
本文整理自汪源在 ArchSummit 深圳 2021 上的演讲:《《打造开放的云原生操作系统和系统软件架构》。
真正的云原生,必须以一套技术体系支持任意负载,运行于任意云环境。
大家早上好,我今天给大家分享我们的基础软件建设。网易杭州研究院在整个网易集团的主要职责是为网易的非游戏业务构建统一的技术平台,来支撑网易音乐、网易新闻、严选,以及之前的考拉海购的业务需求。在 2019 年的时候,我们把考拉海购出售给阿里集团了,但是在之前,考拉也曾经一度是我们最大的一个支撑对象。所以对我们来讲,重点就是要去探索一个比较统一的、开放的、自主可控的技术架构,来满足我们的业务需求。
这三年我们也给很多外部的客户提供了一些服务,大家的认知也非常一致:中大型的企业需要一个自主可控的体系,在当前计算环境下能够形成一个对于企业来说可以长期发展和演化的技术演进的路线。我的演讲标题为《打造开放的云原生操作系统和系统软件架构》,实际上这两个领域都是基础软件的范畴,一般来讲操作系统、数据库、中间件,也包括现在的大数据计算、机器学习平台、开发工具等等,都是基础软件的范畴。
为什么要做云原生操作系统
我今天的分享包括四个部分。
第一部分,我想介绍一下我们为什么要去做这个事情。当时有几个方面的因素需要考虑。第一点是我们当时已经实现了互联网业务的大规模上云。从 2012 年开始网易就基于 OpenStack 研发了一套基于虚拟化技术的私有云。2018 年的时候,95% 以上的互联网业务已经上云,整个私有云规模超过五千个节点。同时在大数据领域,我们整体上围绕着 Hadoop、Spark 这样的技术,实现了大数据技术的平台化。
另外,我们基本上所有的业务在 2018 年的时候实现了微服务化,服务的数量超过一千。其中考拉是最大的,考拉最多的时候达到了七百个服务;网易云音乐当时大概是三四百个服务,现在也更多了。我们当时还基于虚拟化的技术整体研发了将近十个的 PaaS 服务,包括 RDS、MongoDB、MQ 等等。
我们分析过当时的架构遇到一些什么样的痛点和问题,我相信这些问题,大家或多或少也会遇到。总结起来主要是四个方面。
第一个是效率不够高。我们的业务都已经进行了微服务的拆分,那么对研发迭代的需求实际上要求很高,但是我们微服务的实现底层依赖的是虚拟化的技术。这个技术相对来说会比较重,我们统计了一下,一次典型的应用发布要 12 分钟左右,那么这个时间是比较不理想的。我们的目标是要优化到两分钟以内。当时我们看到 Facebook 有公布一个数据,应用发布的时间如果超过一分半钟,那么你的工作效率就会比较明显的受到一些影响,包括程序员的心态也会受到一些影响。
第二个是系统运行的成本比较高。我们通过虚拟化之后把资源利用率从平均不到 10% 提升到 20% 到 30% 左右,但是我们发现利用率就停留在 20% 到 30%,再也提高不上去了,这个成本还是很高的。理论上来讲,我们最好能够把它优化到 50% 到 60%。
另外,我们的 PaaS 服务,每个服务都需要三到五个人的团队去开发和维护,这对我们来说,成本是非常高的,比如说一个 RDS 的服务要 5 个人,一个 MQ 的服务可能要 3 个人。
第三个是系统的弹性会比较差。在那个时候我们已经遇到一些对弹性要求比较高的场景,比如说考拉双十一、音乐年终的盘点,这些时候我们会发现自有 IDC 的容量不够。因为自有的 IDC 是不可能去堆非常多的空闲容量来满足这些临时性的活动需求的,但是我们的架构那时候又很难灵活地扩展到比如说像阿里云这样的公有云上面去。
我们面临的自有 IDC 的资源不够,但在自有 IDC 内部,我们又发现系统各个集群之间的资源比较割裂,不能能够灵活的相互调配。所以在一些活动的时候,我们发现虽然我们的总资源是够的,但是要进行调配会比较困难。当时我作为这个中间协调的人,经常需要为考拉的活动去找各个 BU 来借服务器用,这个过程是非常复杂,非常麻烦的。
我们发现还有一个很大的问题就是维护难,最突出的是,我们基于 RPC、SDK 这样的中间件技术,它跟应用之间是耦合的,所以我们的中间件没法灵活的去迭代,那面临这些问题怎么办呢?我们当时看到在环境上有一些新的变化,使得我们有能力去比较好地解决这个问题。最主要的是云原生技术在 2018 年已经展现出一个非常好的势头,这其中最主要的是 K8s 和容器,我们就坚定地选择了围绕 K8s 去构建我们云原生的技术。虽然当时还有像 Docker Swarm,还有像 Mesos 等等一些竞争的技术。但我们认为 K8s 是未来的一个主流。
当时也看到 Service Mesh 已经开始起步,虽然当时我们选择了 Istio+Envoy 去做我们的 Service Mesh 基础框架的时候,心里还是比较惶恐的,因为在 2018 年的时候,非常难以看出来,Service Mesh 的社区主流技术到底是哪个。但幸运的是,到目前为止这两个还是 Service Mesh 社区里面最主流的技术。

另外,在硬件的环境上,我们发现在那个时候也有些新的变化是对构建新的系统和技术架构有利的,其中一个比如说高速网络,我们发现 25G 的网络可能很快就可以普及。
然后就是智能网卡。我们在那个时候就开始跟英特尔、迈络思等等这些厂商沟通智能网卡方面的工作。我们看到智能网卡可能比较快就能达到量产,然后我们就可以把很多虚拟化,或者容器化集群管控的一些负载放到智能网卡的这个层面去做,使得我们在整个操作系统、中间件这些层面的计算和应用的计算能够比较好地隔离出来。智能网卡可能承担了像 AWS 发布的 Nitro 架构、阿里云发布的神龙架构这样类似的作用,能够把我们系统层面的负载跟应用层面的负载进行隔离。
另外非常大的环境是多云。对于网易这样的企业,我们一定是会部分上云的,我们一定是会需要有一个混合云的架构。同时对于公有云的厂商也一定不会绑定在其中的一家,在国内我们会使用阿里云、华为云,或者是腾讯云,我们在海外,可能会使用 AWS、GCP,或者 IBM 等等。
我们面临的是一个多云的环境,那我们的技术架构怎样能够更好地去适配多云的环境?到今天,我们已经 Run 在 AWS 上,也有些业务在阿里云和华为云上。当时基于这些环境和面临的痛点,我们策划了一个整体的云原生操作系统的概念,我们认为有必要去构建一个统一的基于 K8s 的容器操作系统,通过这个操作系统来屏蔽底层的一系列的异构的、混合的资源,来进行统一管理。K8s 社区本身就在往这个方向努力,所以我们能够跟着这个潮流走,而不需要自己去发明一套技术。所以这是一个非常好的环境了,对我们来说。
既然有了统一的云原生容器化的操作系统,那我们就有可能把所有的工作负载,包括业务的负载、数据库、大数据、机器学习、基础中间件等等,所有的负载都围绕以 K8s 为基础的容器化的操作系统来做。我们当时就规划了这么一套体系和方案,我们认为如果做出这样的一套方案,对于所有的中大型的企业来说,在当前的技术环境下也是一个最适合的解决方案和路径。
做这个事情的主要价值有几个,第一个我们可以让这套技术相对来说是自主可控的,我们不会被一些厂商的技术绑定得太深。因为整套技术是构建在社区的开源技术之上,而不是某一个厂商的私有的技术体系之上。
第二个是标准统一。我们用同样一套体系可以应用于私有云的环境、公有云的环境、混合云的环境、多云的环境等各种环境。
第三个可以降低成本,能够提高资源的利用率。比如说通过发挥业务的错峰效应来提升资源的利用率,降低成本。
最后一个可以提高资源弹性。资源之间相互打通了之后,通过调度的优势来提高弹性。如果说我们把这套架构 Run 在公有云之上,它还有一个额外的好处是可以在保证弹性的同时还能让你享受到公有云提供的包年包月的低价。大家知道如果使用公有云的弹性服务,那么在弹性上是非常好的,但是成本非常高。公有云所提供的弹性的服务比包年包月的资源,成本可能会高两到三倍。基于我们这套云原生操作系统,用户既可以享受包年包月的低价,同时也能满足比较好的弹性。
云原生操作系统
接下来我想分两个部分来介绍我们到底是怎么做的。第一个,我想讲一讲云原生的操作系统是一个什么概念、是怎么实现的。第二个是基于这个云原生的操作系统,我们的系统软件要怎么做、要做到什么样的一个状态。当然了,我们现在有比较多的工作也在进行的过程中,这套体系并没有达到一个非常完善的一个层面,但我今天讲的都是在我们内部至少有试点应用的技术成果。
对于云原生操作系统,我们认为最主要要解决五个方面的问题。
第一个在计算的层面,我们要做到让操作系统的负载和操作系统所承载的业务的负载,它们之间要能够隔离。要提供一个高性能并且稳定的环境,相互之间不能干扰。这个也是我们在 2017 年的时候去参加 AWS re:Invent 大会所引发的我们的一个思考,就是我们一定要把操作系统的负载隔离在一个独立的硬件上,不能跟业务负载混淆在一起,否则的话,就不能很好地支撑一些特别需要高性能的像数据库、中间件这些业务的负载。

在网络层面我们要构建一个高带宽、高 PPS、低抖动的技术。我们最怕网络的抖动,基础网络一抖动,上层的应用就抽风。在存储层,因为这些云原生的操作系统化了之后,我们很多的数据库、大数据的计算都需要演变成存储和计算分离的架构。所以我们就需要一套高可用、高性能的存储来支持存储计算分离的架构。
我们要支持跨集群的多层调度,支持多个 IDC 混合云和多云的架构。还要支持混部,要基于标准的 K8s 技术来支撑混部,早在四、五年前业界很多大厂就已经分享过混部,最早的可能是 Google,但是所有的这些技术可能都不是标准化的,都是没有办法给广大的企业所使用的。我们追求的是做一套基于 K8s 标准实现的混部技术,来支撑不同负载之间的资源的隔离,并且保证 QoS 和 SLA。
那么在计算层面要怎么做?我们可以基于智能网卡来实现一个裸金属的计算服务器。刚才说在 2018 年的时候我们就跟英特尔、迈络思等等进行了持续的对接和沟通,最终我们选用的是迈络思的 BlueField 系列,这个网卡里面包括 8 核和 16 核的配置,16G 的内存,ARM 的指令集,这个对我们的研发适配成本也不高。
我们充分利用这块智能网卡的能力,把 I/O 的负载、网络控制面代理、网络数据面的转发都放在了智能网卡的计算能力之上,这使得我们的系统层面的一些负载跟应用的负载形成比较好的隔离。最终我们发现智能网卡确实能够比较好地满足我们的需求,它的性能测出来接近于物理机的性能。在成本效益上,智能网卡可以给我们节省 8 到 10 个 Core,当然就目前而言,智能网卡的成本相对来说也比较高,核算下来在成本方面是持平的,但是长期来看,应该会稍微便宜一点。
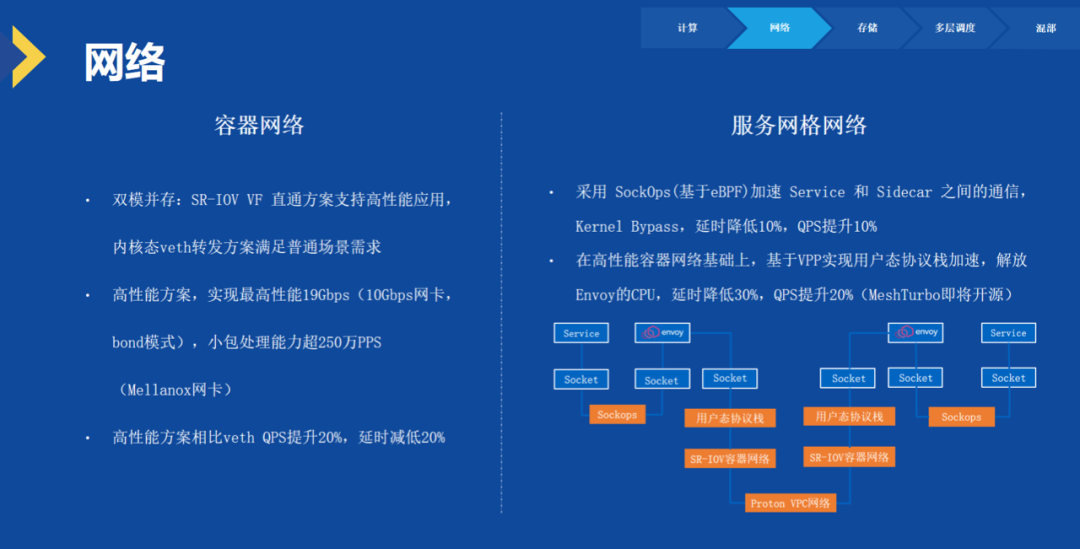
网络层面其实比较复杂。
首先在容器的网络上我们采取了两种模式,一种是基于网卡直通的 SR-IOV VF 直通的模式,提供给特定的一些高性能应用,最典型的就是右边这种服务网格的网络,就是采用了这个 SR-IOV 直通的模式,因为它在一台物理机上只需要有一个实例部署。对于普通的容器来说,当然是没有办法用 SR-IOV 直通的方式来做的,我们通过内核态 veth 转发的方式来满足需求。这个 SR-IOV 直通的高性能的方案能够达到万兆网卡的限速,小包的处理能力单个可以达到 250 万的 PPS,相对 veth 方案,它的 QPS 和延时都会更好。
另一方面,更复杂的是要解决服务网格的网络。我们可以看上图,服务网格的网络实际上中间经过了很多个步骤,从一个 Service 到另一个服务端的 Service 之间,有六个环节。怎么尽可能地提升每个环节的性能,降低它的这个抖动和波动?我们也进行了一年多的研究和开发,最后采用的技术方案是在 Service 和 Sidecar 之间,我们采用了 SockOps,这里面采用了像 eBPF 的技术,那它能够把我们这两者之间的通信,Bypass 内核协议栈延迟可以降低 10%,QPS 提升 10%。现在提升的这个幅度并不是特别的大,但也是非常有效的。然后在两个 Sidecar 之间的通信我们(在 SR-IOV 直通基础上)基于 VPP 去实现用户态协议栈加速,它的效益会更大一点,延迟降低 30%,QPS 提升了 20%,同时我们把这一套技术,命名作为一个叫 MeshTurbo 的项目,很快会把它开源出来贡献给社区。

刚才说了存储我们要做到一个高性能的高可用的存储来支持存算分离的架构,比如说支持类似于像 PolarDB 云原生的数据库,我们在 2018 年开始就自主研发了一套叫 Curve 的存储系统,并于去年的 7 月份向社区开源了,也希望大家能够有兴趣来关注和参与这个项目。
Curve 采用了 Quorum 的机制,写大多数副本即可返回,它的性能会比较高,同样的原因也使得它的可用性会更高。像 Ceph 如果有一台服务器挂掉,I/O 会堵塞至少十秒钟,这是一个非常严重的问题,但 Curve 没有这样的问题。根据我们的测试,Curve 相比 Ceph 的 L 或 N 版本,单个卷 IOPS 达到它的 3 倍,延迟大概降低了一半,多卷随机读 IOPS 达到 Ceph 的 1.5 倍,延迟降低 27%。我们也还在不断的去优化 Curve 的性能和系统的质量。
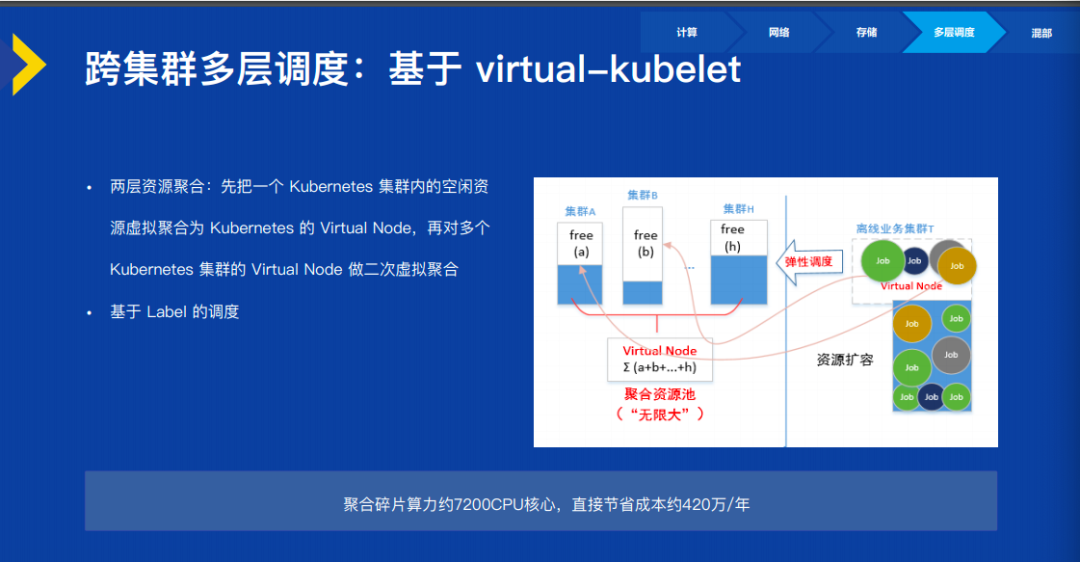
怎么解决多层调度的问题?我们的核心是基于 virtual-kubelet,这是 K8s 里面一个核心的概念,把所有集群的闲置资源能够有效的利用起来。我们将所有 K8s 的集群里面的空闲资源汇总成一个叫 Virtual Node,然后再把多个集群的这些资源又汇总成一个大的 Virtual Node,有这样一个基础支撑之后,我们的应用在申请资源的时候就不需要去指定具体是哪一个集群,而是调度到一个 Virtual Node 上,我们自己扩展的 K8s 调度器就可以把它调度到相应的空闲资源之上了。我们内部有一个应用案例,是几个集群汇合起来大约有 7200 个 CPU 的 core,这个资源每年节省了 420 万。
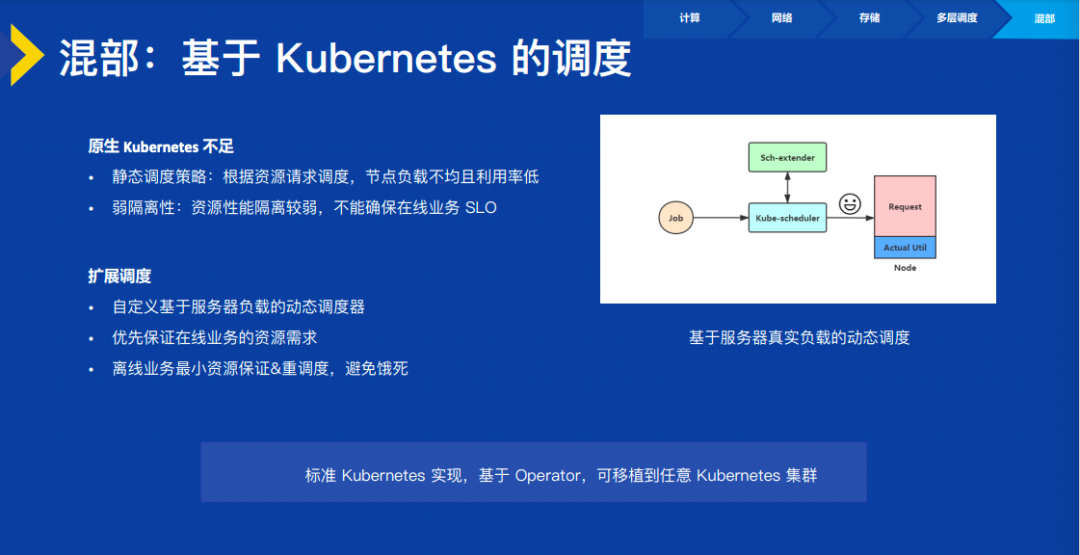
最后一个是怎么样基于 K8s 来做混部。原生的 K8s 在调度上采取的是静态的调度,是没有办法做混部的。首先我们扩展了 K8s 的调度器,基于当前的负载做动态的调度。这个调度器优先要保障在线业务的资源需求,但同时也要保证离线业务的资源不能被饿死。这个调度器也是基于标准的 K8s 实现的扩展,可以移植到任意的 K8s 的集群之上。这些 Feature 也都在我们的开源计划过程中。
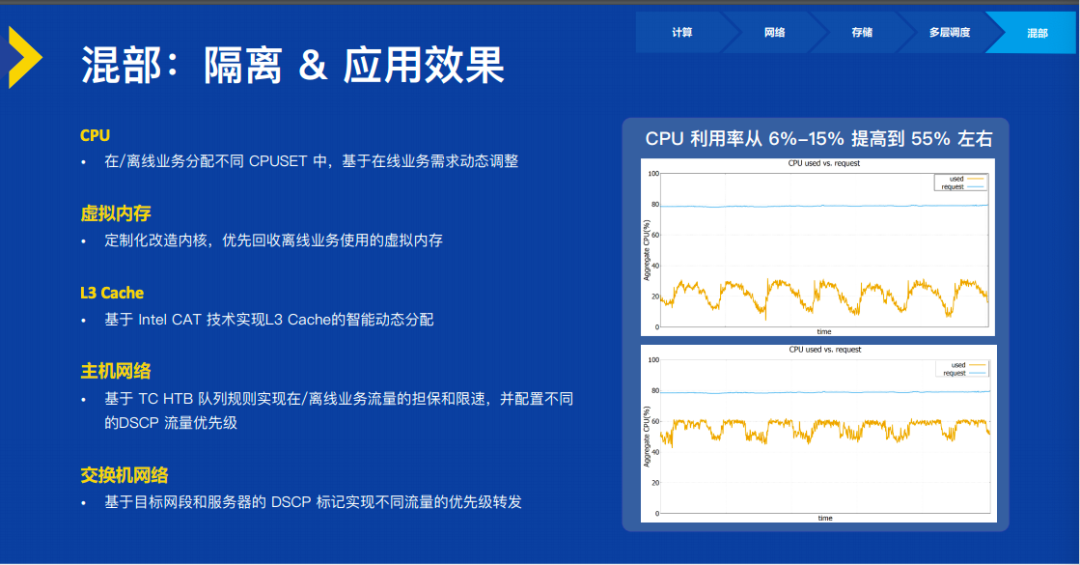
混部还有非常重要一点是要在很多层面做好隔离,来保证我们的在线资源不被离线资源所影响。如果不能保证这一点,这个混部是不可行的。比如说用 CPUset 做 CPU 的隔离;在虚拟内存上要优先给在线的业务做保障;在 L3 的 Cache 上,通过 Intel CAT 技术来做隔离;在主机网络、交换机网络上都要进行针对性的处理,来使得在线业务的负载被离线业务的干扰和影响可以控制在 10% 以内,这样就达到了一个我们业务方所能接受的一个状态,在线业务是不会被那些混部进来的离线业务所影响、所干扰的。
云原生系统软件
既然有了这样一个云原生操作系统,我们所有的系统软件都要跟它进行改造和适配,我想讲两个方面的,一个是中间件,一个是大数据。
基础中间件
在基础中间件方面,我们围绕云原生的技术体系,重新打造了一个基础中间件的体系,在这个过程中,我们非常注重复用云原生生态已有的能力。

对一个中间件的管理来说,这个中间件底层的内核都是开源的技术,我们要做的就是它的上层的管理套件,这个管理套件主要做五件事情,第一是实例生命周期的管理,是基于 K8s 的 Operator 框架去实现的。
第二是高可用的部署,这个时候 K8s 的调度器做一定的扩展就能够比较好的来满足我们的需求。故障的自愈也可以借助 K8s 的内置的一个多副本的控制器、容器探针等机制来做,比较方便的实现。可观测性方面,云原生体系提供了像 Prometheus 这样比较标准化的一个框架,我们完全可以对接到这个框架,我们的实现也会更加简单。最后运行的资源管理和容器编排,我们借助于 K8s 内置的 Node 的管理、Pod 的调度等等这些方面,我们的实现也会更加的便捷。
所以基于 K8s 去做,跟我们原来基于虚拟化去做,同样一个中间件,我们的研发代码量减少了 50% 到 80%。这个对于我们来说是非常大的一个收益,我们可以投入更少的人去做这个事情,而且我们做出来的软件跟统一的操作系统之间,结合度会更加的紧密,适配性更强。凡是有标准的 K8s 环境,我们的中间件就可以很顺畅地跑在上面,所以说这样的中间件体系是更加有利于部署和落地的。
服务网格

再就是服务网格。服务网格我们的核心基础技术是 lstio 和 Envoy 两个,一个做控制面,一个做数据面。在服务网格的工作中要关注的是三点。第一个是兼容性,因为应用从原来基于典型的 RPC 的模式,切换到服务网格,不可能一下切过来,一定是有一个逐步迁移的一个过程。每个应用又有已有的环境,我们服务网格技术就需要对这些环境做很好的兼容。所以说在落地方面,首先第一个兼容性,我们要兼容各种注册发现机制,比如说有些业务是用 Consul,有些用 ZooKeeper,有些人用 Eureka 等等,需要去兼容它们。在服务的基础设施方面要支持物理的环境、容器的环境、虚拟机的环境等等。
在可落地性方面我们也要支持网格化和非网格化集群混合调用,因为迁移一定是逐步进行的,这些在云原生的社区版本里面的功能都是比较弱的,还需要自己去做一些扩展。还有一个非常重要的是要支持 Sidecar 热升级、业务无感。因为 Sidecar 在产品的迭代过程中一定要进行升级和维护。我们还做了一系列服务网格的运维增强的功能,这些功能作为 Slime 项目,也在 Github 开源了,大家也可以去关注。
目前通过这样的应用,我们把启动时间从分钟级降到了秒级,我们在数据面的内存下降了 80%,控制面推送时的内存下降了 70%。这些都有助于我们大规模应用,比如严选、传媒的业务,现在已经 80% 以上都是在服务网格的这个技术体系上。
大数据
最后一个细节部分,是怎么样把 Spark、Flink 这样的典型的大数据框架运行到 K8s 上进行统一的调度。
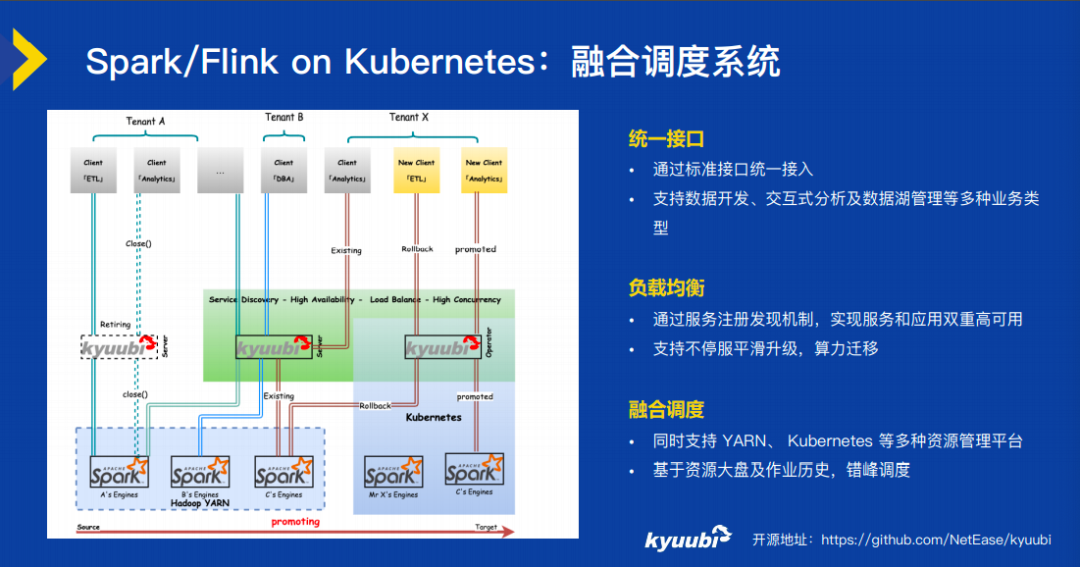
第一件事情我们要做一个统一的调度系统。这个统一的调度系统是为了方便我们把 Spark 从 YARN 逐步地迁移到 K8s 上。任务迁移可能是个长期的过程,在这过程中会出现“双跑”现象,用于验证任务的准确性,这个长期的过程首先就需要有一个统一的调度系统。这个调度系统,首先它统一接口,使得大家不用关心底层到底是在 YARN 上,还是在 K8s 上。这个统一的接口要支持像数据开发、交互式分析、ETL 等各种不同的大数据业务场景。
这个统一的调度系统还要做到负载均衡和融合的调度,要把 YARN 和 K8s 之间调度过程做得相对来说比较平滑。这个方面我们也提供了一个开源的项目叫 Kyuubi,Kyuubi 意思是九尾狐,后面有很多个不同的分叉,有可能是 K8s,有可能是 YARN。
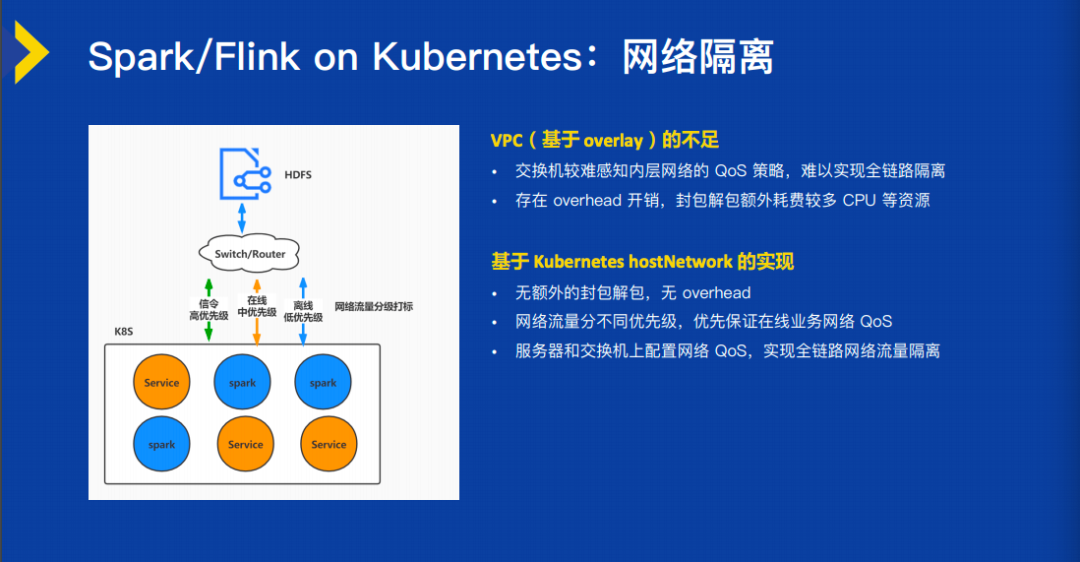
第二个是把大规模的 Spark 和 Flink,尤其是 Spark,跑在 K8s 上,涉及到网络层要怎么解决?我们私有云采取的是基于 overlay 的 VPC 网络实现的。但是,如果用 VPC 来跑 Spark 这样的大数据的负载,它是有一定的缺点的。第一个有比较大的一个开销,要拆包、解包,需要消耗比较多的 CPU 资源。但是 Spark 集群的通讯,对 Overhead 是比较敏感的。第二个在这个时候交换机层面比较难以感知到内层的一些 QoS 的策略,所以实现全链路的隔离就比较复杂。我们最终选择的是基于 K8s 的 hostNetwork,通过主机网络来实现 Spark 层面的网络通信,这样就没有这种额外的分包解包 Overhead,并且在服务器和交换机上都可以做好 QoS 的分配策略和流量隔离。
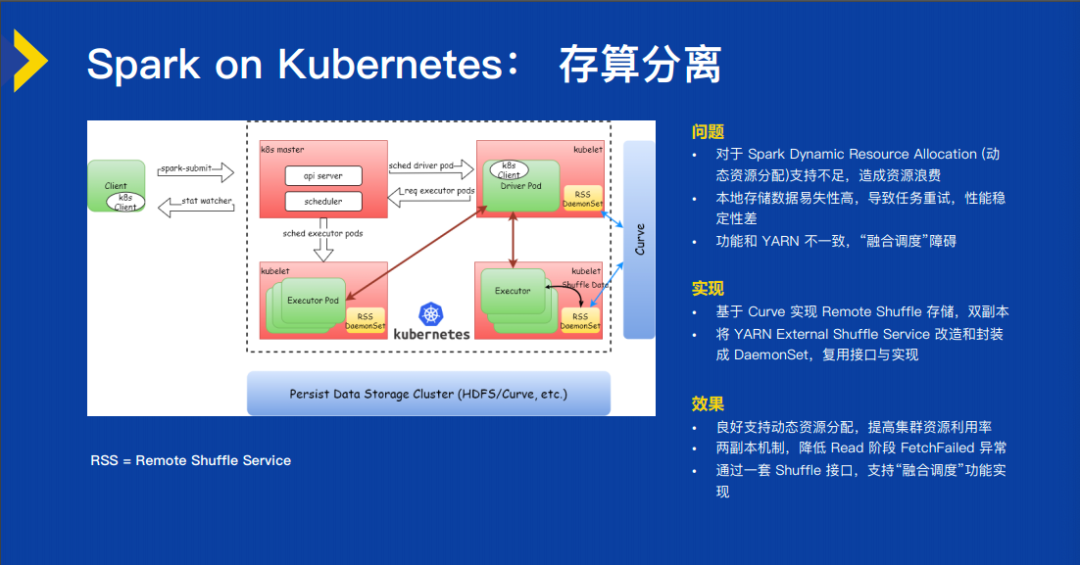
第三个还要解决很大的问题是存算分离的问题,因为原来 Hadoop 体系是存算一体的。存算一体的时候,计算产生的临时数据都写在本地磁盘上,如果把 Spark 跑在 K8s 上,K8s 集群是一个典型的计算集群,本地是没有存储套件的,相应的存储还在 HDFS 上。这带来的问题,Spark 的资源分配支持不足会造成浪费,因为在混部的场景下,Spark 任务比较容易被杀掉,就是在线业务一旦有资源需求的时候,它就会把离线的业务踢掉。这个时候如果用 K8s 集群的本地存储来做 Shuffle 存储,我们就会发现,一旦一个任务被踢掉,Shuffle 的存储没有了,那整个任务就要重跑。
刚好我们打造了一个高性能的存储平台 Curve,所以我们就把计算产生的临时数据(Shuffle)放到远程存储,这样就能够比较好地解决这些问题。实现的方式也比较简单,我们在 K8s 上做的一个特殊的 DaemonSet,叫 RSS(Remote Shuffle Service)。
解决了这三大问题之后,基本上就解决了怎么把 Spark 和 Flink 这样的大数据的负载跑在 K8s 上面的问题了。目前我们的应用规模还不是很大,我们还在逐步推广,但是这条路径我们觉得是走通了,是可行了。
而且经过混部之后我们发现很多集群的资源利用率,从刚才说的 20% 到 30%,提升到现在的 50%,甚至有些集群提升到 70%,资源节省了很多。尤其是我们传媒的业务,经过大规模的混部之后,利用率的提升是非常显著的。
总结
最后我做一个小结和展望。
我想强调的是我们理解的云原生。云原生理念上我认为是面向云环境所设计的一套技术架构。那么云环境来说,对于中大型企业一定是一个混合云加多云的环境,不可能是只有一朵云。面向云的设计,最核心的是要做到弹性和资源的池化。针对这样的云原生理念的实现,我今天可能贡献了一条思路,就是基于一个以 K8s 为基础的的统一操作系统来构建,并且把所有的基础软件要跟这个操作系统去做适配,来管理和调度所有的计算;同时我们要做存算分离,要有强大的存储基础设施,让基础软件都能提供弹性的服务。我们有句口号,就是真正的云原生,我们认为是以一套技术体系支持任意的负载,运行于任意的云环境。如果只跑在一个特定的环境下,这样的技术做得再好也不是真正的云原生。未来我们希望继续扩大存算分离架构的应用范围,继续扩大混部和资源池化的范围,继续我们的开源。
演讲嘉宾介绍:
汪源博士,网易副总裁,杭州研究院执行院长,互联网技术委员会主席,网易数帆总经理。
2006 年获浙江大学计算机专业博士学位,是国内大型通用关系数据库内核技术最早的研究者和实践者之一。毕业后加入网易,长期主持网易杭州研究院技术研究工作,在国内最早开展分布式数据库、文件系统、搜索等大数据系统建设。
现作为网易杭州研究院执行院长,全面负责网易集团基础设施 / 云原生 / 中间件 / 大数据 / 人工智能 / 信息安全 / 中台等核心技术平台建设、项目管理 / 用户体验与设计 / 运维保障 / 质量保障 / 创新服务等创新平台建设和网易云政企业务。




