
概述
RUM 英文全称是 Real User Monitoring,它作用是捕获和分析用户与网站的所有交互细节,旨在提高网站的可用性、提升用户体验。提升网站体验的方式非常多,可以优化数据库、优化接口调用,那为什么要 RUM 呢?主要是 RUM 更直接,更直接的反应了用户如何和你的网站交互细节,通过真实的行为更精准衡量用户满意度。
我们来看看 RUM 跟踪真实的用户行为到什么程度?
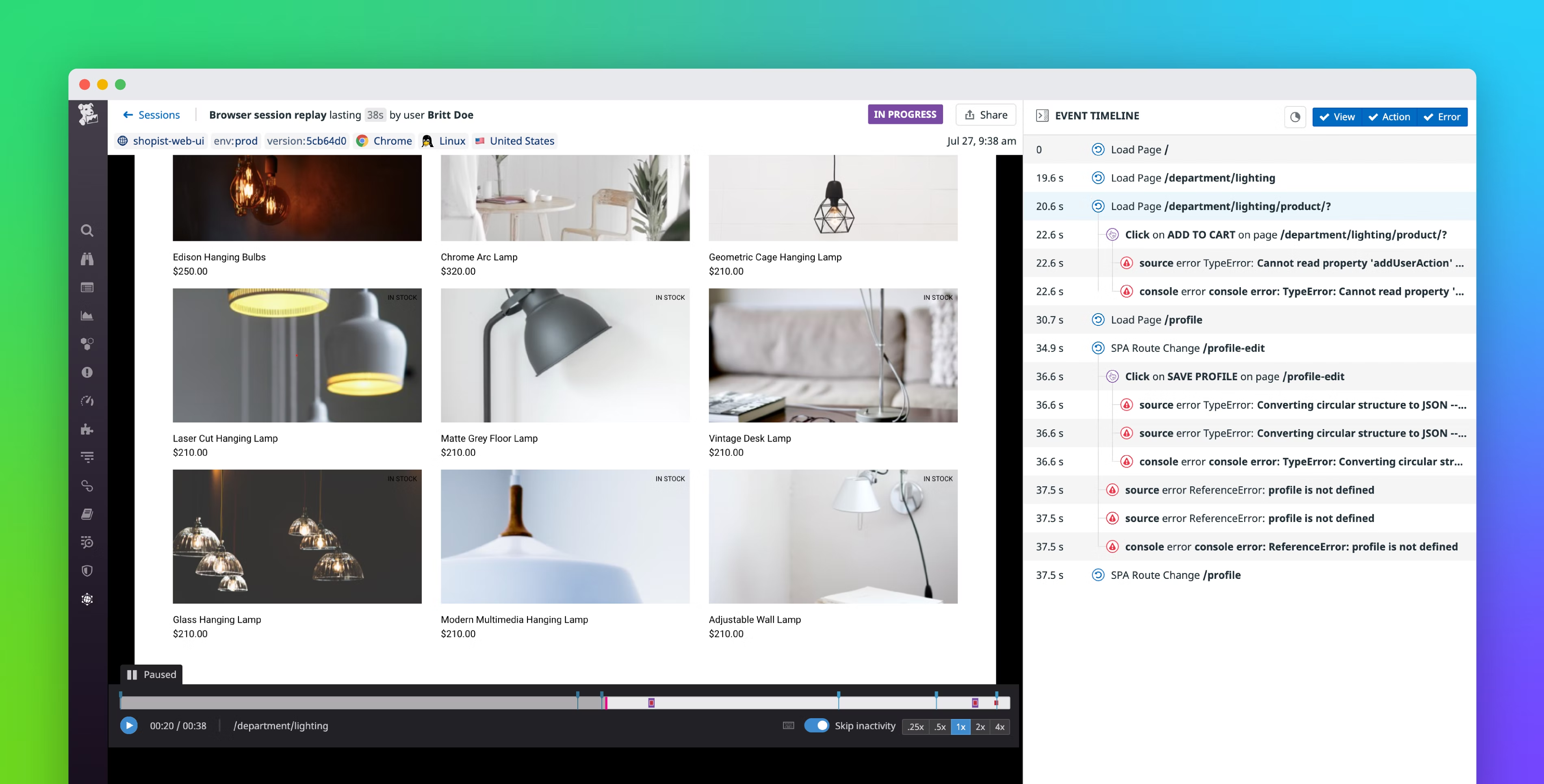
Datadog RUM 对用户行为的精准跟踪
Datadog 有一个 Session Replay 功能,大致原理:通过 UserID 标签采样网站链路数据,然后在后台完整回放用户具体行为:比如先后访问哪些页面,点击了什么按钮或链接。以时间轴方式回放了整个过程。而且,RUM 上还展示出每次交互产生的性能指标和异常报告。这样的功能,是不是觉得很实用?是的,在不需要太多技术门槛,你可以很方便观察起业务系统和用户行为。
具体视频演示,可以访问地址
RUM 可观测性系统的定位
为了方便大家方便理解 RUM、APM、Observability 概念和他们在 IT 系统稳定性保障的定位,我大致梳理了下面这张体系图
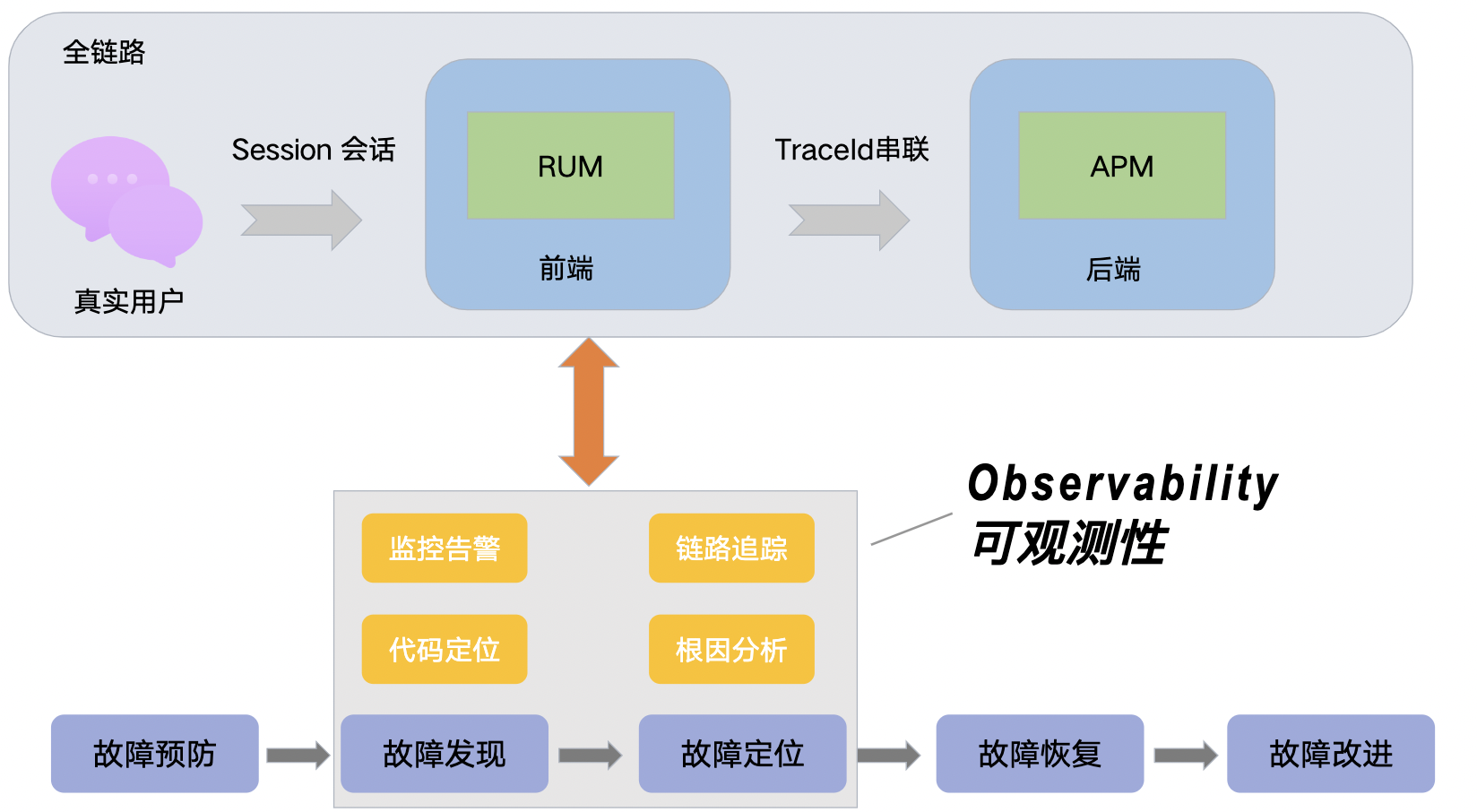
其实,RUM 目前业界定义略有差异:
Datadog、OpenTelemetry 趋向于和 APM 做对比,APM 既然重在后端程序的链路监控。RUM 就主要特指前端网站的用户交互行为,所以常规理解,RUM 就是前端监控
但譬如 New Relic 没有提 RUM ,它针对产品使用对象,区分为 Browser Monitor 和 Mobile Monitor。甚至它提出 RUM 本身属于 APM 的范畴,下面的解释也是可以理解
RUM is a core feature of application performance monitoring (APM).
Real user monitoring is also sometimes known as browser monitoring because the end user experience happens in the browser. While other aspects of application performance monitoring involve measuring server-side performance (the backend), real user monitoring measures client-side performance—the browser where users interact with your application.
因为现在广泛大前端,除了浏览器,还包含移动端小程序、H5,Webfunny、Sentry、腾讯云其它商业产品把对它们的可观性统称前端监控,也并没有过多提 RUM 概念。移动端本质也是用户使用的 Application,所以对 Android、IOS 的终端的监控也是 RUM 范畴也不未过
综上说讲,RUM 无论怎么划分覆盖范围,重点还是在于 Real User ,本文也侧重在网站监控,那么移动端的用户行为监控,本质也是差不多的。
下面演示可观测系统下,RUM 和 APM 配合如何做到全链路方式追踪用户访问
RUM 现状
近几年涌现了许多非常优秀的 RUM 产品,我列举部分如下
除上面提及产品 ,市面上还有譬如:Arms RUM、腾讯云前端监控,Dynatrace。限于篇幅和个人了解程度,本文不做对比。我主要收录的维度:
产品体验:侧重生产环境的 RUM 功能上易用性、实用性;主要介绍 Session Replay、Synthetic Monitor、错误追踪等功能的支持和对比。
用户行为分析:很多 APM 在生产环境中收集链路数据过多,会遇到很多性能问题。特别大型分布式系统中,APM 采样能力、存储能力决定 APM 的靠谱程度;
数据采集能力 Agent:从 Agent 的技术生态、支持组件、开发框架能力。很多公司生产系统在这个维度就已经做了 RUM 的选型了。比如公司使用了 Nodejs 的 RabbitMQ 客户端,只有 Datadog 目前友好支持。或者使用 taro 国内受欢迎小程序搭建框架,还只能国内 Fundebug 来支持。
Source Map 的支持:哪些 RUM 通过 Source Map 技术,实现和如何支持错误代码定位。
SPA 的兼容:SPA 由来介绍,产品上如何兼容 SPA 监控。
全链路能力:RUM 和 APM 联动的支持,同时对全链路监控给出一些产品选型的建议,和产品体验感受。
中国特色个性化定制:微信公众号、小程序,小游戏,支付宝小程序如何做到可观测。
社区和文档支持:产品对应的技术社区成熟度和产品文档的质量;
其它:Crash 上报能力,数字大屏,数据采样能力。限于优先级和本文篇幅,以后可以做更多相关分享,在此不多做介绍;
产品使用体验
性能概览 Performance Overview
Datadog 支持常见的 Real User Monitoring 性能指标采集
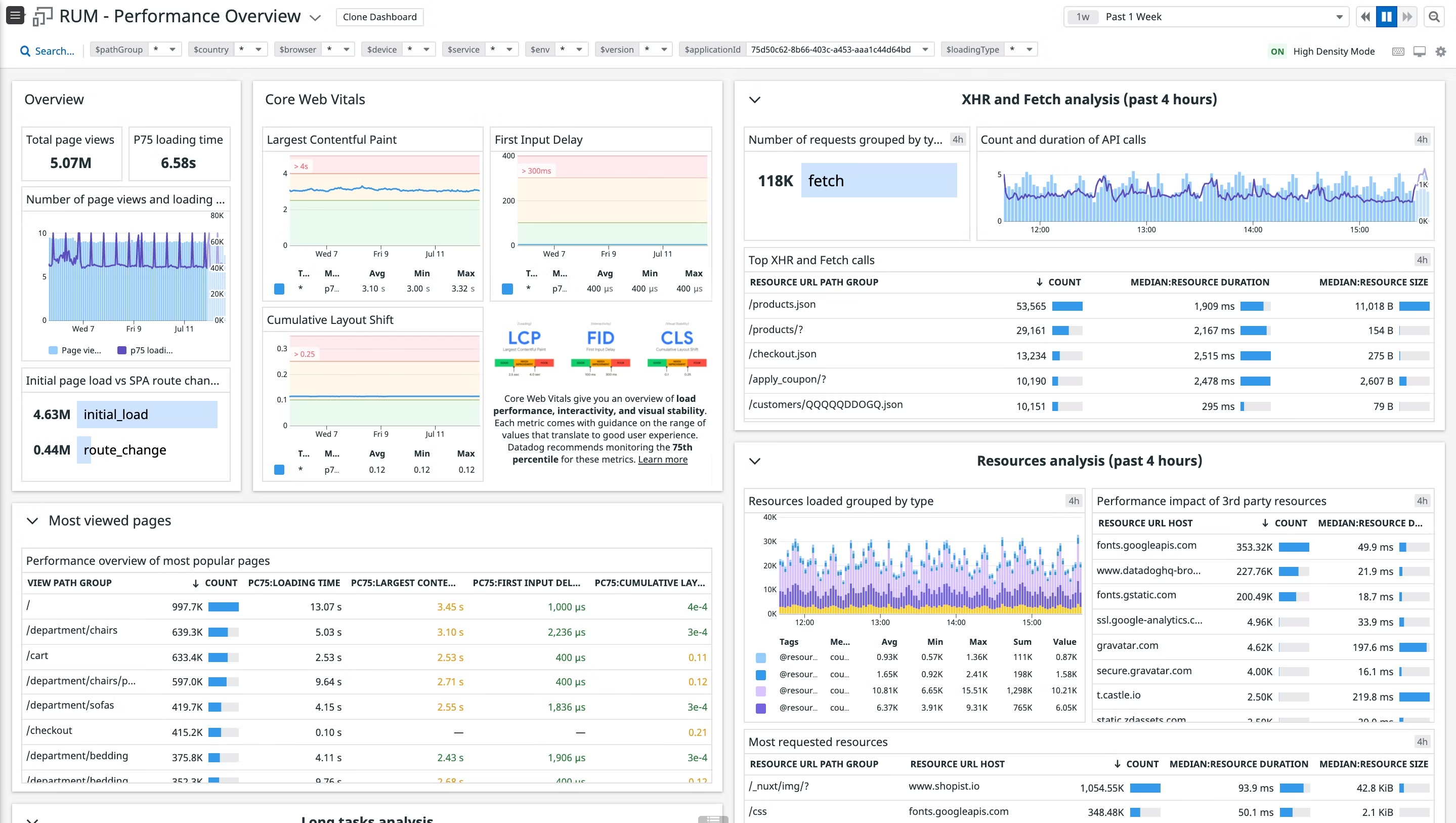
1、Google 网站核心指标(LCP、FID、CLS)
2、Top Visit
统计最常访问页面,还单独将异步 XHR 请求进行统计,对于 web2.0 网站比较友好
3、Resources analysis
总结:界面人性化,指标清晰。而且性能指标的钻取非常方便。同时上面 Tag Search,Time Line 筛选,也是做到了 To C 产品体验,相信经常用的人会感觉得很舒服。
用户会话概览 User Session
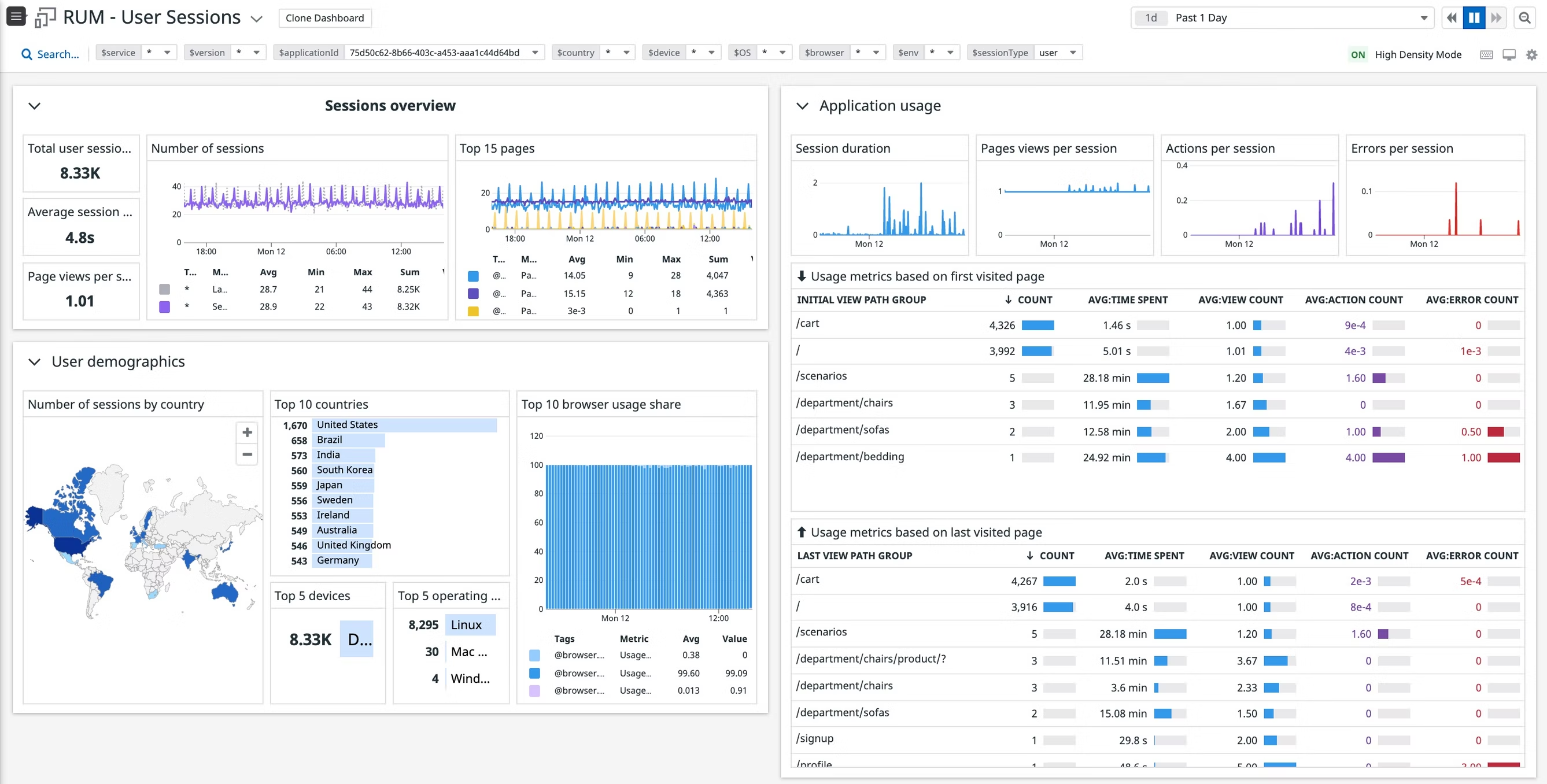
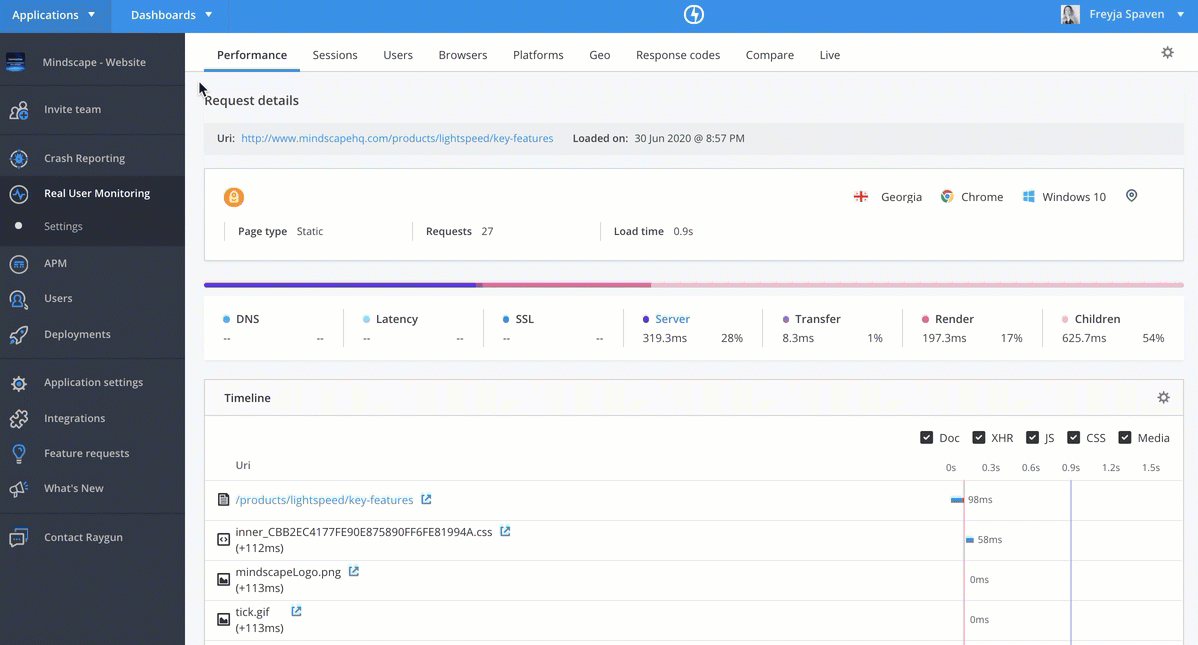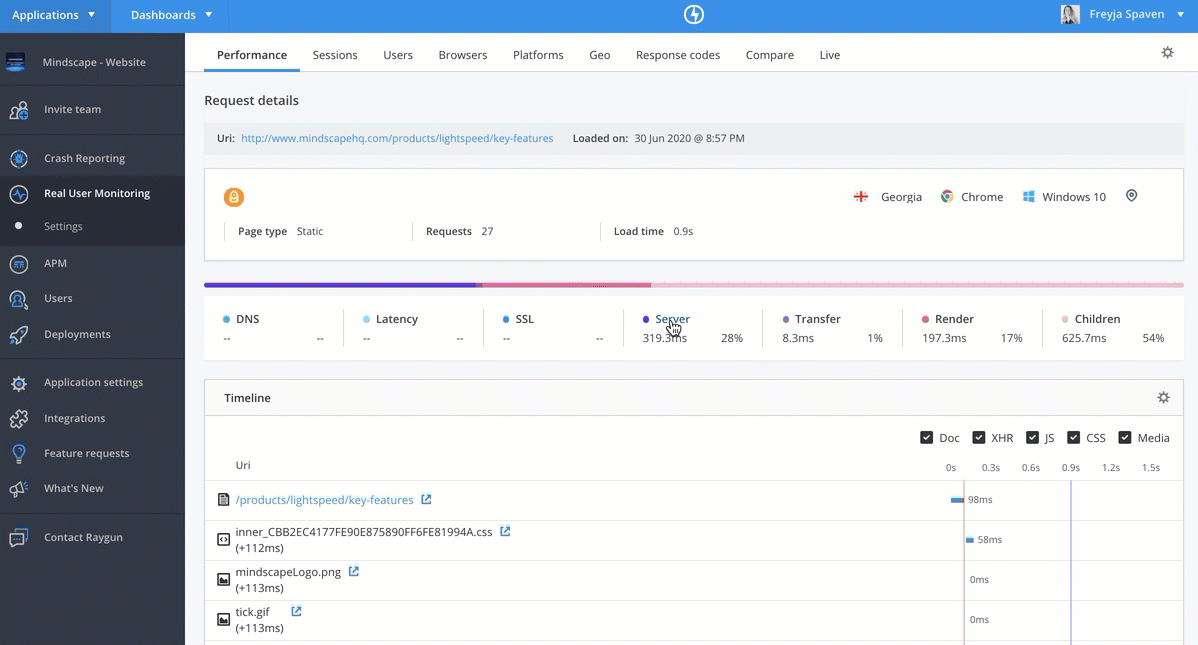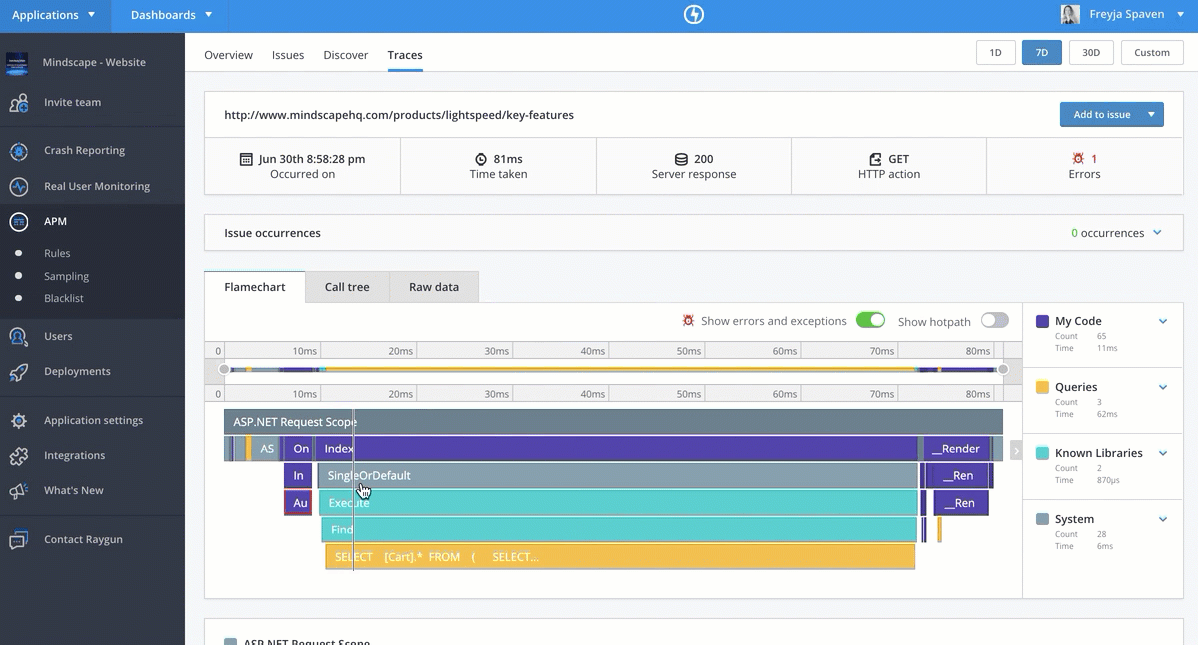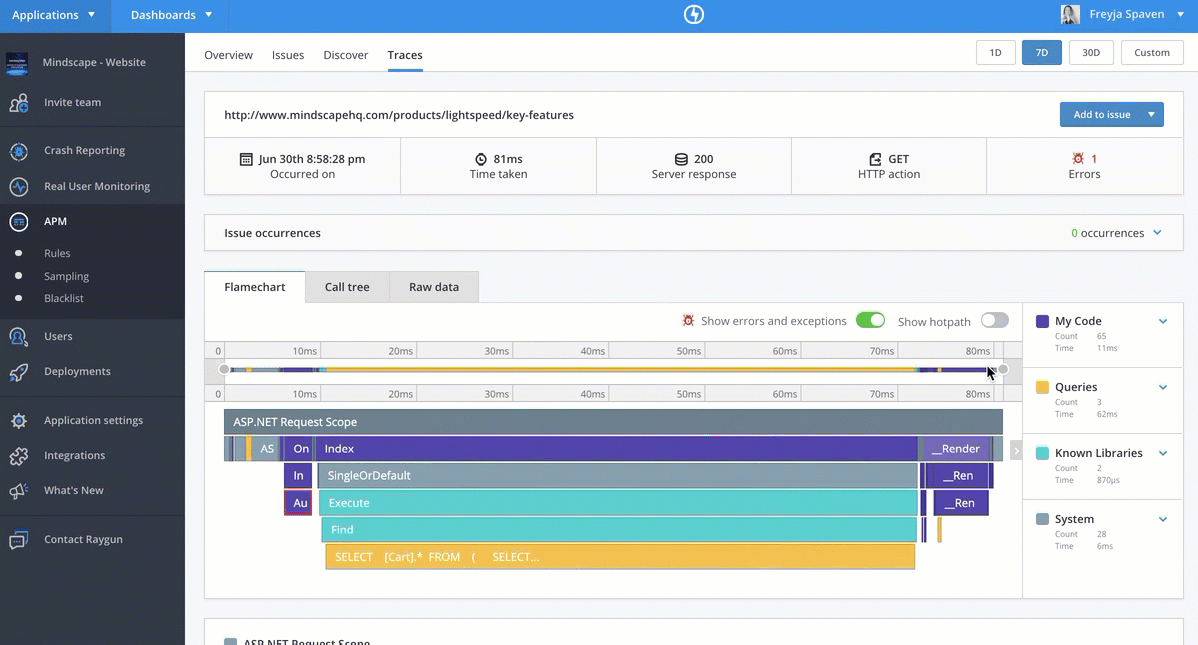
Session Trace
Http Session 会话作为一次用户访问行为。一个用户可能一天当中会有多次 Session 访问
每次 Session 生产一个 Trace,这个 trace 进行跨进程通信,也会传递给 back-end 程序
通过 RUM、APM 关联,我们可以完整看到一个 Session 的后台请求链路信息
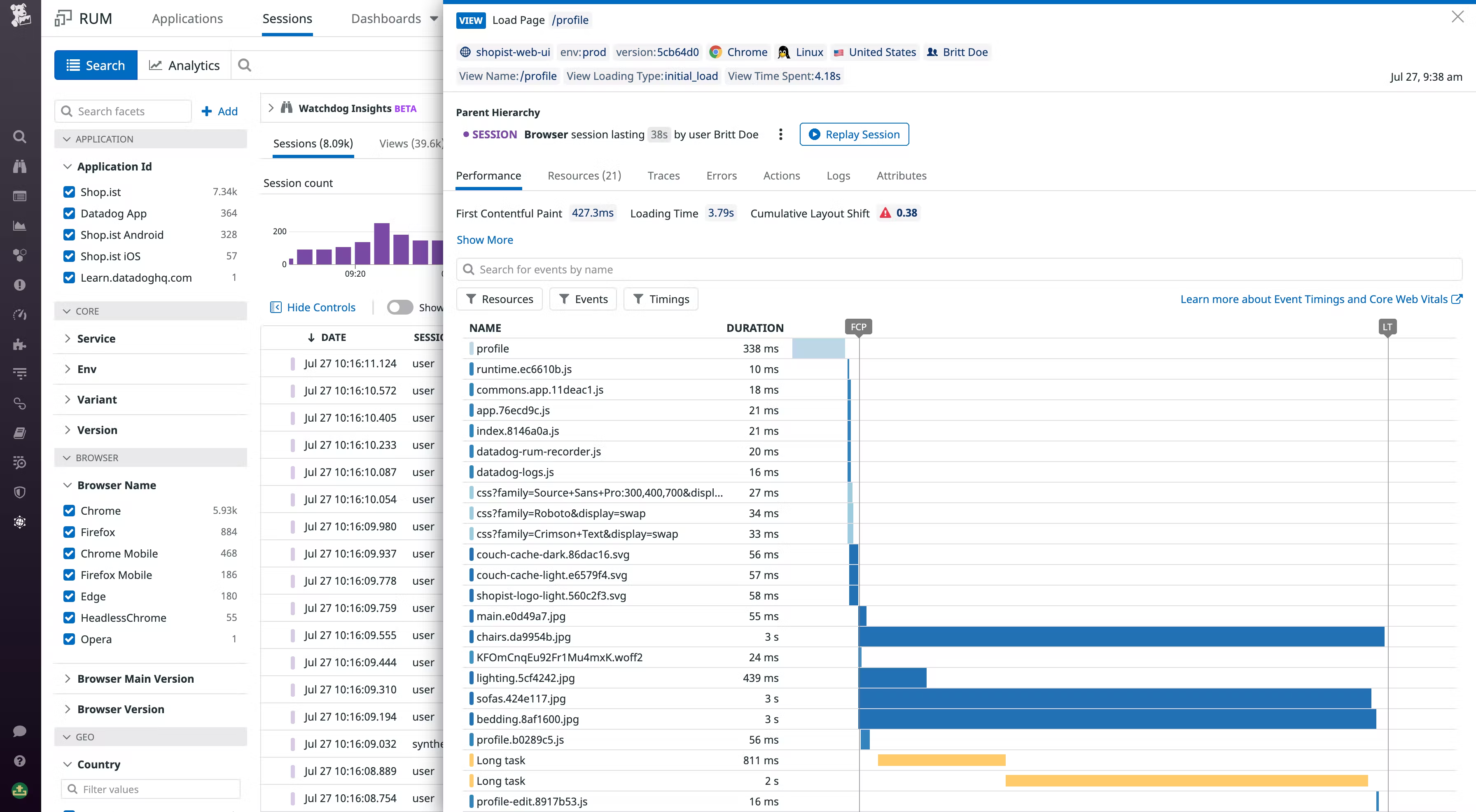
从交互来说,Datadog 链路甘特图展示比较完整,和界面体验非常舒服
Synthetic Monitoring
什么是 Synthetic Monitoring?和 RUM 什么关系
从技术方面来讲,前端性能监控主要分为两种方式,一种叫做合成监控 SYN(Synthetic Monitoring),另一种是真实用户监控 RUM(Real User Monitoring)
合成监控:就是在一个模拟场景里,去提交一个需要做性能审计的页面,通过一系列的工具、规则去运行你的页面,提取一些性能指标,得出一个审计报告
SYN 中比较流行的是 Google 的 Lighthouse
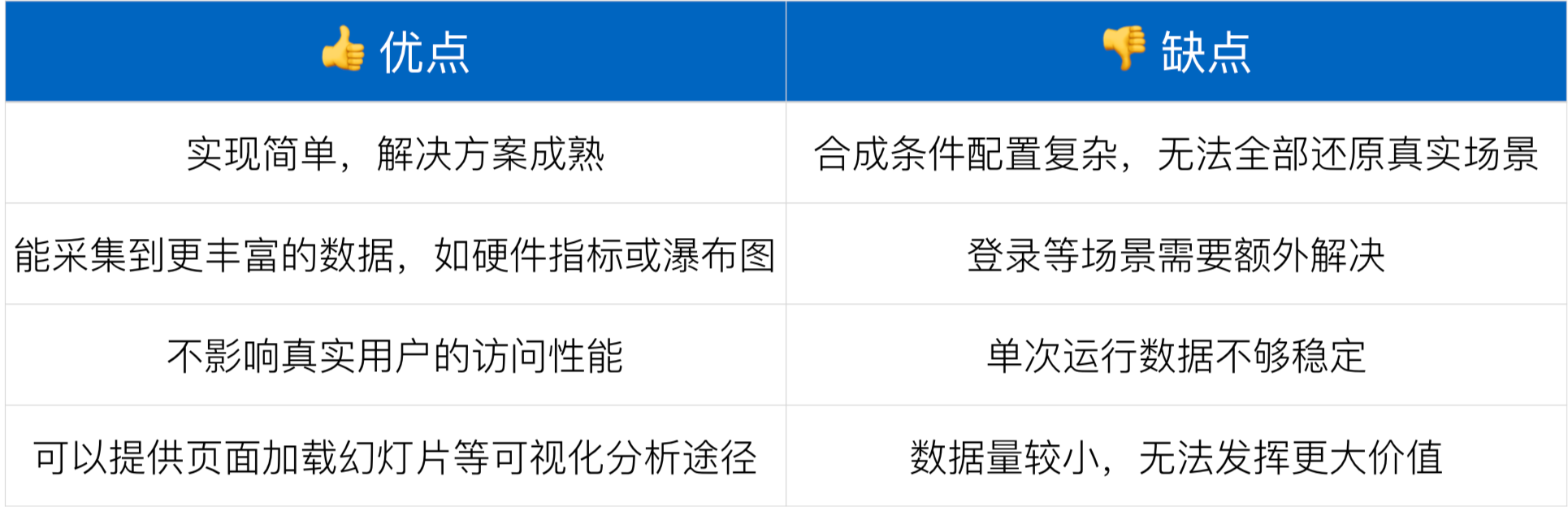
合成监控的优缺点
我们通过下表总结,来看看合成监控的优缺点
Analyze the root cause of load time spikes with rich waterfall reports on an element level 通过丰富的 DOM 瀑布流报告分析负载时间峰值的根本原因
总结:核心性能指标对用户体验影响比较大,比如提到的 Google 网站性能指标 LCP、FID、CLS。RUM 系统都支持自带 Synthetic Monitoring 功能,尤其 Uptrends 提供的最详尽,你想得到的它都给你支持了
Uptrends Synthetic Monitoring 工具库
用户行为回放 Session Replay
基于一次 HTTP Session 回话,通过记录 Page Event,将每次 DOM 的渲染记录下来,从而达到记录用户交互行为。目前,Datadog、Fundebug 都支持类似功能。他们底层核心都基于开源框架技术,叫做 rrweb,一种非常受欢迎用来记录和回放 Web 中用户行为的开源项目
我们简单看看 Datadog 关于 Session Replay 的描述
On the Datadog replay view, the page is rebuilt and the recorded events are re-applied at the right time.
The browser SDK is open source and leverages the open source project rrweb.
从 Replay 的功能体验来说,Datadog 产品功能体验最好的。
Session Replay 的作用:
1、定制化分析用户行为轨迹:比如一个分布式电商系统,我们可以通过一个 User 的访问活动 Session,看到它具体这次访问哪些页面,如何交互,对于调用了哪些后台接口,一目了然
2、方便跟踪具体的异常:因为没有完善可观测系统,过去在故障定位中,往往从请求端一个个系统做排查,这样效率比较低下。而且,有些复杂故障可能由不同条件触发,某些交互行为正常,某些情况下才出现异常。这就导致线上排查难度极大:测试如果回归不到触发条件,很难复现问题,让故障定位和排查时间,人力成本急剧上升。
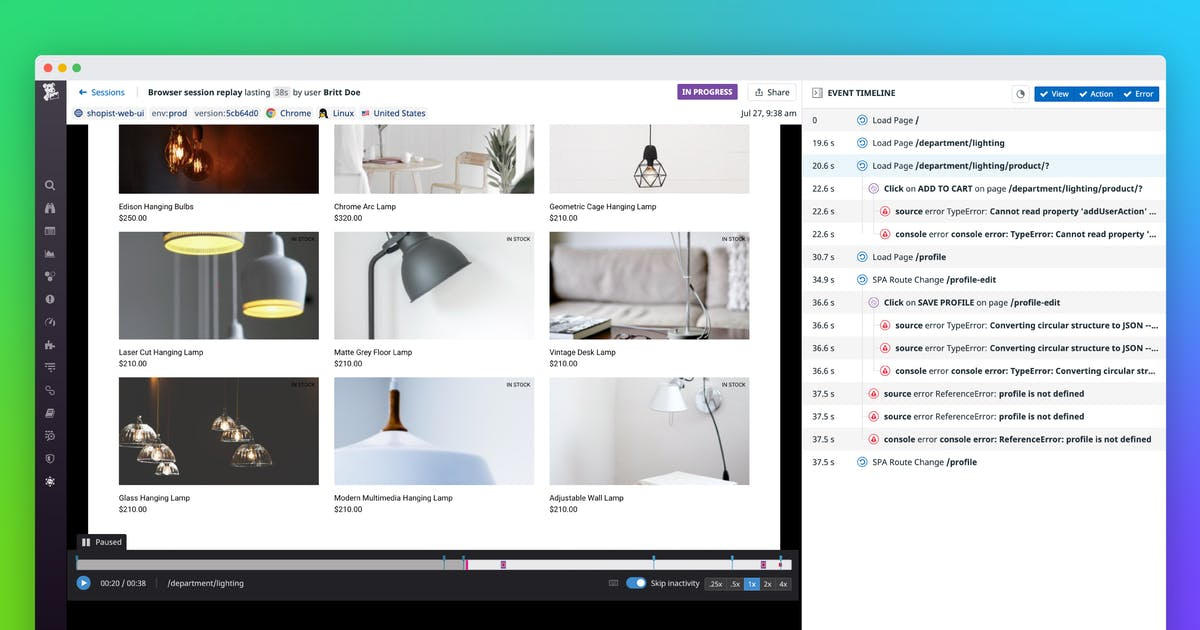
Session Replay 回放用户访问电商网站行为
甚至,线上业务系统过于复杂导致短期无法定位问题!这是真实存在的。
总结:Session Replay 是一个非常实用的功能,也体现了可观性的价值:真正观察用户行为,配合 APM 得到完整用户访问的全链路信息,基于此,对于故障的根因分析和定位,提供根本性的解决方案
错误追踪和 Crash 上报
错误追踪,RUM 主要指 Js 错误汇总和错误展示。Crash 上报,一般都是通过 SDK 方式集成。
区别在于 Saas 和私有化部署需不需要走外网的网络差异。
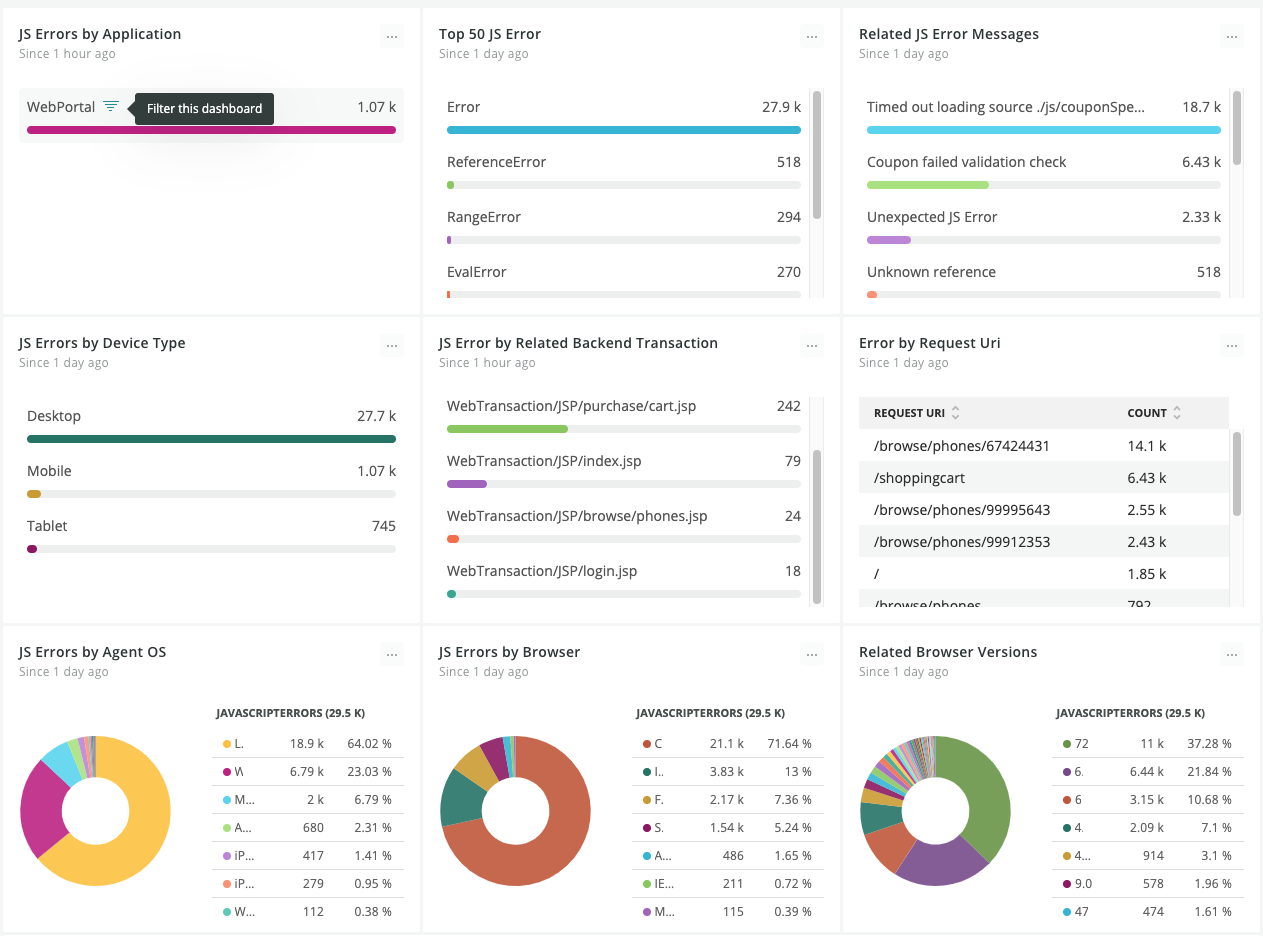
各个 RUM 错误追踪功能,从产品功能布局,展示上有不同差异,基本上核心统计指标都有。
从细节和功能适用度,能看出简陋和丰富的区别。Datadog、Sentry 更强,主要从几个方面:
1、Sentry 在 Error Track 统计专业、应用: 易用统计大屏,清晰从 Project 维度拆解 Error 统计,很方便让对于系统的研发团队跟踪,统计问题。而且,Erorr Track 支持逐级钻取数据,通过集成 Sourcemap 功能,直到看到错误源代码。
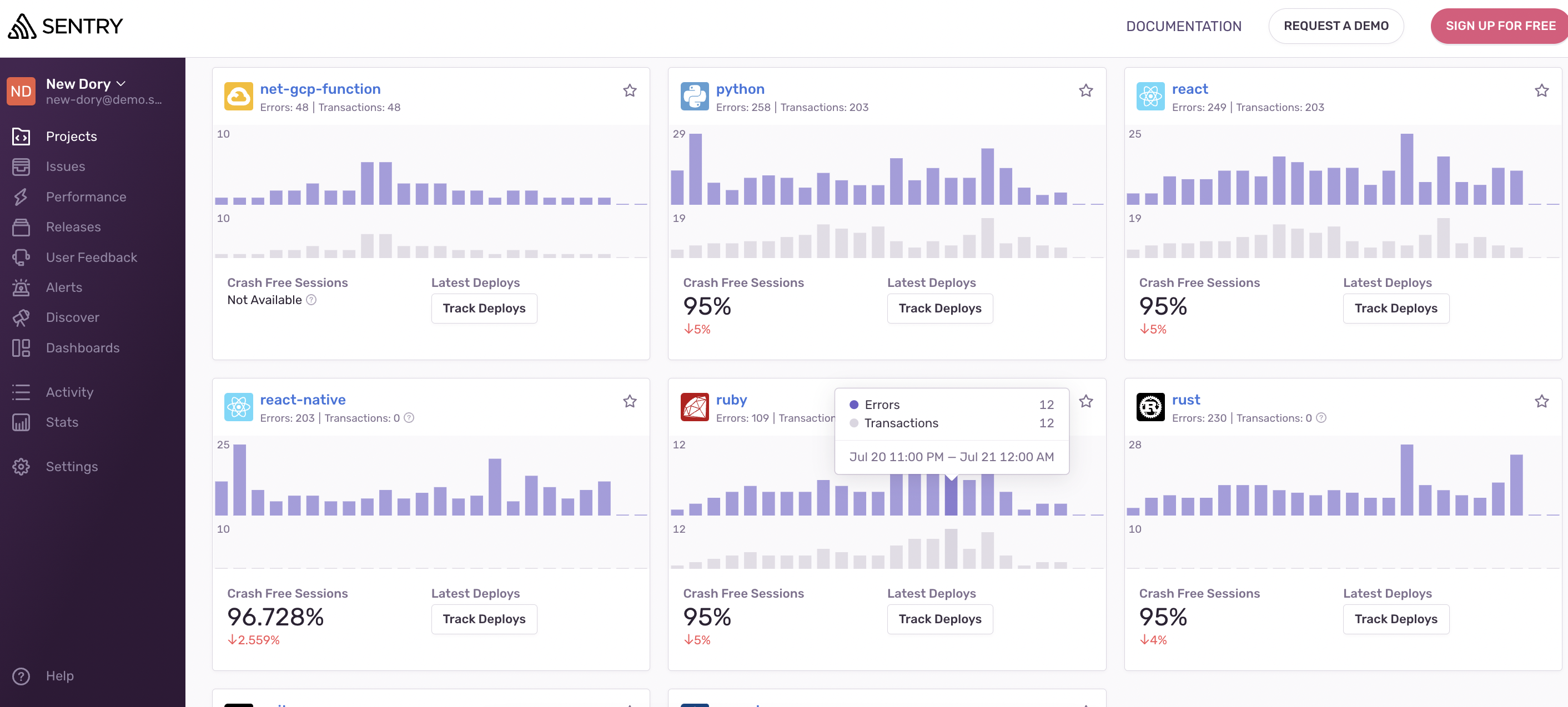
2、Datadog、Sentry 还支持 Error Issue 功能:对于要修复的 Error ,在平台直接管理 Issue :1)、支持更新 Error 的状态,有 Erorr 用户影响面汇总统计,帮助决策优先级;2)、可以指派 Error 修复人 Sponsor,类似于 Jira 进行基本 bug 生命周期管理,支持消息推送
总结:Sentry 在错误追踪和上报做的非常专业,甚至说最好的。这和它本身的产品定位有很大基因关系,它重心就是“”。
SourceMap 技术
什么是 Source Map
通俗的来说,Source Map 就是一个信息文件,里面存储了代码打包转换后的位置信息,实质是一个 json 描述文件,维护了打包前后的代码映射关系
Source Map 的价值
随着前端项目结构化发展,代码越来越庞大和复杂。大部分源码(各种函数库、框架)都要经过转换,才能投入生产环境
常见的源码转换,主要有这样一些场景需要
压缩,减小体积
多个文件合并,减少 HTTP 请求数
其他语言编译成 JavaScript
这些场景,都使得实际运行的代码不同于开发代码,调试代码变得困难重重 Source Map 在即使打包过后的代码,也可以找到具体的报错位置,这使得我们 debug 代码变得轻松简单,这就是 Source Map 想要解决的问题
Source Map 演化史
2009 年 Google 在介绍 `Cloure Compiler` 时, `Google` 也趁便推出了一款调试东西: `Firefox` 插件 `Closure Inspector` ,以便利调试编译后代码
2010 年,在第二代即 `Closure Compiler Source Map 2.0` 中,Source Map 以 `JSON` 格式作为标准, `mapping` 算法运用 `base 64` 编码
2011 年,第三代 Source Map
https://docs.google.com/document/d/1U1RGAehQwRypUTovF1KRlpiOFze0b-_2gc6fAH0KY0k/edit#
它脱离 `Clousre Compiler` ,演化成了一款独立东西,也得到了浏览器的支撑。这一版最大的改动是 `mapping` 算法的紧缩换代,运用[VLQ] 编码生成[base64] 大大缩小了.map 文件的体积
Source Map 的工作原理
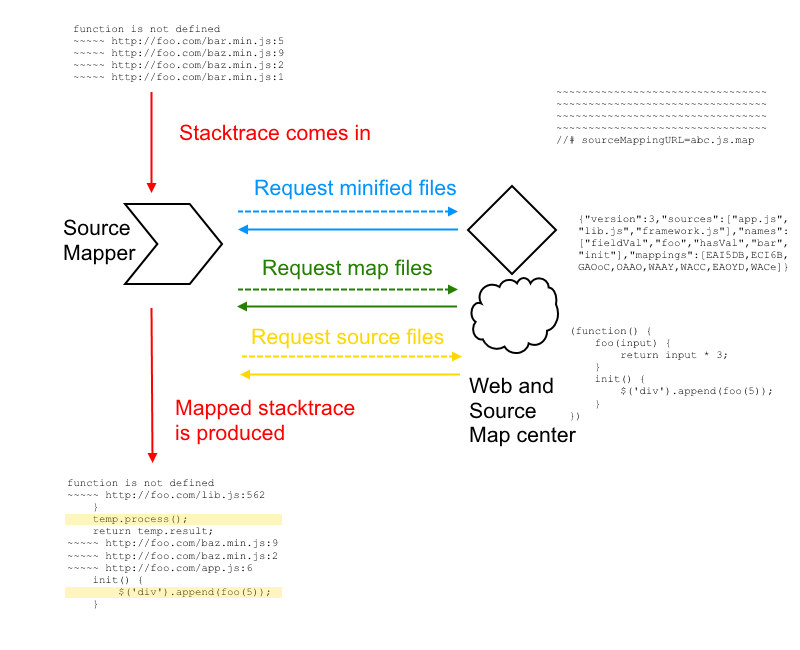
核心数据结构
通过.map 的 Json 文件描述代码映射关系,包含了以下一些信息:
version:sourcemap 版本(最新 v3)
file:转换后的文件名
sourceRoot:转换前的文件所在的目录。如果与转换前的文件在同一目录,该项为空
sources:转换前的文件。该项是一个数组,表示可能存在多个文件合并
names:转换前的所有变量名和属性名
mappings:记录位置信息的字符串
mappings 信息是关键,它使用 Base64 VLQ 编码,包含了源代码与生成代码的位置映射信息。mappings 的编码原理详解有兴趣可以参考
http://www.ruanyifeng.com/blog/2013/01/javascript_source_map.html
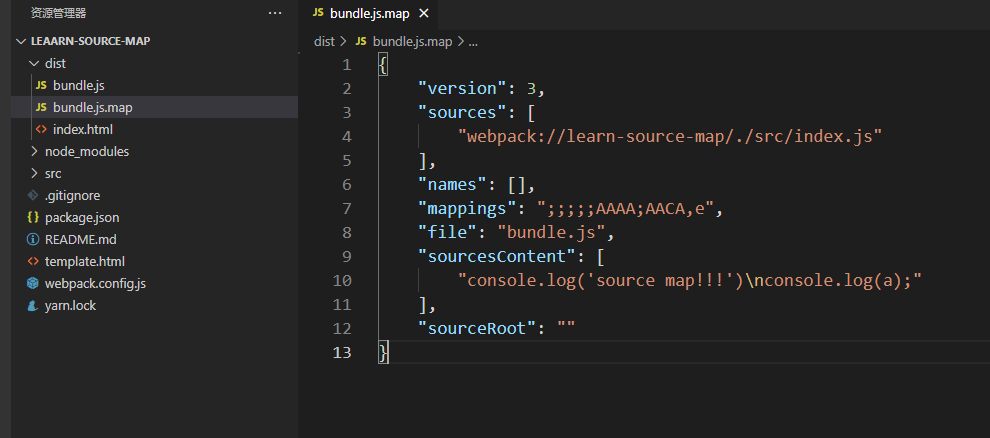
Source Map 的源文件
Source Map 进行 Bug 诊断
有了它支持,我们在链路异常信息中,快速定位到错误代码,当然前提源文件上传 Source Map
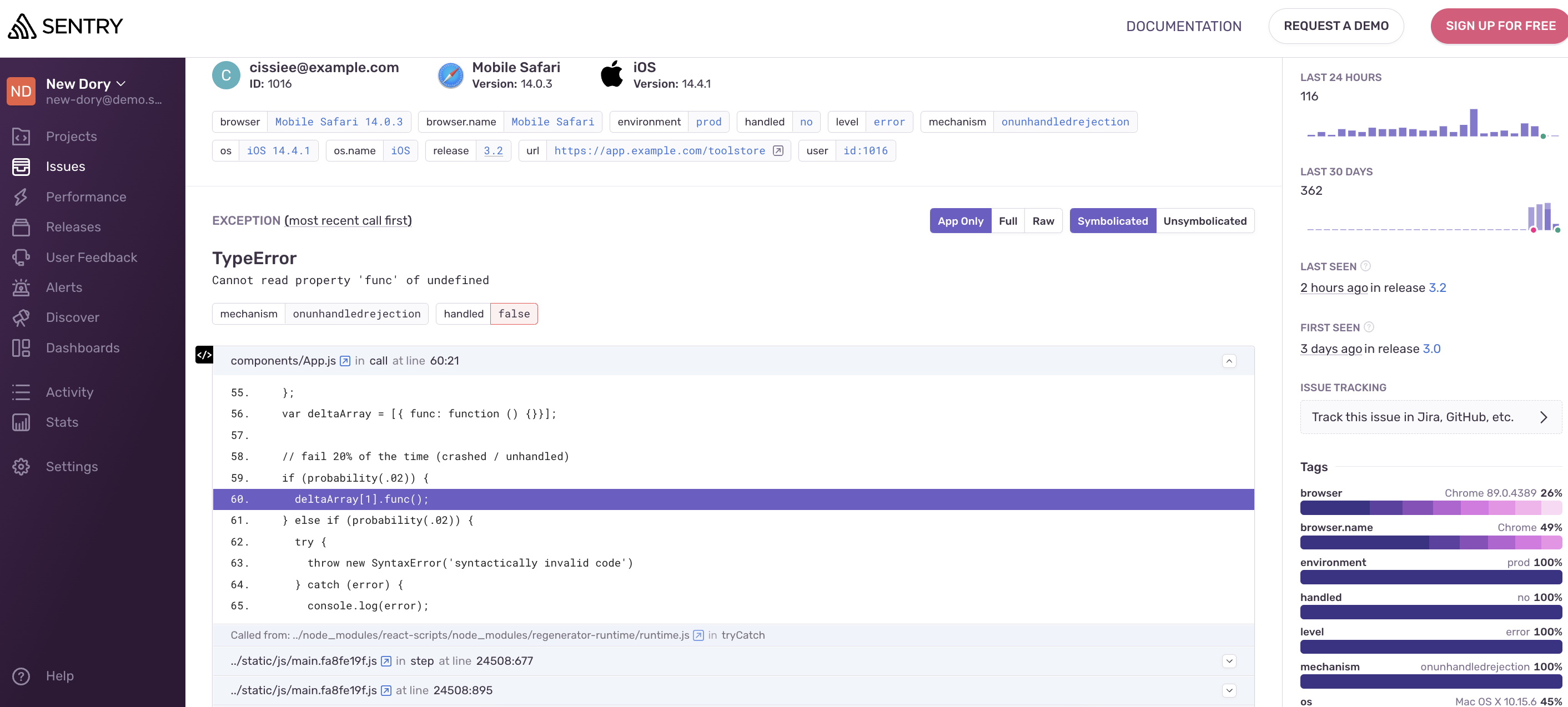
如何上传 Source Map
RUM 提供了以下常见 Sourcemap 支持方式
Fundebug 还支持前端 UI 上传 Source Map
如果你是希望多 Source Map 原理和配置了解更多,推荐可以看看 Fundebug 中文文档
总结:当然,Source Map 虽然很好,但是如果 RUM 是 Saas 或者非私有化部署,是否考虑代码完全性问题,Sentry 和 Fundebug 也都做了一些安全支持。
比如 Sentry 支持在相应的 Project 设置 Security Token,如果外网访问 Source Map ,都必须提供 X-Sentry-Token ,当然 Sentry 控制台请求时,自动带上这个 Security Token
GET /assets/bundle.min.jsX-Sentry-Token: {token}相比 Fundebug,就处理简单一些:通过修改网页服务器或者代理服务器的配置,仅允许 Fundebug 下载 Source Map 文件即可。这种扩展性就比较差,配置也比较麻烦,而且还要看组件支不支持。例如项目使用 Nginx 作为代理服务器
在 Nginx 配置文件中新增 location 模块,使用正则表达式匹配 .map 文件。其中/dist/为 Source Map 文件所在目录路径
location ~ ^/dist/(.+)\.map$ { allow 120.77.45.162; allow 120.79.16.115; deny all; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $remote_addr; proxy_set_header Host $host; proxy_pass http://192.168.59.225:8000; }数据采集能力 Agent
New Relic
3 个月左右做一次更新频率
Added NetworkInformation attributes to LCP & FI. January 6, 2022
Agent 数据采集支持了很广泛的 JS 框架:React、Angular、AngularJS、Backbone、Ember
、Vue、Meteor、Zepto、Jquery 等
Fundebug
半年做一次更新
Datadog
datadog Agent 探针都做了开源,而且迭代速度非常快。几乎半个月一个版本,主要迭代目标是为了支持更多的组件和框架
简单看看它一次典型更新到底做了什么,比如 2022-06-09 更新:
Bug Fixes
koa: fix middleware overwriting route of actual route
aws-sdk: fix
completeevent running in wrong async contextImprovements
http: report the
User-Agentheader inhttp.useragenttag by default in web tracesmysql: add support to dynamically set
serviceinmysqlandmysql2plugins
修复 NodeJs 的 Koa 框架,亚马逊云 SDK 集成 Bug
支持 Mysql 插件里动态设置 Service 属性
amqplib: fix incorrect
thisreference when the plugin is disabledelasticsearch: fix elasticsearch plugin re-normalizing its configuration on every query
RUM 支持 elasticsearch 搜索插件、NodeJs 的 MQ 中间件 Rabbitmq 插件
可以看到,Datadog Agent 支持组件非常丰富和广泛,远远超过其他 RUM 平台能覆盖前端组件范围,这是 Datadog 全世界广泛客户群的一个重要原因吧
OpenTelemetry
另外思路:专注于数据采集,尽量兼容和支持广泛的组件和主流框架,这一点不限于 RUM,包括 APM、NPM 等等核心可观测模块
本地核心库:
半个月更新一次
第三方插件库:生态内开源组织和商业平台主动贡献
阿里云、亚马逊云都来拥抱生态,贡献平台级组件库
https://github.com/open-telemetry/opentelemetry-js-contrib/releases
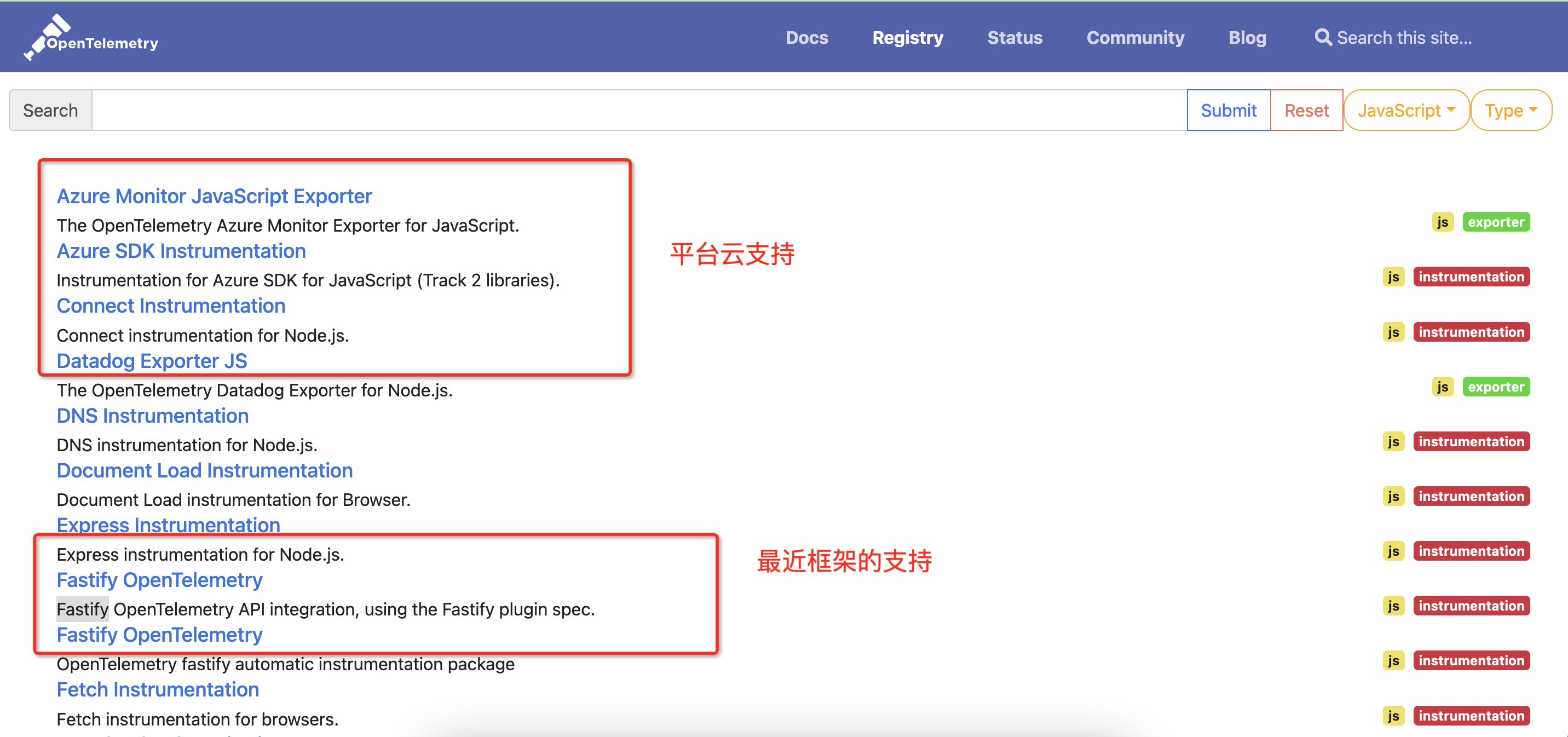
非常强大、丰富的组件查询库,我们可以简单看看哪些 RUM 组件目前 OpenTelemetry 在贡献
https://opentelemetry.io/registry/?s=&component=&language=js
监控告警能力
https://docs.datadoghq.com/monitors/create/types/real_user_monitoring/#overview
告警类型
基于 RUM 时间 event 一定时间内触发前端事件统计
基于 facet :facet 指的特别 Tag 标签,比如浏览器类型,服务器环境(env),只要是能筛选出来的 Tag,都可以基础之上进行 count ,做报警阈值
基于度量的监控: 筛选存在的 Facet 标签属性值,给定一定阈值进行预警触达。为此,提供常见的度量范围:(min, avg, sum, median, pc75, pc90, pc95, pc98, pc99, or max).
报警方式
亮点:Fundebug 本土化,支持报警消息源比较多,还支持自定义 Webhook 送达

用户行为分析
埋点能力 RUM Event
SDK 探针发布,用户可以根据自己的需求,创建不同的埋点,选择不同的图形在数据看板中来展示分析数据。
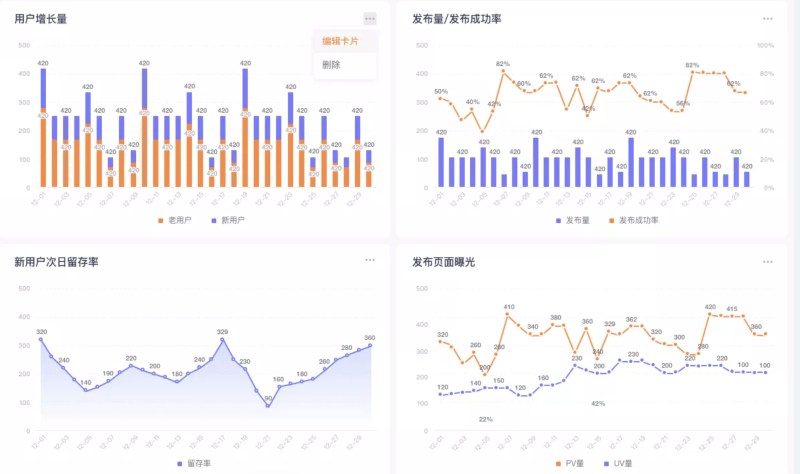
数据大屏,和 RUM 非常用价值的漏洞模型。这块相对来说,独立第三方 RUM 做得比较通用,比如 Webfunny,它还支持项目、团队、分组的管理,这让 RUM 用户分析在业务系统分析更加清晰
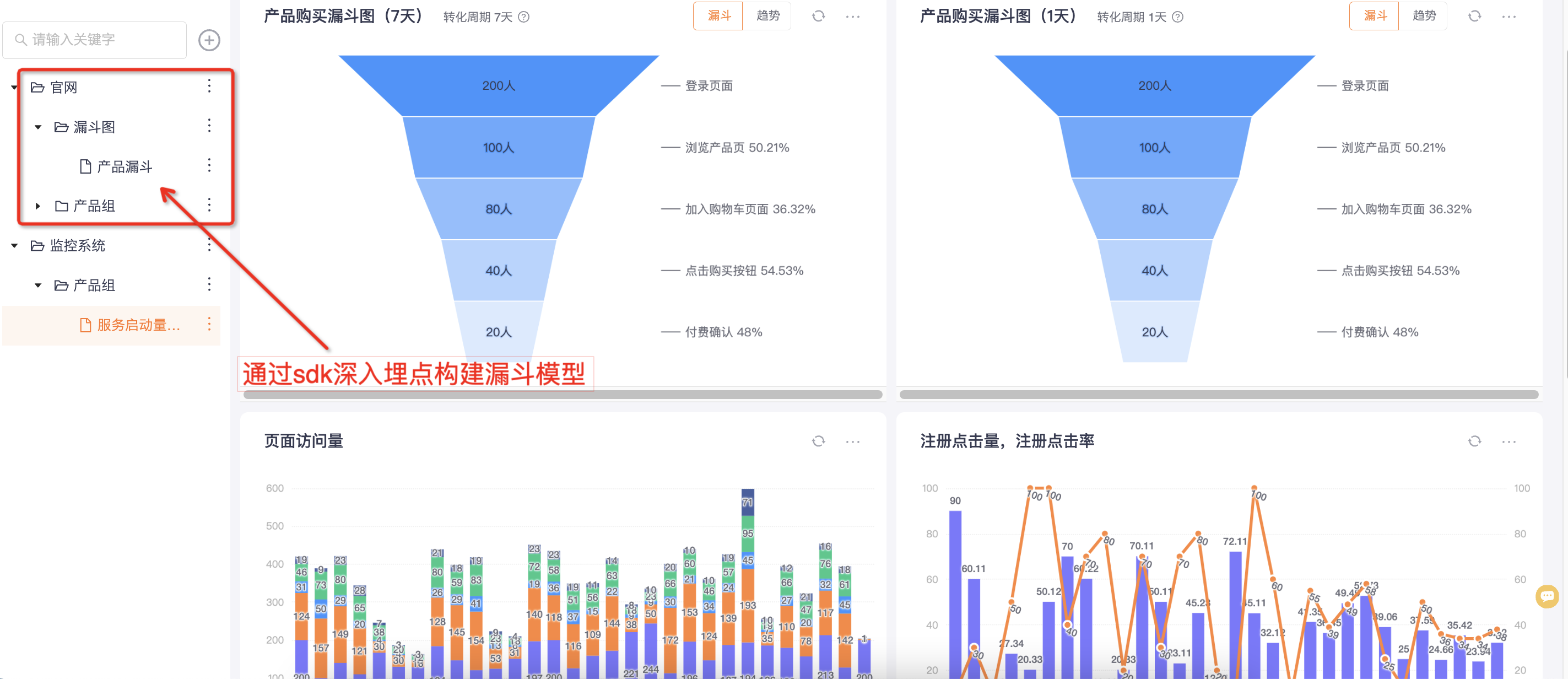
创建点位字段--创建点位--创建 SDK--创建项目--创建卡片--引入探针--分析数据
Webfunny 添加探针 SDK 文件,作为资源文件引入
<script src="xxxxx/sdk.js"></script>在脚本 SDK 中,添加点位值事件监控
//测试数据 const data = { age: 20, name: '张三'}//数据上报, 其中10 表示点位值 _webfunnyEvent[10].trackEvent(data);Webfunny 添加曝光和点击埋点
<!--曝光埋点--><li _webfunny-eo='{"pointId":10, "Doratest":"adwq", "name": "hahaha"}'>我是曝光埋点示例</li><!--点击埋点--><li _webfunny-ce='{"pointId":11, "Doratest":"adwq", "name": "hahaha"}'>我是点击埋点示例</li>RUM Visualize
转化漏斗:Funnel 功能
Datadog 支持动态的组合 View,生成想要的漏斗转化模型,对于数据分析非常的实用和强大
https://docs.datadoghq.com/real_user_monitoring/explorer/visualize/#timeseries
比如,下面例子,把用户端到端的接口访问以工作流方式平铺展开,统计各个阶段访问频率,
完成一个业务系统的访问漏斗,同时 Datadog 自动计算了中间各个阶段的转化率
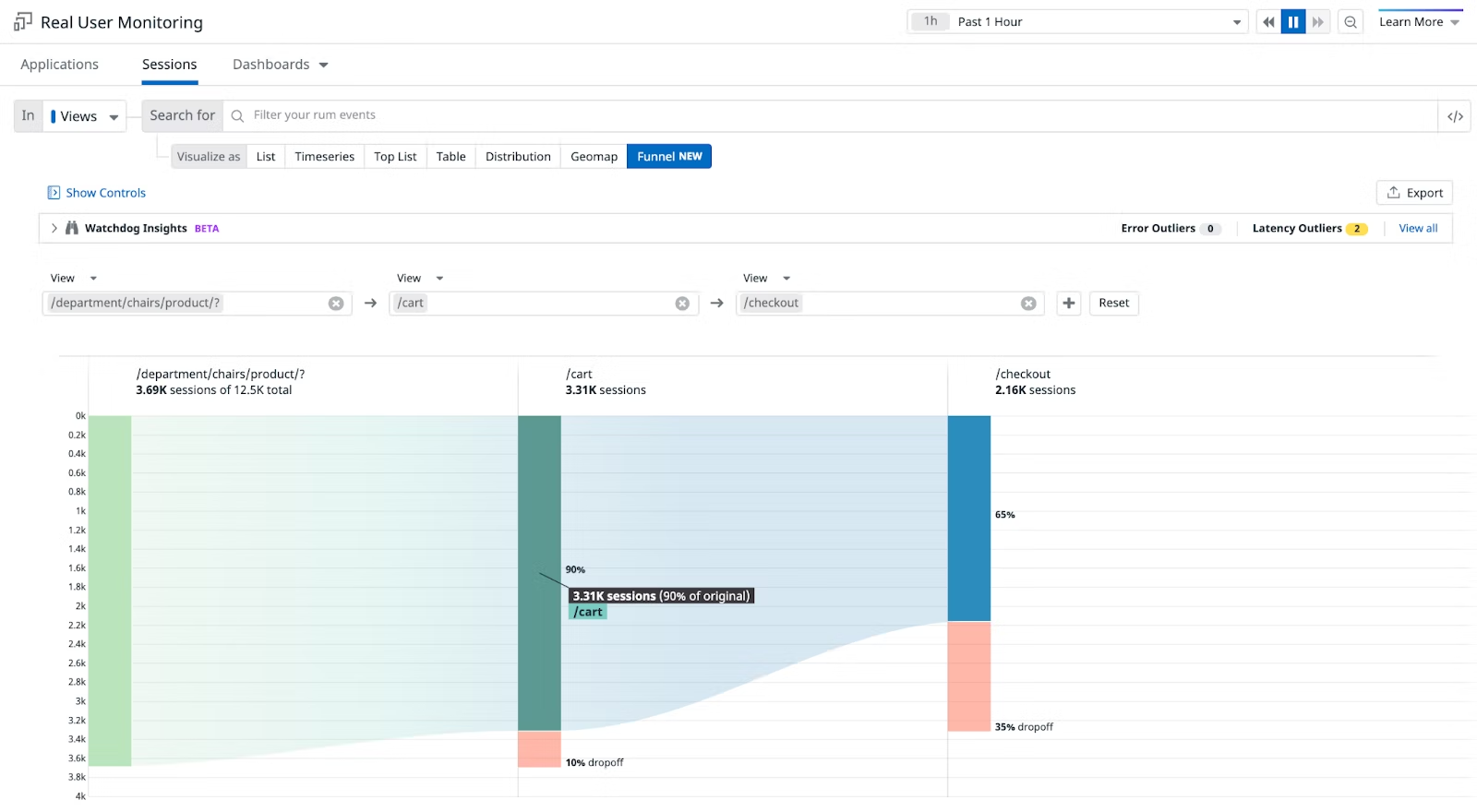
Datadog 灵活生成的漏斗模型
强大的扩展性 Facet 和 View
在 RUM 各个产品都会生成自己一定特色的数据大屏,这个没有绝对谁出的数据更好结论。
一方面,大家最关心数据视图,一般多少有不同视图支持
另一方面,更看中视图是否可以动态配置,满足个性化需求。就像上面 Datadog 的漏斗模型,
需要平台支持数据模型底层的扩展性,让数据大屏可以动态配置,生成想要的数据视图。这里,就不深入扩展,只重点提交 Datadog 这方面数据模型设计是很强的:
通过通用的 Facet 标签、Measure 度量组合成不同的 View,进而展示出丰富的 Funnel 、Timeseries、Distributions 等等数据视图
Timeseries 时序图:给定时间周期,可视化关心性能指标,支持 Facet 筛选
Distributions 分布图:给定度量范围,统计某些性能指标的分布范围,支持 Facet 筛选
产品选型
Case By Case 不按场景选型,都是无意义。
是否需要全链路监控能力?
常规的 RUM 功能来说,Fundebug、uptrends 并不比商业平台 Datadog、New Relic 弱,相反在某些功能上还要比他们做得更细、支持更多。比如 Uptrends 提供很多 RUM 实用小工具
这里面非常清晰认知了,既然 Fundebug、uptrends 产品专注定位在 RUM,如果你只是想要做一些前端监控,并不需要了解 APM 功能,那你就是他们的精准客户。比如他们典型客户往往:
1、前端团队:开发调试,故障定位,一定程序用户交互行为分析
2、一些只偏重前端业务的系统,比如 h5 小程序、Web 小游戏等
当然,越复杂业务系统往往后端服务越重要。再加上如今的微服务、容器化普及,单单 APM 系统只能窥见业务系统冰上一角,而且很难感知用户行为。一旦系统出现问题,如何定位故障在哪里?到底该看 APM 还是 RUM?因此,做到全链路可追溯就太重要了
自己试用,不能只看 PPT 和 Demo 演示
很多可观性功能,使用结合自己项目部署验证,这里面坑比较多。很难靠前期设想就能够满足场景,比如说考虑重点两个维度
1、是否 RUM 能完整覆盖业务系统所有组件和框架,这是前期极其容易掉坑环节,如果选型对自己系统框架不去完整做确认,上了以后才发现不支持是很头疼的问题
2、针对业务系统可能得性能环节,要求对客观性系统做适当压测验证,这种东西 PPT 和文档是看不出来的
全链路监控能力
Fundebug、Webfunny 本身产品定位,专注 RUM,不支持全链路功能。
Sentry 这样产品,虽然也有 APM 探针,但是产品更侧重 Error Track,产品并没有支持全链路异常分析,各种异常分布在 Project 分开管理。
Datadog、New Relic 本身商业化可观性平台,对全链路支持越来越多,以后优先级越来越高
RUM 和 APM 的联动
Datadog 下 RUM、APM 联动,我们可以很清晰看到前端 Web App 、后端服务 Back Services 的消耗时间占比,RUM 入口通过查看"Traces",很方便看到完整全链路概况。
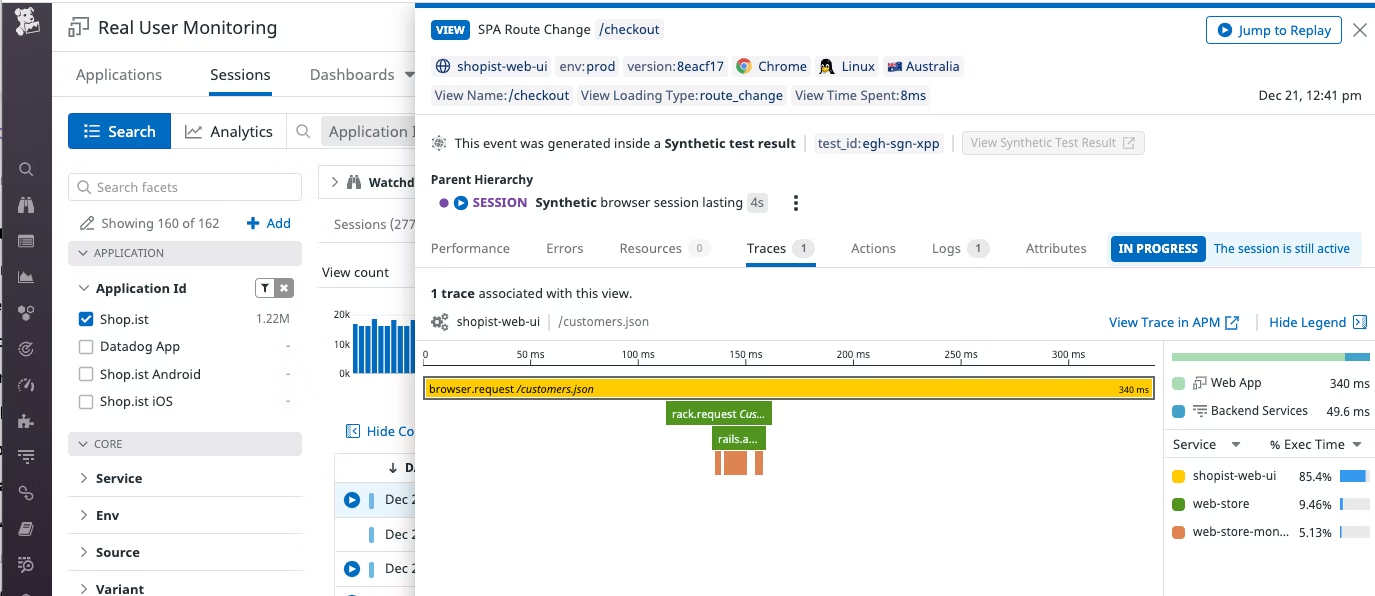
通过"Jump to Replay",我们还可以复现用户整个访问行为。
通过 RUM 和 APM 的联动,实质通过链路的 Span 关系,关联前、后端视图,达到整个系统可观性的初衷
Correlate data collected in front end views with trace and spans on the back
Datadog 中 RUM 通过 SDK 方式关联 APM 系统实例
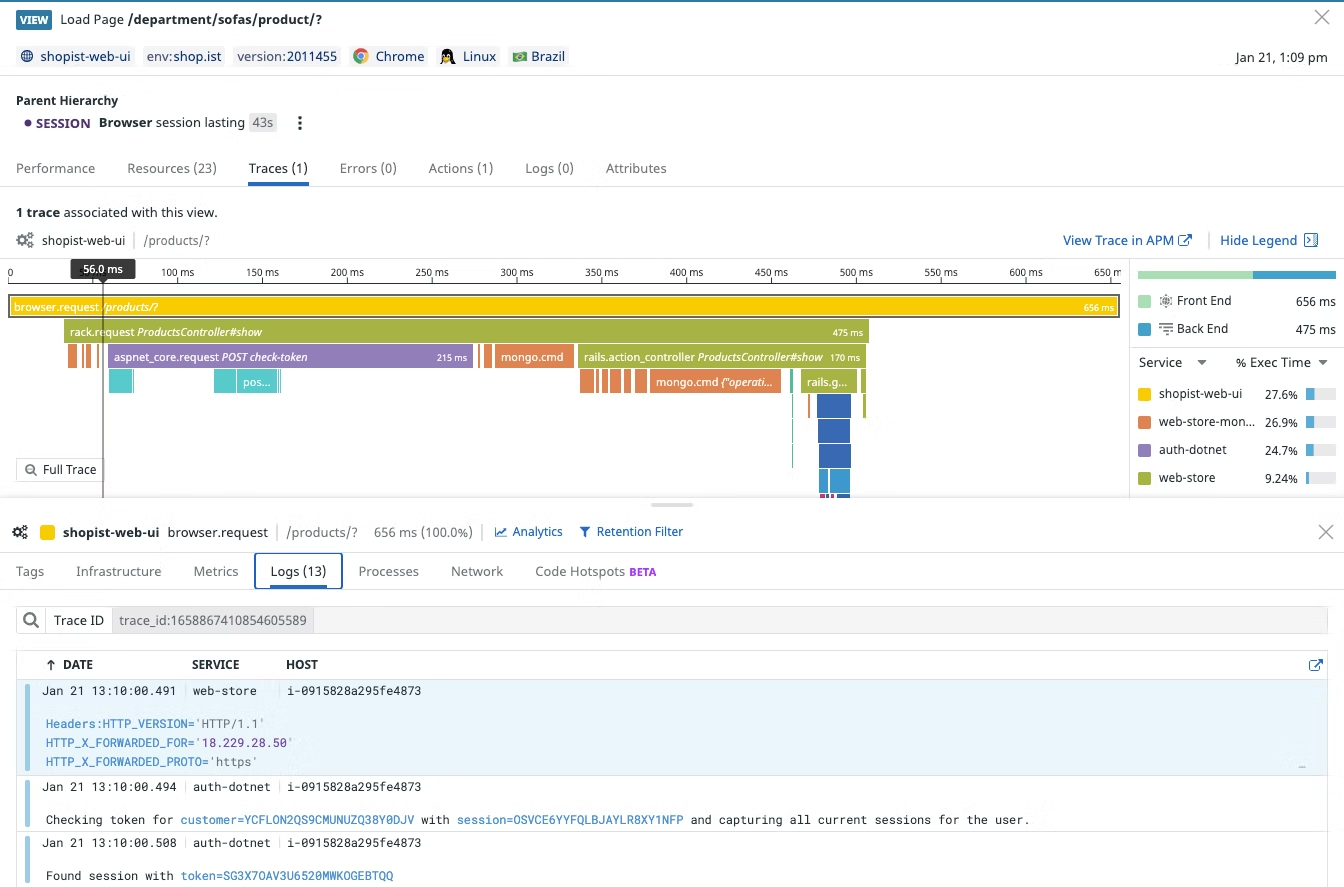
import { datadogRum } from '@datadog/browser-rum'datadogRum.init({ applicationId: '<DATADOG_APPLICATION_ID>', clientToken: '<DATADOG_CLIENT_TOKEN>', ...otherConfig, service: "my-web-application", allowedTracingOrigins: ["https://api.example.com", /https:\/\/.*\.my-api-domain\.com/]})关于全链路监控,其实 RUM 和 APM 联动只是一部分,只限于 Traces 的范畴。核心还包含 Traces 和 Logs 联动,Metrics 和 Trace 的捆绑等等。这个限于篇幅,以后再深入分享。
我们看看通过 Datadog 实现一个完整闭合场景,展现强悍的可观测监控能力:
1、假设我们做一些核心性能指标监控预警,比如 RUM 响应时间设置最长阈值。配置 Datadog 告警事件,一旦发生,Datadog 会推送结果
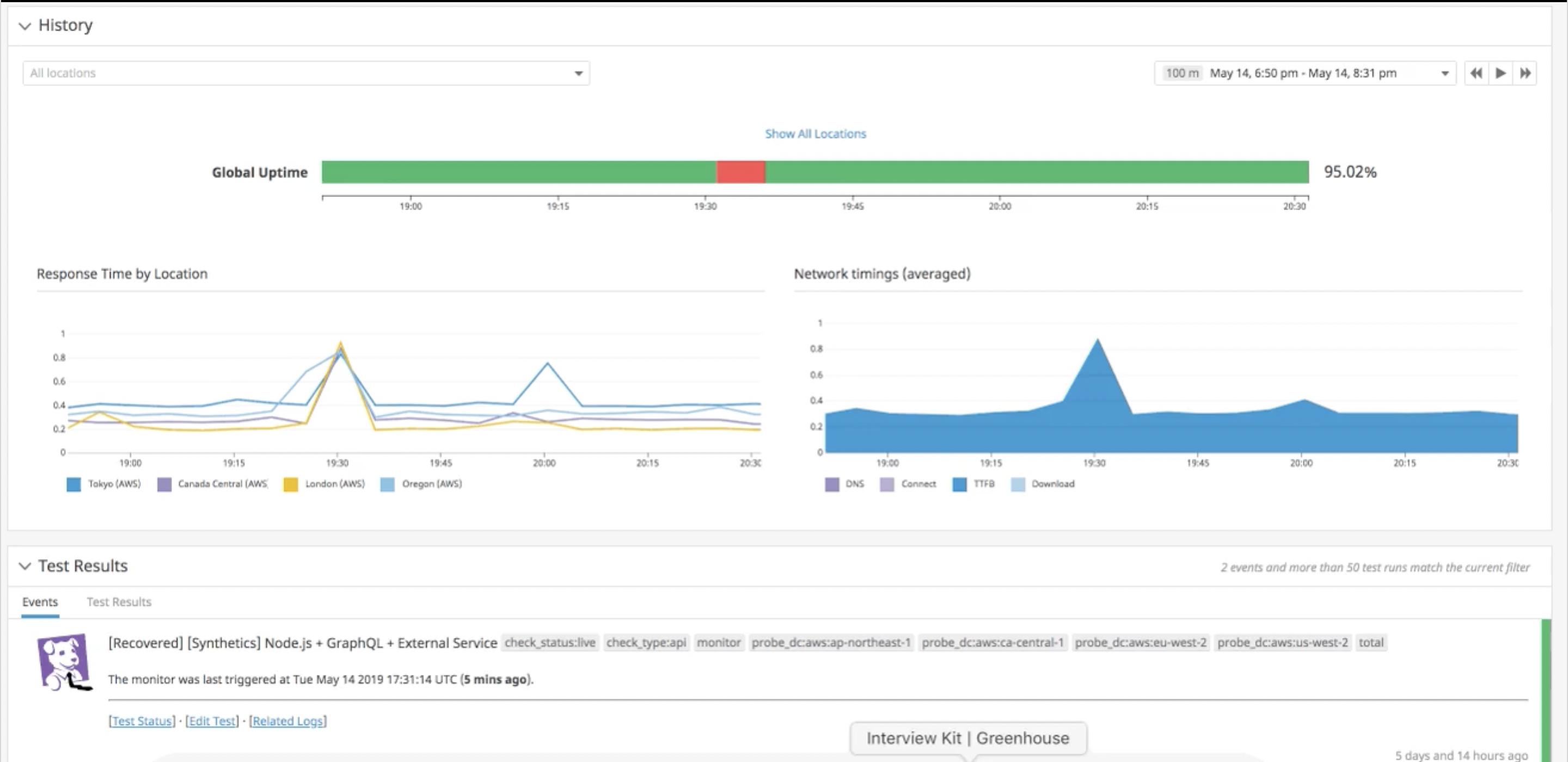
2、通过告警结果,关联钻取响应的全链路服务
通过告警信息提示和链接,我们钻取对于的链路看看具体访问情况
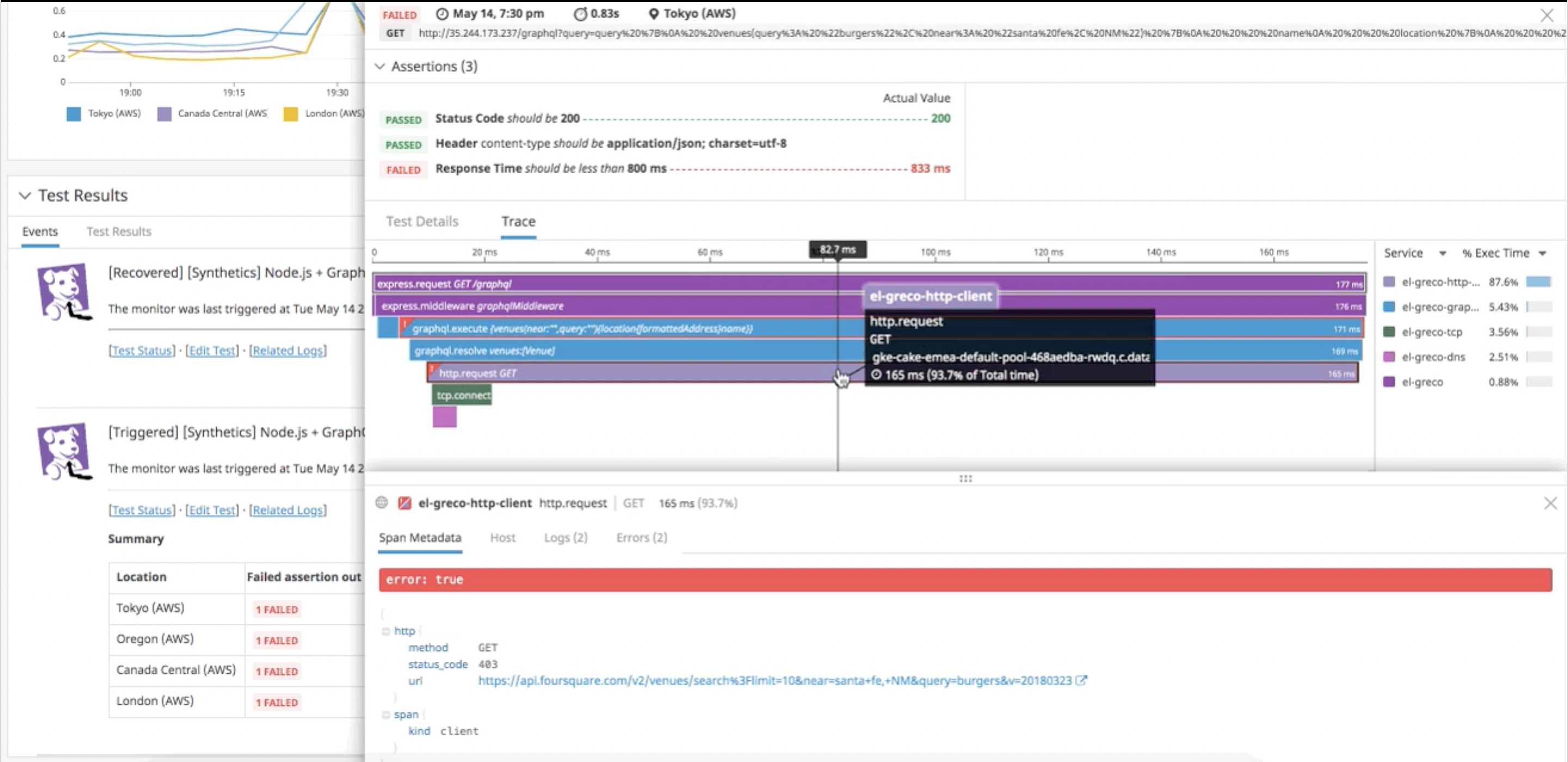
3、 通过上图,清晰标示出了链路中哪个 Span 的阈值发生了异常,马上定位到故障
SPA 监控支持
什么是 SPA
SPA(single-page application),单页应用SPA是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换打断用户体验在单页应用中,主要典型考虑手机端应用程序。所有(HTML、JavaScript和CSS)都通过单个页面的加载而检索,异步局部刷新页面模块,不会出现整个页面跳转。我们熟知的 JS 框架如react,vue,angular,ember都属于SPA
MPA(MultiPage-page application),多页应用,每个页面都是一个主页面,都是独立的当我们在访问另一个页面的时候,都需要重新加载html、css、js文件。多用在网站
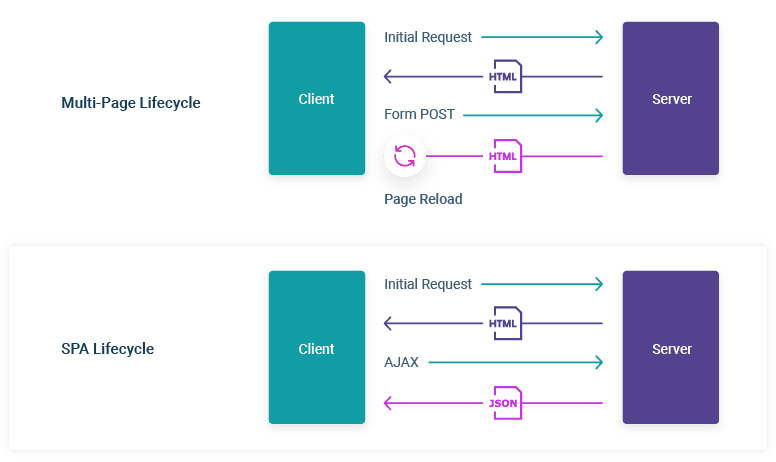
SPA 和 MPA 原理
单页应用与多页应用的区别
对 SPA 支持
在 SPA(Single Page Application)单页面应用中,页面只会刷新一次。传统的方式只会在页面加载完成后上报一次 PV,而无法统计到各个子页面 PV,也无法让其他类型日志按子页面聚合
New relic 详尽文档配置和完整的支持,针对 SPA 页面的两种处理方式
开启 SPA 自动解析
通过 SPA API 方式,手动上报
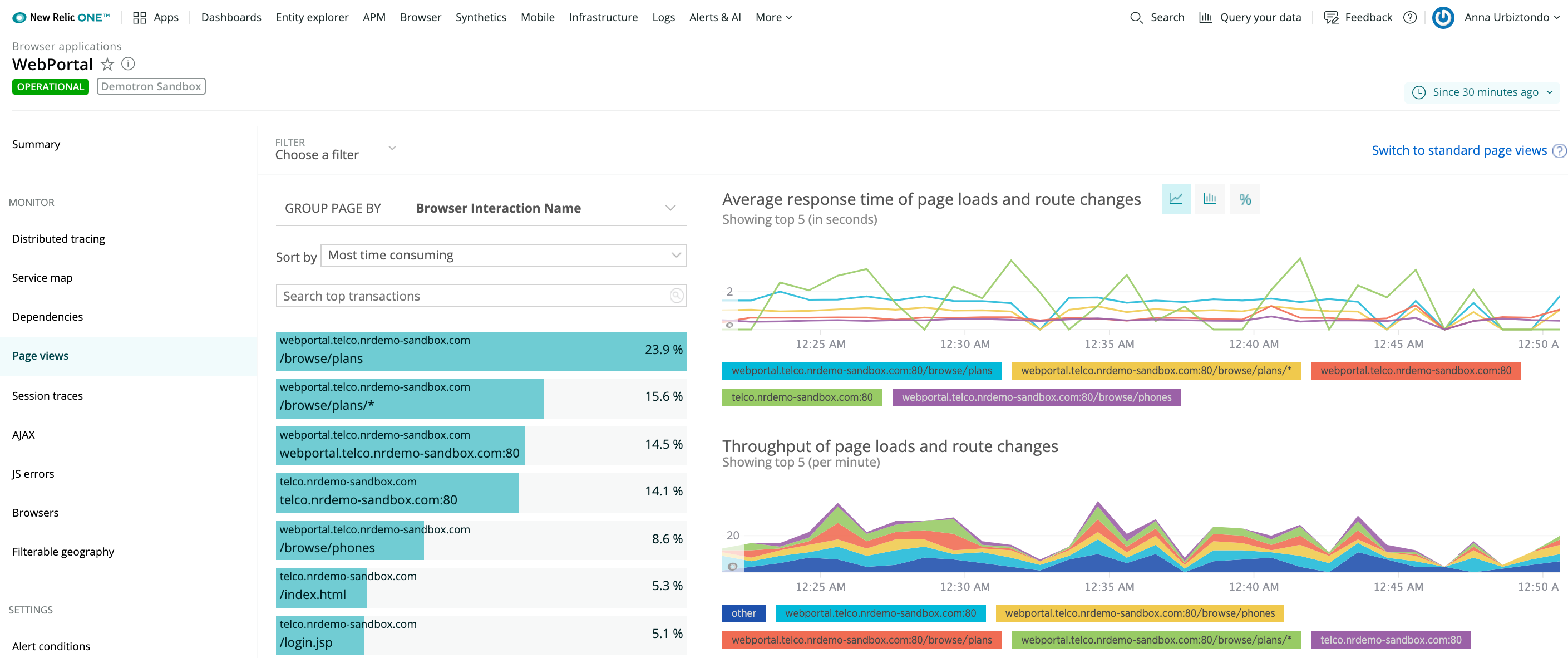
Datadog、OpenTelemetry、Fundebug 也对 SPA 不同程度支持,相对体验没有 New Relic 好
中国特色
公众号、小程序等监控
因为国内微信、支付宝庞大用户群。公众号,小程序,小游戏在终端应用程序是非常庞大的市场占有率。它们底层基于 Web + Native 实现,因为其技术、产品特殊性,国内的 RUM
Fundebug、Webfunny 专门做特殊支持。主要体现两个维度:
技术支持
底层实现的监控,比如 Fundebug 算是比较丰富,支持一些常见框架监控,下面例子
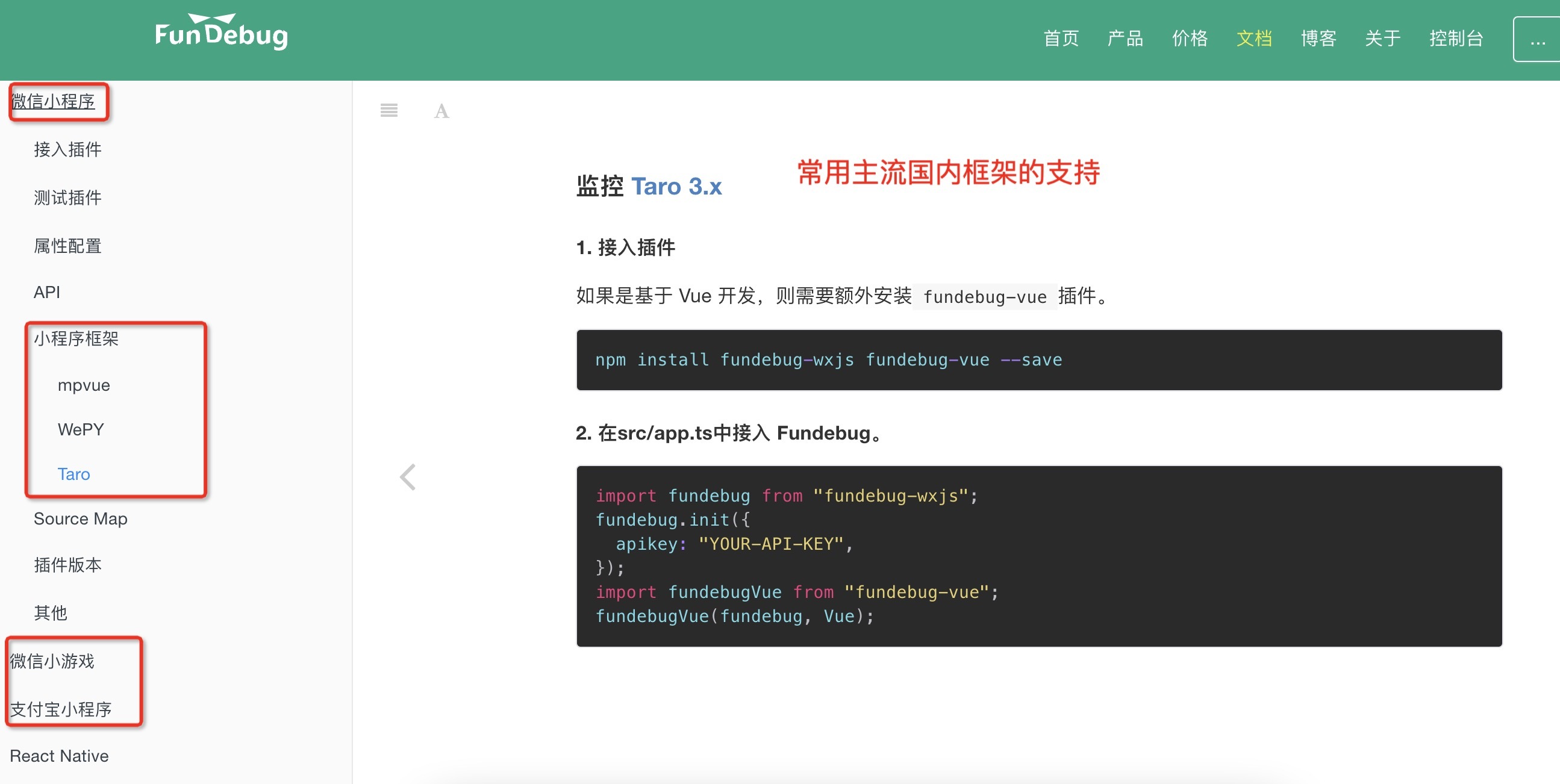
Fundebug 关于微信小程序监控集成
比如上图对 taro 框架集成监控,taro 是 github 上比较受大家欢迎的小程序开发框架
https://github.com/NervJS/taro
开放式跨端跨框架解决方案,支持使用 React/Vue/Nerv 等框架来开发微信/京东/百度/支付宝/字节跳动/ QQ 小程序/H5/React Native 等应用
监控大屏
Webfunny 开发的微信小程序数字大屏
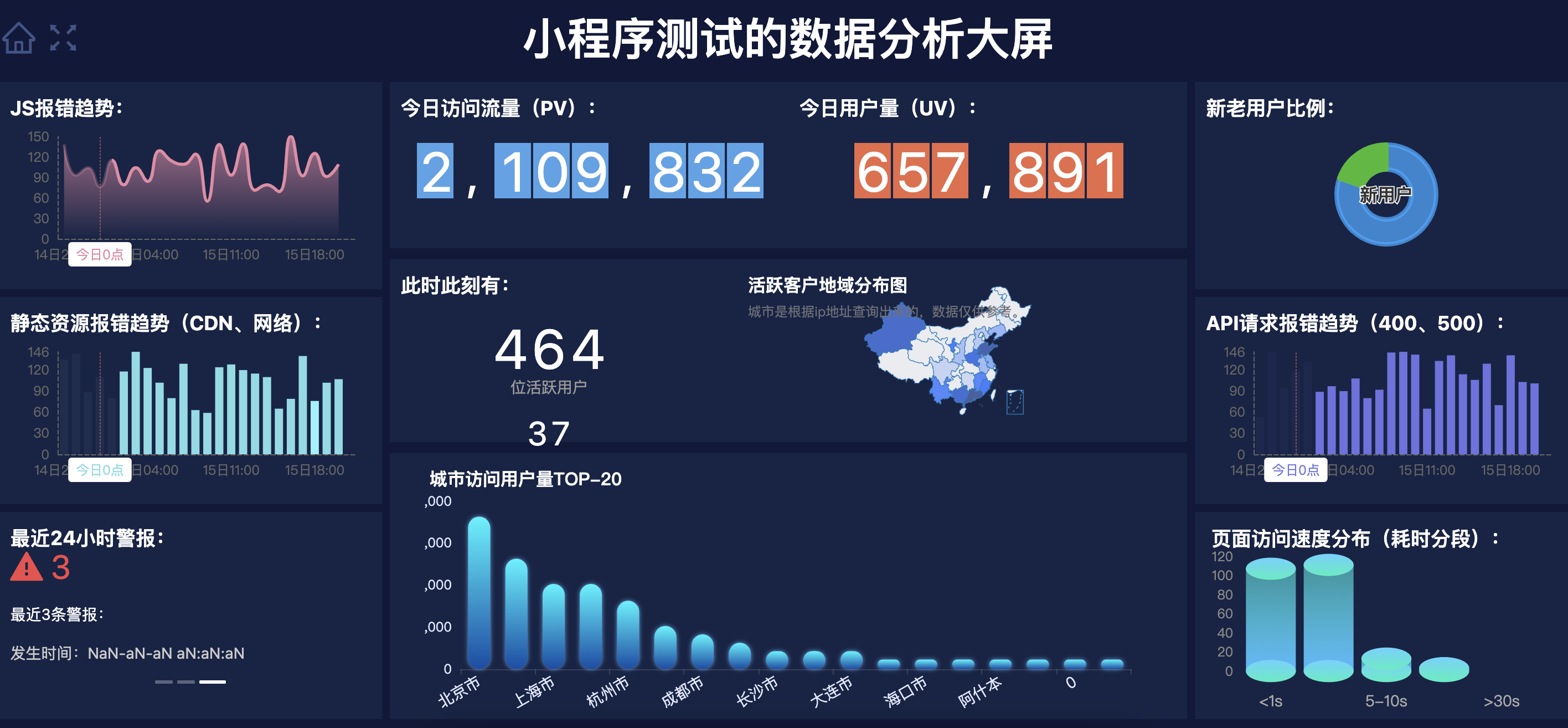
部署能力
私有化部署
Webfunny 、Fundebug、Sentry 都支持私有化部署,单独的 RUM 售价非常便宜
Sentry、Webfunny 完全开源
Saas 部署
Datadog 、New Relic、Fundebug、Sentry
总结:Sentry、Datadog 开源业界很有口碑,通过 Sentry 私有化、Saas 部署都非常成熟
国内 Fundebug、Webfunny 私有化部署客单价很实惠
八、社区和文档支持
技术文档
Datadog、New Relic、Webfunny、Fundebug 文档中心完整丰富。同时 Datadog、New Relic 在网上搜索一些问题,都能找到合适的解决方案,这对于维护者来说是非常有价值的。好的产品文档,也有助于我们了解产品的内部运行原理。
商业产品开源贡献:
Webfunny 完全做了产品开源版本,国内很多前端监控开发在用,一直持续更新中
而且提供通用私有化部署方案
Datadog 开源探针都做了开源,Github 口碑也是不错
推荐总结:要上生产环境,我们往往希望系统是可控的,完善、成熟的技术文档对于选型来说,是一个很基本的要求。开源还有一个额外的好处,就是代码的开放性,不用担心黑盒的情况存在。如果团队技术能力足够强,也能自己 Fix 问题。
社区生态
开源产品一大优势在于开放性,主要体现社区和技术支持上。 比如 Webfunny、Opentelemetry 国内都有活跃的社群,大家在社群上寻求帮助和交流产品问题,而且社群上都有核心的开源负责人答疑解惑,这本身也是一种友好的技术支持。
Webfunny & OpenTelemetry 微信群
技术支持
开源产品,本身自带社区属性,遇到技术问题寻求支持时,整体流程会更高效,但是解决问题速度和反馈因不同团队的精力而异。国内,RUM 产品体系认知不多,社区生态比较弱,没有特别推荐的技术社区。 在国外 OpenTelemetry 显得更活跃。
在商业 RUM 里,Datadog 借助 Slack 方式技术支持做得特别好:既有内容沉淀,使用者接入门槛比较低。更重要,还能更好提炼客户需求。
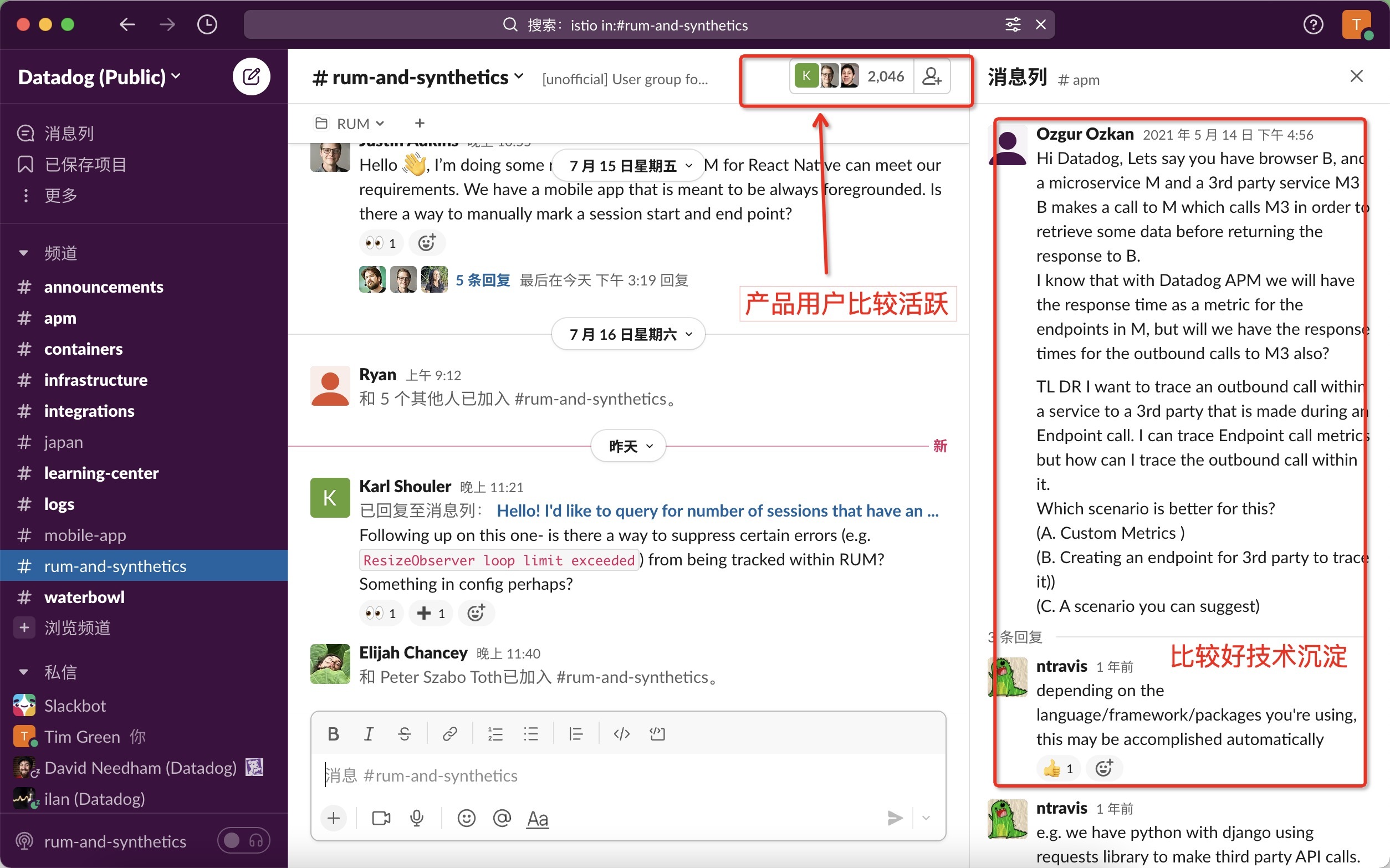
Datadog RUM 技术社区
总结
我们从几个维度介绍、对比了主流的 RUM 产品,总结了一些实际场景下的选型建议。
在过去我曾参与过 RUM 产品自研,也曾部署在其业务系统。关于 RUM 产品价值和如何选型问题,其重要还是基于场景化:每个公司 IT 系统既有通用性,也有其自身业务特性。而且,系统复杂度各不同,前端项目要求度也不尽相同。比如 To B 和 To C 的前端体验,是不同产品逻辑。采用哪一种 RUM 方案,是否需要做全链路监控,要不要考虑 SPA 的问等等。都是在考虑当前最合理的方案,而不是最完美的方案。也许,很多复杂的功能并非你想要的。希望我的分享能帮助你,也欢迎大家留言提问。
作者介绍
蒋志伟,爱好技术的架构师,先后就职于阿里、Qunar、美团,前 pmcaff.com CTO,目前 OpenTelemetry 中国社区发起人,https://github.com/open-telemetry/docs-cn 核心维护者
欢迎大家关注“OpenTelemetry” 公众号,这是中国区唯一官方技术公众号




