
语音分离(Speech Separation),就是在一个有多个说话人同时说话的场景里,把不同说话人的声音分离出来。目标说话人提取(Target Speaker Extraction)则是根据给定的目标说话人信息,把混合语音当中属于目标说话人的声音抽取出来。
下图汇总了目前主流的语音分离和说话人提取技术在两个不同的数据集上的性能,一个是 WSJ0-2mix 纯净数据集,只有两个说话人同时说话,没有噪声和混响。WHAM 是与之相对应的含噪数据集。可以看到,对于纯净数据集,近两年单通道分离技术在 SI-SDRi 指标上有明显的进步,图中已 PSM 方法为界,PSM 之前的方法都是基于频域的语音分离技术,而 PSM 之后的绝大多数(除了 deep CASA)都是基于时域的语音分离方法。
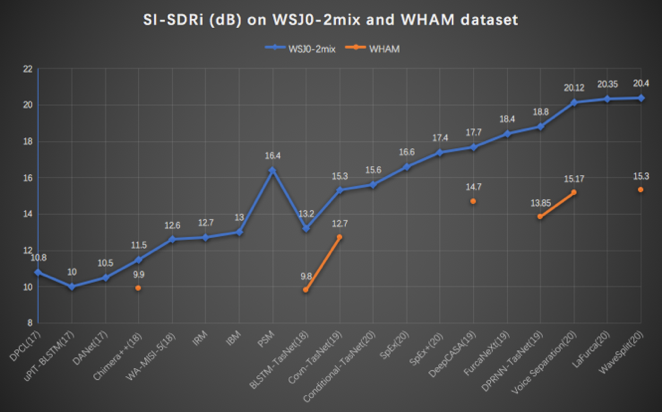
噪声场景相对更贴近于真实的环境。目前,对于噪声场景下的分离技术性能的研究还不是特别完备,我们看到有一些在安静环境下表现比较好的方法,在噪声环境下性能下降比较明显,大多存在几个 dB 的落差。同时,与纯净数据集相比,噪声集合下各种方法的性能统计也不是很完备。
通常来讲,单通道语音分离可以用“Encoder-Separator-Decoder”框架来描述。其中, Encoder 可以理解为将观测信号变换到另外的一个二维空间中,比如离散傅里叶变换将时域信号变换到频域,1-D CNN 将时域信号变换到一个二维潜空间中;Separator 在变换域当中进行语音的分离,学习出针对不同声源的 mask,与混合信号做一个元素级别相乘,由此实现变换域中的语音分离操作;Decoder 就是把分离后的信号反变换到一维时域信号。这套框架既可适用于频域的分离方法,也可用于时域的分离方法。
大部分 Encoder 都是通过线性变换完成的,通过一组滤波器将时域混合语音变换到另外的一个二维空间当中。滤波器组的设计是值得研究的。最简单的方法是用固定的滤波器,比如短时傅里叶变换。此外,人们更愿意用 data-driven 的方式学习滤波器组的系数,比如常用 1-D CNN。所以,单通道的语音分离,便可以依据此划分为频域和时域两类方法。
第一类是基于频域的语音分离方法。这种方法的优点是可以与传统的信号处理方法更好的相融。频域法中的 encoder 多数情况下由傅里叶变换实现。在多通道场景下,可以与后端的频域波束形成更好的配合。第二个优点就是 Separator 中 Mask 的可解释性比较强,即通过网络学出来的特征更加稀疏和结构化。这种方法的缺点也比较明显。第一,傅里叶变换本身是一种通用的变换,也是信号处理当中的经典变换,但它并不一定适用于分离任务。第二个比较明显的问题是相位重建比较困难。Separator 中学习 Mask 通常利用的是幅度谱,而在语音重构的时候会利用混合语音的相位,所以会有语音失真的产生。第三,因为要做傅里叶变换需要有足够的采样点保证频率分辨率,所以延时比较长,对于对时延要求比较高的场景,频域分离法会有限制。
第二类方法是时域分离法。它的第一个优点是用一种 data-driven 的形式完成 encoder 变换,比较常用的是 1-D CNN 或是更深的 Encoder 来完成这种变换。另外,时域方法不需要处理相位重建。第三,它的延时比较短,比如 Conv-TasNet 可以做到两毫秒的延时,DPRNN-TasNet 可以做到采样点级别的延时。时域方法的缺点是 Mask 可解释性比较差,我们并不知道信号会变换到什么样的域当中,也不知道在这个域当中 Mask 到底有什么物理含义。此外,时域法和传统的频域信号处理方法相结合也稍显复杂。
如果我们只想得到我们感兴趣的说话人的声音,而不需要分离出每一个说话人,这就是目标说话人抽取。它可以解决盲源分离中的两大痛点,即输出维度问题和置换问题。此外,由于只需要抽取出一路信号,因此不需要在分离出的多路信号中进行选择,从而节省运算量。它的附加条件是需要一个参考,既然要抽取特定的说话人,那么必须要事先知道关于这个说话人的信息,也就是 speaker-embedding,将这些信息作为参考输入给抽取网络。在一些实际场景中,获取参考并不困难。
早期的语音分离多采用基于频域的方法,比如 u-PIT,这是一种比较流行的训练方法,很多时域的分离网络依然沿用了这种训练思路。Deep CASA 是频域方法当中性能比较突出的一种方法,它是基于 CASA 框架。CASA 的基本框架分为两部分:第一步是基于帧级别的分离;第二步则是对上一步的结果聚合得到输出。Deep CASA 顾名思义是将上述两步用更深的网络来实现,这是近两年在频域算法中表现比较突出的方法。
对于目标说话人抽取技术,最早是由谷歌提出的 Voice filter,它利用了目标说话人的声纹信息,将声纹 d-vector 作为参考输入到抽取网络中,抽取网络可以只抽取出与该声纹信息相匹配的信号。另一种现阶段更为常用的抽取方式是引入一个辅助网络,通过联合学习的方式得到高质量的 speaker-embedding,帮助抽取网络完成目标说话人声音的提取。
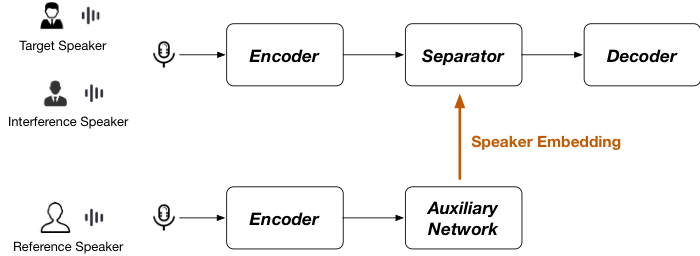
基于时域的语音分离技术,比较有代表性的包括 Conv-TasNet、DPRNN-TasNet 等。对于时域目标说话人抽取任务来讲,SpEx 和 SpEx+目前的表现比较好,它们的基本框架也是借助于辅助网络提取声纹信息,SpEx 和 SpEx+的不同点在于,后者的 speech encoder 和 speaker encoder 是权值共享的。此外,多尺度输入对于抽取性能提升也是有帮助的。
SpEx+是基于 Conv-TasNet 的说话人提取网络,ResNet 作为辅助网络进行目标说话人 speaker embedding 的提取,是目前公开的论文中性能最好的算法。目前语音分离最好的模型之一是 DPRNN-TasNet,模型较小,性能较优。基于 SpEx+,我们提出了模型规模更小的说话人提取网络 DPRNN-Spe,将 SpEx+提取网络的 TCN 用 DPRNN 替代,且声纹信息只输入一次到提取网络。DPRNN-Spe 模型框架如下图所示。
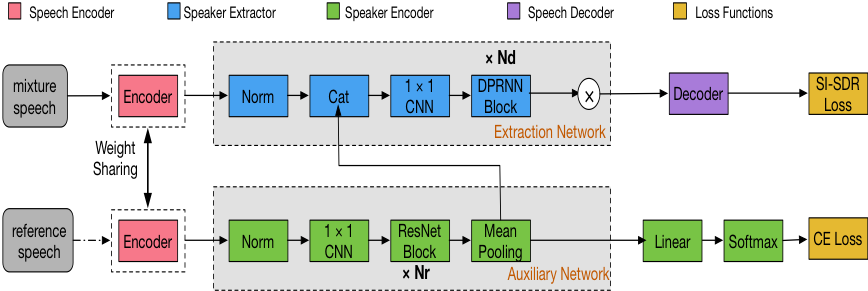
无论 SpEx+或是 DPRNN-Spe 在参考 speaker embedding 比较匹配的时候,都能取得较好的提取效果。然而对于未注册的说话人或者辅助的 speaker embedding 与混合语音中的声纹信息不够匹配时,现有的模型的性能都会有较大幅度的降低。在实际场景中,未注册的目标说话人是远大于注册说话人的。而 speaker embedding 会因年龄、身体健康、情绪、录音环境和说话速度等因素发生或大或小的改变,它的负面效应很可能会在说话人提取网络中被放大。此外,相比于文本相关的 speaker embedding,文本无关的 speaker embedding 可能会产生一定的冗余信息。
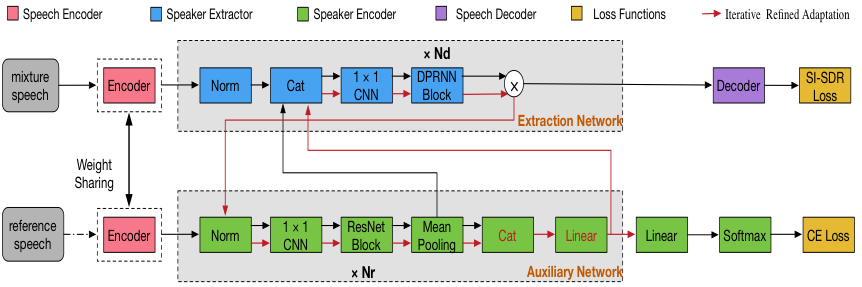
针对以上存在的问题,我们提出了一种机制——Iterative refined adaptation (IRA),可以更好的提高模型的鲁棒性,它本质上是一种 adaptation 方法。该机制受听觉感知的启发,人们可以随着在交谈或者聆听的过程增加对特定说话人的熟悉程度从而更好地聆听或者交谈。基于 IRA 机制的 DPRNN-Spe-IRA 说话人提取流程如下图所示。首先,我们利用初始的参考信号获得最初的 speaker embedding,然后将 speaker embedding 输入到提取网络中得到初次的提取结果,接下来将初次提取的结果反馈到辅助网络中得到新的 speaker embedding,将新旧 speaker embedding 进行加权相加得到更匹配的 speaker embedding,然后再次传给提取网络进行目标说话人提取。即提取网络和辅助网络的信息是互相优化更新的。此过程可以反复进行,随着迭代次数的增加,提取的目标语音效果越好。
实验表明,在说话人提取网络中引入 IRA 机制,无论在无噪或者含噪场景下都能有较大的性能提升。实验结果如下图所示。测试集均是未注册的目标说话人。(即与训练集不同的说话人)
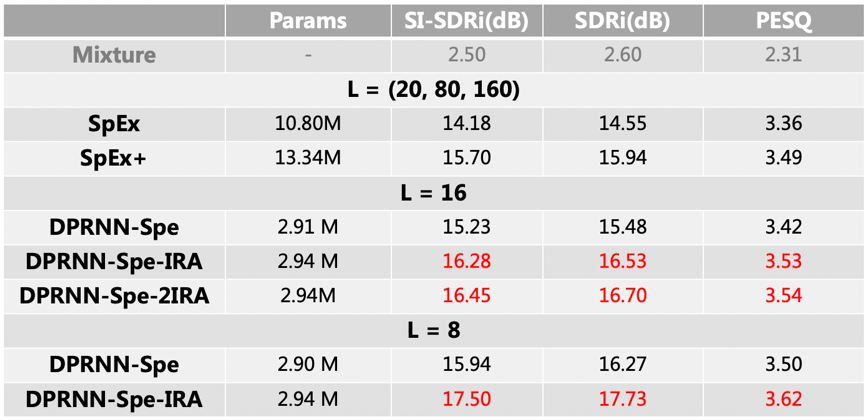
WSJ0-2mix-extr (无噪场景):
WHAM!(含噪场景):
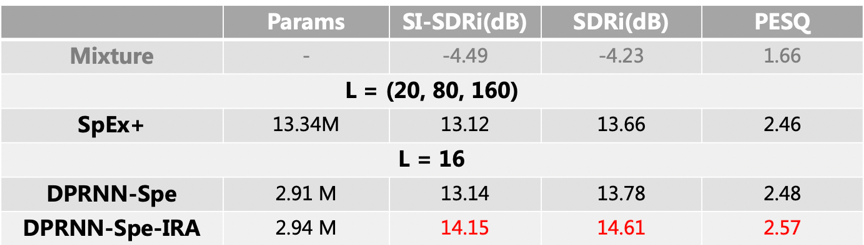
以上两个表格中 L 表示编码器 CNN 中的滤波器的长度,图中展示了在相同参数条件下,IRA 能够更好的提升模型的性能指标。以下是含噪场景中,说话人提取效果的示例。从频谱上看,噪声基本已被去除,提取的语音和原始干净语音对比无明显的失真。
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODEw
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODEx
Mixture VS Extraction
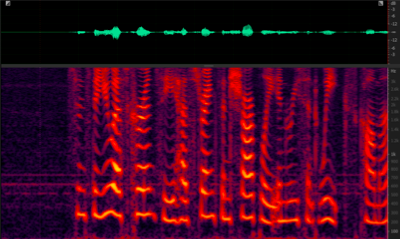
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODEy
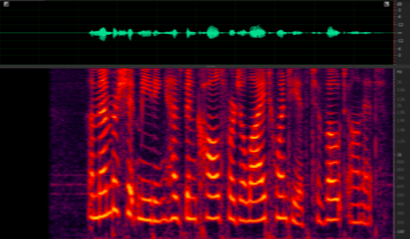
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODEz
Reference VS Clean
说话人提取是从混合语音中提取特定说话人语音的技术,同样,我们也可以在混合语音中对特定的语音进行抑制,即说话人抑制。与说话人提取类似,我们需要给辅助网络提供特定说话人的语音,利用提取网络输出我们想要的目标信号即可。说话人抑制技术与回声消除(AEC, Acoustic Echo Cancellation)实现了相同的功能,由于 AEC 算法存在延时估计不准以及滤波器收敛等问题,导致回声消不干净或者对回声消除较大进而对近端语音造成了损伤,但是说话人抑制可以很好的解决上面的问题。目前,滴滴主要将说话人抑制技术应用于去除导航音,经过实验发现,相比于 AEC,说话人抑制技术能够更好的去除导航音,并且对近端语音没有损伤。
关于说话人抑制的研究目前还处于继续研究的阶段,但是现有模型在实际数据中已经表现出了优于 AEC 的效果,对近端语音没有造成损伤。下图为实际采集的语音,利用说话人抑制模型去除导航音的效果。
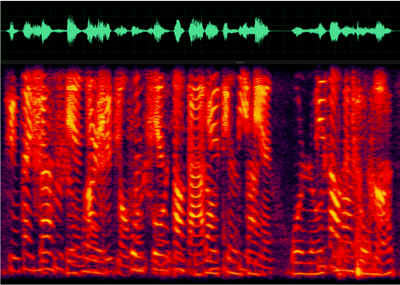
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODE0
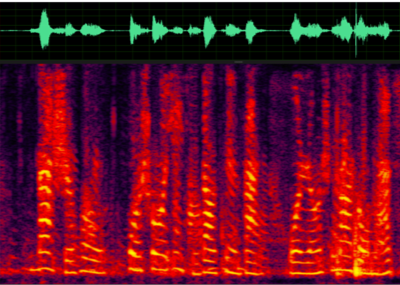
https://res.wx.qq.com/voice/getvoice?mediaid=MzU1ODEzNjI2NF8yMjQ3NTE1ODE1
采集语音 VS 抑制结果
作者介绍:
Chopper,滴滴高级研究员
实践证明,IRA 机制能够进一步提高说话人提取模型的鲁棒性,对 IRA 机制和说话人抑制的有关研究仍在继续进行,比如 IRA 会随着提取网络建模精度的提升带来更大的收益等;说话人抑制模型训练过程中,在训练集中添加合适比列的负样本,能够更好的消除只包含导航音的语音片段。
Aishinichi,滴滴研究院
2019 年 8 月加入滴滴,任滴滴高级研究员,从事滴滴语音前端信号处理中多种场景的前沿技术研发和落地工作,包含语音前端信号处理开源项目、数字水印、语音分离与导航音去除等。2018 年 6 月研究生毕业于大连理工大学,硕士阶段的研究方向为信号处理。曾在中兴工作,专注于信号处理算法的优化与落地。在语音顶级会议 Interspeech 上作为主要作者发表了两篇论文。
Carter,滴滴高级专家研究员
2019 年 7 月加入滴滴,任滴滴研究员,从事滴滴语音前端信号处理中增强、分离领域的前沿技术的探索。2019 年 6 年研究生毕业于北京邮电大学。正式入职以来,以第一作者身份在 ICASSP 和 Interspeech 发表 2 篇论文,累计发表论文 4 篇。和团队一起参与了导航音去除、噪声抑制等业务项目。
2018 年 5 月加入滴滴,语音研究实验室负责人,负责滴滴语音和音频信号处理算法的研发。博士毕业于清华大学。曾在百度工作,专注于语音信号处理技术的研发。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:




