
导读: 小米知识图谱于 2017 年创立,已支持公司了每天亿级的访问,已赋能小爱同学,小米有品、智能问答、用户画像、虚拟助手、智能客服等互联网产品。通过引入知识图谱,这些产品在内容理解、用户理解、实体推荐等方面都有了显著的效果提升。本文的主要内容包括:
小米知识图谱介绍:包括小米的商业模式、小米人工智能部、知识图谱在人工智能部的定位、小米知识图谱的发展历程、以及小米知识图谱的落地场景。
小米知识图谱关键技术:小米知识图谱在成长过程中的技术积累。
小米行业知识图谱探索:结合业务,跟大家分享下小米在行业图谱上的探索。
01 小米知识图谱介绍
1. 小米知识图谱介绍

在了解小米知识图谱之前,先介绍下小米的商业模式。小米在商业模式上提出硬件+新零售+互联网铁人三项的商业模式。这种商业模式下有像手机、小米音箱类的智能硬件;有米商城,有品电商这样的新零售;还有像人工智能这样的互联网服务。三者相扶相持,相互促进,是一种闭环的生态模式,在这种生态模式下,有很多潜在的应用场景,对人工智能,对内容和知识有很多诉求。
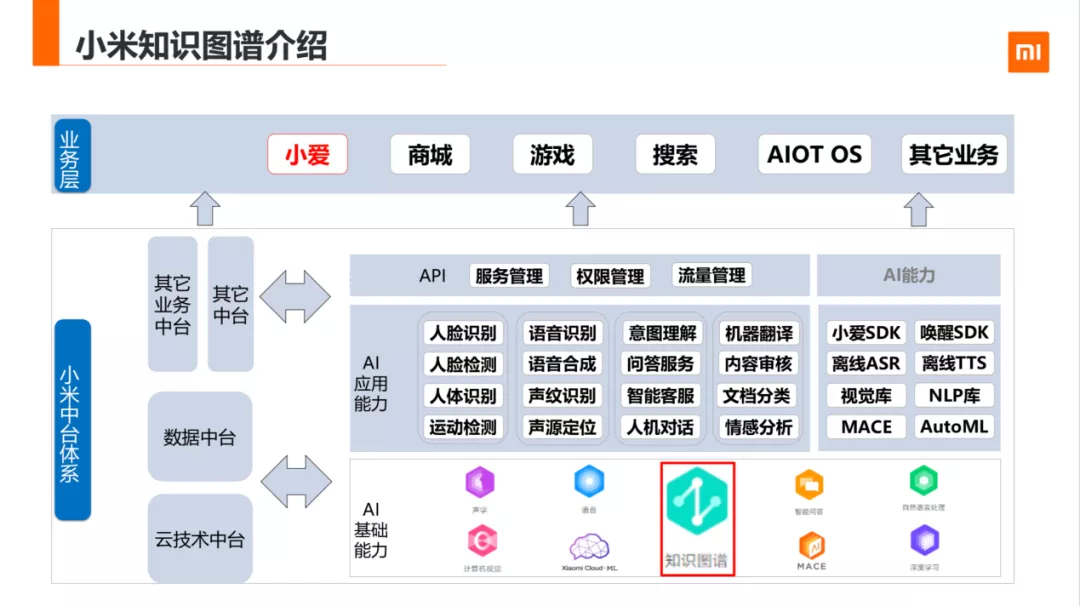
小米人工智能部已经构建了完整的中台体系,囊括了视觉、NLP、知识图谱、语音、深度学习等底层的基础能力,其中知识图谱就处于这一层。
中间层是问答服务、智能客服等应用能力层,上层是小爱同学、商城等互联网业务和传统业务层,这些都是知识图谱的落地场景,其中小爱同学是小米公司推出的虚拟人工的智能助理,小爱同学适用于手机、音响、电视、手表以及手环等穿戴设备,通过搭载小爱同学的智能硬件,可以满足用户获取知识和信息的需求。
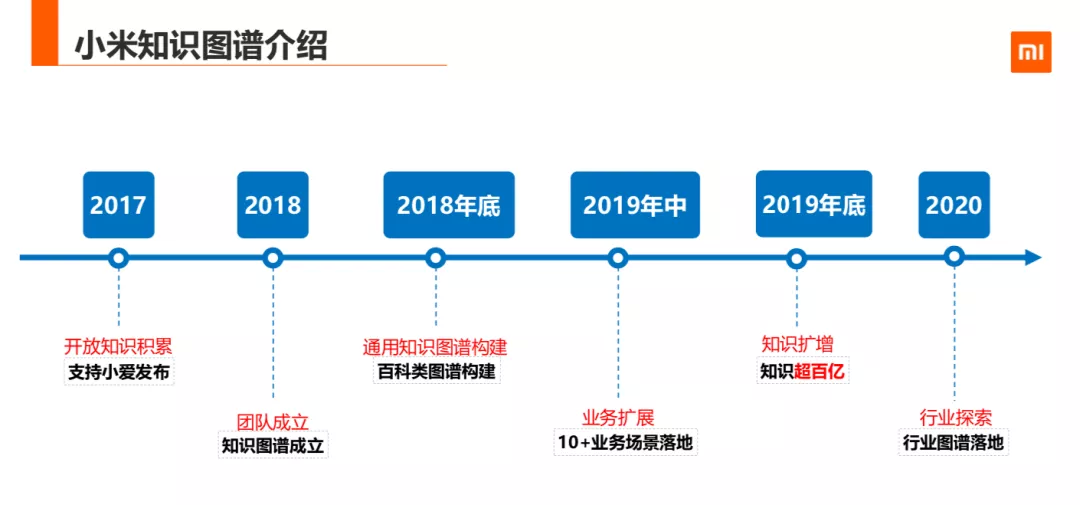
小米知识图谱在中台体系下不断的成长,2017 年小米知识图谱有了一些开放知识的积累, 2018 年知识图谱团队成立,2018 年底,通用知识图谱的构建,百科类图谱构建完成,2019 年中,业务拓展,线上调用达到近亿次,2019 年底,知识扩增,知识积累了超三百亿,2020 年行业探索,行业图谱落地。虽然发展的比较晚,但是在自己的业务场景下,发展还算迅速。
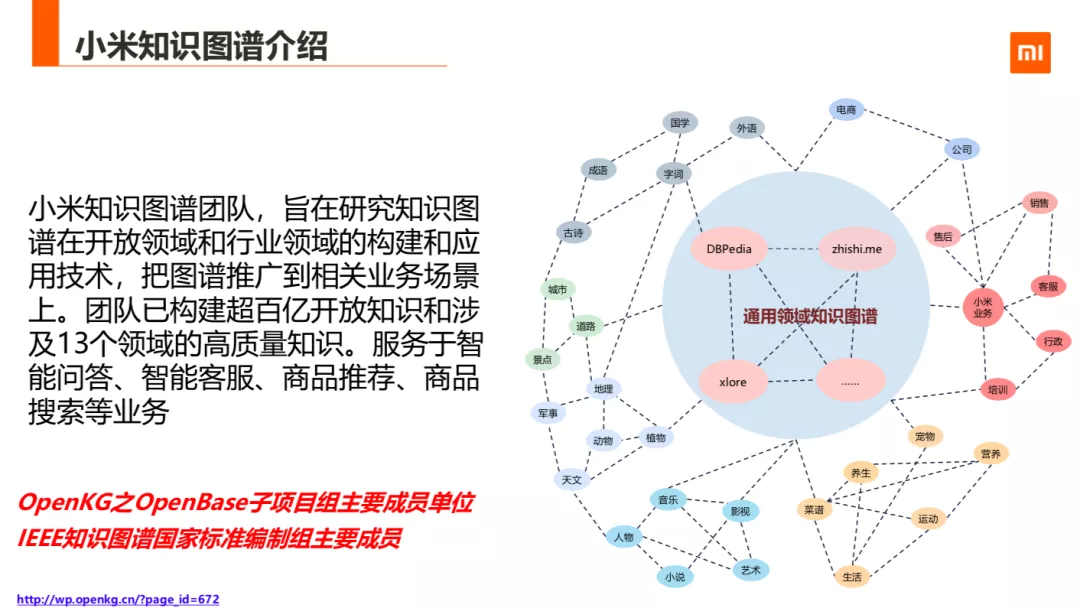
小米知识图谱在公司的职责,主要是研究开放领域和行业领域的构建和应用技术,并把图谱推广到相关业务场景上,来提高用户的满意度的和业务变现转化能力。团队已构建超三百亿开放知识和涉及 13 个领域。除此之外,小米还参与了一些开放知识图谱的构建,是 OpenKG 之 OpenBase 子项目组主要成员单位,是 IEEE 知识图谱国家标准编制组主要成员。

小米知识图谱已经已经赋能公司 10+个业务场景,这些落地场景包括智能问答、智能客服、小爱同学、虚拟助手、全局搜索、NLP 等这样通用的知识领域。还有像游戏中心、广告,小米有品,小米网等这样的行业知识,下面我会重点介绍一下具体场景的细节。
2. 应用场景:智能问答

第一个是小米知识图谱在智能问答场景的应用,这个比较广泛,落地的设备较多,已服务于手机、音响、智能穿戴、智能车载、电视、儿童设备。应用于小爱音响、小爱同学、小寻手表、车载设备等,满足用户近亿次/天的请求,后面我们介绍落地场景的示例。
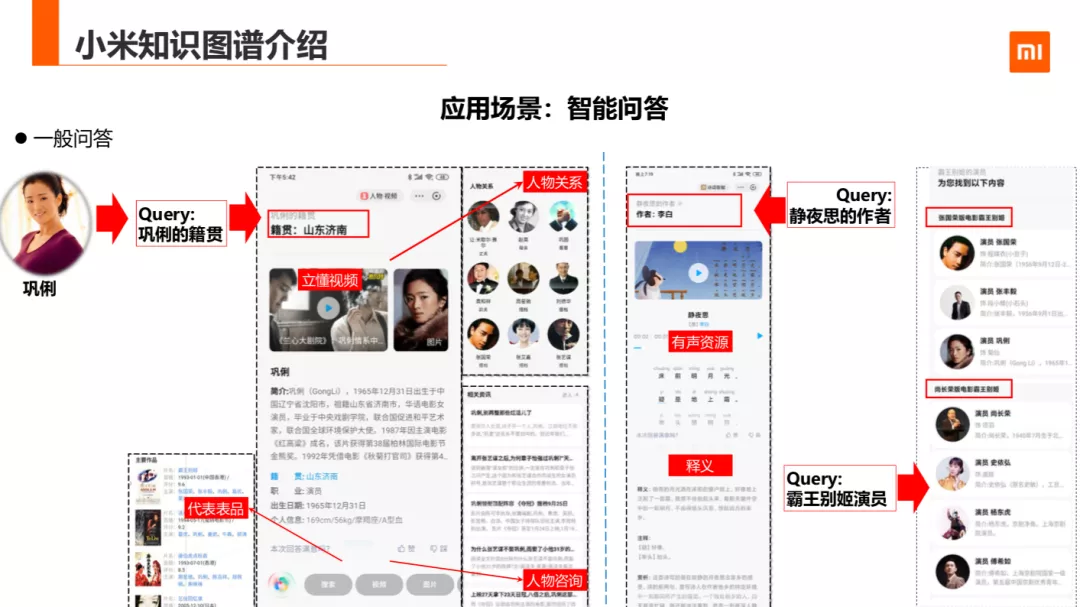
目前,智能问答包括两种模式:一种是一般问答模式,还有一种是规则推理的。一般问答场景下,在返回具体答案的同时,还会把关联实体的附加信息满足给用户,比如用户询问巩俐的籍贯的时候,返回答案不只是会返回山东济南,还会把问答实体巩俐的视频,人物关系,资讯新闻,代表作品等都呈现给用户,这样在用户兴趣激发上起到了很大作用。另外一个古诗词 CASE,也能很好的体现这一点,比如用户问静夜思的作者是谁,用户除了想得到这首诗的作者外,可能还想温故这首诗,也可能想要了解这首诗的释义。所以我们会把有声资源、释义一并满足给用户。
最后,问答在歧义场景下还支持列表形式展现。
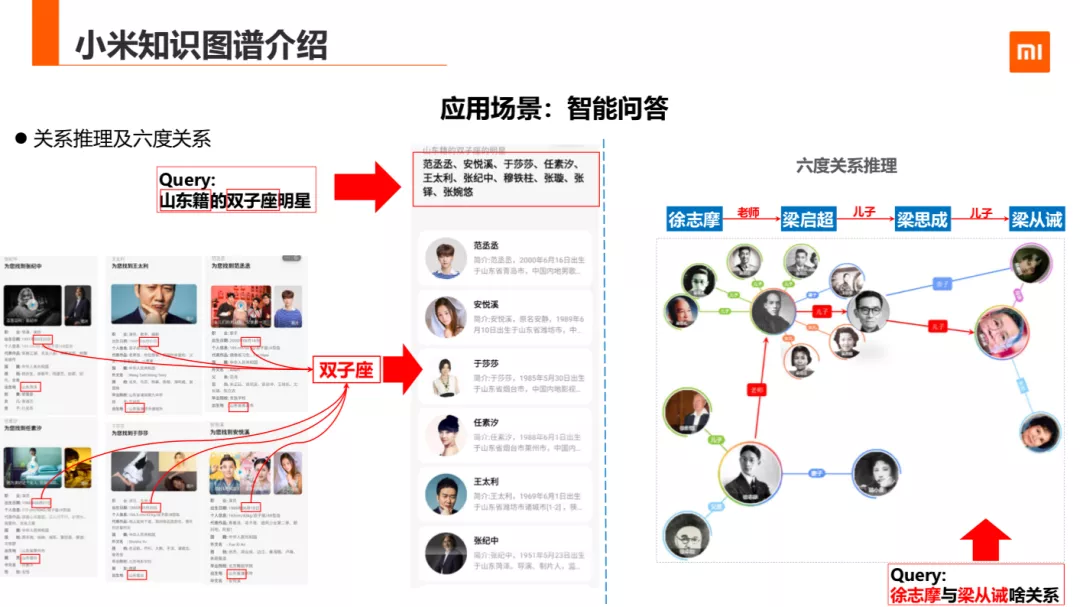
除了一般的问答方式以外,小米还支持推理的问答。比如:多条件推理,多跳关系推理,还支持像求最大值,最小值这种基础推理算子。多条件推理的例子如:山东籍的双子座是谁,首先会对数据库中人物实体的生日推理出星座是双子座,然后推出省份,最后筛选聚合产出实体结果 ,第二种是多跳关系推理,比较典型的就是人物与人物的六度关系推理,如:徐志摩与梁思成的儿子梁从诫是什么关系?我们会试图计算起始实体到目标实体的关系的最短可达路径呈现给用户。现有的推理逻方法,比如说基于规则的推理、基于模型的推理,规则推理主要包含规则引擎和一阶的逻辑规则。模型推理是用机器学习去表示学习关系推理。所以这里根据自己的需求、应用场景和应用情况去选择。
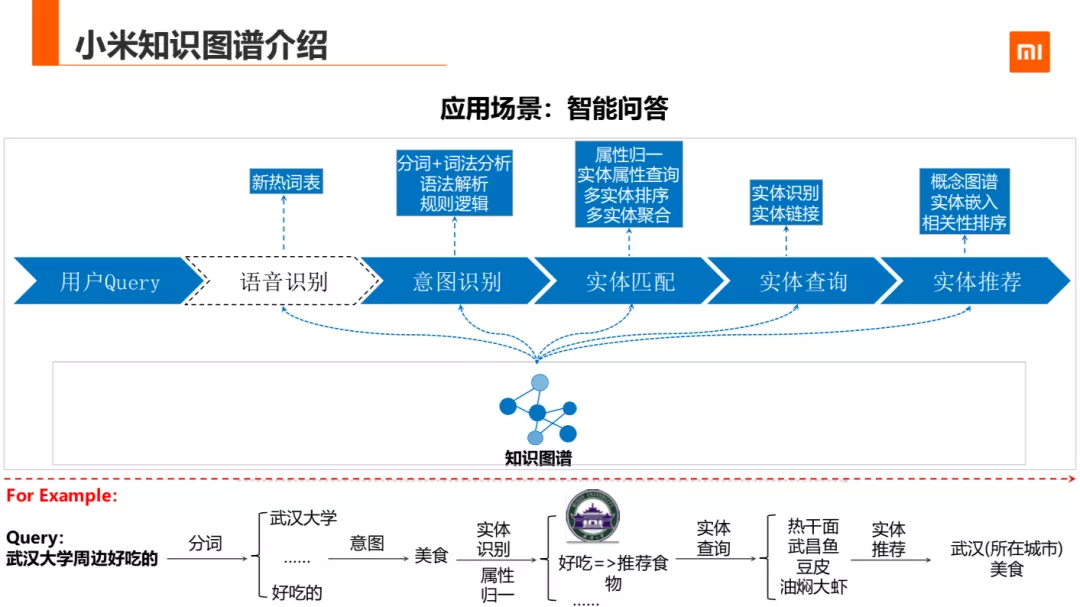
后面介绍一些基于智能问答的一些方法。基于图谱的智能问答,通用流程如下:语音识别环节,意图识别,实体匹配,实体查询返回结果。
举个例子,如武汉大学周边什么好吃的,首先做分词或者词法分析,分出武汉大学和好吃的这些关键 mention,然后意图识别计算得到是美食需求的,第三步是实体识别,把 mention 武汉大学映射到知识图谱中的实体上,把属性好吃映射成推荐食物,最后实体查询计算,返回热干面,武昌鱼,豆皮,油焖大虾。
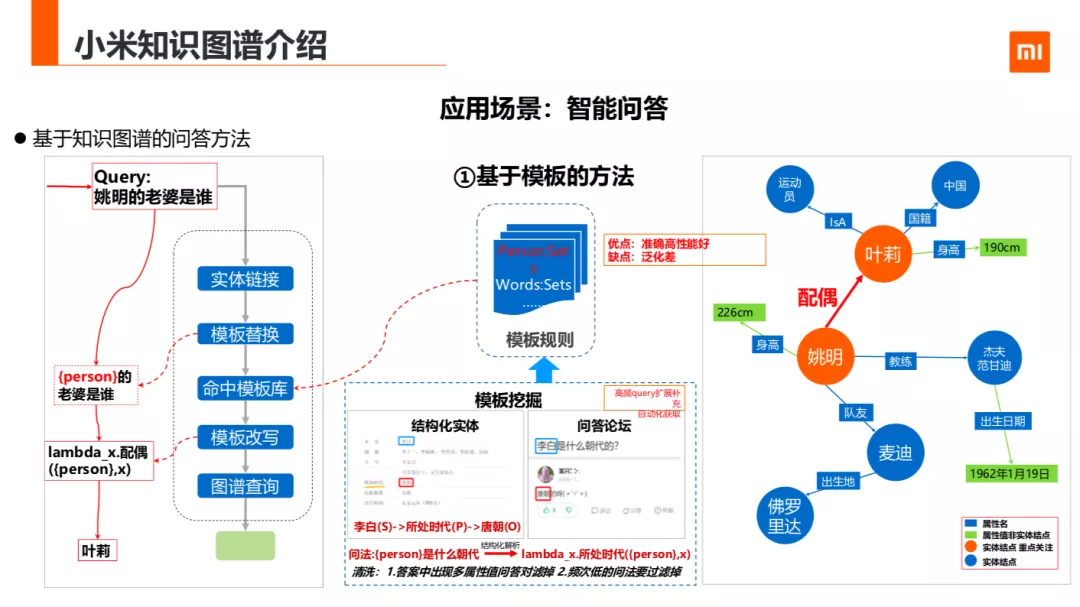
小米基于知识问答有很多方法,第一种是基于模版的方法,它的大体流程是这样的:
第一步对 query 做实体链接(实体链接技术在第二部分会详细介绍),第二步把实体名用实体链接后的主实体对应的实体类型替换后去离线的模板库匹配,返回模板库中映射后的归一的模版,最后查询实体库返回答案。
举个例子:
姚明的老婆是谁,第一步先做实体链接,后面把姚明的实体类型人物替换姚明,去人物垂域模板规则库查询模板,发现命中了 lambda_x.配偶这个模板。最后在图谱数据国查询姚明的配偶,返回答案叶莉。这种方法有一个好处就是准确率比较好,是离线挖掘的模板,所以性能也比较好,但是缺点也比较明显泛化能力差。其中模板的挖掘方法的话,主要是离线从知识图谱中实体中找目标实体对,然后去问答论坛去匹配问题与答案分别出现的 pair,生成模板的 pair,这么做会有很多噪声需要做进一步过滤,比如:需要过滤掉出现多属性的问答对的情况和频次出现比较低的情况。
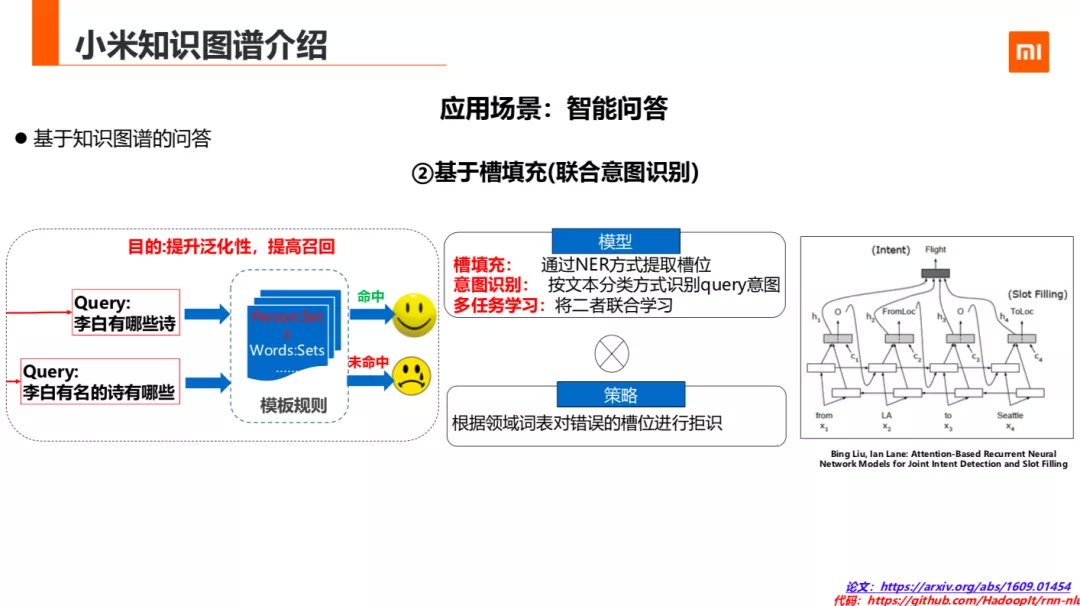
为了解决第一种方法泛化性能比较差的问题,用第二种方式基于槽填充的方式来互补。第一种方法在李白有哪些诗的时候,可以命中模版库满足用户的需求。但是变成李白有名的诗有哪些时,就无法找到答案了。为了解决这种问题,我们用了槽填充和意图识别联合学习的方法方法,借鉴了 2016 年 liu 的基于 attention 的意图检测和插槽填充联合学习的的方法。该方法把槽填充与意图识别联合的学习,方法包含两部分槽填充和意图识别,两部分组成,第一部分是槽填充问题转化为序列标注的 NER 问题,第二步是意图识别,把意图识别转换为文本分类问题。最后把两个问题整合做一个联合学习。PPT 右下角已给出论文和代码。该方法在部分垂哉上的召回的提升比较明显。在菜谱,古诗垂域上欠召回的 badcase 解决率为 30%
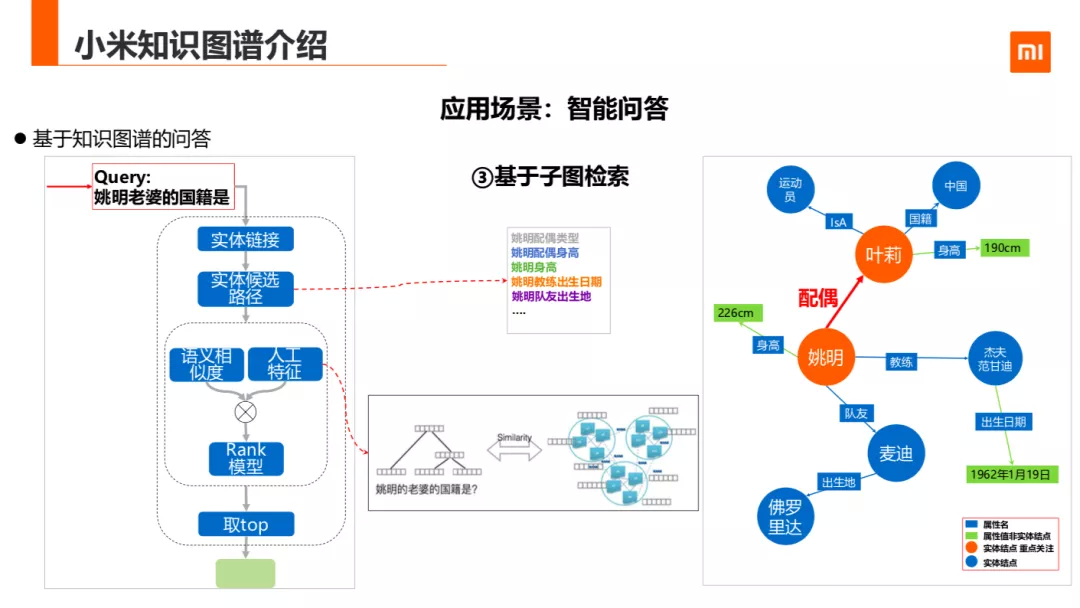
第三种方法是基于子图检索,该方法依赖于实体的关系路径。具体第一步 query 做实体链接,把实体转化为实体 ID,第二步根据实体周围的属性筛选出候选路径。第三步对输入文本与候选路径进行实体语义相似和排序,取 top 结果。
以姚明老婆的国籍是啥为例子,第一步用实体链接找到用到接接到知识图谱姚明这个实体;第二步就是找到姚明这个实体周边的候选的属性路径,如姚明的配偶的国籍,姚明配偶的身高,姚明配偶的类型,姚明教练的出生日期,姚明队友的出生地等;第三步用 bert 计算候选路径和目标路径的相似关系,除了相似度外,引入了像类型过滤这样的条件约束,过滤给出排序分值然后取一个最大值。
以上都是基于图谱的结构化的问答场景,对于非结构的, 比如:天空为什么是蓝色的,怎么控制猫的饮食量,青蛙王子是不是安徒生的童话,这三种为什么,怎么样,是不是,类型的问题,以上方法无法解决,需要通过基于搜索的 FAQ 的方式,这里就不介绍了。
3. 应用场景:智能客服
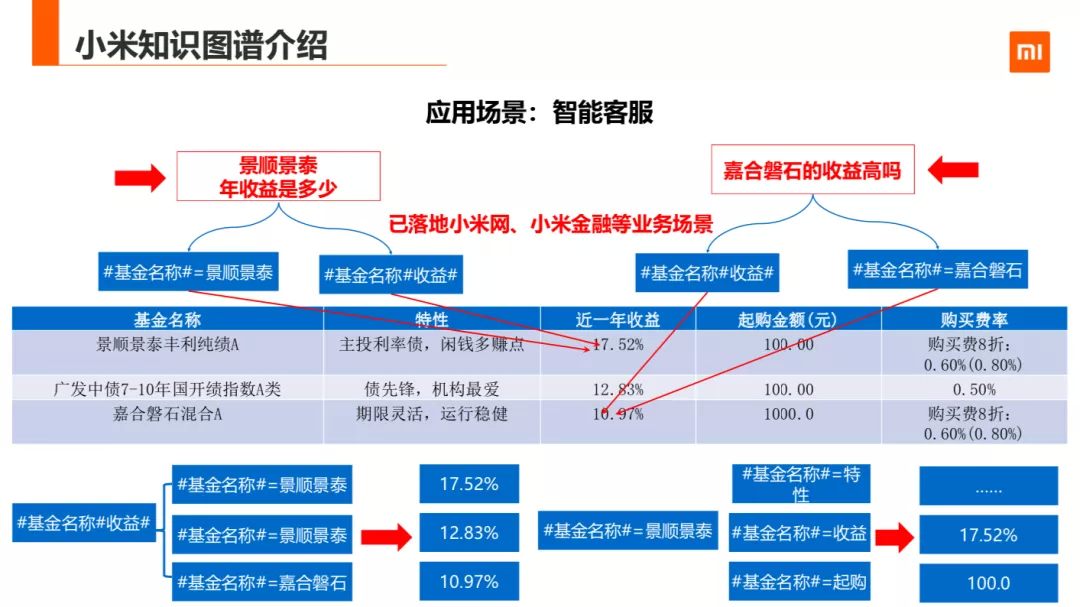
第二个是知识图谱到智能客服的场景。目前智能客服已经落地小米网和小米金融等业务场景下。PPT 中是智能客服团队用 NL2SQL 的方法在基金客服上的一个落地场景。
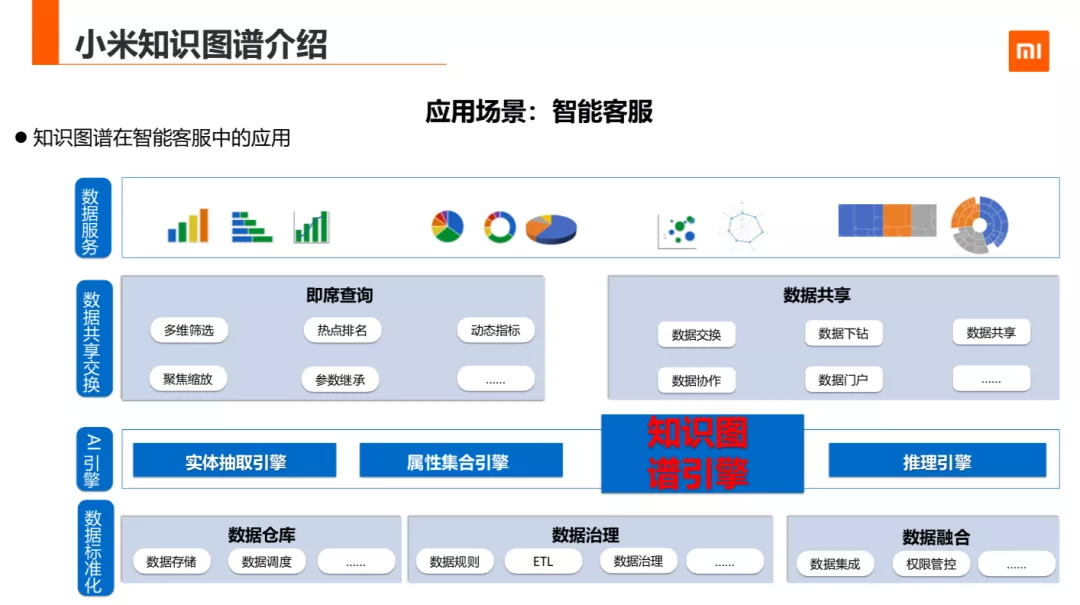
知识图谱在智能客服中的技术框图体系,第一层是数据标准化层,主要包括数据仓库,数据治理,数据融合,第二层是 AI 引擎层,有实体抽取引擎,属性集合引擎、知识图谱引擎等,第三层是数据共享交换层,第四层是数据服务,数据分析等。
4. 应用场景:小米商城 &游戏中心
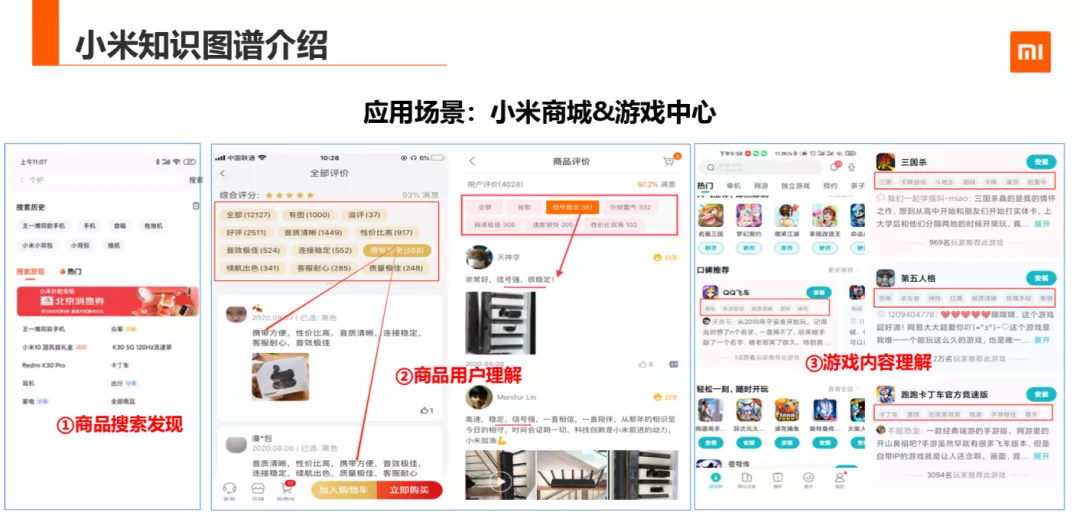
第三个应用场景是在小米商城和游戏中心的应用,目前商品图谱和游戏图谱已应用到小米商城,有品商城,游戏中心等业务下。已落在有品商城/小米商城的场景词搜索发现、用户 sug 引导、商品评价的用户观点的的用户观点的抽取及聚合,及游戏的评论的观点抽取及聚合业务上。在小米的商品图谱取得不错的效果,已助力商品转化率、用户购买转化率及游戏下载率至少有 30%的提升。
5. 应用场景:AI 虚拟助手
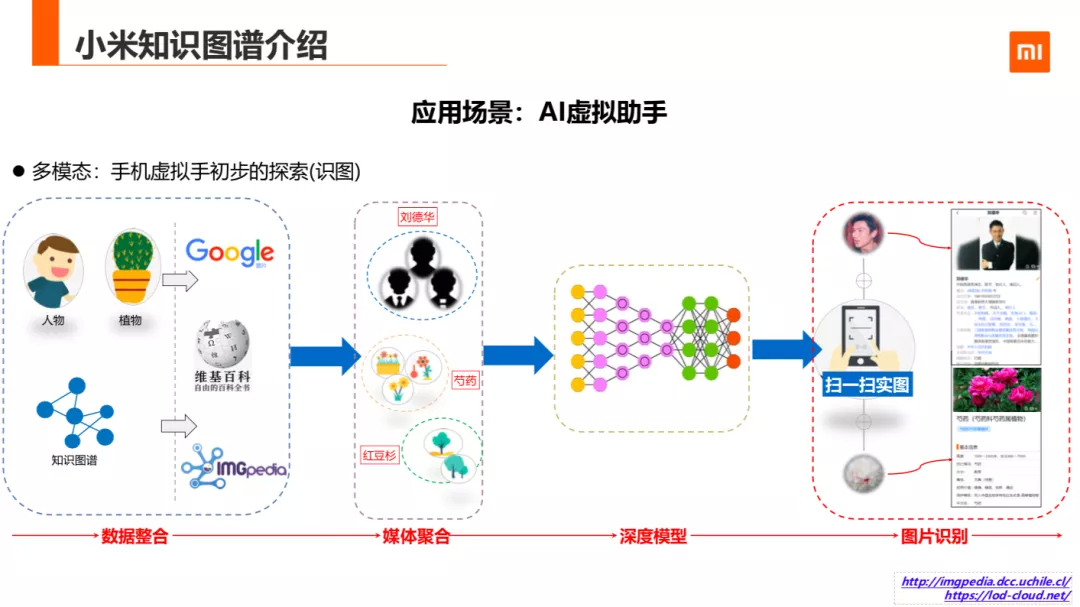
另外小米知识图谱还在多模态图谱应用场景下做了尝试,与 AI 虚拟助手合作探索了图片态与文本态实体语义关联,目前已上线植物识图的功能,后面会持续的扩展。小米知识图谱的落地场景很多,这里只介绍了一部分,后面是小米知识图谱积累的一些关键技术。
02 小米知识图谱关键技术
1. 小米知识图谱赋能各业务场景
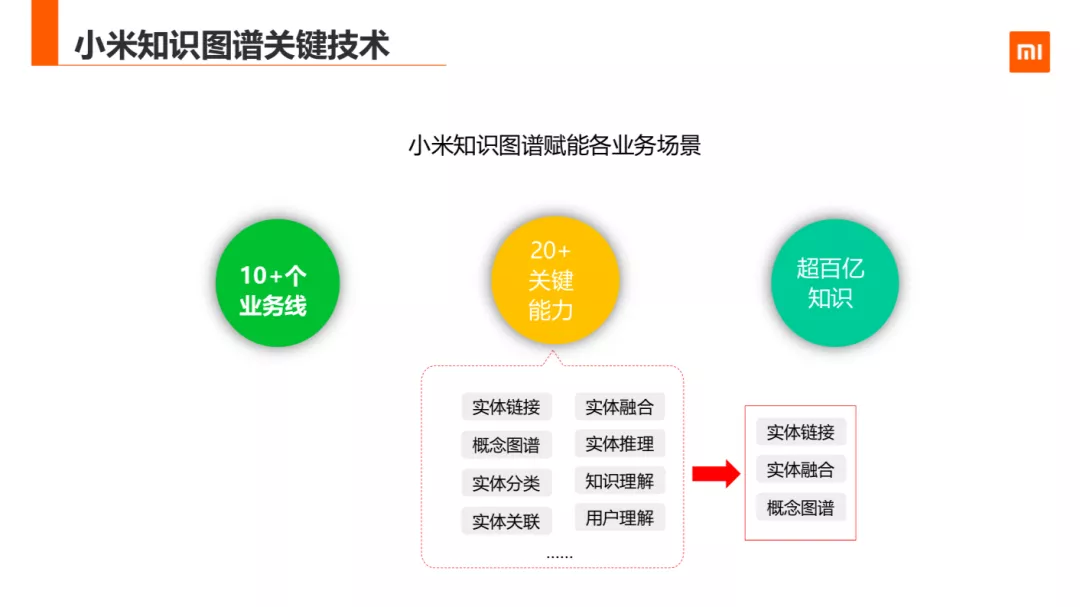
目前小米知识图谱已经具备 20+关键能力,比如实体链接,实体融合,概念图谱,实体推理,实体分类,知识理解,实体关联,用户理解等等,后面挑出实体链接,实体融合,概念图谱挖掘三个关键技术和大家分享探讨。
2. 关键技术:实体链接
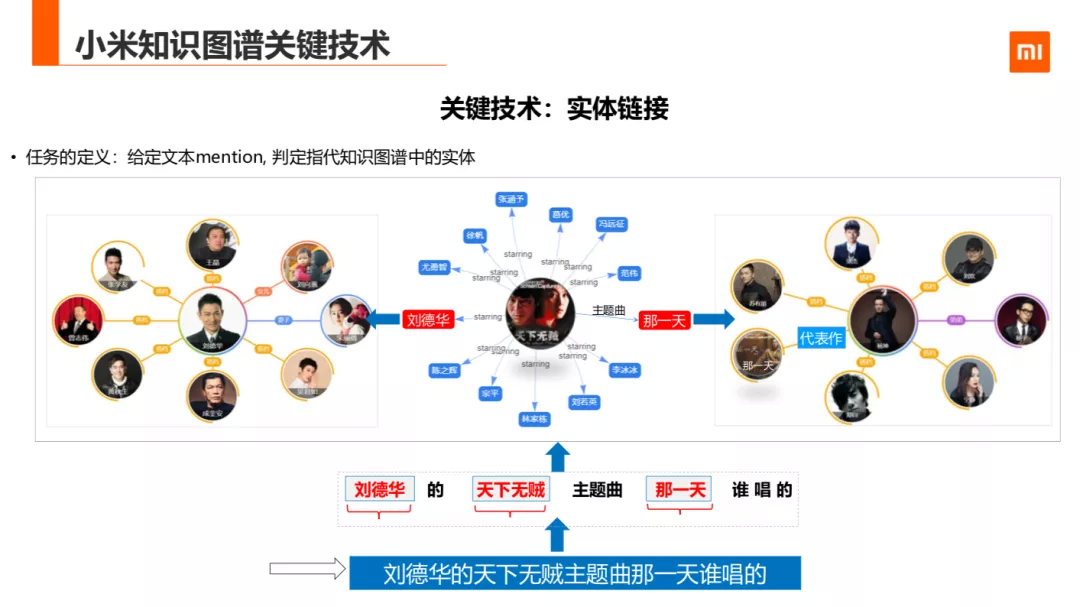
实体链接 ( Entity Linking ),也叫实体链指,该任务要求我们将非结构化数据中的表示实体的词语(即所谓 mention,对某个实体的指称项)识别出来,并将从知识库 ( 领域词库,知识图谱等 ) 中找到 mention 所表示的那一个实体所以实体链接的任务定义:就是给定文本 mention,判定指代知识图谱中的实体首先第一个是实体链接 ( Entity Linking )。
举个例子:
比如说刘德华的天下无贼主题曲那一天是谁唱的,实体链接需要把刘德华,天下无贼,那一天三个 mention 联接到知识图谱的实体上。以方便应用到如主题分析,语义的信息检索等更深度的应用场景下。
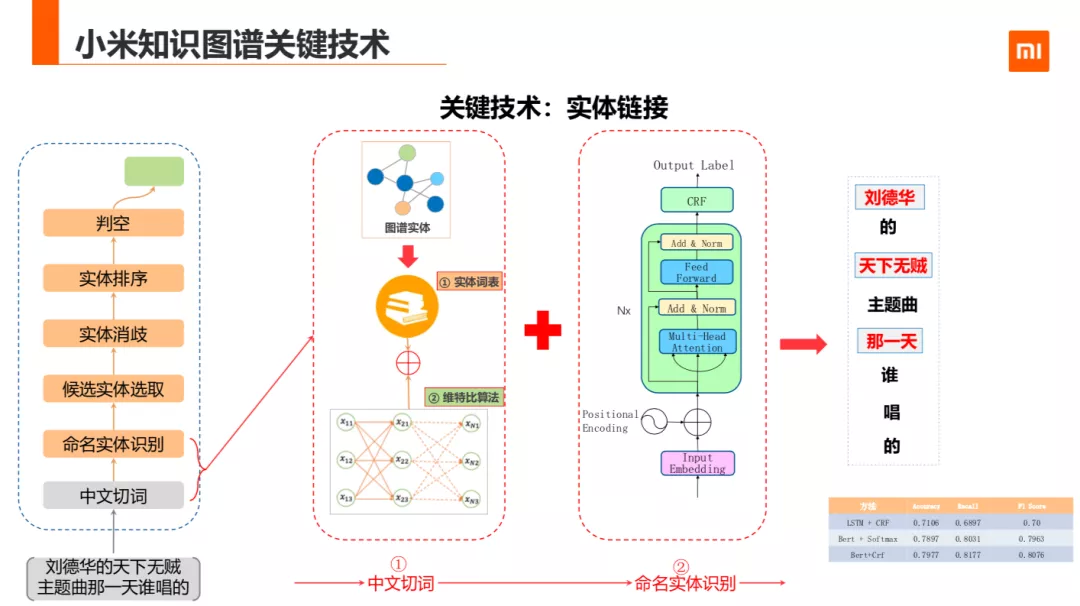
常见的实体链接如 PPT 流程。包括中文的切词,命名实体识别,候选实体选取,实体消歧,实体排序,判空几部分。第一步中文切词有很多方法,比如像结巴等一些开源的工具,我们的做法是整合了已有的实体名、实体同义词名,及开放锚文本信息做为词典,用维特比算法构造了切词功能。除了切词外我们还用的序列标注的方式做了命名实体识别,把实体词表与 NER 的结果合并。
其中 NER 用的是 BERT+CRF。在 NER 的训练数据集构造上,起初用远程监督的方法构造训练集的方法,但是发现在句子中有多个实体词的情况,远程监督的方式只能标注出部分实体词,这样对模型的召回影响比较大。所以我们利用开放比赛的标注数据作为数据集,再加上部分远程监督的数据和人工标注的数据作为最终的训练样本。这种方式的训练结果比只有远程监督的样本训练的结果提升 10 个点左右。
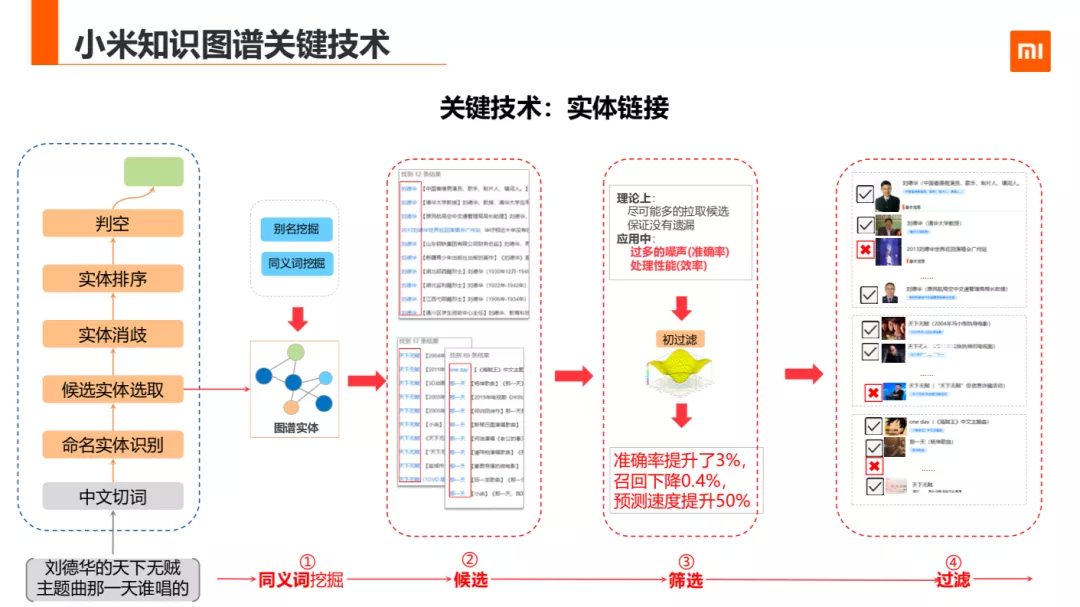
接下来第二步是候选实体选取,我们离线挖掘了大量的同义词,别名,缩写词等,放在图谱实体。命中 label,alias,同义词,缩写的作为候选对象。但是调研中发现过多的候选词不一定有好的效果,比如:长尾的,互动比较少、丰富度比较少的实体引入会造成很多噪声并且很影响处理性能。因此我们利用用户使用的热度,实体的流行度,实体丰富度等对候选实体做了筛选和过滤。精简后准确率提升了 3%,召回下降 0.4%,预测速度提升 50%。
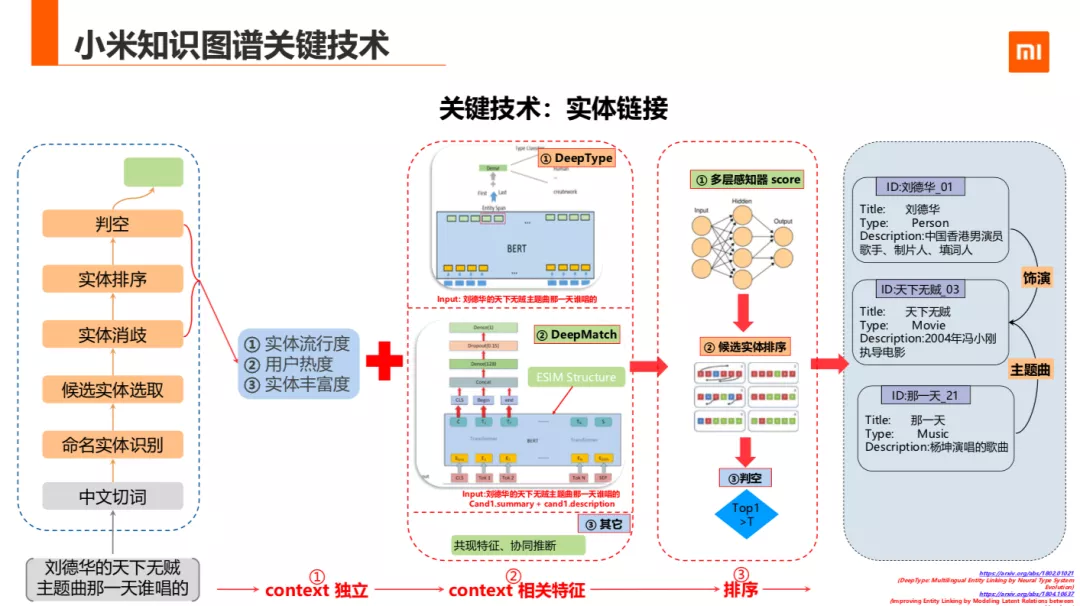
接下来是实体消歧,实体排序,判空这三块。这三块不好解耦,所以可以一块来说。这里用到了两处种特征,第一种是上下文无关的,第二种是语义相关联的特征。
上下文无关的特征包含:实体流行度,用户热度,实体丰富度等等。语义相关的特征包括三部分:
① 对输入实体 mention 预测实体类型, 用到的 18 年 Raiman, J. R., & Raiman, O. M.发表的"DeepType:用神经网的分类系统演化来做多语言实体链链接"的方法,该方法基于当我们知道了候选实体的类型之后,这个消歧的任务便被解决得差不多了的假设将实体链接过程看成是分类获取的过程。分类的过程是针对知识库中的分类体系设计了一个 DeepType 的预测系统。具体是用输入数据文本通过 bert 编码取 CLS 位置的向量、候选实体对应开始和结束位置对应的特征向量,三个向量连接,经过全连接层,最后 softmax 激活得到候选实体的类别得到分类。
② 是 DeepMatch 部分,参照 18 年 Le, P., & Titov, I 的一种通过候选实体与 mention 之间的潜在关系建模来提升实体链接的效果。该文章提出了将实体链接问题转化为文本语义匹配问题,构建了一个 DeepMatch 模型来匹配输入语句的上下文和候选实体的描述信息对。把待消歧文本作为 text_a,每个候选实体的 SPO 全部连接起来组成一段文本 text_b,计算 text_a 和 text_b 的相关性 。训练时选取连接到的实体作为正例,在候选实体里选取负例。两个句子长度最大选取为 256,负样本选取了 3 个。取 CLS 位置向量、候选实体对应开始和结束位置对应的特征向量,三个向量连接经过全连接层,最后 sigmoid 激活得到候选实体的概率得分。
③ 除了这两个特征外还有共现、协同推断等特征。最后把是否存在多个同义词指向同一个实体、其他 mention 是否出现在该实体的信息里、LinkCount、DeepMatch 模型的相似度、DeepType 模型的相似度等经过 MLP 得到一个分值,排序取 top1 的实体,如果 top1 的分值大于阈值就判定该实体,如果小于阈值则为空。

小米知识图谱通过该方法参加了 2020CCKS 比赛,很荣幸拿到了总决赛的第一名,F1 的值达到了 0.8954。但是这种方法在我的业务场景,准确率召回可以达到 96%以上。
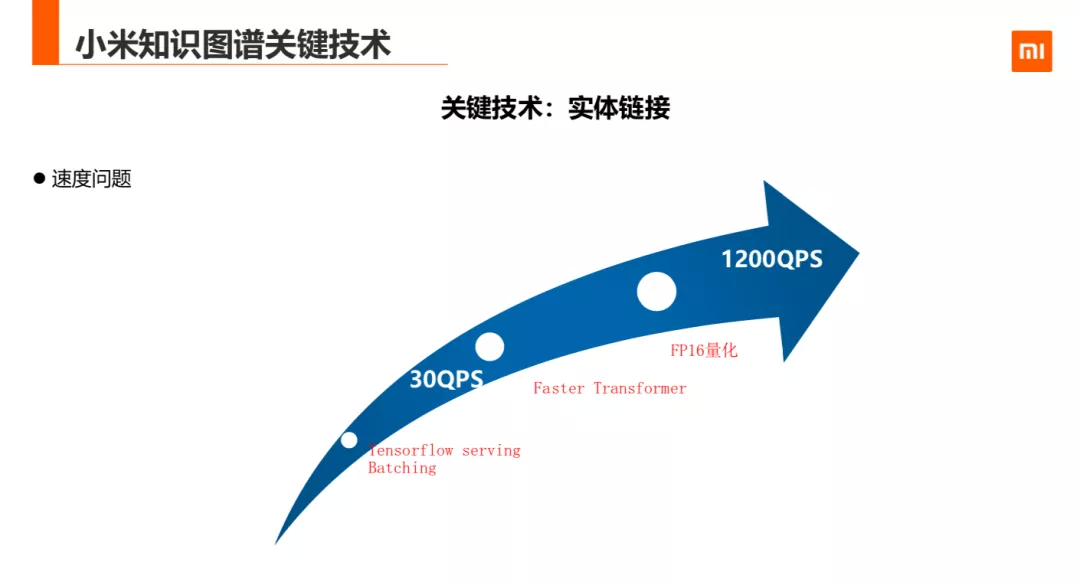
另外,除了效果,这里在业务上有会有处理性能的问题,所以这里用到三种方法加速,第一是引用了 tensorflow 的 batching serving,第二是把 bert 中的 transformer 用 nvidia 的 faster Transformer 替换,第三是用 Fp16 的方法量化,这种加速效果比较明显的 QPS 从 30 提升到 1200。
3. 关键技术:知识融合
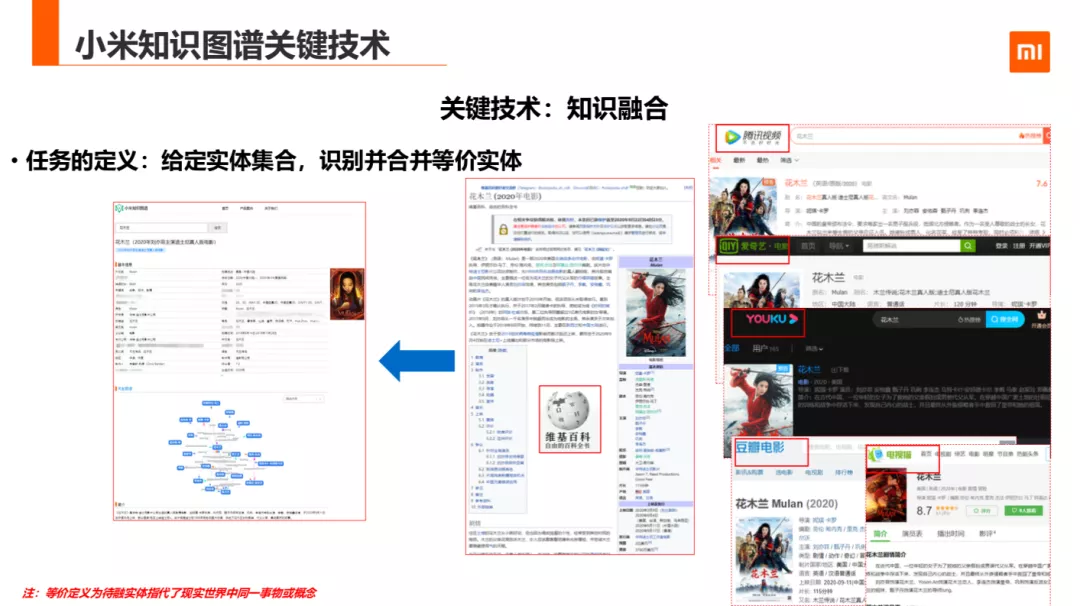
第二种关键技术,是知识融合,该任务的定义是,给定实体集合,识别并合并等价实体 ( 注:等价定义为待融实体指代了现实世界中同一事物或概念 ) 。举这个例子,花木兰电影有来自腾讯,爱奇艺,优酷,豆瓣,电视猫, 维基的数据。需要把实体化后的小实体,找到归一组,合并融合生成新的实体,更新至知识库图谱中这一过程中称为知识融合。
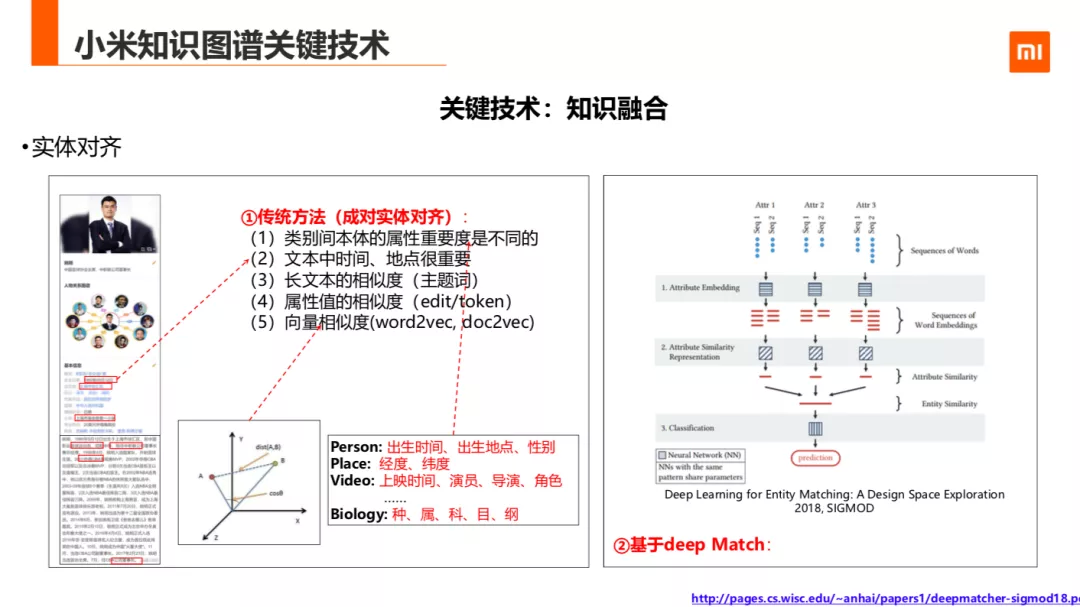
基于任务定义,把这种任务,拆解成了实体对齐和实体择优两部分。
实体对齐的方法目前包含成对的实体对齐,集体实体对齐,大规模集体实体对齐及知识库与知识库之间的模式层的实体对齐。小米着重做的是成对对齐,现在用了就两种的方法:
第一种方法是传统的方法,基于观察的先验,比如:
① 类别间的属性重要度是不同的 ( 比如人物中,出生时间,出生地点,性别,职业很重要;地点类的,经度,纬度很重要;视频: 上映时间,演员,导演,角色很重要;生物:种属科目纲很重要等 )。
② 文本中的时间,地点很重要,( 比如一些 infoxbox 中未覆盖的事件的时间及地点等 ) 基于这两个经验,我用一些 tfidf 的方法计算一些属性在不同类中的重要性,并找文本中的时间/地点做为一个重要的文本特征,并计算对应属性值相似度,目前用对一些相似度主要是一基于字粒度的文文相似度,及 token 粒度的主题相似度等。
第二种方法用基于 embedding 的 deep Match 方法,主要参照了 2018 年 ACM SIGMOD 的方法做了一些改进,该方法把实体中的每个属性下的 O 的 Value concate 成一个句子,通过双向 LSTM 等一模型 encodeing 成向量,计算每个属性下的 emdming 的相似度,最后经过一个分类模型,判断是否是同一个实体。该方法没有考虑类别中的属性重要度的差异,所以准确与召回效果都不太理想,我们也在考虑更多的方法尝试改进。
以上两种方法是针对对于结构化实体对齐的方法,如果是开放文本要依赖实体链接技术。
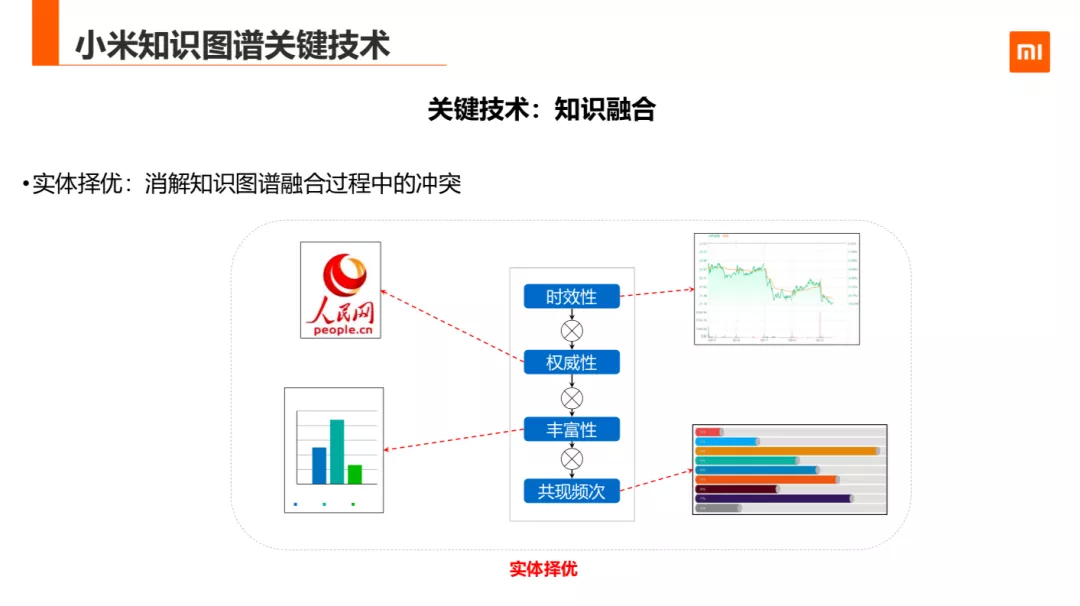
知识融合第二部实体择优,是在经过实体对齐后,把实体属性的差异性或者冲突性做消解。目前的做法基于以下几个方面对实体的质量进行控制控制:
实体的更新时效性
权威性,不同来源,权威性不同的,比如,人民网的权威性要比一般咨询类的站会要高
丰富性,不同来源 O 的值缺失程度是不同的
共现频次,当多源有冲突时,可以用投票的选出不同来源中出现最多的属性
4. 关键技术:概念图谱
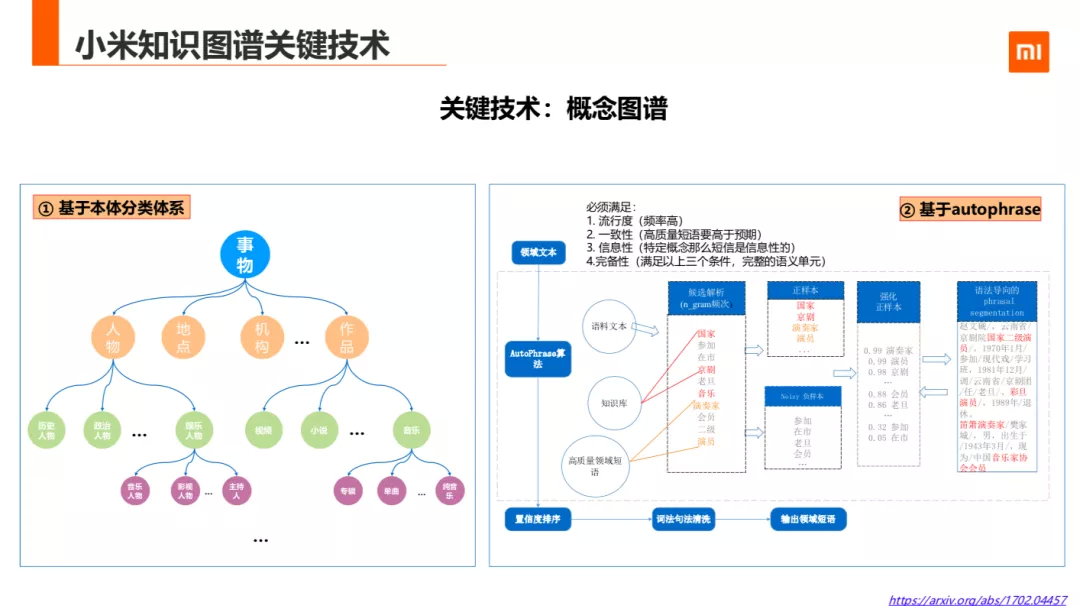
概念图谱的概挖掘目前小米图谱基本三种方式构建。
第一种是在本体模式层构建了分类体系, 分类体系参照了一些开放的行业和分类标准,还参考了一些人工整理的行业的标准体系。
第二种是基于 autophrase 的方法,是实例层的 ISA 关系的挖掘,该方法是 2017 年一篇论文中采用海量文本挖掘的方法,该方法通过主要是用短语挖掘的方法来挖掘概念。这种方法需要满足四个条件:
流行度:质量短语应该出现的频率足够高
一致性:token 在高质量短语中的搭配出现的概率明显高于预期
信息性:短语可以表达一个特定的主题或概念
完备性:一个短语可以在特定的文档上下文中解释为一个完整的语义单元
这个模型的训练用实体的长文本和内容文本、远程的 Wikipedia/cn_probase 拿到的开放的的高质量的短语及根据不同领域标注的高质量的词语三个输入作为输入语料。第二步用 n_gram 的候选筛选,出正样本与负样本,正样本是 N_grame 频率大于阈值和人工标注的领域短语及人工 cnproese 匹配的高质量短语;剩余是负样本。由于负样本中掺杂大量的正样本,所以后面是从负样本中使用集成分类器训练了多个基分器来从负样本中强化出正样本。为了保证概念短语的质量,方法通过词性分析过滤不符合语法的短语。
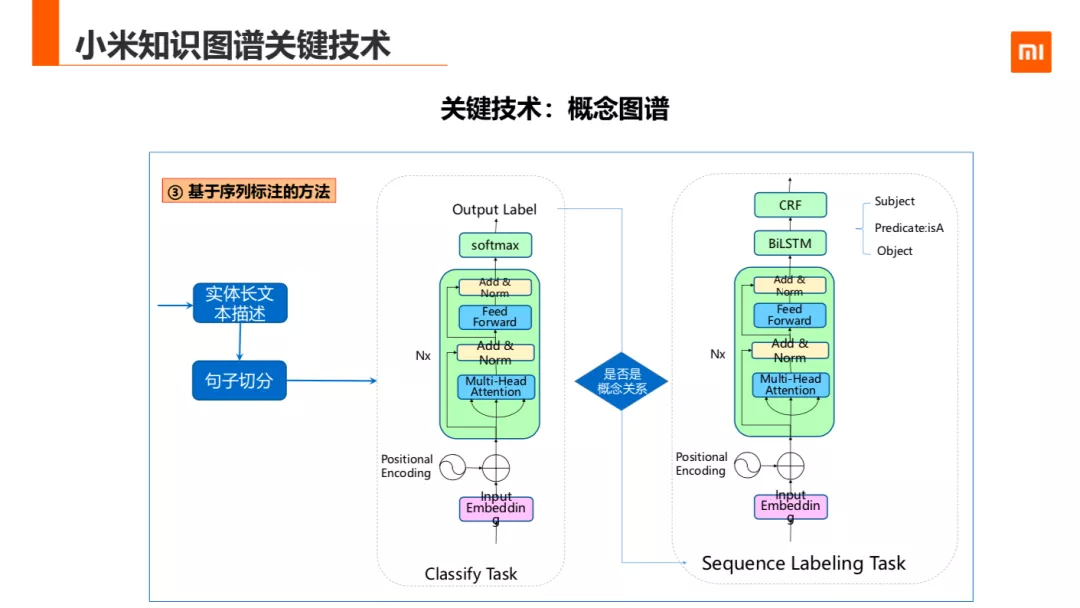
针对概念挖掘的第三种方法是基于序列标注的方法。分为两步。第一步做一个分类,针对实体长文本描述进行句子拆分,之后判断 否有这个概念相关的一个实体词。第二步使用 Bert+BiLSTM+CRF 的方式作序列标注,标注出 SPO 的值。
上面三种方法都是概念挖掘,对于实体与概念的关联,可以用实体分类的方法把模式层的与实体挂接,用实体链接的方法把开放词中的短语与体挂接。
5. 关键技术:自动化构建技术
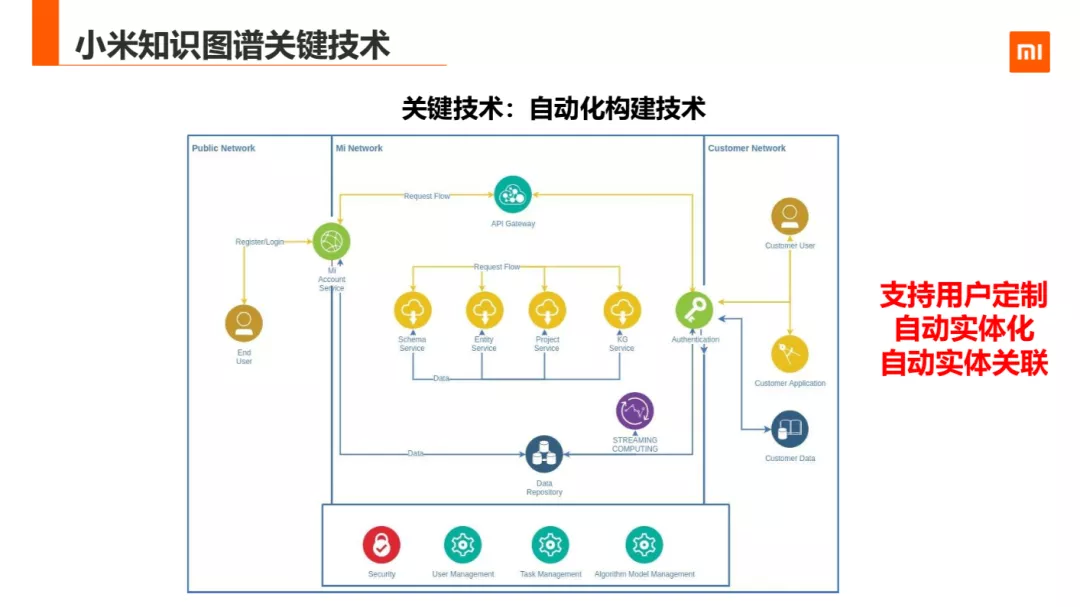
除些之外呢,小米图谱还在工程构建已有了一套完成的自动化构建技术,可以支持用户定制,自动实体化,自动实体关系等。
03 小米行业知识图谱探索
小米知识图谱的关键技术还有很多,我们在这里只给大家介绍典型的几个关键技术,有兴趣的话可以线下交流。最后我们看一下小米知识图谱在行业的一些探索。
1. 商品图谱
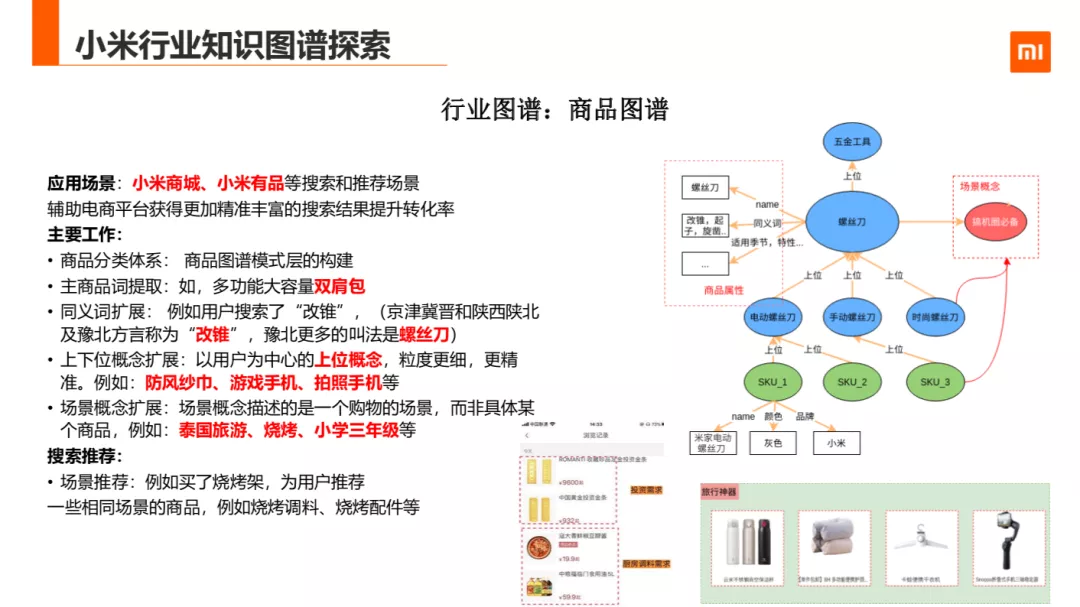
第一个业务场景的探索商品图谱,主要的应用场景是小米商城,小米品的搜索和推荐场景,目标就是辅助电商平台精准的搜索。
现在商品图谱已在商品分类体系的建设、主商品词提取、商品同义词挖掘、上下位体系构建、场景概念挖掘五个方向构建完成。其中分类体系是在模式层的构建;主商品词提取和商品同义词挖掘用于精确匹配与召回;上下位体系结构用于用户推荐;场景概念挖掘用于搜索发现及场景推荐。
场景挖掘以泰国旅游为例,可以与沙滩鞋,电话卡,浮潜装备等商品有关联,烧烤场景可能与烧烤架,木炭,食材等商品关联。
目前商品图谱已把这五个方向的数据和技术落地到小米商城,有品商城上。用户转化率和商品转化率都有不错的提升。
2. 上位词

上位词挖掘的方法分为三部分:
第一部分是上位词判定,用 bert 加上分类模型从用户日志的 query 中提取出来确识别是否是商品词或者上位词。第二部分通过层次化的分类器,对挖掘到的上位词合并到分类体系中,这里用的了 HMC 的多分类器。第三部分是把商品与上位词关联,用商品名做 texta, 上位词做 textb,把关联问题转化为文本分类问题。
目前用这种方法挖掘出的上位词,平均每个商品覆盖 10.5 个上位词。
3. 同义词
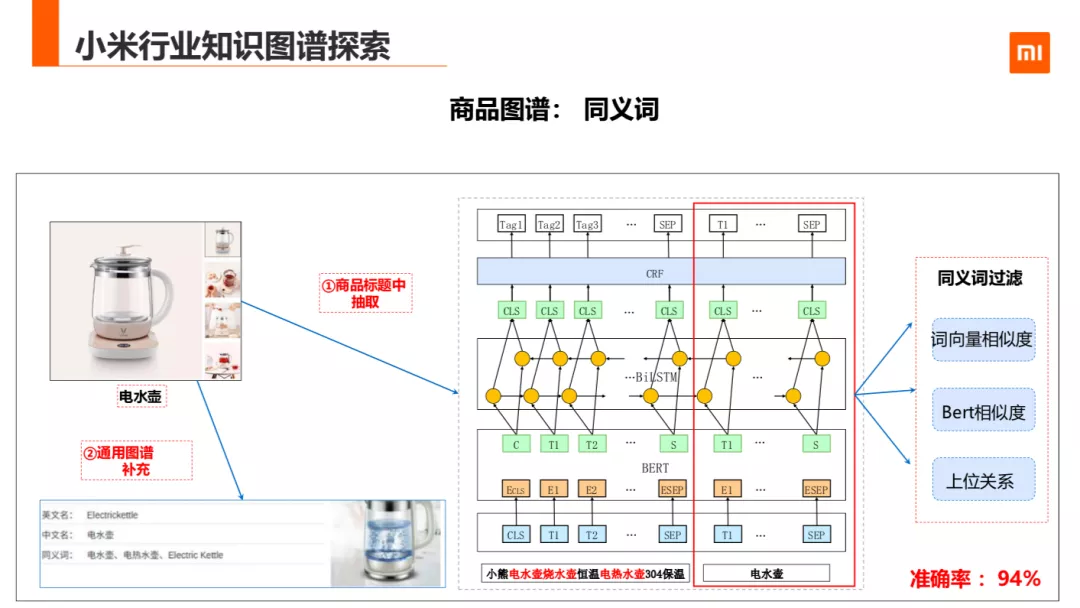
商品图谱涉及到的还有一个就是同义词挖掘。我们是从商品标题中抽取同义词,在调研中发现,很多商铺为了尽可能多的命中搜索词,会把可能多的把相同相近或者同义的词堆砌到商品名中。所以基于这个假设,我们把同义词的挖掘,转化为一个序列标注问题。
其中训练数据用人工标注+ ( 通用图谱+同义词库 ) 远程数据作为训练样本。商品 title 做为 texta, 候选的词做为 textb 最后标注出 BIOS。因为店铺除了堆砌到同名商品外,还会打包买一些东西,比如锅盘垫与炒锅盖打包卖,所以这样做会有准确的问题。为了这种问题,我用了以下三种方法去噪:
检测上位关系是否冲突,锅盘垫->餐具->餐垫,炒锅盖->锅具->锅盖等
用词向量相似度
用 bert 相似度计算分类判断是否同义
用三种方法过滤后我们的准确率达到 94%。
4. 金融图谱
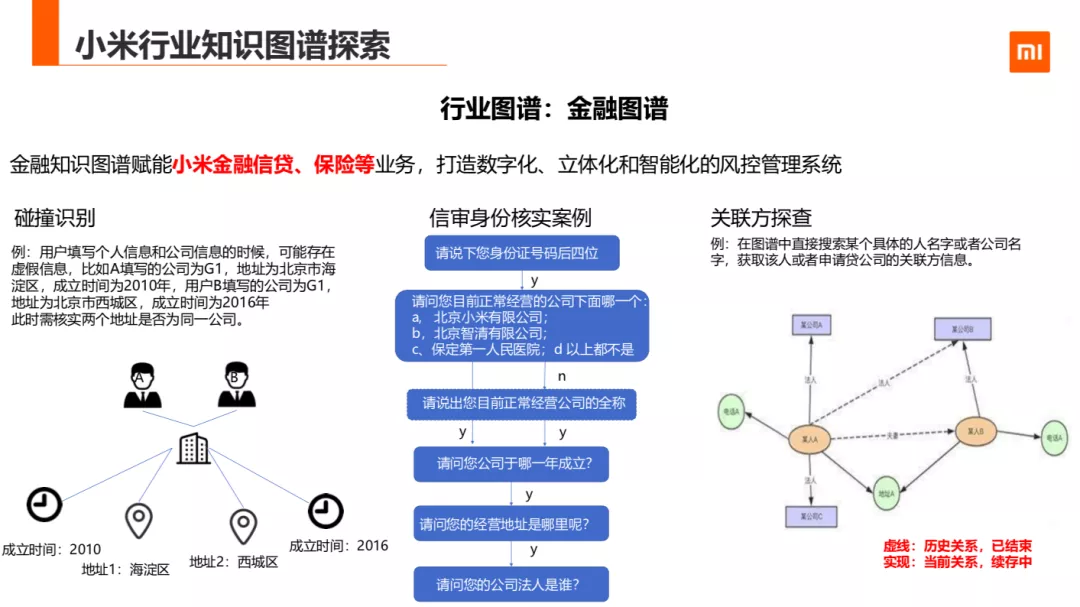
第二个行业落地场景,是客服团队金融图谱在小米金融信贷及保险等业务的应用。我们就业务场景中的身份核实的子功能举例:
碰撞识别主查核实多个用户的公司地址是否为同一公司
关联方探查,是判断申请贷人与信息是否一致
后面就是金融知识图谱的框图:
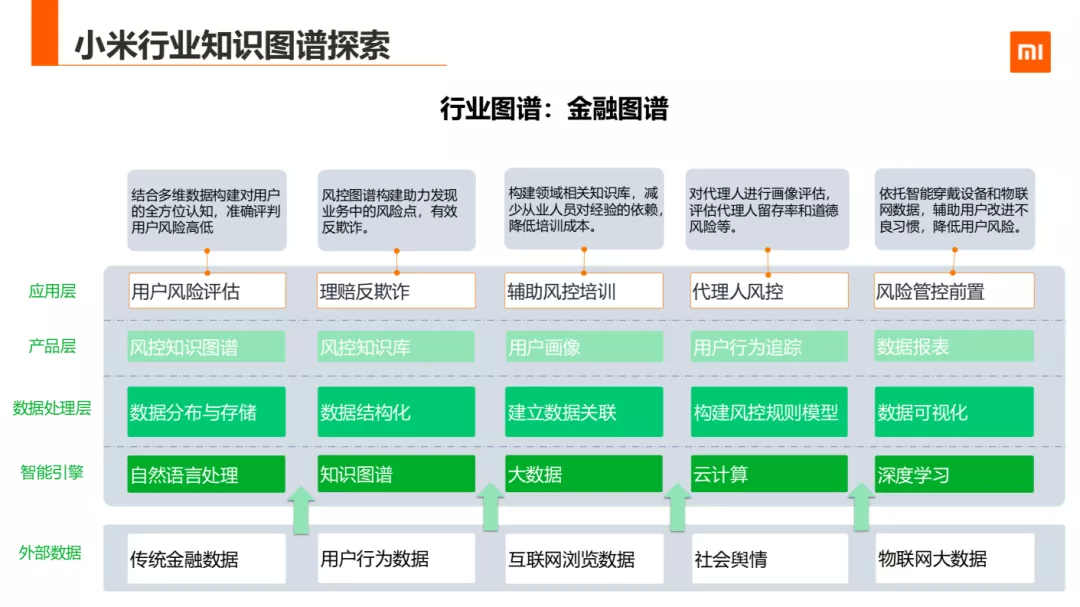
除了商品及游戏及金融行业的应用外,我们在更多的行业图谱的落地及更多的通用图谱的应用场景也在持续探索中。
04 总结
简单总结下,小米知识图谱已构建超百亿的知识,落地 10+的业务场景,拥有 20+个技术能力,拥有成熟的自动化构建流程,小米知识图谱已有多个行业知识图谱落地。最后,欢迎大家体验/使用小爱同学等小米的产品,也欢迎大家吐槽!
今天的分享就到这里,谢谢大家。
作者介绍:
彭力,小米高级软件工程师
彭力,小米 AI Lab 知识图谱高级软件工程师,参与 IEEE p2807 知识图谱的标准制定;在小米主要负责知识图谱的构建和探索知识图谱在公司业务场景下落地。已推动知识图谱在小爱同学、小米商城、游戏商城、虚拟助手、智能问答等业务开花结果。
本文来自 DataFunTalk
原文链接:




