
当地时间周三(9 月 27 日),OpenAI 在 X(前身为推特)上宣布,其聊天机器人产品 ChatGPT 可以通过微软的必应搜索引擎进行网络搜索,将不再局限于 2021 年 9 月之前的数据。
OpenAI 称:“现在 ChatGPT Plus 和 Enterprise(企业版) 用户可以使用浏览功能,将很快扩展到所有用户。要启用,请在 GPT-4 下的选择器中选择‘使用必应浏览’( Browse with Bing)。”
需要说明的是,OpenAI 早些时候测试了相关功能,允许 Plus 用户通过必应搜索访问最新信息,但后来因担心用户绕过付费墙,禁用了这项功能。
值得一提的是,OpenAI 本周早些时候还宣布了另一项重大更新,将使 ChatGPT 可以通过图片和语音命令交互。
ChatGPT 再迎重大升级:“能看、能听,也能说”
本周一,OpenAI 宣布对 ChatGPT 进行重大更新,使其 GPT-3.5 和 GPT-4 两大 AI 模型能够分析图像内容,并在文本对话中据此做出反应。OpenAI 方面表示,ChatGPT 移动版应用还将引入语音合成选项,在与现有语音识别功能配合使用时,能够与 AI 助手进行全口语对话。
OpenAI 也强调,语音合成功能目前仅适用于 iOS 和 Android 平台,而图像识别则将登陆 Web 版和移动版应用。
OpenAI 解释称,ChatGPT 中的全新图像识别功能允许用户基于 GPT-3.5 或 GPT-4 模型,根据上传的一张或多张图像开展对话。该公司在其宣传博文中宣称,这项功能能够对接各类日常应用,例如为冰箱和食品储藏室拍摄照片以确定晚餐吃点什么,还有排除烧烤炉出故障的原因。该公司还提到,用户可以使用设备的触控屏圈出自己希望 ChatGPT 重点关注的部分。
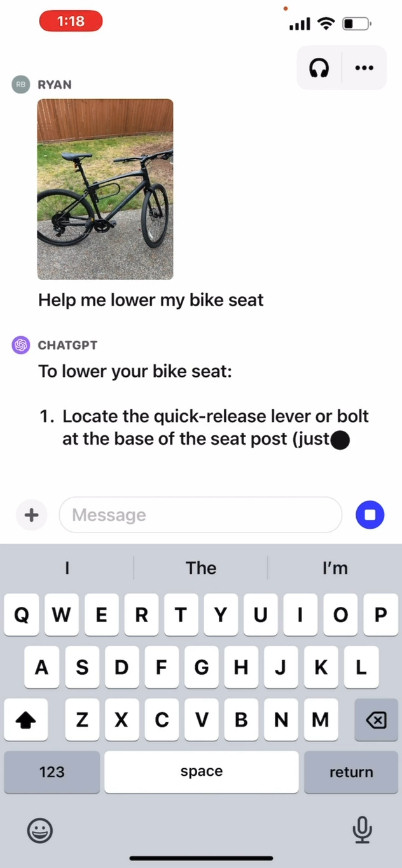
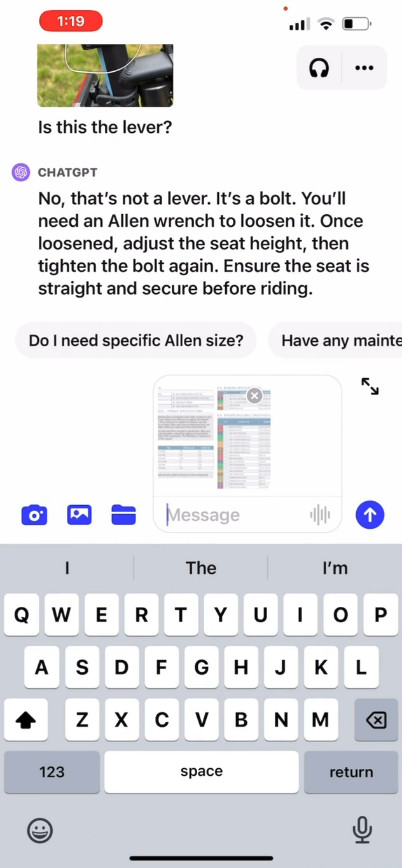
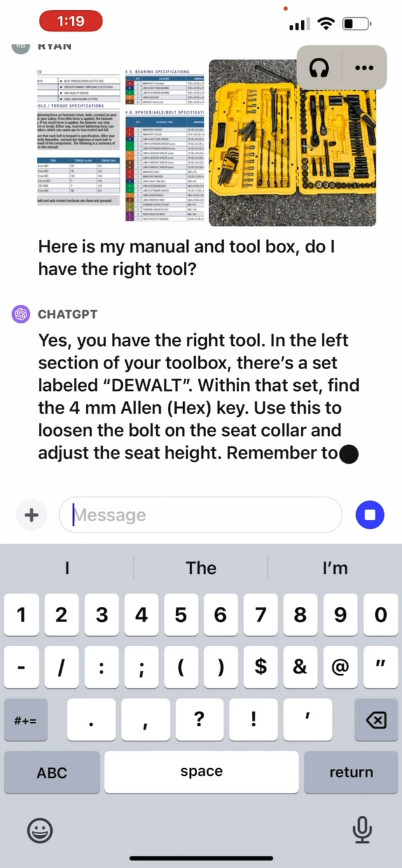
OpenAI 宣传视频中的画面,ChatGPT 在分析用户照片以帮助其调整自行车座高。
在官方网站上,OpenAI 发布了一段宣传视频(https://openai.com/blog/chatgpt-can-now-see-hear-and-speak),展示了与 ChatGPT 的交流过程。其中用户询问要如何升高自己的自行车座垫,并上传了车辆、说明手册以及工具箱的照片。ChatGPT 迅速做出反应,并为用户提供了完成调整过程的说明。我们还没有亲自测试过此功能,因此不太清楚实际效果是否真有这么惊艳。
那这一切到底是怎么实现的?OpenAI 尚未发布 GPT-4 或其多模态版本 GPT-4V 的底层运行细节。但根据其他厂商(包括 OpenAI 合作伙伴微软)的已知 AI 研究,多模态 AI 模型往往能够将文本和图像转化为共享编码空间,借此通过同一套神经网络处理多种类型的数据。OpenAI 可以使用 CLIP 来弥合视觉与文本数据间的差异,从而在同一潜在空间(一种表达数据关系的向量化网络)上实现图像和文本表示对齐。正是这项技术,让 ChatGPT 具备了跨文本和图像进行上下文推理的能力——当然,这一切都只是外界的推测。
与此同时,报道还指出 ChatGPT 的全新语音合成功能允许用户与其进行直接对话,而且此功能由 OpenAI 的“新文本转语音模型”驱动。尽管文本转语音技术已经相当成熟,但该公司表示在此功能推出之后,用户可以在应用端的设置中选择语音对话,之后从五种不同的合成语音中做出选择,具体包括“Juniper”、“Sky”、“Cove”、“Ember”和“Breeze”几个选项。OpenAI 称这些声音均是与专业配音演员合作开发而来。
OpenAI 的 Whisper 是一套开源语音识别系统,此次也由它继续负责对用户语音输入的转录。Whisper 于今年 5 月正式与 ChatGPT iOS 版应用集成,随后在 7 月登陆 ChatGPT 的 Android 版应用。
“请注意,ChatGPT 给出的结果不一定准确”
OpenAI 于今年 3 月公布 GPT-4 时,就曾经展示过该模型的“多模态”功能,据称可以处理文本和图像输入。但在随后的测试阶段,公众一直无缘真正体验其图像功能。期间 OpenAI 与 Be My Eyes 合作开发了一款可以为盲人描述场景照片的应用。今年 7 月,有报道称 OpenAI 的多模态功能之所以迟迟未能发布,主要是受到隐私问题的影响。与此同时,微软则于 7 月匆忙在基于 GPT-4 的 AI 助手 Bing Chat 中启用了图像识别功能。
在最近的 ChatGPT 更新公告中,OpenAI 称其扩展功能仍有一些限制,并承认该模型仍可能出现潜在的视觉混淆(即对某些内容的错误识别)、对非英语语种无法完美识别等问题。该公司表示,他们已经“在极端场景和纯科学验证角度”对新功能进行了风险评估,同时征求了 alpha 版本内测人员的意见,目前的观点仍然是建议谨慎使用,特别是在科学研究等高风险或专业性较强的背景之下。
鉴于在开发 Be My Eyes 应用时遇到的隐私问题,OpenAI 表示已经采取“技术措施来尽量限制 ChatGPT 对人类对象做分析和直接描述的能力。因为 ChatGPT 给出的结果不一定准确,AI 系统应当尊重个人隐私。”
尽管仍有种种缺陷,但 OpenAI 在营销材料中还是强调 ChatGPT 如今已经“能看、能听,也能说”。当然,并不是每个人都能认同这种充满拟人倾向的炒作宣传。Hugging Face 公司 AI 研究员 Sasha Luccioni 博士就在 X 上发推称,“别再像看待人类那样看待 AI 模型了。ChatGPT 根本就没法看、没法听,也没法说。它只能跟各种传感器相集成,以不同于人类的方式接收和发出信息。”
虽然 ChatGPT 及其底层 AI 模型还远远算不上“人”,但如果本次公布的结果不假,那也至少代表着 OpenAI 的这款虚拟助手实现了巨大的功能增强。
此外,OpenAI 也强调了推迟开放有其充分理由:“我们认为应该逐步推出自己的工具,这样我们才能随时间推移不断改进并完善风险缓解措施,同时也让大家能为未来更强大的 AI 系统做好准备。”
参考链接:




