
Zendesk 通过将 DynamoDB 迁移到使用 MySQL 和 S3 的分层存储解决方案,将数据存储成本降低了80%以上。该公司考虑了不同的存储技术,并决定将关系型数据库和对象存储结合起来,在降低成本的同时,取得可查询性和可伸缩性之间的平衡。
Zendesk 使用DynamoDB存储为事件流数据创建了持久性解决方案。最初的设计很有效,但运营成本越来越高。团队切换到了一个预置的计费模型,将成本降低了 50%,但是随着客户群的增长,以及需要使用Global Secondary Indexes(GSI)来支持新的查询模式,该架构运转所需的成本变得不可持续。
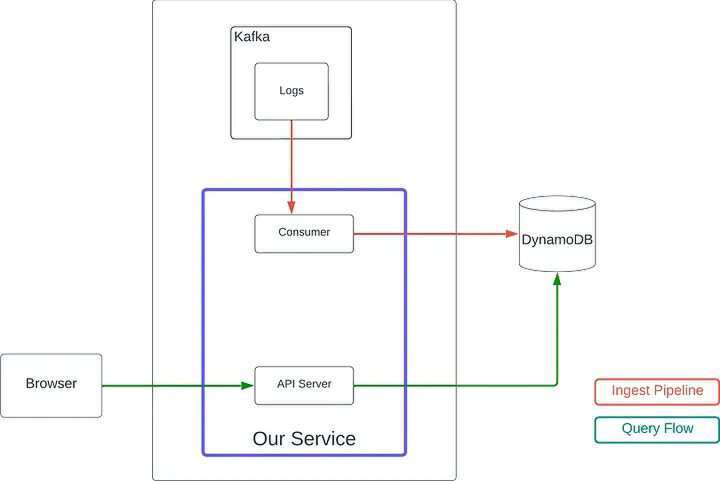
原来使用 DynamoDB 的架构(图片来源:Zendesk工程博客)
由于 Zendesk 在 AWS 上运行其平台,该团队一直在寻找能够满足其功能和技术要求,同时又能降低成本的替代存储解决方案。他们考虑了S3、Hudi(Zendesk 使用的数据湖)、ElasticSearch和MySQL,但因为复杂性和 24 小时延迟而放弃了 Hudi,而 ElasticSearch 的成本与使用 DynamoDB 相似。最后,团队决定使用 MySQL 来缓冲来自Apache Kafka的日志及存储元数据,并使用 S3 来存储原始数据,每个文件 10000 条记录。
摄取流(ingestion flow)将 Kafka 消费的日志数据存储到 MySQL 的缓冲表中。每隔一小时,后台作业就会以每个文件 10000 条日志为单位,将缓冲表中的新记录批量上传到 S3 中,并为每个 S3 文件插入一条元数据记录。另有一个作业每隔一小时会从缓冲表中删除超过 4 小时的日志。
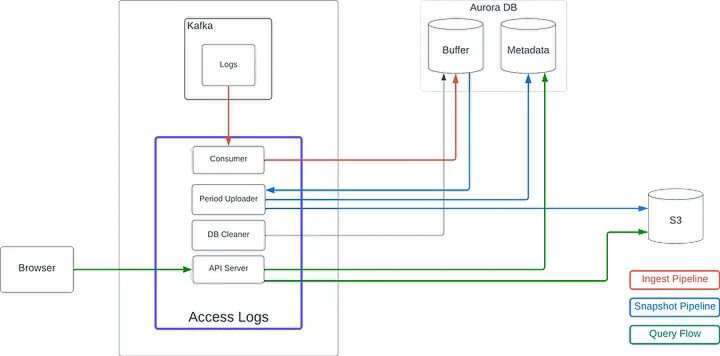
使用 MySQL(AuroraDB))和 S3 的新架构(图片来源:Zendesk工程博客)
为了处理查询,新解决方案需要在 MySQL 元数据表中进行查找,然后对查找返回的文件并行执行一组S3-Select查询。由于数据布局针对时间顺序检索进行了优化,所以团队在执行更复杂的查询时遇到了问题。
Zendesk 集团技术主管Shane Hender解释了在新架构中进行灵活查询所面临的挑战:
在完成了上述所有工作后,当客户端希望通过时间戳以外的任何字段筛选结果时,我们遇到了性能问题。例如,如果客户端需要特定 user-id 的日志,那么在最坏的情况下,为了查找相关日志,我们必须扫描给定时间范围内的所有 S3 数据,这使得我们很难确定哪些查询可以并行执行。
工程师们曾考虑通过在 S3 中复制数据来处理筛选多个字段的情况,但考虑到字段组合的数量比较大,这种方法并不可行。最终,他们找到了Bloom Filters,并进一步将其与Count-Min Sketch数据结构相结合,提供了一种支持多字段筛选查询的有效方法。改进后的解决方案需要一个额外的表来存储序列化数据结构,用于确定所要查询的 S3 文件。
迁移完成后,Zendesk 将存储成本降低到不到 DynamoDB 配置成本的 20%,其中 MySQL (AuroraDB)占 90%以上,S3 和 S3-Select 占不到 10%。新的解决方案提供了大约 200 到 500 毫秒的查询延迟,不过峰值有时会达到几秒,团队正设法进一步优化。
原文链接:
https://www.infoq.com/news/2023/12/zendesk-dynamodb-mysql-s3-cost/




