
1. 业务背景
随着数据量增加、计算能力增强以及深度学习理论技术的发展,语音识别准确率不断提升,应用领域不断拓宽。在滴滴,语音识别的应用有交互式的,如搭载在车机/手机上的语音助手,通过语音识别把用户的语音转换为机器能够理解的文字,使得机器执行对应任务并给予反馈,实现一种自然的人机交流。在一些国家,由于法律法规禁止在驾驶过程中操作手机,语音甚至成为车载场景中驾驶员与手机交互的唯一一种方式。此外还有非交互式的应用,例如通过行程录音保障司乘安全,以及在客服质检、智能外呼等领域上的应用。
以交互产品为例,语音识别的准确率基本可以达到 95%的字准水平。但是这并不能满足日新月异的业务需求。尤其是对于细分领域新增的专有词汇,如英文词、地名、专业用语,如果不针对性的调优模型,任何一家厂商的语音识别模型都难以满足业务要求。由于业务的优化周期一般可达几周甚至几月,多条业务线时间存在交叠,偶尔也会出现紧急需求,完全依靠有限的语音工程师处理,并不能及时响应,影响业务推进和用户体验。
于是我们开发了语音识别模型自学习平台来缓解这个问题。语音识别简单来说分为声学模型,语言模型,解码器和发音词典。声学模型重建音素级别的内容;语言模型表征词间关系;解码器将声学模型、语言模型和发音词典结合到一张加权有向图上,输出音频对应的最高分数的词(字)序列。我们可以通过语音识别自学习平台对声学模型和语言模型进行优化,它具有以下优势:
由于项目经理、业务方、合作伙伴以及用户往往会第一时间拿到需要识别支持的 query,比如说定制车的信息、城市的道路信息,于是我们开发了良好的平台交互界面,即非语音相关的技术人员,只需要通过平台输入词级别、句子级别甚至篇章级别的业务文本信息,就可以自动触发模型训练、模型测试、模型发布、在线服务构建的流程,对业务专属模型进行自助优化。完成这些只需要几分钟的时间且无需重启识别服务,就可以实现大部分业务词汇的识别效果提升。
由于深度学习模型需要与业务场景符合的大量数据进行训练才能更好地提升整体效果,业务落地之后,我们就可以逐步合规地收集这些真实场景数据。对线上数据全部进行人工标注价格不菲。我们可以通过平台添加任务周期性地回流线上数据,简单说就是筛选识别结果高置信的音频/文本加入模型训练,达到模型自动更新、闭环迭代的效果。
部署方便,可支持数据隔离要求较高的私有化部署。
2. 平台架构
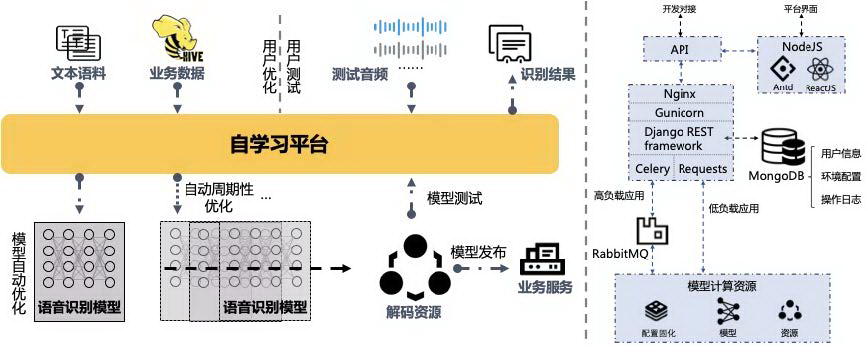
2.1 用户接口与数据输入
自学习平台为用户提供了 Web 界面和 API 接口两种操作方式,通过两种用户接口均可进行优化所需数据的输入更新、优化后模型的测试识别。一方面,为了满足非专业用户参与模型优化,自学习平台基于 NodeJS/Antd 开发了 Web 前端页面,为用户提供了简单、易用的模型自学习优化操作界面;另一方面,为了支持开发人员进行定制化的二次开发,平台基于 Django REST framework(DRF)开发了 RESTful API,可以方便地使用标准 HTTP 协议进行跨语言调用。借助前端页面和 API 接口的解耦,平台同时也实现了前后端模块的分离。
此外,进行自学习优化需要大量的数据输入和更新操作。为此,平台支持用户上传文本语料和从业务数据仓库(如 Hive 等)进行语料数据拉取。文本语料快速上传可用于模型针对性的优化测试和快速响应的迭代调整;而从业务数据仓库拉取则可用于大量数据的更新、业务数据的回流等。
2.2 配置固化与权限控制
为了持续、稳定地为用户提供服务,同时保证用户配置、模型、数据和资源的安全性,平台后端实现了用户配置的固化和权限的控制,从而也为平台管理者提供了一系列的用户、项目、数据、资源管理功能。平台后端通过 ORM 与数据库后端解耦,从而可以依靠用户在用的后端数据库(MongoDB/MySQL 等)进行配置、权限的固化存储、控制管理等。此外,平台面向项目构建了“用户-项目-<数据/资源>“的配置、权限管理框架,使其更加符合在业务实践中团队协作针对项目进行模型优化的应用需求。借助该管理框架与基础设施,我们还支持了用户操作日志的记录,确保结果可查看、操作可溯源,进一步提高了平台操作的安全性。
2.3 任务调度与异步处理
模型自学习过程中的大量任务,诸如数据拉取、模型训练、识别推理等,耗时较长、计算资源消耗大,给整个平台造成的负载压力大;而同时平台在处理这些高负载应用时仍然需要对用户进行的操作进行快速响应。为了保证响应速度和服务质量,平台支持任务调度和异步处理。借助分布式的任务队列 Celery 和消息队列 RabbitMQ,我们为低延时、低消耗的任务(Sync Tasks)即时分配资源进行处理;而对于高耗时、高复杂度的任务(Async Tasks)则进行异步处理。同时,利用 Celery 平台也为模型自学习需要的周期性优化任务(Periodic Tasks)提供了支持。
3. 算法应用
3.1 声学模型优化
在模型训练及优化时,通常需要大量的标注数据进行数据支撑,然而标注数据本身获取的时间较长,同时成本较高。为了能够在标注数据较少,甚至没有的情况下,也能够较快的进行模型的优化。对此我们采取了半监督(SSL -- Semi-Supervised Learning)的训练方式,充分利用线上的大量无标注数据,快速进行模型的自学习优化。
3.1.1 半监督训练
在进行模型训练时,通常我们将在大量带标签的语料库上进行的训练称之为有监督训练。而与之区别,半监督训练的特点是可以利用已有的模型或网络对大量无标签数据进行预测,并将它的伪标签(Pseudo label)作为新的训练数据放入网络中进行自学习的模型训练。这种自学习的训练方式通常能比单纯使用少量标注数据时,能够带对模型效果带来更大的提升。
3.1.2 声学数据回流
自学习框架是通过半监督的方式,利用庞大的线上数据完成模型自动优化的框架,其具体框架如下:
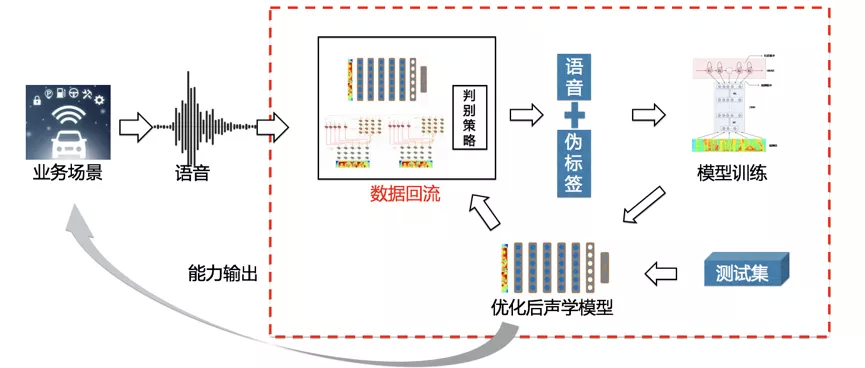
对于一个新的业务场景,我们首先将线上的语音数据通过定时器定期的从数据库 hive 表中拉取后,将其放入由多个召回模型和一个可选择的判别策略组成的数据回流模块中,通过数据回流召回质量较高的语音并得到与其对应的伪标签。而这些被我们从线上召回的数据将被作为新的训练数据加入模型中,并根据业务侧提供的测试集自动的进行模型的优化和参数的调整。最后优化得到的模型将在进行能力输出的同时也放回数据回流模块中,通过更新召回模型的方式优化下一次召回的数据质量。其中,一些主要的模块功能介绍如下:
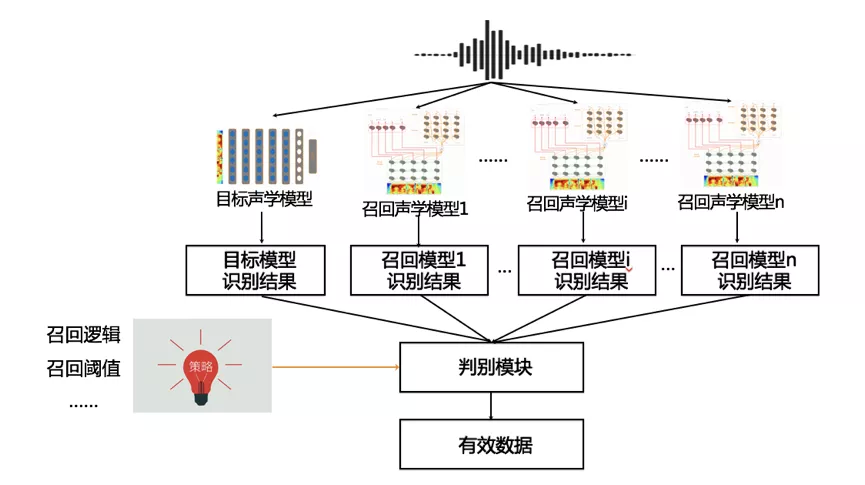
a. 数据召回模块
数据召回模块的主要功能是筛选出质量高的语音,并且预测与语音对应的伪标签。它是由数据处理、多个召回模型和判别策略组成。期间为提高模块所召回数据的质量,在进行数据召回时,没有选择使用单一模型进行伪标签预测,而是选用多个与目标场景类似的模型在规定阈值的情况下,按照一定的相似度来进行数据的选取以及伪标签的预测。这种方式不仅可以保证数据的质量能够对模型训练的性能带来有效提升,同时也能够增加训练样本的多样性,让模型在训练的过程中变得更为鲁棒。
b. 模型训练模块
在进行模型训练时,依据召回的数据量,进行模型迭代的周期可能是一周或者数周。为了能够随时检测训练出的模型质量,在训练的过程中采取了在训练的同时进行解码的方式,每检测到一个新训练出的模型之后即开始进行同步的模型打包和解码。同时为保证在每个批次中解码的参数是对于当前模型最优的,框架在每次进行新一轮的解码时,都会自动的进行参数的调节,目前可支持最大精度为 0.0005。在检测到效果更优的模型出现后,将其记录备份,并作为新一轮模型训练的 base 模型进行进一步的迭代优化。同时也会将新的模型更新到数据召回模块中的目标模型部分,来优化下一次召回的数据质量。
3.2 语言模型优化
3.2.1 热词模型
在很多垂直领域应用场景下,业务需求往往并不需要语音识别服务对所有的通用词汇精准识别,而更加偏重于对某些关键指令、词汇的识别。为了满足这些特定场景下的识别任务,我们提出了支持热更新的热词模型解码框架,在该框架下,语言模型的有向图结构由两个语言模型组成,一个是模型体积较大的通用语言模型,一个是由垂直领域关键词汇、指令语料训练的热词语言模型。热词模型由于体积小,可以快速展开成图并入通用语言模型的图结构,即可实现快速更新。
3.2.2 重排序
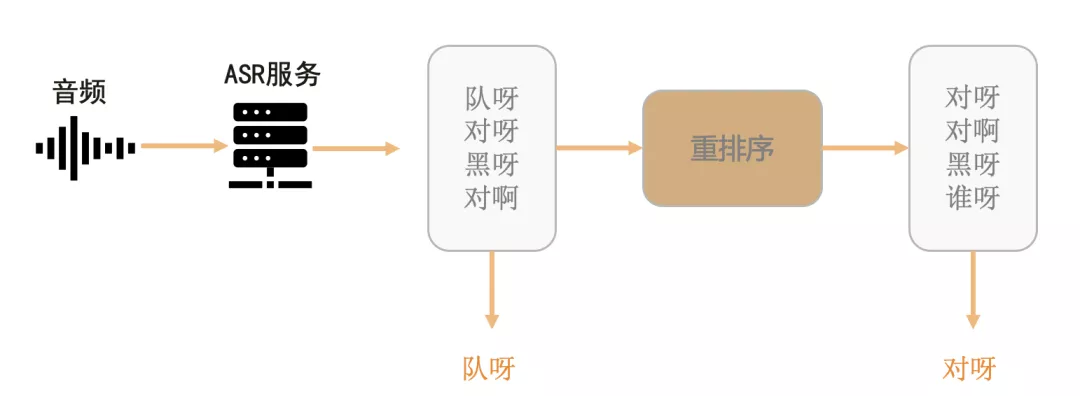
现有的语言识别服务一般采用 beam-search 方式进行解码,最终往往得到 N 个可能的解码结果(即为 N-best),上图所示,其中 N=4;最后采用 N-best 中得分最高的候选序列作为识别结果。采用得分最高的序列作为识别结果在实际上是存在某些问题的,通过一些解码实验我们发现,如果系统每次都选取 N-best 中与文本标注编辑距离最小的结果作为输出,准确率会比直接选取得分最高的结果高大约 5 个百分点。因此我们提出基于 LSTM 语言模型的重排序框架,如下图所示。
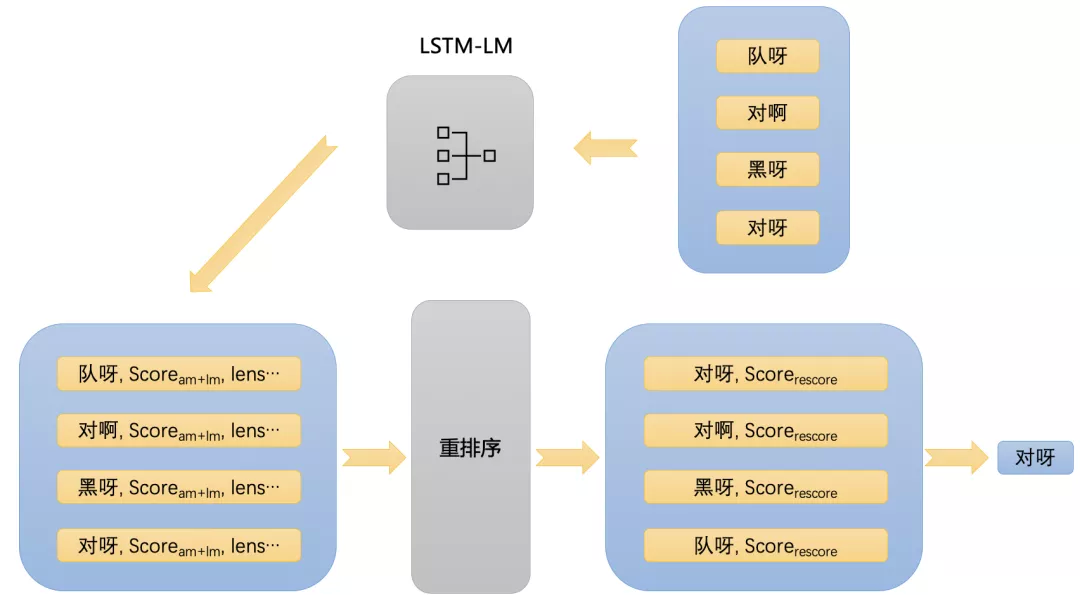
在重排序框架中,ASR 服务输出的 N-best 序列及其对应模型分数,接着我们将 N-best 序列输入到预先训练好的 LSTM 语言模型中得到语言模型得分,然后将 N-best 序列及其对应得分、lens 等特征输入重排序模型中打分,最后选取打分最高的序列作为输出。本质上重排序模型的作用在于通过 LSTM 语言模型去学习如何判断 ASR 服务的识别结果是否正确,并通过打分对其进行重新排序,从而获得更好的识别效果。
3.2.3 文本数据回流
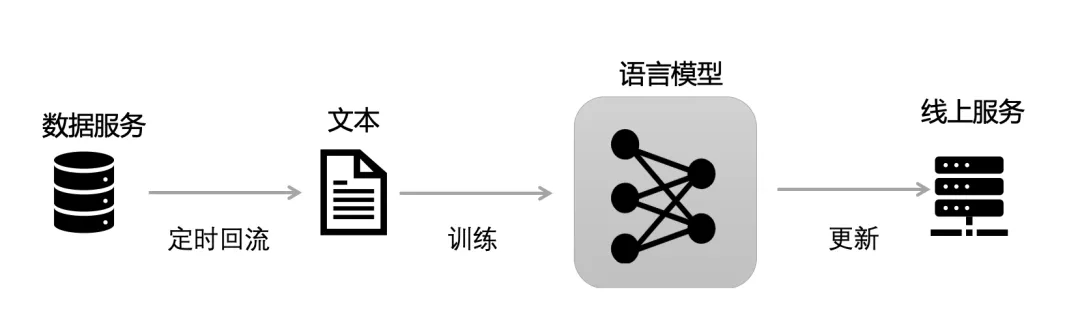
在很多业务场景中,文本数据是慢慢通过线上模型对业务实际场景音频的解码和置信度筛选不断累积的,因此我们构建了一个支持定期拉取业务数据更新语言模型的周期任务。在该任务中,系统定期从数据云服务中拉取回流的数据对线上模型进行迭代训练,以保持 ASR 服务对最新业务场景的鲁棒性。
4. 产品落地
在滴滴夸项目中,我们使用自学习平台定制周期性数据回流-模型迭代任务,每周定时从 MySQL 服务中拉取线上回流数据更新线上服务语言模型。经过 2~3 个月模型迭代,滴滴夸 ASR 服务字准从 80%提升到 90%,效果显著。
在 D1 定制车项目中,我们使用后处理服务和模型自训练服务对线上 ASR 服务进行个性化的定制及优化。经过多轮测试和优化后,语音交互成功率从 80%提升至 95%以上。
作者介绍:
Zomens
滴滴高级算法工程师
Monica
滴滴算法工程师
Molly
滴滴资深算法工程师
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:




