
在二十年前刚刚加入谷歌时,我们关注的问题只有一个——如何面向这么多不同种类的联网计算机提供一整套质量出色且涵盖范围全面的网络信息搜索服务。到如今,尽管我们面临着各种各样的技术挑战,但谷歌已经基本达成了组织全球信息,并使其具备普遍可访问性的总体目标。到 2020 年,随着 COVID-19 肆虐全球,我们意识到研发技术能够帮助全球数十亿人更好地交流、了解事态发展并找到新的工作方式。我为我们取得的成就感到自豪,也为即将出现的全新可能性感到振奋。
谷歌研究院的目标是解决一系列具有广泛意见的长期问题——从预测 COVID-19 疫情的蔓延路径到设计算法、愈发强大的自动翻译服务,再到缓解机器学习模型中的偏见问题等。着眼于过去四年来的进展,我们将在本次回顾中再次审视 2020 年这不平静的一年。如需了解更多详情,请参阅我们在 2020 年内发布的 800 多篇研究文章。本文篇幅较长,但明确划分为多个部分,您可以通过下表目录了解相应内容(可通过网页左侧的目录跳转至相应内容)。

COVID-19 与健康
随着 COVID-19 疫情给全球民众的日常生活造成巨大损失,世界各地的研究人员与开发人员齐心协力开发工具与技术,旨在帮助公共卫生官员及政策制定者理解并应对这场突如其来的疾病。
苹果与谷歌在 2020 年合作开发的 Exposure Notifications System (ENS)是一种基于蓝牙的隐私保护技术,一旦接触到 COVID-19 检测呈阳性的人员,该技术将立即对用户发出提醒。ENS 给传统接触者跟踪方法提供有效补充,目前已经被公共卫生部门部署在超过 50 个国家、州/省及地区,帮助多地遏制疫情的传播势头。
在疫情初期,公共卫生官员表示需要更全面的数据来对抗病毒的迅猛传播。我们的社区流动性报告中囊括了关于病毒流动趋势的匿名洞见,不仅能够帮助研究人员了解居家观察与社交隔离等政策影响,同时也有助于做出经济预测。
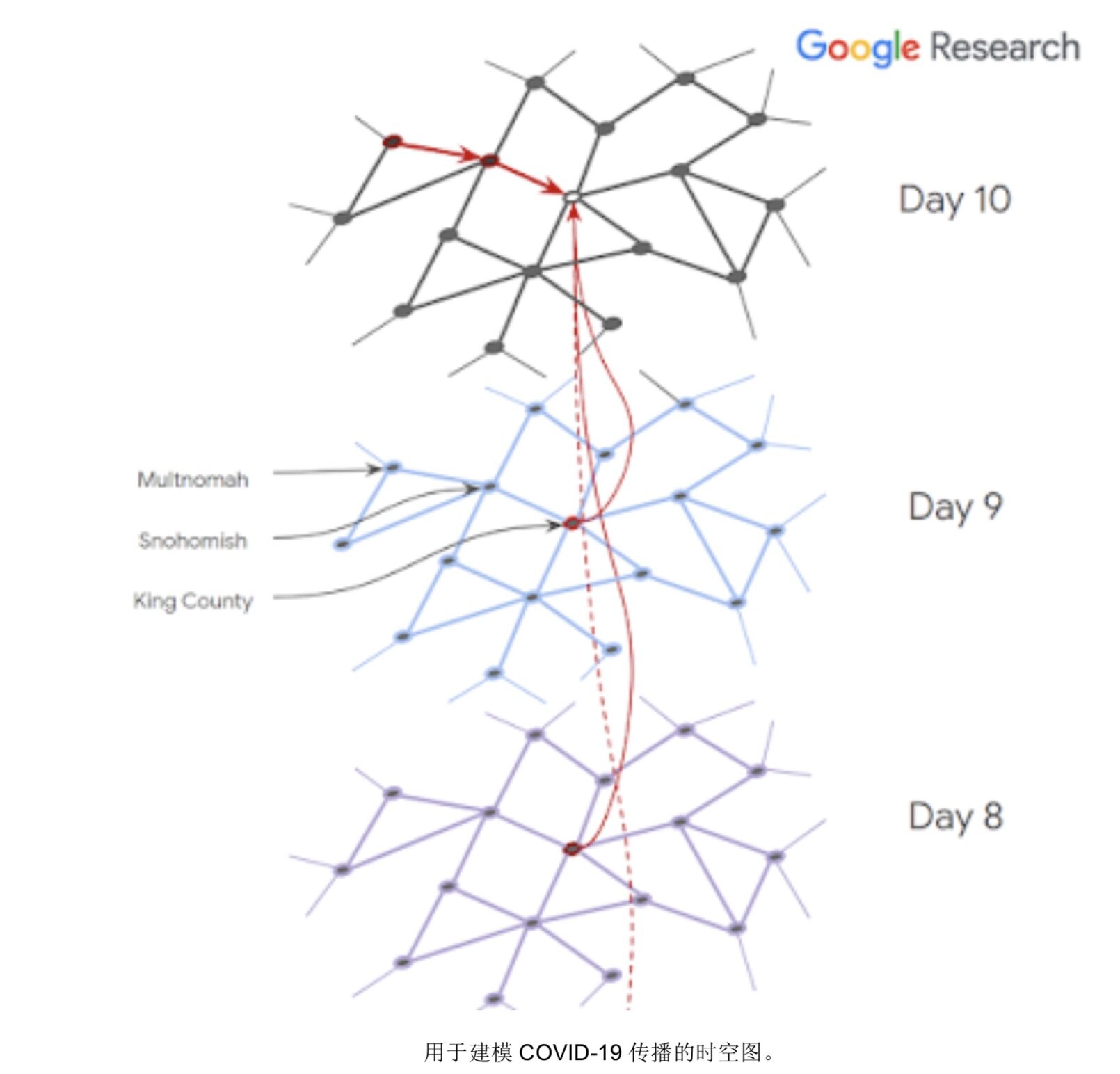
谷歌内部的研究人员还探索了使用这种匿名数据,通过图神经网络(而非传统基于时间序列的模型)来预测 COVID-19 传播。
尽管研究社区最初对这种疾病以及继发性的效应知之甚少,但我们每天都在接触更多、学习更多。我们的 COVID-19 症状搜索趋势让研究人员得以将不同症状关联起来,例如嗅觉丧失症——即因病毒感染导致嗅觉丧失。为了给研究社区提供更广泛的支持,我们还推出了 Google Health Studies 应用,向民众开放公开研究通道。
谷歌团队还在为更广泛的科学界提供工具与资源,帮助从业者努力解决由病毒引发的健康与经济影响。
准确的信息对于应对公共卫生威胁至关重要。我们与谷歌内部的多个产品团队合作,通过支持事实检查以及 YouTube 导流等方式提高谷歌新闻与搜索中关于 COVID-19 的信息质量。
另外,通过赞助 Nextstrain.org 发布每周本地疫情报告,并与 Translators Without Borders 合作开发 COVID-19 开源并发数据集,我们还帮助多语言社区平等获取关键 COVID-19 信息。
对复杂全球事件进行建模极具挑战性,而更全面的流行病学数据集、开发新颖的可解释模型以及基于代理的模拟器,帮助公众更从容地应对健康。机器学习技术还通过自然语言理解、快速筛选 COVID-19 科学文献、应用匿名化技术实现隐私保护、提供丰富数据集等多种方式为研究人员提供助力。更重要的是,公共卫生部门也在谷歌技术成果的支持下,从以下几个方面做出抗疫探索:
这些只是谷歌开发的诸多工作中的一个侧面,也代表着谷歌帮助用户及公共卫生当局更从容地应对 COVID-19。关于更多详细信息,请参阅使用科技成果帮助应对COVID-19。
医学诊断领域的机器学习研究
我们将继续努力,帮助临床医生运用机器学习的力量为更多患者提供更好的护理。今年,我们在应用计算机视觉帮助医生诊断及管理癌症病患方面取得了显著进展,包括帮助医生在结肠镜检查期间不致错过潜在的癌性息肉。此外,我们还证明机器学习系统完全能够实现更高的准确性,除了精度堪比病理学家对前列腺组织的格里森分级之外,还能帮助放射科医师在检查 X 光片中是否包含乳腺癌迹象时大大降低假阴性与假阳性检查比例。
我们还一直在研究可帮助识别皮肤疾病、检测年龄相关黄斑变性(已经成为美国及英国民众发生失明病变的首要原因,同时也是全球范围内造成失明的第三大原因),并尝试探索新的非侵入性诊断方法(例如通过视网膜影像检测出贫血迹象)。
今年我们还带来了令人振奋的示范,展示了如何将上述检测技术引入人类基因组当中。谷歌的开源代码工具 DeepVariant 使用卷积神经网络识别出预测数据内的基因组变体,并借此在今年的 FDA 挑战赛拿下最高奖项(在总计四个类别中的三个类别获得最佳准确性)。使用相同的工具,由达纳-法伯癌症研究所进行的另一项研究,成功对 2367 名癌症患者体内导致前列腺癌及黑色素瘤的遗传变异诊断准确率提高了 14%。
我们的研究也不止于衡量实验的准确性。最终,要真正帮助患者获得更好的护理,必须了解机器学习工具如何给现实世界中的人们造成影响。今年,我们开始与 Mayo Clinic 合作开发出一套机器学习系统,用以协助放射治疗项目并探索如何更好地将技术部署到临床实践当中。通过与泰国合作伙伴的协作,我们得以对糖尿病引发的眼病进行筛查测试案例,借此了解如何构建起以人为本的系统方案,也逐步意识到多样性、公平性以及包容性在提升人类社会整体健康水平的基础性作用。
天气、环境与气候变化
机器学习可以帮助我们更好地了解环境,做出有用的预测,借此帮助人们解决日常难题、克服自然灾害。以天气预报和降水为例,长期以来,以 NOAA 的 HRRR 为代表的计算密集型物理模型一直是行业中的首选方案。但我们已经证明,基于机器学习的预测系统能够以更好的空间分辨率来预测当前降水情况(回答「我家附近的公园正在下雨吗?」,而不只是「当前所在城市正在下雨吗?」),并产生未来 8 小时内准确率远高于 HRR 的短期预报。这套模型不仅预报计算速度更快,同时也拥有更高的时空分辨率。
我们还开发出一种名为 HydroNets 的改进型技术,其使用神经网络对全球范围内的真实河流系统进行建模,借此准确分析上游水位与下游泛洪之间的相互作用,借此更准确地做出水位预测与洪水预报。使用这些技术,我们将印度与孟加拉国的灌水警报覆盖范围扩大了 20 倍,为 25 万平方公里内的 2 亿多居民带来更强大的生命安全保护能力。
凭借更出色的卫星图像数据分析能力,谷歌用户也可以准确把握野火的影响与烈度(今年,野火给加利福尼亚州及澳大利亚造成了毁灭性的影响)。我们证明,即使以往的卫星图像数据有限,对最新卫星图像的自动分析仍可以有效评估自然灾害带来的损失。此外,这项技术还可以评估不同城市当中的树冠覆盖范围,并据此设计新植被种植规划以帮助城市对抗自然灾害。我们也展示了如何利用时态背景下的机器学习技术,帮助人们改善对生态及野生动植物的监测水平。
基于这项工作,我们很高兴能够与 NOAA 合作,利用 AI 与机器学习通过 Google Cloud 基础设施扩大 NOAA 的环境监测、天气预报与气候研究范围。
辅助功能
机器学习在改善辅助功能方面同样表现出惊人的能力,因为它能够学会将一种感官输入转换为其他感官输入形式。例如,我们发布的 Lookout 是一款 Android 应用,可以通过识别杂货店与家中厨房橱柜中的食品余量帮助视障用户。Lookout 背后的机器学习系统证明,强大且紧凑的机器学习模型完全可以在手机上实时识别出近 200 万种产品。
同样的,使用手语进行交流的人们很难使用视频会议系统。现有基于音频的发言检测系统往往无法识别出他们的发言动作。为此,我们开发出用于视频会议的实时、自动手语检测模型,借此将做出手语表达的用户正确识别出活跃发言者。
我们还为重要的居家客户提供强大的 Android 无障碍功能,包括语音访问与有声通知。
Live Caption 也迎来扩展,能够支持 Pixel 手机上的呼叫,并提供语音与视频通话的字幕生成功能。这项成果源自 Live Relay 研究项目,此项目能够帮助聋哑用户在无需帮助的情况下顺利拨打电话。
机器学习在其他领域的应用
机器学习也不断地在众多重要的科学领域证明着自己的实力。2020 年,我们与 HHMI Janelia Research Campus 合作建立了 FlyEM 团队,共同发布了果蝇半脑连接组——这是一份表现大脑连接的大型突触分辨率图,其中使用大型机器学习模型对高分辨率电子显微镜捕捉到的组织图像进行了重建。该连接组信息将帮助神经科学家们执行各类查询,帮助我们更好地了解大脑的运作机理,这里建议大家观看这段3-D UI互动展示。
机器学习技术在系统生物学领域的应用也在快速扩张。我们的 Google Accelerated Science 团队与 Calico 的同事们合作,将机器学习引入酵母分析,借此更好地了解基因在整个生态系统中如同协同工作。我们还一直探索如何使用基于模型的强化滓技术,借此设计出具备医学或工业用途的、拥有特定性质的生物序列——例如 DNA 或蛋白质。基于模型的强化学习能够提高样品效率。在每轮实验中,我们都使用适合先前轮次的特征测量模拟器对策略进行离线训练。在设计 DNA 转录因子结合位点、设计抗菌蛋白以及对基于蛋白质结构的 Ising 模型进行能量优化等任务上,我们发现基于模型的强化学习已经成为一种极具吸引力的替代性解决方案。
在与 X-Chem 制造公司以及 ZebiAI 的合作中,我们也一直在开发机器学习技术,通过计算对有希望的分子化合物进行“虚拟筛选”。该领域以往的工作倾向于集中处理少量相关化合物,而在谷歌的研究中,我们尝试使用 DNA 编码的小分子库更准确地概括大范围“命中”区间。这种新方法消除了实体实验室中缓慢、低效的实体流程,有望单纯立足理论产出可行的药物配方。
我们还看到通过机器学习解决核心计算机科学及计算机系统问题的成功案例,这方面趋势也催生出以 MLSys 为代表的会议平台。在基于学习、面向 C++ Server 工作负载的内存分配用例中,基于神经网络的语言模型能够预测出与上下文相关的各分配站点对象生命周期信息,并借此组织堆以减少内存碎片。在纯使用大内存页(更适合 TLB 行为)时,这种方法能够将碎片减少达 78%。用于图优化的端到端可转换 Deep RL 则提出一种用于端到端且可转换的图优化计算深度强化学习思路。与 TensorFlow 中的默认优化方法相比,其在三项图优化任务上实现了 33%到 60%的收敛加速效果,全面压倒原有计算图优化方法。
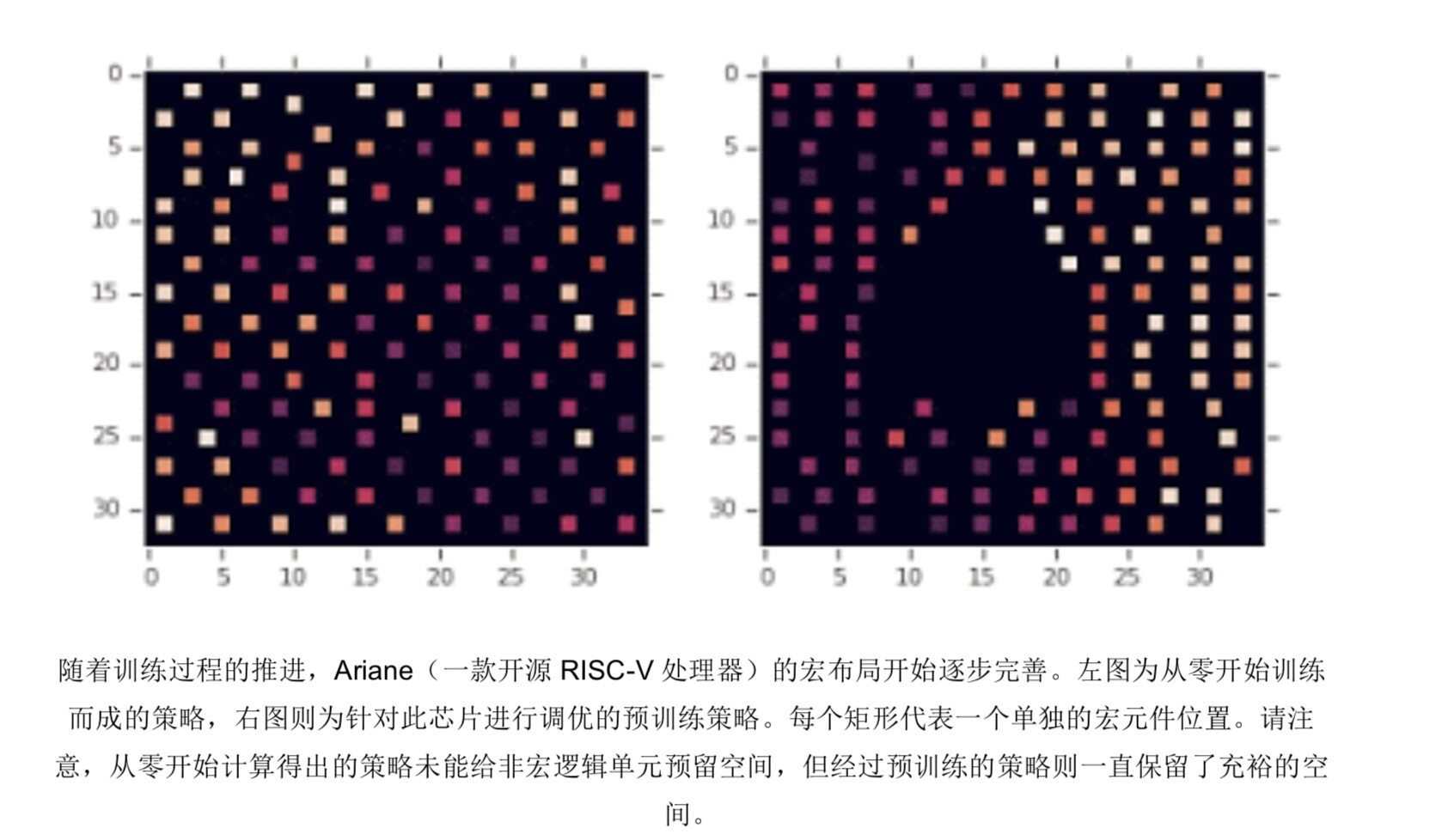
正如《采用深度强化学习进行芯片设计》(Chip Design with Deep Reinforcement Learning)所述,我们也一直在利用强化学习技术解决计算机芯片设计中的线路布局问题。长期以来,这一直是项费时费力的工作,同时也严重制约着芯片产品由设计灵感到建立完整设计、再到压片制造的推进速度。与以往的方法不同,我们的新方法能够从过往经验中学习思路,并随时间推移不断改进设计效果。具体来讲,我们在训练中使用的芯片设计成果越多,我们的方法就越是善于通过前所未有的设计方式产出高度优化的布局方案。这套系统能够生成整体优于人类芯片设计专家的布局,我们也一直在利用该系统(运行在 TPU 上)为下一代 TPU 进行主体布局设计。Menger 是我们专为大型分布式强化学习而构建的最新基础设施,并在解决芯片设计等强化学习难题中表现出令人振奋的性能水平。
负责任的 AI
谷歌 AI 的原则引导着我们开发先进技术,我们将继续投入负责任 AI 的研究中,更新我们在这一领域的技术实践,并就实施进度定期发布共享更新——2020 年内发布的各博文及报告正是其中的重要部分。
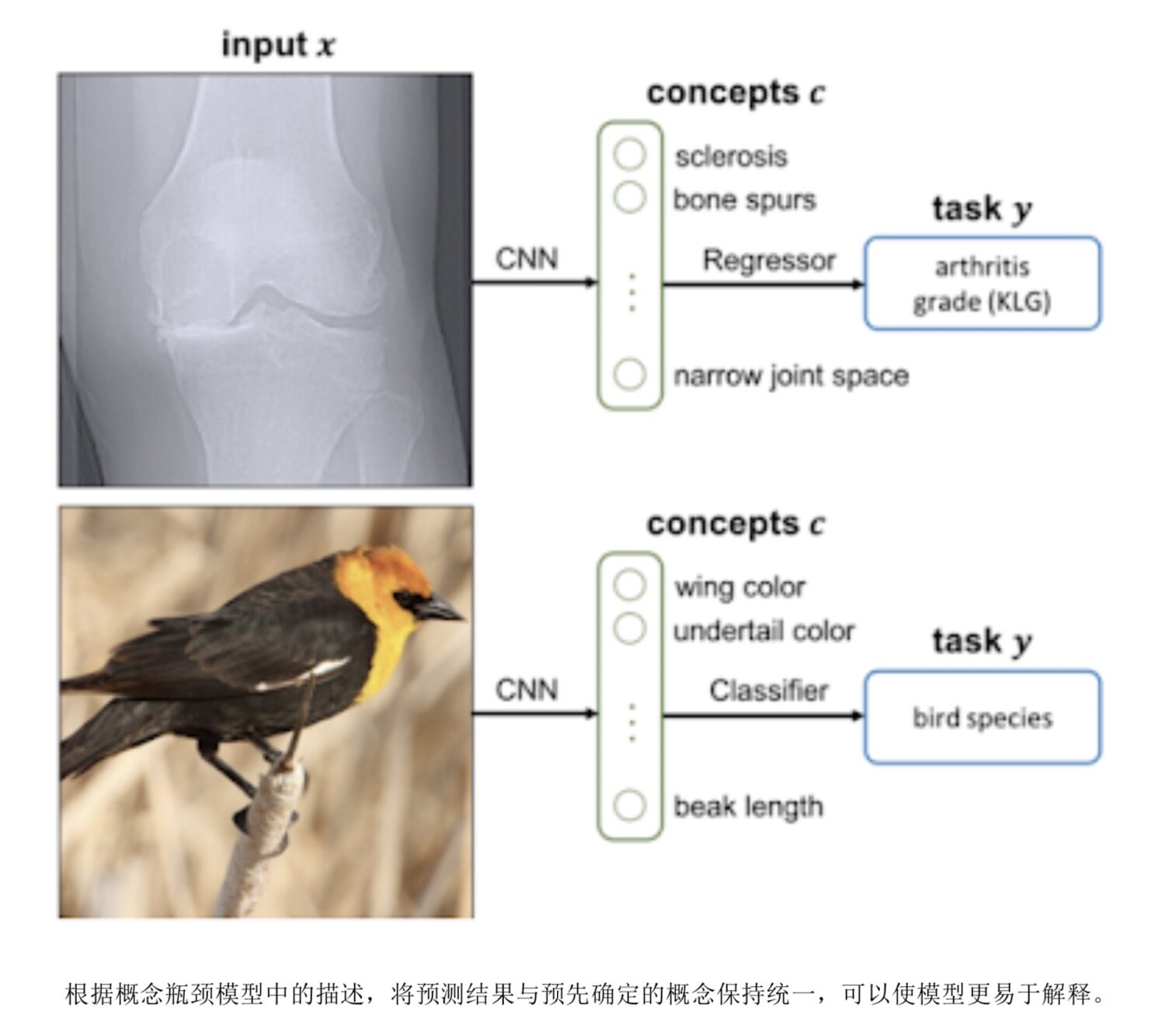
为了帮助大家更好地理解语言模型的行为,我们开发出语言可解释性工具(LIT)。这套工具包能够提高语言模型的可解释性,由此实现交互式探索并分析决策结果。我们还在预训练的语言模型中开发出可衡量性别相关性的技术,以及用于减少谷歌翻译中性别偏见问题的可扩展技术。我们使用内核技巧提出了一种简单方法,用以估计各训练数据示例对单一预测的影响。为了帮助非专业人士解释机器学习结果,我们扩展了 2019 年引入的 TCAV 技术,现在已由此建立起一套完整且充分的概念体系。在初步 TCAV 工作中,我们可以将“毛茸茸”与“长耳朵”设定为“兔子”这一预测结果的重要前提性概念。通过这项工作,我们还可以认定这两项概念足以完全解释预测结果,再不需要其他概念的引入。概念瓶颈模型则是另外一种技术,旨在通过模型训练降低该模型的解释难度。我们首先将其中一层与预定义的专业概念(例如下图中的「骨刺」与「翅膀颜色」)相匹配,而后再进行建模。如此一来,我们不仅能够解释得出最终预测结果的理由,还可以即时开启/关闭各项概念。
通过与其他各机构开展合作,我们还对语言模型的记忆效应加以研究,证明提取训练数据信息完全有可能成为各类最新大型语言模型的现实威胁。这一发现外加嵌入模型可能泄露出的信息,也许会给隐私保护工作产生重大影响(尤其是针对私有数据训练而成的模型)。在《芝麻街窃贼:基于 BERT 的 API 上的模型提取》(Thieves of Sesame Street: Model Extraction on BERT-based APIs)当中,我们证明仅对语言模型进行 API 访问的攻击者(即使只对原始模型进行少量 API 查询)完全可以建立起输出结果与原始模型具有高度相关性的模型。之后的工作又进一步证明,攻击者能够以任意准确性提取较小的模型。以 AI 安全原则为基础,我们证明即使是在部署有自适应攻击评估方案的情况下,敌对方仍可以绕过 13 种针对对抗性示例的公开防御方法。后续,我们的工作重点将放在自适应攻击的方法与手段身上,希望能帮助社区在建立更强大的模型方面取得更多进展。
对机器学习系统的检查方法本身也是个重要的探索领域。我们与各 AI 伙伴开展合作,携手定义出一套框架,能够借鉴来自航空航天、医疗设备以及金融行业的经验教训及最佳实践,借此审计软件产品中机器学习技术的实际使用情况。通过与多伦多大学及麻省理工学院的合作,我们发现在审计人脸识别系统性能时可能出现的一些道德问题。通过与华盛顿大学的合作,我们现在确定了在针对多样性及包容性目标评估算法公平性时,应遵循哪些标准来选择数据子集。为了让负责任 AI 真正服务于更多乃至全球范围内的用户,并帮助行业理解公平概念在世界各地是否具有一致性,我们分析并创建了印度算法公平框架,其中包含数据集、公平性优化、基础设施与生态系统等多个组成部分。
谷歌与多伦多大学于 2019 年合作推出的 Model Cards 项目也在稳步实现影响力增长。事实上,众多知名模型(例如 OpenAI 的 GPT-2 与 GPT-3)、谷歌的 MediaPipe 模型以及多项 Google Cloud API 都采用了 Model Cards,借此向机器学习模型用户提供关于该模型的开发信息以及在不同条件下观察到的模型行为。为了让其他人更轻松地将 Model Cards 引入自己的机器学习模型,我们还推出了 Model Card Toolkit,用以简化模型透明度报告。为了提高机器学习开发实践的透明度,我们在整个数据集开发生命周期中展示了一系列最佳实践及具体用例,包括数据需求规范与数据接纳测试等。
我们与美国国家科学基金会(NSF)合作发布并资助国家 AI 研究院发起的人与 AI 交互及协作项目。我们还发布了 MinDiff 框架,这是 TF 模型修正库中提供的一种新型正则化技术,能够高效便捷地缓解机器学习模型训练过程中存在的偏见问题。其同时还提供机器学习公平性训练房功能,可通过简单的模拟系统探索机器学习决策系统在部署并长期应用之后可能因社会环境受到的后续影响。
除了开发公平框架之外,我们还开发出能够识别并改善推荐系统体验与质量的方法,包括使用强化学习技术提高建议路线的安全度。我们也致力于提高机器学习系统的可靠性,并发现包括生成对抗示例在内的多种方法有助于提升稳健性、进而带来更强大的公平性表现。
差别隐私是一种能够明确量化的隐私保护方式,我们需要重新思考各类最基本的算法,确保其在运作过程中不会泄露任何特定个人的信息。具体来讲,差别隐私有助于解决前文提到的记忆效应与信息泄露问题。2020 年行业出现了不少振奋人心的发展,让我们能够更有效地计算出如何尽可能降低个人体验风险,同时又最大程度提升个人聚类的生成准确率。另外,我们还开放了谷歌内部工具核心中的差别隐私库,并高度关注如何防止由实数浮点表示引起的泄漏问题。事实上,谷歌也在使用这些工具生成差别个人 COVID-19 移动报告,这些报告也成为研究人员及政策决定者们手中极具价值的匿名数据来源。
为了帮助开发人员评估其分类模型的隐私属性,我们在 TensorFlow 中发布了机器学习隐私测试库。我们希望该库能够为其他更为强大的隐私测试套件提供启示,目前此套件已经面向全球各地的机器学习开发人员公开开放。
除了推动开发隐私算法的最新进展之外,我们还努力将隐私因素全面融入到底层产品结构当中。Chrome 提供的“隐私沙箱”功能就是最好的例子,它能够改变广告生态系统的基本运作方式,有助于系统化保护个人隐私。作为项目的一部分,我们发布并评估了多种不同 API,包括针对特定目标群体的联邦学习(FLoC),以及用于差别隐私衡量的聚类 API。
诞生于 2017 年的联邦学习技术现已形成一个完整的研究领域,仅 2020 年一年就发表了超过 3000 篇关于联邦学习的论文。我们在 2019 年联合其他机构发表的《联邦学习中的进步与开放性问题》(Advances and Open Problems in Federated Learning)调查论文在过去一年内被引用 367 次,其更新版本也将很快发表在《机器学习的基础与趋势》系列文章当中。去年 7 月,我们还举办了联邦学习与分析研讨会,并公开了所有研究报告及TensorFlow联邦学习教程。
我们不断推动联邦学习的发展,包括开发出新的联邦优化算法,例如自适应学习算法、后验平均算法以及在联邦环境中模拟集中式算法的技术、对互补密码协议的实质性改进等等。我们发布并部署了联合分析方案,借此对存储在用户本地设备上的原始数据进行数据科学分析。谷歌产品本身也给联邦学习提供了重要的应用平台,包括在 Gboard 中提供上下文表情符号建议,以及 Google Health Studies 借此开拓隐私保护医学研究等等。此外,在通过随机登记进行隐私放大这一研究中,我们还推出了第一种用于联邦学习的隐私财会核算机制。
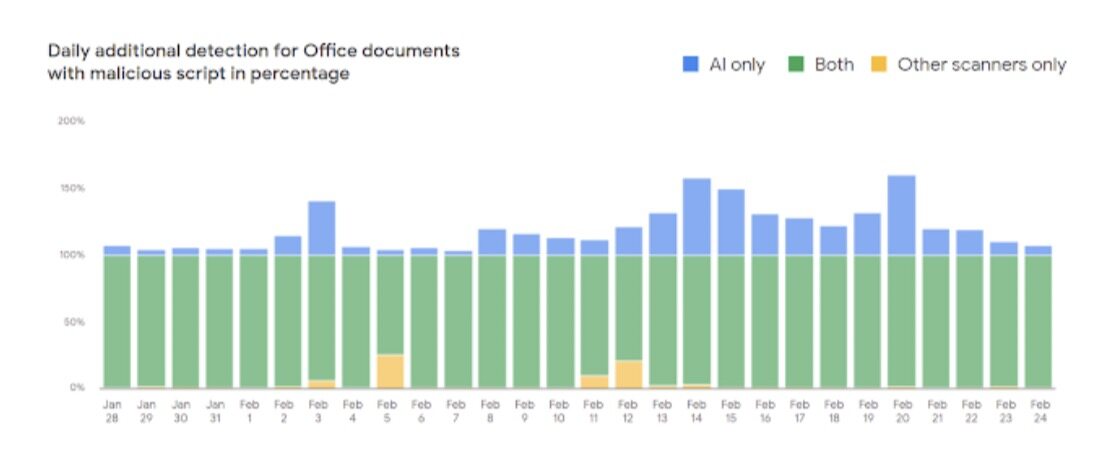
用户安全也是我们高度关注的研究领域。2020 年,我们继续部署新的机器学习文档扫描器,借此抵御恶意文档的侵袭,进一步提高对 Gmail 用户的保护力度。现在,我们将日均恶意 Office 文档检测率提高了 10%。凭借着良好的通用性,我们这款工具也在阻止其他敌对恶意软件活动方面发挥重要作用,并在特定场景下将检测成功率提高达 150%。
在账户保护方面,我们发布了一款完全开源的安全密钥固件,旨在提高双因素身份验证领域的技术应用水平。面对网络钓鱼的一波波冲击,安全密钥已经成为保护账户的最佳方法。
自然语言理解
这一年,我们在自然语言理解能力方面取得了长足进步。谷歌及其他各方的大部分自然语言理解项目普遍依赖于 Transformers——一种最初专为语言理解开发而成的特殊神经网络模型(目前有更多证据表明,其同样适用于图像、视频、语音、蛋白质折叠以及其他多个领域)。
对话系统领域的一大重要进展,在于现在的对话系统能够与用户就感兴趣的内容进行聊天,且支持期间进行的多次交互。但迄今为止这一领域中的成功案例,大多要求创建专门针对特定主题(例如 Duplex),因此无法进行通用形式的对话。为了创建出具备更高开放性对话功能的系统,我们在 2020 年发布了 Meena。这是一种常识渊博的对话代理,愿意与用户就任何话题展开讨论。Meena 还在 SSA 对话系统指标上获得高分,意味着其拥有良好的响应敏感性与特异性。根据观察,我们发现随着 Meena 模型规模的扩大,其适应对话内容的能力越来越强。而且根据相关论文的解释,适应力越强(即对话困惑度越低),SSA 得分越高。
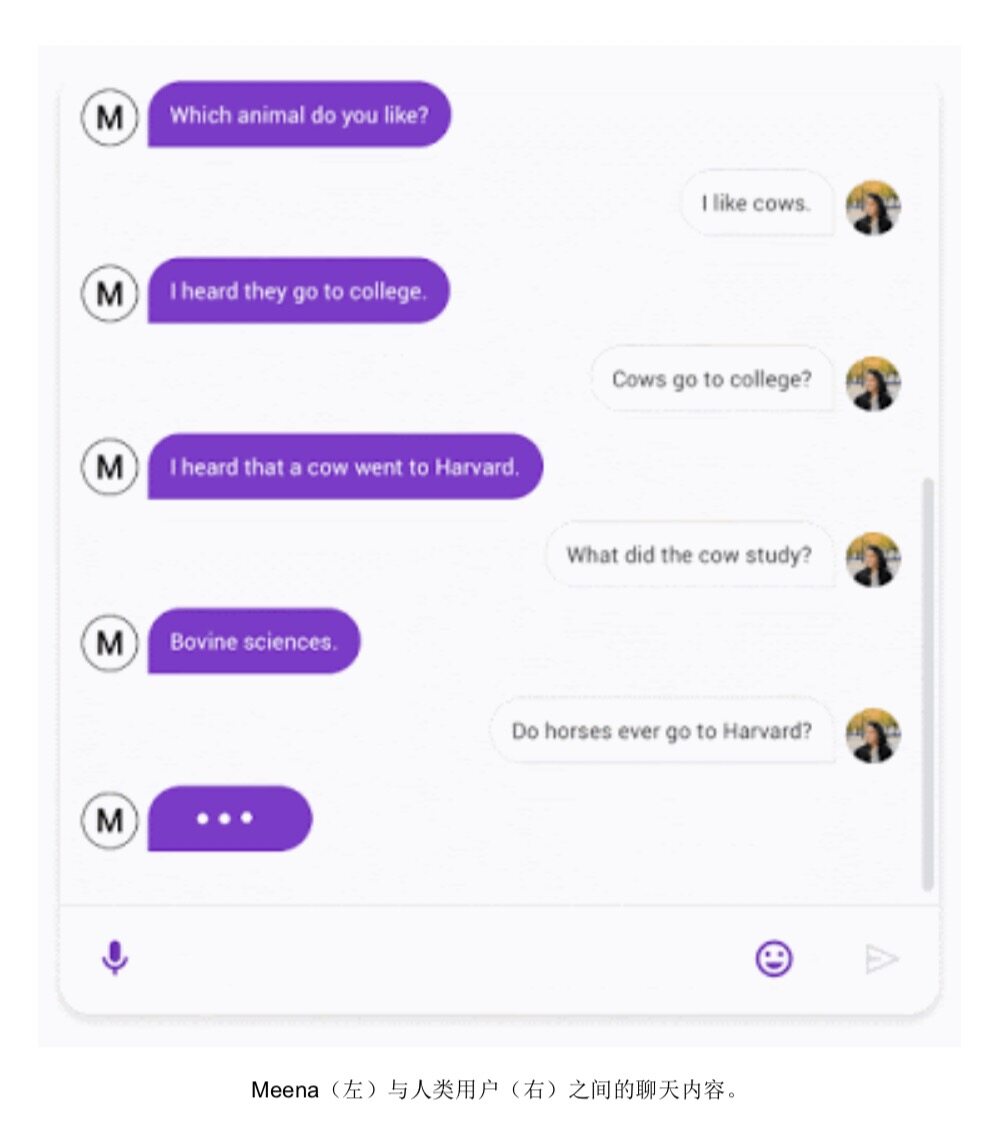
在生成式语言模型与对话系统,存在着一个广为人知的难题——在讨论事实数据时,模型容量往往不足以记住与主题相关的每一个具体细节,这意味着模型给出的结果虽然合理、但却并不正确。(当然,这不是机器所特有的问题,人类也可能犯下类似的错误。)为了在对话系统中解决此类问题,我们正尝试允许对话代理访问外部信息源(例如大量文档、文档库或者搜索引擎 API)以增强对话代理。此外,我们还尝试开发新的学习方法以作为附加资源,借此生成与检索到的文本相一致的语言。此领域的工作成果包括将检索集成至语言表示模型当中(要使其正常起效,一项关键底层技术在于 ScaNN 等方案中使用的有效矢量相似度搜索,借此将所需信息与文本语料库内的信息进行有效匹配)。一旦找到适当的内容,我们就可以由神经网络在表内查找答案、并从临时文档中提取结构化数据等方法,更好地建立起语义理解。我们在 PEGASUS(一套用于对文本摘要进行抽象的最新模型)上取得进展,能够为任意文本片段自动创建摘要——这项功能将给对话、检索系统以及多种其他用例带来重要助益。
2020 年,我们的另一大重点在于提升自然语言处理(NLP)模型的执行效率。迁移学习与多任务学习等技术,可以帮助通用 NLP 模型借助少量计算应对种种全新任务。这一领域的工作包括在 T5 中进行迁移学习探索、模型的稀疏激活(详见后文中的 Gshard 部分)以及使用 ELECTRA 提高模型预训练效率等。我们还着力推进其他几项计划,希望在基础 Transformer 架构之上做出改进。以 Reformer 为例,它使用局部敏感哈希与可逆计算有效支持更大的注意力窗口;在蛋白质建模中探索 Performers(使用线性、而非平方方法)的应用;外加通过全局与稀疏随机连接为大型结构化序列的 ETC 与 BigBird 实现线性缩放等。我们还探索用于创建极轻量级 NLP 模型的技术,此模型的大小仅为 BERT 模型的百分之一,但在某些任务上拥有几乎相同的性能表现,因此非常适合运行在边缘设备之上。在《编码、标记与实现》(Encode, Tag and Realize)中,我们则探索如何使用编辑操作(而非完全通用型文本生成方法)生成文本模型的新途径。这种方法在较少计算资源消耗、更大的所生成文本控制空间以及较低的训练数据需求等方面具有独特优势。
语言翻译
高效的语言翻译服务,可以帮助使用不同母语的人员彼此顺畅交流,进而将整个世界更紧密地联系在一起。截至目前,全球已经有超过 10 亿用户使用谷歌翻译。去年开始,我们又新增五种新的语言选项(卢旺达语、奥里亚语、鞑靼语、土库曼语与维吾尔语),目前已经有 7500 万用户使用这些语言。此外,我们还通过改进模型架构与训练方式、更好地集中处理数据噪声、多语言传输与多语言处理等技术不断提高翻译质量。从 2019 年 5 月至 2020 年 5 月,谷歌翻译提供的 100 多种语言选项整体迎来了+5 BLEU 评分提升,同时也能够更好地使用单语数据改进资源匮乏型语言(即互联网上相关书面内容较为有限的语种)的翻译效果。事实上,我们一直强调提高机器学习系统的公平性,尽可能为不同群体提供效果相仿的机器学习技术功能。
我们坚信,不断扩展多语言翻译模型将进一步带来翻译质量改进,最终为全球数十亿使用资源匮乏型语言的用户带来更好的实际体验。谷歌研究人员在《GShard:通过条件计算与自动分片实现巨型模型伸缩》(GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding)中证明,通过训练稀疏激活型多语种翻译模型(其中包含多达 6000 亿个参数),能够在 100 种语言的 BLEU 得分层面实现远优于基准水平的翻译质量。文中的图六部分展示了此项工作中的三大趋势,具体转载如下:
通过多语种训练,所有语言的 BLEU 分数都有所提高;其中资源匮乏型语言的改善效果甚至更好(图中右侧线高于左侧)。这些语言主要分布在全球各边缘化社群当中,但使用者人数仍多达数十亿。图中各个矩形,代表使用者达到 10 亿规模的语种。
模型越大、层数越多,所有语言的 BLEU 得分提高幅度就越明显(几乎没有例外)。
大型稀疏模型还证明,与训练大型密集模型相比,稀疏模型的训练计算效率提高了 10 到 100 倍;此外,其 BLEU 得分也等同甚至显著超过了大型密集模型的 BLEU 得分(论文也就此对计算效率问题做出讨论)。
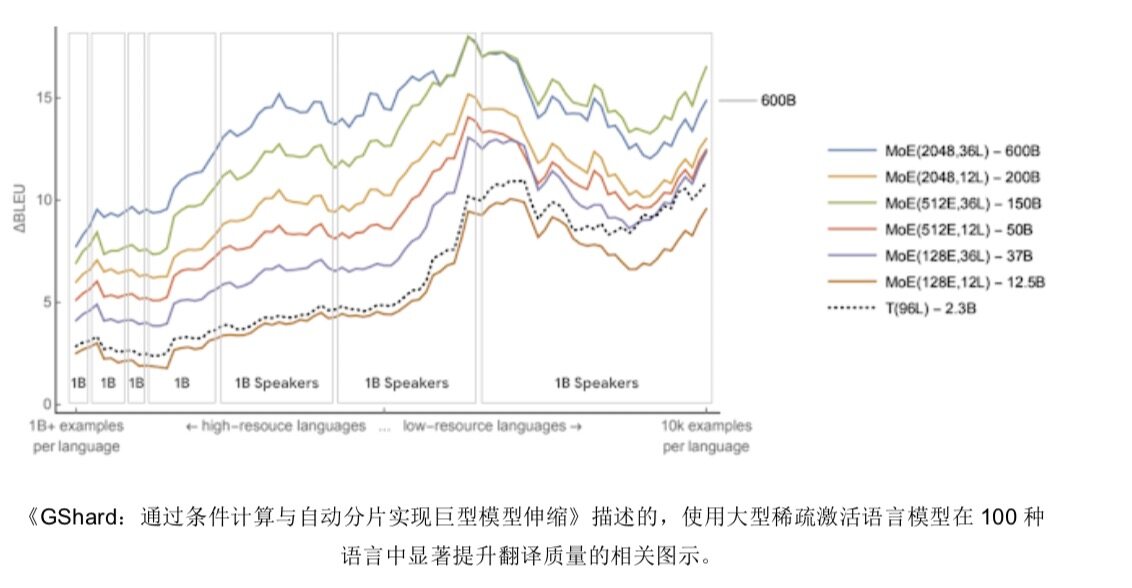
我们一直在积极努力,希望将 GShard 研究工作中得出的成果正式引入谷歌翻译,并训练出能够涵盖 1000 种语言(包括迪维希语与苏丹阿拉伯语)的单一模型,同时分享期间我们所面临且有待解决的各项挑战。
我们还开发出可为 BERT 模型创建语言中立性句子表示的技术,借此开发出更强大的翻译模型。为了高效评估翻译质量,我们引入了 BLEURT。这是一种用于评估翻译等语言生成类任务的新型指标,其不仅会考虑单词与实际数据间的重叠量,同时也能兼顾所生成文本的实际语义,具体如下表所示。

机器学习算法
我们将继续开发新的机器学习算法与训练方法,使系统能够使用较少的监督数据更快完成学习。通过在神经网络训练过程中重播中间结果,我们发现可以有效填充机器学习加速器上的闲置时间,借此加快神经网络训练速度。此外,通过在训练过程中动态改变神经元的连通性,我们还找到了优于静态连接神经网络的解决方案。我们开发出 SimCLR,一种新的自我监督与半监督学习技术,不仅能够最大程度提高同一图像在不同变换视图间的一致性,同时也让不同图像在变换视图之间的一致性处于最低水平。这种方法显著超越了原有最佳自我监督学习技术的性能水平。
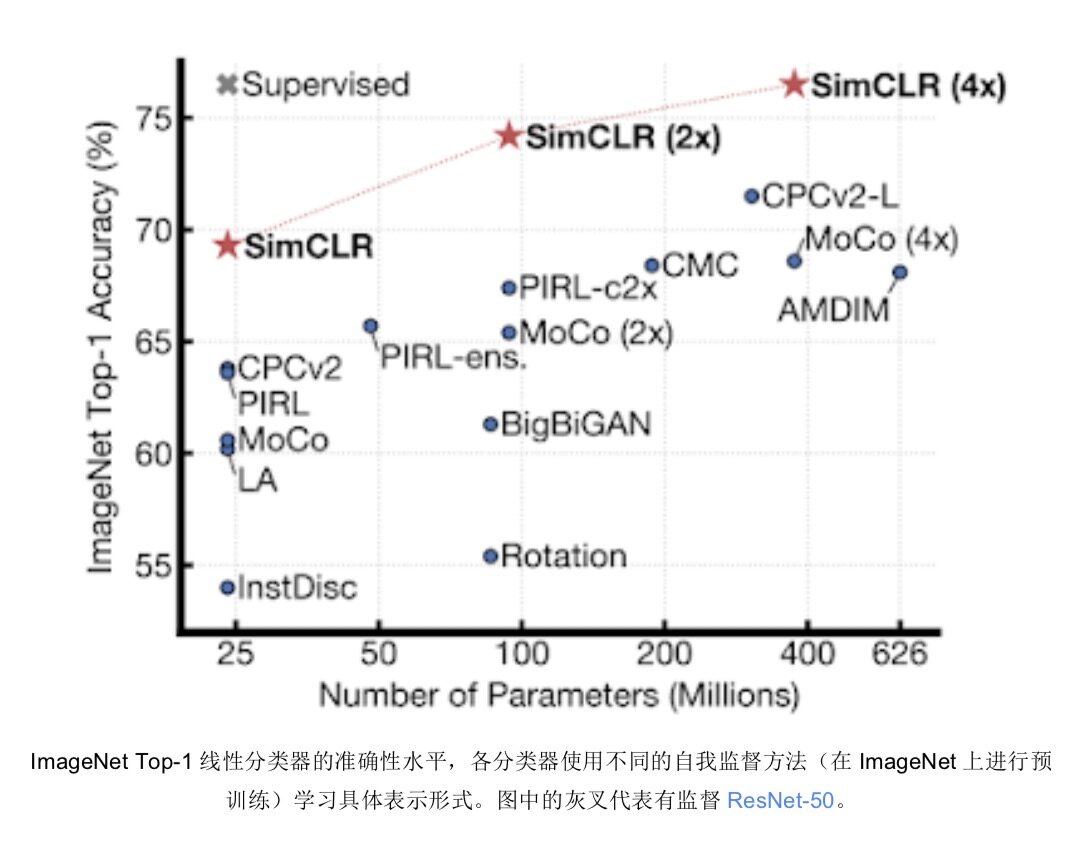
我们还将对比学习的概念扩展到监督机制当中当中,由此产生的损失函数能够大大改善监督分类问题的交叉熵。
强化学习
强化学习(RL)的本质,在于以有限的经验中总结并学习制定长期决策的核心依据。强化学习领域的一大重点挑战,是如何利用极少量固定数据点做出准确决策,并不断通过其余代理进行改进性探索,最终显著提高强化学习算法的效率。
2020 年,我们的关注重点在于离线强化学习。其仅依赖于固定且预先收集完成的数据集(例如来自先前实验或人类演示),借此将强化学习扩展至无法即时收集训练数据的应用场景当中。我们还在强化学习中引入了对偶方法,由此开发出的改进型算法可用于非策略评估、估计置信区间并实现离线策略优化等。此外,我们还与广泛的社区开展合作,尝试发布开源基准测试数据集以及雅达利 DQN 数据集来解决这些问题。

另一项研究则通过学徒学习向其他代理学习经验,借此提高样本效率。我们开发出新的方法,能够向其他经过训练的代理学习,或者从其他代理的分布匹配/对抗示例中学习模式。为了改进强化学习中的探索机制,我们尝试了基于奖励的探索方法,包括如何模仿已经对当前环境拥有先验知识的代理所产生的结构化探索结果。
我们在强化学习的数学理论方面同样取得了重大进展。我们的主要研究领域之一,在于探索如何将强化学习视为一种优化过程。我们发现了强化学习与 Frank-Wolfe 算法、动量方法、KL 散度正则化、算子理论以及收敛性分析之间的联系;这些洞见又推动我们建立起新的算法,能够在极具挑战性的强化学习基准测试中达到最佳性能,也借此让多项式传递函数回避了强化学习与监督学习中关于 softmax 的收敛问题。我们在安全强化学习这一主题之下同样取得令人振奋的进展,包括如何在遵循重要实验约束条件的情况下,发现包括安全策略优化框架在在内的各种最佳控制规则。我们还研究出如何通过高效强化学习算法解决所谓平均场博弈问题,这种博弈模型能够帮助决策者完成从移动网络布设到电网设计的多种建模需求。
我们在新任务与新环境泛化领域取得的突破,也让强化学习在面向复杂实际问题的扩展方面迈进了新的一步。2020 年,我们的重点研究方向是基于群体的“学会学习”方法,即由另一强化学习或进化代理对当前强化学习代理群体进行训练,借此建立包含多种复杂紧急情况的学习内容表,最终发现新的强化学习算法。这种能够根据训练集内各数据点的重要性做出估计,并有选择地注意某些特定视觉输入部分的能力,将给我们带来更加强大的强化学习算法。
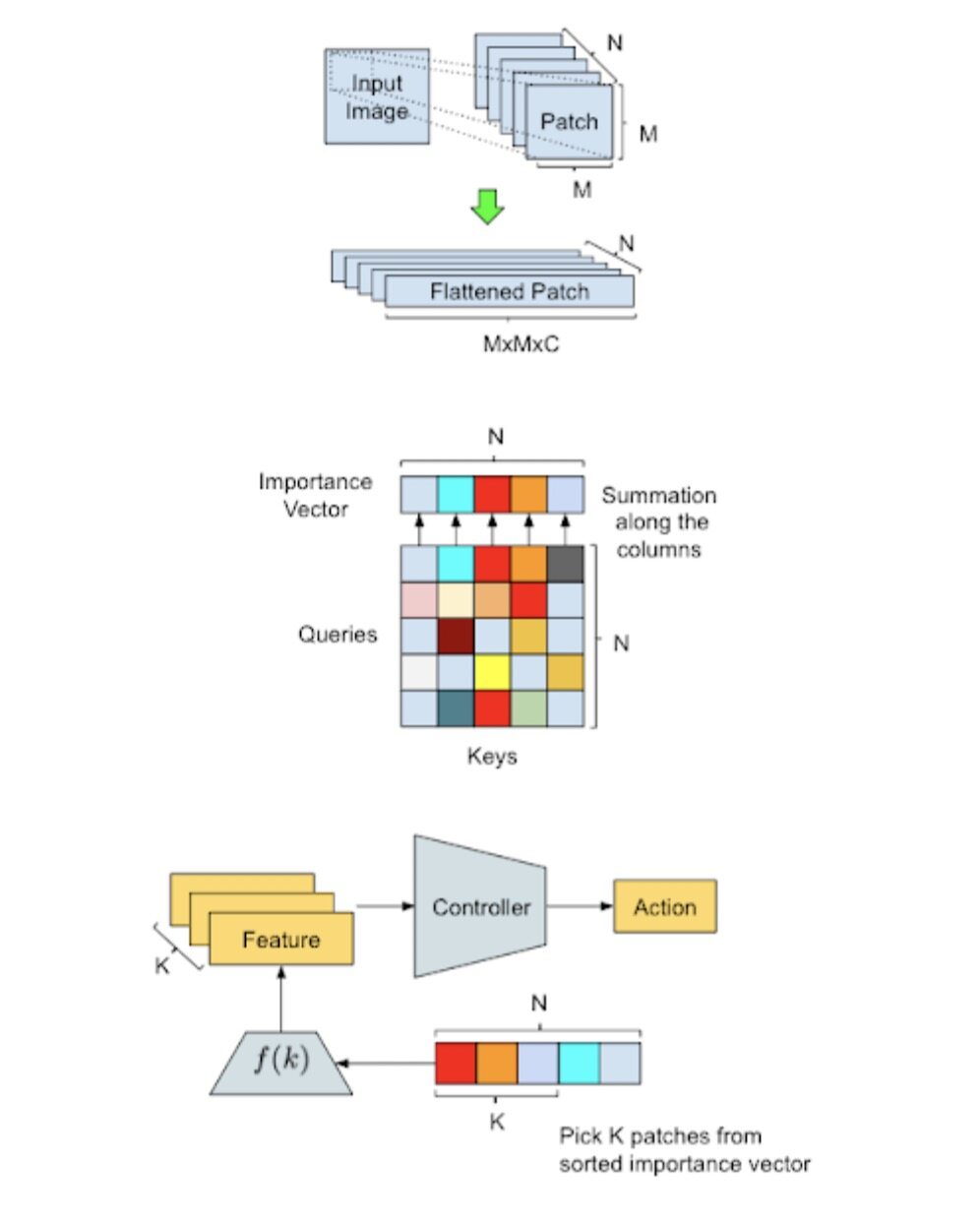
我们在 AttentionAgent 中使用的方法概述与数据处理图示。顶部图:输入转换——由滑动窗口将输入图像 分割成多个较小的块,而后再对结果进行“拉平”降维以备后续处理。中部图:补丁选举——修改之后的 自我注意模块将对各补丁进行投票,借此生成补丁的重要度向量。下部图:动作生成——AttentionAgent 会选出最重要的补丁, 取相应特征并根据这些特征做出决策。
此外,我们还证明学习预测行为模型能够加速强化学习速度,由此在不同团队中实现分散协作式多代理任务,进而学习长期行为模型并最终在基于模型的强化学习领域取得新的进展。通过观察那些能够在环境中引发预测变更的 skill,我们发现 skill 无需监督。表示形式越精准、强化学习的效果越稳定,而分层潜在空间与值改进路径则能带来更好的性能。
我们还共享了用户扩展强化学习与生产强化学习的开源工具。为了帮助用户进一步扩大能够应对的场景范围与问题类别,我们还推出了 SEED(一种大规模并发强化学习代理),发布了一套用于衡量强化学习算法可靠性的库;同时还推出 TF-Agents 的最新版本,其中包含分布式强化学习、TPU 支持以及全套的 Bandit 赌博机算法。此外,我们还对强化学习算法进行了大量实证研究,希望改善超参数选择与算法设计能力。
最后,我们还与 Loon 合作训练并部署了能够高效控制平流层气球的强化学习模型,希望借此改善各气球联网节点的功耗与导航能力。
AutoML
使用学习型算法开发新型机器学习技术与解决方案(又称元学习)代表着非常活跃且令人兴奋的研究领域。在以往的大部分相关工作中,我们一直在创建搜索空间,借此寻找如何以前所未有的方式将复杂的手工设计组件整合起来。而在《AutoML-Zero:具备学习能力的进化型代码》(AutoML-Zero: Evolving Code that Learns)中,我们开始采取不同于以往的方法,即由进化算法提供一套由原始运算(例如加法、减法、变量赋值以及矩阵乘法)组成的搜索空间,借此尝试能否从零开始发展出现代机器学习算法。事实上,具有实用价值的学习型算法非常稀少,但这套系统确实逐步发展出了越来越复杂的机器学习算法。如下图所示,该系统重现了过去三十年中诸多最重要的机器学习发现,例如线性模型、梯度下降、修正线性单元、高效学习率设置与权重初始化、以及梯度归一化等等。
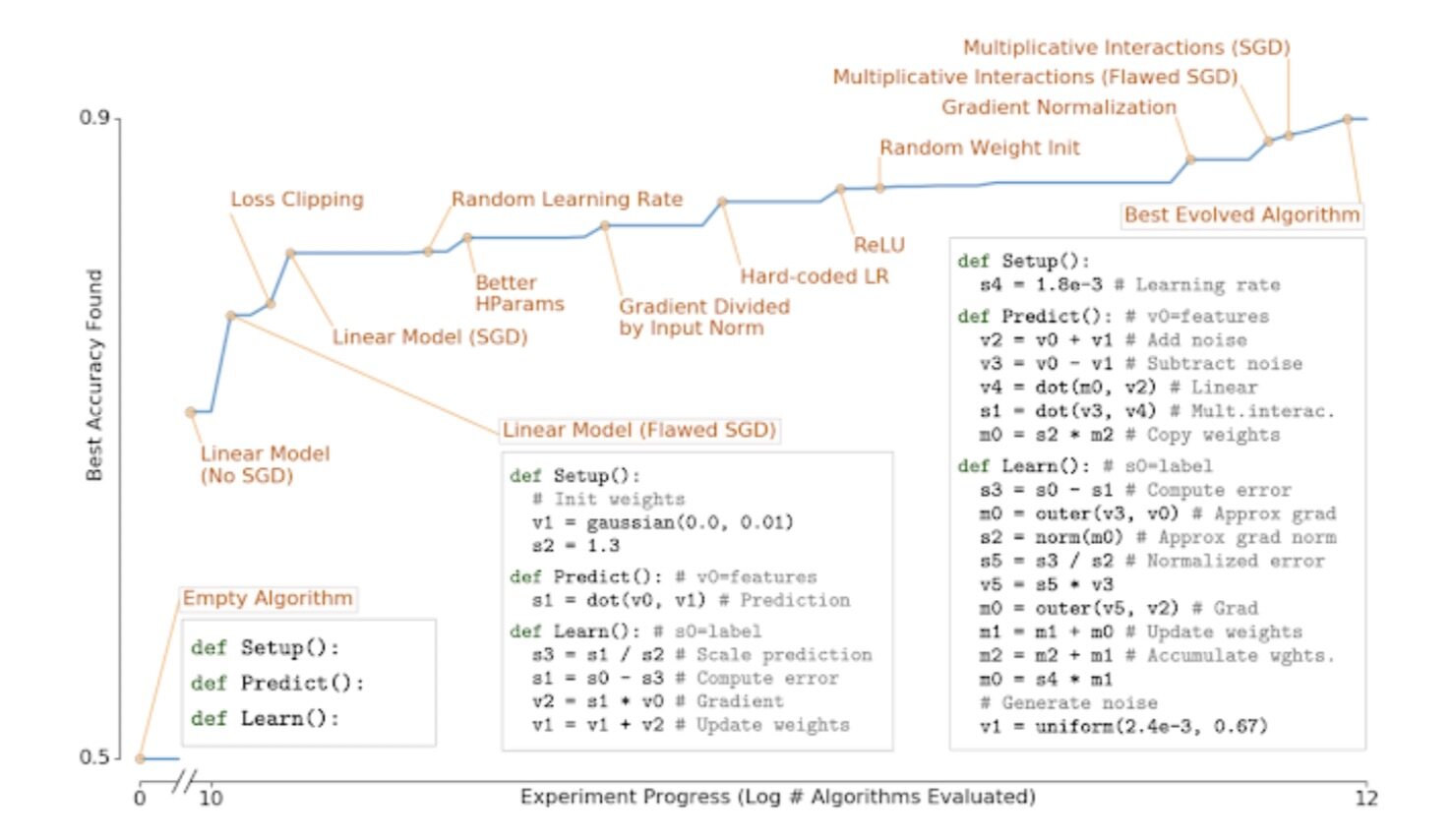
我们还使用元学习方法,发现了多种能够从静态图像及视频中检测出各类对象的多种高效架构。过去一年,我们使用 EfficientDet 这套高效图像分类架构做出种种探索,并发现其图像分类准确性明显提升、计算成本则有所降低。在后续研究中,我们发表了《EfficientNet:迈向高效可扩展的对象检测之路》(EfficientDet: Towards Scalable and Efficient Object Detection)中提到,EfficientDet 能够派生出新的对象检测与定位架构,同时在绝对准确率与计算成本方面实现显著改进。在达到与以往模型相同的准确性水平时,新模型的计算成本仅为后者的十三分之一到四十二分之一。
我们在 SpineNet 上提出一种元学习架构,其不仅能够有效保留空间信息,同时也能以更高分辨率进行检测。我们还专注于针对各类视频分类问题自主学习出新的有效架构。《AssembleNet:在视频架构中搜索多流神经连通性》(AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures);《AssembleNet ++:通过注意力连接组合出模态表示》(AssembleNet++: Assembling Modality Representations via Attention Connections);以及《AttentionNAS:用于视频分类的时空注意力单元》(AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification)具体展示了如何使用进化算法,创建出前所未有的新型视频处理机器学习架构。
这种方法还可用于开发出有效的模型架构,借此进行时序预测。《使用 AutoML 实现时间序列预测》(Using AutoML for Time Series Forecasting)中描述了一种系统,可自动在包含多种底层构建块的搜索空间内自动搜索,进而发现新的预测模型。这种方法也在 Kaggle M5 预测竞赛中凭借生成的算法证明了其有效性。该系统在 5558 种参赛方案中排名第 138(位列前 2.5%)。不同于其他需要耗费数月时间人工构建的竞争性预测模型,我们的 AutoML 解决方案能够在很短时间内找到理想模型、计算成本适中(500 个 CPU、2 个小时)且无需人为干预。
更好地理解机器学习算法与模型
深入理解机器学习算法与模型,对于设计并训练更有效的模型、以及理解模型在哪些情况下无法起效可谓至关重要。一年以来,我们专注于围绕表示能力、优化、模型概括与标签噪声等基础问题做出研究。如前文所述,Transformer 网络给语言、语音以及视觉问题建模产生了巨大的影响,但这些模型所代表的特征类别是什么?最近,我们证明 transformer 属于一种面向序列到序列函数的通用型逼近器。此外,即使稀疏 transformer 仅使用令牌之间的线性交互次数,其仍然属于通用逼近器范畴。我们也一直在开发基于分层自适应学习率的新型优化技术,希望借此提高 transformer 的收敛速度。例如,《用于深度学习的超大批量优化(LAMB):在 76 分钟内训练出 BERT 模型》(Large batch optimization for deep learning (LAMB): Training BERT in 76 minutes)。
随着神经网络在深度与广度层面的不断拓展,相关模型的训练速度得到整体加强,泛化能力也有所提升。经典学习理论认为,大规模网络应该会出现过度拟合;但正是前面这种与经典理论相悖的效果,让深度学习在实际应用中牢牢占据着主动。我们也在努力理解过度参数化状态下的神经网络。在不设宽度限制的情况下,神经网络能够采用令人惊讶的简单形式,并通过神经网络高斯过程(NNGP)或神经正切核(NTK)进行描述。我们从理论与实验两个角度出发研究这种现象,并公布了 Neural Tangents——一套由 JAX 编写的开源软件库,可供研究人员构建并训练无限宽度的神经网络(即超宽深度网络)。
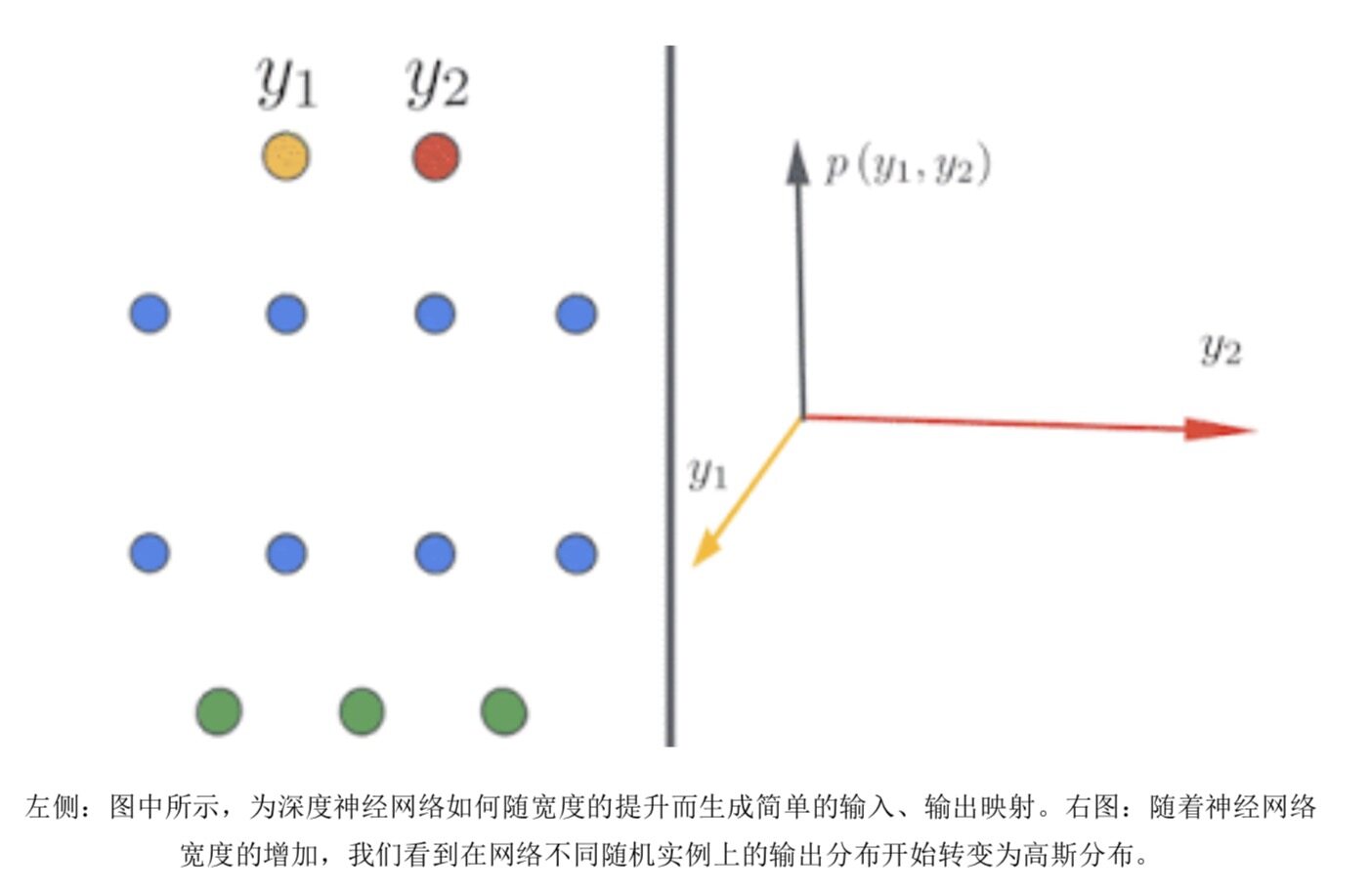
随着有限宽度网络的不断扩大,其还会表现出特殊的双重下降现象——随宽度增加,其泛化度先是变得更好、之后变得更差、接着又变得更好。我们已经证明,这种现象可以通过新的偏差-方差分解来解释,而且在进一步扩展后有可能表现为三重下降。
最后,在实际问题中,我们往往需要处理明显的标签噪音问题。例如,在大规模学习场景中,我们往往只能从高噪音标签中获取到弱标签数据。现在,我们已经开发出新的技术,能够从严重的标签噪音中提取出有效的监督信息,借此获取最佳结果。我们还进一步分析了使用随机标签进行神经网络训练的效果,证明这种方式能够增强网络参数与输入数据之间的匹配程度;与从零开始进行初始化相比,新方法还能加快下游训练速度。我们也探讨了标签平滑或梯度裁剪能否减轻标签噪音问题,由此给利用有噪声标签实现模型训练带来新的指导性洞见。
算法基础与理论
2020 年,我们在算法基础与理论方面的工作也取得了重大成果,先后发表多篇高影响力论文。在优化方面,我们探讨边缘加权在线二分匹配的论文提出一种新的在线竞争算法技术,解决了三十年来长期困扰人们的边缘加权变量这一开放性问题,相关成果已经被应用于在线广告分发当中。除此之外,我们还开发出双镜像下降技术,其有望应用于带有多样性及公平性约束的多种模型当中。我们还发表了在线调度、在线学习与在线线性优化领域,应如何使用机器学习实现在线优化的系列论文。另一项研究结果则让密集图上的经典二分匹配问题取得了五十年来的首次突破。最后,我们在另一篇论文中解决了长期存在的、如何在线追踪凸体的开放性问题——这里我们使用的仍然是The Book中的一种算法。
我们还继续在可伸缩图挖掘以及基于图的学习领域开展研究,并在 NeurIPS’20 大会上的Graph Mining & Learning at Scale Workshop研讨中以主持的身份讨论了包括图聚类、图嵌入、因果推理以及图神经网络在内的各种可伸缩图算法成果。在此次研讨中,我们展示了如何通过类似于 BigTable 的分布式哈希表,对 MapReduce 等标准同步计算框架进行扩展,借此在理论与实践层面提升部分基础图问题的处理速度。我们的广泛实证研究还验证了 AMPC 模型的实际应用潜力,这套模型的灵感来自我们在面向分层聚类与互连组件的大规模并发算法中使用的分布式哈希表。理论结果表明,这种方法能够在恒定的分发轮次中解决多种此类问题,由此极大提高计算效率。我们还在 PageRank 与随机游走计算中实现了指数级的加速成绩。在图学习领域,我们发布了 Grale,我们自主设计的机器学习图框架。此外,我们还介绍了如何构建可伸缩性更强的图神经网络模型,并证明 PageRank 能够显著加快 GNN 中的推理速度。
在作为计算机科学与经济学交叉领域的市场算法中,我们继续研究如何对在线市场做出改进,例如衡量广告竞拍中的激励属性、双边市场以及优化广告选择中的订单统计等。在重复竞拍领域,我们开发出多种框架,使得动态机制具有更强的稳健性,因此防止对当前市场及或/未来市场做出预测或估计错误,由此产生更准确且可验证的动态机制。此外,我们还描述了何时可以通过几何式标准实现渐近最优目标。我们还比较了实践中使用的一系列预算管理策略的均衡结果,证明了这些策略对于收入及买家最佳平衡点产生的影响,并阐明了其中的激励属性。再有,我们还继续研究最佳拍卖参数,并解决了批量学习中的复杂性与收益损失问题。我们还设计出最优反悔机制,研究上下文竞拍定价中的组合优化,并开发出一套新的竞拍主动学习框架,借此改善竞拍标价近似性。最后,受到竞价中激励重要性的启发,我们希望帮助各广告商深入研究激励属性在竞价活动中的影响,并为此推出了一项数据驱动型指标、用以量化特定机制与激励兼容性之间的偏离程度。
机器感知
感知我们周遭的世界——包括对视觉、听觉及多模输入形式的理解,为此建模并采取行动——仍是一个重要的研究领域,也具有巨大的发展潜力。相关突破性成果有望显著改善我们的日常生活。
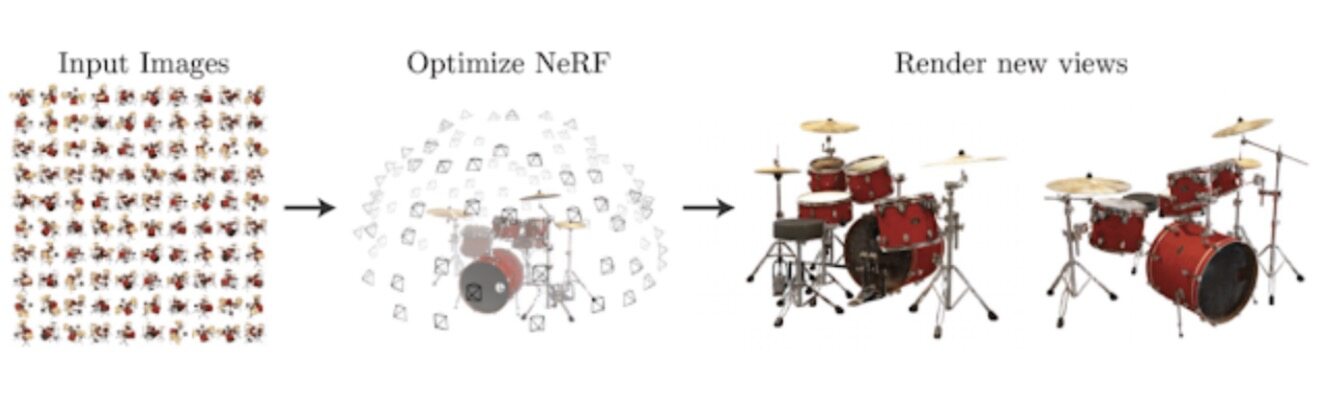
2020 年,深度学习技术衍生出能够将 3D 计算机视觉与计算机图像紧密结合的全新方法。CvxNet、用于描述 3D 形状的深层隐式函数、神经立体像素渲染与 CoReNet 都是这一领域中的典型成果。此外,我们还在研究如何将场景表示为神经辐射场(简称 NeRF),这也是谷歌研究院通过学术合作促进神经体积渲染技术的又一重要案例。
在与加州大学伯克利分校合作的《学习城市分解与照明》(Learning to Factorize and Relight a City)论文中,我们提出一套学习型框架,能够将室外场景分解为随时间变化的照明条件与永久性场景因素。以此为基础,我们能够任意生成一切“街景”式全景照明效果与场景几何,甚至能够借此生成全天延时拍摄视频。

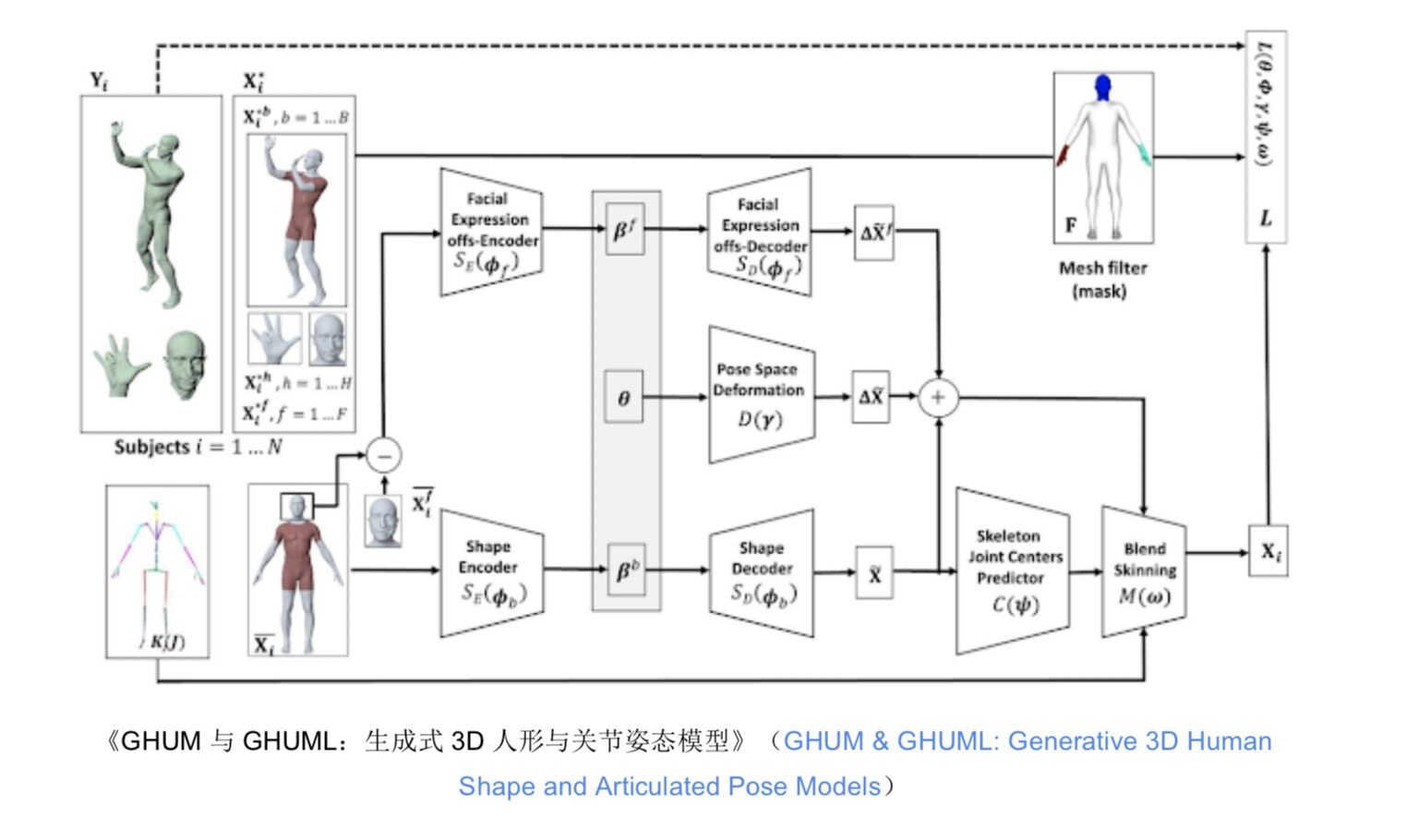
我们还着力探索生成式人形与关节姿态模型,希望在完全可训练的模块化深度学习框架中引入统计型、支持关节形态的 3D 人体建模管道。此类模型能够通过一张照片对其中的人体进行 3D 姿态与形状重构,由此更好地理解画面中的场景。
2020 年,使用神经网络进行媒体压缩的尝试也在不断升温。除了图像压缩,这项技术也开始在视频压缩、深度体积压缩方法以及深度形变中立式图像水印方面取得了不错的性能表现。

感知研究中的其他重要主题还包括:
更好地使用数据资源(例如通过有噪声学员进行自我训练,从模拟数据中学习,从有噪声标签中学习,对比学习等)。
跨模推理(例如,使用跨模监督、视听语音增强、语言基础、采用本地化特征描述的 Open Images(V6)更新——可将视觉与语言以多模注释方式联系起来)。
开发执行效率更高的感知方法,特别是可运行在边缘设备上的方法(例如快速稀疏卷积,用于模型压缩的结构化多哈希等)。
增强对各类对象及场景进行表示与推理的能力(例如检测 3D 对象并预测 3D 形状、通过单一 RGB 图像重构 3D 场景、利用时间上下文进行对象检测、学习查看透明对象并通过立体关系估计其姿态)。
利用 AI 支持人类创造力(例如根据网页自动创建视频、智能视频重构、使用 GAN 创造奇幻生物、照亮画像等)。
我们还通过开源解决方案及数据集,同更广泛的研究社区进行互动,希望携手推进感知研究的发展。2020 年,我们开源了 MediaPipe 中的几种新型感知推理功能及解决方案,包括基于设备的人脸、手部与姿态预测;实时身体姿态跟踪;实时虹膜跟踪与深度估计;以及实时 3D 对象检测。

在机器学习技术的支持下,我们还在不断改善移动设备的使用体验。我们得以在移动设备上运行更复杂、更强大的自然语言处理功能,由此实现更自然的对话体验。2020 年,我们还扩展了 Call Screen 并新发布 Hold for Me,帮助用户更快处理多种日常任务;另外,我们还在 Recorder 应用中提供基于自然语言的操作与导航功能,借此提高用户的工作效率。
我们还使用谷歌的 Duplex 技术向各业务部门发起呼叫,确认需要临时关闭的功能。以此为基础,我们得以在全球范围内对业务信息进行 300 万次更新,更新结果已经在地图与搜索内获得超过 200 亿次浏览。我们还使用文本到语音技术,借此让谷歌助手通过 42 种语言大声朗读文本,借此降低页面的访问难度。
我们也在不断对拍摄应用做出改进。我们通过更多创新控件及功能在谷歌相册中提供光照调节、编辑、增强与重现等功能,由此帮助用户轻松在 Pixel 上留下珍贵的回忆。从 Pixel 4 与 4a 机型开始,我们在拍照应用中引入了 Live HDR +,其使用机器学习技术培训在取景器中实时估算 HDR +连拍摄影的动态、曝光与效果均衡。我们还开发出双重曝光控件,允许用户在取景器内实时调整场景内暗部与亮部的具体亮度。
最近,我们还推出了 Portrait Light 肖像光功能,这是一种用于 Pixel Camera 与谷歌相处应用的全新后期捕捉功能。此功能可为肖像添加模拟定向光源。此功能同样采用机器学习技术,已经在超过 70 位测试人员身上进行训练,并配合包含 331 个 LED 灯珠的 Light Stage 计算照明系统中完成了全面的光照效果学习。
过去一年中,谷歌研究人员还在谷歌产品的具体使用方式层面作出不少探索,其中包括:
通过增强现实轻松获取家庭作业帮助或 3D 概念探索,借此增强学习效果。
在浏览器内部实现背景模糊,借此改善虚拟会议效果。这项功能已被正式引入 Google Meet。
提供新的方式,可帮助用户在家中虚拟试用新产品。
通过视频内的关键帧,帮助用户快速找到最相关的内容。
通过哼唱帮助用户找到听到的歌曲。
帮助 YouTube 识别出有害内容,以供进一步人工审核。
通过自动声音增强与背景降噪,帮助 YouTube 创作者制作出更好的视频。
机器人
在机器人研究领域,我们使用前文介绍过的多项强化学习技术,尝试使用更少的数据学习到更复杂、更安全且更健壮的机器人行为,并由此取得了长足进步。
Transporter Networks是一种能够将机器人任务表示为空间位移形式的全新学习方法。与环境中的绝对位置相反,Transporter Networks 能够以非常高效的方式在表示对象与机器人末端执行器之间建立关联,帮助机器人快速学会在当前工作区内行动。

在Grounding Language in Play中,我们展示了如何教导机器人根据自然语言指令(支持多个语种)执行任务。很明显,我们需要一种可扩展的方法,用以收集自然语言指令与机器人行为之间的配对数据。通过研究,我们发现可以通过呼叫机器人操作器轻松与机器人交互,之后再将指令效果整理为标签并加以调整、借此引导机器人逐步学会如何正确执行指令。

我们还尝试了完全不经由机器人本体(由人类手持配备有摄像头的抓杆)以收集更具可伸缩性的数据,借此探索怎样更有铲地跨越多种机器人类型传递视觉表示。
我们还研究了如何从自然界中汲取灵感,使用进化型元学习策略、人类演示以及深度强化学习训练数据控制器等方法,总结出高度敏捷的机器人运动策略。

这一年中,人们对于安全性的关注进一步提升:我们如何才能在现实世界中安全部署配送无人机?我们如何保证机器人在探索世界的同时,不至于陷入无法挽回的困境?我们要如何证明学习行为的稳定性?面对这一关键研究领域,我们未来将继续做出积极探索。
量子计算
我们的Quantum AI团队继续致力于探索量子计算技术的实际应用。我们在 Sycamore 处理器上运行了实验算法,借此模拟与化学及物理相关的系统。这些模拟场景在规模上已经逼近经典计算机的可行性极限,也在实质上验证着费曼当初提出的、使用量子计算机模拟重要量子效应系统的基本思路。我们还发布了新的量子算法,例如执行精确的处理器校准、证明量子机器学习优势以及测试量子增强优化效果等。我们还发布了 qsim,这是一种高效的仿真工具,能够在 Google Cloud 上开发并测试最高使用 40 量子比特的量子算法。
我们还在继续探索发展路线图,希望构建起通用性质的纠错量子计算机。我们的下一个里程碑,在于证明量子纠错能够在实践层面发挥作用。为了达成这个目标,我们需要证明尽管量子比特、耦合器或者 I/O 设备等单一组件中存在缺陷,但规模更大的量子比特网格仍能够在逻辑信息的存储时长方面实现指数级增长。更令我们兴奋的是,现在我们已经拥有自己的无尘室,能够大大提高处理器制造工作的速度与质量。
支持更广泛的开发人员与研究人员社区
2020 年,TensorFLow 迎来了五岁生日,项目下载量已经走完 1.6 亿次。TensorFlow 社区也一直通过新的特别兴趣小组、TensorFlow 用户群组、TensorFlow 证书、AI 服务合作伙伴以及#TFCommunitySpotlight启发性演示保持着惊人的规模增长。我们还通过无缝 TPU 支持、开箱即用高性能(在 MLPerf 0.7 上取得了同类最佳性能)、数据预处理、分发策略以及新的 NumPy API 给 TF2.x 带来显著改进。
我们还向 TensorFlow 生态系统中引入更多新功能,希望帮助开发人员与研究人员高效处理工作流程:Sounds of India 使用 TFX 进行训练,并以 TF.js 的形式部署在浏览器内,借此在短短 90 天之内完成了从研究到生产的整个过程。借助 Mesh TensorFlow,我们突破了模型并发性的边界,得以提供超高分辨率的图像分析能力。我们还开源了新的 TF 运行时,用于进行模型性能调试的 TF Profiler,以及多种负责任 AI 工具——例如实现模型透明化的 Model Card Toolkit、外加一套隐私测试库。借助 TensorBoard.dev,您可以免费托管、跟踪并共享自己的机器学习实验。
此外,我们还进一步加大了对 JAX 的投入。JAX 是过去两年以来发展迅猛、主要关注学术研究方向的机器学习系统。谷歌及其他企业的研究人员目前已经在广泛使用 JAX,具体场景涵盖差别隐私、神经渲染、遵循物理原理的网络、fast attention、分子动力学、张量网络、神经正切核与神经 ODE 等。JAX 还加快了 DeepMind 的研究进程,为不断发展的库生态系统提供劲力,同时也给 GAN、元梯度、强化学习等探索注入能量。我们还使用 JAX 与 Flax 神经网络库建立起创纪录的 MLPerf 基准测试性能,在 NeurIPS 大会上展示了下一代云 TPU Pod 的强大使用体验。最后,我们还努力保证 JAX 能够与各 TF 生态系统工具无缝协作,包括 TF.data 数据预处理、TensorBoard 实验可视化以及 TF Profiler 性能调试等等。2021 年,我们还将不断推出更多新的功能。
算力的不断提升让我们迎来一系列重大突破,我们则通过 TFRC 计划向全球研究人员免费提供超过 500 千万亿次的云 TPU 算力资源,希望借此帮助学术社群探索机器学习研究议题。截至目前,学界已经发表 120 多篇 TFRC 支持下的论文。如果没有该项目提供的海量计算资源,相当一部分成果根本不可能达成。例如,TFRC 研究人员最近开发了野火蔓延模拟模型、帮助用户分析社交媒体上的 COVID-19 舆情与疫苗关注度变化,同时也幸了我们对于博彩假设与神经网络剪枝的整体理解。TFRC 社区的成员们还发表了关于波斯诗歌的实验,在 Kaggle 竞赛中赢下细粒度时尚图像分割挑战,更重要的所有教程及开源工具均实现了全面共享。2021 年,云 TPU 将在 TensorFlow 之外新增对 JAX 及 PyTorch 的支持,因此我们有意将 TFRC 计划更名为 TPU 研究云计划,更明确地体现其广泛包容的定位。
最后,2020 年对于 Colab 同样是非常重要的一年。Colab 的使用量增加了一倍,我们也推出多项生产级功能以帮助用户高效完成工作——包括改进 Drive 集成以及通过终端访问 Colab 虚拟机。我们还推出了 Colab Pro,帮助用户获取更强大的 GPU、延长运行时间并使用更高的内存容量。
开放数据集与数据集搜索
具有明确且可量化目标的开放数据集,一直在机器学习技术的发展当中扮演着至关重要的角色。为了帮助研究社区获得更多有趣的数据集,我们将继续通过谷歌数据集搜索功能为不同组织发布的各类开放数据集建立索引。我们还认为,更重要的是创建新的数据集以供社区用于开发新型技术,同时还应保证以负责任的方式共享这些开放数据。2020 年,除了帮助解决新冠疫情危机的开放数据集之外,我们还在其他多个不同领域发布了多种开放数据集:
使用数据集搜索功能分析在线数据集:一套囊括多种数据集的元数据集。
谷歌计算集群跟踪数据:2011 年,谷歌在一套内部计算集群上发布了为期 29 天的计算活动跟踪,事实证明这一尝试帮助计算机系统社区更好地探索出作业调度策略,也帮助各方更深入地理解了集群资源的利用率情况。2020 年,我们发布了规模更大的新版本,涵盖 8 套内部计算集群,提供的信息也更为详尽。
发布 Objectron 数据集:这套数据集包含 15000 段以对象为中心的短视频素材,各视频片段还带有 3D 边界框,从多个角度捕捉出一组规模庞大的公共对象。此外,数据集还从具有良好地理多样性的样本中收集到 400 万张带有注释的图像(涵盖五大洲的 10 个国家/地区)。
Open Images V6——现具有本地化特征描述:除了继承 V5 版本中拥有的 9000 万张注释图像、3600 万条图像级标签、1580 万个边界框、280 万条实例分割记录以及 391000 项视觉关系之外,新版本还引入了本地化特征描述。这是一种全新的多模注释形式,涵盖所描述对象上的同步语音、文本与鼠标轨迹。在 Open Images V6 中,本地化特征描述已经覆盖 50 万张图像。为了便于同以往成果进行比较,我们还为 COCO 数据集发布了涵盖全部 123000 张图像的本地化特征描述。
我们与华盛顿大学以及普林斯顿大学的研究人员合作创办了 Efficient Open-Domain Question Answering 挑战赛与研讨会,希望参赛者能够创建出可以回答任何问题的系统。关于竞赛及研讨的更多详细信息,请参阅技术报告。
TyDi QA:一项多语种问答基准测试,旨在探索新的多语种问答效率基准(目前这一领域中的大多数基准只支持单一语种,我们认为必须扩展出多语种支持能力)。
Wiki-40B:多语种语言模型数据集。这是一种新的多语种模型基准测试,包含 40 多种语言且涵盖数个脚本及语言族别。凭借约 400 亿个字符,我们希望这一新资源能够加速多语种建模领域的研究进度。我们还在这套数据集上训练并发布了高质量训练语言模型,可帮助研究人员轻松比较不同技术在这项基准测试上的差异。
XTREME:用于评估跨语言泛化效果的大规模多语种多任务基准测试,可帮助研究人员评估多任务环境下的跨语言泛化水平。
如何提高问题质量?(How to Ask Better Questions?)这是一套面向 Rewriting III-Formed Questions 的大规模多维数据集,提供跨 3030 个领域的 427719 个问题/答案对,可用于训练模型以将存在格式错误的问题重写为质量更高的形式。
Open-Sourcing Big Transfer (BiT):一套用于探索大规模计算机视觉预训练效果的开源预训练模型,可作为多种图像相关任务的理想起点。
与捷克维多利亚大学、捷克科技大学以及 EPFL 合作创办的 2020 图像匹配基准与挑战赛,旨在通过一套数据集发起基准挑战,借此解决从运动中(包括视频或通过多个不同角度捕捉的静态图像)捕捉 3D 结构的问题。
元数据集:用于少量样本学习的数据集的数据集。这是一套囊括多种数据集的数据集。机器学习领域拥有一项长期目标,即构建出一套能够在几乎无需额外训练的前提下、将某一任务中的示例推广至另一任务示例的系统。这套元数据集有助于我们衡量这一终极目标的当前达成进度。
Google Landmarks Dataset v2——一项用于实例级识别与检索的大型基准测试,用于在人造及自然地标场景下进行大规模、细粒度的实例识别与图像检索。GLDv2 是截至目前规模最大的此类数据集,其中包含超过 500 万张图像与 20 万个不同的实例标签。其测试集拥有 11 万 8 千张带有真实情况注释的图像,可用于各类检索及识别任务。
增强研究社区在“真实语言任务”中对街景全景素材的访问权限。这是一套新的开放数据集,可向研究人员提供街景全景素材以比较真实语言导航或者其他依赖于此类数据的任务,借此比较不同技术方案之间的性能差异。
研究社区互动
我们热衷于热情支持并广泛参与研究社区的日常运作。2020 年,谷歌研究人员在各顶级研究会议上发表了 500 多篇论文,同时也担任过项目组委会、研讨会、教程编撰等活动的组织方。关于我们 2020 年在各大型研讨会议中的具体贡献信息,请参阅关于ICLR 2020,CVPR 2020,ACL 2020,ICML 2020,ECCV 2020以及NeurIPS 2020的博文。
2020 年,我们在外部研究方面投入了 3700 万美元资金,其中包括 850 万美元 COVID 研究资金、800 万美元包容性与公平性研究资金,以及 200 万美元负责任 AI 研究资金。去年 2 月,我们公布了 2019 年谷歌教职员工研究奖获奖名单,希望资助来自全球的 150 名教职员工的研究计划。其中有 27%的获奖者源自历史上技术领域的边缘社。我们还公布了一项新的研究学者计划,计划以不设上限的奖励数额支持当前从事谷歌相关领域研究的年轻学术人才。十多年以来,我们还一直鼓励博士生们申请 Google PhD Fellowships 奖学金,帮助他们在获得资助的同时申请研究方向指导,同时为他们提供与其他 Google PhD Fellows 研究员互动的机会。
我们还在不断扩展新的包容性方法,希望将更多新的声音带入计算机科学领域。2020 年,我们建立了新的包容性研究奖项目,旨在帮助传统意义上的低关注度群体提供计算与技术领域的学术研究支持。在首批获奖名单中,我们与 25 位主要研究员共同选择了 16 项资助提案,重点涵盖多样性与包容性、算法偏见、教育创新、健康工具、辅助功能、性别偏见、社会公益 AI、安全与社会公平等议题。我们还与西班牙裔服务机构计算联盟(CAHSI)以及教授联盟 CMD-IT 多样化未来领导者项目(FLIP)开展合作,帮助更多处于传统边缘群体的博士生顺利完成最后一学年内的论文发表工作。
2019 年,谷歌 CS 研究指导计划(CSRMP)向 37 名本科生提供指导,帮助他们深入了解计算机科学的研究过程。结合 2019/2020 学年的成功经验,我们决定在 2020/2021 学年积极扩展计划规模,组织数百名谷歌研究员为本科生们提供一对一指导,鼓励更多来自传统边缘社群的年轻学子迈入计算机科学研究领域。最后,去年 10 月我们向全球 50 个机构提供 explorerCSR 奖励,用于奖励那些向传统边缘群体本科生举办讲习班的教师,引导更多年轻人从事计算机科学研究。
展望未来
从开发下一代 AI 模型到建立不断壮大的研究人员社区,我们对未来的一切始终充满期待。
我们将继续以 AI 原则为指导框架,高度关注各项技术议题可能引发的广泛社会影响,希望确保 AI 技术能够负责任地产生积极影响。前文提及的负责任 AI 论文只是谷歌过去一年中相关研究中的冰山一角。在相关研究当中,我们将专注于:
提高研究完整性:确保谷歌继续以适当方式推进广泛研究,并针对各种有趣且极具挑战的议题提供全面的科学观点。
致力于负责任 AI 的发展:我们将继续以应对棘手议题作为工作核心。谷歌也会不断创建新的机器学习算法,保证机器学习技术更加高效、易于访问,同时找到新的方法以应对语言模型中的不公平偏见,设计新方案以保护学习系统内的隐私等等。更重要的是,除了殷切期待 AI 技术本身的发展之外,我们也将高度关注社区内其他成员在缓解潜在风险方面的努力,确保新技术给整个人类社会带来更公平、更积极的影响。
促进多样性、公平性与包容性:我们深切关注产品与计算系统的构建方法,要求保证这些成果能够更好地反映世界各地人群的使用习惯与切身利益。在谷歌研究院乃至更广泛的研究及学术领域,我们呼吁各学术及行业合作伙伴共同为此做出努力。就个人而言,我在过去几年中已经为这方面目标投入数百个小时,同时为伯克利、卡耐基梅隆、康奈尔、佐治亚理工学院、霍华德大学、华盛顿大学以及众多其他组织提供包容性支持。这项工作对我个人、谷歌乃至整个计算机科学界而言,都非常重要。
最后,展望未来,我希望能够出现更多对数据规模依赖度更低,可以处理多种模式且能够灵活解决新任务的通用型机器学习模型。机器学习领域的进步将给人们带来功能更强大的产品,包括给全球数十亿人提供更好的翻译质量、语音识别效果、语言理解以及创作支持。
原文链接:
https://ai.googleblog.com/2021/01/google-research-looking-back-at-2020.html
相关阅读:




