
交通出行公司优步(Uber)详细介绍了他们在主流的分布式事件流平台 Apache Kafka 中添加新的分层存储功能的工作。该功能是在 Apache Kafka 3.6.0 中添加的,目前还处于早期访问阶段,旨在帮助运行大型 Kafka 集群的组织来解决可伸缩性和效率方面的挑战。
分层存储允许 Kafka 将其存储功能从本地的代理(Broker)磁盘扩展到远程存储系统上,如 HDFS、Amazon S3、Google Cloud Storage 和 Azure Blob Storage。这一增强使 Kafka 集群能够独立于计算资源而扩展存储,从而潜在地降低了成本和运维的复杂性。
根据 优步的博客文章,该项目的动机是为了克服 Kafka 集群通用扩缩方式的局限性。
“Kafka 集群存储通常通过添加更多的代理节点来进行扩缩。但这也会给集群增加不必要的内存和 CPU,与将旧的数据存储在外部存储中相比,总体的存储成本效率较低。”
他们补充道,由于存储和处理是紧密耦合的,具有更多节点的大型集群会增加部署的复杂性和运维成本。
分层存储架构引入了两个存储层:本地层和远程层。本地层由代理的本地存储组成,而远程层则是扩展的存储,如 HDFS 或云对象存储。这两个层都可以根据特定的用例来制定单独的保留策略。
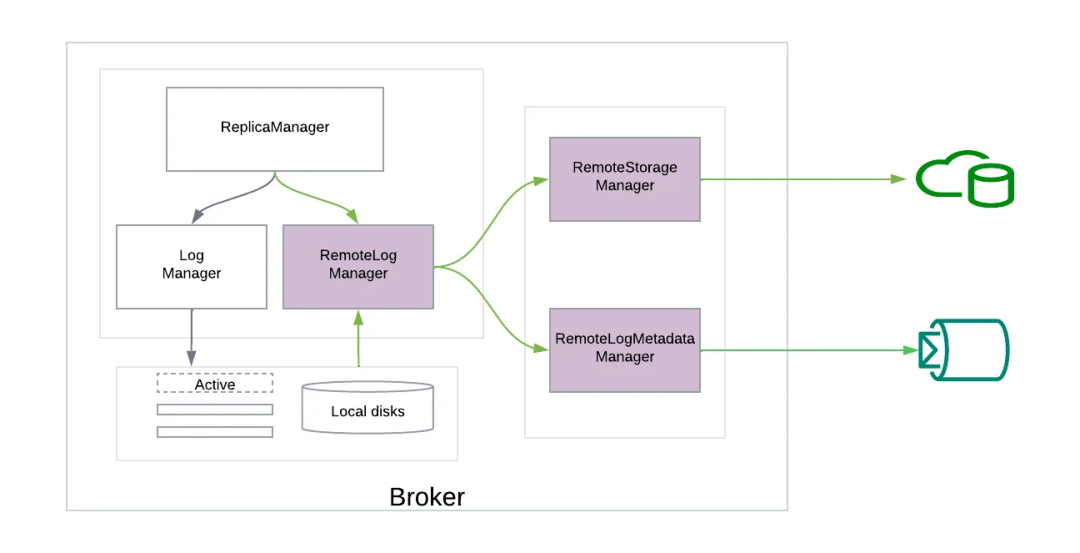
在对该功能的详细分析中,红帽公司(Red Hat)概述了它的优势:
弹性:计算和存储资源现在可以独立扩缩了。
隔离性:延迟敏感数据可以通过本地层提供,而历史数据则可以通过远程层提供,而无需更改 Kafka 的客户端。
成本效益:远程对象存储系统通常比快速的本地磁盘便宜,这使得 Kafka 的存储更便宜了,并且几乎不受限制。
分层存储系统的工作原理是将符合条件的日志段从本地复制到远程存储中。如果日志段的结束偏移量小于分区的最后一个稳定偏移量,则认为该日志段是符合条件的。充当主题分区领导者代理负责这一复制过程。
为了促进这一过程,优步在实施中引入了新的组件:
RemoteStorageManager:处理远程日志段的操作,包括从远程存储中复制、获取和删除。
RemoteLogMetadataManager:管理具有强一致性语义的远程日志段元数据。
RemoteLogManager:监督远程日志段的生命周期,包括复制到远程存储、清理过期段以及从远程存储中获取数据。
AWS 通过 Amazon Managed Streaming for Apache Kafka(Amazon MSK)分层存储进一步发展了这一概念。根据 AWS 在一篇博客文章中 的说法,该功能显著地提高了 Kafka 集群的可用性和弹性。撰写这篇文章的 AWS 工程师强调了如下的几个关键优势:
更快的代理恢复:通过分层存储,数据会随着时间的推移自动从更快的 Amazon Elastic Block Store(Amazon EBS)卷移动到更具成本效益的存储层。当代理发生故障并恢复时,追赶过程会更快,因为它只需要同步领导者(leader)存储在本地层上的数据。
高效的负载平衡:具有分层存储的 Amazon MSK 的负载平衡更高效,因为在重新分配分区时需要移动的数据更少。这种更快、资源消耗更少的流程可以实现更频繁、更无缝的负载平衡操作。
更快的扩缩:使用分层存储可以无缝扩缩 MSK 集群。无需进行大量的数据传输和更长时间的分区重新平衡,即可将新的代理添加到集群。
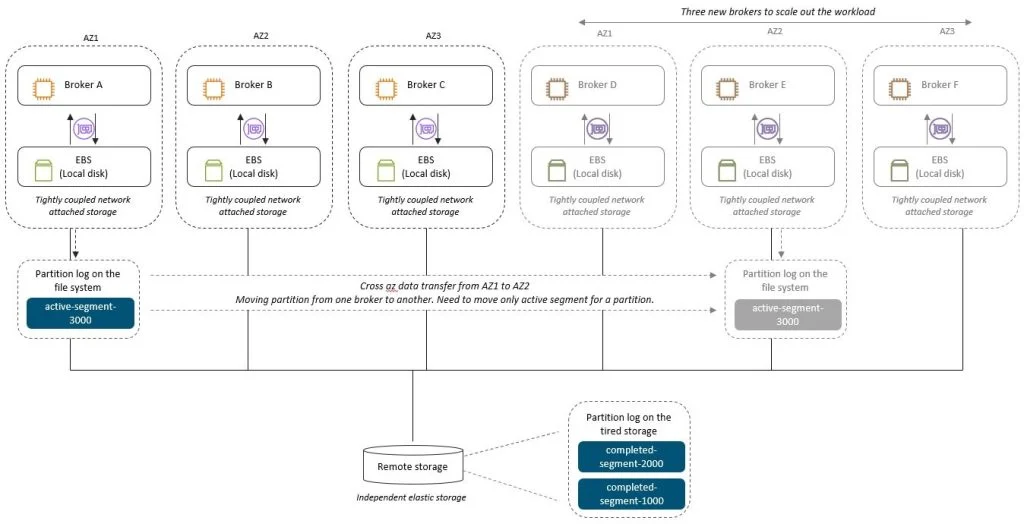
AWS 使用具有 m7g 实例类型的三节点集群进行了实际测试,以演示上述优势。他们创建了一个复制因子为 3 的主题,并提取了 300GB 的数据。当添加三个新代理并将所有分区从现有代理移动到新代理时,在没有分层存储的情况下,大约需要 75 分钟,并且会导致 CPU 使用率升高。在对同一主题启用分层存储后,本地保留期为 1 小时,远程保留期为 1 年,他们重复了该测试。这一次,分区移动操作在不到 15 分钟内即可完成,并且没有明显的 CPU 使用率提升。AWS 将这一改进归因于这样一个事实,即只有小的活动段需要在启用分层存储的情况下移动,因为所有关闭的段都已经转移到分层存储中了。
然而,只有一些业内人士对分层存储抱有同样的热情。WarpStream 的 Richard Artoul 提出了一个更为谨慎的观点,他认为虽然分层存储可以帮助降低成本,但它可能会引入新的复杂性和潜在的故障模式。Artoul 认为,管理两个存储层会增加复杂性,从而可能增加运维开销并影响系统的可靠性。
Artoul 引起了对从远程存储中获取数据的性能影响的关注,这可能会引入延迟并影响实时处理能力。他指出,分级存储节省的成本可能会与管理和访问远程存储系统中的数据相关的费用所抵消,特别是由于云环境中跨区域产生的网络费用。此外,Artoul 认为,分层存储需要解决用户目前在 Kafka 上遇到的两个主要问题:复杂性和运维负担,以及成本(特别是跨区域的网络费用)。他认为,分层存储可能会加剧而不是解决这些问题。
虽然分层存储具有潜在的优势,但需要注意一些当前的局限性。根据 红帽公司(Red Hat)的分析,该功能仍需要支持多个日志目录(JBOD)或压缩主题。此外,关闭主题的分层需要在删除原始主题之前将数据传输到另一个主题或外部存储中。
优步和红帽都强调了在使用分层存储时进行监控的重要性。引入了新的指标来跟踪远程存储操作,允许用户监控并创建潜在问题的报警,如上传 / 下载速度慢或错误率高。
优步已经将该功能在不同的工作负载上的生产环境中运行了 1-2 年,但它在开源 Apache Kafka 3.6.0 版本中,仍然被认为是早期访问版本。考虑采用该技术的组织应该仔细评估其当前的能力和局限性。
引入分层存储可能会使大规模数据流的管理更加高效且更具经济效益。正如 AWS 在 Amazon MSK 的实现中所展示的那样,在某些场景中,它可以显著地提高集群的弹性和可伸缩性。然而,Artoul 的批评则强调,该特性可能只是一些 Kafka 用户的灵丹妙药。与其他任何新特性一样,特别是在早期访问阶段,建议用户在部署到生产环境之前,先在其特定的环境中进行彻底的测试并监控其性能,需要在其潜在的好处和增加的复杂性及运维挑战之间进行权衡。
作者介绍
Matt Saunders 通过 Adaptavist Group,帮助团队使用 DevOps 流程和工具快速高效地交付质量可靠的软件,同时最大程度地减少压力。他曾与大型的企业、小型初创企业、中小企业以及介于两者之间的所有企业合作过。同时他还管理着伦敦 DevOps 聚会小组,该小组有超过 1 万名成员,每月搜会举办一次非常受欢迎的行业活动。
原文链接:
https://www.infoq.com/news/2024/08/apache-kafka-tiered-storage/




