
“让软件开发人员去设计一个运营体系” – Benjamin Treynor Sloss, Vice President of 24x7 Engineering, Google
在上一篇文章中,我们讲到 SRE 的核心诉求是围绕 SLO 进行运维,并着重介绍了如何围绕 SLO 设计运维流程。在本次文章中,我们来讨论一下在组织文化上和运维工具上,SRE 实践是如何考虑的。
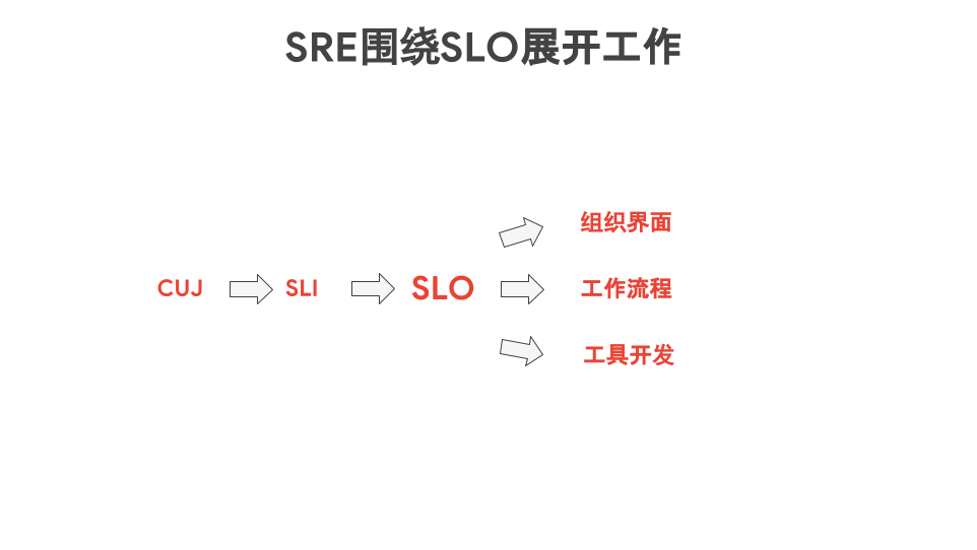
组织与文化
在上一篇文章中,我们提到 SRE 需要建立一个有开发能力的运维团队,这个团队的多数精力都应该放在开发上,用开发的运维工具来实现运维。此外,这个团队也需要分配精力帮助开发人员评审软件架构以及响应运维事件上。由此可见,对于 SRE 人员来说,以下能力是比较重要的:
端到端的架构能力
当你在浏览器中点击 google.com 时会发生什么?要回到好这个问题,需要对计算机的体系结构有深入的了解。作为 SRE ,不但需要了解从网络,到存储,再到 CPU 这些知识,并且还需要有把这些知识进行重组以解决现实的架构问题的能力。
代码的能力 SRE
通过开发软件来进行运维。在 Google , 数以万计的服务器数量使得工程师无法一台一台来管理维护它们,SRE 需要通过开发自动化工具来完成工作。相比与软件工程师,SRE 工程师的在编程上会更偏向采用高效、实用的方法解决问题。这一点上,Golang 很好说明了 SRE 对编程的需求:运行比 Python 快,但是写起来别比 Python 复杂太多。
解决问题的能力
现场解决问题是 SRE 的工作之一。SRE 需要知道如何循序渐进的对故障进行分析,逐步而准确的缩小故障范围,最终排除故障,而完成这个过程,往往需要在有时间压力的情况下进行。所以这部分工作虽然占的时间比例不多,但是却是很有挑战的一部分。
除了对工程师能力上的要求之外,SRE 组织在考核方式上也往往采用 OKR 体系。OKR 是目标与关键成果的简称。SRE 组织中的每个人都需要设立自己的 OKR ,保持自己的 OKR 与部门的 OKR 看齐,并且为 OKR 中定义的目标努力。通过这种方式,可以保持 SRE 团队不断的对工作进行改进,才能更好的应对在运维中遇到各种未知问题,提前准备好解决方案。“建立解決方案而不是变成解決方案"。
OKR 体系的附加好处就是容易实现开发人员跟运维人员的目标一致。这样可以帮助打破部门隔阂,从而解决由于开发跟运维的目标不一致带来的矛盾。例如,为了达成 SLO 目标,SRE 工程师可以改进现有的工具来减少发布所花费的时间,从而提高可用性;而开发人员可以通过修复 BUG 来提高应用的稳定性,这两者都是各自团队的“关键成果”,这两个关键成果都对达成 SLO 目标有贡献,这样就把运维和开发团结起来,减少了矛盾。
SRE 工程师应免于恐惧。人是会犯错的,“人为”错误即是系统问题。 你无法“修复”人员,但你可以改进系统和流程,以更好地支持人去做出正确的选择。因此在 SRE 组织中,不指责是一个非常重要的原则。只有在不指责的前提下,对故障的事后检讨才能充分执行并获得期望的效果。SRE 在实践上要求对任何的故障或事件都要做事后检讨以确保:
事件被记录在案,并在整个组织内分享
引起故障或者事件的根本原因能被充分理解
采取有效的预防措施以减少再发生的可能性和/或影响
撰写事后检讨并不是一种惩罚,而是工作的一部分(关键成果,或者对某个关键成果有贡献)。一个好的事后分析报告要包含以下三个部分:
事件的详细描述
事件的根源分析
详细行动计划
SRE 的工具
SRE 依赖工具进行运维。SRE 并不限定这些工具是自己开发的,抑或是外购或是开源软件,只要用的顺手,都可以用。然而在执行上,SRE 会对团队使用的工具提出一些要求:
有人维护的工具才可以用
有人维护意味着有 SLO ,那么工具使用者的 SLO 就有了支撑。如果某个工具没人维护了,那么这个工具就应该被退役,特别的,这里的工具应具体到某个特定版本。当然,退役某个工具(或版本)是有成本的,而继续维护这个工具(或版本)也是要付出代价的,因为在这两者之间是可以达成平衡的。实践上,当工具的运维团队计划退役某个工具或版本,他们当然可以把帮助这个工具的使用者迁移到新工具或新版本列入自己 OKR 。
工具应尽可能开放
工具应可以直接与工具对话,这样 SRE 工程师就可以利用现有工具去整合出新的自动化脚本从而完成更复杂的任务。这就要求工具是开放的,从调用接口,到数据接口,都尽可能开放。
建设工具应该从最简功能( MVP )开始
专注 MVP 的工具建设可以让工程师免于在一些暂时用不到的功能上浪费时间和精力。
SRE 的工具通常有这几类:
监控与日志管理工具
SRE 对监控工具的要求就是要跟 SLO 直接挂钩。比如,某个应用定义了 HTTP 请求的成功率和延迟作为服务等级指标( SLI ) ,那么监控工具就应该能直接获得跟这两个指标相关的第一手数据。
自动化工具无论是对基础设施的管理,还是对工作负载的管理,SRE 都是通过自动化工具来实现的。
知识共享工具在 SRE 团队中,知识应该是自动流动的,无论是事后检讨报告,还是监控与日志数据,还是代码,都应该在不违反信息安全和法律法规的前提下在团队中共享。
Google 的 SRE 团队在多年的实践中,积累了大量的经验,Google 也在持续的将这些工具向社区输出。
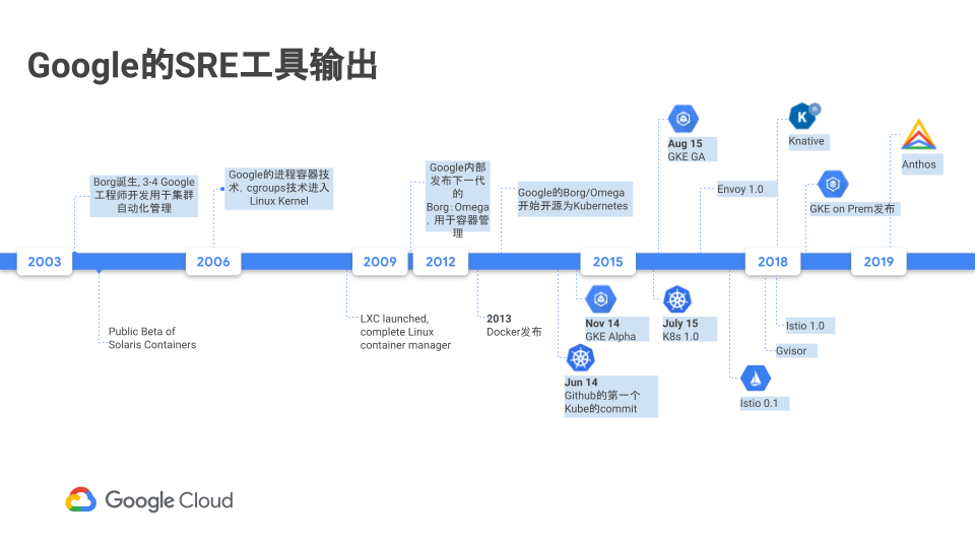
其中,Kubernetes 可以看作是提供基础设施的自动化管理的平台,而基于 Kubernetes 平台之上建设的 Anthos 套件,又把 ASM 、ACM 这样的工具带给我们的客户。
ASM 是 Anthos 服务网格的简称,它能提供容器网路的东西向和南北向的可见性和可管理性能力,为面向 SLO 的监控提供支持。
ACM 是 Anthos 配置管理的简称,它一个基于 GitOps 理念开发的集群管理工具,ACM 与 Kubernetes 一起,能极大简化 SRE 的自动化工具的构建。
小结
本篇介绍 SRE 在实践过程中,对组织的建设和工具的建设的要求,并且提到了 Anthos 这个套件能帮助 SRE 开展工作。在接下来的文章中,我们会就工具进行进一步展开,对 GitOPS ,服务网格,CICD 等做一些详细分析。




