
数据仓库是当前数据中台体系的核心组件之一,也是网易云音乐数据化运营的发动机,本文总结了 2020 年网易云音乐数据仓库团队的一些核心工作、取得的进展以及相关实践经验,希望对读者有所启发。
2020 年已结束,网易云音乐(以下简称云音乐)数据仓库团队取得了较为满意的成绩,也获得不小的成长。回顾团队过去一整年的工作,我们主要聚焦于两件事:
数据交付提效
数据质量提升
交付提效
我于 2019 年加入云音乐,当时数仓团队给我的第一印象是忙碌、年轻,这群基本都是 90 后的年轻人每天都会加班,晚一点的甚至会加班到 10 点后,大家每天都在忙碌的处理工单,包括数据报告、数据埋点、临时数据拉取等工作,但这些工作是琐碎的,交付效率也不如意。事实上,大家都意识到,工作可以是琐碎的,但是数据仓库是需要化零为整的,于是,管理层启动了当时数仓的“任督计划”,要构造新的云音乐的数仓数据体系。
数仓数据体系建设,是个很大的工程,包含数据架构、数据模型、数据质量、元数据管理、数据服务等工作,但是大家首当其冲的意识,是要做好数仓建模,也就是数据的通用层抽象,云音乐也不例外,在数据体系建设第一个重点工作便是数仓的通用层数据建模(data modeling)抽象。
音乐数仓的通用层建模规范
这里大家可能会有个疑问:为什么数仓的通用层数据建模会是第一高优的重点工作?这里我讲一个实际例子。2019 年 11 月,我刚来云音乐不到两个月便收到一个需求:业务策划同学希望通过一系列策略运营,最终能促成 look 直播里的主播同时也能成为云音乐主站的高质量创作者(比如 mlog 创作者、电台创作者、DJ、音乐人等等),这意味着在数据层面,look 直播的主播、音乐主站各种角色的创作者必须在数据上是通路的。较为遗憾的是,当时数仓通用层建设不够,很多人与人之间的关系、人的实体标签体系并未建立,所有的工作都需要从 0 开始做,因此,这个需求最终也是集结了当时云音乐所有数仓开发同学、耗时一个多星期才最终完成。所以我当时的想法便是,要快速的整理出云音乐数仓的通用层数据建模规范与方法并落地。
整理的过程细节便是数仓建模的标准流程,这里就不一一展开介绍了。不过最终,我们编写了《云音乐数据仓库建模规范》,并在该规范基础上与负责集团通用基础软件研发的网易数帆(以下简称数帆)团队共同创建了“EasyDesign”数仓模型设计系统,云音乐的数据主题域、主题域之间的关系也明确下来,如下图:
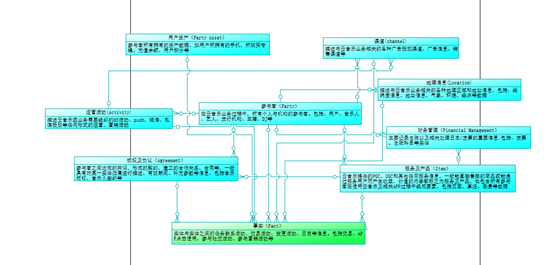
EasyDesign 数仓模型设计系统截图:
基于此数仓通用层建模规范,云音乐的数据资产沉淀开始变得有方向,在半年内,便把大量关于人、物、场景等实体的高频数据资产完成通用化设计并落地,工单需求的开发链路得以缩短、整体交付效率开始改观。
不过,虽然通用层的建设减少了重复性的开发工作,但毕竟是中间层,在针对一线同学的业务需求交付的“最后一公里”仍然存在瓶颈:手工、Excel、报表的交付始终是被动的、要排期的、不那么高效的,我们如何才能更高效的交付呢?甚至让一线的业务用户能自助的获取想要的数据?为解决这个问题,EasyFetch 孕育而生。
自助取数,数据配送的“最后一公里”
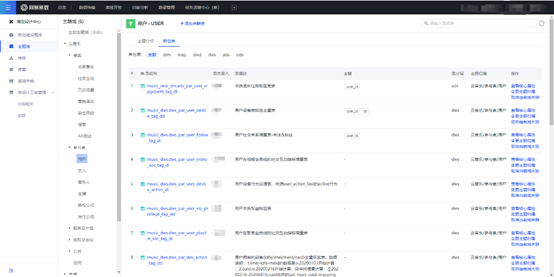
EasyFetch 的诞生还是一波三折的,当我意识到在交付最后一公里的问题后,我便联系数帆大数据专家郭忆,看看是否有现成的工具能帮助解决这个问题。我记得当我把需求给郭忆讲清楚后,一开始郭忆的反应是选型类似考拉海购的数据提取产品,但几经讨论,最后确定在介于有数报表、数据模型之间创造出一个新的分层 OLAP 工具,计算引擎选用 Impala,并且在初期独立开发以快速迭代试错,后期出成果后合并至有数。至此,自助取数产品 EasyFetch 诞生。
EasyFetch 初期时截图:
EasyFetch 上线之后,团队很快收到了来自云音乐业务策划、运营团队的反馈,主要集中在如下两个方面:
有些同学仍然习惯于人工手工取数排期,不了解自助拉取数据的新工作模式
好用,取数再也不用排期了,希望获得更高的性能,以及报表、推送、分享等功能
第一点反应的是工作习惯转变的适应过程,我们做了如下的努力:
加入了精炼的使用入门视频,帮助运营、策划快速上手;
维度、指标数据获取的过程,尽可能只需通过拖拉拽就可实现;
明确每个指标、口径,并明确其使用方法;
加入数据首页,对每个数据模块进行使用场景介绍;
前前后后组织 30+ 场线上线下培训,针对每条业务线的运营、策划成立自助取数 POPO 运维群,甚至一对一交流;
以上努力的效果是显著的,到 2020 年 9 月份后,我们的自助取数 POPO 运维群的交流骤减,但是取数的吐吞量稳步上升,这意味着自助取数已成为普遍的习惯。
至于第二点,一方面需要在有数的基础上做功能迭代,于是在去年的 5 月份,云音乐数仓团队同数帆的有数 BI 团队完成了到有数 EasyFetch 的迁移以满足用户不断对系统功能的需求;另一方面我们同数帆的大数据平台研发团队针对慢查询的场景,做了大量的 Impala 性能优化工作;借此契机,云音乐数据开发与数帆大数据平台研发团队建立了良好的数据开发知识分享机制。
这里也简单介绍下依据当时策划、运营要求,EasyFetch 所实现的功能要求:
圈人,且圈人后能生成人群包对接投放
自助拉取的数据能生成图表
能自驱生成数据任务,并定时调度同步至其他系统或 Excel
自己生成的取数、报告甚至是维度、指标能分享其他人
有数版本的 EasyFetch 截图:
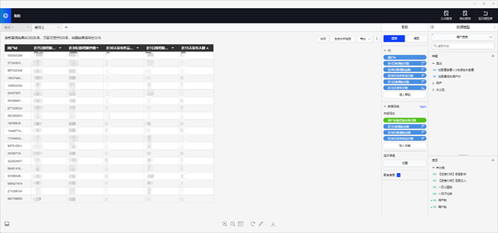
最终,在云音乐、数帆双方不懈努力下,EasyFetch 在音乐发芽、生长,成为了业务策划、运营临时取数、多维分析的重要手段,也大幅度的释放了云音乐数据开发的人力资源。总的说来,一线业务策划、运营获取数据的时间从天级缩短到秒级、分钟级内,极大缩短了策划、运营取数周期,在数据开发人力方面预计节约 4-5 人力(30% 效能提升),因为人力的节省、释放,云音乐数据仓库团队才得以喘息,有更多的人力投入在数仓基础建设工作上,整体进入良性循环。
自 2020 年 6 月起的数据表现:
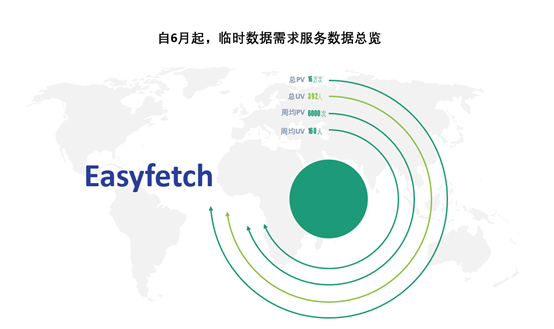
数据需求的管理面板
任务管理是本分工作,做了并不会有多少正面的夸赞,不做,一定会有反面的投诉。
过去的一年,云音乐数仓团队一共承接了约 1200 个功能性的大小需求。在初期,很多业务策划、运营同学抱怨自己提完需求后,根本不知道要做多久、什么时候交付,即使口头约定了交付日期,也可能因为诸如老板需求插入等原因导致交付 delay。另一方面,我们的数据开发同学每天都很忙,经常是满负荷运转,手头上需求很多,但是不知道哪个优先级是最高的,即使交付了需求还经常面临着被投诉 delay 的情况。
针对这样的情况,我们务必要针对各业务线建立其任务管理的面板,其目的有二:
让业务策划、运营同学非常清楚知道自己的需求在哪提、怎么提、要多久、目前进度在哪
让数据开发同学的工作有计划、有优先级
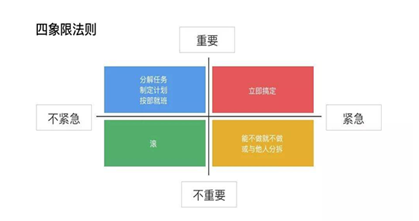
依照任务管理的四象限法则,我们对任务进行了分类,在任务收集、任务执行、任务完成三个环节定义了若干管理的要素,如下图:
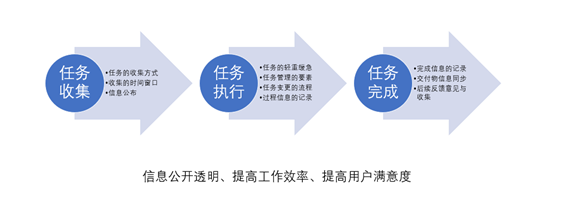
同时,我们建立的任务看板,并同步至一线的业务策划、运营同学。
至此,数据开发任务对于策划、运营同学们完全透明,随之而来的结果也是业务对数据开发的整体满意度评价提高了 40%。
质量提升
数据质量是任何一家数据驱动的互联网公司都避不开的高优话题,云音乐也是如此,而埋点的数据质量治理则是云音乐数据质量治理的核心工作。
而像云音乐这样的音乐内容生产、消费的商业公司,数据质量的问题主要集中在用户行为日志的采集上,也就是埋点。同大多数社交类互联网公司一样,在云音乐,核心 KPI、产品功能的迭代、AB 测试、市场投放、流量分发、内容效率的评估等等业务都是构建在埋点数据基础之上的,因此,埋点的重要性可见一斑。比较遗憾的是,截止 2020 年初,云音乐的埋点的 bug 还是较多的,各业务线时不时会投诉埋点数据不准。

有的同学会问,要解决埋点的数据质量问题为何不采用市面上成熟的商业化埋点产品?要回答这个问题,我们先了解下一般随着企业的发展,埋点的发展历程会经历的以下三个阶段:
阶段一:在 APP 的关键流程中,记录曝光、点击等时间,以满足基本的转化率统计,如点数 / 曝光;
阶段二:在阶段一的基础上,增加事件之间的关联追踪,以达到用户链路分析;
阶段三:在阶段二的基础上,增加用户链路上消费的任何商品、信息、内容,通过 ETL 最终建立用户画像分析、资源画像分析、用户流量分析、流量地图等数据资产;
很明显,云音乐已步入了第三个阶段,市面上成熟的商业化埋点产品无法自由的定义、管理、采集用户链路上的任何商品、信息、内容,这与企业的业务是息息相关的。因此,市面上通用的商业化的产品是无法满足云音乐埋点需求的。
基于以上原因,我们再次选择了与数帆团队进行了共建,制定流程、规范并完成系统化,埋点管理平台“EasyTracker”面世。
借力 EasyTracker 埋点管理平台,云音乐实现了埋点的事前、事中、事后管理。
事前 - 基于 SPM/SCM 的需求管理
先介绍下概念。
SPM (Super Position Model 超级位置模型):与 Google Analytics 在 URL 里面拼上 utm_source, utm_medium 等参数大同小异,主要是用来定位;
SCM(Super Content Model 超级内容模型):与业务内容一起下发的埋点数据,用来唯一标识一项业务内容。客户端打点时,将 SCM 编码作为埋点的参数上传;
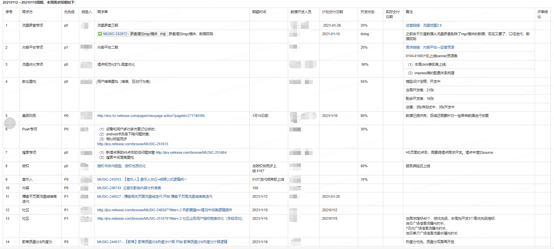
云音乐 SPM 格式由 6 段组合而成,即 A.B.C.D.E.F(其中 A、E 在采集中实现),具体信息如下
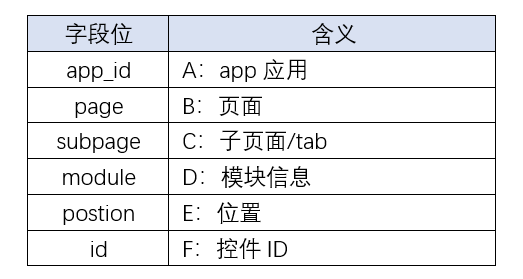
在云音乐原有的埋点需求 JIRA 中,业务策划、业务分析师会各显神通描述各自要实现采集的数据格式、内容,没有统一的语言来描述埋点需求,导致的结果:
理解成本极大,需要花大量时间进行需求沟通;
无统一实现规范,无法形成技术沉淀,不同的客户端同学对同一埋点的埋点时机、枚举值都可能不一致,最终导致数据质量问题;
SCM 枚举值较为随意,需要大量的 hardcode 来处理异常值,难以保证效率、质量;
因此,在事前约定好一套同一的埋点数据需求规范(DRD)变得极为重要。
新增埋点数据需求的规范化,也是围绕坑位来进行的,最终云音乐与所有产品策划、业务开发、业务 QA 共同制定了一套规范化的数据需求格式文档,格式如下:
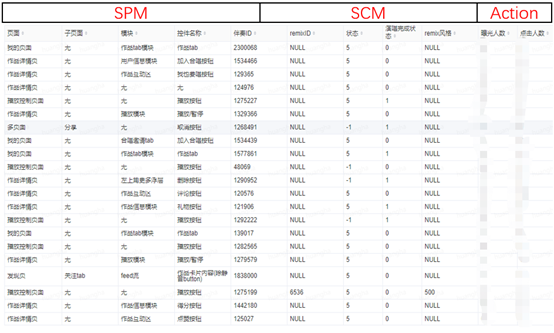
整个埋点数据需求(DRD)描述清楚用户需求的三个要素:SPM、Action、SCM。
一方面,SCM 定义后需在 EasyTracker 系统里进行需求登记:
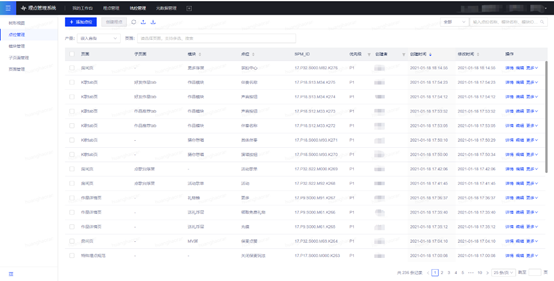
另一方面在 EasyTracker 进行 SCM 的枚举值管理
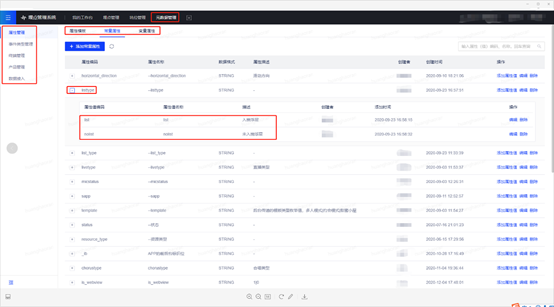
至此,在埋点事前的需求管理上,云音乐统一了语言。
事中 - 建立规范的多方的协作、任务流转
流程与效率有时候是针锋相对的,但是流程对规范化的执行是促进的。过重的流程当然会影响工作效率,因此,云音乐本次的流程改造仍偏向轻量级,着重解决因需求不规范造成的数据需求理解偏差与数据质量管理的问题。
经与埋点参与的各方讨论后,制定了如下流程:
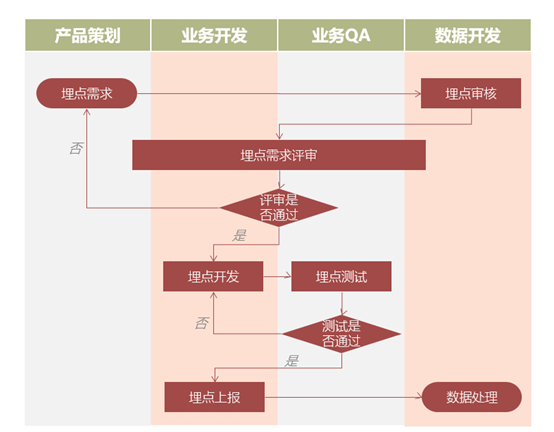
在此流程中,数据开发作为需求的承接方、埋点格式的设计方,需在评审中把控两件事:
埋点格式在 APP 的各版本、各终端是规范、一致的
明确埋点内容、埋点时机与业务需求期望是相符的
以上两件事确认后,方可进入埋点开发实现的流程。通过此流程的规范,数据分析需求与埋点实现的 gap 得以控制。
系统实现如下:
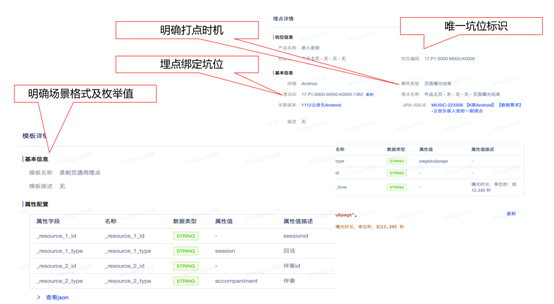
事后 - 建立数据稽核机制
在埋点实现后,埋点的监控着重针对以下两个场景进行数据稽核:
灰度版本
线上版本
数据稽核报告,着重监控埋点日志、坑位两部分数据质量。
整体埋点监控规则设计:
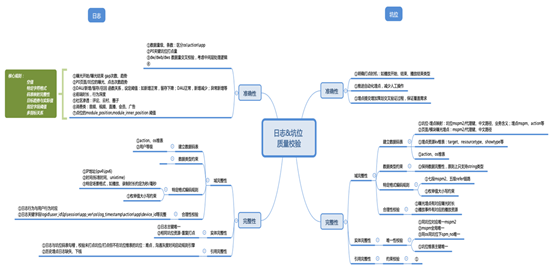
基于上图的规则设计,我们在 2020 年 8 月整体上线了埋点数据稽核的模块


最后,经埋点的前、中、后三环节的治理,最终在 2020 年年底,埋点的线下 bug 率下降了 50%。
总结
最后在总结环节,谈谈自己这一年来在数仓开发团队管理方面的一些体会:
交付效率的提升,不是埋头苦干,也不是简单的制度流程,反而更像是是需求方与开发方的小生态平衡:当开发方让开发任务变得有序、透明会反推需求方的需求提得更合理、更聚焦;
质量的管控是一场持久战,要不断在事前、事中、事后三个环节折腾、PDCA(plan、do、action、check),要学会归纳总结,找到 root cause,问题自然会慢慢收敛;
无论是提效抑或是质量管理,沉淀的经验、规则最好是固化成系统产品,数据的研发也应该有自己的 CI/CD 体系;
最最重要的一点,团队成员的成长至关重要,我们坚持的每周分享、学习帮助大家刷新了数据驱动的思维,并逐渐学会了新的任务管理模式,也夯实了每位同学的开发技巧。
作者简介:
黄浩然,网易云音乐数据平台开发专家,数据仓库负责人,在大数据架构设计、数据治理、数据模型设计和数据仓库领域已经拥有 16 年工作经验。




