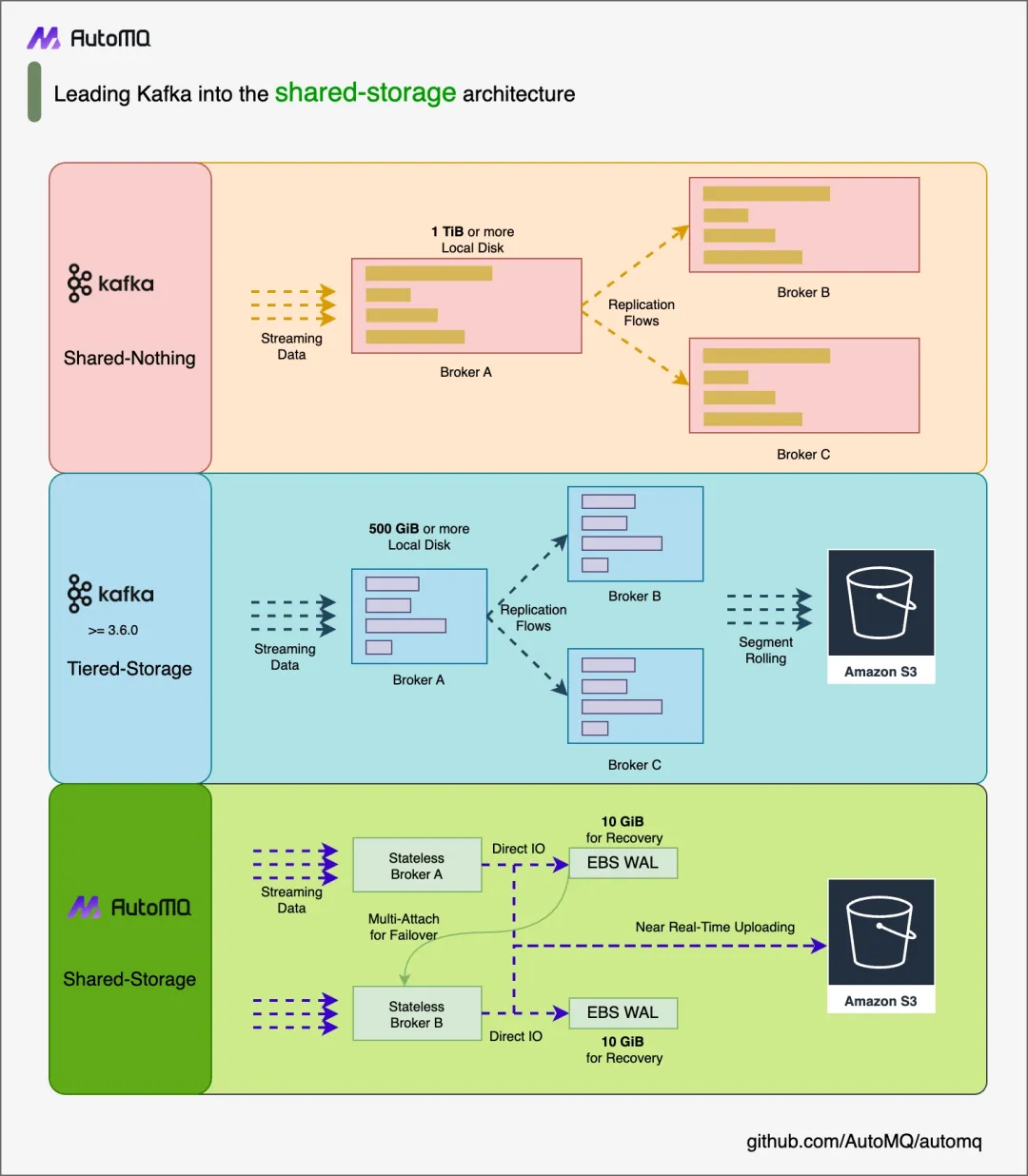
01 TL;DR
Apache Kafka 不是 Kubernetes Native 的数据基础设施。虽然 Kubernetes 作为云原生技术的集大成者,大大提升了企业在资源管理和 DevOps 方面的效率,但也对在其上运行的应用程序提出了新的挑战。为了充分发挥 Kubernetes 的潜力,其 Pod 需要能够在节点之间快速迁移和恢复。Apache Kafka 诞生于十多年前,设计初衷是面向传统数据中心(IDC)场景。其存算一体化的架构在云原生时代面临弹性不足、无法充分利用云服务、运维复杂、成本高昂等问题,使其难以很好地契合 Kubernetes 所遵循的云原生理念。在 Kubernetes 上使用非 Kubernetes Native 的 Kafka 服务将使得你的 Kafka 生产环境置于危险中,你必须小心翼翼地维护他来确保他的可用性与性能。稍有不慎,你可能为这些 Kafka 故障承担责任,丢掉你的工作。而 AutoMQ [1] 作为新一代基于云原生理念构建的 Kafka,很好地解决了这些问题,为用户提供了 Kubernetes 原生的 Kafka 服务。这篇文章将与你介绍在 Kubernetes 上部署 Apache Kafka 会带来什么问题,以及 AutoMQ 是如何解决它们的。
02 什么是 AutoMQ
AutoMQ[1] 是一款贯彻云原生理念设计的 Kafka 替代产品。其除了在 Github 上提供源码开放的社区版本 [2],同时也在云上提供 SaaS 和 BYOC 的商业版本。AutoMQ 创新地对 Apache Kafka 的存储层进行了基于云的重新设计,在 100% 兼容 Kafka 的基础上通过将持久性分离至 EBS 和 S3 带来了 10x 的成本降低以及 100x 的弹性能力提升,并且相比 Apache Kafka 拥有更佳的性能。你可以通过以下的对比系列文章来进一步了解 AutoMQ。
AutoMQ vs. Apache Kafka [3]
AutoMQ vs. WarpStream [4]
AutoMQ vs. Amazon MSK [5]
03 什么是 Kubernetes Native Kafka
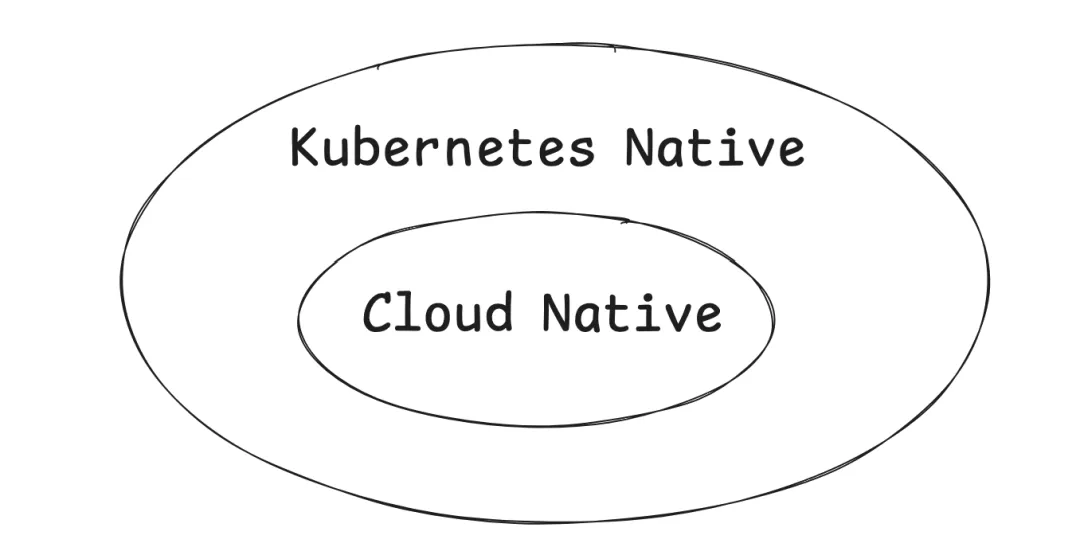
Kubernetes Native[6] 的概念最早由 Redhat 的 Quarkus 提及。Kubernetes Native 是一种特化的 Cloud Native。Kubernetes 本身是 Cloud Native 的,其充分利用 CNCF 所定义的容器化、不可变基础设施、服务网格等云原生技术。Kubernetes Native 的程序拥有 Cloud Native 所拥有的所有优势。在此基础上,额外强调能够与 Kubernetes 可以进行更加深度的集成。而 Kubernetes Native Kafka 则表示可以与 Kubernetes 深度集成充分发挥 Kubernetes 全部优势的 Kafka 服务。Kubernetes Native Kafka 可以将 Kubernetes 的以下优势彻底发挥出来:
提升资源利用率:Kubernetes 提供了更细粒度的调度单元(Pod)和强大的资源隔离能力。容器化的虚拟化技术使得 Pod 可以在节点之间快速迁移;资源隔离确保同一节点上的 Pod 可以合理使用资源。结合 Kubernetes 强大的编排能力,可以大大提升资源利用率。
屏蔽 IaaS 层差异,支持混合云避免供应商锁定:通过 Kubernetes 来屏蔽 IaaS 层差异,可以使得企业更加轻松应用混合云架构,避免供应商锁定,从而在采购云厂商服务时拥有更多的议价权。
更加高效的 DevOps: 贯彻 Kubernetes 的最佳实践准则,可以让企业以 IaC 的方式来实现不可变基础设施,通过和企业内部 CI/CD 流程打通,利用 GitOps 结合 Kubernetes 本身提供的运维部署支持,可以大大提升 DevOps 的效率和安全性。
04 为什么需要 Kubernetes Native Kafka
4.1 Kubernetes 在中大型企业中变得流行
Kubernetes 在中大型企业中越来越受欢迎。对于这些企业来说,每天的资源消耗都是一笔不小的费用。通过将所有应用部署到 Kubernetes 上,可以显著提升资源利用率,实现统一标准化管理,并在 DevOps 过程中获得最大的好处。
当企业内的所有应用程序和数据基础设施都运行在 Kubernetes 上时,从公司战略角度来看,像 Kafka 这样的核心数据基础设施也应当运行在 Kubernetes 上。AutoMQ 服务的客户中,例如京东和长城汽车,从集团战略层面就要求 Kafka 必须运行在 Kubernetes 上。
此外,中大型企业相比小型企业更有混合云的需求,以避免供应商锁定的问题。通过利用多云策略,这些企业可以进一步提升系统的可用性。这些因素都进一步推动了对 Kubernetes Native Kafka 的需求。
总结来说,Kubernetes Native Kafka 能够帮助中大型企业在资源利用率、标准化管理、DevOps 效率、混合云策略和系统可用性方面获得显著优势,因此成为这些企业的必然选择。
4.2 Apache Kafka 是 Kubernetes rehost,不是 Kubernetes Nativei Kafka
虽然 Kafka 凭借其强大的生态能力,诞生了诸如 Strimz[12] ,Bitnami Kafka[13] 这样优秀的 Kafka Kubernetes 生态产品,但是不可否认的是 Apache Kafka 本质不是 Kubernetes Native 的。在 Kubernetes 上部署 Apache Kafka 本质是一种将 Apache Kafka 在 Kubernetes 上进行 rehost 的行为。即使配合 Strimz 和 Bitnami Kafka 的能力,Apache Kafka 仍然无法将 Kubernetes 的潜力全部发挥出来,包括:
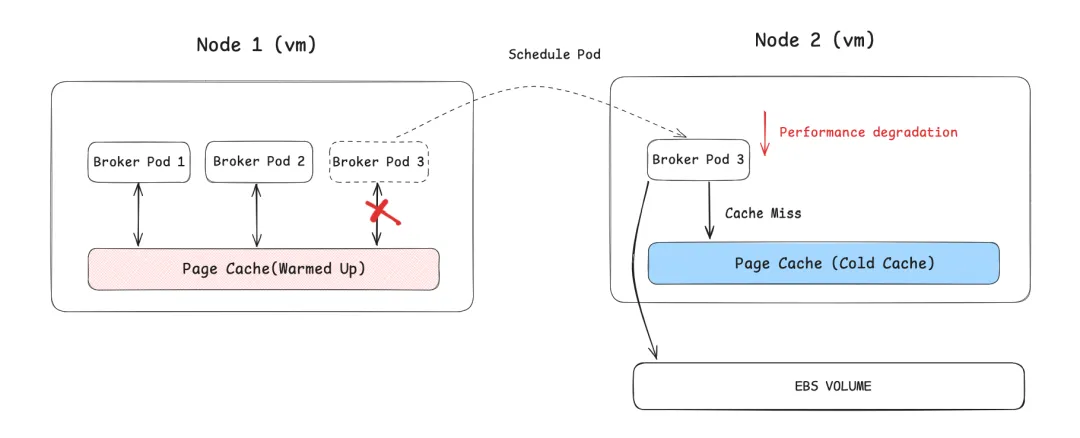
4.2.1 Broker Pod 无法在 Node 间进行性能无损的随意调度
Apache Kafka 强大的吞吐能力和性能与其基于 Page Cache 的实现方式有密切关系。容器不会虚拟化操作系统内核。因此,当 Pod 在 Node 之间漂移时 Page Cache 都需要进行重新预热 [8],这会影响 Kafka 的性能。当处于 Kafka 业务的高峰时期,这种性能影响将会更加显著。在这种背景下,如果 Kafka 的使用者关注其性能对业务的影响,则不敢让 Kafka Broker Pod 在 Node 之间随意漂移。如果 pod 无法在 Node 之间快速自由地漂移,则会大大削弱 Kubernetes 调度的灵活性,无法将其编排和提升资源利用率的优势发挥出来。下图展示了 Broker Pod 漂移时,因 Page Cache 没有预热导致引发磁盘读使得 Kafka 性能受损。
4.2.2 Apache Kafka 在 Kubernetes 上无法完成自动弹性
Apache Kafka 本身基于多副本 ISR 来保证数据的持久性。当在 Kubernetes 上需要对集群进行横向扩容时,Apache Kafka 需要非常多的人为干预,整个过程不仅不是自动化的而且还有很大的运维风险。整个流程包括:
分区迁移评估:扩容前首先需要由对集群业务和负载充分了解的 Kafka 运维人员评估将哪些 Topic 的分区迁移至新创建的节点之上。并且要确保新节点的机器规格满足这些分区的读写流量要求以及评估迁移时长以及迁移对业务系统的影响。光是第一步,就已经是非常繁琐并且很难实施的步骤。
准备分区迁移计划:需要准备 partition reassign policy 文件,其中具体列出要将哪些分区迁移到新的节点
执行分区迁移:Apache Kafka 按照用户给定的 partition reassign policy 来执行分区的迁移。整个过程的耗时取决于用户在本地磁盘保留的数据大小。这个过程一般会耗费数小时甚至更久的时间。迁移期间由于大量的数据复制,会抢占磁盘和网络 I/O,影响正常的读写请求。此时集群的读写吞吐会受到显著影响。
4.2.3 Apache Kafka 在 Kubernetes 上没法自动做高效率、安全的 rolling
正是由于 Apache Kafka 缺乏弹性以及强依赖 Page Cache 等特点,进一步使得其无法在 K8s 上执行高效率和安全的滚动升级(Rolling)。在 K8s 上对高流量、高容量的 Apache Kafka 进行滚动重启是一件很有挑战的事情。因为,在迁移过程中 Kafka 的运维人员必须时刻关注集群的健康状况。分区数据的复制、Page Cache Miss 引发的 Disk Reads 都会影响整个集群的读写性能,从而进一步影响用户依赖 Kafka 的应用程序。
4.2.4 K8s 的 Kubernetes PV 不支持缩容,存储成本高昂
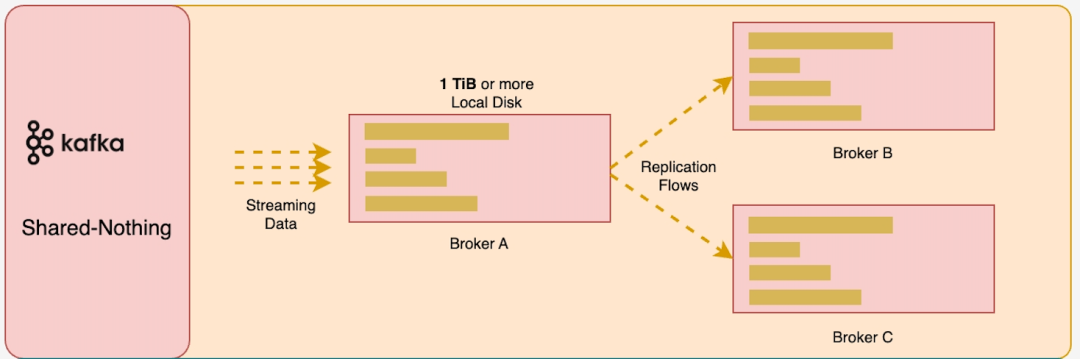
K8s 当前仍然没有支持 PV 进行缩容 [11]。K8s 对于无状态或者计算存储完全解耦的程序来说是十分友好的。但是,对于这些有存储状态的程序来说则有比较大的限制。PV 不支持缩容意味着 Kafka 必须按照峰值吞吐来持有存储空间。为了保证高吞吐和低延迟,用户往往需要使用昂贵的 SSD 来存储 Kafka 的数据。当用户吞吐较大并且数据保留时间较长时,这将耗费用户大量的金钱。
05 AutoMQ 如何做到真正的 Kubernetes Native
5.1 复用 Kafka Kubernetes 生态,可提供成熟的 Helm Chart 和 Operator
得益于 AutoMQ 对 Apache Kafka 的 100% 完全兼容,AutoMQ 可以充分利用 Kafka 已有的 K8s 生态产品,例如 bitnami 提供的 Kafka chart 以及 strimizi 提供的 kafka operator。如果用户原本就已经在使用 bitnami 或者 strimzi 的 Kafka K8s 方案,即可以无缝平滑迁移至 AutoMQ,立刻享受 AutoMQ 提供的低成本、弹性等云原生优势。

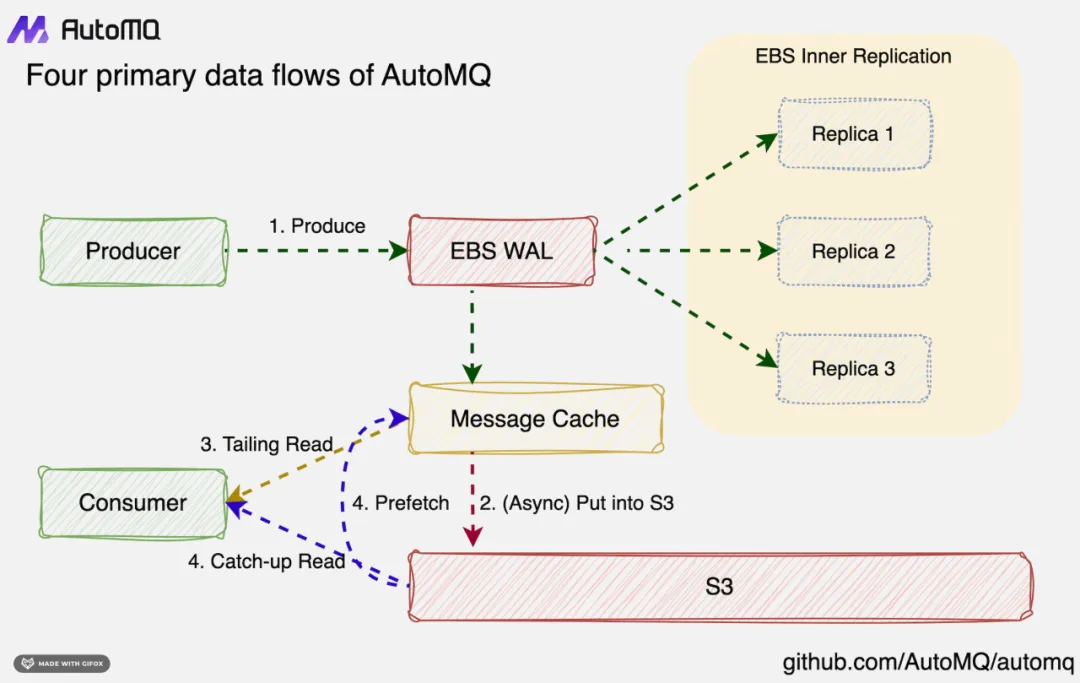
5.2 不依赖 Page Cache,pod 可以在容器上自由迁移,无需担心影响性能
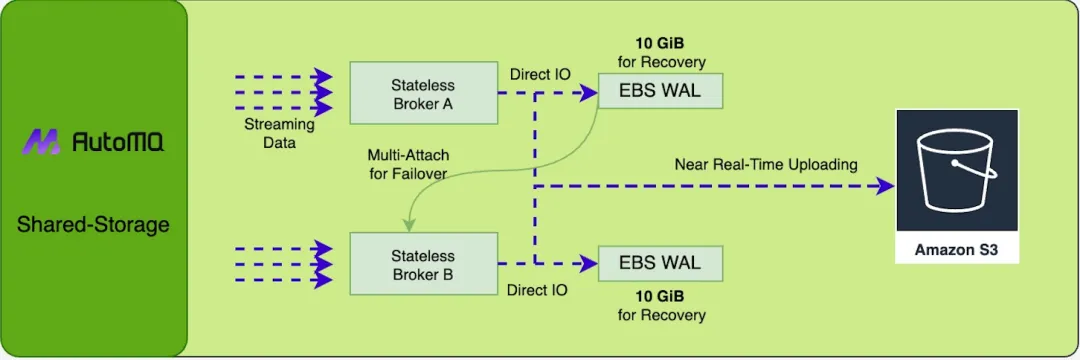
AutoMQ 无需像 Apache Kafka 一样担心 pod 迁移时 Page Cache 没有预热导致的性能劣化问题。与 Apache Kafka 通过多副本以及 ISR 来保障数据持久性不同的是 AutoMQ 利用 WAL 将数据的持久性卸载至云存储 EBS。利用 EBS 内部多副本机高可用来保证数据持久性。虽然不再使用 Page Cache,但是结合 Direct I/O 配合云盘 EBS 本身低延迟高性能的特征,AutoMQ 仍然可以做到个位数毫秒的延迟。具体的数值,可以参考 AutoMQ vs. Kafka 性能报告 [15]。
5.3 强大的弹性能力充分发挥 k8s 资源管理和自动运维部署的潜力
在 K8s 上使用 AutoMQ 无需担心 Apache Kafka 由于其自身缺乏弹性带来的无法自动弹性、Rolling 等问题。只有 Kafka 真正支持自动弹性、高效安全的 Rolling ,K8s 才可以自动、高效安全地腾挪 Pod 提升资源利用率以及利用其基于 IaC 的自动化 DevOps 来提升运维管理的效率。AutoMQ 通过以下技术手段保证了用户可以自动、安全地在 K8s 上对其完成自动弹性、Rolling 等操作:
秒级分区迁移:在 AutoMQ 中,分区迁移不再涉及任何数据复制。当需要对 Broker 上的分区进行移动时,仅仅是元数据的变更操作,可以在秒级内完成分区的迁移。
持续流量自平衡:Apache Kafka 仅提供了分区迁移工具,但具体的迁移计划则需要运维人员自行决定,而对于动辄成百上千个节点规模的 Kafka 集群来说,人为监控集群状态并制定一个完善的分区迁移计划几乎是不可能完成的任务,为此,社区也有诸如 Cruise Control for Apache Kafka[16] 这类第三方外置插件用于辅助生成迁移计划。但由于 Apache Kafka 的重平衡过程中涉及到大量变量的决策(副本分布、Leader 流量分布、节点资源利用率等等),以及重平衡过程中由于数据同步带来的资源抢占和小时甚至天级的耗时,现有解决方案复杂度较高、决策时效性较低,在实际执行重平衡策略时,还需依赖运维人员的审查和持续监控,无法真正解决 Apache Kafka 流量分布不均的问题。而 AutoMQ 内置了自动的自平衡组件,根据搜集的 metric 信息,自动可以帮助用户生成分区的迁移计划并且执行迁移,使得自动弹性完成后集群的流量也能自动重平衡。

AutoMQ 在 K8s 上与其自动弹性相关的生态产品,例如 Karpenter[17] 和 Cluster Autoscaler[8] 也可以非常好的进行协同工作。关于 AutoMQ 在 K8s 上自动弹性的解决方案如果有兴趣可以参考 AWS 官方博客内容《使用 AutoMQ 实现 Kafka 大规模成本及效率优化》[19]。
5.4 将 AutoMQ 部署到 Kubernetes 不会导致复杂度爆炸
我们必须承认,不是所有规模的企业或者程序都可以从 K8s 中获益。Kubernetes 本身在应用程序和底层 VM 之间增加了一层新的抽象,从安全、网络、存储等维度都带来了新的复杂度。将不是 Kubernetes Native 的程序强行 rehost 到 k8s 上,会进一步放大这种复杂度,引发更多新的问题。用户为了让非 Kubernetes Native 的程序可以在 k8s 上运行良好,自身可能需要做非常多的与 k8s 最佳实践违背的 Hack 行为以及大量人工介入。以 Apache Kafka 为例,无论是 Strimz 还是 Bitnami 都无法解决其横向扩展的问题,因为该过程必须人为介入从而保证扩缩容过程时集群的可用性与性能。当这些人为操作与 K8s 自动化的 DevOps 理念格格不入。使用 AutoMQ 则可以真正消除了这些人为干预的行为,充分利用 K8s 自身的机制来对 Kafka 集群进行高效、自动化地集群容量调整以及更新升级。

5.5 存储卸载至云存储,不依赖本地磁盘空间
K8s 本身不是为有状态的数据基础设施而设计的,因此其很多默认提供的能力对于有存储状态或者存储解耦不彻底的程序来说不是十分友好。K8s 倾向于用户在其上部署无状态的应用程序,并将有状态的数据彻底解耦出去,从而可以充分发挥其提升资源利用率、改善 DevOps 效率的优点。Apache Kafka 存算一体的架构强依赖本地存储,加之 PV 不支持缩容,使得其在 K8s 上运行需要预留大量存储资源,加剧了存储成本的开销。AutoMQ 的存储和计算层完全分离,仅仅将固定大小的(10GB)的块存储作为 WAL,数据全部卸载至 S3 存储。在这种存储架构下,充分利用云对象存储服务无限扩容、pay-as-you-go 的特性,使得 AutoMQ 可以像无状态的程序一样在 K8s 上面工作,将 K8s 的潜力完全发挥出来。
06 总结
AutoMQ 通过其创新的基于 WAL 和 S3 的共享存储架构以及秒级分区迁移、持续流量自平衡等亮点特性,构建了真正的 Kubernetes Native Kafka 服务,可以充分发挥 Kubernetes 的全部优势。你可以使用 Github 上开放源码的 AutoMQ 社区版来进行体验,也可以在 AutoMQ 官网申请免费的企业版进行 PoC 试用。
参考资料
[1] AutoMQ:https://www.automq.com
[2] AutoMQ Github: https://github.com/AutoMQ/automq
[3] Kafka Alternative Comparision: AutoMQ vs Apache Kafka:https://www.automq.com/blog/automq-vs-apache-kafka
[4] Kafka Alternative Comparision: AutoMQ vs. AWS MSK (serverless): https://www.automq.com/blog/automq-vs-aws-msk-serverless
[5] Kafka Alternative Comparision: AutoMQ vs. Warpstream: https://www.automq.com/blog/automq-vs-warpstream
[6] Why Kubernetes native instead of cloud native? https://developers.redhat.com/blog/2020/04/08/why-kubernetes-native-instead-of-cloud-native#
[7]Kafka on Kubernetes: What could go wrong? https://www.redpanda.com/blog/kafka-kubernetes-deployment-pros-cons
[8] Common issues when deploying Kafka on K8s: https://dattell.com/data-architecture-blog/kafka-on-kubernetes/
[9] Apache Kafka on Kubernetes – Could You? Should You?:https://www.confluent.io/blog/apache-kafka-kubernetes-could-you-should-you/
[10] Kafka on Kubernetes: Reloaded for fault tolerance: https://engineering.grab.com/kafka-on-kubernetes
[11] Kubernetes 1.24: Volume Expansion Now A Stable Feature: https://kubernetes.io/blog/2022/05/05/volume-expansion-ga/
[12] Strimz: https://strimzi.io/
[13] Bitnami Kafka: https://artifacthub.io/packages/helm/bitnami/kafka
[14] How to implement high-performance WAL based on raw devices?:https://www.automq.com/blog/principle-analysis-how-automq-implements-high-performance-wal-based-on-raw-devices#what-is-delta-wal
[15] Benchmark: AutoMQ vs. Apache Kafka: https://docs.automq.com/automq/benchmarks/benchmark-automq-vs-apache-kafka
[16] Cruise Control for Apache Kafka: https://github.com/linkedin/cruise-control
[17] Karpenter: https://karpenter.sh/
[18] Cluster Autoscaler: https://github.com/kubernetes/autoscaler
[19] 使用 AutoMQ 实现 Kafka 大规模成本及效率优化:https://aws.amazon.com/cn/blogs/china/using-automq-to-optimize-kafka-costs-and-efficiency-at-scale/
今日好文推荐
剥离几百万行代码,复制核心算法去美国?TikTok 最新回应来了
IBM 中国撤退进行时:仅三分钟研发测试千人全被裁,周一冒雨上班发现公司没了
传IBM中国研发岗位员工被收回访问权限,涉全国各地千余人;《黑神话:悟空》涉嫌抄袭?突发!Telegram创始人被捕 | Q资讯