
过去数年来,大规模集群联邦因其资源无限扩展能力、高可用架构设计及混合云协同优势,成为企业应对业务全球化、场景多元化的关键技术选择。
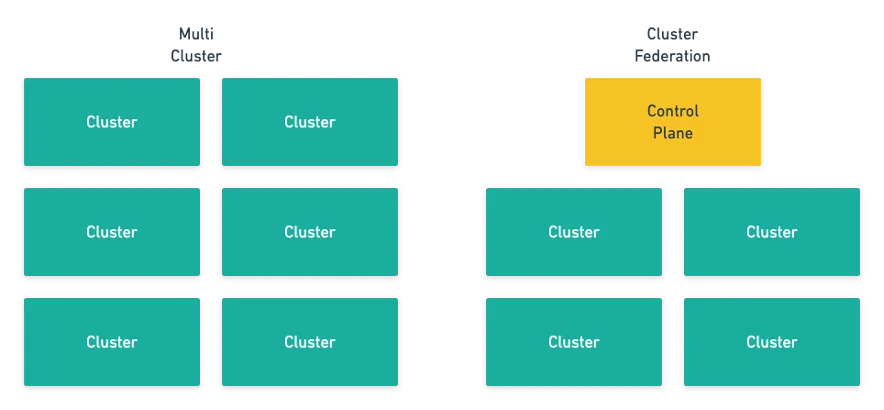
然而,当企业业务规模突破百万节点大关,大规模集群联邦的弊端也开始凸显:复杂业务场景下,资源调度与负载均衡复杂度激增,发布与运维成本增加,容灾能力因故障域扩大而削弱,与此同时,异构环境兼容性、安全治理及成本优化等问题也进一步加剧了大规模集群联邦的稳定性与性能压力。而行业普遍采用的控制面扩展方案往往难以同时满足性能、扩展性和容灾的需求。
与此同时,随着企业对业务连续性的要求达到"分钟级"甚至更低,大规模集群联邦的控制面架构也开始从“中心化管理”向“分布式自治”演进,字节跳动提出的控制面单元化架构正契合这一技术潮流,其核心在于将控制平面“化整为零”,构建多个自治控制单元,从而实现资源的精准调度和高效的容灾备份。
在 3 月 15 日举办的 KCD(Kubernetes Community Days)Beijing 2025 上,字节跳动字节跳动云原生架构师任静思带来了精彩专题演讲“基于控制面单元化的 Kubernetes 集群联邦”,系统揭秘了这项技术的全貌。
内容亮点
大规模集群联邦架构演进与问题剖析
控制面单元化架构核心组件
负载均衡映射算法设计、迁移工作逻辑与容灾恢复策略解析
字节跳动在云原生技术架构设计中构建了统一的云原生基础设施平台。其中,上层平台层直接对接 Kubernetes 集群资源,并基于 Kubernetes 原生 API 标准,通过大规模集群联邦模式实现多集群的统一接入与管理。目前,集群联邦已经覆盖了字节跳动 90%以上的资源,节点数超过 21 万,管理超 10 万在线微服务与 1000 万 Pod,是目前业界规模最大的生产级集群联邦应用之一。
大规模集群联邦的业务背景与核心挑战
从业务场景的角度看,集群联邦所服务的业务类型复杂多样,包括:
在线微服务:支撑应用的业务逻辑、产品基础功能的后端服务;
推广搜服务:为抖音、西瓜视频、懂车帝等 Feed 服务和搜索提供内容列表的后端服务,属于对延迟敏感的 Socket 服务,需绑定单机拓扑;
有状态服务:有特定数据,并根据这些数据来提供服务,这类服务通常对存储的依赖程度较高;
批处理任务:如视频处理、机器学习和大数据服务等偏离线服务。
复杂场景下,集群联邦面临着多种挑战:
具体来说,资源调度方面,集群联邦需要支撑超大规模节点的动态调度;
发布效率方面,由于字节跳动目前所有的业务平台均通过集群联邦架构对接资源层,字节跳动 PaaS 平台 TCE(Toutiao Cloud Engine)的系统日均配置变更量超过 30000 次。与此同时,需要将过去单集群的发布和升级体验平滑地兼容到集群联邦之上。
容灾能力方面,字节跳动本身采用了多数据中心(DC)与虚拟可用单元(VAU)的部署模式,物理层面上会有主机房和卫星机房这样的拓扑结构,因此在进行调度和拓扑分配的时候,就需要每个虚拟可用单元(VAU)内的 Pod 能够形成独立的流量自闭环处理单元,并执行集群层级的 Pod 动态再平衡(Rebalance)操作。
为了解决上述挑战,字节跳动在早期架构中采用了多层级集群划分机制:首先根据业务线构建物理集群,然后在物理集群内部进一步通过节点层级(Node-level)的标签管理机制将其划分为不同的逻辑子集群。但这样的方式存在两大痛点:
第一,部署业务时就需要考虑并选择部署到哪一个物理/逻辑集群,会造成严重的用户心智负担。
第二,每一个独立的物理和逻辑集群都是事实上的资源孤岛,如果想在不同集群之间进行资源腾挪的话,必须依赖 SIE 这种手工的运维操作。
因此,从 2019 年开始,字节跳动就着手设计集群联邦式架构。目前该架构已经在业界已经相对成熟,典型代表包括华为开源的 Karmada、字节跳动开源的 KubeAdmiral 以及腾讯的 ClusterNet 等,其核心架构模式是在底层 Kubernetes 集群上构建一个联邦控制面,该控制面主要由 API Server、Etcd 分布式存储以及联邦控制器(Controller)三个组件构成。在该架构中,所有资源都会被先提交到联邦控制面,由联邦控制面负责资源的调度,并分发到各个成员集群(Member Cluster)。成员集群作为实际的工作负载承载单元,负责运行用户 Pod 并处理业务流量。
从架构层面分析,联邦控制面本身也是一个中心化系统,由于采用了单一的控制平面,因此存在两个关键的性能瓶颈:
系统可扩展性受限:单个 Kubernetes 集群作为联邦控制面,承载能力有上限,当业务规模达到阈值,需要考虑通过水平拆分多个控制面集群,提高系统的线性扩展能力。
缺乏高可用性:一旦联邦控制面发生故障会导致整个集群池化资源不可用,风险较大。通过拆分多个联邦控制面的方式,一方面可以减小并隔离故障域,另一方面引入控制面之间的相互备份,在灾难场景下做到快速恢复。
基于控制面单元化的 Kubernetes 集群联邦整体设计
为解决上述问题,字节跳动提出了基于单元化设计的联邦架构优化方案,方案在保持联邦系统上下两层结构不变的前提下,通过以下改造实现了架构升级:
将单一联邦控制平面拆分为多个独立单元
每个单元均包含独立部署的 API Server、Etcd 分布式存储及联邦控制器
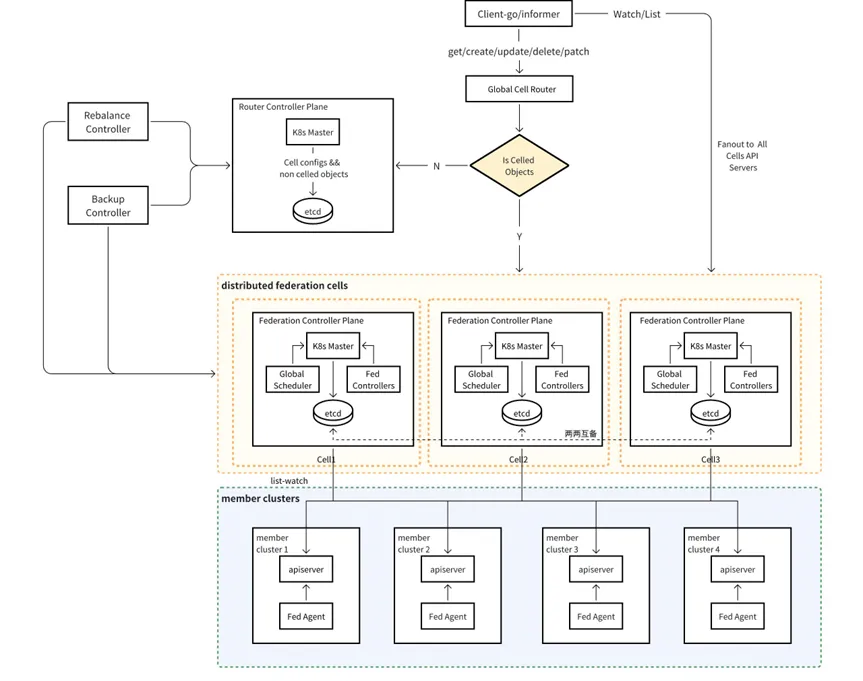
当工作负载被调度至某一单元时,该单元能够独立完成子集群调度状态的收集及状态信息全局同步,相当于每个不同的单元都具备独立存活与容灾的能力,在该架构下,工作负载通过分片(Shard)机制分布式存储于各单元中,每个分片则由所属单元的联邦控制器独立管理,进行控制面循环。
从外层接入角度解析,架构顶层由控制器及用户客户端(Client)构成,该层的核心设计目标在于与 Kubernetes(k8s)原生 API 的兼容性适配。具体来说,兼容性方案需同时支持两类原生 API 接口规范:其一为面向批量数据操作的 API,其二为针对单一资源实例进行操作的 CRUD 标准接口。
对于批量数据操作的 API 接口,其核心是接入 Client-go 的 Informer 架构,但原生的 Informer 架构只能从单一控制平面或独立集群维度进行资源列表的操作。在引入单元化设计后,从用户接入层的视角来看,需要通过扇出机制分发到多个单元,然后进行多单元工作负载的聚合处理,再提供给上层的控制器使用。
因此,字节跳动在客户端接入层自主研发了新的 Informer 架构以实现平滑切换。该 Informer 核心设计包含两个层面的处理逻辑:对于批量查询场景,系统会获取所有联邦控制面的数据并进行聚合处理;而对于单对象查询请求(如 Department Workload 这类资源的 Get、Create、Update、Delete、Patch 等 CRUD 操作),则是通过路由判断当前工作负载所属的部署单元(Cell),从而将请求定向到对应的目标单元完成业务处理。
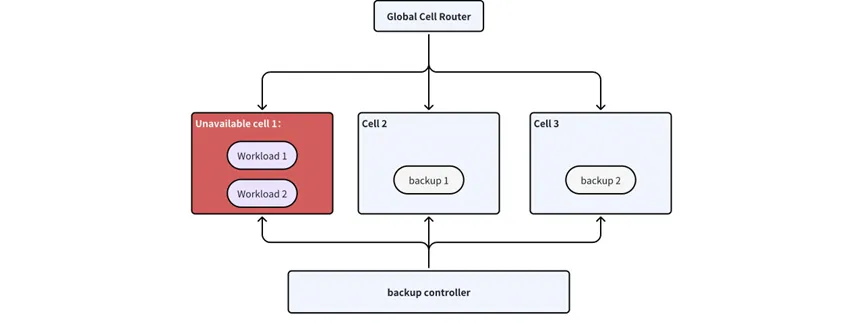
在该架构中,Global Cell Router 组件负责根据映射算法,把工作负载映射到某个单元中。同时,Global Cell Router 也会加载部分联邦层的配置,例如每个单元的 API Server 地址以及单元权重等等。
Router Control Plane 用来存储单元化配置和不需要单元化的对象。
负载均衡迁移控制器(Rebalance Controller)的主要功能是当控制面单元数量发生变化时进行负载均衡与工作负载迁移。当系统需要新增单元或者裁撤失效单元时,负载均衡迁移控制器会将工作负载从目标单元重新分配到其他单元,从而确保系统资源的高效运行。
容灾备份控制器(Backup Controller)作为旁路控制器,主要负责工作负载在单元间的备份。例如业务负载常态部署于单元一时,容灾备份控制器会实时将工作负载状态持续镜像至单元二。从而确保单元一发生不可用故障时,单元二能够实时启用,无缝接管控制循环。
基于控制面单元化的 Kubernetes 集群联邦技术细节
以下是部分关键技术细节:
映射算法
映射算法主要解决的就是工作负载需要具体被路由到哪个单元的问题。因为工作负载的生命周期是动态的(受创建、升级、发布及删除等操作影响),工作负载一旦被创建,就会根据路由算法被分配到指定单元中,由对应单元的 Fed controller 进行管理。
因此,映射算法在设计之初就要考虑以下问题:
负载均衡:各个单元间的工作负载的数量应该相对均衡,并与每个单元的承载能力成正比。
去除单点瓶颈:工作负载与单元间的映射关系不应该依赖于某种单点的存储系统记录,最好能够根据配置和算法进行动态计算。
增添/裁撤单元:随着联邦系统的容量扩展和升级,会出现增添新单元以及裁撤旧单元的需求,此时工作负载和单元之间的映射关系会发生改变,存在工作负载在单元间迁移的过程,这一过程最好是对外透明的,只影响正在迁移的工作负载。
容灾备份:工作负载常态下存储在主单元中,受主单元的 Fed controller 管理,一旦主单元发生不可用故障,需要能够快速切换到备份单元中,由备份单元的 Fed controller 接管。
在整体映射算法的设计过程中,字节跳动进行了多维度考量。最初的解决方案是对工作负载名称进行哈希运算后,再对单元数量取模的方式进行映射,但这种方式存在两个弊端,第一是系统在进行单元扩充或者撤裁时,需要重新计算哈希值,并且计算结果需要存储在数据库中,会出现单点瓶颈;第二是在单元的扩充和裁撤的过程中,副本迁移的规模是比较大且不可控的。
因此,字节跳动选择了分布式领域的一个经典算法:一致性哈希算法。该算法不仅能够有效保障负载均衡,并且在节点数量发生变化时,能够确保所需迁移的工作负载达到最小化,与字节跳动的核心需求高度符合。因此,整体的映射算法以一致性哈希为基础,并在此之上进行了针对性的功能扩展和技术优化。
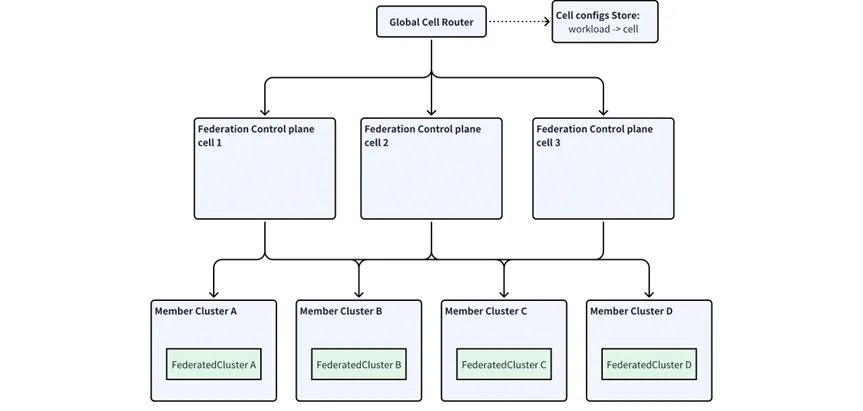
迁移工作逻辑
以一个简单的工作负载迁移为例:假设当前只有两个单元,并且所有的工作负载都部署在这两个单元中,此时如果要加入第三个单元,并且希望迁移尽量少的工作负载,实现三个单元的负载均衡,就需要两个单元各迁移 1/3 的工作负载到第三个单元中。
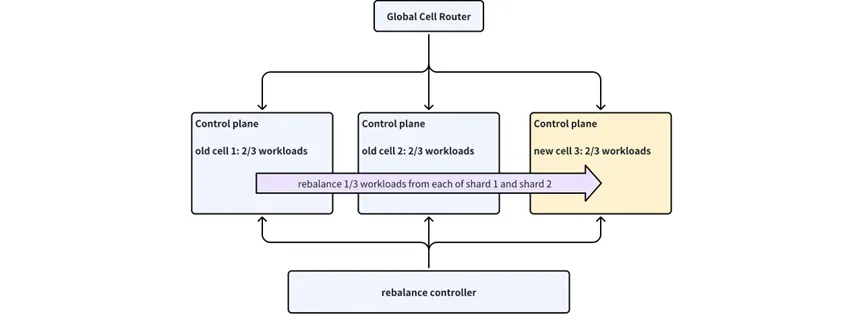
这个过程需要映射算法配合 Rebalance Controller 实现,其核心在于以下几点:
移动尽量少的工作负载, 使单元间重新达到负载均衡。
工作负载的迁移过程需要是有序可控。
工作负载迁移期间,映射算法能够正常工作,把请求转发到对应的单元。
不依赖中心化的存储。
具体到增加/裁撤单元操作,假设下图中左侧粉红色 out 的部分代表希望裁撤掉的部分,中间绿色 normal 的部分表示现行系统稳定运行的保留部分,右侧浅绿色 in 的部分代表希望新增的部分,由于映射算法可以同时支持裁撤单元和新增单元,因此,在单元扩缩容完成之前,单元集合(Current Cells)是 Out Cells 和 Normal Cells 的并集;而在单元扩缩容完成之后,单元集合(Desired Cells)则是 In Cells 和 Normal Cells 的并集。

