
COVID-19 席卷全球,对全球生命卫生安全构成了极大挑战。截至 2020 年 11 月 3 日,COVID-19 全球累计确诊 4718 万人,累计死亡 120 万人。在没有疫苗情况下,早发现、早报告、早隔离、早治疗是控制疫情的最有效方案。
在疫情防控最关键的前几个月,京东数科智能城市部门帮北京市找到 500 余名高危的密切接触者,为宿迁市找到全市范围四分之一比例的新冠肺炎确诊人员;在全国范围内,帮广州、南京、成都等 18 个省市做了高危人群态势分析。其中,JUST 团队做出了重要贡献。我们提出了一种新颖的轨迹感染风险度量和高效的查询方案,这项工作已发布在论文[1]。
一、问题背景
致命病毒在人与人之间的传播一直是全球公共卫生面临的重要问题。从 19 世纪前半叶开始,由霍乱狐菌引发的霍乱夺取了无数人的生命,仅仅印度,在霍乱爆发之后的 100 年间,由其造成的死亡人数高达 3800 万人。在欧洲,仅在 1831 年间死亡人数高达 90 万人。2002 年底,“非典”疫情爆发,其病死率近 11%。
自 2019 年底开始至今,一种新冠病毒(SARA-Cov-2)造成的疾病 COVID-19 席卷全球,对全球生命卫生安全构成了极大挑战。截至 2020 年 11 月 3 日,COVID-19 全球累计确诊 4718 万人,累计死亡 120 万人。

在没有疫苗情况下,早发现、早报告、早隔离、早治疗是控制疫情的最有效方案。中国政府根据四早方案,果断采取封城、方舱隔离等措施,很快控制住了 COVID-19 的传播,保障了人民的安全。
因为 COVID-19 具有极高的传染性,它可以通过唾液等传播,并且几乎人人易感。因此,早发现病毒携带者并及时将其隔离,就能阻止他传播给其他人,进而有效地防止疫情大规模传播。
传统寻找病毒携带者主要通过以下两种方案:1)人工询问患者曾经去过的地方和接触的人群,然后让相关社区工作人员去核实和隔离密切接触者;2)通过患者的出行记录,如火车票,飞机票等,找到与患者同乘的人。但以上这两种做法十分依赖于患者的记忆,并且很难找全与患者有过一段近距离共处的陌生人。
随着移动互联网的高速发展,每时每刻都会产生大量的时空数据。这些时空数据记录着人的活动轨迹。因此,如果我们掌握了 COVID-19 患者在被隔离前的活动轨迹,那么我们就可以很清楚地知道他去过的地方,再通过时空范围查询就能找到跟患者有过近距离接触的人群。如图 1 所示,给定患者移动轨迹(如图 1 中红色轨迹),易感人群挖掘找出与这条轨迹有过密切接触的人群(如图 1 中蓝色人群)。
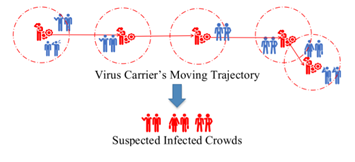
图 1:易感人群示意图
现存轨迹度量,如 DTW、EDR、Hausdorff 等算法能计算轨迹的全局相似度[3]。但是,只要与患者在很小的时空范围内近距离接触就可能被感染,因此这些度量不适用于易感人群判断。此外,COVID-19 潜伏期很长,甚至超过了 14 天,并且它在潜伏期也有传染性。然而,一座城市 14 天产生的轨迹数据量可能会十分庞大。因此,计算全城中所有与患者接触的人群需要巨大的计算量。
为此,我们提出了一种新颖的轨迹度量,它将轨迹分成若干传播子段,再计算各个子段与患者密切接触程度,最后我们将疑似人与患者所有传播子段的接触概率综合起来评价他被感染的概率。此外,我们利用 JUST 引擎管理防疫期间的海量轨迹,并设计了一种空间优化索引 SFT,其将相近时空范围内的轨迹段聚集在一起,极大地加快了查询效率。
二、基本框架
为了处理大量患者传播的易感人群,我们开发了一个快速查询的解决方案。如图 2 所示,我们系统的主要结构由三个部分组成:数据预处理,候选者提取和感染性探索。
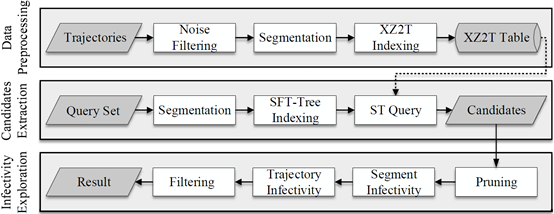
图 2:算法框架
数据预处理: 如图 2 中最上面的方框所示,我们首先将轨迹的噪声位置过滤掉。之后,我们将轨迹分段。然后,我们使用 XZ2T 索引来组织轨迹段,再通过 JUST[2]将它们存储到 NoSQL 数据库中。
候选者提取: 候选者提取过程使用分段算法、SFT 索引策略和时空查询接口。分段的目的是避免轨迹太长而带来的较大的内存和 I/O 开销。我们在所有待查询轨迹段上建立了 SFT 索引,其中具有类似时空范围的段被放置在 SFT 索引同一叶节点中。然后,我们通过扩展 SFT 每个叶节点的时空范围,再从数据库中提取候选片段。最后,我们从数据库中获得了粗粒度的候选对象,并且数据冗余度低且 I / O 消耗较小。
感染性探索: 图 2 的最底部的框显示了感染性探索的过程。首先,我们修剪一些不可能是密切接触的候选人;然后,我们计算剩余疑似人群在患者可传播段的感染概率,再聚合属于同一轨迹的局部轨迹段的所有传染性,并计算出其轨迹的总体传染性。最后,我们过滤传染性低于感染阈值的轨迹。
三、数据预处理
由于用户轨迹数量巨大,造成传统数据库难以实现快速查询。因此,我们通过分布式数据库(如 HBase),将海量轨迹数据用 key-value 的形式存储在具有多备份且安全的分布式集群上。然而,传统分布式并不直接支持轨迹数据,为此需要为轨迹数据设计特殊的行键结构,才能取得更佳查询效率。
我们设计的 XZ2T 索引,能高效的管理类似轨迹这种多维时空数据。XZ2T 索引按照固定时间跨度(如,年,月,日)将时间划分为若干不相交的区间,并通过 XZ2 索引将二维空间范围映射到一维整数域中,如图 3 所示,然后再组合时间分区号和空间编码值为存储键,再将其键和数据存储在分布式数据库中以备易感人群挖掘查询离线使用。
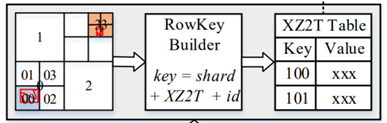
图 3:表设计
四、候选者提取
1、分段
首先,我们患者的轨迹分成若干个可传播片段,这些片段可以准确的表示患者曾经在那些地方活动过。然后,我们通过查询每个轨迹片段可能感染的时空范围,找到候选易感人群。我们从两个时间或者空间间隔超过一定值的轨迹点中间切断轨迹,形成轨迹段。如图 4 中,最大时间间隔为 30 分钟,最大空间间隔为 50m。
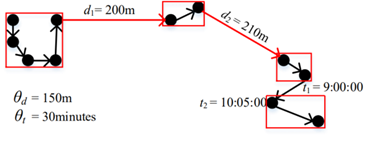
图 4:轨迹分段
2、SFT 索引
在实际的使用场景中,患者的数据会批量增加,如果采用循环查询将花费大量的时间。为此,我们设计了空间优先时空索引 SFT,其将相近时空范围内的轨迹段聚集在一起并一同查询疑似人群。这样的设计极大地减少了 I/O 开销和数据冗余。如图 5 所示,在 SFT 索引中,我们首先通过四叉树将轨迹段聚类在不同节点上,然后再在每一个叶子节点中建立一维 R 索引管理时间范围。
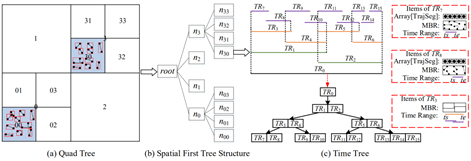
图 5:SFT 空间优先索引
3、ST Query
如图 6 所示,我们患者轨迹(蓝色轨迹)分成两条子段 s$_1$, s$_2$,每条轨迹段会形成一个活动的空间(如图 6 中红色实线表示的矩形范围)和时间(如图 6 中 q$_1$. t 和 q$_3$ .t 之间的时间范围)范围,我们将空间范围和时间范围扩张 θ$_d$ , θ$_t$ 得到受影响时空范围。最后,我们从数据库中提取出所有出现在患者影响时空范围内的人群,并根据用户 ID 聚合属于同一人的轨迹,进而得到疑似人群。并通过下面的具体实现第五节中描述的感染风险度量方案确定疑似人群的风险值。
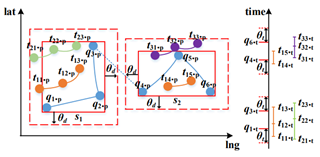
图 6:疑似人群查询
五、感染风险
COVID-19 患者会感染跟他有过密切接触的人。因此,被感染风险的影响因素与患者和正常人接触的时空距离远近有很重要的关系。所以,患者轨迹中的每一个轨迹点都能形成一个传播的时空范围。
1、时空关系度量
我们将轨迹点定义为 l = (p, t) ,其中 p 表示位置, t 表示时刻。给定一个轨迹点位置 l , 一个空间影响范围 θ$_d$ 和一个时间影响范围 θ$_{t.}$我们用 STR ( l , θ$_d$ , θ$_{t.}$)来表示时空影响范围。如下:
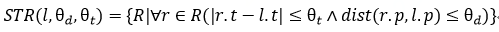
其中 dist 表示空间距离,在位置 l 影响的时空范围 STR ( l , θ$_d$ , θ$_{t.}$)内,我们通过公式计算人群与该时空位置上的密切接触程度:
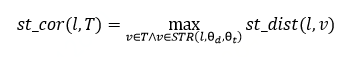
其中, st_dist ( l , v )表示两个时空位置之间的距离。

其中,λ属于[0, 1]区间,它用来控制空间和时间的偏好,和将空间距离和时间间隔归一化到[0,1]范围内。注意,如果一条轨迹与 STR ( l , θ$_d$ , θ$_{t.}$)不相交,那么它在 l 处的时空接触可能为 0。
2、轨迹感染风险
(1)局部轨迹段的感染风险
为了更精准的描述患者传播路径,需要将患者从潜伏期开始到被隔离期间的所有轨迹集中起来。但由于 GPS 终端有些信号不稳定或者用户关闭了终端等原因,造成了患者在这段时间的轨迹并不一定是一直连续的。并且,患者所有时空点组成的一条轨迹具有较大的时空范围,这样会在时空查询时产生大量的冗余数据。因此,我们需要将轨迹分段,将长轨迹分割成较为合适的轨迹局部段。如图四所示,我们从两个时间或者空间间隔超过一定距离的轨迹点中间切断轨迹,形成轨迹段。
给定病毒携带者的局部轨迹段( s )和疑似感染人员的轨迹(T),我们通过公式衡量疑似人员在携带者的局部轨迹段被感染的风险。
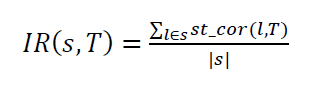
其中, l 是轨迹段 s 中的一个时空位置,| s |代表 s 的时空位置数量。
(2)轨迹感染风险
一个病毒携带者的完整轨迹由多个局部轨迹段组成。因此,仅仅通过局部轨迹段的感染风险并不能完全反应疑似人员被感染风险。如,某个疑似人员虽然跟患者在各个轨迹局部段接触并不多,但是他多次出现在患者不同的局部轨迹段中,那么他也被感染的风险应该更大。
因此,简单的做法通过将疑似人员在携带者各个局部段的被感染风险值相加作为最终感染风险。但是,如果病毒携带者在某一个轨迹局部段停留时间越长,那么他在该位置传播病毒的可能越大。我们需要考虑给携带者的局部轨迹段加上权重来标记它可能的传播强度。
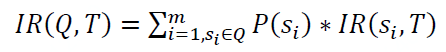
我们用时间的相对占比来标记可能的强度。
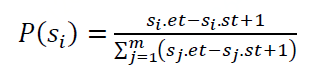
3、剪枝策略
易感人群算法需要计算患者每个时空点与附近疑似人群的感染概率,因此需要大量的计算量。所有,我们提供了四种剪枝策略来减少计算量。剪枝策略的详细描述见[1]。
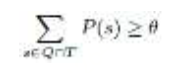
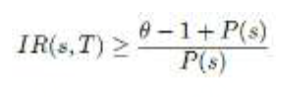
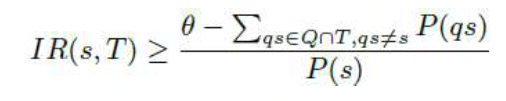
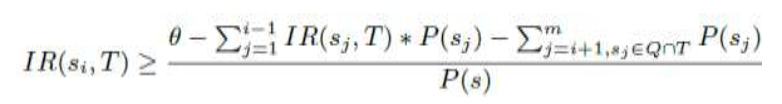
六、案例
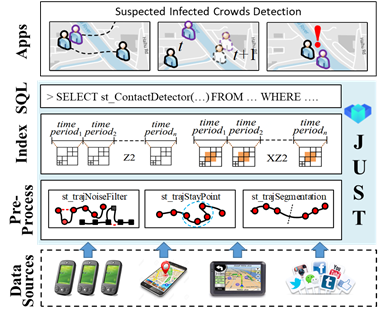
图 7:易感人群系统
我们基于本算法开发了易感人群查询系统。如图 7 所示,我们将手机等设备和应用产生的时空轨迹数据存储在 JUST 平台中,并利用 JUST 提供的轨迹预处理功能完成原始轨迹去噪和分段操作。然后我们将轨迹存储在 JUST 提供的轨迹表中。再将第五节设计的易感人群算法封装为 DAL 操作,让用户可以通过一条简单的 SQL 语句就能很快地完成易感人群查询。最后,对外输出易感人群名单支持上层应用。
该系统已经支持了北京、武汉、广州、南京、成都等多个省市。在疫情最关键的前几个月,我们帮北京市找到 500 余名高危的密切接触者;为宿迁市找到全市范围四分之一比例的新冠肺炎确诊人员;并协助其它团队完成高危人群态势分析。
参考文献:
[1] He, Huajun & Li, Ruiyuan &Wang, Rubin & Bao, Jie & Zheng, Yu & Li, Tianrui. (2020). EfficientSuspected Infected Crowds Detection Based on Spatio-Temporal Trajectories.
[2] http://just.urban-computing.com/
[3] https://mp.weixin.qq.com/s/95DJin1jHNntg1X9sp6R8Q
本文转载自公众号京东数科技术说(ID:JDDTechTalk)。
原文链接:




