
背景
端点科技是一家 ToB 的软件产品供应商,在长期自研软件产品和给规模型企业交付的过程中,逐渐总结沉淀出一款面向多云的 PaaS 平台 Erda 来作为企业数字化的底座。我之前曾在端点担任 PaaS 平台架构师的时候,负责设计和实现了其中的监控平台,这个平台的初始目标包括:
监控客户环境的多云 Kubernetes 集群
监控 PaaS 自身的运行状态
监控运行在 PaaS 平台上面的业务系统性能
为了实现上面的目标,Erda 的监控平台也经历了监控到 APM 到可观测性平台的演进过程,接下来我们具体看一下在每个阶段做的事情和完成的效果。
监控系统演进
最初,我们基于 Telegraf 作为数据采集器,并二开了大量 Input 插件来满足 PaaS 内部对 Mesos 和容器的监控需求( 在 17 年实现第一版 PaaS 的时候,使用了 DC/OS 作为底层容器平台,从 19 年开始才逐步切换到 kubernetes ),在后端基于 Goka 实现了数据的消费和实时聚合的能力,然后把数据存储到 KairosDB 中。这个流程大概如下图所示:
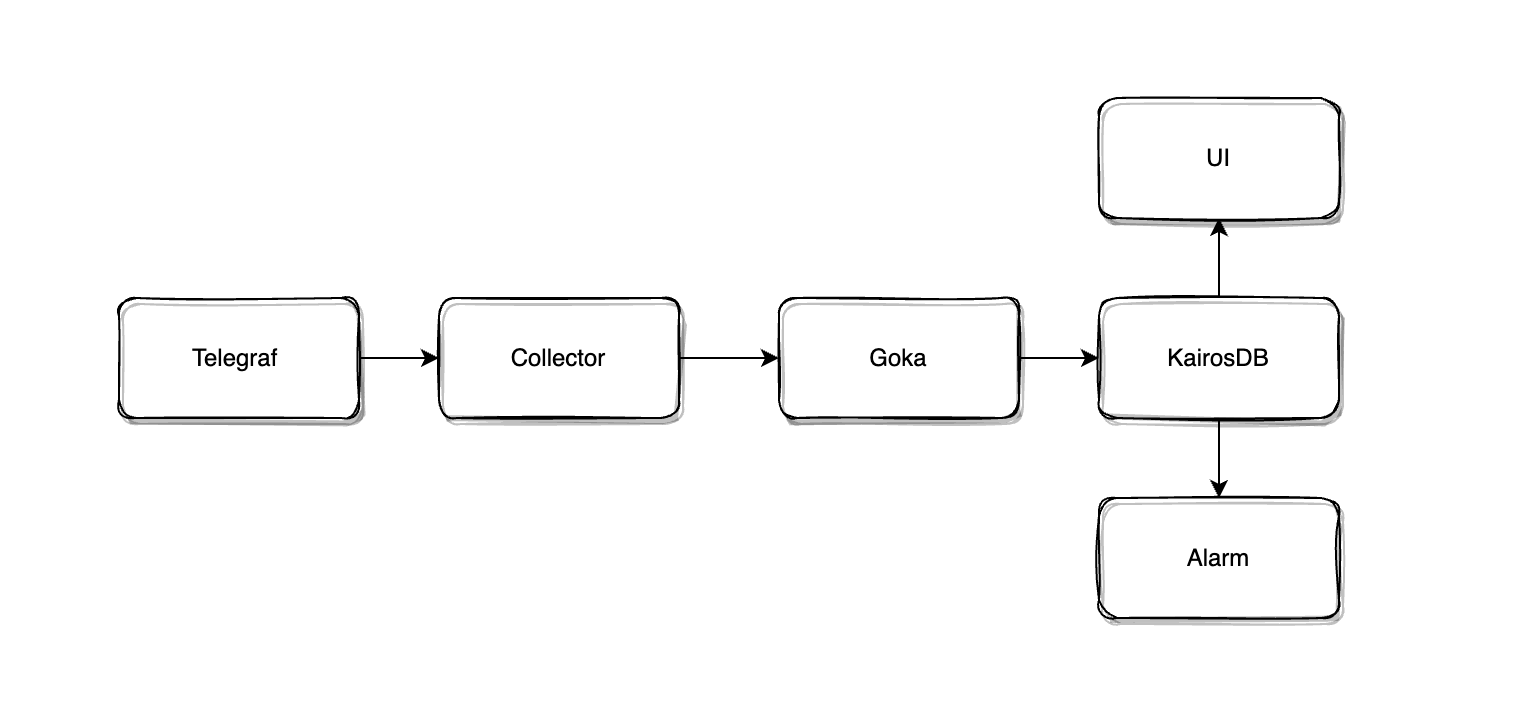
随着 PaaS 开始逐步交付到业务部门,这个监控系统的问题也逐渐被暴露出来。比如
使用了硬编码的方式预创建时序数据表,导致每增加一种监控指标就需要代码实现,版本迭代后才能上线
用户开始创建大量告警规则后对 TSDB 的查询压力过大
业务团队对应用监控的需求日渐强烈等
在达到千万级的序列规模后,Goka 和 KairosDB 的性能压力也开始凸显出来
为解决上面的问题,我们开始思考和设计第二代监控系统,和前面的监控系统相比,新的系统解决了下面的几个问题:
设计了指标元数据系统和 Metrics 数据标准化,监控系统内部不再感知指标的具体含义,增加新的指标只需要接入方按照数据规范打点即可
实现了 Trace 模块,开发 Java Agent 实现业务系统的链路追踪接入,引入 ES 来存储 Trace 数据
为了实现了对 kubernetes 体系的监控,在 Telegraf 上做了大量的定制开发,同时也把 Telegraf 作为机器内数据聚合和转发的 One-Agent
使用 Flink 流计算平台替代 GoKa,基于 Flink 实现了 DSL 方式的指标聚合和告警规则计算,减轻对存储的压力
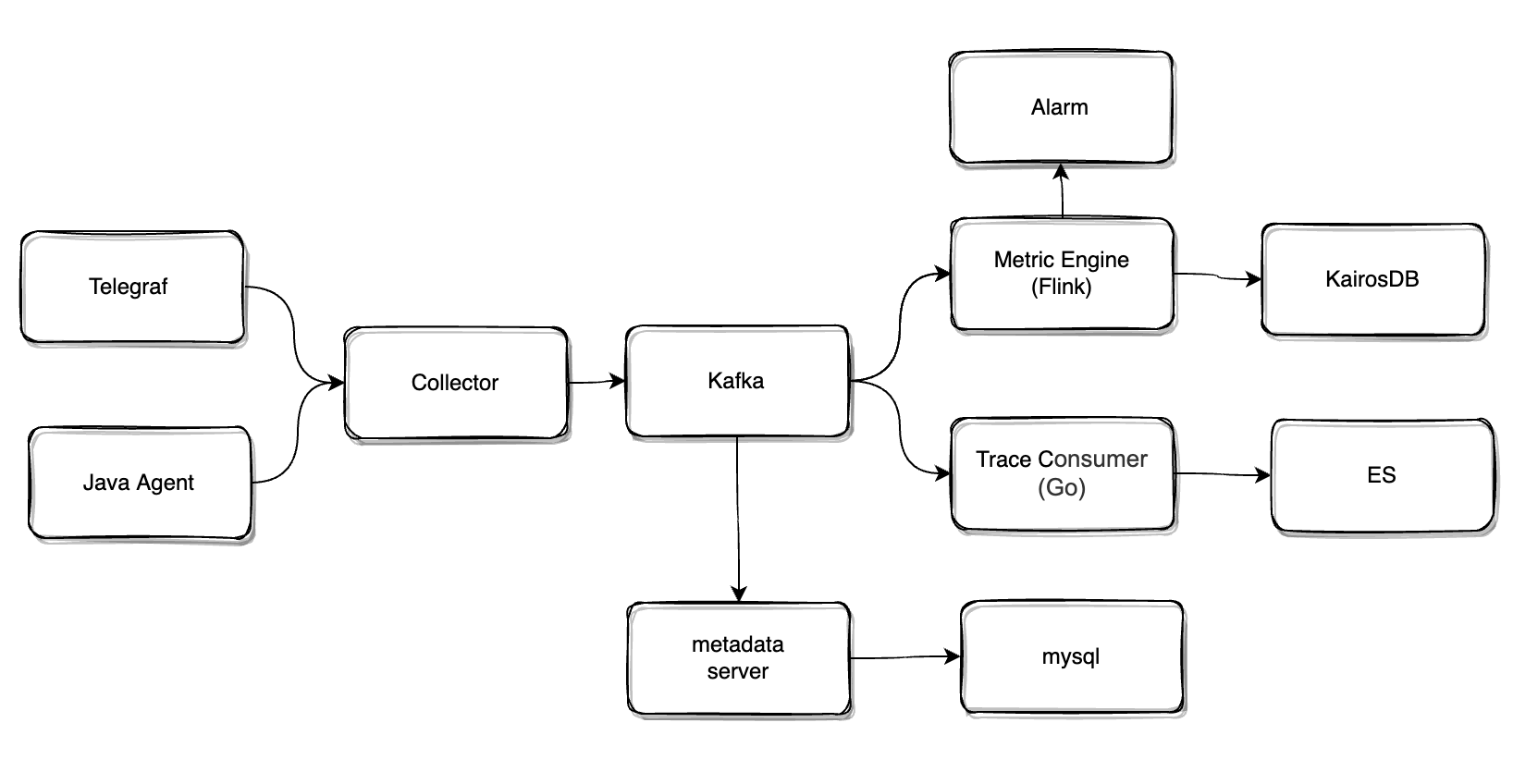
这个版本的监控系统架构如图所示,接下来我们重点介绍一下 Trace 和 集群采集端两个模块的设计。
APM 的 Trace 实现
在 Trace 的实现中,尤其是采集侧语言 SDK 中,我们借鉴了很多 SkyWalking 的设计思路。首先我们在 SkyWalking Java Agent 的内核基础上只保留了它的插件机制,把 Trace 内核和跨进程传播协议替换为 OpenTracing,其次参考了 SkyWalking 提出的 STAM 协议在 OT 的 Baggage 里传递更多的上下文信息,得以在 SDK 侧而不是 APM 的服务端进行 Trace 的分析。拿 HttpClient 插件举例,我们可以使用如下的实现:
public class HttpClientExecuteInterceptor implements InstanceMethodsAroundInterceptor { @Override public void beforeMethod(IMethodInterceptContext context, MethodInterceptResult result) throws Throwable { ... Tracer tracer = TracerManager.currentTracer(); SpanContext spanContext = tracer.active() != null ? tracer.active().span().getContext() : null; Span span = tracer.buildSpan("HTTP " + httpRequest.getRequestLine().getMethod() + " " + url.getPath()).childOf(spanContext).startActive().span(); ... // 在 baggage 里注入上下游服务的元数据 span.getContext().getBaggage().putAll(new ServiceMetaBaggage()); TextMapCarrier carrier = new TextMapCarrier(); tracer.inject(span.getContext(), carrier); ... }}// 把 ServiceMetaBaggage 展开看一下public class ServiceMetaBaggage implements Context.ContextIterator<String> { ... public TransactionMetricContext() { map.put(Constants.Metrics.SOURCE_PROJECT_ID, Configs.ServiceConfig.getProjectId()); map.put(Constants.Metrics.SOURCE_PROJECT_NAME, Configs.ServiceConfig.getProjectName()); map.put(Constants.Metrics.SOURCE_APPLICATION_ID, Configs.ServiceConfig.getApplicationId()); map.put(Constants.Metrics.SOURCE_SERVICE_NAME, Configs.ServiceConfig.getServiceName()); map.put(Constants.Metrics.SOURCE_SERVICE_ID, Configs.ServiceConfig.getServiceId()); ... }}在业务的 Server 端被 JavaAgent 拦截之后,从 baggage 中读取到上游服务的信息记录到自身的 Tag 中,那么 Server 端记录的 Span 数据如下所示:
{ "name": "GET /api/order", "span_kind": "server", ... "tags": { "src_project_id" : "1", "src_app_id" : "1", "src_service_id" : "1", "src_service_name" : "admin", "dest_project_id" : "1", "dest_app_id" : "2", "dest_service_id" : "3", "dest_service_name" : "order" }}同时我们没有使用 SDK 直连Collector的发送方式,而是在 JavaAgent 把 Span 数据全量推送到宿主机的 Telegraf 中,通过 Telegraf 将命中采样的 Span 数据转发到后端 Collector,并使用一个 Go 开发的 Consumer 组件将数据存储到 ElasticSearch 中。由于每个 Span 已经附带了调用上下游的数据,也可以很容易的在 Telegraf 的管道内把 Span 聚合为如下的 Metrics :
service_node描述服务的节点和实例service_call_*描述服务和接口的调用指标,包括 HTTP、RPC、DB 和 Cacheservice_call_*_error描述服务的异常调用,包括 HTTP、RPC、DB 和 Cacheservice_relation描述服务之间的调用关系
通过上面的方式,我们得以在 APM 系统的资源消耗和性能取得相对平衡的情况下实现展示给用户全量的拓扑、服务调用次数等数据的能力。
集群采集端实现
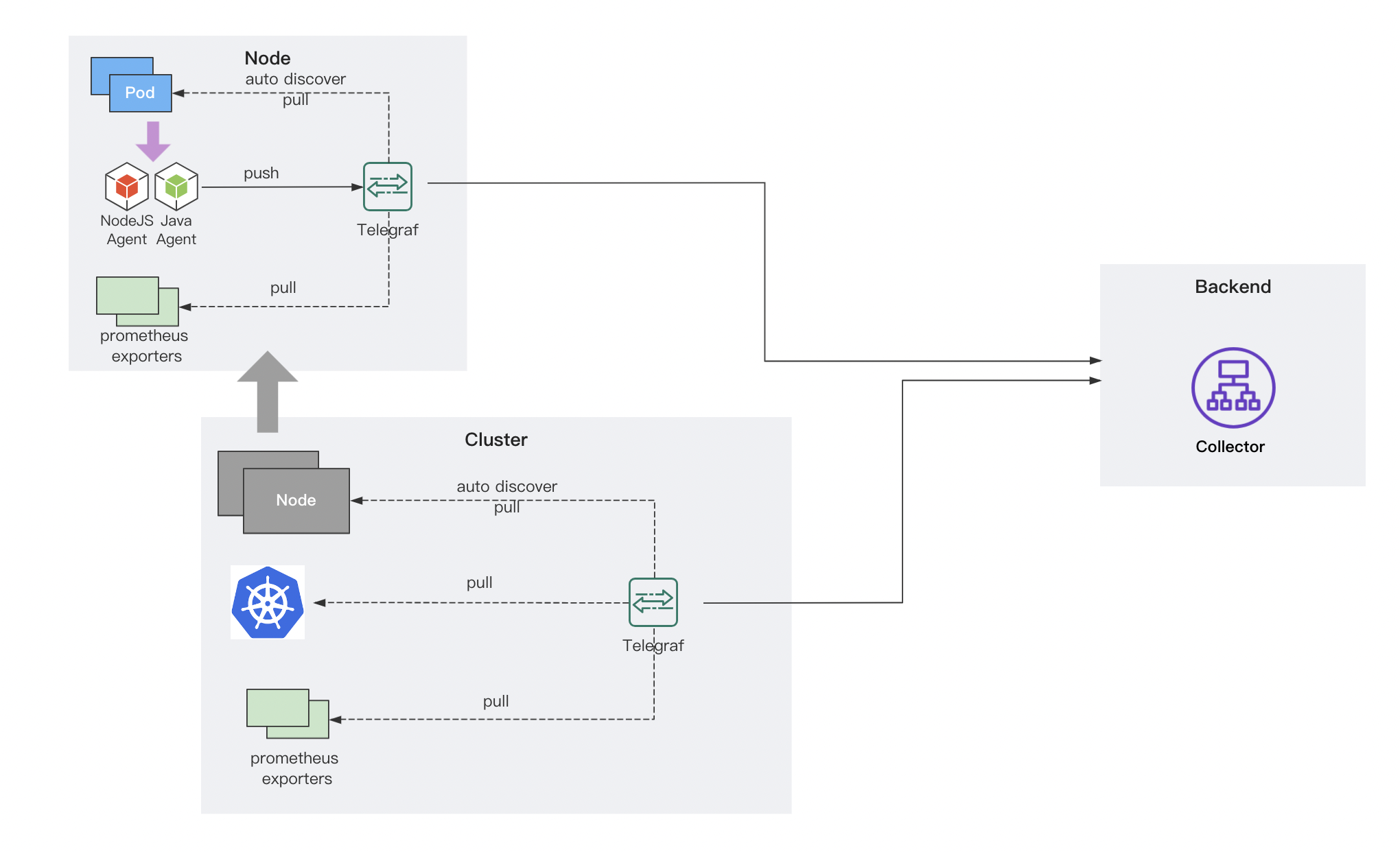
采集端的设计如上图所示,我们在每个集群中安装基于 Telegraf 深度定制的 Cluster Agent,负责采集 Kubernetes 和 PaaS 在集群中部署组件的监控数据,同时这个 Agent 也可以模拟成一个 Prometheus Server,拉取集群中被自动发现的 Exporters 数据。每个节点上,也会部署一个 Telegraf 的 DaemonSet 作为 Node Agent,基于我们定制的 Docker Input 插件自动发现节点上的容器,并把容器识别为 PaaS 平台定义的 Service、Job 或者 Addon 组件。在上文中我们提到 Telegraf 也会作为一个本地 Proxy,接收 Pod 中的业务应用 Java Agent 探针上报的应用请求和 Trace 数据,转发给后端的 Collector 组件。
还有什么问题
通过上面的一些方案,我们覆盖了对宿主机、Kubernetes、容器、业务进程的监控数据采集和对 Java 微服务系统的 Trace,但离我们最初的目标还有些差距:
监控客户环境的多云 Kubernetes 集群基本实现,但定制较多,还需要自己去兼容不同的容器运行时
监控 PaaS 自身的运行状态,未实现
监控运行在 PaaS 平台上面的业务系统性能,已经实现对 Java 应用系统的 Trace,但客户也有其他语言比如 PHP、Go 的监控需求
对于问题 1 我们提出使用 Prometheus 来替换 telegraf 作为集群内的数据采集方案。由于我们已经实现一套完善 Metrics 流分析、存储和查询系统,我们只把 Prometheus 作为数据采集器,通过在 Collector 中实现 Remote Write 协议接收数据,而无需考虑 Prometheus 的存储高可用问题。这个时候 Kubernetes 集群的监控数据链路:Prometheus -> Collector Remote Write receiver -> Metrics System -> Query & Dashboard。
接下来我们将更多的关注点放在问题 2 和 3 之上。PaaS 平台的控制面本身也是使用 Golang 语言开发的一个微服务系统,大概包含 20+ 的微服务模块。通常情况下,我们会搭建独立的分布式追踪、监控和日志系统来协助开发团队解决微服务系统中的诊断和观测问题。但同时 PaaS 本身也提供了功能齐全的服务观测能力,而且在社区也有一些追踪系统(比如 Apache SkyWalking 和 Jaeger)都提供了自身的可观测性,给我们提供了使用平台能力观测自身的另一种思路。
最终,我们选择了在 PaaS 平台上实现 PaaS 自身的可观测,使用该方案的考虑如下:
平台已经提供了服务观测能力,再引入外部平台造成重复建设,对平台使用的资源成本也有增加
开发团队日常使用自己的平台来排查故障和性能问题,吃自己的狗粮对产品的提升也有一定的帮助
对于监控系统的核心组件比如 Kafka 和 数据计算组件,我们通过 SRE 团队的巡检工具来旁路覆盖,并在出问题时触发报警消息
这时如果把问题 2 和 3 放在一起来看,我们要解决的事情就变成了,如何实现多语言的 Trace 和 Metrics 监控。
接入 OpenTelemetry Trace
OpenTelemetry 是 CNCF 的一个可观测性项目,由 OpenTracing 和 OpenCensus 合并而来,旨在提供可观测性领域的标准化方案,解决观测数据的数据模型、采集、处理、导出等的标准化问题,提供与三方 vendor 无关的服务。https://opentelemetry.io
我们在社区寻找多语言的 Trace 接入方案时,注意到 OpenTelemetry 项目,在经过调研和对比后我们认为它不仅可以满足我们目前的需求,我们还认可 OpenTelemetry 在可观测性方向上的潜力。
在上文中也提到,我们在实现 Trace 时使用了类似[STAM](https://wu-sheng.github.io/STAM)的传播协议,OpenTelemetry 的 Trace 协议则没有包含太多的上下游服务的信息。在这种情况下我们想到两种方式来做实现,一个是扩展 OpenTelemetry SDK 来实现上文中提到的我们私有的 baggage 注入,另一个方式是使用原生的 OpenTelemetry SDK,在 APM 后端重新实现 OpenTelemetry Trace 数据的聚合和分析。这里我们使用了方案二,原因如下
我们在之前定制和改造 telegraf 后期难以和社区的版本进行同步,导致我们不得已一直去维护一个分支版本,在引入新的组件时要尽可能的避免再次出现这种情况
我们观察到社区越来越多的框架和系统开始集成 OpenTelemetry ,兼容原生 SDK 的数据上报也有利于我们之后更容易的对接其他系统
具体的实现上,如下图所示,我们在 Collector 组件中实现 otlp 协议的 Receiver,并且在数据消费端实现一个新的 Span Analysis 组件把 otlp 的数据分析为 PaaS 平台原有的 Trace 模型和服务 Metrics
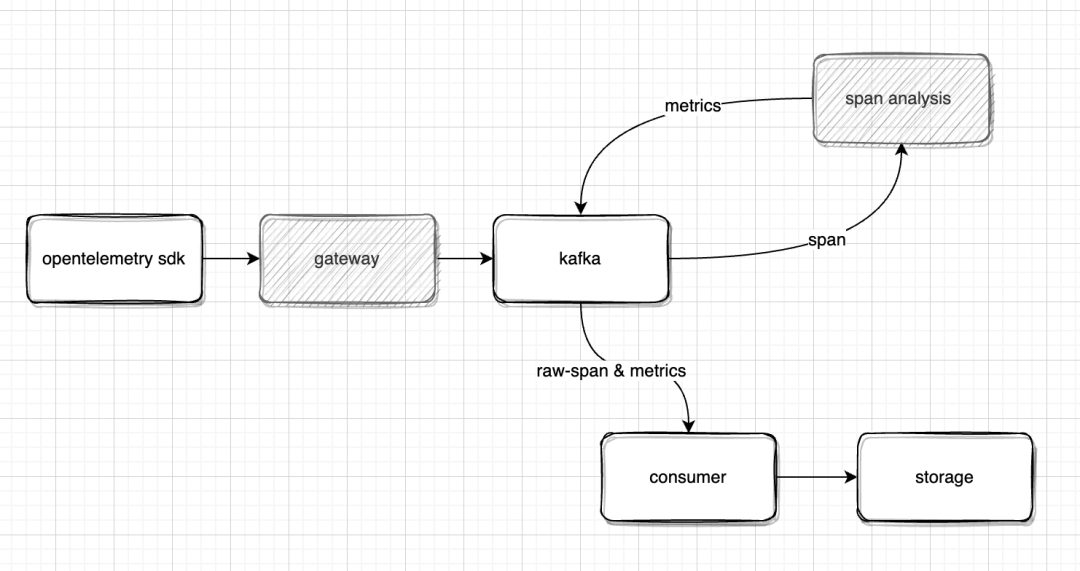
其中,Collector (Gateway) 组件使用 Golang 轻量级实现,核心的逻辑是解析 otlp 的 proto 数据,并且添加对租户数据的鉴权和限流。在 otlp receiver 插件中,我们添加 go.opentelemetry.io/proto/otlp依赖,其中内置了对 otlp proto 数据的解析:
import ( "github.com/golang/protobuf/proto" otlpv1 "go.opentelemetry.io/proto/otlp/trace/v1")...func ProtoDecoder(req *http.Request, entity interface{}) error { contentType := req.Header.Get("Content-Type") if _, ok := acceptedFormats[contentType]; !ok { return errors.New(fmt.Sprintf("Unsupported content type: %v", html.EscapeString(contentType))) } if entity, ok := entity.(*pb.PostSpansRequest); ok { body, err := readBody(req) if err != nil { return err } // 使用proto包的 Unmarshal 函数即可解析otlp上报的数据 var tracesData otlpv1.TracesData err = proto.Unmarshal(body, &tracesData) if err != nil { return err } entity.Spans = convertSpans(&tracesData) } return nil}Span_Analysis 组件基于 Flink 实现,通过 DynamicGap 时间窗口,把 OpenTelemetry 的 span 数据聚合分析后产生如下的 Metrics (和上文中提到的在 Agent 端聚合的 Metrics 一样):
service_node描述服务的节点和实例service_call_*描述服务和接口的调用指标,包括 HTTP、RPC、DB 和 Cacheservice_call_*_error描述服务的异常调用,包括 HTTP、RPC、DB 和 Cacheservice_relation描述服务之间的调用关系
通过上面的方式,我们实现了将 OpenTelemetry 的 Trace 接入到 PaaS 的 APM 系统。
如上文所说,我们把 PaaS 控制面看做一个 Go 开发的微服务系统,那么以 Go 语言接入为例,我们可以使用原生的opentelemetry-goSDK 进行接入。首先引入 SDK 依赖:
go get go.opentelemetry.io/otel/sdk假设 PaaS 部署后暴露的 Collector 接入点为 https://collector.paas.io/api/otlp/v1/traces,我们在使用 otlp http exporter进行数据上报:
// Init configures an OpenTelemetry exporter and trace providerfunc Init(ctx context.Context) *sdktrace.TracerProvider { //New otlp exporter opts := []otlptracegrpc.Option{ // 配置上报地址,如 config.yaml 里已配置,此处可忽略 otlptracehttp.WithEndpoint("https://collector.paas.io/api/otlp/v1/traces"), otlptracegrpc.WithInsecure(), } exporter, err := otlptracehttp.New(ctx,opts...) tp := sdktrace.NewTracerProvider( sdktrace.WithSampler(sdktrace.AlwaysSample()), sdktrace.WithBatcher(exporter), sdktrace.WithResource(r), ) otel.SetTracerProvider(tp) return tp}接入的拓扑效果如图所示 :
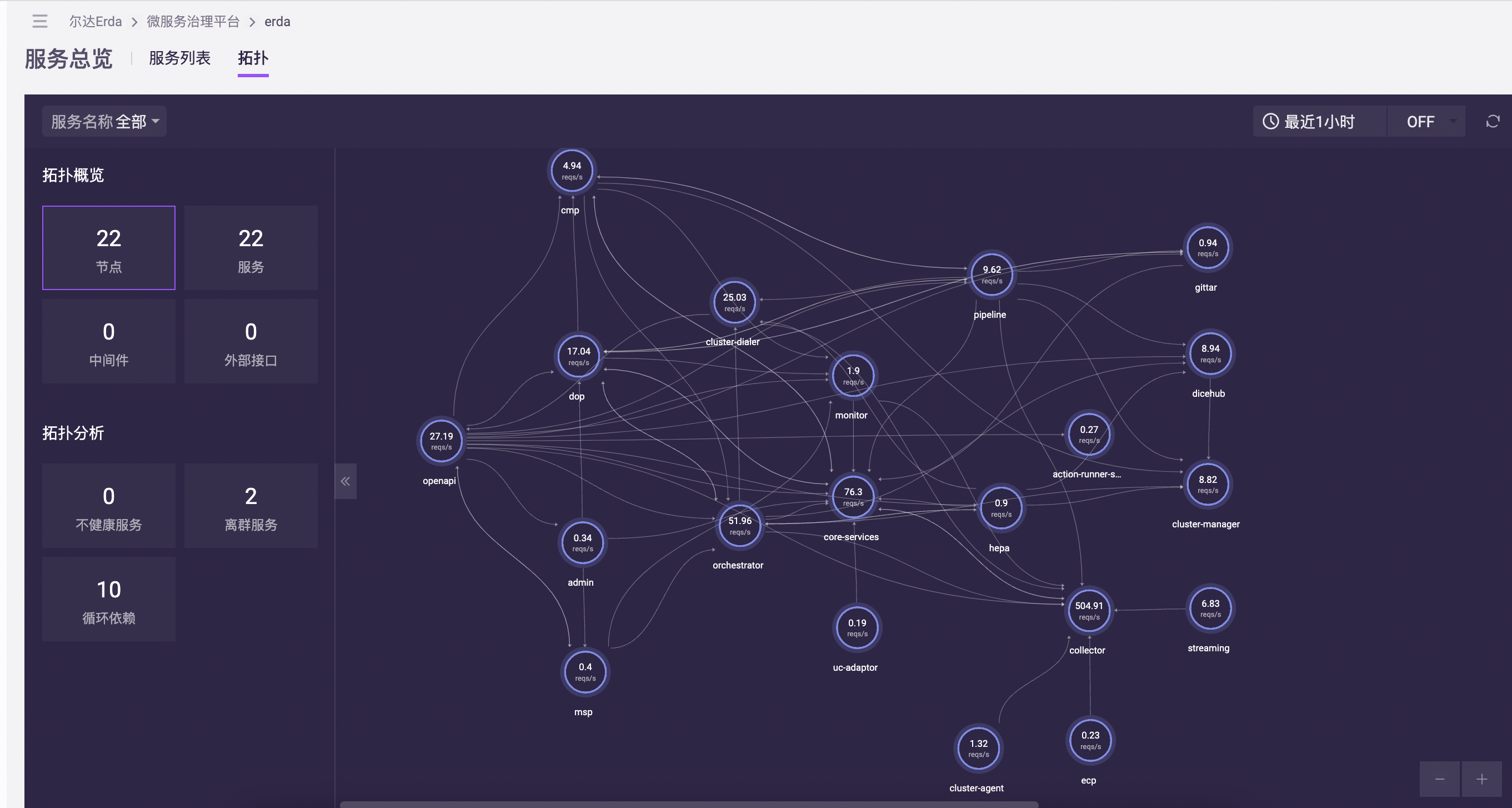
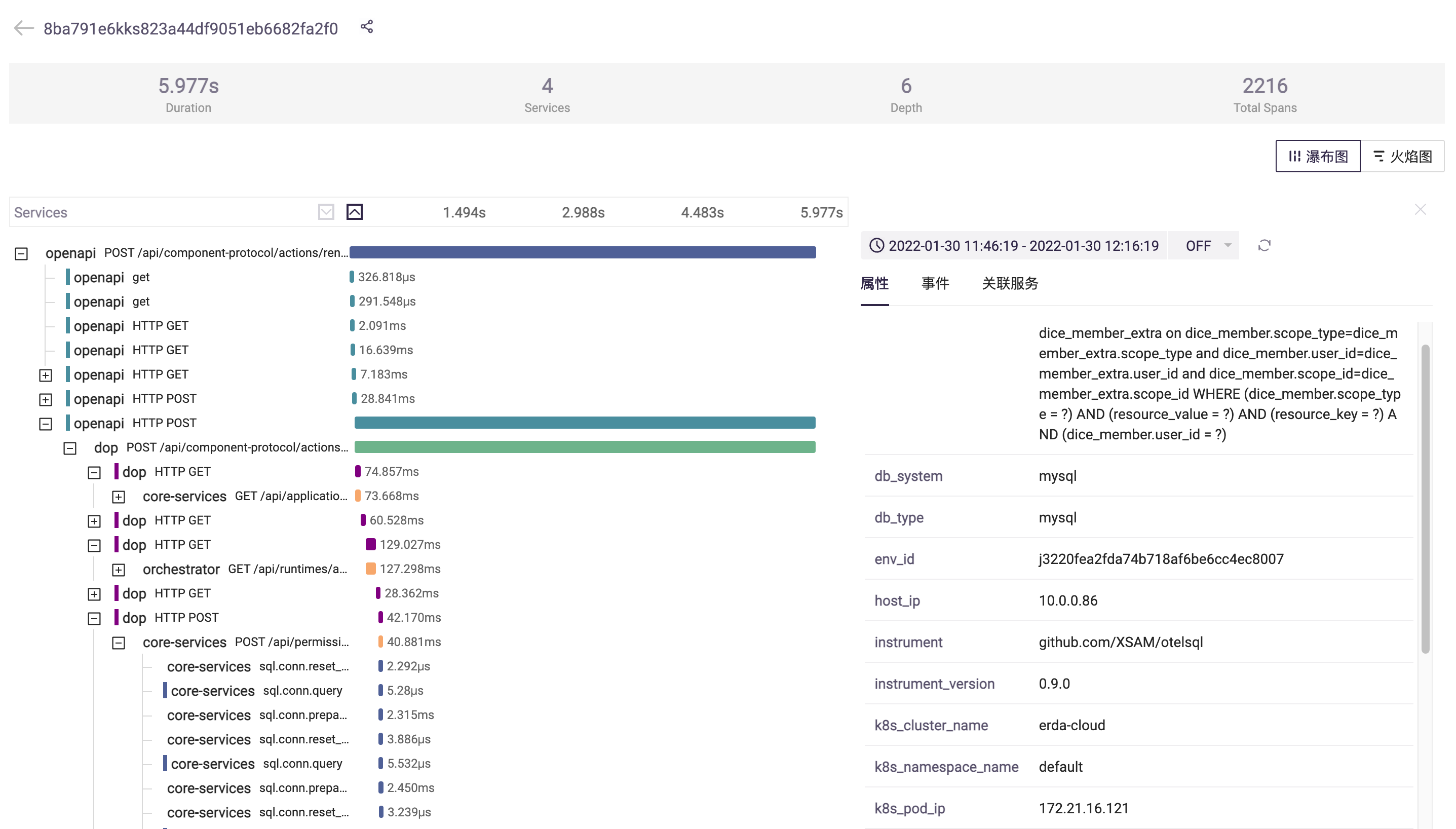
链路追踪的效果如图所示:
总结
Trace 的接入作为我们的第一步尝试,在 Opentelemetry 和我们 PaaS 自研的 APM 后端/产品功能的集成上的效果还是比较令人满意的。之后我们也计划了更多的 Opentelemetry 对接目标(如 Metrics、Log 集成,和使用更推荐的 Opentelemetry Collector Exporter 来上报数据),期望通过 Opentelemetry 来降低上文描述的接入端的架构复杂度和实现可观测性数据接入的标准化。但可惜的是,之后由于我个人原因的工作变动,上述计划没有完成最终的落地。最近受 OpenTelemetry 中文社区的发起人蒋志伟老师约稿,把我在可观测性系统演进和 OpenTelemetry 落地中的一些经验分享给社区供大家进行参考,也欢迎大家对本文的内容提出更多的建议和交流。
作者介绍
刘浩杨,Apache SkyWalking PMC 成员。