针对正在迁移的工作负载,需要为其添加特定标签进行标识,类似于在 CRD(Custom Resource Definition,自定义资源定义)或者是原生对象上打标签,标签名为 rebalanceStatus,用于追踪和管理工作负载的迁移状态。
对于正处于迁移过程的资源对象,需要将其标签设置为"migrating"。在整个单元扩缩容期间,路由会针对每个工作负载的请求处理将执行两次一致性哈希计算:首次一致性哈希计算的输入是工作负载的名称以及当前可用的单元集合(Current Cells),输出结果为 OldCellID;在第二次一致性哈希计算中,输入是工作负载的名称以及目标单元集合(Desired Cells),输出结果为 NewCellID。

根据 OldCellID 与 NewCellID 的归属关系,理论上将产生四种情况。以下图中左上角的情况为例,如果 OldCellID 归属于待撤裁单元集合(Out Cells),且 NewCellID 归属于待新增单元集合(In Cells)表明该工作负载需要从 Out Cells 迁移到 In Cells。

以此类推,情况二和情况三都代表工作负载需要进行迁移,其中情况二代表工作负载需要从 Normal Cell 迁移到 In Cells,情况三代表工作负载需要从 Out Cells 迁移到 Normal Cells。情况四则代表工作负载保持在 Normal Cells 中不变。
针对这四种不同情况,路由映射也有所不同:
对于情况四,如果两次映射都在 Normal Cells 中,则他们的一致性哈希结果一定相等,此时将请求转发到对应的单元即可。
对于情况一二三,代表工作负载需要被迁移,路由需要根据这次迁移操作是否完成来决定把请求转发到 OldCellID 还是 NewCellID, 此时的处理逻辑也很简单,只需要从 OldCellID 分片获取工作负载的元数据:
如果工作负载的 rebalanceStatus 标签是空,说明负载均衡迁移控制器(Rebalance Controller)还没有开始当前对象的迁移,路由把请求转发给当前集群即可。
如果工作负载的 rebalanceStatus 标签值为 migrating,说明负载均衡迁移控制器正在对当前对象进行迁移,需要禁止对工作负载进行写操作,此时读请求正常转发,写请求返回重试即可。
如果工作负载已经不存在或者 rebalanceStatus 标签的值为 migrated,说明负载均衡迁移控制器已经完成当前对象的迁移操作,或者这个对象本身就不存在,此时路由把请求转发到 NewCellID 所在集群即可。
对于上述三种工作负载需要被迁移的场景,具体的迁移过程由旁路的负载均衡迁移控制器进行管理,Rebalance Controller 会根据配置的迁移窗口大小,选取一定数量的工作负载,进入如下迁移流程:
设置工作负载的 rebalanceStatus 标签值为 migrating,此时可以保证路由和 fed manager 都不会再更新该对象。
把工作负载从 OldCellID 的单元复制到 NewCellID 的单元。
更新 OldCellID 中的工作负载 rebalanceStatus 标签值为 migrated。
等待一定时间后(如 12 小时或一个配置时间后),删除 OldCellID 中的工作负载,完成迁移。
容灾恢复机制
通常情况下,资源对象只会在对应的单元(主单元)内完成 federation controller 控制循环,字节跳动在设计容灾机制的时候引入了旁路备份机制,通过备份控制器(Backup controller)实时把资源对象同步到一个备份单元中,在主单元发生灾难的时刻,可以更改配置把资源映射切换到备份单元中,实现快速恢复,保证服务不中断。
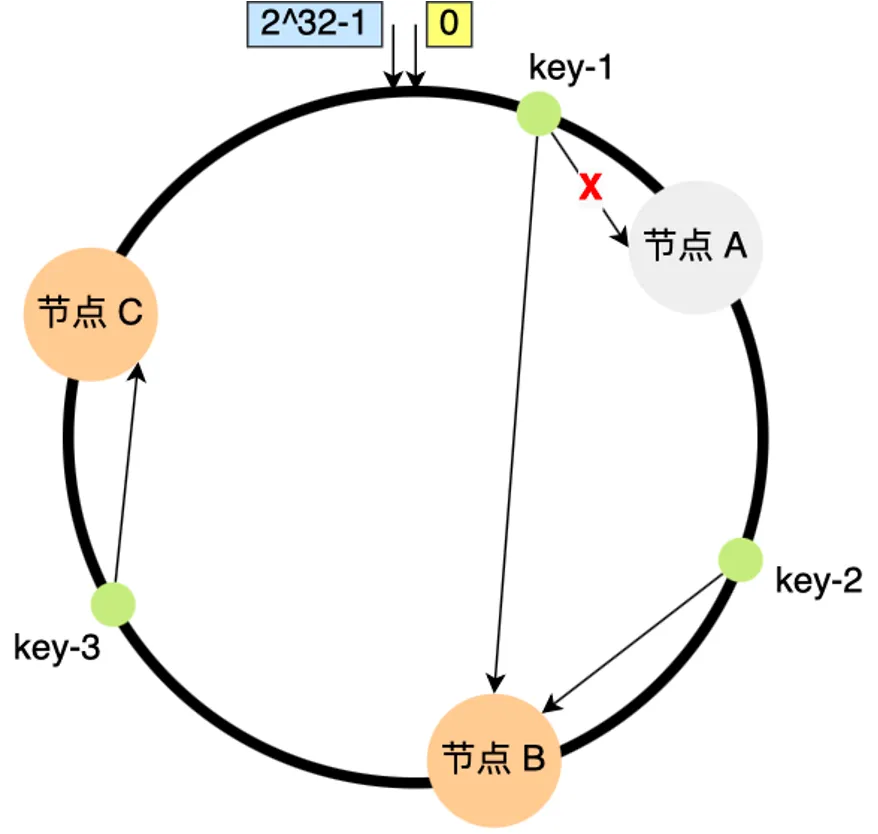
容灾单元的选择策略同样用到了一致性哈希算法,因为一致性哈希算法恰好能应对这种单元数量减少的场景。
具体来说,在单元映射算法中,取一致性哈希的结果为 TargetCellID,取顺时针的下一个单元为 BackupCellID。
备份控制器(Backup Controller)负责实时把主单元中的资源对象复制到备份单元中,并设置 backupCellID 的标签值,如果出现某个单元不可用的情况,路由和备份控制器会执行以下操作:
路由:在配置中去掉不可用的单元, 请求会自动路由到 BackupCell 中
备份控制器:根据最新的单元配置计算 CellID, 如果 CellID 和 backupCellID 相等,则删除 backupCellID 标签值,把备份转正。
总结
针对大规模集群联邦面临的资源调度复杂、运维成本高昂及容灾能力受限等挑战,字节跳动优化了控制面单元化架构。该架构将传统单一控制平面拆分为多个独立单元(每个单元包含独立的 API Server、Etcd 存储及联邦控制器),通过一致性哈希算法实现工作负载的智能映射与负载均衡。配合负载均衡迁移控制器和容灾备份控制器,系统可动态调整资源分配,确保高效运行与故障快速恢复,显著提升了架构的扩展性和灵活性。
该设计在字节跳动复杂业务场景中展现显著优势,支撑了包括在线微服务、推广搜服务、有状态服务及批处理任务在内的多元业务。有效解决了大规模场景下资源调度冲突、跨集群发布效率低及容灾域过大导致的风险扩散问题,为字节跳动的全球化业务提供了稳定、高效的运行基座,同时也为大规模集群联邦管理提供了全新的思路。




