
本文最初发布于 Netflix 技术博客,经授权由 InfoQ 中文站翻译并分享。
作为 Android 开发人员,我们通常可以将后端视为在云中运行的黑盒,负责忠实地向我们返回 JSON。在 Netflix,我们采用了服务于前端的后端(Backend for Frontend,BFF)模式:我们没有一个通用的“后端 API”,而是每个客户端(Android/iOS/TV/web)有一个后端。在 Android 团队中,尽管我们大部分时间都花在了应用程序上,但还要负责维护与应用程序通信的后端及其编排代码。
最近,我们完成了为期一年的项目重构工作,并将后端与之前使用的中心化模型解耦。我们的迁移工作没有减慢常规的版本更新节奏,并特别注意避免对用户体验造成任何负面影响。
我们以前用的本质上是单体服务中的无服务器模型,现在则要部署和维护一个托管我们应用程序后端端点的全新微服务。这让 Android 工程师对我们获取数据的过程有更多的控制权和可观察性。
在本文,我们会讨论迁移方法、采用的策略和为支持这一迁移工作而构建的工具。
背景
Netflix Android 应用程序使用falcor数据模型和查询协议。这使应用程序可以在每个 HTTP 请求中查询一个“路径”列表,并获取我们用于缓存数据和对 UI 进行水化处理的特殊格式的 JSON(jsonGraph)。如前所述,每个客户团队都拥有各自的端点:这实际上意味着我们要为查询中的每个路径编写各自的解析器。
例如,要渲染此处显示的页面,应用程序将发送如下查询:
paths: ["videos", 80154610, "detail"]一个路径从根对象开始,然后是要检索其数据的一系列键。在上面的代码段中,我们正在访问 ID 为 80154610 的 video 对象的 detail 键。
对于该查询,响应为:
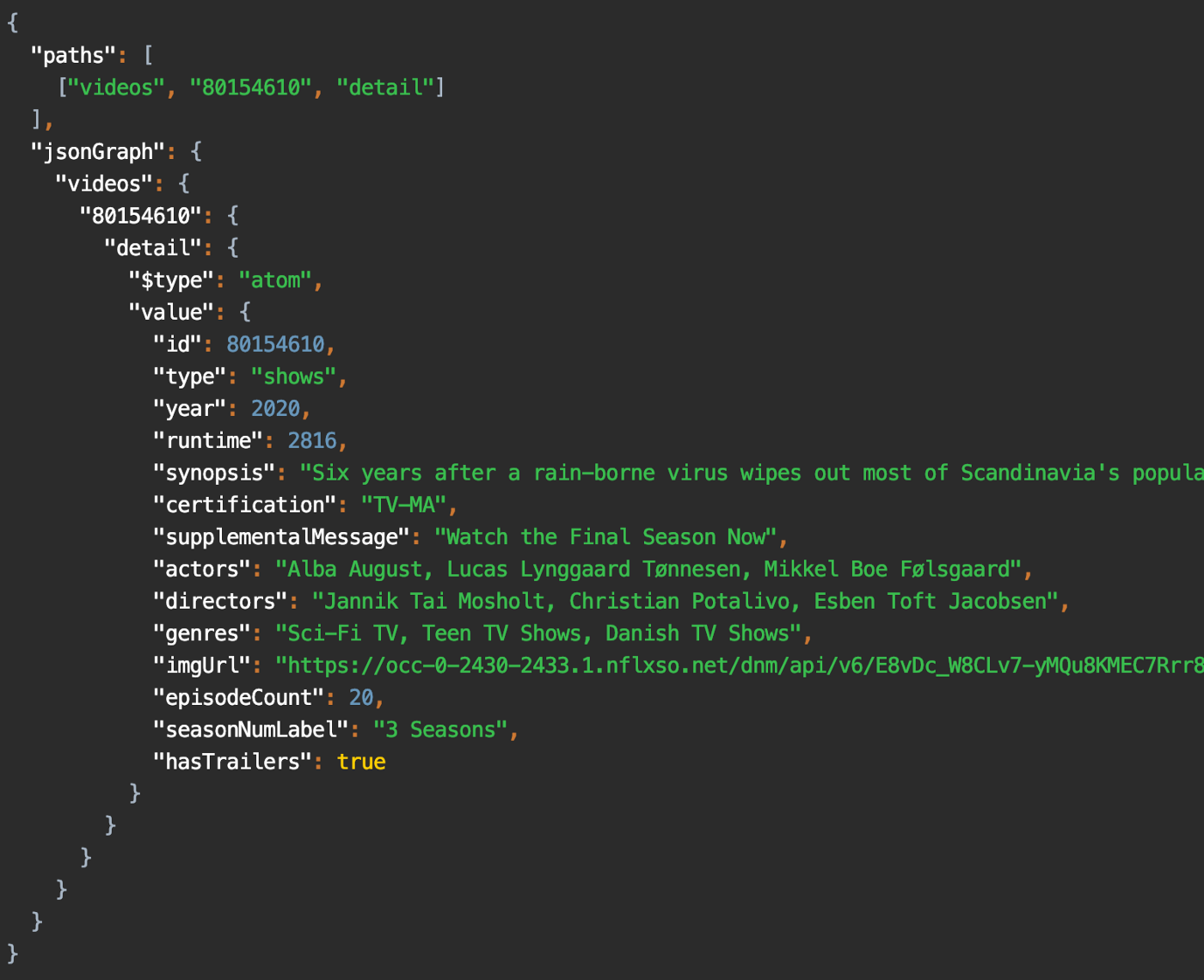
对查询的响应["videos", 80154610, "detail"]
单体架构的情况
在上面的示例中,应用所需的数据由不同的后端微服务提供。例如,插图服务与视频元数据服务是分开的,但是我们都需要两者 detail 键中的数据。
我们使用 API团队提供的库在端点代码上进行编排,该库公开了一个 RxJava API 以处理对各种后端微服务的下游调用。一般来说,我们的端点路由处理程序使用这个 API 有效地(通常是在多个不同的调用之间)获取数据,并将其组合为 UI 期望的数据模型。我们编写的这些处理程序已部署到 API 团队运行的一个服务中,如下图所示。
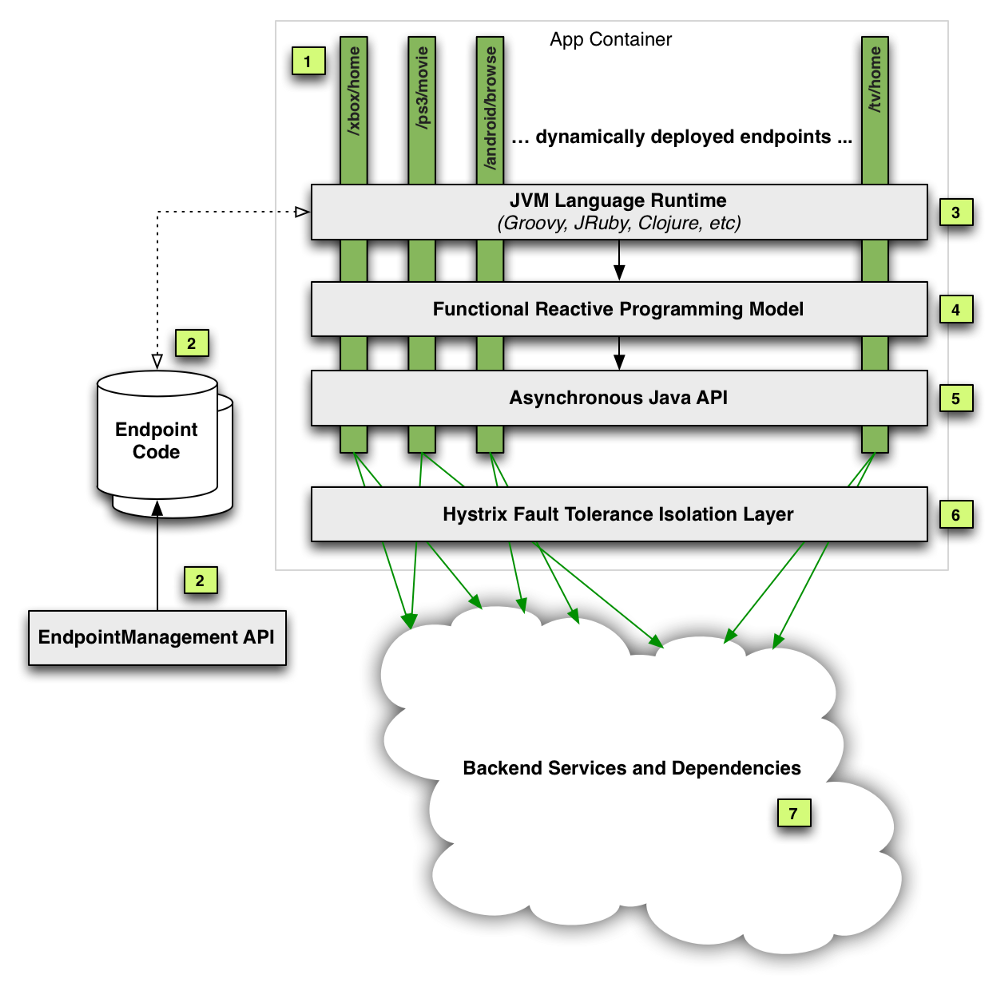
如你所见,我们的代码只是这个单体服务的一部分。除了托管我们的路由处理程序外,该服务还负责处理以容错方式进行下游调用所需的业务逻辑。虽然这为客户团队提供了非常方便的“无服务器”模型,但随着时间的流逝,我们在使用此服务时遇到多个运营和 devex 挑战。你可以在我们之前的文章中阅读更多关于此部分的内容:第1部分,第2部分。
微服务
显然,我们需要将(每个客户团队拥有的)端点代码与下游容错调用的复杂逻辑隔离开来。从本质上讲,我们想将特定于客户端的代码从这个单体中分解出来,隔离成自己的服务。
我们尝试对这个新服务做了一些迭代,最终选择了一种现代化的架构,旨在为客户团队提供对 API 体验的更多控制权。这是一个具有可组合 JavaScript API 的 Node.js 服务,该 API 执行下游微服务调用,取代旧的 Java API。
Java……Script?
作为 Android 开发人员,我们开始依赖像 Kotlin 这样的强类型语言的安全性,也许还有一部分 Java。由于这个新的微服务使用了 Node.js,因此,我们不得不用 JavaScript 编写端点,我们团队中许多人都不熟悉这种语言。为什么要为这个新服务选择 Node.js 生态系统呢?这一决策的背景本身就可以扩展开来写一篇文章。对我们来说,这意味着我们现在需要在编写路由时打开大约 15 个 MDN 标签页。
我们来简要讨论一下这个微服务的架构。它看起来像 Node.js 世界中非常典型的后端服务:是 Restify、HTTP 中间件堆栈和基于 Falcor 的 API 的组合。我们将详细介绍该堆栈的具体内容:总体思路是,我们仍在为[videos, 之类的路径编写解析器,但现在我们会使用 JavaScript 编写它们。
而与单体架构的最大区别在于,它现在是作为独立服务,部署为我们的云基础架构中的单独“应用程序”(服务)。
更重要的是,我们不再只是从服务中运行的端点脚本的上下文中获取和返回请求:我们现在能完整地处理 HTTP 请求。从“终止”来自公共网关的请求开始,然后我们对 API 应用程序进行下游调用(使用前面提到的 JS API),并构建响应的各个部分。最后,我们从服务中返回所需的 JSON 响应。
迁移
在讨论这一变化对我们意味着什么之前,我们想谈一谈我们是如何做到的。我们的应用程序有约 170 个查询路径(路由处理程序),因此我们必须找出一种迭代的方法来完成迁移任务。为了支持迁移任务,我们在应用中内置了一些内容。回到上面的屏幕截图,如果你在页面上进一步向下滚动,则会看到标题为“More Like This”的部分:

如你所见,这里的视频详细信息数据并不属于原视频。相反,它是另一条路径的一部分:[videos, 。这里的总体思路是,每个 UI 页面(Activity/Fragment)都需要来自多个查询路径的数据来渲染 UI。
为终端技术栈的重大变化做好准备,我们决定围绕响应查询所花费的时间来跟踪指标。经过与后端团队的协商,我们认定将这些指标分组的最有效方法是通过 UI 页面来分组。我们的应用使用了一种版本库模式,每个页面都可以使用查询路径列表来获取数据。这些路径以及其他一些配置可用来构建一个Task。这些Task已经带有一个uiLabel,它可以唯一地标识每个页面:这个标记成为我们的起点,我们将它放在一个标头里传递给端点。
然后,我们使用它来记录响应每个查询所花费的时间(按uiLabel分组)。这意味着我们可以按页面跟踪用户体验的任何可能的回归,这与用户浏览应用的方式相对应。在后面的章节中,我们将详细讨论如何使用这些指标。
快进一年:我们从开始时的 170 缓慢而稳定地减少到 0,我们将所有“路由”(查询路径)迁移到新的微服务。那么,结果怎么样呢?
收益
今天,大部分迁移工作已经完成:我们大多数应用程序都是从这种新的微服务获取数据的,希望我们的用户从未注意到迁移过程的波动。与任何如此大规模的迁移一样,我们在这一过程中遇到一些障碍:但首先,让我们看看迁移带来的好处。
迁移测试基础架构
我们的单体架构已经存在很多年,而且设计时并没有考虑到功能和单元测试,因此这些都是由每个 UI 团队独立确定的。对迁移而言,测试是“一等公民”。尽管没有技术上的因素阻碍我们提早添加完整的自动化覆盖,但在迁移每个查询路径时,添加这部分内容要容易得多。
对于我们迁移的每条路由,我们都希望确保不引入任何回归:以丢失(或更糟,错误)数据的形式,或是增加每个端点的延迟。如果我们将问题简化为最基础的内容,那么实际上有两个返回 JSON 的服务。我们要确保对于给定的一组作为输入路径,返回的 JSON 始终完全相同。在其他平台和后端团队的帮助下,我们采取了三管齐下的方法来确保所迁移的每条路线的正确性。
功能测试
功能测试是所有部分中最简单的:在每个路径旁边放一组针对新旧端点的测试。然后,我们结合了出色的 Jest 测试框架与一组自定义匹配器,以清除时间戳和 uuid 等一些东西。它在开发过程中给了我们很高的信心,并帮助我们涵盖了必须迁移的所有代码路径。测试套件可以自动执行一些操作,例如设置测试用户,以及匹配真实设备发送的查询参数/标头:但也只有这些了。功能测试的范围仅限于已经设置好的测试方案,但是我们永远无法复制全球数百万用户使用的各种设备、语言和语言环境组合。
重播测试
谈到重播测试。这是一个定制的三步流水线:
捕获所需路径的生产流量
在 TEST 环境中针对两种服务重播流量
比较并断言差异
根据设计,这是一个自包含的流程,它捕获了整个请求,而不仅仅是我们请求的一条路径。该测试是最接近生产环境的测试:它重播了设备发送的真实请求,从而执行我们的服务中从旧端点获取响应,并将它们与新端点的数据缝合在一起的部分。重播管道的完整性和灵活性也值得单独写一篇文章来分析。对我们来说,重播测试工具让我们确信新代码几乎没有任何错误。
金丝雀
金丝雀是“审核”我们新的路由处理程序实现的最后一步。在这一步骤中,管道将选择我们的候选更改,部署服务,使其可公开发现,并将一小部分生产流量重定向到这个新服务上。你可以在 Spinnaker 金丝雀文档中找到关于其工作机制的更多详细信息。
这就是我们前面提到的uiLabel指标大显身手的地方:在金丝雀期间,Kayenta被配置为捕获和对比所有请求的这些指标(除了已经在跟踪的系统级指标,例如服务器 CPU 和内存)。金丝雀结束时,我们得到一份报告,该报告汇总并对比了特定 UI 页面提出的每个请求的百分位。查看我们的高流量 UI 页面(如主页),可以让我们在为所有用户启用端点之前识别由端点引起的任何回归。下面是这类报告的一个例子,可以帮你大致了解一下:
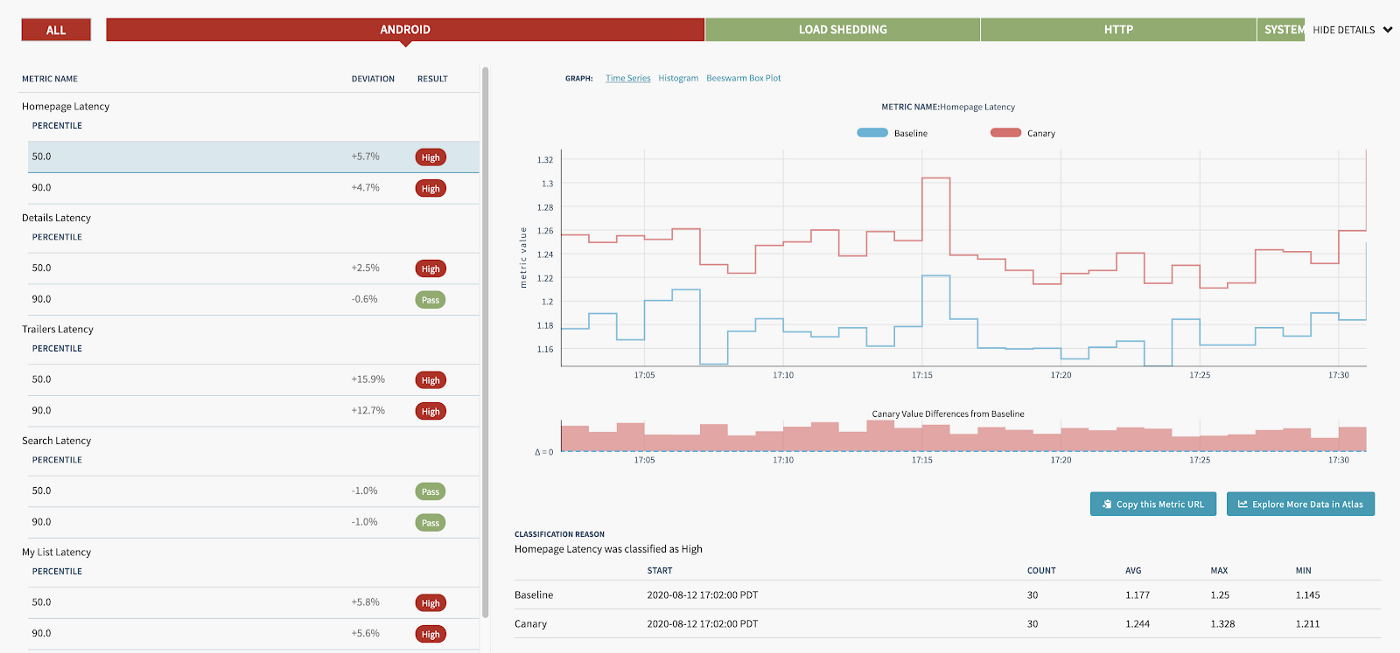
每个确定的回归(像上图这样的回归)都需要大量分析:分析其中的一些回归就让我们找出了先前无法确定的性能提升的原因!启用一个新路径使我们能够验证延迟和错误率是否在可接受的范围内。这种类型的工具需要花费时间和精力来创建,但是最终,它提供的反馈非常值得这些投入。
可观察性
许多 Android 工程师很熟悉 systrace 或 Android Studio 中的某个优秀的 profiler。想象一下,你为端点代码做了类似的跟踪,遍历了许多不同的微服务:这实际上就是分布式跟踪所做的事情。我们的微服务和路由已经集成到 Netflix 请求跟踪基础架构中。我们使用Zipkin消费踪迹,让我们可以按路径搜索踪迹。一个典型的踪迹如下所示:

典型的 zipkin 踪迹(已截断)
对 Netflix 基础架构的成功而言,请求跟踪至关重要,但是当我们用的是单体架构时,是无法深入了解应用程序如何与各种微服务交互的。为了展示它是怎样帮助我们的,我们放大图片的这一部分:

对该服务的序列化调用会增加几毫秒的延迟
在这里很明显,这些调用正在被序列化:但这时,我们已经从微服务断开了大约 10 个跃点。只查看原始数字很难得出结论并发现这类问题:无论是在我们的服务上,还是在上面的testservice上,想要追溯原因到确切的 UI 平台或页面是更难的事情。借助 Netflix 微服务生态系统中丰富的端到端跟踪功能,又有了 Zipkin 这样的轻松访问工具,我们就可以迅速找出这个问题的成因,将其归类给对应的负责团队。
端到端所有权
如前所述,我们的新服务现在在请求的整个生命周期中都拥有“所有权”。以前,我们只将 Java 对象返回给 API 中间件,而现在,服务的最后一步是将 JSON 刷新到请求缓冲区中。
所有权的扩大为我们提供了在这一层轻松测试新优化的能力。例如,经过大约一天的工作,我们就做了一个使用二进制 msgpack 响应格式代替纯 JSON 的应用原型。除了灵活的服务架构之外,这还归功于 Node.js 生态系统和可用 npm 软件包的丰富选项。
本地开发
迁移之前,由于部署缓慢且缺乏本地调试,因此在端点上进行开发和调试是很痛苦的事情(这篇文章对此做了详细介绍)。Android 团队执行这一迁移项目的最大动机之一就是改善这种体验。通过在本地 Docker 实例中运行服务,新的微服务为我们提供了快速部署和调试支持,从而显著提高了生产力。
不太理想的方面
在打破单体的艰难旅程中,你可能会碰到一两个锋利的碎片。接下来要讲的很多事情并不是特定于 Android 的,但是我们想简要介绍一下这些问题,因为它们的确影响了我们的应用。
延迟
旧的 API 服务运行的“机器”上还缓存了许多视频元数据(根据设计)。这意味着静态数据(例如视频标题、说明)可以在多个请求之间积极地缓存和重用。但使用新的微服务时,即使要获取这些缓存的数据也需要网络往返,这会增加一些延迟。
这听起来像是“单体 vs 微服务”的经典案例,但实际情况要复杂一些。从本质上讲,单体还是在与许多下游微服务对话:只不过,这里它恰好具有定制设计的缓存,效果很不错。更好的可观察性和更有效的请求批处理可以缓解某些新增的延迟。但对于一小部分请求,经过大量的优化尝试后,我们只能接受延迟的增加:有时,我们是没有银弹可用的。
增加的部分查询错误
由于对端点的每个调用都可能需要向 API 服务发出多个请求,因此其中一些调用可能会失败,从而给我们留下部分数据。处理此类部分查询错误并不是一个新问题:它已融入 Falcor 或 GraphQL 等复合协议中。但是,当我们将路由处理程序移到新的微服务中时,我们现在获取任何数据时都引入了一个网络边界,如前所述。
这意味着我们现在由于自定义缓存而陷入了以前不可能出现的部分化状态。在迁移开始时,我们还没有完全意识到这个问题:只有在我们的一些反序列化数据对象具有空字段时,我们才意识到它。由于我们的许多代码都使用 Kotlin,因此这些部分数据对象会立刻导致崩溃,这帮助我们及早发现了问题:在问题进入生产环境之前。
由于部分错误的增加,我们不得不从整体上改进错误处理方法,并探索将网络错误的影响最小化的方法。在某些场景下,我们还在端点或客户端代码上添加了自定义重试逻辑。
总结
对 Android 团队来说,这是一段漫长的旅程,也是一段充实的旅程:正如我们前面提到的,我们的团队一般专注于应用本身,之前没有机会深入探索端点到这个程度。通过这个项目,我们不仅了解了微服务世界许多有趣的内容,而且获得了绝佳的机会来为我们的应用-端点交互增加可观察性。同时,我们遇到了一些意外问题,例如部分错误,并在处理它们过程中让我们的应用更具弹性。
在多个后端和前端团队的共同努力下,我们成功完成了这项新服务的规划和迁移工作。
原文链接:




