
“对于人工智能,2022 年是有史以来最激动人心的一年。”微软首席技术官 Scott Stein 在近日的分享中说道,但他还自信地表示,“2023 年将是 AI 社区有史以来最激动人心的一年。”
值得关注的是,微软是 OpenAI 的主要投资者,而 OpenAI 最近 GPT-3.5 系列主力模型之一的ChatGPT 爆火,Stein 的这次发言也牵动了网友敏感的神经:GPT-4 要来了?
生成预训练 transformer(Generative Pre-trained Transformer,简称 GPT)是一种可利用互联网数据进行训练的文本生成深度学习模型,在问答、文本摘要、机器翻译、分类、代码生成和对话式 AI 领域都有相当出色的表现。
2022 年 7 月,OpenAI 发布了最先进的文本转图像模型 DALLE2。就在几周之后,Stability.AI 推出了 DALLE-2 的开源版本,名为 Stable Diffusion。两款模型在亮相后均大受好评,也在质量和理解文字描述的能力上展现出可喜的成果。最近,OpenAI 又推出名为 Whisper 的自动语音识别(ASR)模型,带来了优于原有同类模型的稳健性和准确度。
从过往趋势来看,OpenAI 在接下来几个月内推出 GPT-4 的概率很大。市场对大语言模型有着相当迫切的需求,GPT-3 的流行已经证明大家愿意接受 GPT-4,同时也对它的准确性、计算优化、更低偏差和更高安全性充满了期待。
GPT 不出,AI 万古如长夜
在 GPT-1 之前,大多数自然语言处理(NLP)主要针对分类和翻译等特定任务进行训练,使用的也均为监督学习方法。这类学习方法有两个问题:过度依赖注释数据,而且无法实现任务泛化。
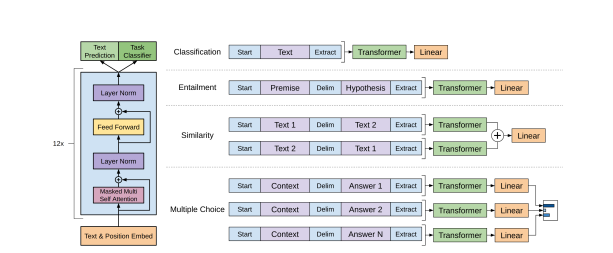
GPT-1(1.17 亿参数)相关论文《Improving Language Understanding by Generative Pre-Training》发表于 2018 年,其中提出了一种生成语言模型,能够使用未标记数据进行训练,并在分类和情感分析等特定下游任务上进行微调。
GPT-2(15 亿参数)论文《Language Models are Unsupervised Multitask Learners》发表于 2019 年,其中使用的参数更多、训练数据集也更大,语言模型自然进一步提升。GPT-2 使用任务调节、零样本学习和零样本任务转换等方式提高了模型性能。

GPT-3(1750 亿参数)论文《Language Models are Few-Shot Learners》发表于 2020 年,其模型参数达到了 GPT-2 的 100 倍,使用的训练数据集更大,因此能在下游任务上取得更好的效果。
GPT-3 在故事写作、SQL 查询、Python 脚本、语言翻译和摘要编写等能力上几乎能够与人比肩,效果惊艳全球 AI 界。如此出色的表现,离不开其中的上下文学习、少样本、单样本及零样本等技术设置。
GPT-4 可能是什么样子
在最近的活动中,OpenAI CEO Sam Altman 证实了 GPT-4 模型的发布传闻。下面是国外数据培训企业 DataCamp 对 GPT-4 模型大小、参数水平以及计算、多模、稀疏性及性能等方面的预测。
模型大小
根据 Altman 的介绍,GPT-4 并不会比 GPT-3 大太多。因此,预计其参数大约在 1750 亿到 2800 亿之间,跟 Deepmind 那边的语言模型 Gopher 基本相当。
块头更大的 Megatron NLG 是 GPT-3 的三倍,参数达 5300 亿,但性能并没有更好。紧随其后的稍小版本反而性能更优,所以单纯堆体量明显不足以让性能更上一层楼。
Altman 表示,他们正努力让更小的模型获得更佳性能。大语言模型需要庞大的数据集、海量算力和更复杂的实现。对于多数企业来说,不要说训练,这类大模型就算部署起来都困难重重。
最优参数化
大模型的优化水平往往不高,为了有效控制模型训练成本,企业必须在准确性和成本之间做出权衡。例如虽然还能改进,但 GPT-3 确实只训练过一次。由于无法承受成本,研究人员根本没办法进一步做超参数优化。
微软和 OpenAI 已经证明,如果用最佳超参数对 GPT-3 进行训练,该模型还有继续改进的空间。在调查结果中,他们发现经过超参数优化的 67 亿参数 GPT-3 模型与 130 亿参数 GPT-3 模型的性能基本一致。
他们还发现了新的参数化方法(μP),即较小模型的最佳超参数与相同架构的较大模型的最佳超参数相同。如此一来,研究人员就能以更低的成本实现大模型优化。
最优计算
DeepMind 最近发现,训练令牌的数量对模型性能的影响也很大,甚至不亚于模型大小。自 GPT-3 面世以来,他们一直在训练具有 700 亿参数的 Chinchilla 模型并证明了这一结论。该模型只相当于 Gopher 的四分之一,但使用的训练数据反而是后者的四倍。
所以我们基本可以假设,要实现模型最优计算,OpenAI 会额外再加 5 万亿个训练令牌。就是说要想将性能损失控制在最低,GPT-4 的模型训练算力将达到 GPT-3 的 10 到 20 倍。
GPT-4 将是一套纯文本模型
在问答当中,Altman 表示 GPT-4 不会是像 DALL-E 那样的多模模型,而是纯文本模型。
为什么这样说?与纯语言或纯视觉相比,多模模型的质量往往难以控制。将文本和视觉信息结合起来本身就是个大挑战,导致多模模型需要身兼 GPT-3 和 DALL-E 2 的双边优势,这显然很不现实。所以,GPT-4 应该不会出现什么花哨的新功能。
稀疏性
稀疏模型使用条件计算来降低计算成本。这类模型可以轻松扩展至超过 1 万亿参数,仍不会产生高昂的计算成本。稀疏模型能帮助我们用较低的资源训练出大语言模型。
但 GPT-4 应该不会是稀疏模型。为什么?因为 OpenAI 长期以来只研究密集语言模型,所以不太可能牺牲体积换取算力节约。
AI 对齐
考虑到 OpenAI 一直在努力解决 AI 对齐问题,所以 GPT-4 的表现应该会比 GPT-3 更好。OpenAI 希望语言模型能延伸我们的认知、坚守人类的价值观,并为此训练出了 InstructGPT。作为 GPT-3 的变体模型,其根据人类反馈接受了训练以确保遵循指令。有专家认为,该模型在多种语言基准上的表现均优于 GPT-3。
目前,GPT-4 的发布日期仍未确定。所以我们可能要到明年才能见其真容,也可能在下个月就迎来惊喜。但唯一可以肯定的是,下个版本一定能解决旧版本的某些问题,并带来更好的性能表现。
当然,目前已经出现了不少关于 GPT-4 且自相矛盾的传闻。比如说它有 100 万亿个参数,而且专门用于生成编程代码。但这些都是纯猜测,没有任何根据。我们不清楚的情况还有很多,毕竟 OpenAI 没有公布关于其发布日期、模型架构、大小和训练数据集的任何消息。
结束语
AI 模型开发领域,经历了预训练模型-大规模预训练模型-超大规模预训练模型的演进。Google 发布的 Bert 模型即是自然语言处理领域最为典型的预训练模型。OpenAI 则提出了 GPT 模型,尤其是 2020 年发布的 GPT-3 模型参数量达到 1750 亿,其在全球掀起大模型的浪潮。
根据 IDC 观察,国内大力投入大模型研发和落地的以大型云厂商为主。例如百度智能云推出了“文心大模型”,包括了 NLP 大模型、CV 大模型以及跨模态大模型等 36 个大模型;阿里达摩院则推出“通义大模型”系列,以 M6 大模型为底座,发布 Alice 一系列模型合集;华为则从框架层、算力层以及软件层面全面发力大模型,既有内部自主研发的盘古大模型,也开放华为昇思 MindSpore 框架支持业界进行大模型的训练。
随着市场对于大模型的认知逐渐理性和落地,使用大模型的价值也开始凸显,如不要求企业具备海量的数据基础、应用大模型的效果更优、降低 AI 开发门槛等。很多 AI 先行者已经在成熟度较高的场景中引入了大模型。
大模型为人工智能未来发展带来了全新的可能,未来将如何迸发出新的可能,我们拭目以待。
参考链接:




