
xAI 发布 Grok 3 和 Grok 3-mini
在 AI 领域,埃隆·马斯克再次成为全球焦点。2 月 12 日,这位科技狂人在迪拜世界政府峰会上透露,其旗下的人工智能公司 xAI 即将发布新一代 AI 模型 Grok 3,并称其为“迄今为止最强大的 AI 模型”。这一消息立即引发科技界强烈关注。
刚刚,Grok 3 连同 Grok 3 mini 如约而至。
发布会一开始,马斯克再次解释了“Grok”一词的含义。这个词来自罗伯特·海因莱因的小说《异乡异客》。这个词被一个在火星长大的角色使用,意思是充分而深刻地理解某事。“Grok”这个词传达了深刻的理解,而同理心是其中的重要组成部分。
马斯克称,Grok 3 之所以能在很短的时间内就超越 Grok 2,是因为背后有一支强大的技术团队和数据中心支持。据 xAI 团队介绍,要训练出超级规模的模型就需要一个超级规模的数据中心做支持,所以他们先是花费了 122 天建成了 10 万卡的数据中心。但随后他们发现,这还远远不够。于是他们又用了 92 天就将原来的 Colossus 规模从 10 万卡扩建到 20 万卡,并在此基础上推出了 Grok 3。

Grok 3 最引人注目的特点将推理能力整合到了模型中。推理指的是模型在尝试解决问题之前需要花费大量时间进行思考。大约一个月前,Grok 3 的预训练完成了,从那时起,xAI 团队一直在努力将推理能力整合到当前的 Grok 3 模型中。然而,这仍处于早期阶段,模型仍在训练中。
今天展示的是 Grok 3 推理模型的一部分。此外,xAI 也在训练一个迷你版本的推理模型。Grok 3-mini 与 Grok 3 在推理上取得的结果相差不大,Grok 3-mini 训练时间更长,有时它的表现甚至略优于 Grok 3 推理模型。这仅仅表明 Grok 3 推理模型具有巨大的潜力,因为它仍在训练中。
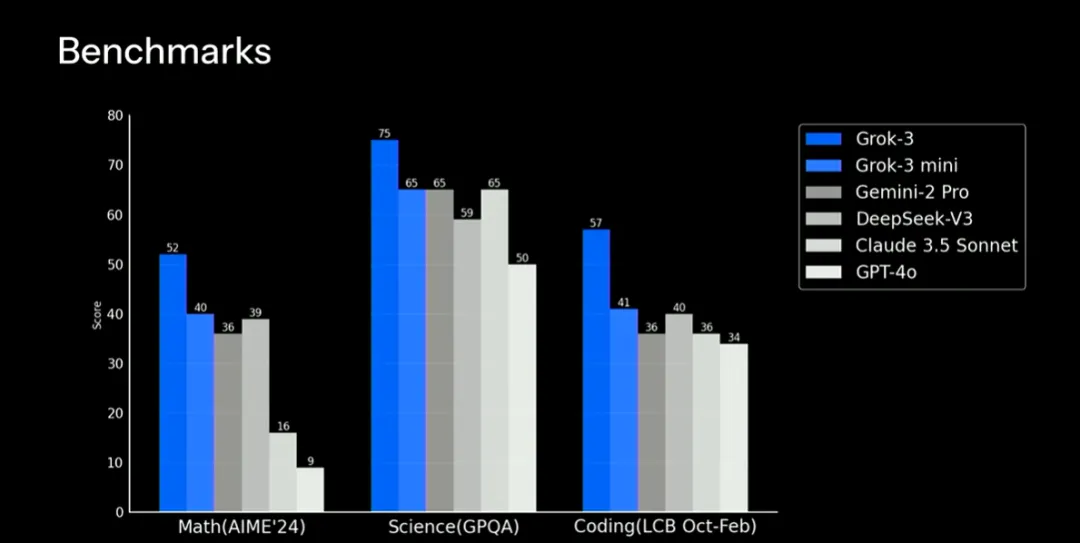
在性能效果上,xAI 从数学、科学和编码三个方面将 Grok 3、Grok 3 mini 与各主流模型进行了对比。综合来看,Grok-3 推理模型测试版在数学、科学和编码三个方面均表现优异,尤其是在编码方面得分最高。Grok-3 mini 推理模型的表现也相当不错,尽管略低于 Grok-3 推理模型测试版,但仍优于 OpenAI 的 o3-mini、o1、DeepSeek-R1 等其他主流模型。
本场发布会,Grok 3 还引入了 DeepSearch,该公司将其描述为一种新型搜索引擎和类似 Agent 功能的早期版本。据 xAI 工程师介绍,DeepSearch 是 xAI 的第一代 Agent 工具,不但能帮助开发者、研究人员和科学家编写代码,实际上还能帮助每个人回答日常遇到的问题。
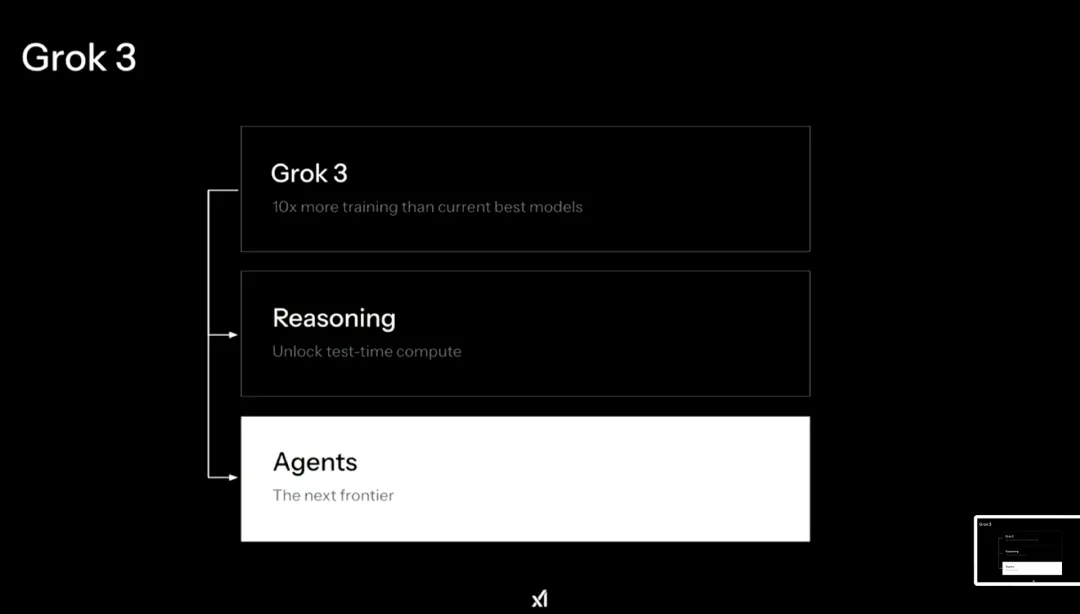
据马斯克介绍,Grok 3 中支持两种订阅模式:X(推特)平台的 Premium+ 深度用户和月费 30 美元 / 年费 300 美元的 SuperGrok。xAI 将在一周时间内在 Grok 3 中上线语音模式,数周后对企业用户提供包含 DeepSearch 的 API 接入方案,并在几个月后对 Grok 2 进行全面开源,但 Grok 3 的关键训练细节和内部权重暂时不会全面公开。
性能如何?
先来具体看看现在 Grok 3 的各项水平是怎样的?
首先来明确一下 xAI 对其的使用场景目标,马斯克在直播中表示,希望能够使用 Grok 3 完成特别重要的现实任务,比如打造一台特斯拉、解决太空发射问题或者应用到数据中心。据其预测,“两年之内会发生两件事情:计算机在各方面打败人类,帮助实现诺贝尔级的科学数据突破。下一次重大突破在明年 11 月出现,我们会真正让 SpaceX 登陆火星,应用 Grok 模型来去计算整个的发射过程。
同时,xAI 宣布将成立一家 AI 游戏工作室来制作游戏。直播中,xAI 现场演示了用 Grok3 创造一个融合《俄罗斯方块》和《宝石迷阵》的游戏案例。
现在也已经有模型体验者用 Grok 3 创建了游戏:
给 Scaling Law 带来什么惊喜
此次 Grok 3 之所以在发布前就吸引来如此多人的关注,原因之一是大家对 Scaling Law 当前真实效果的重视。现在越来越多的声音称“Scaling Law 终结了”,即大模型不再具有规模效应,增加参数数量、算力、训练语料等更多资源或许也无法继续增强模型的性能效果了。
发布会上,xAI 团队透露,Grok 3 背后有 20 万张英伟达 GPU 、4 亿个 GPU 小时的超强算力支持。
Grok 3 由 Colossus 超级计算机训练完成,最初 xAI 用了 122 天让首批 10 万卡集群投入使用,后续又花费 92 天拓展到 20 万卡集群,较前代产品 Grok 2 使用的 15000 个 GPU 实现了数倍的跨越式提升。据公开介绍,OpenAI 训练 GPT-4 用了大约 25000 块 A100 GPU,据 Lambda 测算,H100 的训练吞吐量为 A100 的 160%。也就是说,GPT 4 相当于用了 15625 块 H100。
再对比近期大火的 DeepSeek,据公开论文介绍,DeepSeek-V3 的总训练成本为 278.8 万个 H800 GPU 小时。尽管另据独立研究机构 SemiAnalysis 估计,“DeepSeek 拥有约 1 万张 H800 和约 1 万张 H100。此外,他们还大量订购 H20 GPU”,但也远不及 Grok 3 的训练算力高。
因而,许多网友都将其这次发布当做 Scaling Law 技术路线的又一次验证,并且马斯克在 2024 年中启动 Grok 3 训练时称对标的是 GPT 5。
目前,Grok 3 暂未公布其参数规模。微软在近日发布的一篇医学相关论文中披露,GPT-4 有 1.76 万亿个参数,GPT-4o 和 GPT-4o-mini 的参数分别为 2000 亿和 80 亿。另据公开介绍,DeepSeek-V3 的参数规模达到 6710 亿,但会使用混合专家架构以保证仅激活选定的参数,以便准确高效地处理给定任务。

接下来从性能效果上展开讲讲 Grok 3 到底怎么样。xAI 从数学、科学、编码三方面去对比了 Grok 3 系列和当前热门前沿模型,并在多个基准测试中都击败了其他竞争对手。
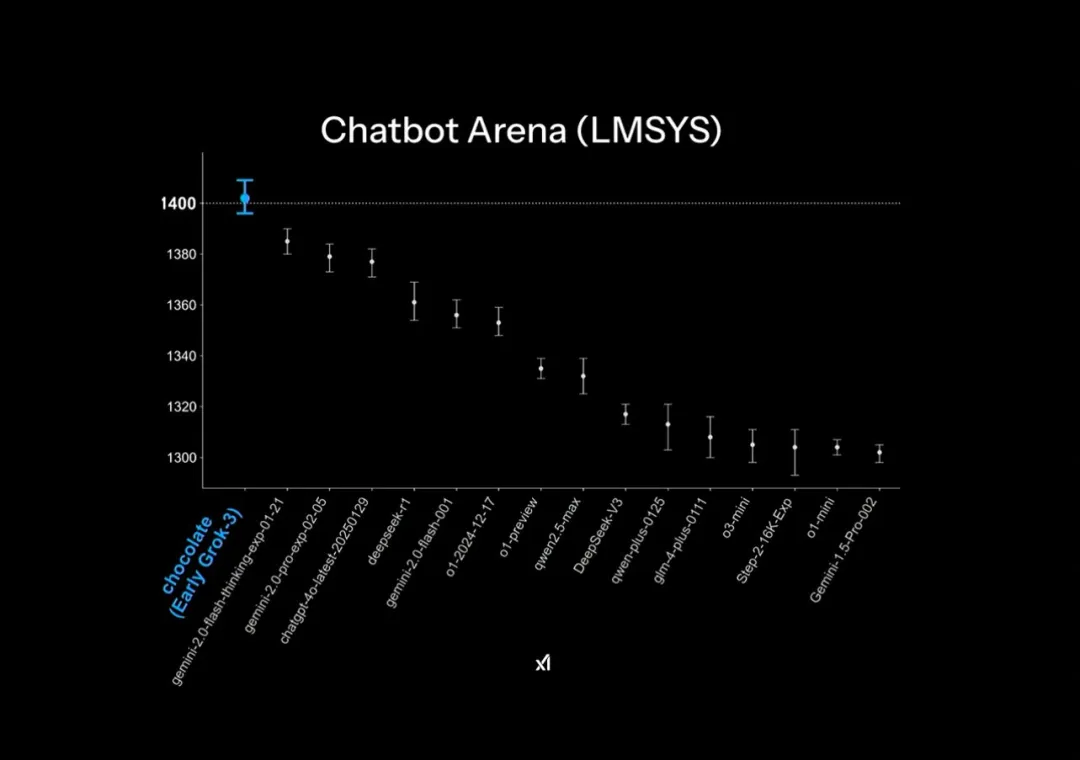
据介绍,在 Arena 中(这是一项众包测试,让不同的 AI 模型相互竞争,并让用户投票选出他们喜欢的答案),Grok-3 是有史以来第一个得分突破 1400 分的模型,并在所有类别中均排名第一。
而去年发布的 Grok 2 模型在 Arena 测试中得分为 1280 分。与 Grok 2 相比,Grok 3 早期版本的性能提升了近 10%。
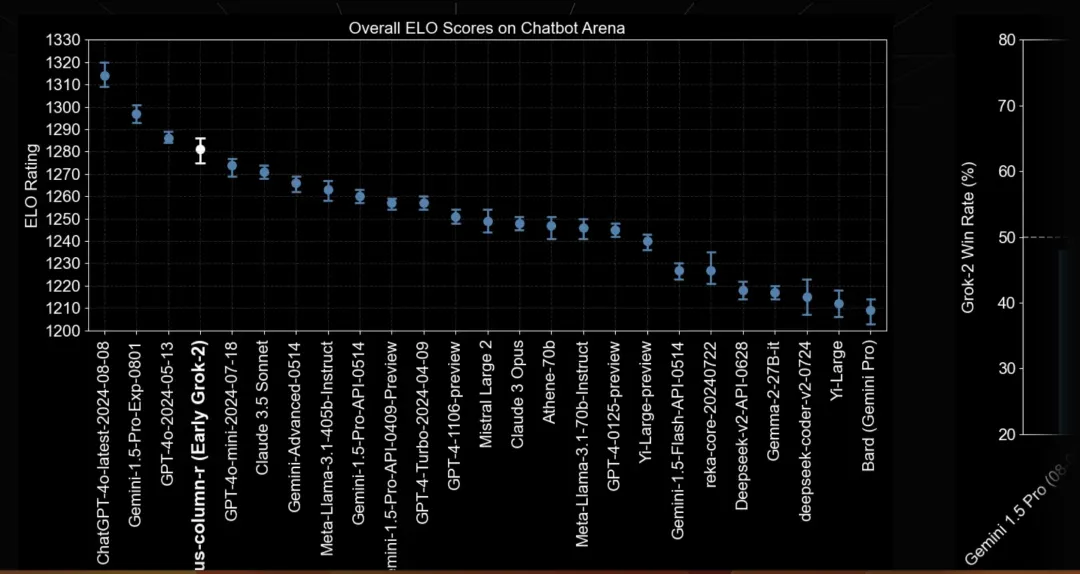
这样来看,在大语言模型(LLM)领域,Scaling Laws 或许依然成立。
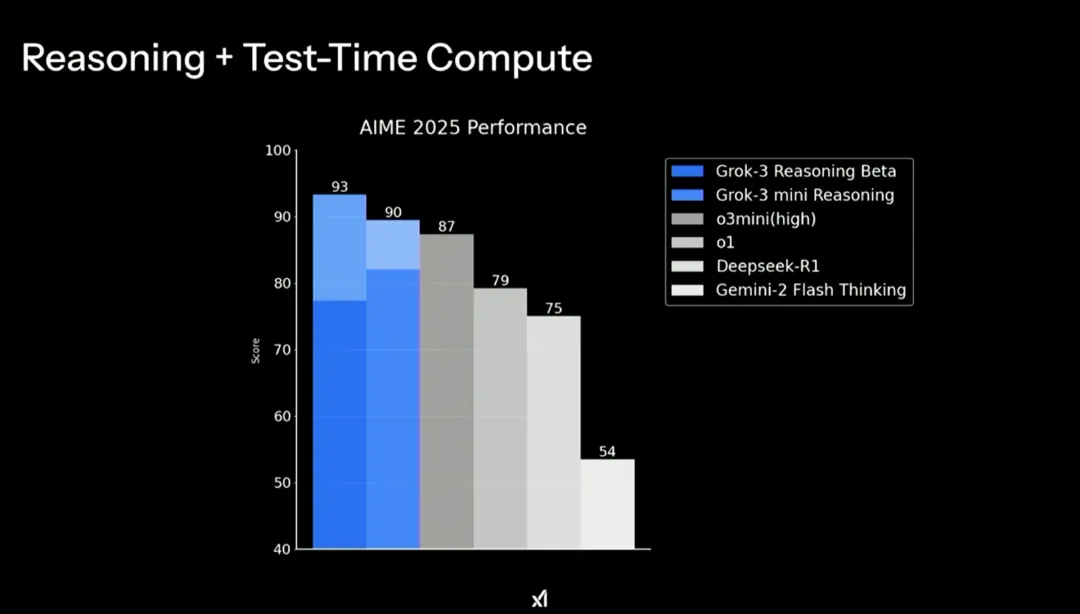
不过,Grok 3 不仅仅是 LLM,还引入了“思维链”(Chain Of Thought)推理能力。马斯克称,Grok 3 在复杂的推理任务中表现优于其竞争对手。据介绍,xAI 的最新模型 Grok 3 在 2024 美国数学邀请考试(AIME)中取得了 93% 的骄人成绩,将其他前沿模型甩在了身后。即使是其 mini 版,也足以与其他 AI 模型的能力相媲美。
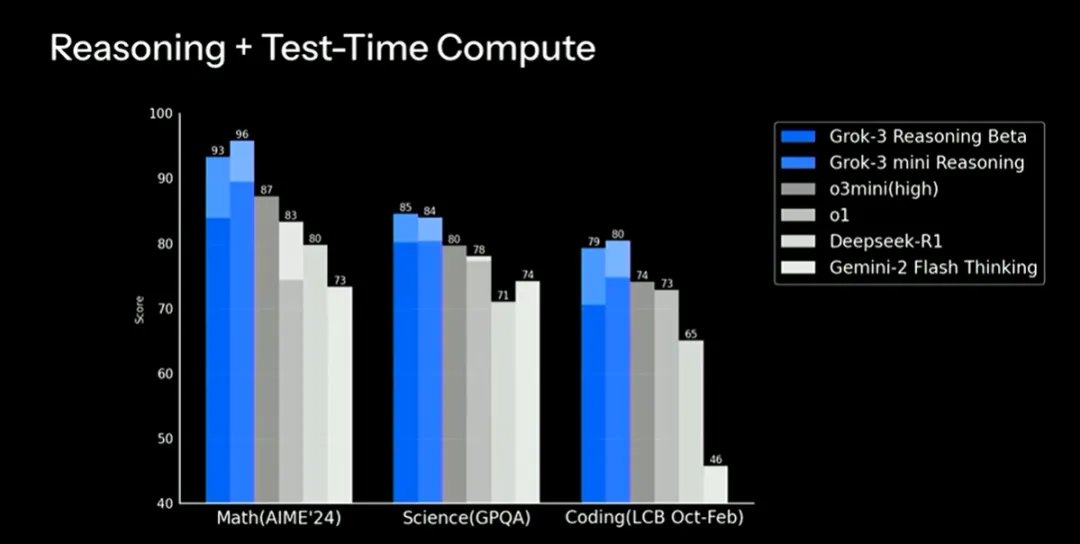
值得注意的是,大约五天前,AIME 2025 竞赛也结束了。随后,xAI 团队让两个模型(Grok 3 和 Grok 3 mini)在同一基准的同一考试中进行比拼。有趣的是,更大的 Grok 3 推理模型在这次全新的考试中表现更好。这表明,与较小的模型相比,更大的模型具有更强的泛化能力和性能。然而,与去年的考试相比,较小的模型表现更好,因为它更有效地学习了之前的考试内容。
Grok 3 能挤进全球模型 Top 5 吗?
这次,不少网友对 Grok 3 模型给出了正面评价,“Grok 3 的出现标志着人工智能发展史上的一个重要里程碑。凭借其令人印象深刻的 ELO 分数和推理能力,我们显然看到了人工智能在解决复杂问题方面的飞跃。”
AI 大佬 Andrej Karpathy 今天早些时候获得了 Grok 3 的早期访问权限,他也成为首批能够快速体验其功能的人之一。Karpathy 表示,Grok 3 好的点是“创建一个棋盘游戏网页,显示一个六边形网格,就像《卡坦岛》游戏中的那样。每个六边形网格都编号为 1..N,其中 N 是六边形瓷砖的总数。使其通用,以便可以使用滑块更改‘环’的数量。例如,在《卡坦岛》中,半径为 3 个六边形。请使用单个 HTML 页面。”
Karpathy 强调,很少有模型能够可靠地准确完成这个任务。顶级的 OpenAI 思维模型(例如 o1-pro,每月 200 美元)也能做到,但 DeepSeek-R1、Gemini 2.0 Flash Thinking 和 Claude 都无法做到。但 Grok 3 也有弱点。“它没有解决我的‘表情符号谜题’问题,在这个问题中,我给出了一个带有隐藏在 Unicode 变体选择器中的消息的笑脸,即使我以 Rust 代码的形式给出了如何解码的强烈提示。我见过的最大的进展来自 DeepSeek-R1,它曾经部分解码了消息。”
那么,Grok 3 能挤进全球顶级模型之列吗?在马斯克看来,是能的。从今天的发布会来看,他对 Grok 3 充满信心,并认为该模型能未来能击败一众先进模型登顶最强模型宝座。
但事实真的如此吗?目前,Grok 在人工智能领域仍是一个小角色。它的受欢迎程度远不及 ChatGPT 等竞争对手,截至 2024 年 11 月,ChatGPT 占据了人工智能工具市场份额的 62.5%。
不过,Grok 确实拥有一些与竞争对手不同的特点。它最大的优势是能原生集成社交媒体 X,使该聊天机器人能够访问社交媒体平台的实时信息,其独特的编程方式使其能够以叛逆和俏皮的语气回答挑衅性的提示。由于这些独特卖点,马斯克的 AI 聊天机器人在 X 用户中很受欢迎。
然而,该聊天机器人经常卷入争议,从回应政治虚假信息到因其可访问 X 数据而宣传有偏见的内容。ChatGPT 和 Gemini 等竞争对手也拥有更多参数,因此它们的响应通常更准确。
基于以上种种,有外界声音认为,堆砌了如此多的算力,即使使用合成训练数据,Grok 3 也不太可能与更大的竞争对手相提并论。
Grok 系列模型的起源与背景
Grok 系列模型是埃隆·马斯克旗下人工智能公司 xAI 的核心产品之一。xAI 成立于 2022 年,旨在开发具有更高推理能力和逻辑一致性的人工智能系统。马斯克一直对人工智能的发展持谨慎态度,多次公开表达对人工智能潜在风险的担忧。然而,他也认为,人工智能技术的进步是不可避免的,因此他希望通过 xAI 开发出更安全、更透明且对人类友好的 AI 系统。
Grok 的名字来源于科幻作家罗伯特·海因莱因的小说《异乡异客》,意为“深刻理解”或“完全掌握”。这一命名体现了马斯克对人工智能的期望:不仅要能够处理复杂的任务,还要具备对人类思维和逻辑的深刻理解。
Grok 1 于 2023 年初发布,是 xAI 推出的首款人工智能聊天机器人。作为初代模型,Grok 1 的主要目标是验证合成数据训练方法的可行性。与当时主流的 ChatGPT 等模型不同,Grok 1 并未完全依赖真实世界数据进行训练,而是采用了大量合成数据。合成数据是通过算法生成的模拟数据,能够覆盖更广泛的情景和逻辑结构。
Grok 1 的推出引起了广泛关注,它能够处理复杂的逻辑问题,并在某些特定任务上超越了当时的 ChatGPT 3.5。然而,Grok 1 也存在一些明显的局限性。例如,由于合成数据的局限性,它在处理真实世界中的细微差别和复杂性时表现不佳。此外,Grok 1 的训练成本极高,且模型规模较小,限制了其在实际应用中的推广。
2023 年年中,在 Grok 1 的基础上,xAI 推出了 Grok 2。这一代模型在多个方面进行了重大改进。依然采用了更大规模的合成数据集,同时结合了少量高质量的真实世界数据,以弥补初代模型在处理真实场景中的不足。Grok 2 还引入了更先进的训练算法,尤其是在数学推理、代码生成和复杂问题解决方面超越了当时的 ChatGPT 4。它还首次尝试了多模态能力,能够处理文本、图像和简单视频数据。
然而,在众多优秀大模型层出不穷的 2023 年,Grok 2 的问世并没有掀起太大水花。Grok 2 依然有着很多弊端,尽管其技术能力备受认可,但由于其使用权限仅限于 X 平台(原 Twitter)的高级用户,普通用户无法直接体验。这一限制导致 Grok 2 的市场覆盖率较低,未能对 ChatGPT 等竞争对手形成实质性威胁。如今 Grok 3 来了,情况会有变化吗?
我们拭目以待。




