
序言:
2 月 14 日晚间,Gartner 公布了 2024 年度 Gartner Power of the Profession 供应链大奖,京东集团荣获供应链技术创新奖,成为获得该奖项的唯一亚洲企业。Gartner Power of the Profession 供应链奖项已经举办十年,是衡量企业供应链创新能力的国际权威奖项。入围决赛的共有 5 家企业,另外 4 家分别是谷歌、思科、MTN 集团、Allina Health。京东智能供应链 Y 业务部研发的“基于概率分布预测以及解释性 AI 的弹性计划技术”,在激烈的竞争中获得冠军,历年的冠军包括微软、辉瑞、壳牌等。此外,几个月前,京东还凭借端到端库存管理等技术入围了 2023 年弗兰兹厄德曼奖(Franz Edelman Award)总决赛,这是一项由美国运筹学与管理科学学会(INFORMS)设立的管理科学界的最高奖项,被誉为工业工程领域的“诺贝尔奖”,旨在表彰运用运筹学和管理科学在实际应用中产生巨大价值的工作。
过去一年,京东零售技术团队持续探索创新。在供应链方向,通过提出并应用端到端库存管理技术和可解释 AI 技术,实现了更快的库存周转和更高效的供应链决策、协同。这是 2023 京东零售技术年度盘点深度文章系列的第三篇,希望能为技术同学们带来一些启发或帮助。

一、供应链决策中的超级难题:如何在保证可解释性的情况下提升预测精度?
销量预测是供应链决策的关键组成部分,其准确性直接影响库存控制、资金安排、生产计划和市场策略。销量预测在传统上依赖于基于统计方法的时间序列模型,但是随着计算能力的提升和数据采集技术的进步,预测方法逐渐演变为更为复杂的机器学习算法,能够处理更多维度的数据并捕捉更深层次的非线性关系。
总体来看,销量预测的发展经历了三个阶段:传统统计方法、机器学习方法以及混合算法。传统的统计方法如 ETS、ARIMA 等,具有清晰的数学结构,但只能处理简单的时间序列数据,无法捕获外生变量的影响,很难进一步提高预测精度。随着电商规模快速发展,商品规模越来越大,传统方法在复杂场景的效果劣势则逐渐显现出来,而机器学习算法由于其强大的拟合能力开始备受追捧,如 xgboost、LSTM、Transformer 等。
然而,目前的机器学习算法普遍是黑盒化的,可解释性的缺乏已经成为这些算法在供应链实践中的一个关键障碍。针对传统方法及机器学习方法的劣势,混合算法逐渐走进大众的视野。混合算法通过将统计模型与黑盒 ML 算法相结合以提高预测准确性和可解释性,如 N-BEATS 和 NBEATSx 。但是这些混合算法存在明显的问题:一方面,现有的混合算法与供应链场景匹配度低,仅仅考虑趋势、季节等固有的时序因素,无法量化营销、促销等特有因素的影响,因此在供应链场景下无法保证可解释性;另一方面,现有的混合算法通常依赖于具有统计假设的理论模型,只关注各成分的准确性,不考虑全局信息,导致准确性的下降。
而对于京东供应链来说,商品补货的决策直接影响生产,所以对于算法的要求不仅仅是准确率,而需要有高度的可解释性,才能获取业务的信任。尤其是针对头部商品,会有补货不足的风险,造成缺货,影响采销的销售计划达成,所以业务需要知道预测结果是如何得到的,比如预测考虑了哪些因素,每种因素带来的影响有多大等等,提升业务的可控度及信赖度。京东智能供应链团队致力于打造一套针对供应链场景下全新的可解释预测算法,其中如何保证可解释性的情况下提升预测精度是最主要的挑战,关键要解决两个技术难点:
(1)高可解释性约束下现有的算法准确性较差
在时间序列预测中,基于时序分解的算法将时序分解为不同的成分,可解释性较强,因此被广泛使用,但是基于传统统计的时序分解算法由于其无法考虑多序列预测及对于复杂场景的拟合能力较差,所以准确性较差。采用这些方法会造成大量的低质量的备货及库存冗余,增加仓储成本。因此如何保证可解释性的情况下提升预测准确率是最大的技术难点。
(2)现有的混合算法全局拟合能力差,与供应链场景匹配度低
为了提高预测精度,最近的可解释算法通常将机器学习方法(ML)与分解相结合,但是现有的混合算法通常依赖于具有统计假设的理论模型,只关注各成分的准确性,不考虑全局信息,而供应链场景下各成分的因素相互依赖,采用统计假设的理论模型难以拟合,这种方式脱离了实际的业务场景,从而导致系统使用率较低,补货不及时等,缺货导致用户买不到自己想要买的商品,影响商品的销售额。
由此,智能供应链团队提出了一种新的可解释预测技术,这是一种新的混合算法,构建了通用的可解释算法框架保证高扩展性,在不同的复杂场景下可解释性及准确性均大幅的提升,主要创新包括:
1.预测流程及结果可解释,大幅提升用户的信任
新的可解释预测技术输出给下游的预测不再是一个最终预测值,预测输出由多个需求因素组成,如基线、促销、营销等,并且基于京东大规模的订单销售、促销等数据,通过因果推断的方式实现数据到模型输入及过程的因果逻辑,既提升了复杂场景的拟合能力,同时让业务了解整个预测流程的流转。比如促销场景下,通过因果算法刻画促销预测量的上升是由于输入的促销数据中业务提报的秒杀促销引起,从而让业务了解整个预测流程的流转,最终通过可解释性的预测指导用户做出准确的补货决策,大幅提升用户的信任。
2.提出了一种通用的结合分解和 ML 的可解释预测算法
智能供应链团队提出了一种通用的结合分解和 ML 的可解释预测算法(W-R 算法),W-R 算法构建了一种通过加权变体的加法组合函数形成的可解释加法模型,既通过分解的范式保证时序的可解释性,又通过深度的权重及残差网络考虑全局信息提升预测准确性,提升了模型全局化拟合能力,解决了现有时序分解算法准确性较差问题。W-R 算法整体分成两个阶段,第一阶段是初始分解模块,通过自定义的分解模块去估计分解的成分,保证预测的可解释性,如在自营场景下:预测 = 基线+促销+营销 。第二阶段为 ML 调整模块,通过构建加权变体加法组合函数去拟合初始分解成分的全局参数,提升预测准确性,自营场景下:预测 = 基线权重基线+促销权重促销+营销权重*营销 +残差,根据权重及残差网络估计相应的权重及残差,最终输出加权的加法组合预测,总体来看既保证可解释性,也保证了准确性。
未来来看,可解释的预测将是供应链领域的重点方向之一,后续智能供应链团队将从全流程可解释、自动诊断归因、计划可解释等多个方向迭代优化可解释预测技术,从而更好的服务下游决策,提升供应链效率。
二、端到端库存管理的策略和模型设计
库存管理是供应链管理中重要的一环,决策者需要根据用户需求、销售计划和供应商能力等信息,安排合理的补货和销售计划。实践中,诸多因素导致库存管理是一项复杂的难题。例如用户需求具有高度的不确定性,商品的种类和数量十分庞大,供应链中间环节较多,供应商送货时间和送货量也有波动性。另一方面,如果库存管理的决策失准,造成的影响也是巨大的。如果对消费者需求预估不足,导致补货数量偏低,会造成频繁的缺货现象,从而影响消费者购物体验,也给平台造成销售损失。如果过高估计了消费者需求,造成补货数量偏高,会导致大量的冗余库存,产生过高的存储费用,同时也占用大量现金流,造成资金浪费。因此,如何应对库存管理这一既重要又有挑战的任务,成为供应链管理中的首要任务。
传统的库存补货方法大多先基于历史数据来预估未来需求,再结合供应商补货提前期(VLT,从向供应商订货到收货完成的时间)等信息,来确定合适的补货策略。这种方式被称为“先预测再优化”框架(Predict-then-optimize, PTO)。然而,PTO 框架将整个补货过程拆分为了预测和优化两个阶段,而输入数据经过第一阶段处理后往往会造成信息损失,因此在后续的优化阶段中无法充分利用原始数据,导致决策偏差。而对于京东场景而言,庞大的商品种类和数量,用户需求的高度随机性,各类意外事件(例如恶劣天气、疫情等)对供应链的影响和冲击,均会进一步提升需求预测中的误差,最终导致供应链成本增加,消费者满意度下降。
为解决上述问题,京东智能供应链团队提出端到端(End-to-end)库存管理技术,基于多分位数循环神经网络(MQRNN)算法,利用商品历史销量、历史采购节奏、供应商履约等数据,直接通过模型来决策最佳补货量。
该模型先使用历史采购数据、销量数据、库存数据,采用基于动态规划框架提出的最优补货量决策模型,确定历史各个下单时间的最优补货量;再基于历史销量信息、送货提前期信息、下单周期、初始库存以及最优补货量构建特征库并生成学习样本;随后设计基于多分位数循环神经网络的深度自学习模块,针对学习样本进行训练优化;最后基于学习后的深度自学习模块进行预测销量、送货提前期以及下单量,实现端到端补货方法。
如图所示,端到端模型的输入项包含 5 类,分别是需求预测相关特征、商品基础特征(例如品类、品牌、仓库信息等)、供应商送货时长特征、库存盘点周期特征和初始库存水位信息。这些输入信息经处理后进入隐藏层,包括需求预测子模块、送货时长模块和优化决策模块。模型最终输出项包括 3 类,第一项是最终的补货决策,是模型的主要输出,第二、三项是同时生成的需求预测结果和供应商送货时长预测结果。由于缩短了决策流程,减少了中间环节预测误差累积对决策效果的影响,端到端模型提升了补货精准度,有效降低成本。
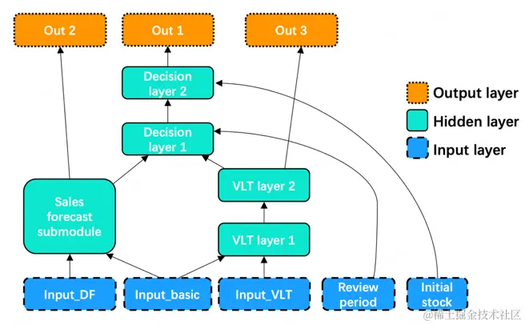
图 端到端补货模型示意
这两项技术上线以来,供应链预测准确度提升 7%,现货率提升 2%,库存周转优化接近 2 天,带来数亿元的持货成本节约。以这两项技术为基础的自动补货系统,已实现超过 85%的自动化率。
目前,京东作为中国最大的零售商,为近 6 亿活跃用户提供超过 1000 万种自营商品。京东自建的覆盖全国的完善物流体系,管理着超过 1600 个库房,运营着超大规模的物流车队。京东如此庞大的零售和物流业务,背后离不开卓越的供应链管理技术,包括库存管理、库房运营、配送履约等。得益于完善的供应链设施和先进的数智化技术,超过 95%的京东自营订单可以实现当日达或次日达,平均库存周转天接近 30 天,现货率高于 97%,达到了行业领先水平。未来,京东将继续通过数智化技术持续优化成本、效率、体验,致力于创造更大的产业价值和社会价值。
本文相关的具体技术细节,可分别参考论文:




