
引言:还记得 3 月 18 日,马斯克开源 Grok 的那一刻吗?如今,Grok 1.5 即将登场,其卓越的编码与数学处理能力、更深入的上下文理解(可处理高达 12.8 万 Tokens)以及更精准的长文本检索能力,令人震惊。马斯克就是马斯克,这速度,何尝不让人叹服。Grok-1.5 在未来几天即将在 X 上与开发者见面。
Grok-1.5 登场
当地时间 3 月 28 日,马斯克发布了 Grok-1.5,这是一个具有前所未有的长上下文支持和高级推理能力的新型人工智能模型。Grok-1.5,作为该系列的最新版本,预计将在未来几天向早期测试者和 X 平台的现有用户开放。借助于两周前公开的 Grok-1 模型权重和网络架构,该团队展现了至去年 11 月为止的技术成就,并自那以后在推理及问题解决方面取得了显著进展。
能力与推理
Grok-1.5 最显著的改进之一,就是更强大的编码与数学相关任务性能。在团队的实验中,Grok-1.5 在 MATH 基准测试上取得了 50.6% 的得分,在 GSM8k 基准测试上取得了 90% 得分——这两项数学基准测试涵盖从小学到高中的各类竞赛问题。此外,Grok-1.5 在评估代码生成与问题解决能力的 HumanEval 基准测试中得分为 74.1%。
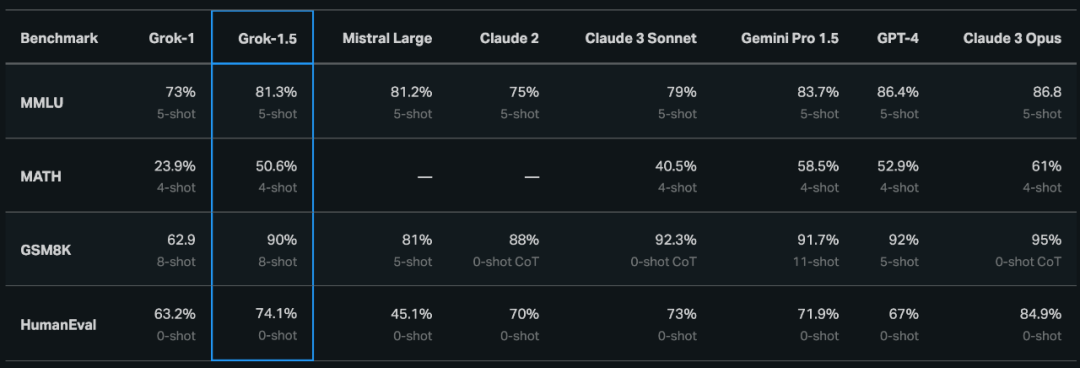
长上下文理解能力
Grok-1.5 中的另一项新功能,就是在上下文窗口中处理多达 128K 个 tokens。这使得 Grok 的记忆容量增加至前代上下文长度的 16 倍,因此能够消化大部头文档中的信息。
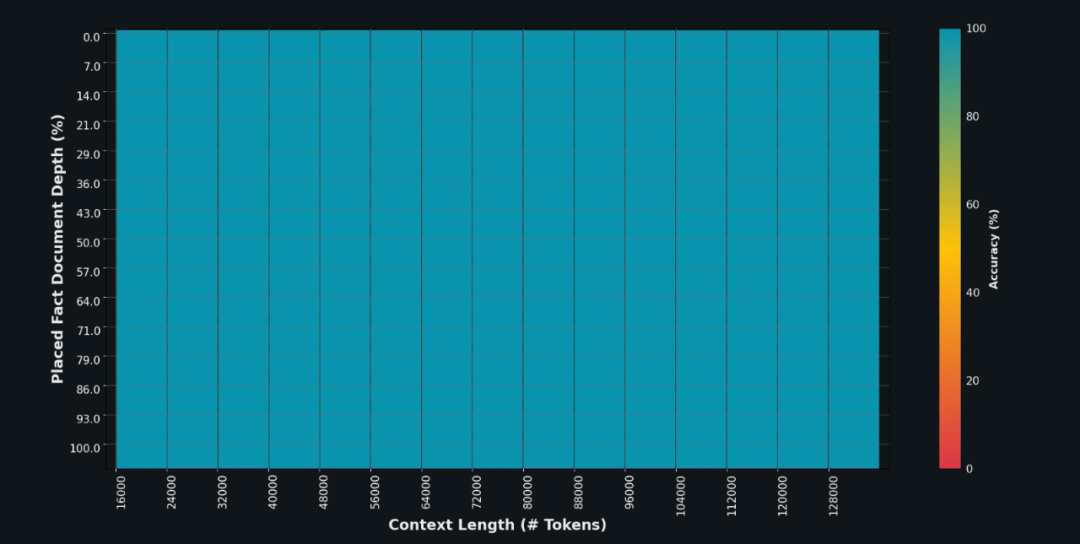
此外,Grok-1.5 模型还可处理更长、更复杂的提示词,在上下文窗口扩展的同时保持其指令跟踪能力。在 Needle In A Haystack (NIAH) 评估中,Grok-1.5 展示出强大的检索能力,可以在多达 128K tokens 的长上下文中嵌入文本,实现完美的检索结果,仅从从文本长度来看,Grok-1.5 可真的跨越极其之大,是 GPT-4 的 16 倍。
那么这么强的模型是如何训练的呢?一起来看看 Grok-1.5 的基础设施。

在大规模 GPU 集群上运行领先大语言模型(LLM),自然离不开强大而灵活的基础设施。Grok-1.5 以基于 JAX、Rust 和 Kubernetes 的自定义分布式训练框架为基础,这套训练堆栈使 Grok 团队能够以最小的投入建立起设计原型,并大规模训练新型架构。
在大型计算集群上训练大模型的核心挑战,在于如何最大限度提高训练作业的可靠性与正常运行时间。Grok 团队自定义训练的协调器能够自动检测到有问题的节点,并将其从训练作业中剔除。团队还优化了检查点、数据加载与训练作业重新启动等机制,尽一切可能减少由故障引发的意外停机。
Grok 1.5 VS “最强”开源大模型 DBRX
目前,Grok 团队并未表示 Grok-1.5 是否开源,但从马斯克在与 OpenAI 的官司中推测,Grok-1.5 大概率是要开源的,否则有“知行不一”嫌疑。
当前的开源大模型市场竞争也是非常激烈的,Meta、Mistral 等已经处于前沿,但市场变化也非常快。当地时间 3 月 27 日,美国的 AI 创业公司 Databricks 以“黑马”之姿宣布,其 Mosaic Research 团队开发的全新通用大模型 DBRX 将被开源。这一消息由 DBRX 项目的首席神经网络架构师 Jonathan Frankle 在确认测试成果后宣布,他自信地告诉团队:“我们已经超越了市场上所有现有的模型。”一些测试成绩如下图所示:
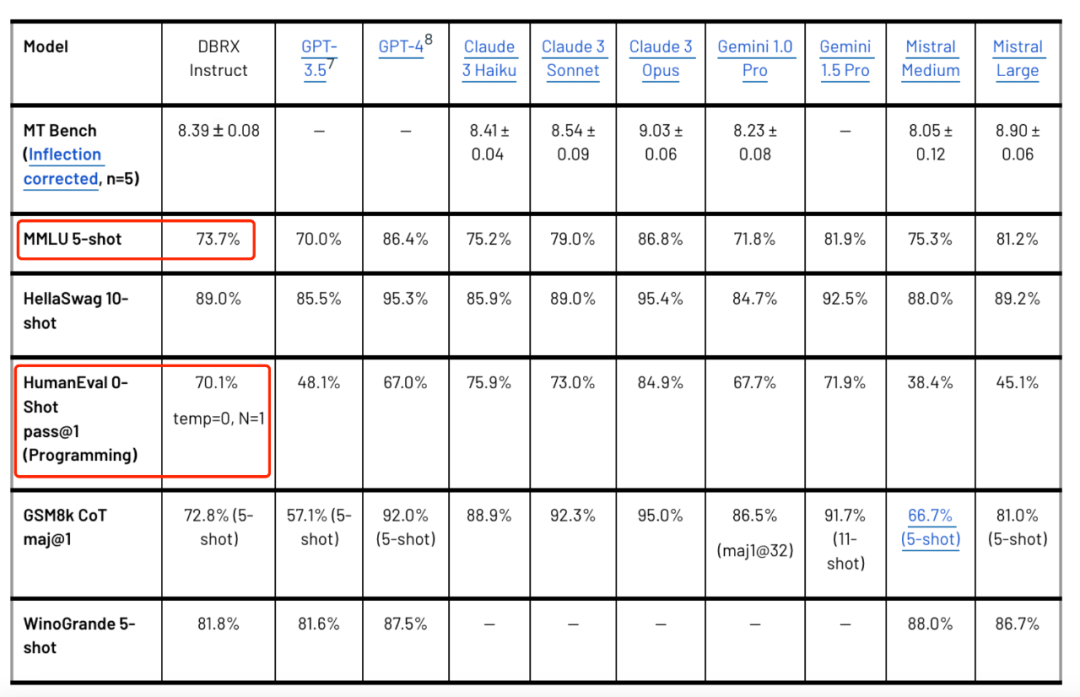
DBRX 在多项关键测试中的表现亮眼。在语言理解的 MMLU 测试中,DBRX 取得了 73.7% 的得分;而在代码生成能力的 HumanEval 测试中,得分为 70.1%。
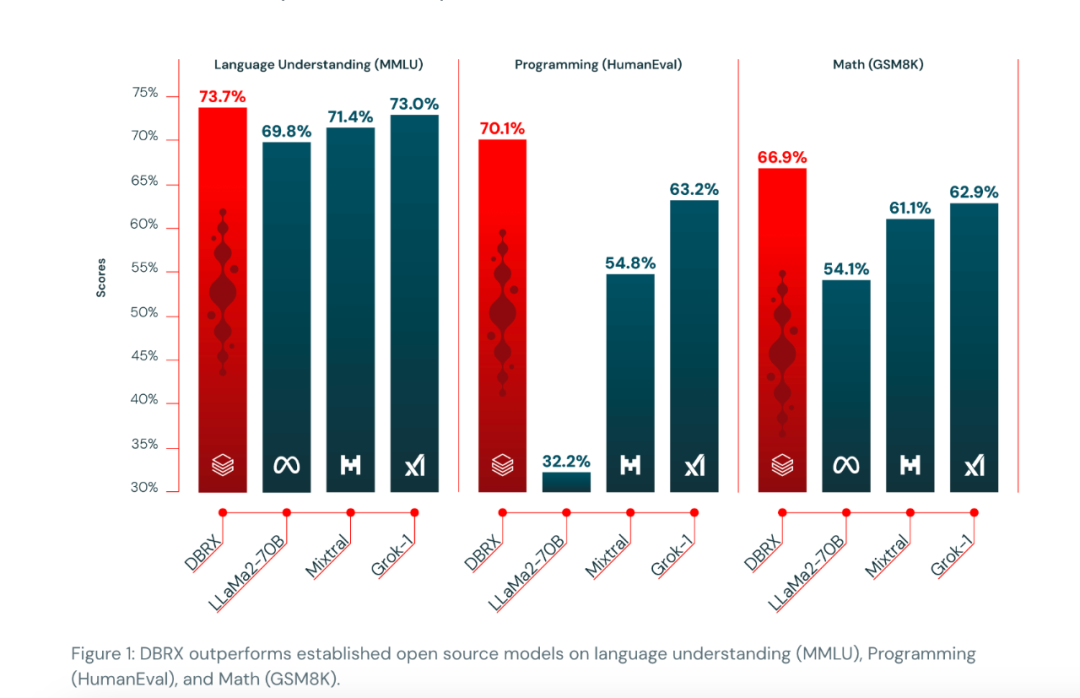
此外,DBRX 在数学问题解决能力上的表现也十分出色,在 GSM8k 测试中获得了 66.9% 的成绩,这些结果表明 DBRX 在编程方面的能力甚至超过了专业模型如 CodeLlaMa-70B。
但是,也仅仅就是一天之后, Grok 1.5 宣告发布,想较于“最强”开源大模型 DBRX,Grok 1.5 表现更为亮眼。假使大家测试都不作弊, Grok 在 MMLU 测试中以 81.5% 的得分领先,HumanEval 测试中以 74.1% 的得分胜出,并在 GSM8k 测试中以 90% 的惊人得分远超 DBRX 的 66.9%。另外在长文本上,Grok 1.5 上下文窗口中处理多达 128K 个 tokens,远超于 DBRX 32K。
当然,这只是测试数据集的表现,不能完全说明实际情况,但是,测试集上表现好肯定也是优势。
开发者对 Grok 1.5 的热切期待
对于 Grok-1.5 的突然发布,有网友表示,来自 Grok-1.5 的测试图表给人留下深刻印象。它在信息检索方面,其表现与 Claude-3-Opus 和 GPT-4-Turbo 相媲美。迫不及待想要试一试了。
网友们对 Grok1.5 的热情洋溢在每一条评论中:“太棒了,这真是令人激动的进展!”随着新功能的即将推出,兴奋之情溢于言表。“我们能了解到网页界面发布的时间表吗?我在澳大利亚迫不及待地期待它的到来。”“请不要忘了智利!即使是 Grok 的 1.0 版本,对西班牙语的支持也已经相当出色了!”
也有网友认为,马斯克除非拥有 10 倍的优势,否则也难以在开源大模型的竞争中取胜。
当然,值得注意的是,马斯克曾表示,X 平台将向更多用户开放 Grok 聊天机器人的访问权限,特别是对于那些已经订阅了每月 8 美元高级计划的用户。这一价格,与每月需要 19.99 美元才能使用的 GPT-4 和每月 28.99 美元的 Gemini Advanced 相比,显著更加经济。
另外,从历史上看,X.ai 的 Grok 模型与其他生成式 AI 模型的不同之处在于,它们回答了其他模型通常无法触及的主题问题,例如阴谋和更具争议性的政治思想。更大胆,更自由。
结语
GPT-4 已经与我们相伴超过一年,而 Gemini 1.5 几个月前亮相,Claude 3 仅数周前登场。昨天发布的开源大模型 DBRX 宣称超越了当前所有大型模型,结果今天就被 Grok 1.5 在一些细分方向超越。究竟哪个模型将在未来占据领先地位?虽然尚未可知,但毫无疑问,我们正处在人工智能发展的黄金时代,我们非常幸运。
参考链接:
https://mp.weixin.qq.com/s/eWsCDWquA0r26NodKlu5bA
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
https://techcrunch.com/2024/03/28/xs-grok-chatbot-will-soon-get-an-upgraded-model-grok-1-5/
内容推荐
大模型应用挑战赛已拉开帷幕。现阶段,多数语言模型已完成 3 轮更新,大模型赛道入场券所剩无几。同时,2023 年超 200 款大模型产品问世,典型场景又有哪些产品动向?对于现阶段的文生图产品而言,四大维度能力究竟如何?以上问题的回答尽在《2023 年第 4 季度中国大模型季度监测报告》,欢迎大家扫码关注「AI 前线」公众号,回复「季度报告」领取。

今日荐文
************你也「在看」吗?************👇




