
人工智能顶级会议 AAAI 2021 将于 2 月 2 日-9 日在线上召开,本次会议,华为云 AI 最新联邦学习成果“Personalized Cross-Silo Federated Learning on Non-IID Data”成功入选。这篇论文首创自分组个性化联邦学习框架,该框架让拥有相似数据分布的客户进行更多合作,并对每个客户的模型进行个性化定制,从而有效处理普遍存在的数据分布不一致问题,并大幅度提高联邦学习性能。该框架已被集成至华为云一站式 AI 开发管理平台 ModelArts 联邦学习服务中。
背景介绍
联邦学习机制以其独有的隐私保护机制受到很多拥有高质量数据的客户青睐。通过联邦学习,能有效地打破数据孤岛,使数据发挥更大的作用,实现多方客户在保证隐私的情况下共赢。但与此同时,在实际应用中各个客户的数据分布非常不一致,对模型的需求也不尽相同,这些在很大程度上制约了传统联邦学习方法的性能和应用范围。为此, 在客户数据分布不一致的情况下如何提高模型的鲁棒性成为了当前学术界与工业界对联邦学习算法优化的核心目标,也就是希望通过联邦学习得到的模型能满足不同客户的需求。
传统的联邦学习的目的是为了获得一个全局共享的模型,供所有参与者使用。但当各个参与者数据分布不一致时,全局模型却无法满足每个联邦学习参与者对性能的需求,有的参与者甚至无法获得一个比仅采用本地数据训练模型更优的模型。这大大降低了部分用户参与联邦学习的积极性。
为了解决上述问题,让每个参与方都在联邦学习过程中获益,个性化联邦学习在最近获得了极大的关注。与传统联邦学习要求所有参与方最终使用同一个模型不同,个性化联邦学习允许每个参与方生成适合自己数据分布的个性化模型。为了生成这样的个性化的模型,常见的方法是通过对一个统一的全局模型在本地进行定制化。而这样的方法仍然依赖一个高效可泛化的全局模型,然而这样的模型在面对每个客户拥有不同分布数据时却是经常可遇而不可求的。
为此,华为云 EI 温哥华大数据与人工智能实验室自研了一套个性化联邦学习框架 FedAMP。该框架使用独特的自适应分组学习机制,让拥有相似数据分布的客户进行更多的合作,并对每个客户的模型进行个性化定制,从而有效地处理普遍存在的数据分布不一致问题,并大幅度提高联邦学习性能。下面我们来具体看下这一新的框架 FedAMP 是怎么提升联邦学习性能的。
论文地址:https://arxiv.org/abs/2007.03797
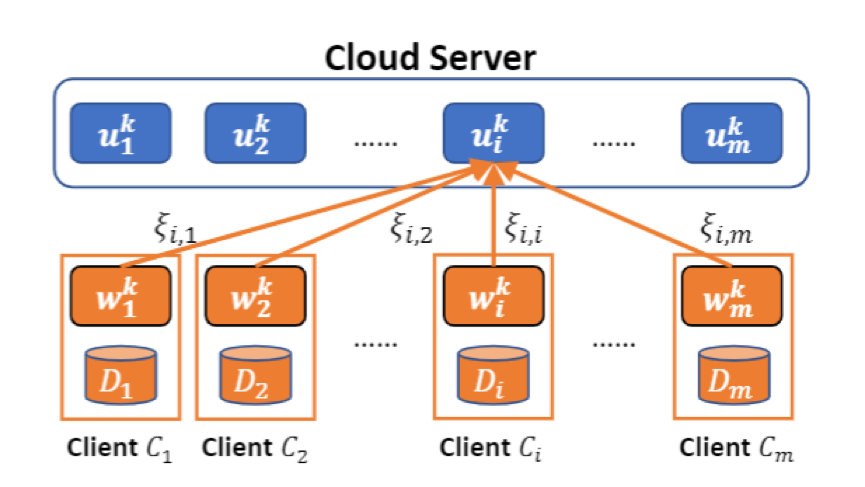
图一: FedAMP 的注意消息传递机制
算法介绍
在这个新的联邦学习框架 FedAMP 中,作者首先引入了一种新颖的注意消息传递机制(Attentive message passing mechanism)。如图一所示,这种机制允许每个客户在拥有本地个性化模型, 同时在云端维持一个个性化的云端模型。FedAMP 通过计算本地个性化模型两两之间的相似度来实现注意消息传递机制,从而使云端可以利用注意消息传递机制聚合本地个性化模型,得到云端个性化模型, 然后再通过本地个性化训练拉近本地个性化模型与云端个性化模型之间的距离。

图二:FedAMP 伪代码
基于上述描述,图二给出了 FedAMP 伪代码。不难看出,在 FedAMP 的迭代中实现了一种正反馈循环,即拥有相似模型参数的客户将逐步形成越来越紧密合作。这样的合作将自适应地隐性地将相似的客户组合起来并因此形成更为高效的合作。
文章在此基础上给出了 FedAMP 框架的收敛性证明,并进一步针对深度学习网络提出了一套启发式个性化联邦学习框架 HeurFedAMP。
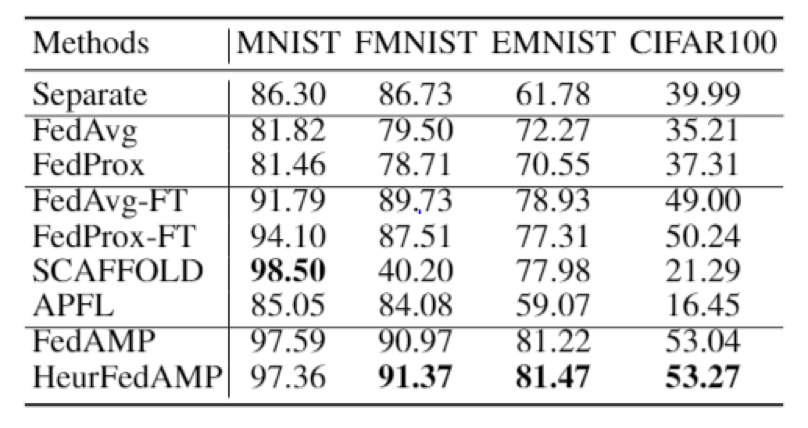
图三:最优平均测试准确率
结果展示
为了评估 FedAMP 及 HeurFedAMP 的性能,作者设计了一套更为符合实际应用场景的非均匀数据分布。如图三所示,FedAMP 及 HeurFedAMP 在四个常见数据集上展示了比现有七种 SOTA 算法更高的最优平均测试准确率。相比 Google 提出的原始联邦学习框架 FedAvg,FedAMP 及 HeurFedAMP 所获得的最优平均测试准确率更是大幅提升,表现非常亮眼。
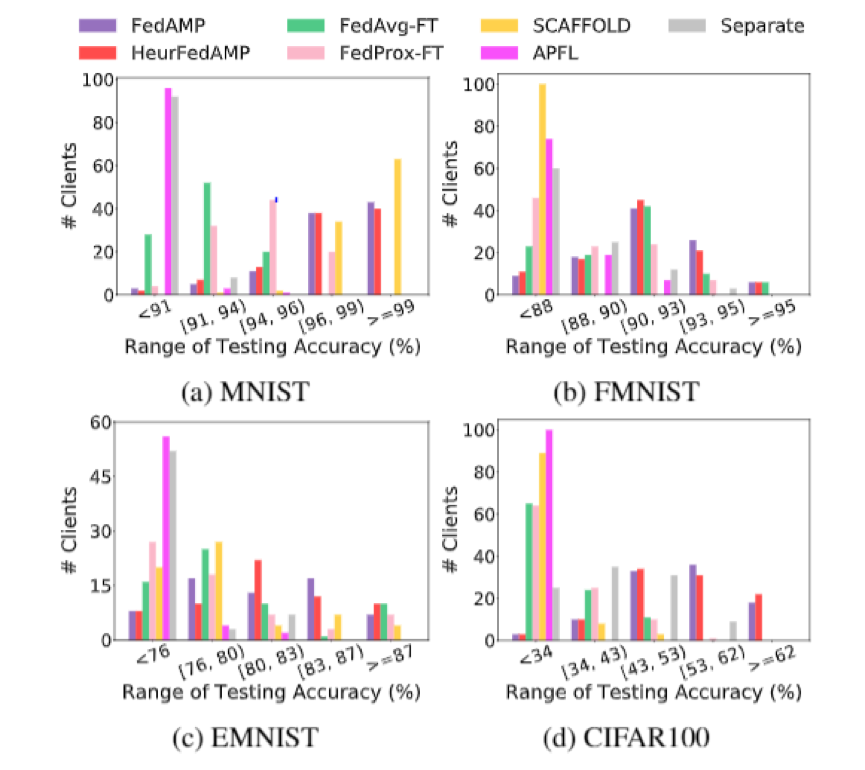
图四:所有客户测试准确率分布
通过分析进一步统计的结果(如图四),作者发现通过 FedAMP 和 HeurFedAMP 所得到的模型对于每个客户的测试精度在统计上显著高于其他方法获得的结果。
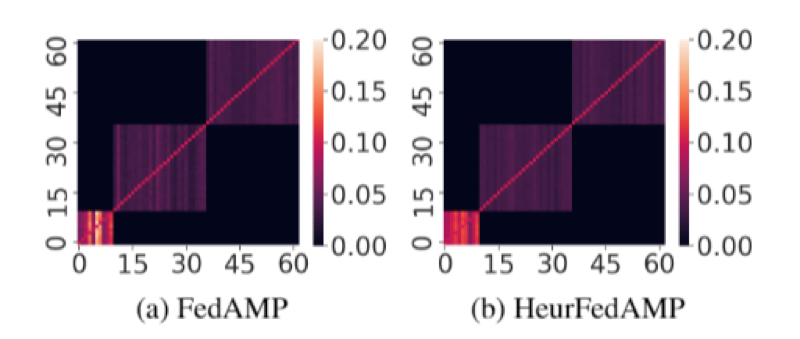
图五:对于 EMNIST 数据集的可视化分组结果
为了更好的理解 FedAMP 及 HeurFedAMP 的机理, 作者进一步分析了注意消息传递机制(如图五)。作者发现 FedAMP 和 HeurFedAMP 均成功发现了蕴含在客户之间的真实分组关系。这一发现进一步解释了 FedAMP 及 HeurFedAMP 在数据分布不均匀时性能卓越的原因。联邦学习三步骤,降低使用门槛基于华为云 ModelArts 平台,实现联邦学习仅需简单的三步操作:第一步:发起者创建一个联邦学习团队,定义联邦任务,并邀请参与者,如图六所示(其中更新策略可配置 FedAVG,FedAMP 等):
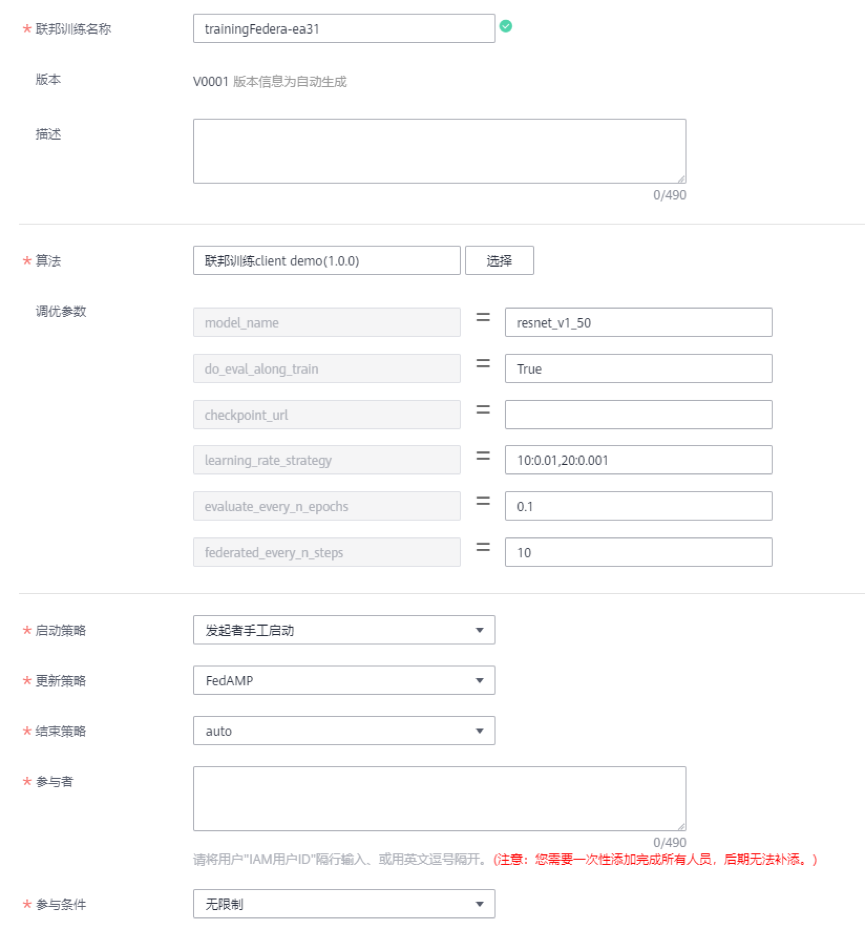
图六:基于 ModelArts 的联邦训练任务创建
第二步:参与者同意加入联邦团队,并配置数据及资源类型,如图七所示:
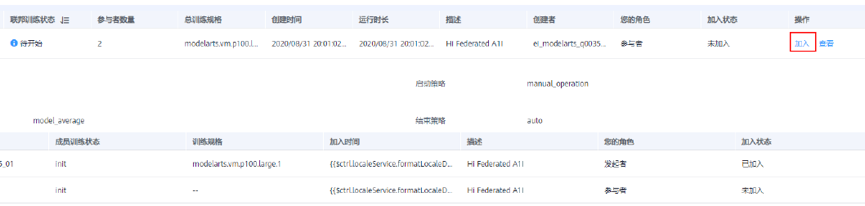
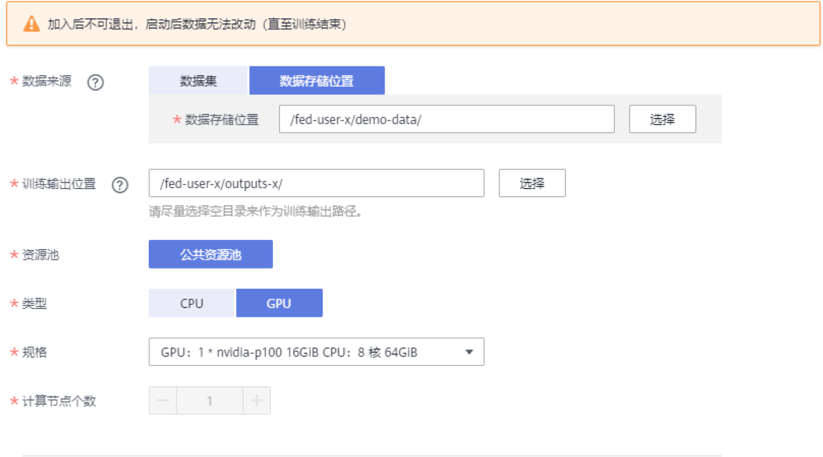
图七:基于 ModelArts 的联邦学习团队加入
第三步:联邦训练发起者启动联邦训练,直至训练完成,如图八所示:
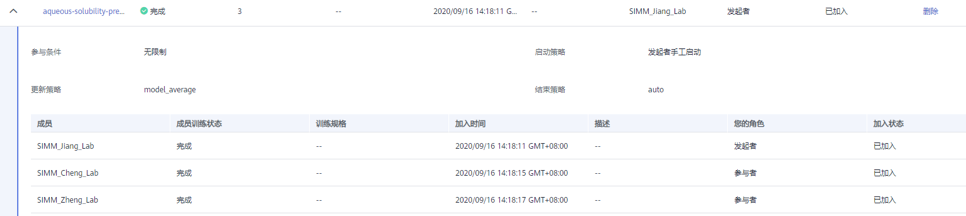
图八:基于 ModelArts 的联邦学习训练
总结
FedAMP/HeurFedAMP 是两种简单高效的个性化联邦学习框架。通过注意消息传递机制,FedAMP/HeurFedAMP 还将天然拥有抗投毒潜力。其在数据分布不均匀时的优异表现,将为云产商吸引更多拥有高质量数据的客户参与联邦学习。
基于上述框架,华为云一站式 AI 开发 ModelArts 提供联邦学习特性,用户各自利用本地数据训练,不交换数据本身,只用加密方式交换更新的模型参数,实现联合建模。算法体验链接




