
当前,大模型推理正在向手机、PC、智能汽车等边缘侧和端侧产品渗透。然而,在终端部署 AI 大模型时,仍面临着存储与计算资源、功耗、软件生态等多重挑战。商汤大装置 HPC 团队基于多年的传统 CNN 推理基础设施研发与优化的经验,推出 SensePPL 端侧大模型推理系统,在计算优化、推理框架、Serving Pipeline 等层面进行深度调优,最终取得了业界领先的首字延迟、Decoding 延迟等端侧性能指标,大幅改善终端大模型落地的交互体验。
在 8 月份举办的 AICon 全球人工智能开发与应用大会上,商汤科技系统研究员雷丹做了主题为“SensePPL 端侧大模型系统与优化”的专题演讲分享,深入探讨在端侧设备上部署 AI 大模型的潜在优势以及面临的主要难题。
12 月 13-14 日,作为全年系列大会的收官之站,2024 AICon 全球人工智能开发与应用大会将在北京举办!本次大会将继续聚焦人工智能的前沿技术、实践应用和未来趋势,比如大模型训练与推理、AI agent、RAG、多模态大模型等等......精彩议题正陆续上线,欢迎访问链接查看详情:https://aicon.infoq.cn/202412/beijing/
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
2024 年被誉为 AI 应用的元年,大模型的发展不再仅仅局限于模型效果,而是更加注重推理成本和商业化落地。端侧大模型作为商业化落地的关键环节,今年特别受到关注。我们团队长期致力于高性能计算领域,过去多年专注于 CNN 推理和部署,推出了 PPL 推理系统。去年,我们开始着手云侧和端侧的大模型推理部署,并推出了云边端一体的推理解决方案——SensePPL。我们的端侧解决方案已成功部署在智能车舱和手机上,并在业界取得了领先的性能优势。
我将从四个方面详细介绍我们的工作。首先,我会解释我们为何要致力于端侧大模型推理。接着,我会分享我们如何通过采用一系列优化技术来实现性能上的优势。然后,我会详细介绍我们的整个 pipeline 流程。最后,我将结合几个具体的端侧应用案例,与大家分享我们的实践经验和成果。
端侧大模型推理发展现状
在过去的一年中,端侧大模型的发展呈现出蓬勃向上的态势。在手机领域,各大品牌如 vivo、OPPO、小米和荣耀,都将端侧大模型视为新的流量入口,并纷纷推出了自己的 AI 手机。苹果公司也在今年推出了其端侧 AI 系统,主要与 Siri 对话功能相结合,这一系统覆盖了平板、手机和电脑。全球 AI 手机的数量在今年第一季度从 16 个增加到了 30 多个。
在汽车行业,理想汽车去年推出了自研的认知大模型。小米汽车在今年也推出了语言大模型,并进行了备案。最新推出的 su7 车型搭载了语音大模型,能够识别前车的车型。我们公司的绝影团队也推出了智能座舱大模型产品体系。
AIPC 成为今年上半年的热点。英特尔、AMD 和微软等公司推出了搭载强大算力和 AI 功能的电脑。虽然这些电脑的价格往往高达数万元,用户可能不会轻易购买,但 PC 由于其较大的体积,能够搭载更强大的算力芯片,并且对散热的要求不那么严格,因此端侧在 PC 上也是一个理想的落地场景。有机构预测,AIPC 在 2027 年的渗透率有望达到 85%。
所有这些应用的发展,一方面得益于大模型的小型化,另一方面则是硬件算力的持续迭代。在大模型小型化方面,业界知名的有 LLAMA3,这是一个 8B 模型,其训练数据量是 7B 模型 LLAMA2 的 7 倍,使用了 15 万亿的 token。微软推出的 Phi-3 性能超过了 LLAMA3。国内方面,面壁智能推出了 Mini CPM。在硬件上,高通和联发科也分别推出了自己的 AI 芯片。这些进展都为端侧大模型的广泛应用提供了坚实的基础。
以上可以看到,端侧大模型一片火热。理想总是很丰满,但现实往往有些骨感。尽管去年业界对端侧大模型的探索充满热情,但事实上,我们发现端侧大模型并没有找到一个非常好的落地点,因此在短期内我们难以看到它的实际价值。那为什么我们仍然要致力于端侧大模型推理的研究和开发?
如果短期内我们看不到它的价值,那么我们可以将视野放得更长远一些。设想一下,如果我们以十年为期限,大模型的最终形态应该是怎样的?我相信,到那时,人工智能将无处不在。而要实现这一点,我们不仅需要云端的模型,同样也需要边缘端的模型。
第一,端侧大模型的部署可以加大用户基数。 目前,国内一些领先的应用,如文心一言和豆包,它们的月活跃用户数大约在 1000 万左右。而像 Facebook 这样的传统应用,其月活跃用户数达到了 29 亿,几乎涵盖了所有说英语的人群。即便是目前非常出名的 ChatGPT,其月活跃用户数也大约在 10 亿左右。与这些传统的互联网应用相比,大语言模型的发展还有很大的差距,尤其是在月活跃用户数上。这就意味着我们需要扩大用户基数以提高月活跃用户数。那么,用户从哪里来?他们将来自千家万户,包括手机、车机、PC、机器人等各种设备。这些设备将成为端侧大模型推理的重要载体,也是我们持续探索和优化端侧大模型推理的重要原因。
规模效应是商业价值产生的基础,而商业价值的实现需要扩大用户基数。这一切的实现,都依赖于端侧技术的落地。我理想中的未来状态是端云协同,即在云端部署大型模型,运行在服务器集群上,同时在边缘端,也就是手机、车机等无数设备上部署模型,通过端和云的协同工作来满足用户的日常需求。
第二,端侧大模型的部署可以缓解算力压力。 首先,我们来看看云端的情况。当前云端面临的一个主要问题是算力成本过高。以 ChatGPT 为例,根据其日活跃用户数推算,它需要大约 46 万台服务器来支持其运行,而 OpenAI 一年的运营成本高达 85 亿美元。其中,训练成本约为 30 亿美元,推理成本约为 40 亿美元。这还不包括自建服务器集群的成本,该集群拥有 12 万张 A100 显卡。尽管使用了微软的 TPU 集群,价格相对较低,但 OpenAI 仍然需要花费 40 亿美元来进行推理。
大模型的竞争已经从模型本身的竞争扩展到了算力的竞争,甚至演变成了国与国之间的竞争。因此,对高性能计算资源的限制也是可以理解的。然而,端侧技术天然具有缓解算力压力的优势。因为一旦用户购买了手机等设备,厂家就不需要为端侧的大模型提供额外的算力,这使得厂家能够在不增加成本的情况下,依托端侧技术提供强大的计算能力,从而缓解算力的压力。
第三,大模型小型化是必然趋势。 目前,端侧发展的主要限制因素是模型本身的效果。大模型的小型化正逐渐成为一个热门话题。最近,贾扬清在推特上提到了 LLAMA 3.1,他描述了现代大模型的发展趋势与 CNN 时代的模型发展有些相似。在那个时期,模型会经历一个快速增长参数的阶段,然后转向更小、更高效的模型。Karpathy 也认同这一观点,我个人也支持这一看法。事物的发展总是先成熟,然后再实现落地。成熟意味着模型越来越大,效果越来越好;而落地则需要低成本和高效率。目前,小型模型的发展势头良好,包括 LLAMA 3、Phi-3 以及国内面壁智能推出的 Mini CPM 等。
第四,端侧大模型天然具有隐私保护的优点。 在当今时代,数据的重要性已经上升到了与能源和粮食同等的地位,它们被视为国家的三大关键基础设施之一。只有当用户的隐私得到妥善保护时,他们才会放心地使用人工智能技术。
推理性能评估指标
在深入探讨这些挑战之前,让我先简要介绍一下大模型推理的基本流程。首先,用户会提供一个 prompt,然后推理框架会根据这个提示生成回答。推理过程通常分为两个阶段:prefill 阶段和 decoding 阶段。
在 prefill 阶段,推理框架接收用户的提示输入,并将其存储为 KV Cache,然后输出第一个 token。这个阶段只运行一次,尽管耗时可能较长,但由于它只执行一次,所以在整体耗时中所占比例相对较小。prefill 阶段是一个计算密集型的操作。
接下来是 decoding 阶段,这个阶段是一个自回归的过程,每次生成一个 token。具体来说,它会将上一时刻的输出 token 作为当前时刻的输入,然后计算下一时刻的 token。如果用户的输出数据很长,这个阶段就会运行很多次,其耗时可能占到整体耗时的 90% 左右。由于 decoding 阶段的输入依赖于上一时刻的 token,对于端侧设备来说,通常它的 batch size(批量大小)是 1,也就是说它的 sequence length(序列长度)也是 1。因此,decoding 阶段是一个访存密集型的操作。
在讨论了大模型推理的流程之后,我们来谈谈评估推理系统性能的四个常见指标:吞吐量、每秒请求数、首次延迟和延迟。
吞吐量是指推理系统在单位时间内能够处理的 token 数量。这通常假设有大量用户同时提出相同的问题,我们想知道整个推理系统能够输出多少 token。然而,这是一种理想化的情况,因为用户不太可能同时到达,也不会提出完全相同的问题。因此,吞吐量数据只能作为一个参考。更实际的指标是每秒请求数,它衡量的是推理系统在实际应用中处理负载的能力。而首次延迟和解码延迟则分别指:
首次延迟:在 prefill 阶段,推理框架接收到 prompt 后输出第一个 token 所需的时间。这个指标直接影响用户的直观体验。
解码延迟:在 decoding 阶段,平均每次生成 token 所需的时间。这个指标影响的是整个推理过程的总体耗时。
我们需要考虑端侧推理与云侧推理对这四个指标的侧重点的不同之处。云侧推理通常部署在服务器集群上,服务大量用户,用户越多,推理系统越高效,所以云侧推理强调的是提高吞吐量以提升效率。相反,端侧推理通常服务于单个用户或少数用户。例如,在汽车中,可能有五个人同时进行语音对话,这时 batch size 可能是 5,所以端侧推理的重点不在于扩展用户数量,而在于如何更好地服务现有用户。因此,端侧推理的指标通常关注首次延迟和延迟,这些指标对于提供流畅的用户体验至关重要。
端侧大模型推理面临的挑战
端侧推理面临的挑战可以从四个主要方面来概括:
内存占用:端侧设备的内存通常是有限的,因此优化内存使用是确保端侧推理能够顺利运行的关键。如果内存占用过高,推理模型可能无法在设备上运行。
延迟:这直接影响到用户体验。优化首字延迟和解码延迟是提高端侧推理速度的关键,确保用户能够快速获得响应。
模型效果:这是一个复杂的问题,需要算法工程师提供更小但知识密度更高的模型。这通常涉及到模型结构的改进和数据的清洗。但对于端侧推理来说,量化也会造成精度损失,因此我们需要特别关注量化精度损失的衡量,以确保推理结果的准确性。
跨平台兼容性:随着我们希望 AI 技术无处不在,优化兼容性成为关键,以确保端侧推理能够覆盖更广泛的设备和平台。
端侧推理框架优化技术
优化显存:解决端侧推理能不能跑的问题
为了解决端侧推理能否运行的问题,我们首先需要优化显存的使用。在研究这个问题时,我们通常会先了解情况再做决定,因此,我们先来深入了解显存的需求。对于一个 7B 参数的模型,如果使用 fp16 格式存储,其权重大约需要 14GB 的显存。每个 token 的 KV 缓存大小是 hidden size 乘以层数,再乘以 2 个字节,再乘以 2(即 key 和 value),大约是 0.5MB。假设最大长度为 4K,最大 KV 缓存占用是 2GB。激活数据,即输入和输出,在内存复用的情况下占比较小,因为它主要取决于网络中最大 tensor 的内存占用,通常占比小于 5%。
我们还需要考虑 KV Cache 对云侧和端侧的不同之处。因为 KV Cache 代表用户的历史信息,那么每个用户的历史信息不同,这也代表每个用户的 KV Cache 是独立的。在云侧,由于服务众多用户,每个用户有不同的 KV Cache,所以云侧优化的重点是如何在固定的内存空间内实现高吞吐量,即每个用户占用的 KV Cache 越小,吞吐量就越高。因此,云侧通常会对 KV Cache 进行 INT8 甚至 INT4 的量化,而权重则通常使用 W8A8 的量化方案。
端侧的情况则不同,通常用户的 batch size 较小,因此 KV Cache 通常只有一份,并且在端侧场景中,最大上下文长度通常不会达到 4K,一般在 200 到 300 之间,所以 KV Cache 的显存占用大约在 200MB 左右,甚至更小。因此,在端侧,权重是显存占用的大头,而 KV Cache 可以忽略不计。权重通常使用 W4A16 的量化方案,而 KV Cache 使用 INT8 量化方案,甚至使用 FP16 也是可行的。
在端侧推理中,我们采用了 W4A16 的权重量化方案。W4A16 是一种 4bit 量化技术,通过将权重按照 group size 为 128 的组大小在 K 方向进行分组来实现。在计算过程中,输入数据保持为 FP16 格式,而权重进行 INT4 反量化为 FP16,然后执行矩阵乘法和矩阵向量乘法,这些操作都是在 FP16 的基础上完成的。
为了提高量化精度,我们采用了业界开源且效果较好的 AWQ 量化技术。AWQ 量化的基本原理是根据激活的分布选择 1% 的权重不进行量化,因为激活数据更难量化,而权重相对容易量化。在实际操作中,如果不进行量化,混合量化将变得复杂。因此,AWQ 量化会将权重乘以一个系数,而输入则去除一个系数。这个系数处理起来较为复杂,通常会将其与前一层的参数融合。我们的工作流程是首先获取模型的 Hugging Face 版本,结合业务标定数据,转化为 AWQ 的 INT4 模型。
W4A16 量化方案特别适用于 decoding 场景。原因在于,W4A16 使权重尺寸大幅减小,但同时增加了反量化耗时,恰好在 decoding 阶段,性能瓶颈在于访存,因此增加一些计算量并不会显著影响最终性能。实际上,由于显存的减少,性能反而得到了提升。然而,在 prefill 阶段,由于其瓶颈在于计算本身,增加计算量反而会成为负优化。目前,我们正在研究如何使 W4A16 量化方案同时适用于 prefill 和 decoding 阶段,因为这两个阶段共用一套权重。在云侧推理中,由于 batch size 较大,例如 128,解码阶段从严格受限于访存转变为计算受限,因此云侧的场景与端侧不同。这也是为什么云侧更倾向于使用 W8A8 和 W4A8 的量化方案,而不采用 W4A16 量化方案。
KV Cache 采用了 INT8 量化。这种量化方式是将 Head Size 每 8 个一组进行量化。然而,这种量化方法在实际操作中存在一些问题。首先,我们需要对 key 和 value 进行量化,然后将量化后的 KV Cache 存储在一个 pool 中。由于后续需要进行自注意力机制的计算,这要求我们与历史的所有 key 和 value 进行注意力机制的计算,因此我们需要从 KV Cache 中提取历史信息。在这个过程中,我们首先需要对存储在 pool 中的 KV Cache 进行一次反量化,以便获取之前所有的 key 和 value。这个量化和随后的反量化过程实际上增加了额外的性能开销。由于所有的算子都是我们自己编写的,我们对这一过程进行了优化,将量化和反量化步骤与自注意力机制进行了融合。通过算子融合,我们实现了一个带有缓存功能的 MHA 算子,减少了重复的量化和反量化操作,提高了整体的计算效率。
优化延迟:解决端侧处理跑得快不快的问题
在确保端侧推理模型能够运行之后,我们现在关注的是模型运行的速度,即它能否快速执行。
在 prefill 阶段,我们通过耗时统计发现,矩阵乘的耗时占比在 70% 到 90% 之间,而 attention 的耗时占比则在 7% 到 30%。这种波动的原因在于,对于不同的序列长度,attention 的耗时与长度的平方成正比。因此,序列越长,MHA 的占比就越高。在短文本场景下,矩阵乘的耗时占比可达到 90%,而在长文本情况下,这一比例会下降到 70%。因此,无论是矩阵乘还是 attention 的计算,在 prefill 阶段都是我们优化的重点。
在 decoding 阶段,我们观察到大约 91% 的时间都花费在矩阵向量乘上。为了判断模型能否快速运行,我们需要先评估系统能达到的性能上限。由于我们主要使用 GPU,我们可以查看 GPU 的理论性能,这通常基于硬件参数计算,并可在芯片的 SPEC 手册中找到。例如,高通 8 Gen 1 设备的的理论带宽大约为 50 多 GB/s,而 8 Gen 3 的理论带宽则在 70 多 GB/s。算力也从 4.8T FLOPS 左右上升到 8T FLOPS 以上。但通过 Benchmark 实际测试后,发现浮点运算的效率大约只有 50%,访存效率大约为 70%。这意味着实际性能并不能完全发挥出理论性能,这与云侧的 CUDA 环境完全不同,后者基本上能够发挥出 90% 以上的性能。
有了这些数据,我们可以根据过程受限的情况推断出大概的性能。在 prefill 阶段,由于它受计算限制,我们使用算力进行评估。根据前面的计算结果,我们使用大约 1T FLOPS 的算力来推算耗时,即先计算总的计算量,然后除以 1T FLOPS 的算力。在 decoding 阶段,由于它受带宽限制,我们需要计算需要搬运的内存量,然后除以 40GB/s 的带宽。最终,我们得到的理论性能与实际测试结果基本吻合。
为了优化端侧推理的延迟,我们需要深入了解 GPU 的内存特性和算法优化。GPU 有两种类型的内存:image 内存和 buffer 内存。image 内存适用于多维数据访问,它在读取数据时使用的是 L1 缓存,而 buffer 内存则一直使用的是 L2 缓存,但它更加灵活。为了最大化内存利用效率,我们通常会更多地利用 L1 缓存。因此,我们采用了一种混合内存分布方式,将所有激活数据按 buffer 内存分布,而将权重按 image 内存分布。
除了考虑硬件架构外,我们还研究了不同的算法策略。这里主要介绍三种算法方式。
n 连续:这种方式是按行排布,每个线程计算 n 列的结果。如果 head size 较大,能启动的线程数量会相对较少。由于 GPU 的访存效率依赖于线程数量,线程越多,越能在线程切换时掩盖延迟,并且能更好地利用 DDR 和 L2 的带宽。为了解决这个问题,我们提出了一种改进方法,即在 k 方向上继续进行切分,类似于 decoding attention 的方式,这样可以启动更多的线程。
k 连续:这种方式是按列排布,每个 sub group 归约一列。它能启动的线程数量最多,但需要进行规约操作,在 GPU 上进行规约是较慢的,因此它更多地是在线程数量和规约之间进行权衡。这种算法适用于 k 较小的情况,因为 k 较小时,规约的次数也会较少。
K8N4:这种算法结合了 n 连续算法的优势,并充分利用了 image 内存的特点,即一个像素点可以直接取出四个数据点,从而提高带宽利用率。

在实际应用中,我们会根据具体情况选择使用这三种算法,并进行具体分析,以确保在不同场景下都能达到最佳的性能。从实测结果可以看出,对于小规模数据,k 连续算法的性能最佳;对于大规模数据,n 连续算法的性能最佳;而对于中等规模的数据,则 K8N4 算法的性能最佳。
在讨论了 GMV 性能之后,我们重点来看 prefill 阶段的矩阵乘问题。这里我们比较了两种常见的方案:n 连续方案和 k 连续方案。
n 连续方案:在这种方案中,一个线程处理一个 BM×BN 大小的块。输入数据通过 buffer 内存访问,而权重数据通过 image 内存访问。采用合适的分块大小可以优化内存访问效率。
k 连续方案:当 k 值较小时,这种方案便于进行规约操作,能够达到 1.3T 的算力。当 k 值较大时,其性能可以与 n 连续方案相媲美。
我们的实测结果显示,对于纯 Half 精度的矩阵乘,算力能够达到 1.1T,而 ALU 的利用率可以达到 50%,这已经是一个相当高的值。当我们引入反量化操作,即将 INT4 反量化到 FP16 时,虽然吞吐量下降到 0.85T,但 ALU 的利用率却能达到 85%。这一结果表明,Half 精度数据的处理可以达到 1T 的算力,但 W4A16 量化方案虽然只有 0.85T 的吞吐量,却有更高的 ALU 利用率,这说明其瓶颈在于反量化过程。
至于 Flash attention 和 decoding attention,我们认为它们本质上属于算子融合的范畴,这是推理框架中常见的优化思路。但融合之后的性能瓶颈又回到了矩阵乘和矩阵向量乘上,因此我们没有对这部分进行更深入的探讨。
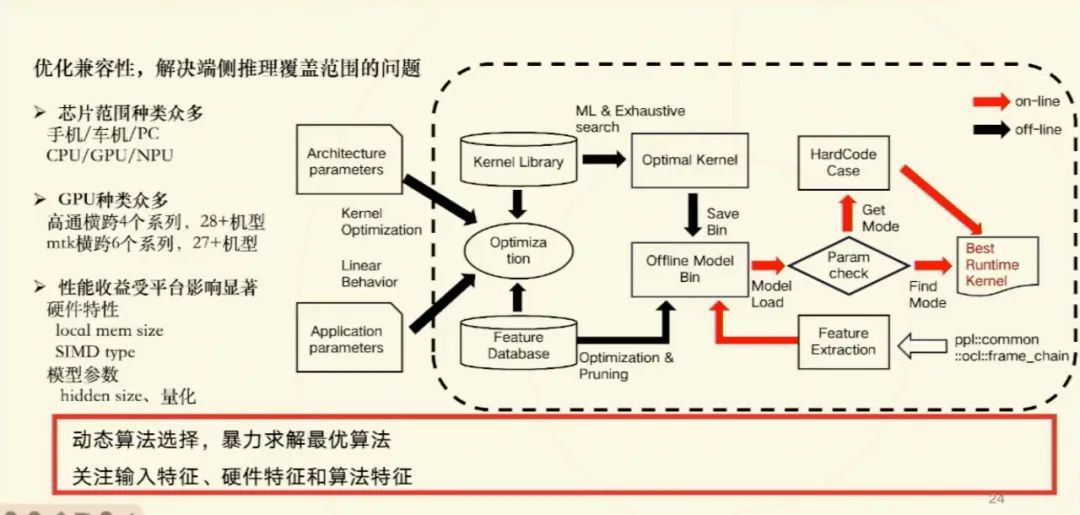
优化兼容性:解决端侧推理覆盖范围的问题
在讨论端侧推理的性能时,我们注意到不同设备上的性能表现存在差异,这主要是由于硬件特性和模型的不同。为了覆盖更多的设备平台,我们需要考虑兼容性问题。芯片的种类繁多,包括手机、车机、PC 等,它们使用的芯片完全不同。即使是在同一设备中,也存在异构架构,如 CPU、GPU 和 NPU。
CPU 在大模型推理中可以作为一种兜底方案,因为它是串行处理的。在内存共享的设备如手机上,CPU 在 decoding 阶段并没有明显劣势。对于 prefill 阶段,由于 CPU 不适合处理大矩阵乘法,其性能会有所下降,但其兼容性更好,因此完全可以作为一个备选方案。
NPU 的门槛不高,厂商会增加更多的计算单元,推出更高算力的 NPU,但它的问题在于缺乏统一标准,兼容性很难做的很好,即使是同一厂商的不同代产品,维护起来也很困难。由于我们主要研发自主推理框架,因此我们将重点放在 CPU 和 GPU 上,而 NPU 通常只提供接口,优化空间有限。
对于 GPU,我们已经适配了高通的多个系列的芯片,涵盖了 28 种机型,以及 MTK 的 6 个系列的芯片,覆盖了 27 个机型。每种硬件的特性都不尽相同,例如 local memory size 和 SIMD type 都有所区别。不同模型的参数不同,其特性也完全不同,因此算法的选择也会有所不同。
为了适配不同的模型,我们提出了算法选择的概念。算法选择的复杂性主要在工程层面,逻辑上却相对简单。我们会根据硬件特性和模型参数选择不同的算法和分块大小。这些选择算法会被存储为字符串,在线推理时直接加载所选算法的字符串,然后编译其 kernel。这包括算法选择、模型的离线处理和编译的离线处理,我们将这三部分提前离线完成,在线时直接加载即可。
Serving Pipeline 流程优化
我们提供了从模型到服务的云边端一体化的推理解决方案,主要包含以下四个方面。
OPMX:OPMX 是一个 Python 代码库,它定义了一套 ONNX 格式,允许用户通过 Python 接口轻松地一键转换模型。部分算子融合也是在 OPMX 处理的。
PPL 框架:PPL 框架是一个云边端一体化的推理框架,支持异构设备。
算子库: 依赖于高性能的算子库。对于 GPU,我们主要使用 OpenCL,而对于 CPU,则主要使用 ARM 的算子库。
PPL Serving:最外层是 Serving,类似于 Triton 这样的服务,它包括分词、采样、异步、多 batch 处理,以及 paged attention 和分布式等特性。
为什么在讨论端侧推理时还要涉及 Serving?
一方面是,PPL serving 提供了整个 pipeline 流程。推理本身是一个从接受用户 prompt 到分词、推理、采样,再到输出的完整过程。Serving 层负责将整个流程串联起来,其中分词和采样在 CPU 中完成,而推理则在 GPU 中进行。通过 CPU 和 GPU 的异步处理,还可以掩盖延迟。
另一方面,Serving 实现的 KV Cache 管理对端侧是有益的。多轮对话优化是实际业务的一个例子。多轮对话的处理需要将当前用户输入与之前的问题和回答组合起来,作为一个长串输入传递给推理框架。但有了对 KV Cache 的管理,整个过程可以进行优化。历史的 prompt 和回答可以拼接并保存在 KV Cache pool 里,只需要对 KV Cache 进行追加即可。
SensePPL 应用
在 4 月 23 日的商汤发布会上展示了我们的 SensePPL 推理系统,它在 prefill 和 decoding 性能方面都表现出色。5 月份,我们为关键客户进行了 SDK 集成,6 月份,绝影团队展示了使用 SensePPL 的多模态推理解决方案。目前,我们正在推广的是商汤的“商量 9 块 9 元 / 年”服务,它支持高通和 MTK 等高端机型。
我们对高通和 MTK 的旗舰手机进行了测试,结果显示,对于高通 8650 旗舰手机,我们的端到端解决方案的首次延迟达到 242 tokens/s,decoding 速度达到 44.41 tokens/s。在 MTK9300 旗舰手机上,首次延迟为 194 tokens/s,decoding 速度为 35.7 tokens/s。
对于部署的 SenseChat-Lite 1.8B 模型,其性能比调优后的 MLC 模型有显著提升。在关键性能指标上,prefill 和 decoding 领先了 30%,资源利用方面,内存占用降低了 50%。此外,我们还支持文本生成和文档 RAG 等应用。
在 WAIC 大会上绝影团队展示了多模态模型部署方案,基于 NPU 部署 Vit 模型,基于 GPU 部署大语言模型。其中 LLM 部分的性能比开源方案提升了三倍,达到了 48 tokens/ 秒。
通过这些介绍,我们希望向大家展示从模型到服务的云边端一体化推理解决方案 SensePPL。它依托于高性能的算子库和极致优化的推理框架,以及支持多种特性的 Serving 层,支持大语言模型和多模态模型等各种模型。目前,它已经应用于 AI 手机和 AI 汽车,接下来我们将重点放在 AIPC 和机器人。我们的目标是让这套推理解决方案能够帮助 AI 真正普及到千家万户,让 AI 无处不在。
演讲嘉宾介绍:
雷丹,商汤科技系统研究员。长期从事 AI 模型推理研发与优化工作,参与 PPL 推理引擎移动端 GPU 的研发和业务落地。目前主要负责 SensePPL 端侧推理引擎的研发,推动 SenseChat-Lite 手机端部署及多模态模型在智能车舱的应用。
会议推荐:
2024 年收官之作:12 月 13 日 -14 日,AICon 人工智能与大模型大会将在北京举办。从 RAG、Agent、多模态模型、AI Native 开发、具身智能,到 AI 智驾、性能优化与资源统筹等大热的 AI 大模型话题,60+ 资深专家共聚一堂,深度剖析相关落地实践案例,共话前沿技术趋势。大会火热报名中,详情可联系票务经理 13269078023 咨询。





