
作者 | 谢宣松 阿里达摩院开放视觉智能负责人
审校 | 刘燕
11 月 3 日,在 2022 云栖大会上,阿里达摩院联手 CCF 开源发展委员会共同推出了 AI 模型社区“魔搭”ModelScope,旨在降低 AI 的应用门槛。
AI 模型较为复杂,尤其是要应用于行业场景,往往需要重新训练,这使得 AI 只掌握在少数算法人员手中,难以走向大众化。而新推出的魔搭社区 ModelScope,践行模型即服务的新理念(Model as a Service),提供众多预训练基础模型,只需针对具体场景再稍作调优,就能快速投入使用。
达摩院率先向魔搭社区贡献 300 多个经过验证的优质 AI 模型,超过 1/3 为中文模型,全面开源开放,并且把模型变为直接可用的服务。社区首批开源模型包括视觉、语音、自然语言处理、多模态等 AI 主要方向,并向 AI for Science 等新领域积极探索,覆盖的主流任务超过 60 个。模型均经过专家筛选和效果验证,包括 150 多个 SOTA(业界领先)模型和 10 多个大模型,全面开源且开放使用。
本文,阿里达摩院开放视觉智能负责人谢宣松,深入解析了魔搭社区里首批开源的 101 个视觉 AI 模型。
计算机视觉是人工智能的基石,也是应用最广泛的 AI 技术,从日常手机解锁使用的人脸识别,再到火热的产业前沿自动驾驶,视觉 AI 都大显身手。作为一名视觉 AI 研究者,我认为视觉 AI 的潜能远未得到充分发挥,穷尽我们这些研究者的力量,也只能覆盖少数行业和场景,远未能满足全社会的需求。
因此,在 AI 模型社区魔搭 ModelScope 上,我们决定全面开源达摩院研发的视觉 AI 模型,首批达 101 个,其中多数为 SOTA 或经过实践检验。我们希望让更多开发者来使用视觉 AI,更期待 AI 能成为人类社会前进的动力之一。
魔搭社区地址:modelscope.cn
一、概要:以人为中心的视觉 AI
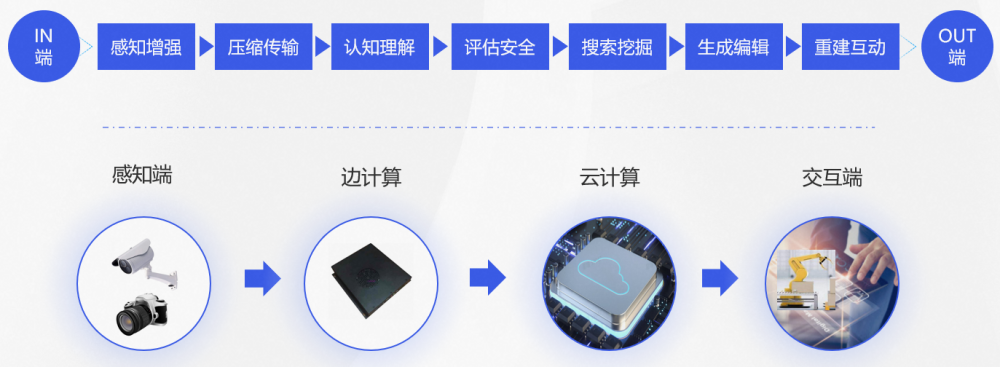
这些年来,达摩院作为阿里巴巴的基础科研机构和人才高地,在阿里海量业务场景中研发出一批优秀的视觉 AI 能力,分布在各个环节:
这些视觉 AI 技术,几乎覆盖了从理解到生成等各方面。因视觉技术任务众多,我们需要有一个相对合理的分类方法,可以从模态、对象、功能、场景等几个维度来分:
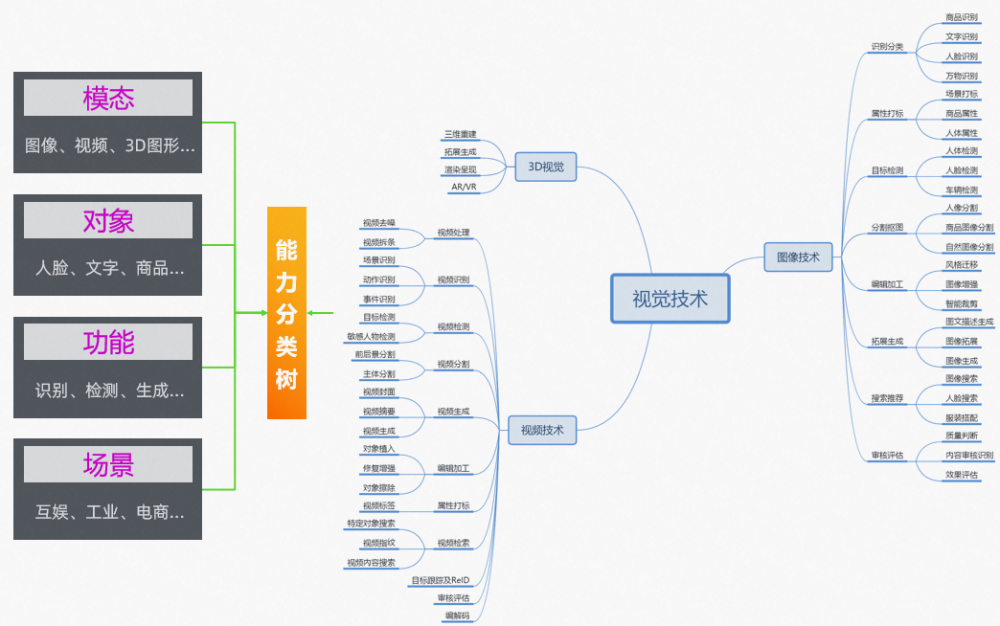
魔搭社区首批开放了主要的视觉任务模型,这些模型即有学术创新的 SOTA 技术,也有久经考验的实战模型,从”功能 / 任务“的维度上,涵盖了常见的感知、理解、生产等大类:

虽然视觉技术有点庞杂,但其实有个核心,那就是研究“对象”,“人”一直以来都是最重要的“对象”。“以人为中心“的视觉 AI 技术,也是研究最早最深、使用最普遍的技术。我们以一个人的照片作为起点。AI 首先需要理解这个照片 / 图像,如识别这个照片是谁,有什么动作,能否抠出像等。然后,我们还需要进一步探索:照片质量如何,能否画质变得更好,其中的人能否变得更漂亮,甚至变成卡通人、数字人等...
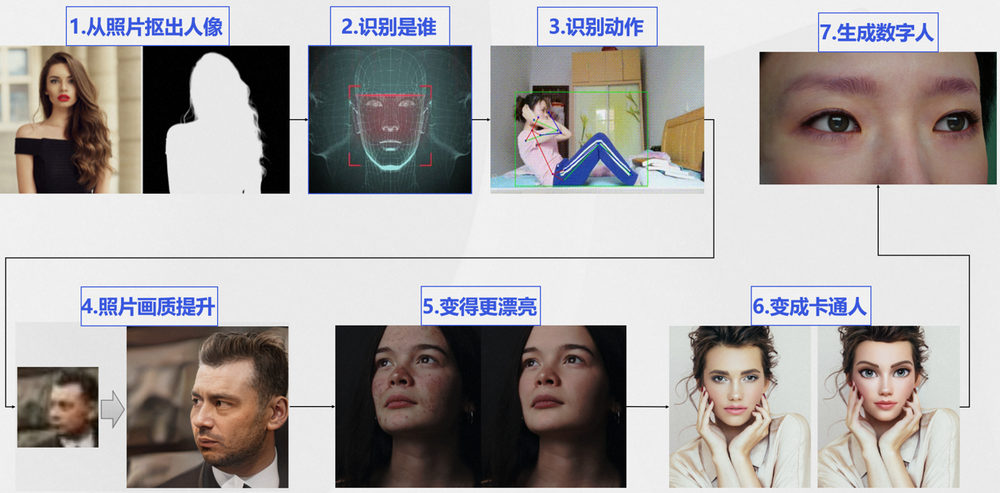
如上的 7 个“人”相关的流程,基本涵盖了视觉任务中的“理解”、“增强”、“编辑”等大类,我们以魔搭社区已开放的相关模型为实例,来分享以人为中心的视觉技术的特点、优点、示例以及应用。
二、感知理解类模型
1、从照片抠出人像
模型名:BSHM 人像抠图
体验链接:
https://www.modelscope.cn/models/damo/cv_unet_image-matting/
从照片抠出人像,去掉背景,是一个非常普遍的需求,也是“PS”的基本操作之一,但传统人工操作费时费力、且效果不佳。魔搭提供的人像抠图模型,是一个 全自动、端到端的人像抠图模型,能够实现发丝级别的精细分割。




技术上我们也进行了创新,不同于其他模型基于大量精细标注数据训练的方法,我们的模型使用粗标注数据就能实现精细抠图,对数据要求低、精度高。
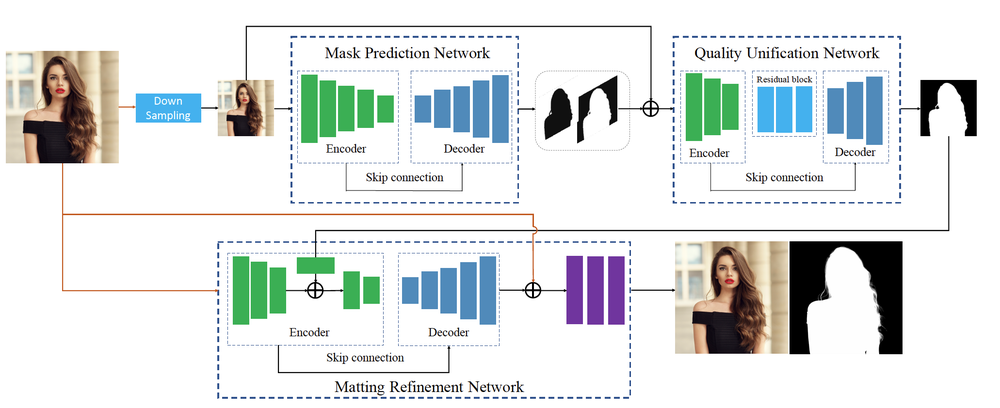
具体来说,模型框架分为三部分:粗 mask 估计网络(MPN)、质量统一化网络(QUN)、以及精确 alpha matte 估计网络(MRN)。我们首先将复杂问题拆解,先粗分割(MPN)再精细化分割(MRN)。学术界有大量易获取的粗分割数据,但是粗分割数据和精分割数据不一致导致预期 GAP 很大,故而我们又设计了质量统一化网络(QUN)。MPN 的用途是估计粗语义信息(粗 mask),使用粗标注数据和精标注数据一起训练。QUN 是质量统一化网络,用以规范粗 mask 质量,QUN 可以统一 MPN 输出的粗 mask 质量。MRN 网络输入原图和经过 QUN 规范化后的粗 mask,估计精确的 alpha matte,使用精确标注数据训练。
当然,抠图分割相关的需求非常多样化,我们也上线了一系列模型,支持非人像抠图以及视频抠图等。开发者可以直接拿来即用,如进行辅助设计师抠图,一键抠图,大幅提升设计效率,或者自由换背景,可实现会议虚拟背景、证件照、穿越等效果。这些也在阿里自有产品(如钉钉视频会议)及云上客户广泛使用。

2、人体关键点及动作识别
模型名字:HRNet 人体关键点 -2D
体验链接:
https://www.modelscope.cn/models/damo/cv_hrnetv2w32_body-2d-keypoints_image/
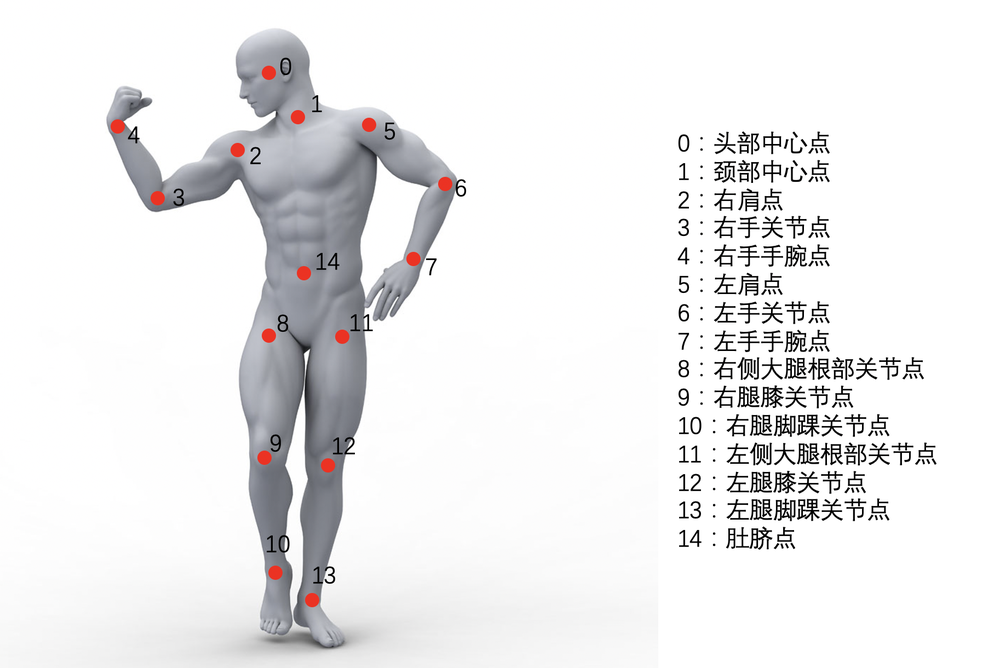
该任务采用自顶向下的人体关键点检测框架,通过端对端的快速推理可以得到图像中的 15 点人体关键点。其中人体关键点模型基于 HRNet 改进的 backbone,充分利用多分辨率的特征较好地支持日常人体姿态,在 COCO 数据集的 AP 和 AR50 上取得更高精度,同时我们也针对体育健身场景做了优化,尤其是在瑜伽、健身等场景下多遮挡、非常见、多卧姿等姿态上具有 SOTA 的检测精度。


为了更好的适用于各种场景,我们持续进行优化:
针对通用场景的大模型在指标上达到 SOTA 性能;
针对移动端部署的小模型,内存占用小,运行快、性能稳定,在千元机上达到 25~30FPS;
针对瑜伽、跳绳技术、仰卧起坐、俯卧撑、高抬腿等体育健身计数和打分场景下多遮挡、非常见、多卧姿姿态等情况做了深度优化,提升算法精度和准确度。
本模型已经广泛应用于 AI 体育健身、体育测试场景,如阿里体育乐动力,钉钉运动,健身镜等,也可应用于 3D 关键点检测和 3D 人体重建等场景。

3、小结
上述三个“人”相关的模型,都属于感知理解这个大类。先认识世界,再改造世界,感知理解类视觉技术是最基础、也是应用最广泛的模型大类,也可以分为识别、检测和分割三小类:
识别 / 分类是视觉(包括图像、视频等)技术中最基础也是最经典的任务,也是生物通过眼睛了解世界最基本的能力。简单来说,判定一组图像数据中是否包含某个特定的物体,图像特征或运动状态,知道图像视频中描述的对象和内容是什么。此外,还需要了解一些更细维度的信息,或者非实体对象的一些描述标签。
目标检测的任务是找出视觉内容中感兴趣的目标(物体),确定它们的位置和大小,也是机器视觉领域的核心问题之一。一般来说,也会同时对定位到的目标进行分类识别。
分割是视觉任务中又一个核心任务,相对于识别检测,它又更进一步,解决“每一个像素属于哪个目标物或场景”的问题。是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。
魔搭社区上面开放了丰富的感知理解类模型,供 AI 开发者试用使用:

4. 彩蛋:DAMO-YOLO 首次放出
模型名字:DAMOYOLO- 高性能通用检测模型 -S
体验链接:
https://www.modelscope.cn/models/damo/cv_tinynas_object-detection_damoyolo/summary


通用目标检测是计算机视觉的基本问题之一,具有非常广泛的应用。DAMO-YOLO 是阿里新推出来的 目标检测框架,兼顾模型速度与精度,其效果超越了目前的一众 YOLO 系列方法,且推理速度更快。DAMO-YOLO 还提供高效的训练策略和便捷易用的部署工具,能帮助开发者快速解决工业落地中的实际问题。
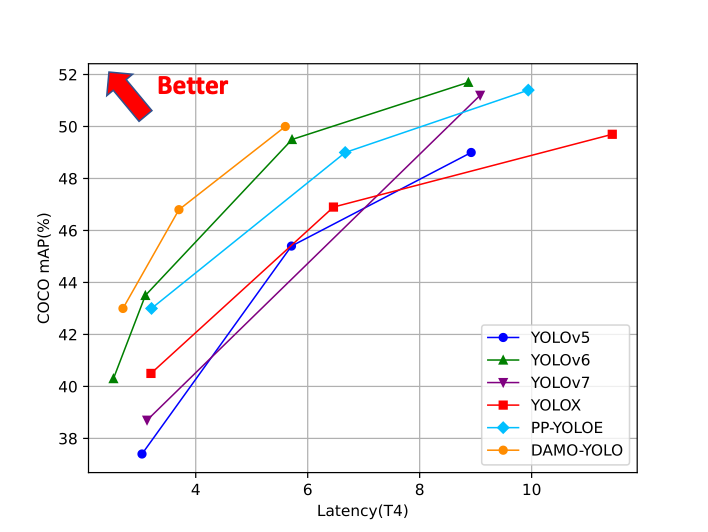
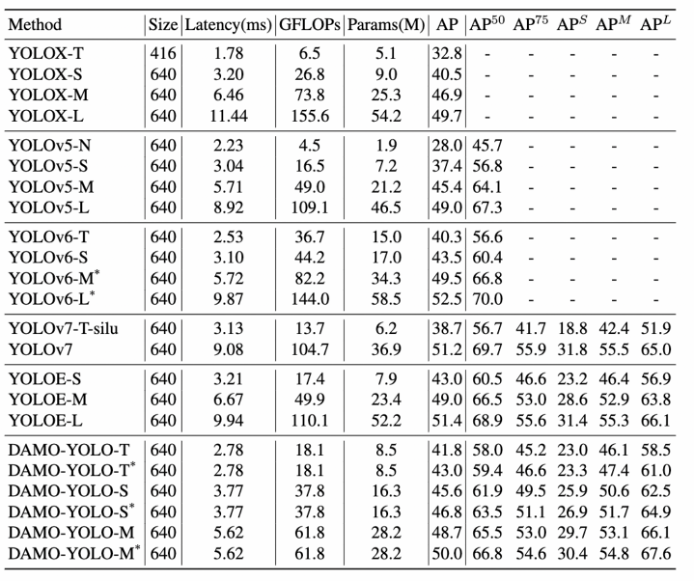
DAMO-YOLO 引入 TinyNAS 技术,使得用户可以根据硬件算力进行低成本的检测模型定制,提高硬件利用效率并且获得更高精度。另外,DAMO-YOLO 还对检测模型中的 neck、head 结构设计,以及训练时的标签分配、数据增广等关键因素进行了优化。由于做了一系列优化,DAMO-YOLO 在严格限制 Latency 的情况下精度取得了显著的提升,成为 YOLO 框架中的新 SOTA。
三、底层视觉模型
1. 照片去噪去模糊
模型名字:NAFNet 图像去噪
体验地址:
https://www.modelscope.cn/models/damo/cv_nafnet_image-denoise_sidd/
因拍摄环境、设备、操作等原因,图像质量不佳的情况时而存在,怎么对这些图像的噪声去除、模糊还原?该模型在图像恢复领域具有良好的泛化性,无论是图像去噪还是图像去模糊任务,都达到了目前的 SOTA。由于技术创新,该模型使用了简单的乘法操作替换了激活函数,在不影响性能的情况下提升了处理速度。


该模型全名叫 NAFNet 去噪模型,即非线性无激活网络(Nonlinear Activation Free Network),证明了常见的非线性激活函数(Sigmoid、ReLU、GELU、Softmax 等)不是必须的,它们是可以被移除或者是被乘法算法代替的。该模型是对 CNN 结构设计的重要创新。
本模型可以做为很多应用的前置步骤,如智能手机图像去噪、图像去运动模糊等。
2. 照片修复及增强
模型名字:GPEN 人像增强模型
体验地址:
https://www.modelscope.cn/models/damo/cv_gpen_image-portrait-enhancement/
除照片去噪以外,对照片的质量(包括分辨、细节纹理、色彩等)会有更高的处理要求,我们也开放了专门的人像增强模型,对输入图像中的每一个检测到的人像做修复和增强,并对图像中的非人像区域采用 RealESRNet 做两倍的超分辨率,最终返回修复后的完整图像。该模型能够鲁棒地处理绝大多数复杂的真实降质,修复严重损伤的人像。


从效果上看,GPEN 人像增强模型将预训练好的 StyleGAN2 网络作为 decoder 嵌入到完整模型中,并通过 finetune 的方式最终实现修复功能,在多项指标上达到行业领先的效果。后续我们将增加 1024、2048 等支持处理大分辨人脸的预训练模型,并在模型效果上持续更新迭代。从应用的视角,本模型可以修复家庭老照片或者明星的老照片,修复手机夜景拍摄的低质照片,修复老视频中的人像等。
3. 小结
底层视觉,关注的是画质问题。只要是生物(含人),都会对因光影而产生的细节、形状、颜色、流畅性等有感应,人对高画质的追求更是天然的,但由于各种现实条件,画质往往不理想,这时候视觉 AI 就能派上用场。
从任务分类上,可以分为:清晰度(分辨率 / 细节、噪声 / 划痕、帧率)、色彩(亮度、色偏等)、修瑕(肤质优化、去水印字幕)等,如下表:

四、编辑生成类模型
1. 变得更漂亮
模型名字:ABPN 人像美肤
体验链接:
https://www.modelscope.cn/models/damo/cv_unet_skin-retouching/
人们对照片人像的美观度是一个刚性需求,包括斑点、颜色、瑕疵等,甚至高矮胖瘦。本次我们开放了专业级别的人像美肤、液化等模型供大家使用。
本模型提出了一个新颖的自适应混合模块 ABM,其利用自适应混合图层实现了图像的局部精准修饰。此外,我们在 ABM 的基础上进一步构建了一个混合图层金字塔,实现了超高清图像的快速修饰。相比于现有的图像修饰方法,ABPN 在修饰精度、速度上均有较大提升。ABPN 人像美肤模型为 ABPN 模型在人像美肤任务中的具体应用。
如下示例:
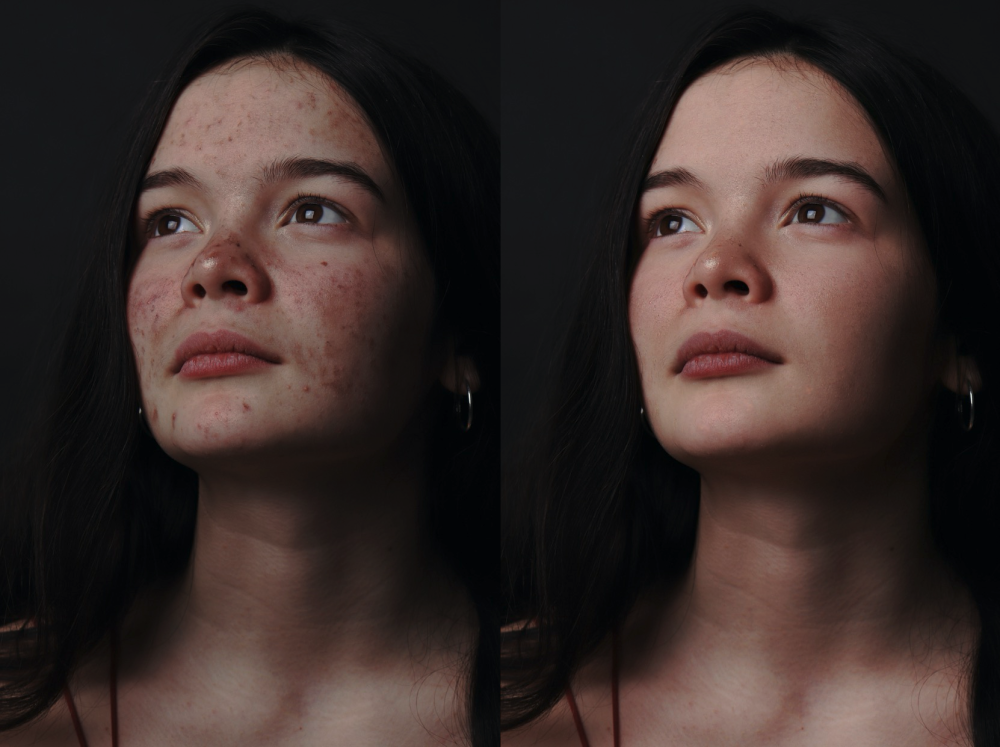

更进一步,我们还可以在服饰上做一些有意思的尝试,如去皱:


甚至瘦身美型:
https://www.modelscope.cn/models/damo/cv_flow-based-body-reshaping_damo/

从效果上来说,有如下几点特色:
局部修饰。只对目标区域进行编辑,保持非目标区域不动。
精准修饰。充分考虑目标本身的纹理特征和全局上下文信息,以实现精准修饰,去除瑕疵的同时保留皮肤本身的质感。
超高分辨率的处理能力。模型的混合图层金字塔设计,使其可以处理超高分辨率图像(4K~6K)。
本模型有很强的实用性,比如可应用于专业修图领域,如影楼、广告等,提高生产力,也可以应用于直播互娱场景,提升人像皮肤质感。
2. 变成卡通人
模型名:DCT-Net 人像卡通化模型
体验链接:https://www.modelscope.cn/models/damo/cv_unet_person-image-cartoon_compound-models/
人像卡通化是一个具有很好互动性的玩法,同时又有多种风格可选。魔搭开放的人像卡通化模型基于全新的域校准图像翻译网络 DCT-Net(Domain-Calibrated Translation)实现,采用了“先全局特征校准,再局部纹理转换”的核心思想,利用百张小样本风格数据,即可训练得到轻量稳定的风格转换器,实现高保真、强鲁棒、易拓展的高质量人像风格转换效果。
如下示例:

从效果上来看:
DCT-Net 具备内容匹配的高保真能力,能有效保留原图内容中的人物 ID、配饰、身体部件、背景等细节特征;
DCT-Net 具备面向复杂场景的强鲁棒能力,能轻松处理面部遮挡、稀有姿态等;
DCT-Net 在处理维度上和风格适配度上具有易拓展性,利用头部数据即可拓展至全身像 / 全图的精细化风格转换,同时模型具有通用普适性,适配于日漫风、3D、手绘等多种风格转换。
后续我们也会对卡通化进行系列化的开放,除图像转换外,后续将包含图像、视频、3D 卡通化等系列效果,先放一些效果大家看看:
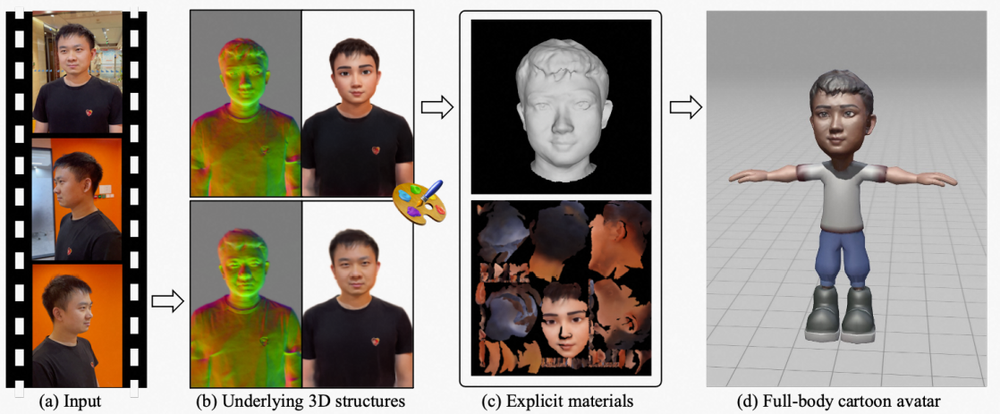
3. 小结
这类模型对图像内容进行修改,包括对源图内容进行编辑加工(增加内容、删除内容、改换内容等),或者直接生成一个新的视觉内容,转换一个风格,得到一张新的图像(基于源图像且与源图不同),都属于编辑生成这个大类,可以理解成,从 A 图得到 B 图的过程。
五、行业场景类模型
如最开始所说,视觉 AI 技术的价值体现,在广泛的各类场景中都存在,除了上述“人”相关的视觉 AI 技术,我们也开放了来自互联网、工业、互娱、传媒、安全、医疗等多个实战型的模型,这些模型可以拿来即用,也可以基于 finetune 训练或自学习工具进一步加工完善,用于开发者、客户特定的场景,这里举一个例子:
模型名:烟火检测(正在集成中)
模型功能: 可做室外、室内的火焰检测以及烟雾检测,森林、城市道路、园区,卧室、办公区域、厨房、吸烟场所等,算法打磨近 2 年,并在多个客户场景实际应用,整体效果相对稳定。

从技术视角来说,本模型提出 Correlation block 提升多帧检测精度,其设计数据增强方法提高识别灵敏度同时有效控制误报。从应用上来说,模型可应用于室内、室外多种场景,只需要手机拍摄、监控摄像头等简单设备就可以实现模型功能。
六、结语:视觉 AI 的开放未来
通过上述分析,我们可以发现,视觉 AI 的应用潜能极为广泛,社会需求极为多样,但现实情况却是:视觉 AI 的供给能力非常有限。
达摩院在魔搭 ModelScope 之前,就率先开放了 API 形态的视觉 AI 服务,通过公共云平台对 AI 开发者提供一站式视觉在线服务平台,即视觉智能开放平台(vision.aliyun.com),其中开放了超 200 个 API,涵盖了基础视觉、行业视觉等方面,也包括上面所说的“以人为中心”的视觉技术。

从开放视觉平台到魔搭社区,这意味着达摩院视觉 AI 的开放迈出了更大的一步。从 OpenAPI 拓展到 OpenSDK、OpenSOTA,从公共云到端云协同,从平台到社区,我们希望去满足千行百业对视觉 AI 的需求,希望促进视觉 AI 的生态发展。

试用链接🫥
人像抠图:https://www.modelscope.cn/models/damo/cv_unet_image-matting/🫣
人脸检测:https://www.modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/
🕺🏻人体关键点动作识别:https://www.modelscope.cn/models/damo/cv_hrnetv2w32_body-2d-keypoints_image/
图像去噪:https://www.modelscope.cn/models/damo/cv_nafnet_image-denoise_sidd/
照片修复增强:https://www.modelscope.cn/models/damo/cv_gpen_image-portrait-enhancement/
💆🏻♀️美肤:https://www.modelscope.cn/models/damo/cv_unet_skin-retouching/
💃🏻瘦身美型:https://www.modelscope.cn/models/damo/cv_flow-based-body-reshaping_damo/🥸人脸卡通化:https://www.modelscope.cn/models/damo/cv_unet_person-image-cartoon_compound-models/




