
在我们看来,目前许多公司全力投入 Kubernetes 都是没有意义的,但选择权在他们。如果你读到了这篇文章,而且你所在的组织目前正在设法确定自己有多需要 Kubernetes,那么我希望本文的观点可以帮助你的团队做出正确的决定。
本文最初发布于 Ably 工程博客,由 InfoQ 中文站翻译并分享。
前言
在 Ably,我们运行着一个大规模的生产基础设施,支撑着 Ably 全球客户的实时消息应用程序。和大多数科技公司一样,这个基础设施在很大程度上是基于软件的;这些软件大部分是部署并运行在 Docker 容器上的,这也和大多数科技公司一样。
如果你一直在关注技术领域,那么你可能会想到,下面这个问题经常会有人问:
“那么……你们用 Kubernetes 吗?”
我们当前的客户,我们潜在的客户,对我们平台感兴趣的开发人员,应聘Ably 职位的人,都问过这个问题。我们甚至还碰到过一些有趣的应聘者,他们放弃我们提供的职位,理由是我们没有使用 Kubernetes。
在规划基础设施长期路线图时,我们也问过自己这个问题:我们应该在某个时候将 Kubernetes 作为主要的部署平台吗?
为什么选择 Kubernetes?
Kubernetes 是最知名的容器化软件大规模编排系统。虽然存在不同的声音,但在很大程度上,它仍然处在炒作周期的顶峰——你经常会觉得每个人都在 Kubernetes 上运行软件,或者至少最近听人说,他们希望将所有东西都移到 Kubernetes 上。Mesos 的流行度迅速降低,Docker Swarm 也是少说为妙,而如果你还在往普通的 EC2 实例上部署,那不如索性用穿孔卡得了。
Kubernetes 有很多优点。它是由一些具有大规模生产负载经验的工程师开发的,而且是在现实世界中经过谷歌 Borg 编排系统证明了的技术。它获得了供应商持续不断的支持,现如今,你不会发布一款软件产品而不提供官方 Docker 镜像和 Kubernetes 部署指南。
多少有点令人惊讶的是,Kubernetes 从其灵感来源 Borg 继承下来的东西已经所剩无几,即将一个大型裸金属机器池变成一个私有云环境。现如今的大多数 Kubernetes 部署似乎都是在虚拟机上,而这些虚拟机多数时候是在公有云提供商那。公有云是现在许多组织部署 Kubernetes 的动因;它被视为一个统一的 API 层,使多云部署对 DevOps 人员透明。
即使在一朵云中,这种 Kubernetes 开发体验也经常被提及。开发人员已经习惯使用 Docker 了,而 Kubernetes 可以让相同的容器轻松在生产环境中运行。此外,借助命名空间、内置资源管理以及内置的虚拟网络特性,或服务网格,或两者兼而有之,它还允许部署由不同团队维护的多个交互式任务,并且彼此互不影响。
Ably 用什么来代替 Kubernetes?
Ably 是一个公有云客户。我们的整个生产环境都在AWS 上,目前没有其他地方。我们运行在 EC2 实例上。一天之中,机器总数是自动变化的,但不管怎么变化,总数至少也有几千台,分布在 10 个 AWS 区域。这些机器确实是在运行 Docker,我们的大部分软件也是部署在容器中的。
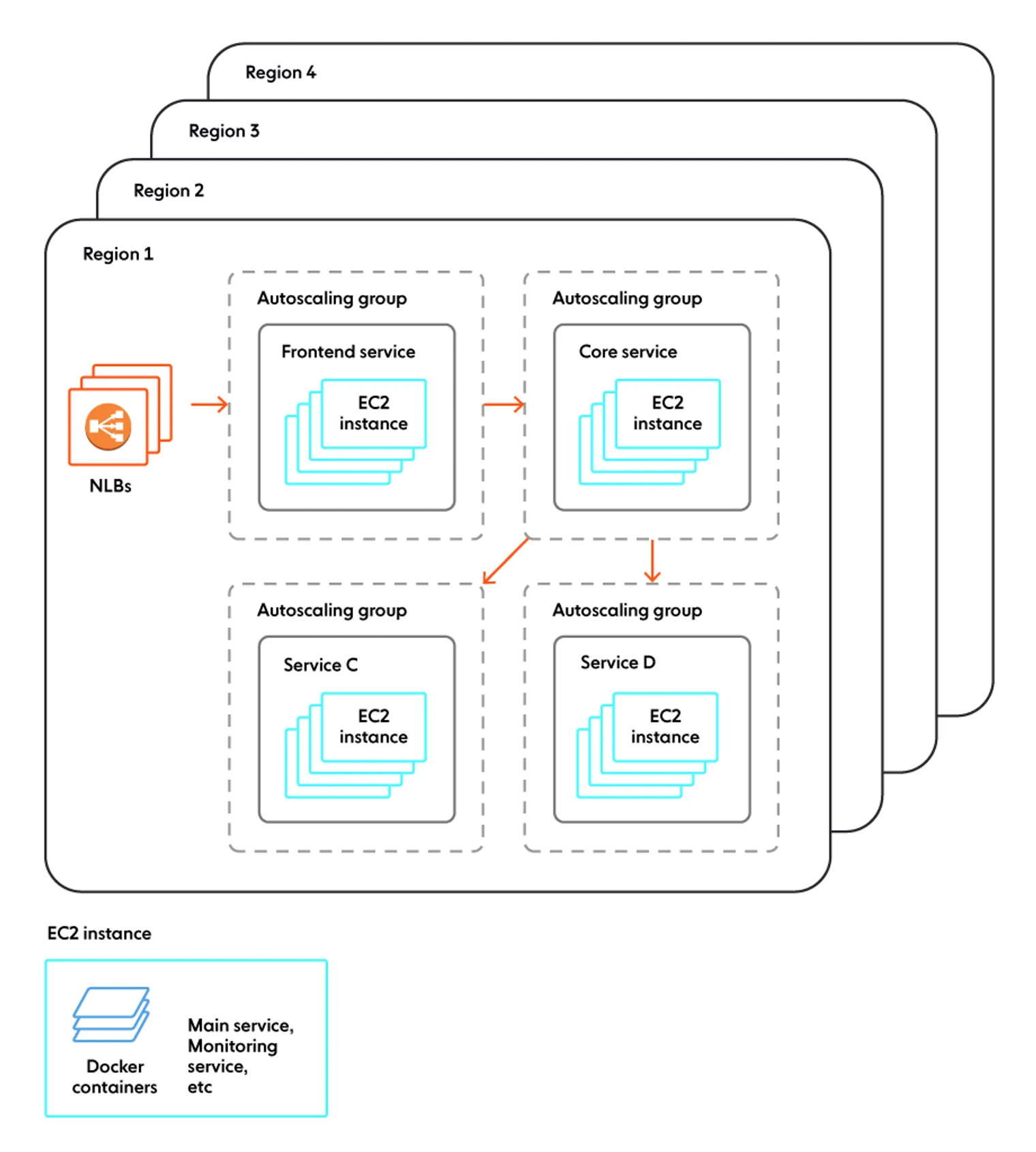
我们没有使用任何知名的运行时编排层。在创建时,根据所在的自动缩放组,每个实例就已经知道自己运行哪个容器。每个实例上都有一个小小的自定义引导服务,这是引导镜像的一部分,它会查找实例配置,拉取合适的容器镜像,并启动容器。
容器集在实例的生命周期里都不会变。不会有一个调度服务将一个实例从“核心”转成“前端”或其他类型的实例:要改变集群的结构,实例会整体创建或销毁,而不是让它们运行一组不同的容器。每个实例上都有轻量级的监控服务,如果一个容器死掉,它会将其复活,而如果一个实例运行了任何集群不再需要的软件版本,那么它会将其终止。
对于进入的流量,我们使用AWS 网络负载均衡器。由于一个缩放组对应一个生产服务,所以我们可以使用常规的 AWS 方法,将一个 NLB 指定到一个缩放组作为目标组,不需要额外的抽象层。
对于内部服务间通信,或者是作为“服务网格”(你愿意的话),我们使用……网络。由于机器上的服务不是任意混在一起的,所以机器自动分配 IP 地址对于我们来说已经完全足够了。
不用 Kubernetes 为什么还要用 Docker?
不管怎样,Docker 仍然是一种非常方便的软件部署格式,尤其是在使用依赖项很多的语言(Node、Python、Ruby……)编写时。在这些情况下,可部署单元是一个复杂目录树下的成千上万且相互依赖的文件,再加上一个执行运行时,而且该运行时的版本必须是与源树快照相对应的版本。
我们以前是通过简单的 tar 包分发软件构建(和 Heroku 一样,我们称之为 slug),每个实例上的管理服务会下载并解压。从功能上讲,我们现在做的还是一样的事,因为实际上,Docker 镜像只是一组 tar 包和与之绑定的 JSON blob 元数据,但 curl 和 tar 被 docker pull 所取代。
(并不是工程团队中的每个人都认为这是一项改进,但关于这一点,我们会在后续的博文中讨论。)
这种设置够灵活吗?
资源管理
在资源管理方面,我们可以根据服务的需求确定要使用的 EC2 实例类型。我们不需要知道如何将较小的服务打包到较大的实例上。关于如何将小型 VM 打包到大型物理机上,亚马逊的经验至少比我们多 10 年,因此,还是由他们处理那些细节吧。
这就是Right Sizing:大多数服务只能有效使用一定数量的资源。一个有两个线程的进程不需要 16 颗 CPU;一个一分钟写一次盘的进程不需要每秒可以完成 9 万次写操作的 SSD 存储;亚马逊提供的 CPU 架构选项可以带来最高性价比。从众多 AWS 服务中选择合适的组件可以帮助我们尽可能缩减开销,控制成本,最终降低客户的每条消息费率。
自动缩放
EC2 实例组知道如何自动增加或减少组中实例的数量来满足需求。可用的工具和 Kubernetes 类似。显然,我们针对 AWS 所做的设计并不能直接在其他云提供商那里使用,但那时我们没有使用任何其他云提供商。
当然,我们还是可以手动管理容量。每个缩放组中的期望实例数随时都可以手动设置,设置完成后,自动缩放策略会再次接管这项工作,根据系统负载增加和减少实例数量。
我们向客户收费是根据他们实际使用服务的情况。任何针对冗余容量的预算都要我们自掏腰包,因此,我们要尽可能地提高资源利用率,同时又要为我们的客户提供良好的服务级别,即使是在出现意外峰值负载的情况下。
流量入口
如果撇开我们遇到的实现 Bug 不谈,那么流量入口在所有主流云提供商那里都是一个已经解决了的问题 。也就是说,你可以持续地将接收外部流量的服务映射到运行该服务的机器集上。
客户流量既可以直接到达 NLB,也可以先绕道 CloudFront。在运行在每个区域中的服务看来,这没什么区别。
无论何种情况,在每个区域中都使用一个负载均衡器是实现横向可扩展性和灵活性的另一种方法——可以应对连接数出现重大变化的情况,如大型体育赛事开幕时吸引了数十万甚至更多的观众。
DevOps
为了确保我们的工程师可以有意义地参与到我们生产系统的管理,开发人员可以设置一个配置值——“该集群现在可以运行这个组件的这个版本,谢谢”——随着时间推移,该服务的所有实例都将被运行新版本的实例所代替。
使用 Kubernetes 的话,情况如何?
如果将生产环境迁移到 Kubernetes 上,我们的环境和进程会有什么变化(希望是有所改进)。
由于我们的基础设施团队规模有限,所以唯一值得考虑的选项就是与 AWS 完全集成的托管 Kubernetes。我们的产品需要全球部署,我们至少需要 10 个集群(每个区域一个)。
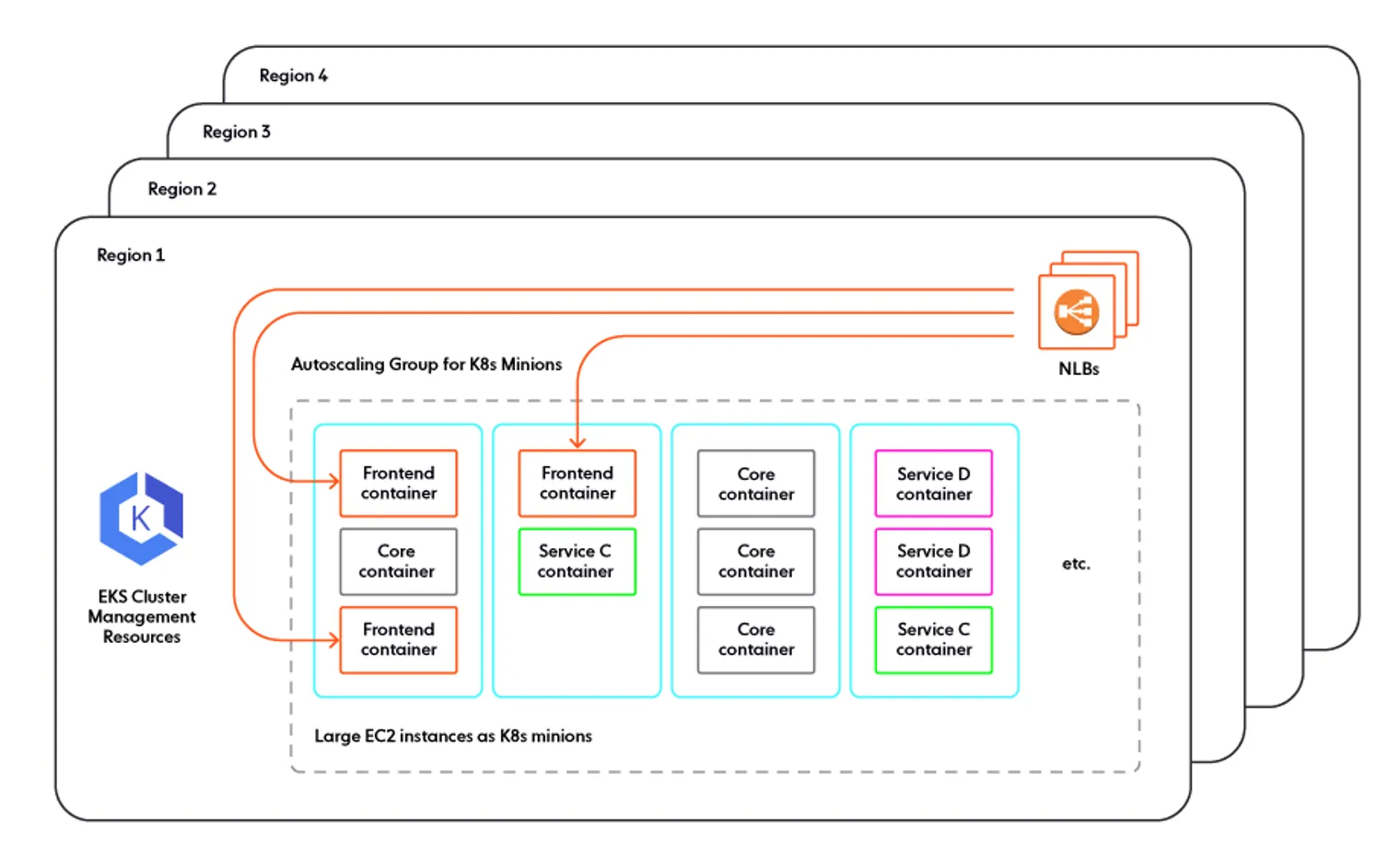
资源管理
当通过 Kubernetes 管理资源时,我们不是针对每个服务使用大小适中的 EC2 实例,而是使用大实例(.metal 类的一种,也许是最大的),并将它们用容器打包。
打包服务器有个小优点,就是可以使用现有服务器上的空闲资源,而不必为资源需求不大的服务额外分配机器。但这也有一个很大的缺点,就是在同一台机器上运行异构服务,导致资源竞争。这不是什么新问题:云提供商在使用虚拟机时也面临同样的问题,即“吵闹的邻居”。不过,云提供商的系统中有 10 几年积累下的秘密武器,可以在最大程度上为客户减轻这个问题。但在 Kubernetes 上,你得自己解决所有问题。
一种可能的方法是设法在使用 Kubernetes 时保留“一个虚拟机,一个服务“模型。Kubernetes minions 不必都相同,它们可以是不同大小的虚拟机,Kubernetes 的调度条件可以确保每个 minion 只运行一个逻辑服务。这样就有一个问题:如果要在特定的 EC2 实例组上运行特定的容器集,为什么还要有一个 Kubernetes 层,而不直接那样做?
自动缩放
在使用 Kubernetes 时,服务的自动缩放看上去也很类似:暴露一个自定义的“当前使用率”指标,然后设置规则根据需要增加或移除容器。当然,只有在集群节点上还有容量时,Kubernetes 集群才能启动额外的服务 pod。这样说来,我们在部署时就需要留下相当数量的空闲容量,并添加Cluster Autoscaler 来根据需要增加节点。
对于 Cluster Autoscaler 来说,向上扩展集群相当简单——“当空闲容量低于期望值时增加节点”。不过,收缩集群就比较复杂了:可能你最终找到了最空闲的节点,但不是空节点。这就需要把剩余的 pod 迁移到其他节点上,腾空这个节点后再停止该节点,完成集群收缩。
关于自动缩放,我们的结论是,工作方式和现在类似,但我们要解决两个自动缩放问题,而不是一个,而且这两个问题都比我们现在要解决的问题更复杂。按需或按计划容量管理(需人工干预)都更复杂一点,因为我们必须首先保证有足够的 Kubernetes 节点,只有那样才有足够的 pod 来提供所需的服务。
流量入口
使用 Kubernetes 时,流量入口就非常简单了。EKS 团队提供了一些非常值得称道的设计选项:如果集群那样配置,每个 pod 都会收到一个 AWS 托管的 IP 地址,该地址与 EC2 的虚拟网络层 VPC 完全集成。在集群内运行的东西可以直接访问这些 IP,运行在 AWS 上同一个 VPC 族内但不在集群里的东西,则需要通过 AWS 提供的两种虚拟负载均衡器访问。
当在服务的 Kubernetes 规范中添加 Ingress 或 Service 小节时,有一个控制器会自动创建 AWS 负载均衡器,并将它们直接指向对应的 pod 集。总的来说,这不会比我们现在暴露流量路由实例的方式更复杂。
当然,这里有一个隐藏的缺点,就是这种出色的集成完全是 AWS 特有的。因此,如果你想在多云环境下使用 Kubernetes,这就不是很有帮助了。
DevOps
在 Kubernetes 的世界中,软件版本管理和我们现在的方式非常类似。现在,我们是在自定义配置系统中指定一个新的目标版本,所有 EC2 实例会自动滚动替换,使用 Kubernetes 的话,我们需要在Kubernetes Deployment 中指定一个新的目标版本,然后 pod 会滚动替换。
但是还有其他好处吗?
总的来说,我们做的事基本不变,但做法更复杂了。在探讨如何移植现有的基础设施时,如果在 Kubernetes 上运行能提供其他我们没有考虑到的好处,那或许值得这样做。让我们看下人们经常提到的 Kubernetes 的其他优点,看看它们对我们是否有帮助。
多云就绪
我们发现自己属于“不应该”的那部分,当前也就没有执行这样的战略。我们并不是完全赞成,Kubernetes 是达成这一战略的好方法。当服务需要访问集群外的服务时,或者需要从集群外访问时,或者使用某种持久化存储时,不同的主流云提供商之间确实存在差别,而 Kubernetes 并不足以完全屏蔽这种差异,让开发完全不用考虑。
如果你仍然需要一个 Kubernetes on AWS 部署策略,以及另一个相似但不同的 Kubernetes on GCP. 部署策略,那么与不使用 Kubernetes 相比,采用两个相似但不同的 AWS 和 GCP 部署策略不是会困难许多吗?
混合云就绪
在我们看来,管理混合云或内部环境(或者换个说法,管理你自己的物理机)是一个部署 Kubernetes 的有效理由。无独有偶,这也是 Borg 的设计初衷。如果我们已经计划好建设自己的物理数据中心,而不是购买公有云资源,我们将在其中安装的几乎可以肯定是裸机 Kubernetes 集群。
还有一个选项是设法基于虚拟机构建私有云,许多组织选择了这种方式。不过,根据已有的经验,构建那种环境绝不是一个实惠或简单的选项。我们还没有准备好创建自己的数据中心。要等到我们的业务翻几番,拥有自己的硬件所带来的好处值得我们在工程部门保有一个物理基础设施小组。
基础设施即代码
基础设施即代码是我们已经在做的工作,用了CloudFormation 和Terraform 以及我们自定义的工具。编写 Kubernetes YAML 文件并不是管理“基础设施即代码”的唯一方式,在许多情况下,也不是最合适的方式。
有一个很大而且很活跃的社区
使用 Kubernetes,人们常说的一个好处是,有一个很大的用户社区可以分享问题和建议。但是,并不是运行了 Kubernetes 才能参与到这个由用户和开发者组成的庞大社区。云计算还涉及许多其他的方面,我们积极参与了其中许多社区。AWS 用户的技术社区比 Kubernetes 开发者和用户社区更大,也有相当大的重叠。我们部署的许多其他技术,如 Cassandra,也非常流行。我们并没有因为身处 Kubernetes 社区之外而感到孤单。
一个让人更不愿意承认的事实是,在许多情况下,产品庞大而且发展迅速的用户社区并没有什么实际的帮助。Ably SRE 有多名工程师之前曾在 Kubernetes 团队工作,他们发现,数量庞大的初学者使得他们很难就 Kubernetes 相关的问题找到有用的信息。许多人使用 Kubernetes,但根据我们的经验,很少有人对它有深入的了解,因此,对于这样一个拥有庞大用户群体的东西,通过社区解决问题比你想象的要难得多。
大量的供应商涌入这一领域,造成了严重的技术搅动,为了适应新出现的第三方插件,Kubernetes 的核心特性频繁增加或变化。一个庞大而活跃的社区既是一种祝福,也是一种诅咒。
Kubernetes 的附加成本
复杂性。迁到 Kubernetes,组织需要一个完整的工程团队才能保证 Kubernetes 集群的运行,这还是假设使用的是托管 Kubernetes 服务,而且要有其他基础设施团队工程师维护上面的其他支持服务以及组织实际的产品或服务。
例如,上面提到的那些做得很好的 AWS EKS 网络和流量入口服务。那不是 EKS 自带的。你需要创建一个 EKS 集群,然后在上面安装并配置那些服务。然后还有一些其他的服务。
如果我们沿着服务提供商提供的道路走下去,那显然可以减轻我们的工作,但那是有代价的。我们前面提到过这样一个生机勃勃的市场所造成的技术搅动,因此,从一个供应商转到另一个供应商远非易事。选择供应商并不是一件轻巧的事,那本身就是一种架构承诺。
这个问题并不是只有 AWS 提供的托管 Kubernetes 才有——整个行业都是如此。重点不是 EKS 团队的工作不够出色,而是说,即使真有一个维护得很好的托管 Kubernetes 设置,也仍然需要做很多工作才能将其从一个基本的集群变成一个可以可靠运行服务的生产环境。
小结
虽然我们知道 Kubernetes 是一个设计得很好的产品,但我们目前没有使用它,或者说没有计划使用它。不是说部署 Kubernetes 没意义,只是说到目前为止,对我们来说没意义。
在经过仔细的成本收益评估后,我们发现,引入这样一个成本高昂的组件并不能真正解决我们的问题,而只是将问题转移到了其他地方。
在我们看来,目前许多公司全力投入 Kubernetes 都是没有意义的,但选择权在他们。如果你读到了这篇文章,而且你所在的组织目前正在设法确定自己有多需要 Kubernetes,那么我希望自己的观点可以帮助你的团队做出正确的决定。
和其他任何组织的系统一样,我们的生产系统无疑也存在问题和技术债务。我们有一个改进清单,我们也会额外招聘工程师来帮助我们实现这些改进。不过,归根结底,“迁移到 Kubernetes ”不在这份清单上。
查看英文原文:No, we don’t use Kubernetes




