
导读:预训练模型在 NLP 大放异彩,并开启了预训练-微调的 NLP 范式时代。由于工业领域相关业务的复杂性,以及工业应用对推理性能的要求,大规模预训练模型往往不能简单直接地被应用于 NLP 业务中。本文将为大家带来小米在预训练模型的探索与优化。
预训练简介
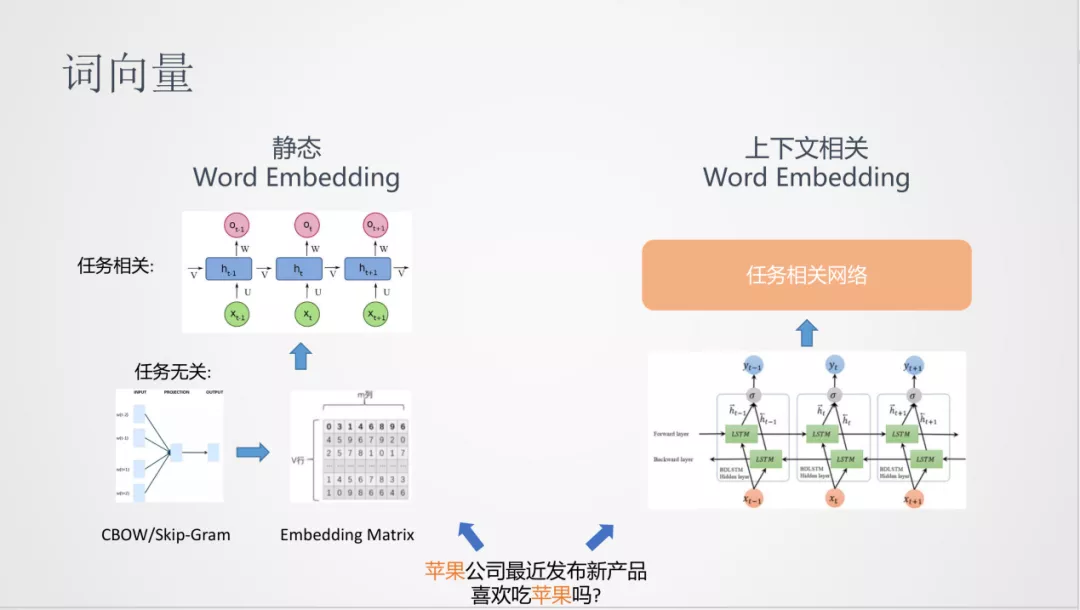
预训练与词向量的方法一脉相承。词向量是从任务无关和大量的无监督语料中学习到词的分布式表达,即文档中词的向量化表达。在得到词向量之后,一般会输入到下游任务中,进行后续的计算,从而得到任务相关的模型。
但是,词向量的学习方法存在一个问题:不能对文档中的上下文进行建模,对于上面的例子“苹果”在两个句子中的表达意思是不一样的,而词向量的表达却是同一个,所以在表达能力的多样性上会有局限,这是一种静态的 Word Embedding。
在后面的发展中,有了根据上下文建模的 Word Embedding,比如,可以在学习上尝试使用双向 LSTM 模型,在非监督语料学习词向量,这比静态的词向量网络会复杂一些,最后可以通过隐层得到动态的词向量输入到下游任务中。
1. 序列建模方法
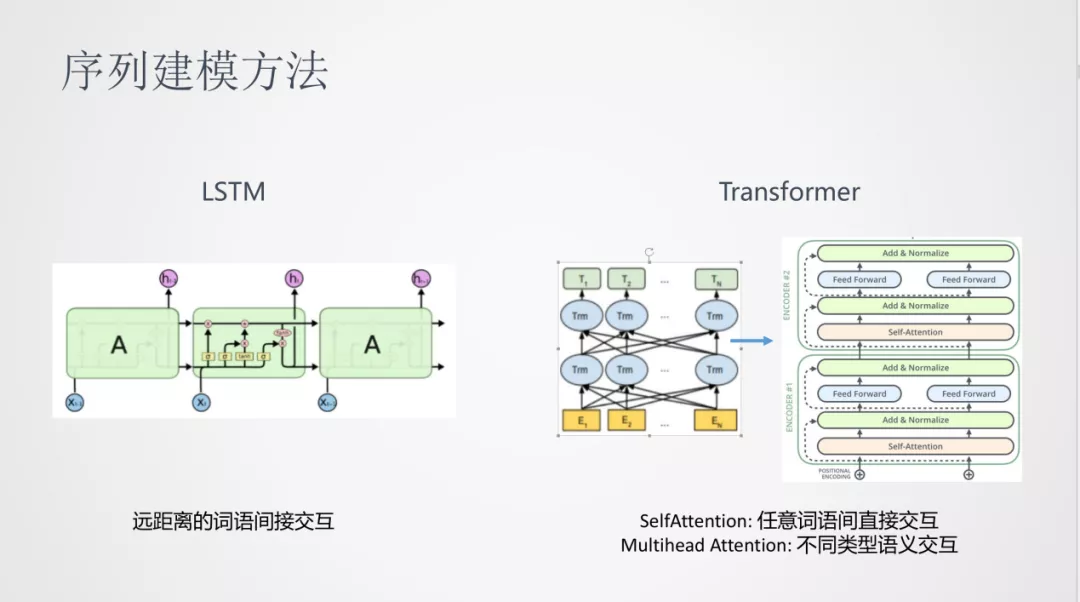
在 NLP 中,一般使用序列建模的方法。之前比较常用的序列建模是 LSTM 递归神经网络,其问题是建模时,句子中两个远距离词之间的交互是间接的。
17 年 Transformer 发布之后,在 NLP 任务中取得了很大的提升。这里面 Self-Attention 可以对任意词语间进行直接的交互,Multi-head Attention 可以表达在不同类型的进行语义交互。
2. 预训练模型
在这之后,预训练模型开始流行起来。
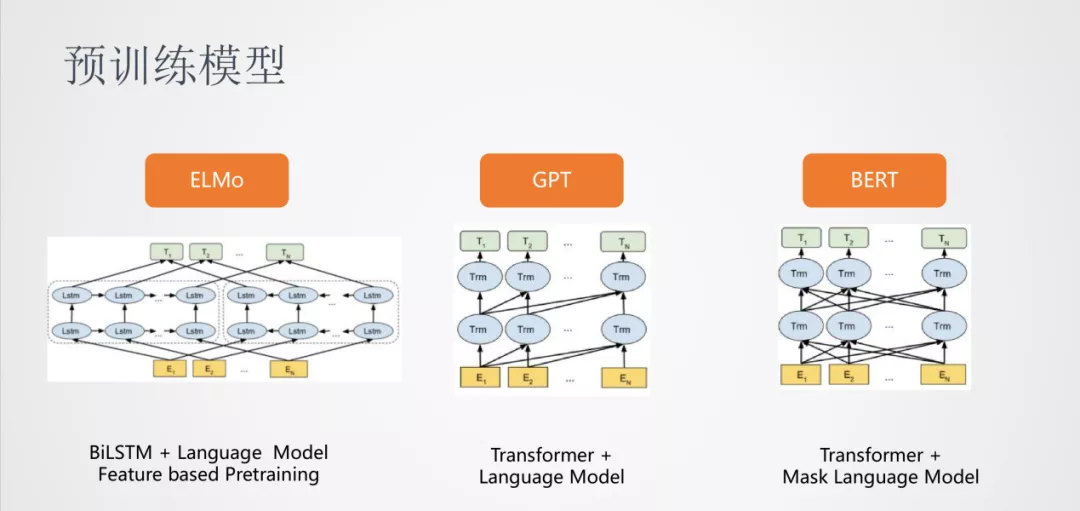
首先是 ELMO,依然使用的是双向 LSTM,它将模型做的更深,并且在大规模的无监督语料中进行训练,使用的训练任务是语言模型。对于具体的任务,将从 ELMO 得到的词向量作为特征输入到下游任务中,ELMO 这种的预训练属于 Feature based Pretraining。
其次是 GPT,它使用的是 Transformer 结构,训练任务是从左到右的语言模型,比较适合生成类的任务。
最后是 BERT,依然使用的 Transformer 结构,训练任务换成了 Mask Language Model,可以对词语的上下文进行建模。
3. BERT 模型
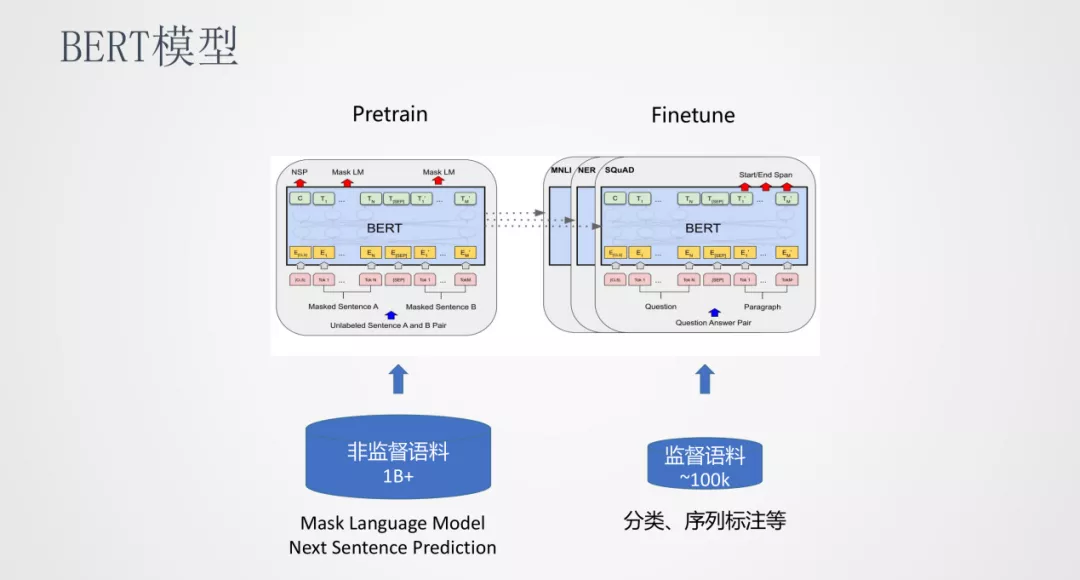
BERT 是一种 Pretrain 和 Finetune 的训练方式,在 Pretrain 阶段使用海量的非监督语料训练出一个与任务无关的公共模型,在 Finetune 阶段可以使用少量的监督语料训练一个任务相关且效果更优的模型。
4. BERT 效果
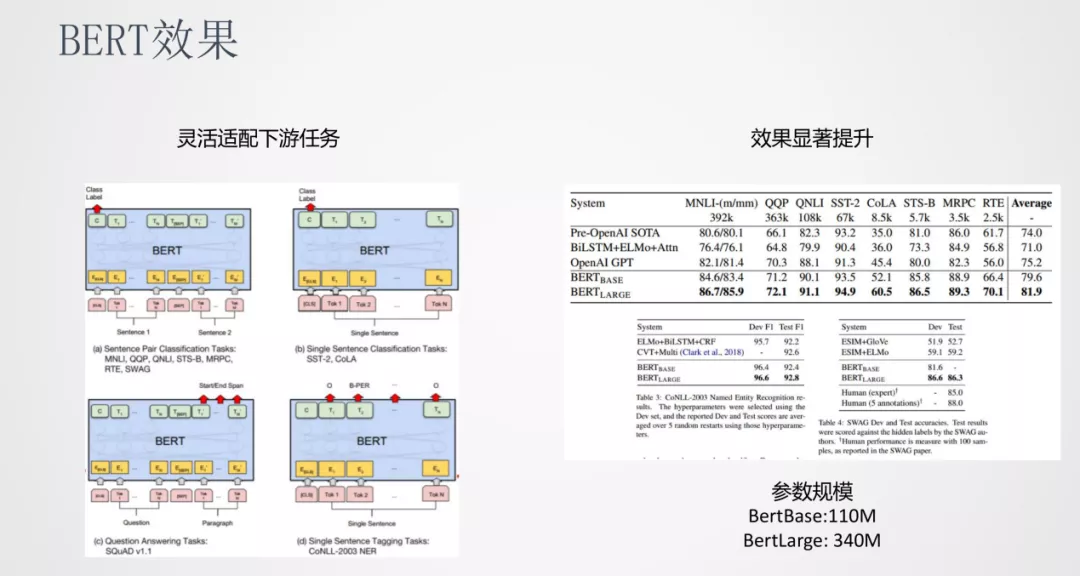
BERT 可以灵活的适配下游任务,比如句对分类、文本分类、序列标注、QA 等等。另一方面 BERT 的参数规模也是非常大的,BertBase 有 110M 的参数,BertLarge 有 340M 参数。
5. 预训练模型发展
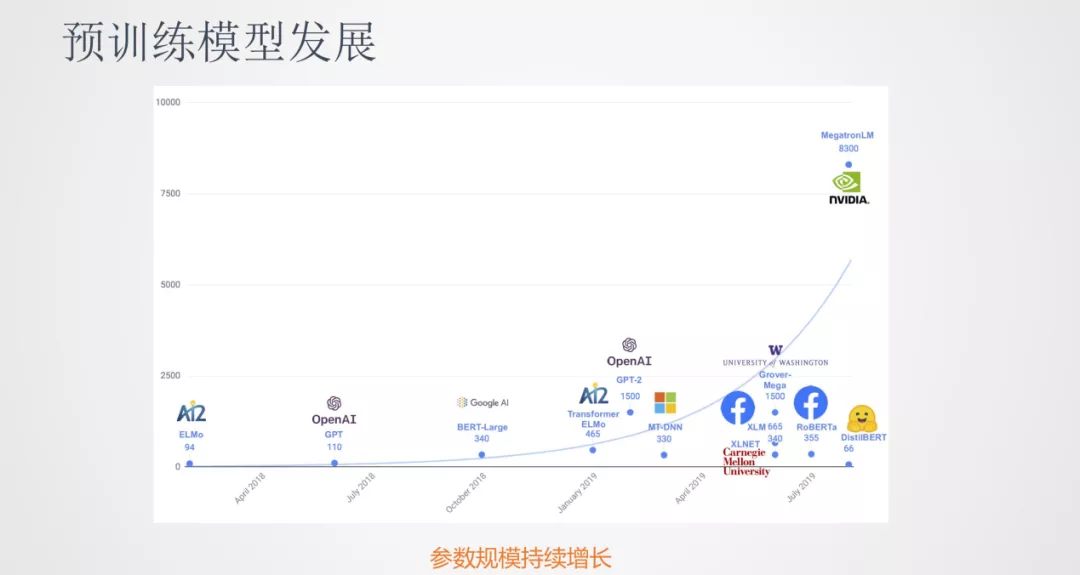
在 BERT 之后,预训练模型的发展非常迅速,出现了很多新的预训练模型。这些模型的趋势是模型参数在不断的增大。
预训练落地挑战
我们以对话系统来介绍下预训练落地的一些挑战。对话系统的流程是将输入的语音通过 ASR 识别成文本 Query,然后进行分词。由于语音的输入一般是连续的,所以需要进行语义的断句。接下来,进行意图分类将 Query 分类到天气/音乐/聊天……这些类别中,再根据 Query 来匹配到答案,其中匹配的方法可以是检索式也可以是生成式。
在整个对话系统中,预训练模型可以应用到很多任务中,遇到的挑战主要有以下几个方面:
挑战一:推理延时高、成本高
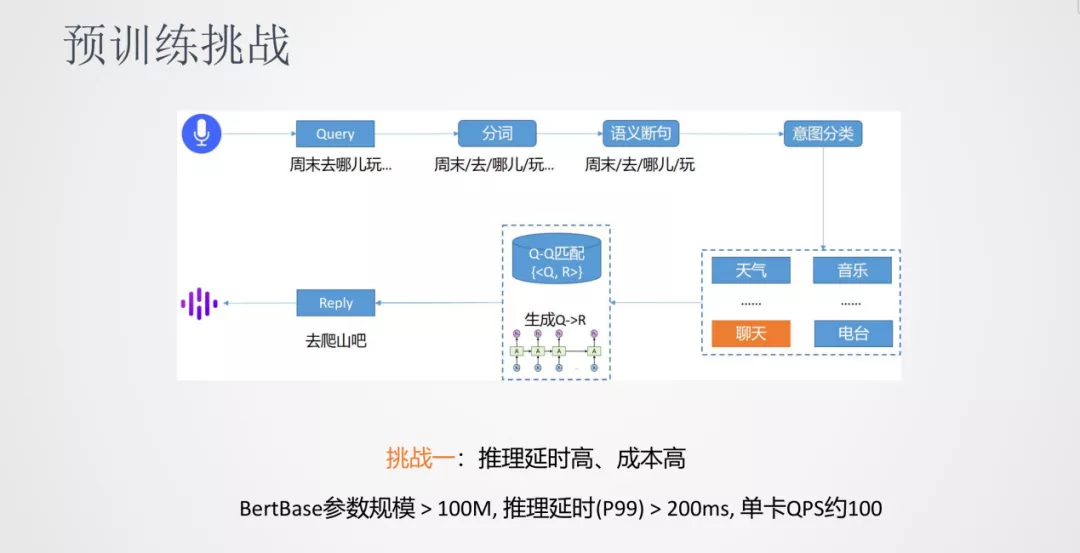
第一个挑战是由于预训练模型的参数比较大,会引起推理的延时比较高以及单卡的吞吐比较低,所以推理延时高和成本高是一个通用的挑战。
挑战二:知识融入
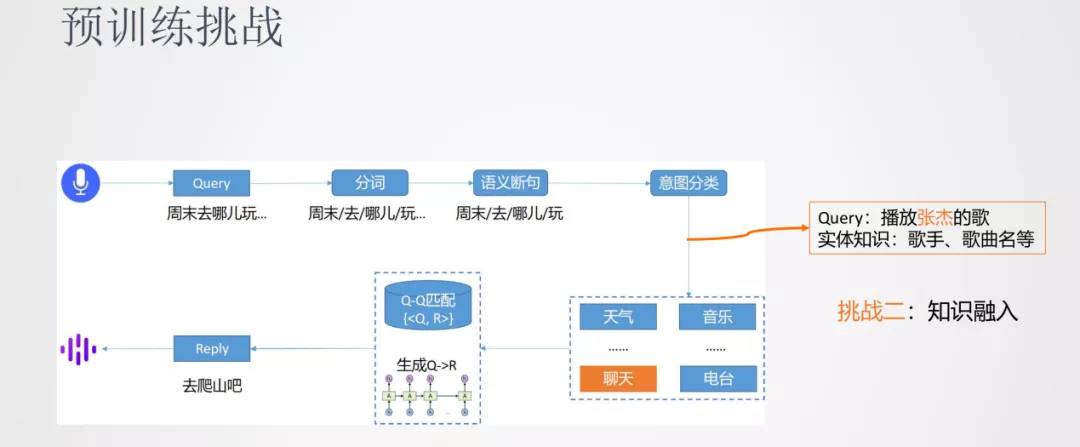
第二个挑战是一些任务除了使用原生的 BERT 模型之外,还需要融入一些外部的知识。比如意图分类的任务,Query 中的歌手、歌曲名实体的融入可以帮助模型将 Query 更准确的分类到音乐类中。
挑战三:如何根据任务调整模型和训练
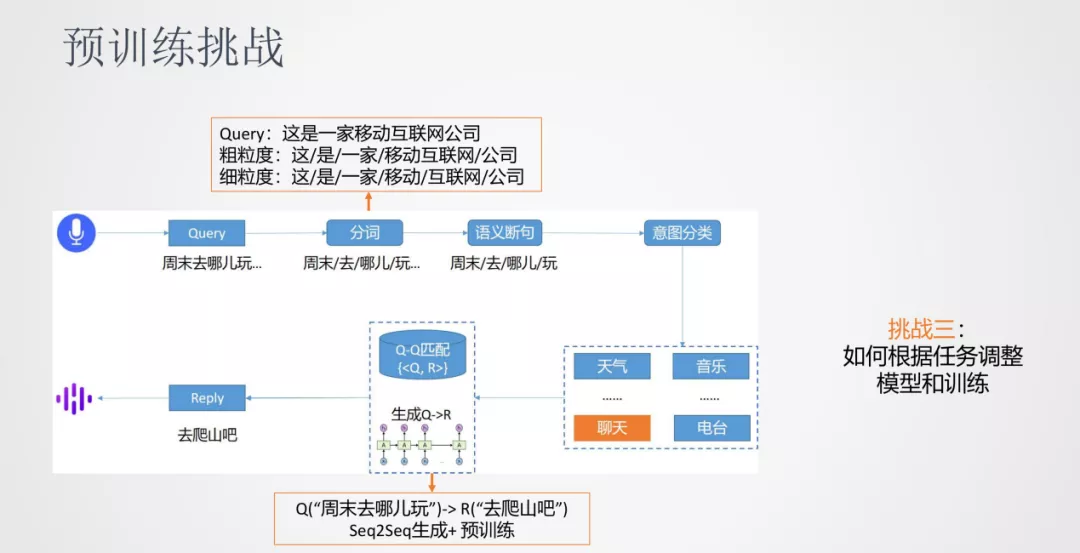
第三个挑战是我们发现一些任务需要在预训练模型的基础上进行调整——模型结构上或者训练方法上。比如分词任务,同样一句话我们可能同时需要粗粒度的分词或者细粒度的分词结果,对于原生 BERT 的序列标注任务需要一些适配。另外,像是对话生成类的任务,传统上使用 Encoder 和 Decoder 的模式,在原生 BERT 需要进行训练方法的改进。
预训练实践探索
1. 推理效率
前面我们已经提到,对于 BERT 的一个挑战是模型参数很大,针对这个问题我们很容易想到是不是可以对模型进行压缩,而知识蒸馏是一种常用的模型压缩方法。
① 知识蒸馏
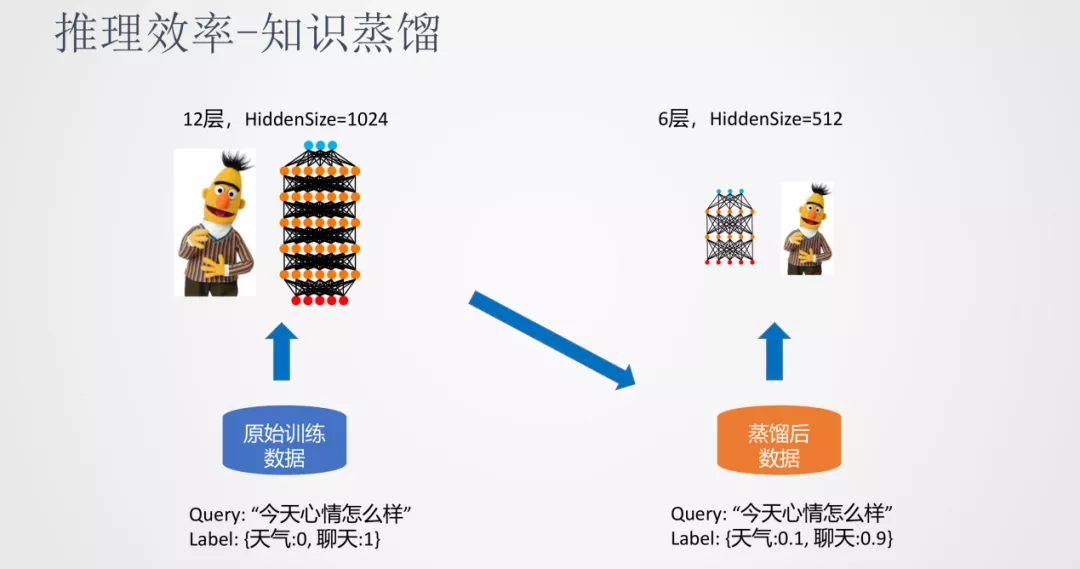
知识蒸馏是由一个大模型(teacher 模型)通过蒸馏数据来生成一个小模型(student 模型)。针对分类任务,蒸馏数据相对原始数据会变成 soft label 的形式,更利于小模型学习到模型中的知识。
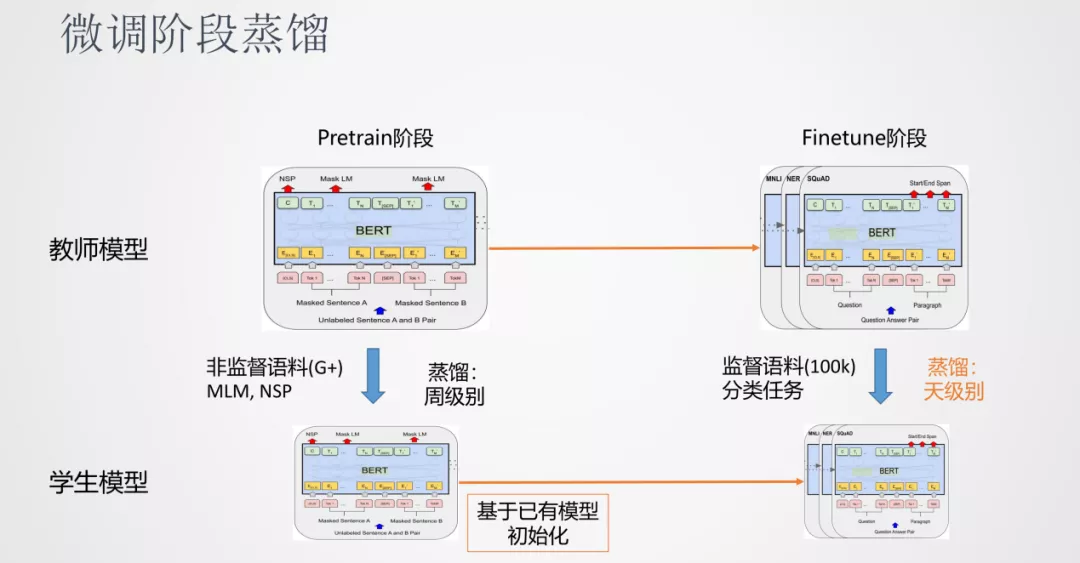
前面说到预训练模型可以分为 Pretrain 阶段和 Finetune 阶段,对于知识蒸馏来说,也可以分别对 Pretrain 阶段和 Finetune 阶段进行蒸馏。其中,因为 Pretrain 阶段时间会很慢,蒸馏 Pretrain 也很慢,一般时间是周级别的。另一种方法是跳过 Pretrain 的阶段,使用小模型作为学生的初始模型,直接进行 Finetune 的蒸馏阶段。在实践中我们发现,这种方式可以得到一个效果不错的模型。好处是 Finetune 阶段比较快,天级别就可以完成一个蒸馏任务。
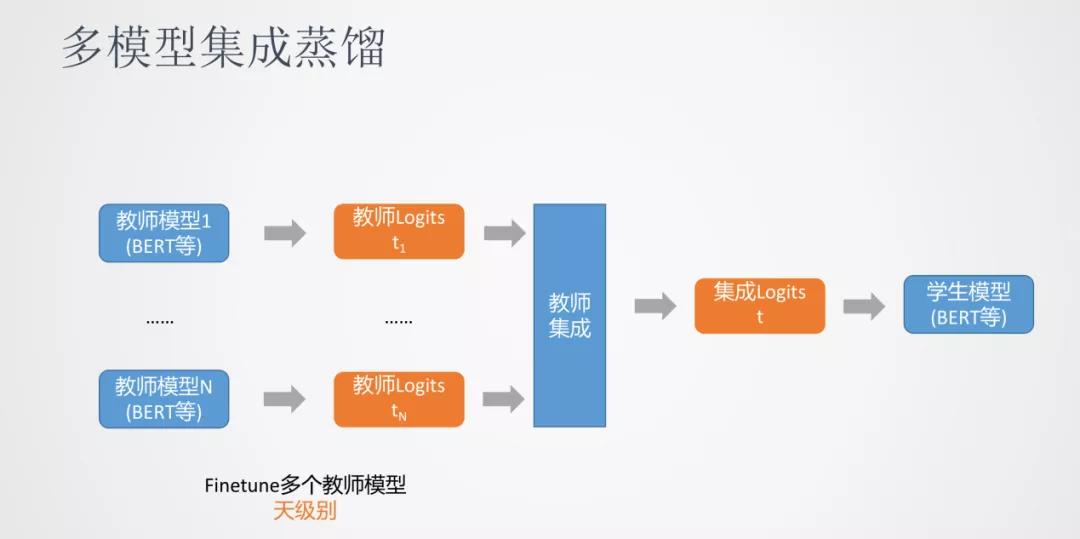
我们发现多模型集成蒸馏对模型效果有一定的提升。多模型集成蒸馏是我们同时训练多个教师模型,每个教师模型会对数据生成一份蒸馏后的数据。比如分类任务,会生成多个 logits 这样概率的分布,然后通过教师集成为一个 logits,最后用这个融合后的 logits 去优化最终的学生模型。
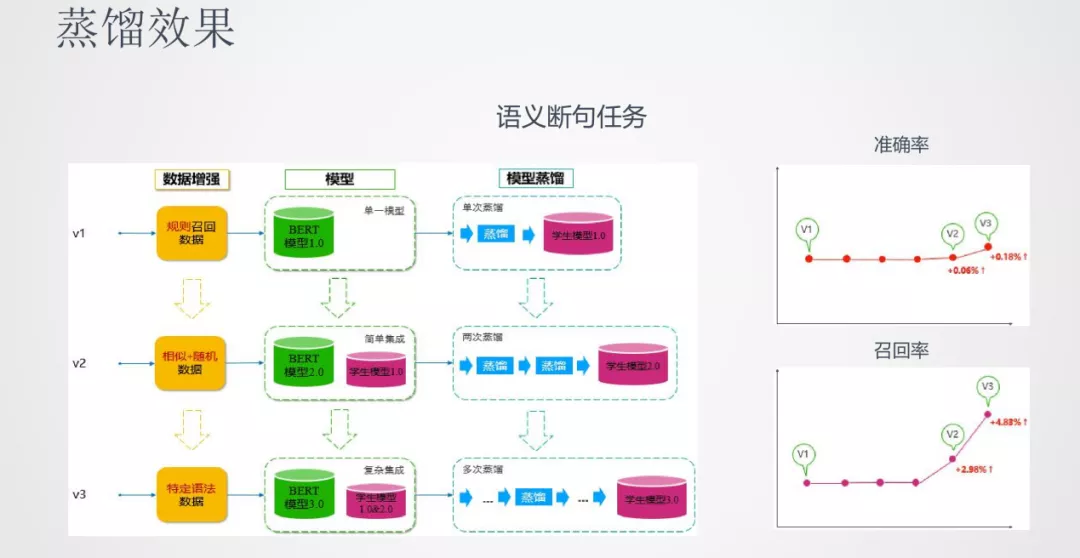
在蒸馏的效果上,以语义断句任务为例,我们做了三版的模型:
第一版使用单模型的 BERT 去蒸馏学生模型
第二版使用多模型进行蒸馏,这里面使用的集成策略也相对简单
第三版使用更多的教师模型且更复杂的集成策略来蒸馏学生模型
从效果上面看,准确率和召回率三版模型都有逐步的提升,尤其集成教师蒸馏的方法在召回率上的效果有了较大的提升。
② 低精度推理
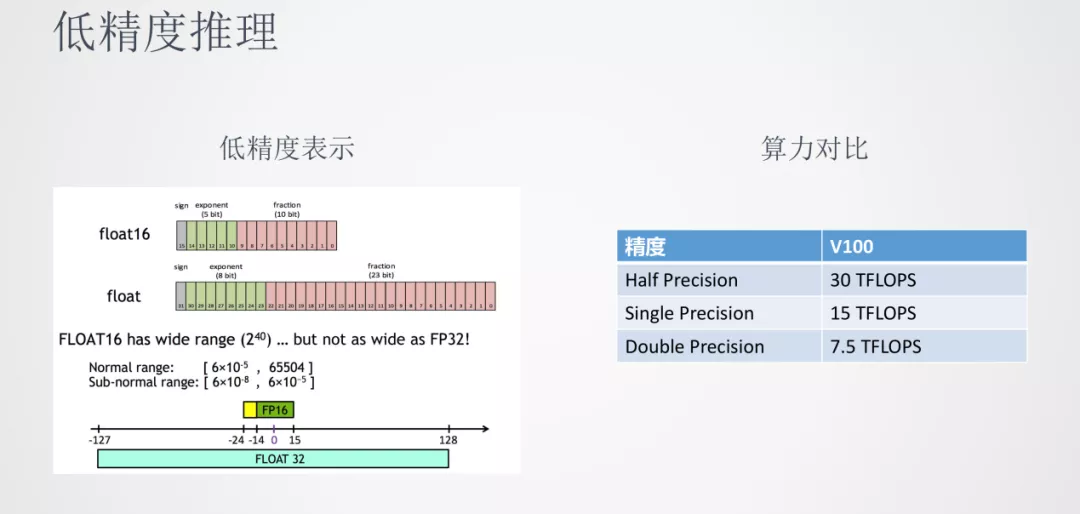
我们都知道在模型训练时,参数一般都是以 float32 存储的。由于神经网络计算有一定的鲁棒性,使用 float16 半精度的表示也可以达到接近 float32 的效果。我们可以看到在 GPU V100 上,半精度算力可以达到单精度的两倍,在推理延时和吞吐上都具有优势。
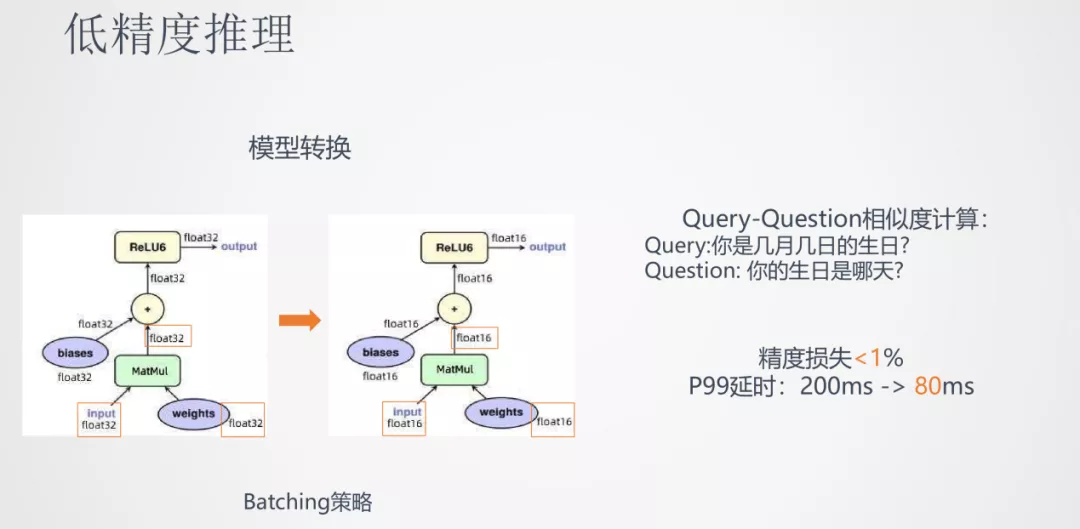
具体的操作是将各个 float32 位的参数矩阵都转换成 float16 位的格式。在实际应用,如 Query-Question 相似度计算任务中,低精度推理的精度损失小于 1%,而 P99 的延时从 200ms 降到了 80ms,有一倍以上的推理速度降低。
③ 算子融合
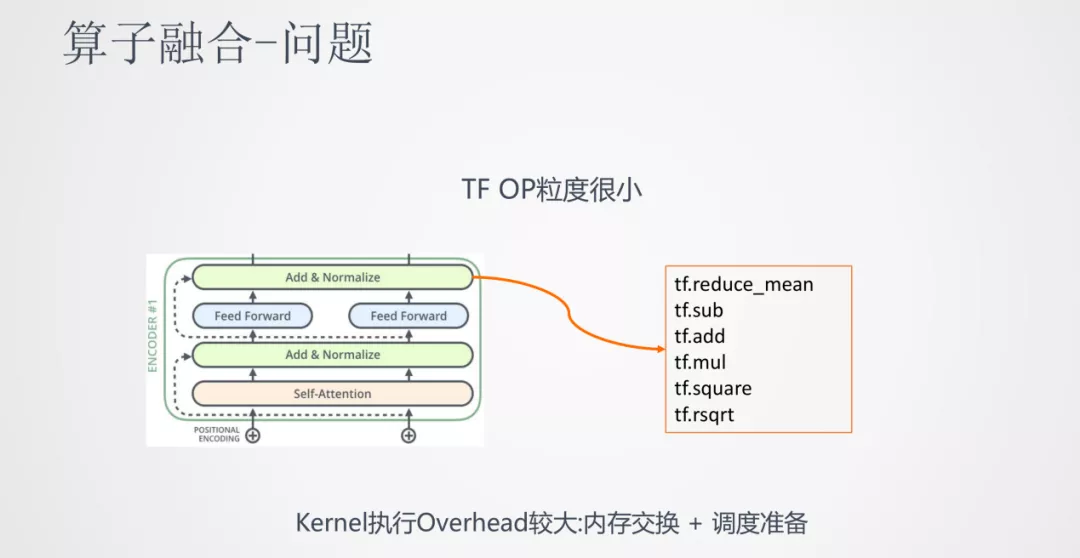
在推理速率上的提升,我们还尝试了另一种方法:算子融合。
它的初衷是,Transformer 从结构上看每一层都有 self-attention,add,layer-normalize,feed forward,sublayer 等步骤。实际上,中间的每一步转化到具体的深度学习框架中都是非常长的算子步骤。比如像 layer-normalize 这一步需要 tensorflow 中 6-7 个甚至更多的算子计算序列来完成。这样在计算框架中 OP 粒度很小,而 CPU 在很多时间都是在等待 OP 的内存交换和调度,导致 CPU 大部分时间都是在空转,使得计算效率较低。
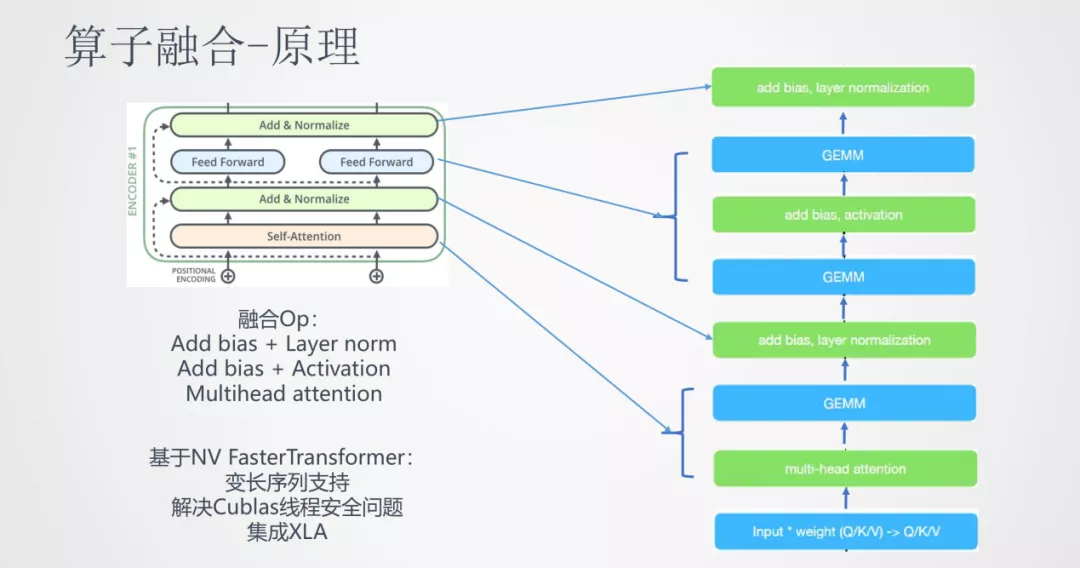
算子融合的思路就是将这些相邻的算子尽可能融合成一个算子,这样就能让 CPU 最大限度的连续运行。上图就是将 Transformer 中的一个 block 进行了算子融合,将多个小的算子融合成大的算子。
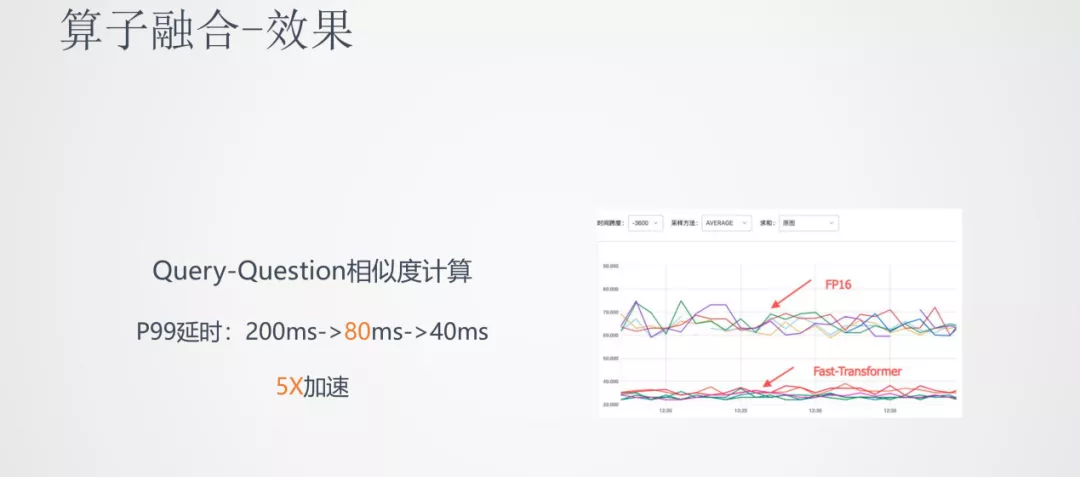
我们可以看到通过加入算子融合,在低精度推理上,推理速度又降低了一倍。这样就可以将 BERT 这种大的模型推到线上落地。
2. 知识融合
① 问题
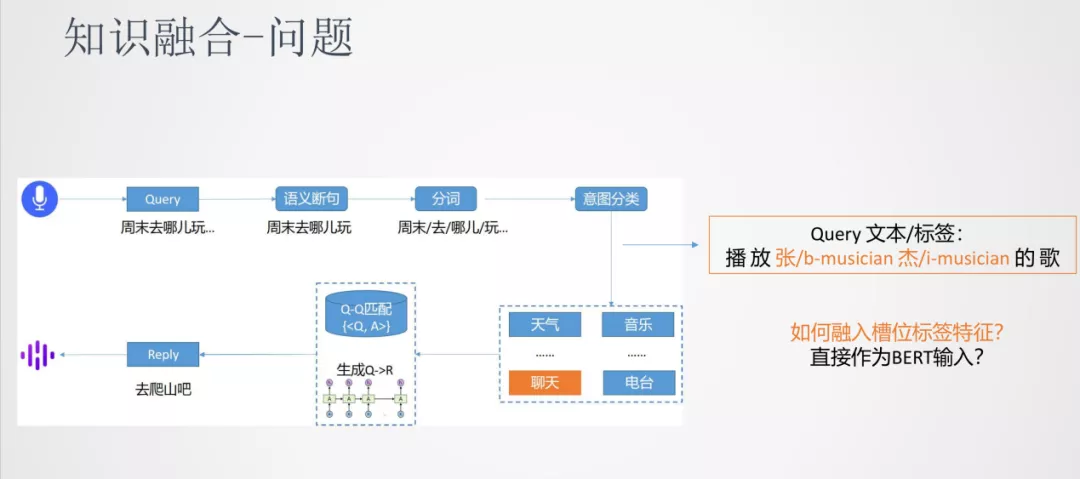
回顾一下之前的对话系统场景,在落地意图分类任务时,有一些类别包含领域相关的外部信息。比如音乐包含歌手名、歌曲名这样的信息,我们利用这些信息可以更容易地将 query 分到对应的类别上。
这样问题就可以抽象表达为如何将输入的原始序列和槽位的标签序列融合在一起用来做分类模型。一个简单的方法就是将标签序列也作为输入,输入到 BERT 中,但是 BERT 在训练中没有见到过这样的输入,这样分类的效果会差一些。
② 方案
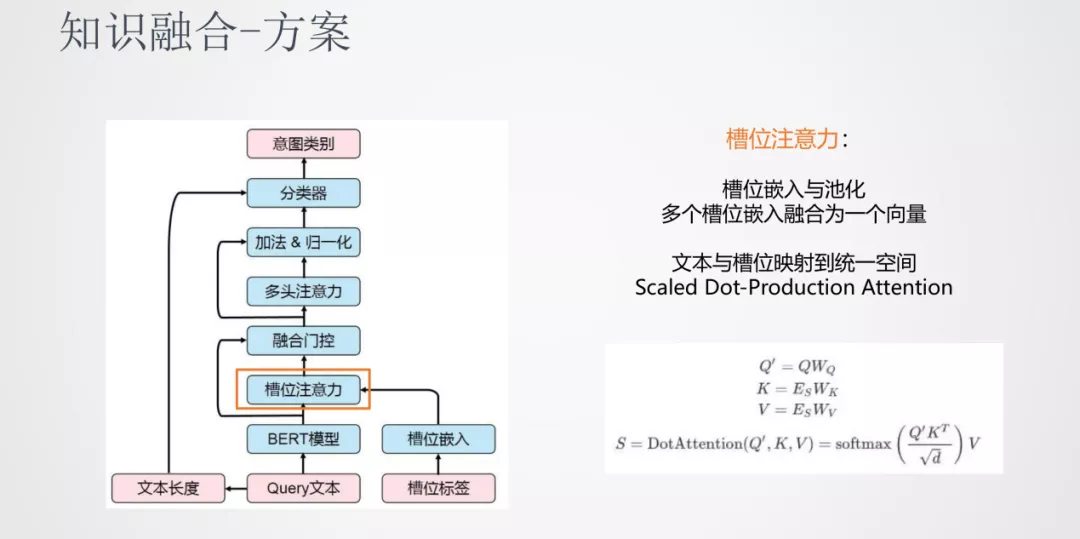
介绍下我们的知识融合方案:
首先引入槽位注意力机制,原始输入的 Query 会经过 BERT 计算输出一个隐层的表达,槽位的标签也会做一个嵌入的表达。考虑到同一个词语位置的地方会有多个槽位信息,我们对于这个多标签的情况可以做一个池化操作,融合为一个向量。之后做一个线性变换,将文本序列和标签序列映射到同一个空间,在同一个空间进行 attention 操作使两个序列进行交互,这样就可以得到原始特征和标签特征的融合特征表示。
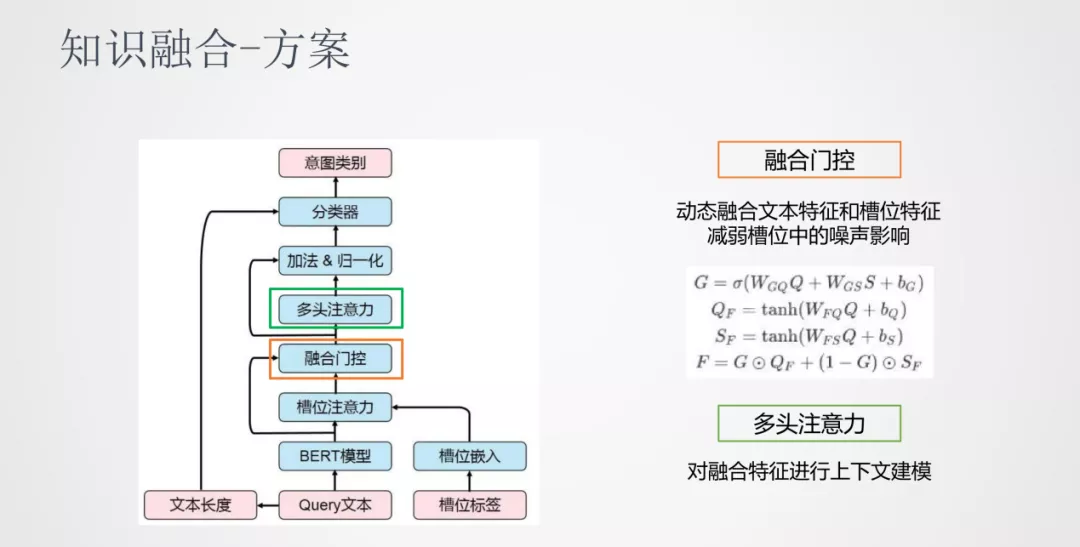
在这之后,我们加入了一个融合门控机制。一般提取出来的标签都会有一些噪声,我们通过外部知识获取的标签会有一些不准确的可能,所以我们需要确定有多少程度的标签信息可以加入到原始序列中。我们加入的是一个动态门控的机制,将文本特征和槽位特征进行一个动态的加权。在融合门控之后加入了一个多头注意力机制,它的作用是在融合之后的特征进行上下文交互来建模。
③ 效果对比
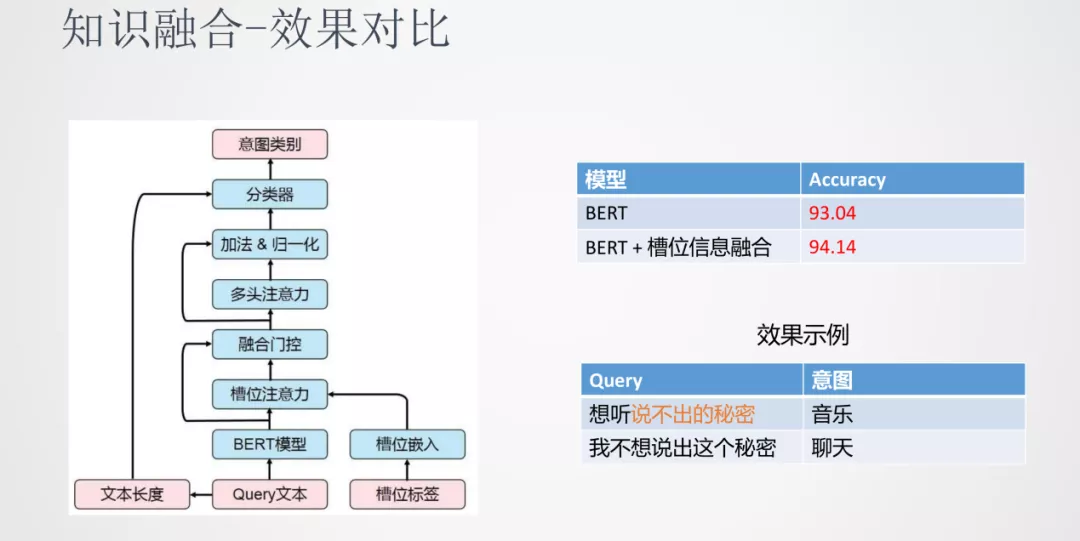
综合上面这些方法的融合,在意图分类这个任务上对比单独使用 BERT 和融入槽位信息的 BERT,融入了槽位信息之后准确率上会有一定量的提升。在上面的例子中,“想听说不出的秘密”和“我不想说出这个秘密”由于加入的外部知识能够很好的分类到相应的类别当中。
3. 任务适配
任务一:多粒度分词
① 问题

针对同一句话,我们会有粗细粒度不同的分词需求。比如:这是一家移动互联网公司,粗粒度:这/是/一家/移动互联网/公司,细粒度:这/是/一家/移动/互联网/公司,所以我们需要模型的调整来完成这样的需求。
分词任务可以看成是序列标注的任务,输入的是文本,输出是每个文字上各个标签的开始或者结束。一种简单的一种做法就是为粗/细粒度分别训练两版不同的模型,但是模型的维护成本和运行成本都比较高。
② 方案
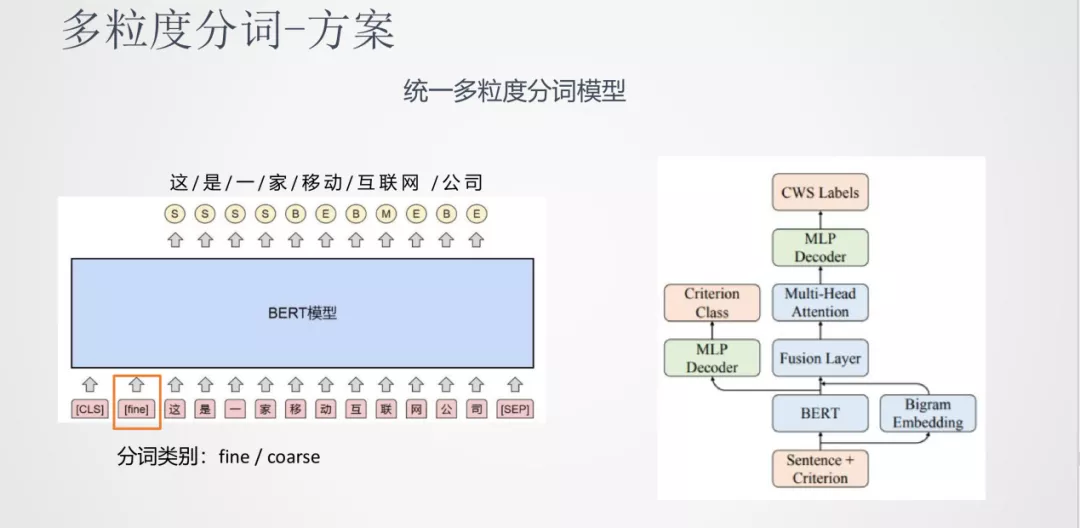
我们的方法是构建一个统一的多粒度分词模型。它的思想是输入时将分词粒度的标签也加入到输入序列中,指导分词粒度的结果。比如上图中使用 fine/coarse 来分别代表细/粗粒度标签,模型的结果就根据这个标签来适配。
我们除了使用 BERT 模型网络外也加入了 Bigram 的向量特征进行融合,之后使用多头注意力机制对融合特征的上下文进行建模,最后进行 MLP Decoder。除了分词本身的学习以外,分词类型也可以作为一个学习任务,两个任务共同训练这样一个网络。
③ 效果
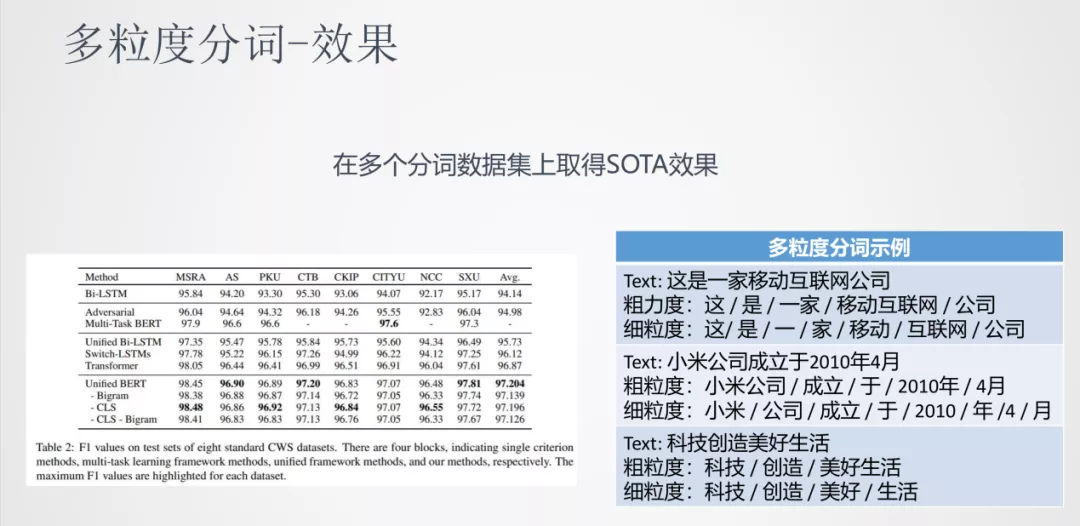
如图中表格所示,我们使用的多粒度分词模型在很多任务上都有不错的效果。通过上面展示的示例可以看到,这种多粒度分词方法也是一种灵活的分词方式。
任务二:生成式对话
① 问题

针对生成式对话这样的场景,一般输入一个 Question,输出为一个 Reply。通常我们会在互联网社区获取大量 Q/R 的数据作为训练语料来训练模型。传统来说,这是一个序列到序列的生成任务,跟翻译模型的训练过程比较相近。
传统的 seq2seq 模型使用 Encoder 和 Decoder 进行建模,问题是没有预训练的过程。
另一种方法是使用类似 GPT 的预训练方式,将 Q 和 R 在一起建模,中间使用[SEP]进行分割,局限是在学习的过程中只能看到文本左边的内容,而不能对整个文本上下文进行建模。
② 方案
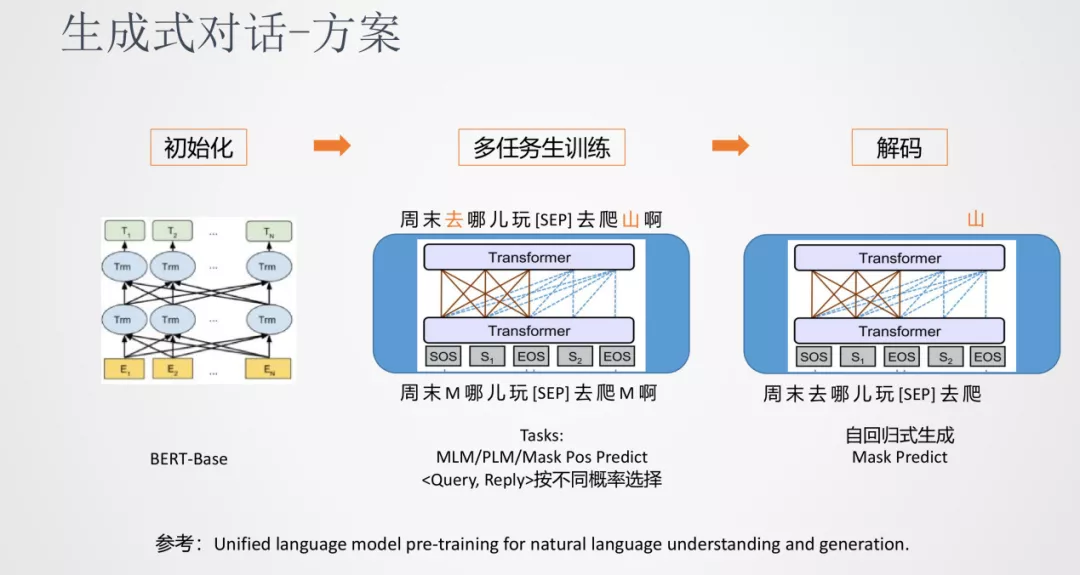
我们采用的是一种多任务的训练方法。先使用一个基础的预训练模型(BERT-Base)来初始化生成式模型的参数,接下来就对话任务进行多任务的训练,比如 MLM、PLM、Mask Pos Predict 等语言模型训练任务,最终在解码阶端可以采用通用的自回归方式生成。
③ 效果
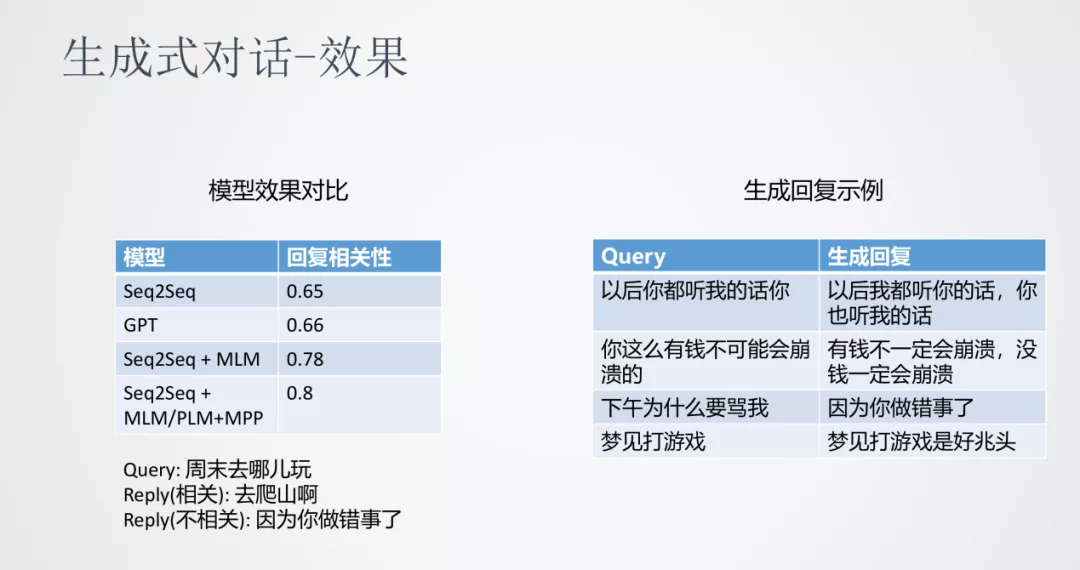
从实验对比来看,跟传统的 seq2seq、GPT 相比,加入多任务训练的方式在针对回复相关性上有很明显的提升。从上图右边示例中可以看到,随着语料数据不断的增大和模型多任务的学习,生成的回复有很好的连贯性和相关性。
总结与展望
1. 总结

本文主要介绍了推理效率、知识融入和任务适配。
推理效率:在知识蒸馏方面使用多教师模型集成蒸馏是一种可以将模型压缩更小,保证模型效果的方法;而推理加速方面使用低精度推理和算子融合的方法可以帮助推理速度有几倍的提升。
知识融入:在对话系统意图识别任务中,通过在原始序列中加入槽位信息序列,使用 attention 的方法将两个特征序列融合成一个序列。
任务适配:多粒度分词任务是在输入上加入适配的标签来指导输出的一种自适应的改变。生成式对话采用联合多任务训练的方式能够集成预训练和序列到序列的生成模型。
2. 展望
轻量级模型
知识融入
预训练平台
本文转载自:DataFunTalk(ID:datafuntalk)
原文链接:小米在预训练模型的探索与优化




