
为了更全面地了解 Pulsar 和 Kafka,我们“复现”了 Confluent 对 Pulsar 和 Kafka 基准测试。重复这一基准测试的原因有两个,一是 Confluent 的测试方法存在一些问题;二是 Confluent 的测试范围和测试场景不够全面。为了更准确地对比 Pulsar 和 Kafka,我们在测试中不仅修复了 Confluent 测试中的问题,还扩大了测试范围,纳入更多性能衡量标准,模拟更多实际场景。
和 Confluent 的测试相比,我们的测试主要有三项改进:
包含 Pulsar 和 Kafka 支持的所有持久性级别。在同等持久性级别下,对比二者的吞吐量和延迟。
引入影响性能的其他因素和测试条件,如分区数量、订阅数量、客户端数量等。
测试的混合负载同时包含写入、追赶读和追尾读,模拟实际使用场景。
我们进行了最大吞吐量测试、发布和端到端延迟测试(具体见下篇)、追赶读测试和混合工作负载测试。由于篇幅有限,本篇主要介绍发布和端到端延迟测试详情。
最大吞吐量测试
测试目标:观测在处理发布和追尾读工作负载时 Pulsar 和 Kafka 可实现的最大吞吐量。
测试设置:通过调整分区数量,观测分区数量对吞吐量的影响。
测试策略:
将所有消息都复制三次,确保容错;
改变 ack 数量,测试在不同持久性保证下,Pulsar 和 Kafka 的最大吞吐量;
启用 Pulsar 和 Kafka 的批处理,为不超过 10 ms 的响应延迟设置最大批处理为 1 MB 数据;
改变分区数量(1、100、2000 个分区),分别测试最大吞吐量;
当分区数量为 100 和 2000 时,使用 2 个 producer 和 2 个 consumer;
当分区数量为 1 时,改变 producer 和 consumer 的数量,观测吞吐量变化;
消息大小为 1 KB;
在所有测试场景中,改变持久性级别,观测最大吞吐量。
测试结果
#1 100 个分区,1 个订阅,2 个生产者/2 个消费者
分区数量为 100,改变持久性保证,分别观测 Pulsar 和 Kafka 的最大吞吐量。在 Pulsar 和 Kafka 中,都使用 1 个订阅、2 个生产者和 2 个消费者。测试结果如下。
在 1 级持久性保证(同步复制持久性,异步本地持久性)下,Pulsar 的最大吞吐量约为 300 MB/s,达到日志磁盘带宽物理极限。Kafka 的最大吞吐量约为 420 MB/s。值得注意的是,在持久性为 1 级时,Pulsar 配置一个磁盘为日志磁盘进行写入,另一个磁盘为 ledger 磁盘进行读取;而 Kafka 同时使用两个磁盘进行写入和读取。尽管 Pulsar 的设置能够提供更好的 I/O 隔离,但单个磁盘最大带宽(~300 MB/s)会限制吞吐量。
将持久性(同步复制持久性和异步本地持久性)配置为 2 级时,Pulsar 和 Kafka 的最大吞吐量均可达到约 600 MB/s 。两个系统都达到了磁盘带宽的物理极限。
图 1 为 100 个分区,同步本地持久性下,Pulsar 和 Kafka 的最大吞吐量。
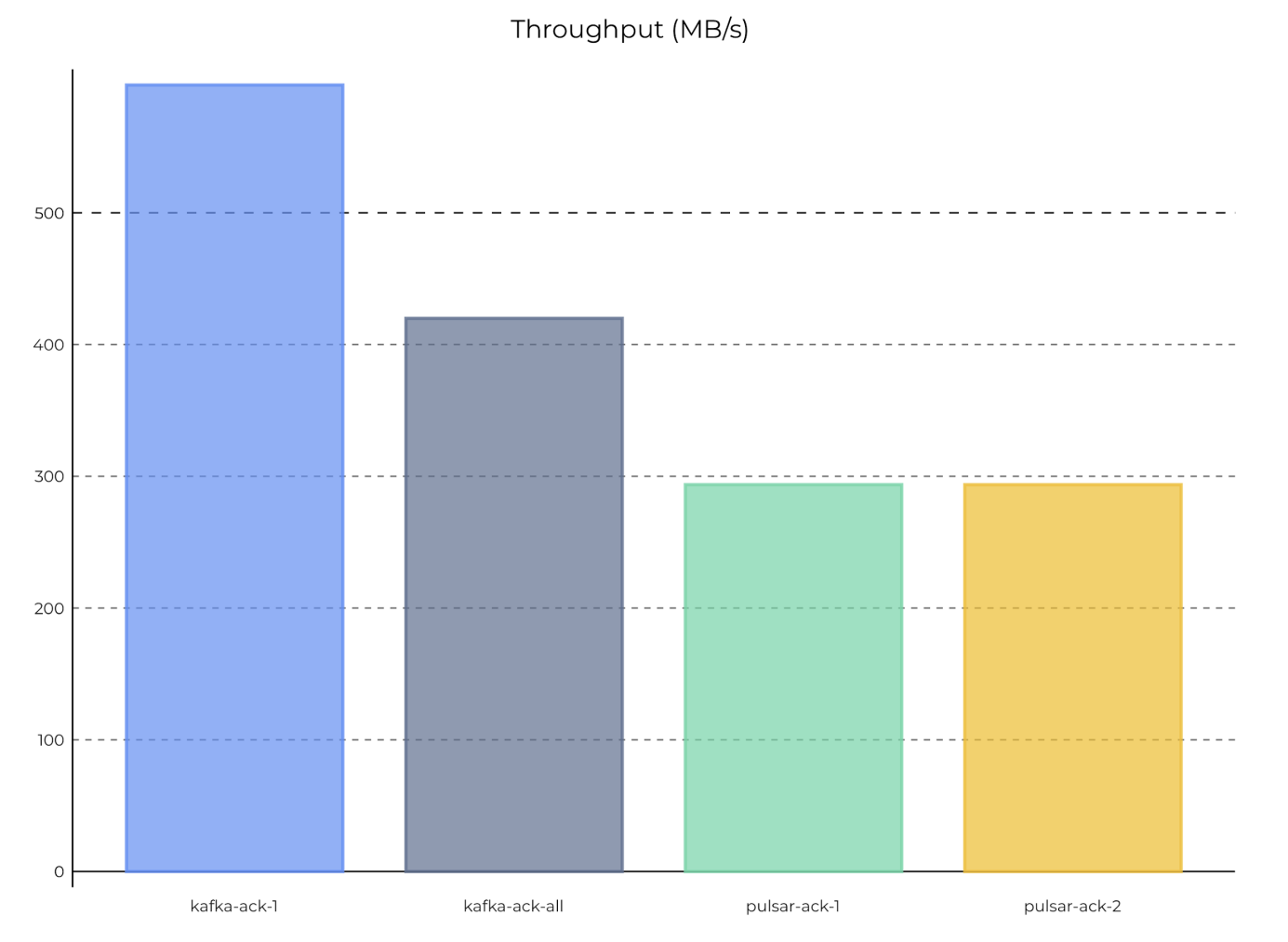
图 1 有 100 个分区时,Pulsar 和 Kafka 的最大吞吐量(同步本地持久性)
图 2 为 100 个分区,异步本地持久性下,Pulsar 和 Kafka 的最大吞吐量。
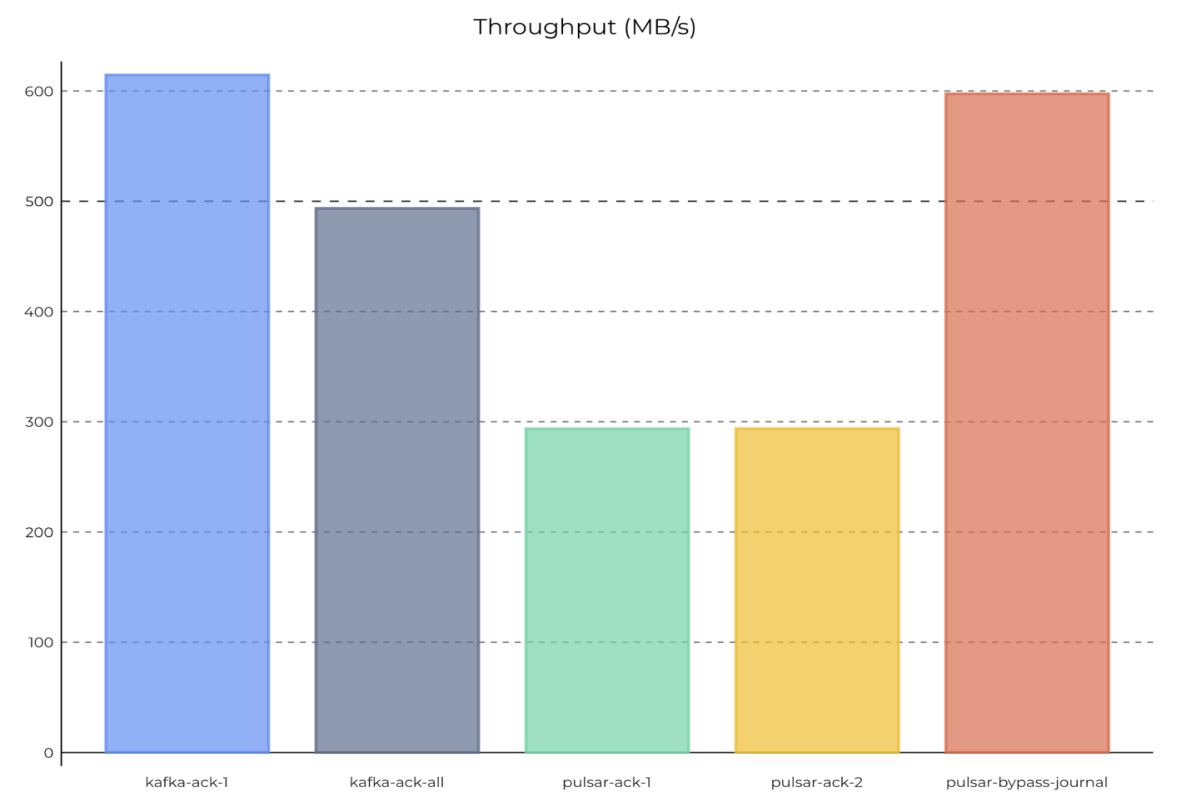
图 2 100 个分区时,Pulsar 和 Kafka 的最大吞吐量(异步本地持久性)
#2 2000 个分区,1 个订阅,2 个生产者/2 个消费者
分区数量从 100 增加到 2000,持久性保证不变(acks = 2),分别观测 Pulsar 和 Kafka 的最大吞吐量。在 Pulsar 和 Kafka 中,都使用 1 个订阅、两个生产者和两个消费者。测试结果如下。
在 1 级持久性保证下,Pulsar 的最大吞吐量保持在约 300 MB/s,在 2 级持久性保证下则增加到约 600 MB/s;
单独为每条消息刷新数据时(kafka-ack-all-sync),Kafka 的最大吞吐量从 600MB/s (100 个分区) 降到了 300MB/s 左右;
使用系统默认的持久性设置(kafka-ack-all-nosync)时,Kafka 的最大吞吐量从约 500 MB/s(100 个分区)下降到约 300 MB/s。
为了了解 Kafka 吞吐量下降的原因,我们绘制了 Kafka 和 Pulsar 在每一持久性保证下的平均发布延迟图。图 3 表明,分区数量增加到 2000 时,Kafka 的平均发布延迟增加到 200 毫秒,P99 发布延迟增加到 1200 毫秒。
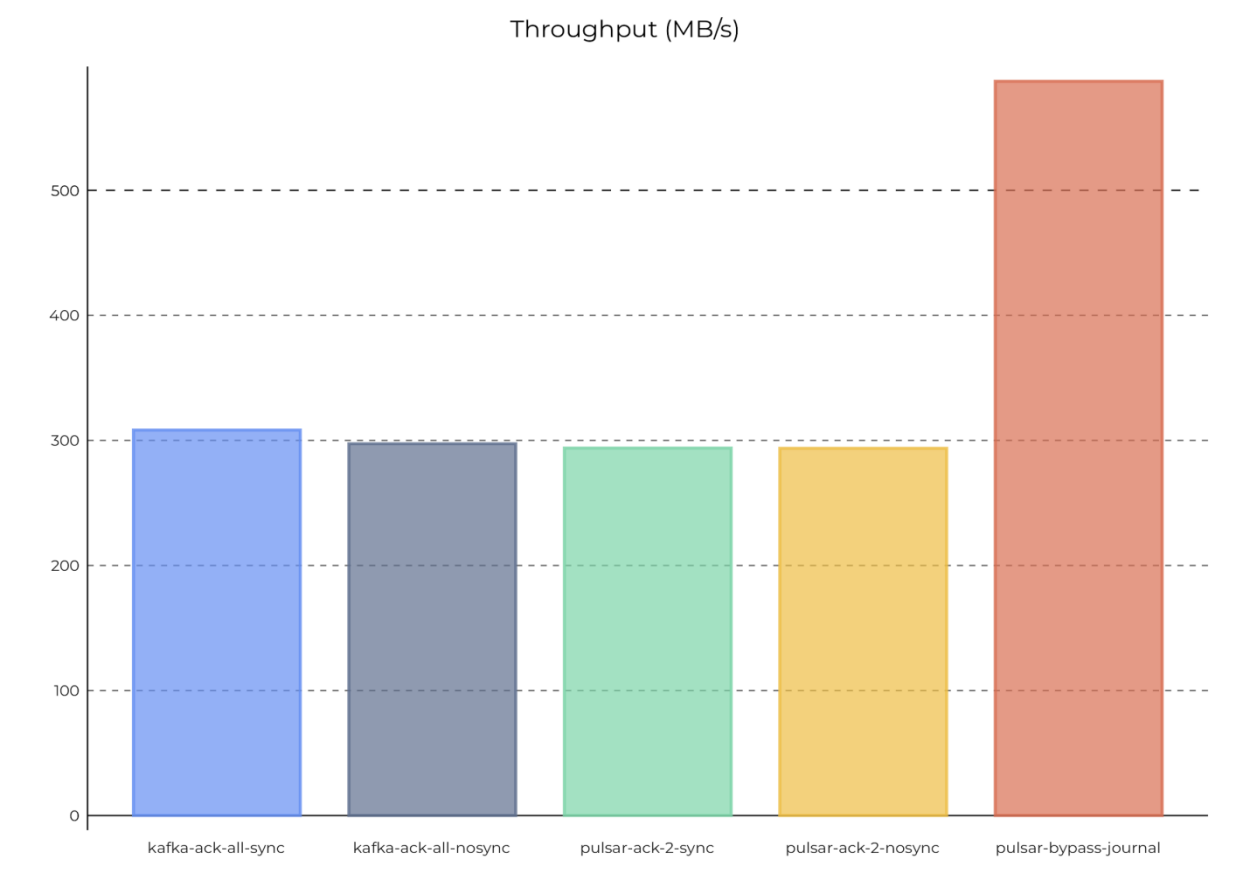
图 3 2000 个分区时,Pulsar 和 Kafka 的最大吞吐量
发布延迟通常会对吞吐量造成显著影响。但由于 Pulsar 客户端充分利用了 Netty 强大的异步网络框架,Pulsar 的吞吐量没有受到影响。而 Kafka 客户端使用同步实现,Kafka 的吞吐量的确受到影响。把 producer 数量增加一倍可以提高 Kafka 的吞吐量。如果生产者数量增加到 4 个,Kafka 的吞吐量能达到约 600 MB/s。
图 4:2000 个分区时,Pulsar 和 Kafka 的发布延迟
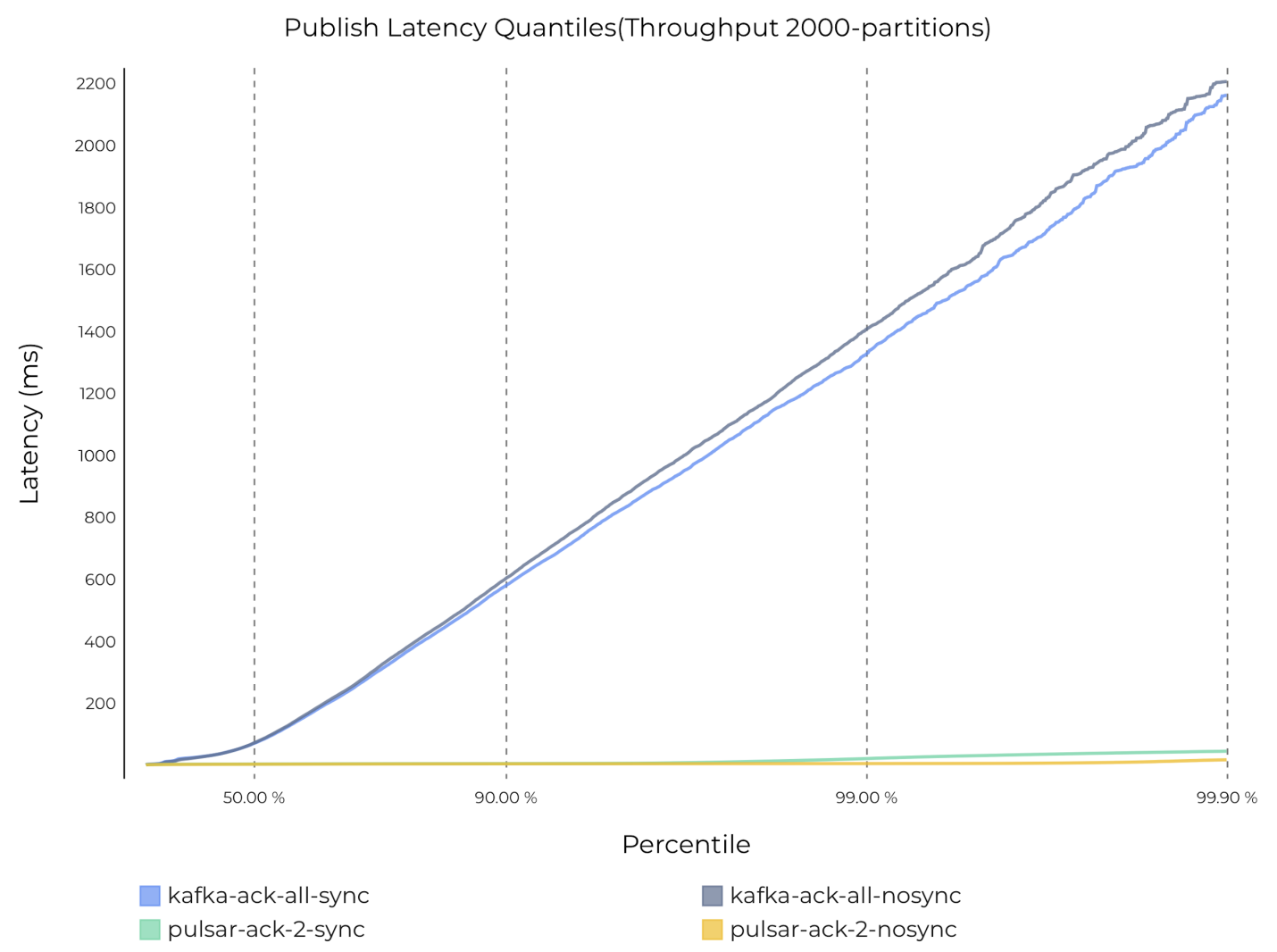
图 4 2000 个分区时,Pulsar 和 Kafka 的发布延迟
#3 1 个分区,1 个订阅,2 个生产者/2 个消费者
增加更多 broker 和分区有助于提高 Pulsar 和 Kafka 的吞吐量。为了更深入地了解这两个系统的效率,我们把分区数量设为 1,观测 Pulsar 和 Kafka 的最大吞吐量。在 Pulsar 和 Kafka 中,都使用 1 个订阅、2 个生产者和 2 个消费者。
测试结果如下:
在所有持久性级别,Pulsar 的最大吞吐量都达到了约 300 MB/s;
在异步复制持久性下,Kafka 的最大吞吐量达到了约 300 MB/s,但在同步复制持久性下只有约 160 MB/s。
图 5:在 1 个分区,同步本地持久性下,Pulsar 和 Kafka 的最大吞吐量
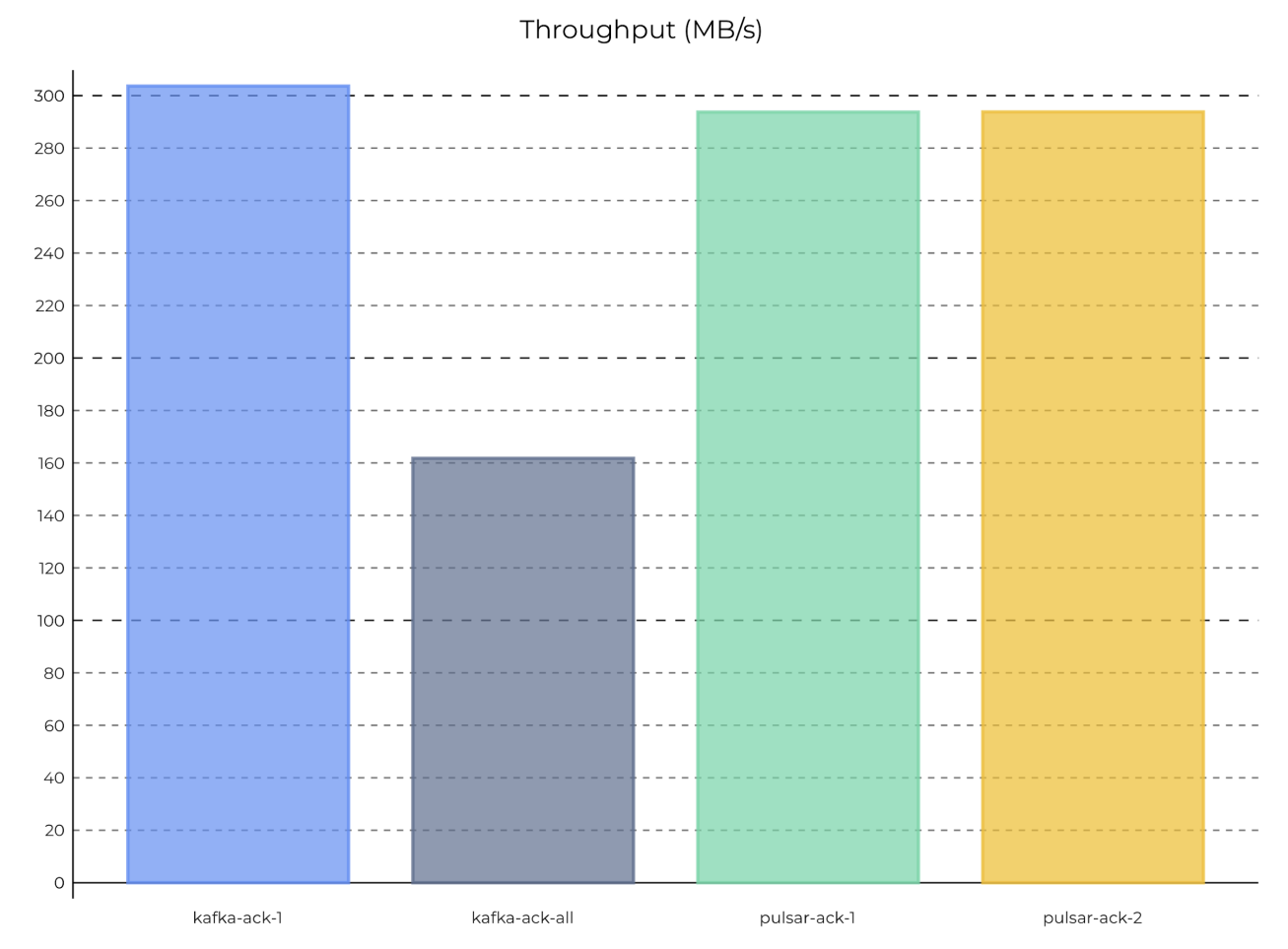
图 5 1 个分区时,Pulsar 和 Kafka 的最大吞吐量(同步本地持久性)
图 6:在 1 个分区,异步本地持久性下,Pulsar 和 Kafka 的最大吞吐量
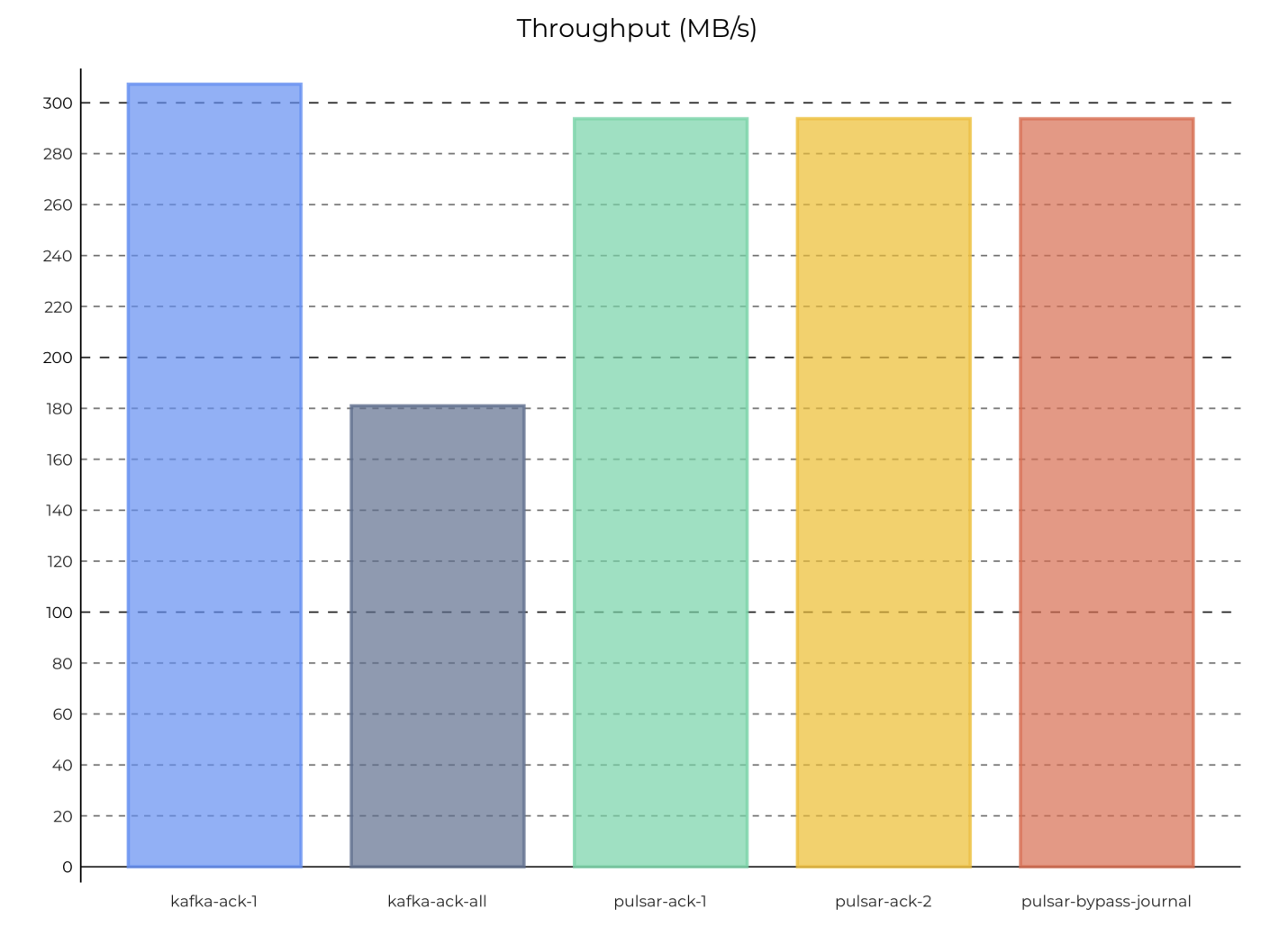
图 6 1 个分区时,Pulsar 和 Kafka 的最大吞吐量(异步本地持久性)
#4 1 个分区,1 个订阅,1 个生产者/1 个消费者
分区数量为 1,订阅数量为 1(与上个测试相同),分别观测 Pulsar 和 Kafka 的最大吞吐量。在 Pulsar 和 Kafka 中,只使用 1 个生产者和 1 个消费者。
测试结果如下:
在所有持久性级别,Pulsar 的最大吞吐量都保持在约 300 MB/s;
在异步复制持久性下,Kafka 的最大吞吐量从约 300 MB/s(测试 #3 中)下降到约 230 MB/s;
在同步复制持久性下,Kafka 的吞吐量从约 160 MB/s(测试 #3 中)下降到约 100 MB/s。
图 7 为在同步本地持久性,一个分区、一个生产者和一个消费者的情况下,Pulsar 和 Kafka 的最大吞吐量
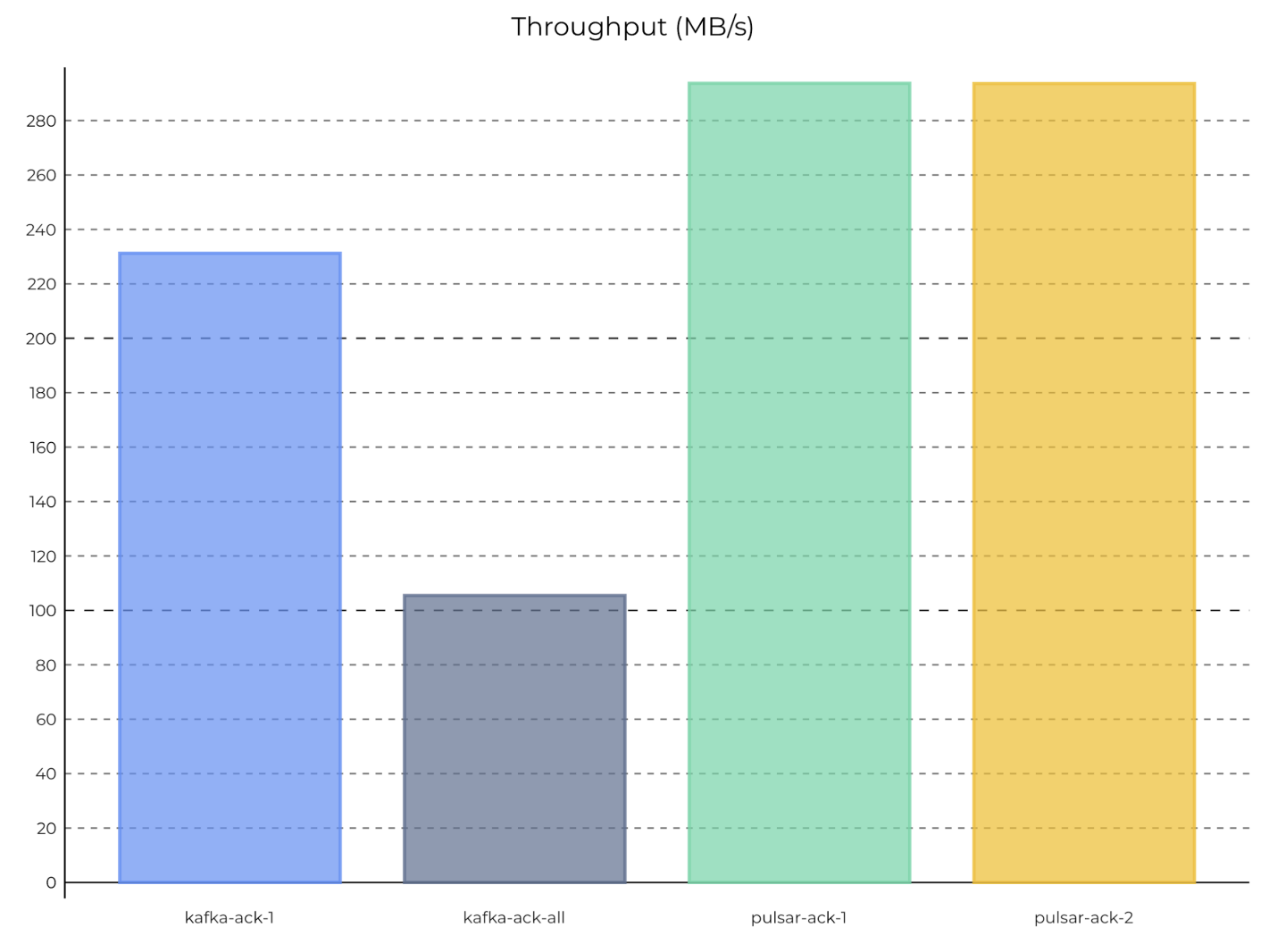
图 7 一个分区、一个生产者和一个消费者时,Pulsar 和 Kafka 的最大吞吐量(同步本地持久性)
为了了解 Kafka 吞吐量下降的原因,我们绘制了 Kafka 和 Pulsar 在不同持久性保证下的平均发布延迟图(图 8)和端到端延迟图(图 9)。从下图中可以看到,即使只有一个分区,Kafka 的发布延迟和端到端延迟也从几毫秒上升到了几百毫秒。减少生产者和消费者数量会对 Kafka 吞吐量造成显著影响。相比之下,Pulsar 的延迟始终保持在几毫秒。
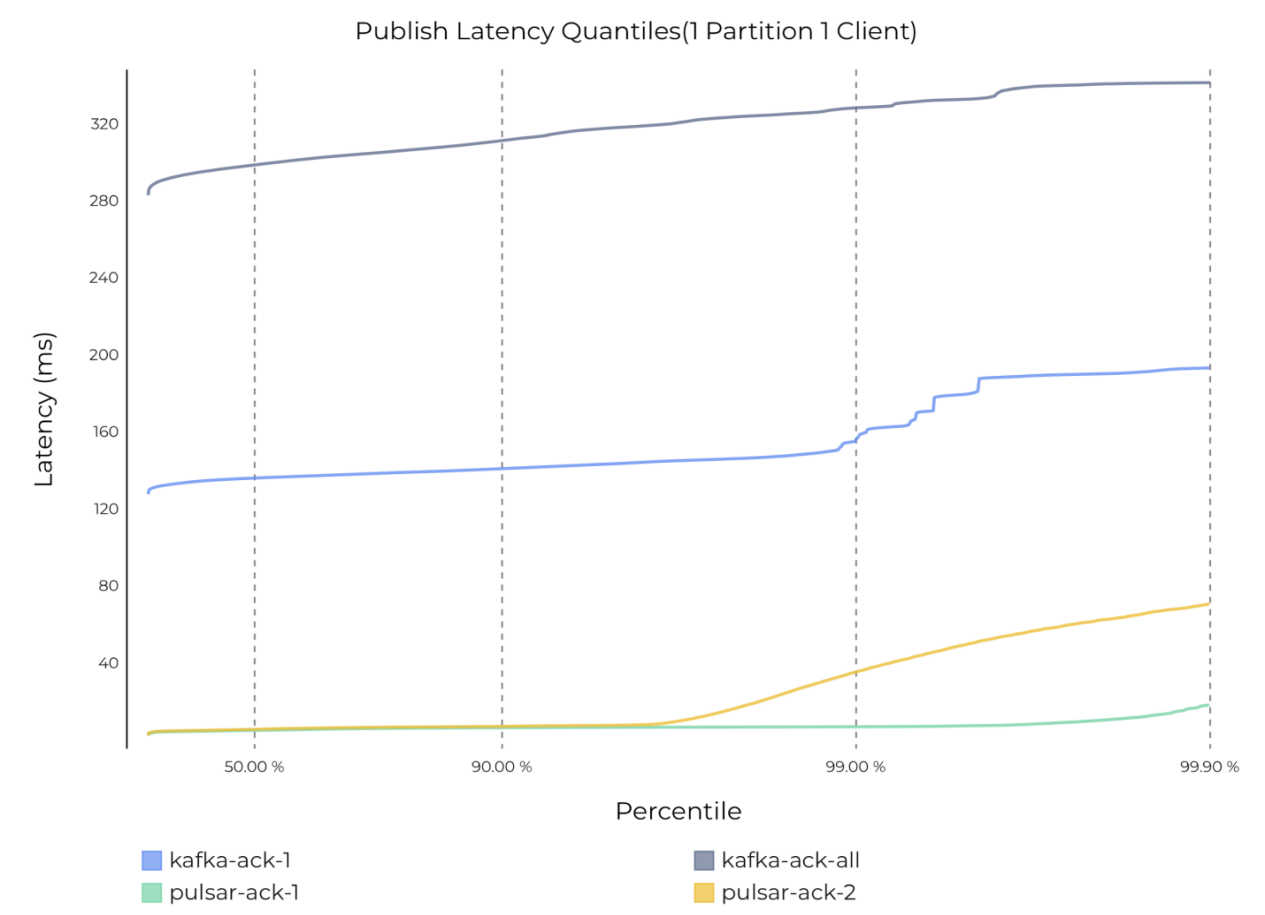
图 8 一个分区、一个生产者和一个消费者时,Pulsar 和 Kafka 的发布延迟(同步持久性)
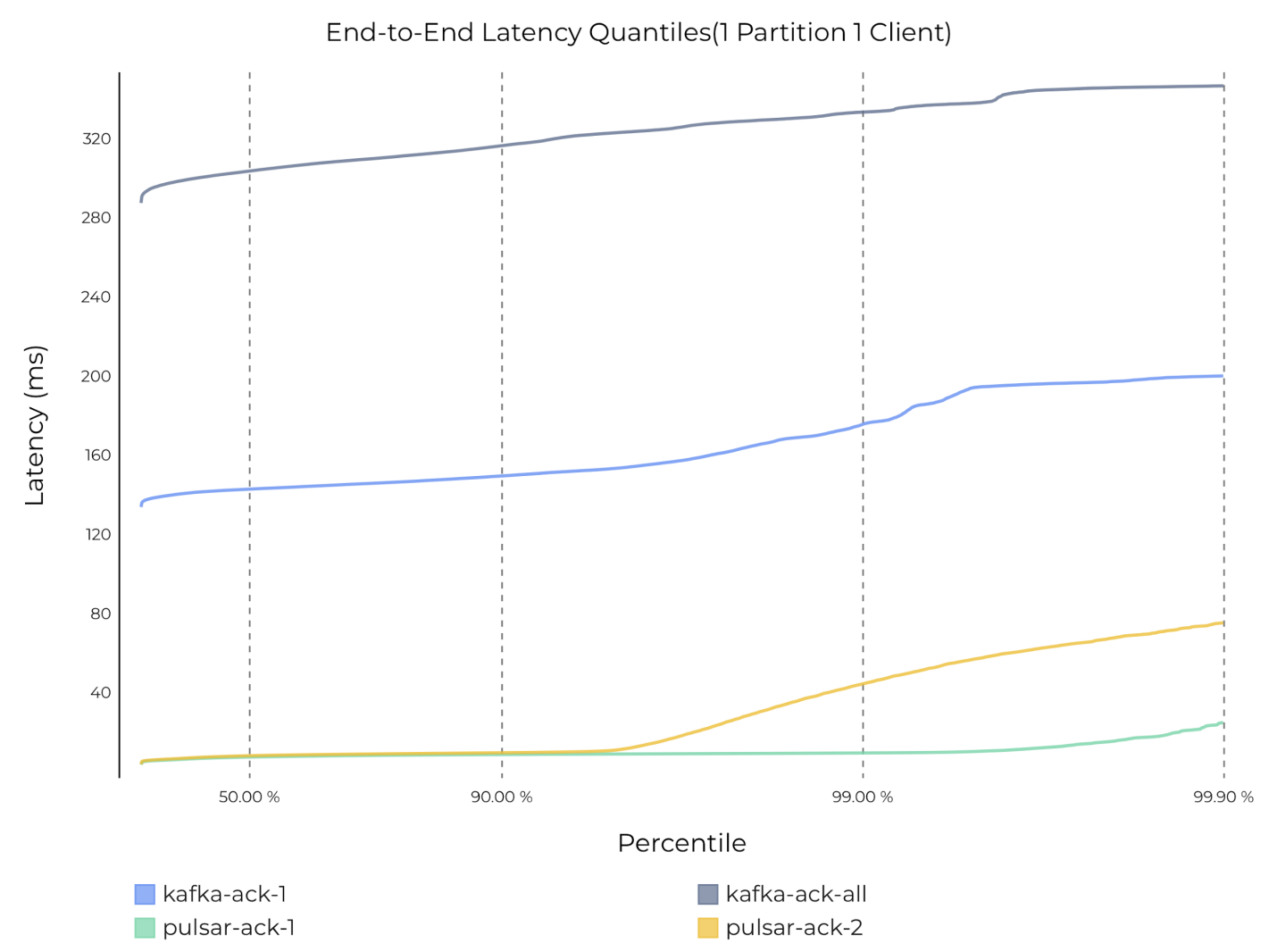
图 9 一个分区、一个生产者和一个消费者时,Pulsar 和 Kafka 的端到端延迟(同步持久性)
发布和端到端延迟测试
该测试详情参见 下篇。
追赶读测试
测试目标:观测在处理仅包括追赶读工作负载时 Pulsar 和 Kafka 可实现的最大吞吐量。
测试策略:
将所有消息都复制三次,确保容错;
改变 ack 数量,测试在不同持久性保证下,Pulsar 和 Kafka 的吞吐量变化;
启用 Pulsar 和 Kafka 的批处理,为不超过 10 ms 的响应延迟设置最大批处理为 1 MB 数据;
在 100 个分区的情况下,对两个系统进行基准测试;
共运行四个客户端--两个生产者和两个消费者;
消息大小为 1 KB。
测试一开始,生产者开始以 200K/s 的固定速率发送消息。队列中积累了 512GB 数据后,消费者开始处理数据,首先从头读取累积数据,然后在数据到达时继续处理传入数据。在测试期间,生产者持续以相同速率发送消息。
我们评估了每个系统读取 512GB 累积数据的速度,在不同持久性设置下对 Kafka 和 Pulsar 进行了比较。各项测试结果如下:
#1 启用 Pulsar 绕过 Journal 写入的异步本地持久性
本项测试中,我们在 Pulsar 和 Kafka 上使用了同等的异步本地持久性保证。我们启用了新的 Pulsar 绕过 Journal 写入,来匹配 Kafka 默认 fsync 设置中的本地持久性保证。
下图 33 给出了测试结果:
只处理追赶读时,Pulsar 的最大吞吐量达到了 370 万条信息/秒(3.5 GB/s)。
Kafka 的最大吞吐量只达到 100 万条消息/秒(1GB/s)。
Pulsar 处理追赶读的速度比 Kafka 快 75%。
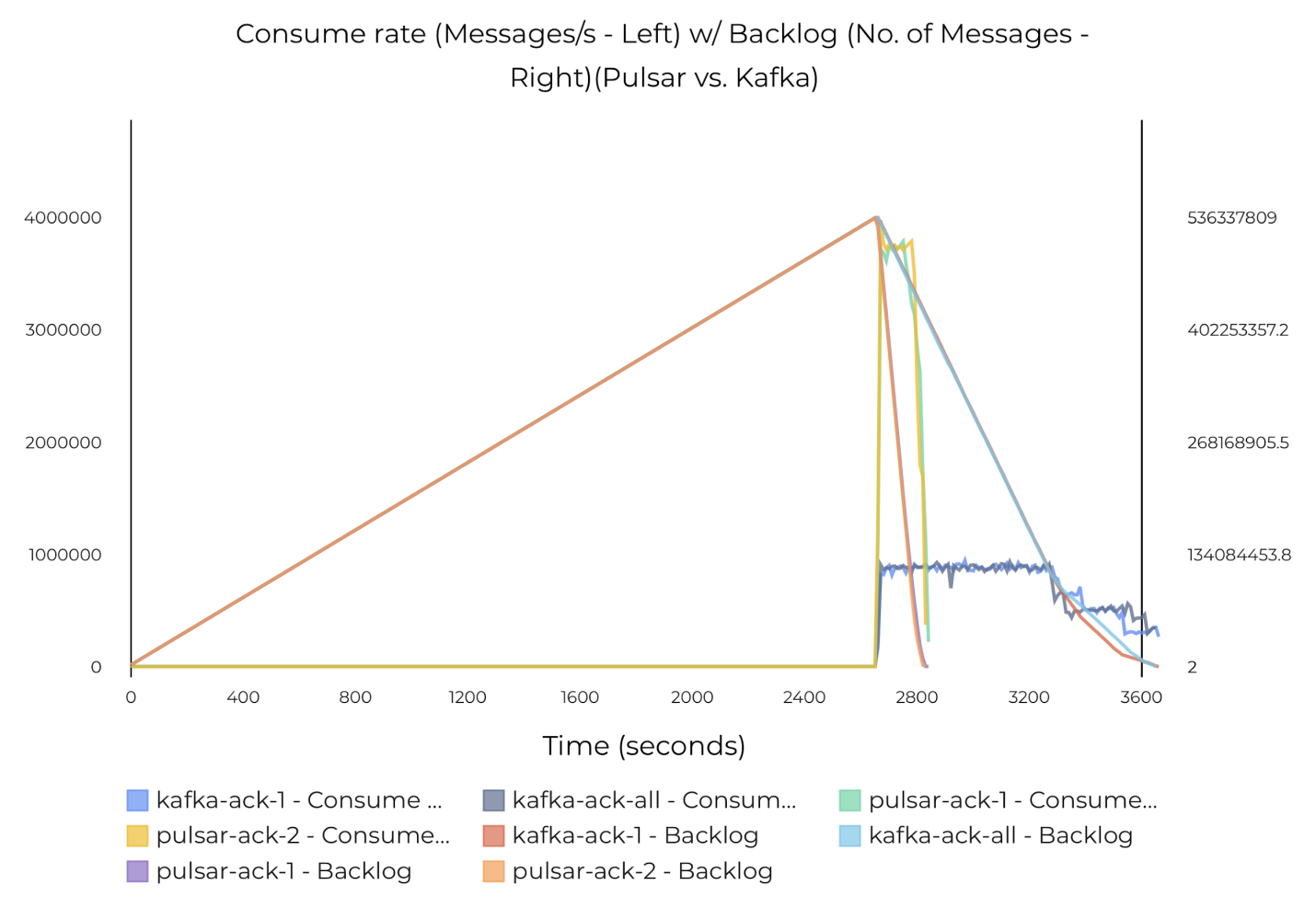
图 33 Pulsar 和 Kafka 的追赶读吞吐量(绕过 Journal 写入)
#2 未启用 Pulsar 绕过 Journal 写入的异步本地持久性
本项测试中,我们在 Pulsar 和 Kafka 上使用了异步本地持久性保证,但并未启用 Pulsar 绕过 Journal 写入。
下图 34 给出了测试结果:
处理追赶读时,Pulsar 的最大吞吐量达到 180 万条信息/秒(1.7 GB/s)。
Kafka 的最大吞吐量仅达到 100 万条消息/秒(1GB/s)。
Pulsar 处理追赶读的速度是 Kafka 的两倍。
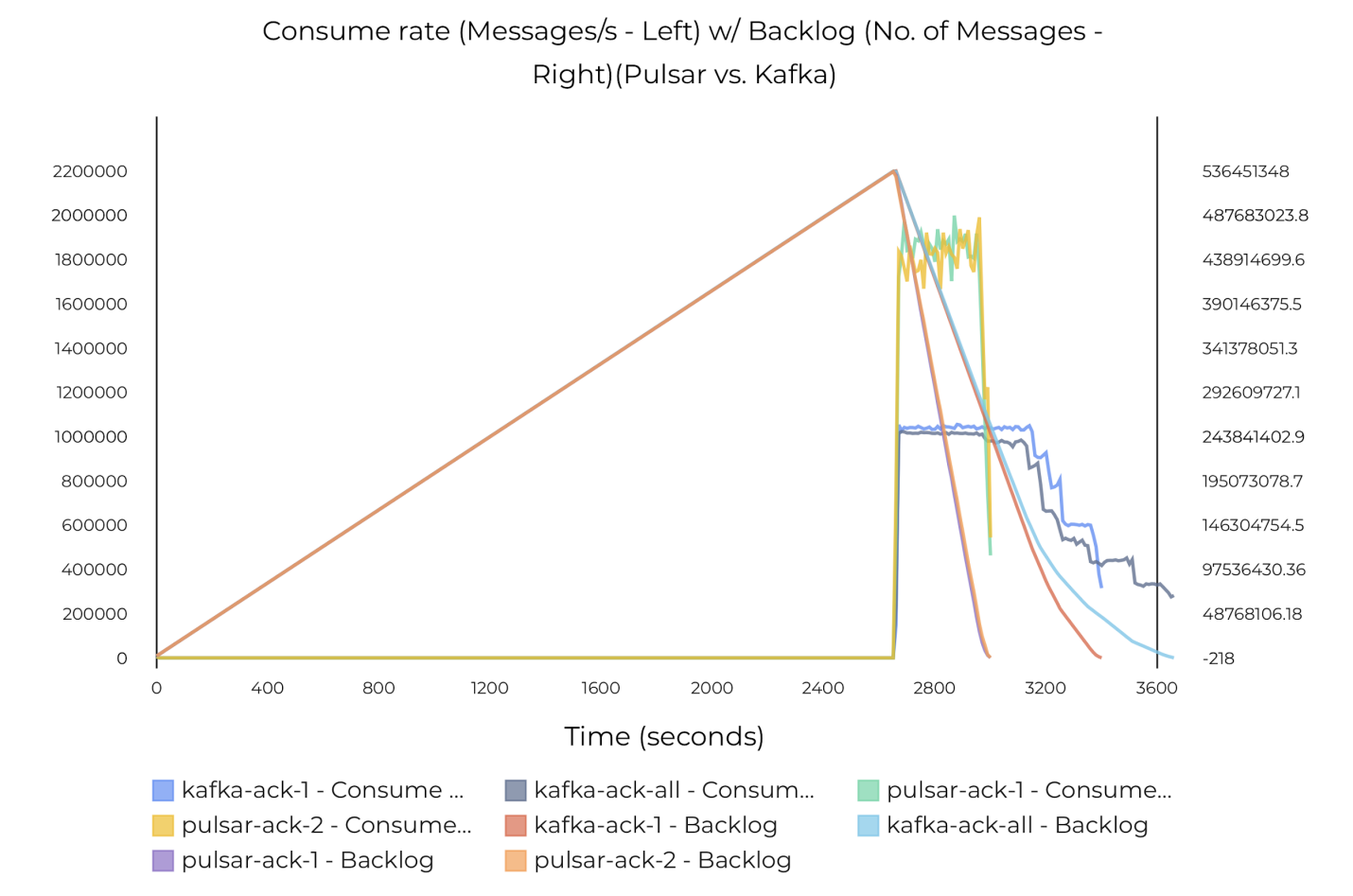
图 34 Pulsar 和 Kafka 的追赶读吞吐量(数据同步)
#3 同步本地持久性
本项测试中,我们在同等同步本地持久性保证下对 Kafka 和 Pulsar 进行了比较。
下图 35 给出了测试结果:
只处理追赶读时,Pulsar 的最大吞吐量达到 180 万条/秒(1.7 GB/s)。
Kafka 的最大吞吐量只达到 100 万条消息/秒(1GB/s)。
Pulsar 处理追赶读的速度是 Kafka 的两倍。
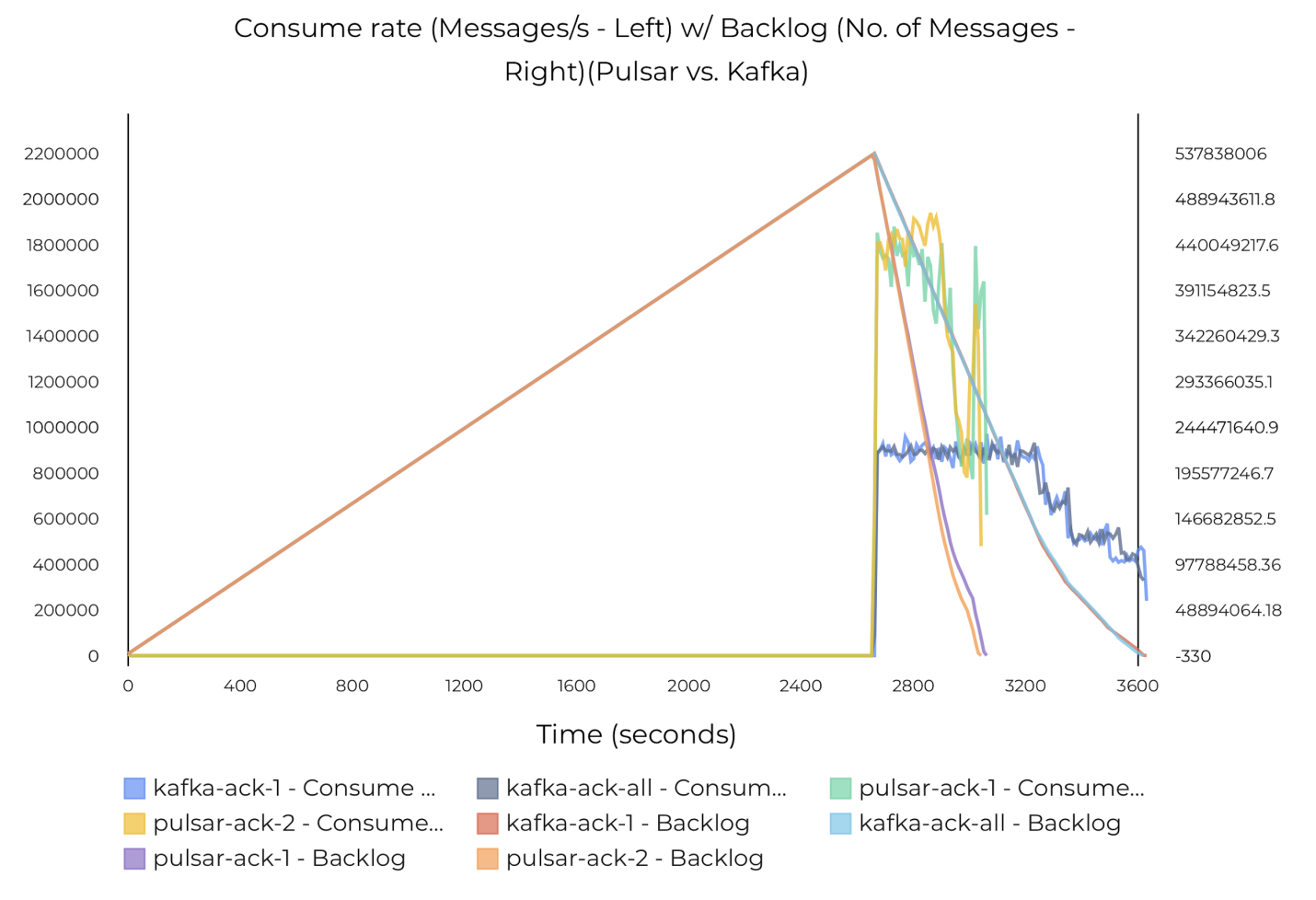
图 35 Pulsar 和 Kafka 的追赶读吞吐量(无数据同步)
混合工作负载测试
测试目标:评估追赶读对混合工作负载中的发布和追尾读的影响。
测试策略:
将所有消息都复制三次,确保容错;
启用 Pulsar 和 Kafka 的批处理,为不超过 10 ms 的响应延迟设置最大批处理为 1 MB 数据;
在 100 个分区的情况下,对两个系统进行基准测试;
在不同耐久性设置下对 Kafka 和 Pulsar 进行比较;
共运行四个客户端--两个生产者和两个消费者;
消息大小为 1 KB;
测试一开始,两个生产者均开始以 200K/s 的固定速率发送数据,两个消费者中有一个立即开始处理追尾读。队列中积累了 512GB 数据后,另一个(追赶读)消费者开始从头读取累积数据,然后在数据到达时继续处理传入数据。在测试期间,两个生产者持续以相同的速率发布,而追尾读消费者继续以相同的速率消费数据。
测试结果如下:
#1 启用 Pulsar 绕过 Journal 写入的异步本地持久性
本项测试中,我们在同等异步本地持久性保证下对 Kafka 和 Pulsar 进行了比较。我们启用了新的 Pulsar 绕过 Journal 写入,来匹配 Kafka 默认 fsync 设置的本地持久性保证。
下图 36 显示,追赶读对 Kafka 写入造成显著影响,但对 Pulsar 影响很小。Kafka 的 P99 发布延迟增加到 1-3 秒,而 Pulsar 的延迟则稳定在几毫秒到几十毫秒间。
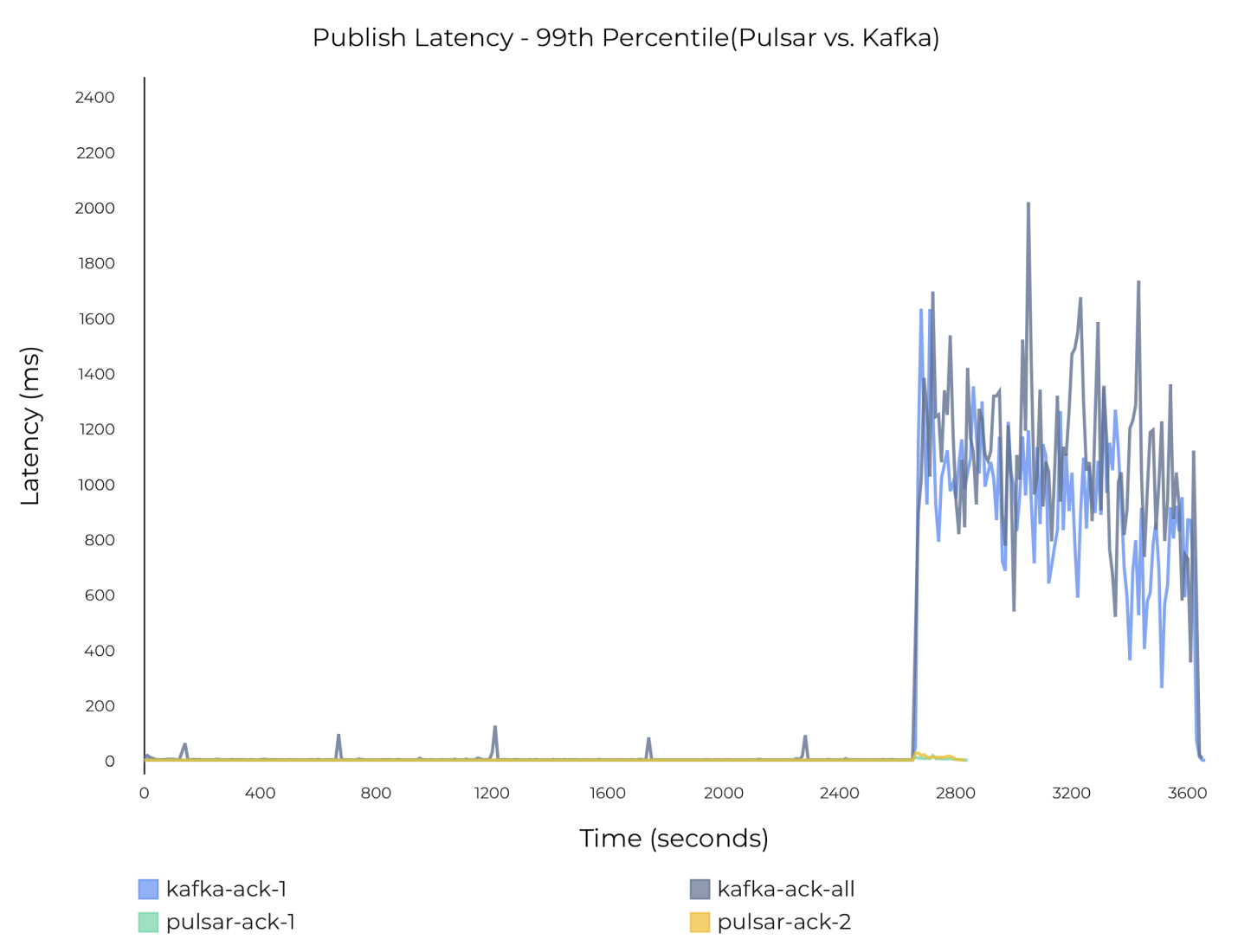
图 36 追赶读对 Pulsar 和 Kafka 发布延迟的影响(绕过 Journal 写入)
#2 未启用 Pulsar 绕过 Journal 写入的异步本地持久性
本项测试中,我们在 Pulsar 和 Kafka 上使用了异步本地持久性保证,但未启用 Pulsar 绕过 Journal 写入。
下图 37 显示,追赶读对 Kafka 写入造成显著影响,但对 Pulsar 影响很小。Kafka 的 P99 发布延迟增加到 2-3 秒,而 Pulsar 的延迟则稳定在几毫秒到几十毫秒之间。
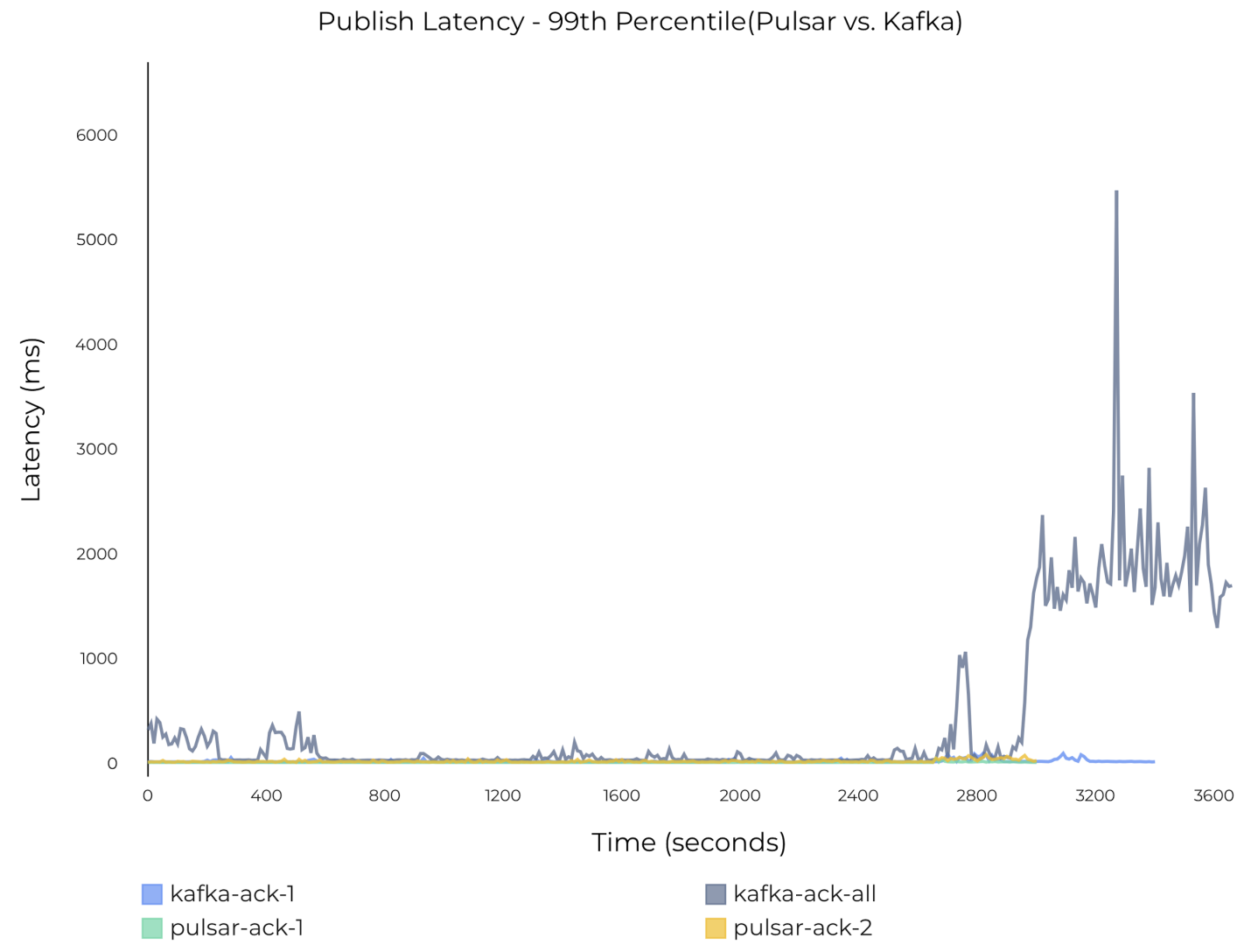
图 37 追赶读对 Pulsar 和 Kafka 发布延迟的影响(数据同步)
#3 同步本地持久性
本项测试中,我们在同等同步本地持久性保证下对 Kafka 和 Pulsar 进行了比较。
下图 38 显示,追赶读对 Kafka 写入造成显著影响,但对 Pulsar 影响很小。Kafka P99 发布延迟增加到约 1.2 至 1.4 秒,而 Pulsar 的延迟则稳定在几毫秒到几十毫秒之间。
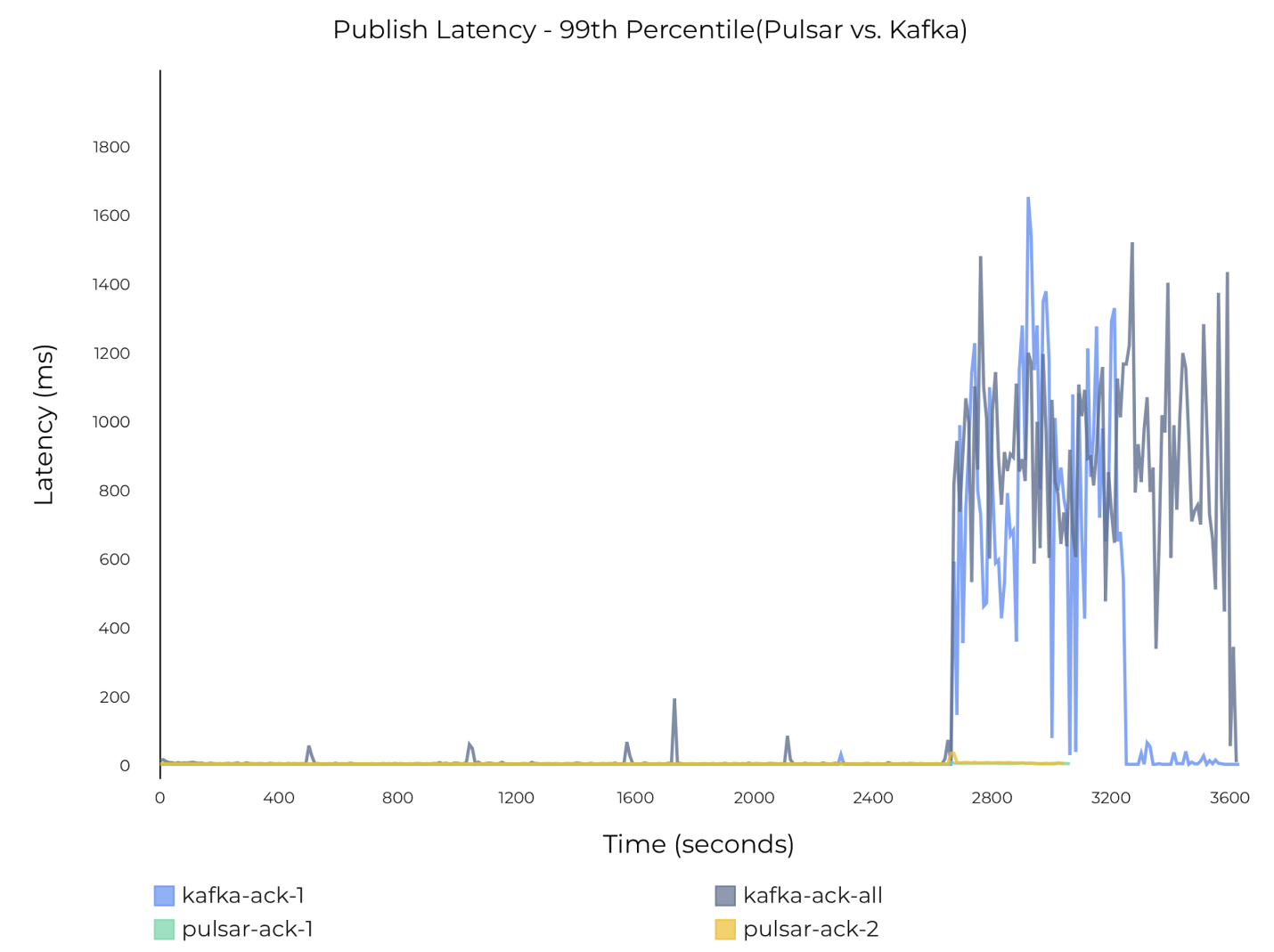
图 38 追赶读对 Pulsar 和 Kafka 发布延迟的影响(无数据同步)
结论
基于基准测试结果,我们得出以下结论:
纠正配置和调优错误后,Pulsar 与 Kafka 在 Confluent 有限测试用例中实现的端到端延迟基本一致。
在同等持久性保证下,Pulsar 在模拟实际应用场景的工作负载上性能优于 Kafka。
以上测试中,改变了持久性保证设置、订阅、分区和客户端数量,结果表明 Pulsar 在延迟和 I/O 隔离方面均明显优于 Kafka。
原文链接:https://streamnative.io/en/blog/tech/2020-11-09-benchmark-pulsar-kafka-performance-report




