化推荐结果。
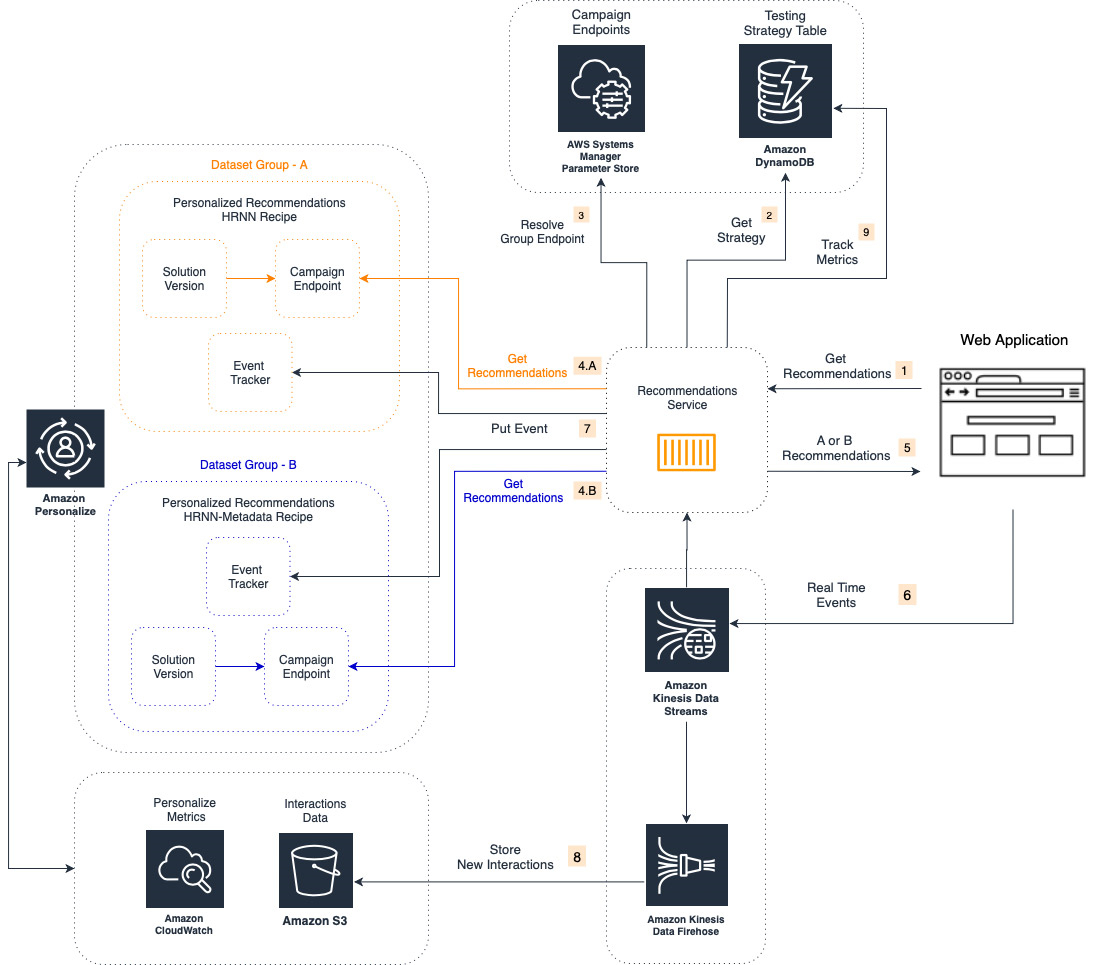
这套架构比较了两项 Amazon Personalize campaign。在将 Amazon Personalize campaign 与基于自定义规则/基于机器学习的推荐系统进行比较时,请注意使用相同的测试逻辑。关于 campaign 的更多详细信息,请参阅创建campaign。
这套架构的基本工作流程如下:
Web 应用程序向推荐微服务请求客户推荐结果。
微服务确定是否存在活动的 A/B 测试。在本文中,我们假定您的测试策略设置存储在 Amazon DynamoDB当中。
当微服务识别出您的客户所属的群组时,即开始解析 Amazon Personalize campaign 端点以查询推荐结果。
Amazon Personalize campaigns 为您的用户提供推荐结果。
用户与其所在的群组推荐结果进行交互。
Web 应用程序将用户交互事件流式传输至 Amazon Kinesis Data Streams。
微服务使用 Kinesis 流,该流将用户交互事件发送至两个 Amazon Personalize event trackers 处。Amazon Personalize 提供Recording events(事件记录)功能,可收集实时用户交互数据并实时提供相关推荐。
Amazon Kinesis Data Firehose提取您的用户-项目交互流,并将互动数据存储在 Amazon Simple Storage Service (Amazon S3)当中以用于后续训练作业。
微服务会在整个实验过程中,持续跟踪您的预定义业务指标。
关于运行 A/B 测试的具体操作说明,请参阅 Github repo上的示例零售店实验研讨部分。
在 A/B 测试期间,对具有良好定义的业务指标进行持续跟踪是一项至关重要的任务。这些指标的变化与改进,直接对应着 Amazon Personalize 推荐结果的实际影响。在 A/B 测试当中测得的指标,必须在所有版本(A 组与 B 组)之间保持一致。例如,电子商务网站可以评估在添加 Amazon Personalize 推荐(A 组)后与原有基于规则的推荐系统(B 组)获得的点击率之间的变化(增加或减少)。
A/B 实验需要在一段时间内保持运行,且通常由达到显著统计学变化所需要的用户数量决定。Optimizely, AB Tasty以及 Evan Miller’s Awesome A/B Tools等能够帮助您确定具体需要怎样的样本体量。A/B 测试往往需要持续几天甚至几周时间,以从用户群体中收集到足够多的样本。下图展示了测试流程、模型调整以及成功推出新功能之间的反馈循环。
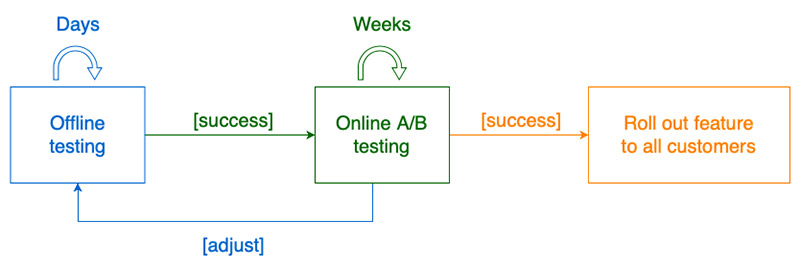
为了保证 A/B 测试成功,您需要对收集到的整体数据进行统计分析,以确定结果中是否存在具有统计学意义的结果。此项分析将以您为实验设定的显著性水平为基础。目前行业标准一般将 5%设定为基准显著性水平。例如,显著性水平为 0.05 则表示当实际情况没有差异时,结果有 5%的几率存在差异。显著性水平设定得越低,则代表我们需要更强有力的证据才能获得具有统计学意义的结果。关于统计显著性的更多详细信息,请参阅统计学意义复习教程。
下一步是计算p值。所谓 p 值,是指当原假设为真时,看到极端特殊结果出现的概率。换句话说,p 值是给定样本中的预期波动,类似于方差。例如,假设我们进行一轮 A/A 测试,向两组用户展示完全相同的内容。经过这样的实验之后,两组之间的预期性指标结果虽然存在差异但已经非常相似,即 p 值大于我们设定的显著性水平。而在 A/B 测试中,我们则期望 p 值小于我们设定的显著性水平,由此即可得出结论,即变量组中确实存在对业务指标有所影响的因素。AWS 合作伙伴(Amplitude 以及 Optimizely)提供了成熟的 A/B 测试工具,可帮助大家简化实验中的设置与分析步骤。
A/B 测试是对 Amazon Personalize 推荐结果有效性的统计学度量指标,可帮助大家量化这些推荐结果对业务指标的实际影响。此外,您还可以使用 A/B 测试收集用户-项目交互中的有机信息,借此对 Amazon Personalize 模型进行后续训练。我们建议您尽量控制离线测试的时长,尽快将 Amazon Personalize 推荐结果发布给实际用户。这有助于消除训练数据集中存在的系统性偏差,保证您的 Amazon Personalize 部署方案能够从真实客观的用户-项目交互数据中学习。
总结
Amazon Personalize 是一项易于使用且具备高可扩展性的解决方案,能够帮助大家实现一系列常见的推荐系统用例:
个性化推荐
相似项目推荐
项目个性化重新排名
A/B 测试还能够提供客户与 Amazon Personalize 推荐结果间实际交互方式的宝贵信息。这些结果将根据明确定义的业务指标进行衡量,使您了解推荐结果的有效性,以及该如何进一步调整训练数据集建立起明确认知。在对此过程进行多轮迭代之后,您会发现各项重要指标都将得到改善,客户参与度也将随之提高。
如果本文对您有所帮助,或者在应用 A/B 测试改善业务指标方面对您有所启发,请和我们分享您的心得与体会。
扩展资源
关于 Amazon Personalize 的更多详细信息,请参阅:
作者介绍:
Luis Lopez Soria
AWS 机器学习团队 AI/ML 专业解决方案架构师。他与 AWS 客户合作,帮助他们大规模采用机器学习技术。在业余时间,他喜爱运动、环游世界,以及体验新的食物与文化。
本文转载自亚马逊 AWS 官方博客。
原文链接:




