
一、概述
在软件开发过程中,经常会遇到需要执行定时任务的场景。目前业界执行定时任务的分布式任务调度平台主要有 XXL-Job 和 Elastic-Job,两者都属于轻量级的调度平台,能满足一定任务数量的作业同时调度,但是如果任务调度量增加到 1 万 TPS 甚至 10 万 TPS,就会遭遇性能瓶颈,出现很多超时任务。
在 OPPO 内部,有些业务部门存在海量作业同时调度的场景,目前业界的任务调度框架难以满足业务需求,所以 OPPO 公司的中间件团队自主研发了一个分布式任务调度平台 CloudJob,它是一个高性能(百万级 TPS)、低延迟(毫秒级)、统一、稳定、精准并满足复杂多样定时任务场景的调度平台。
它的特点如下:
(1)简单:用户可以通过页面对任务进行 CRUD 操作,也可以通过提供的 SDK 对任务进行管理,方便快捷。
(2)动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效。
(3)一致性:“调度中心”通过分布式锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行。
(4)高性能、低延迟:支持百万级任务同时调度执行,且延迟在毫秒级。
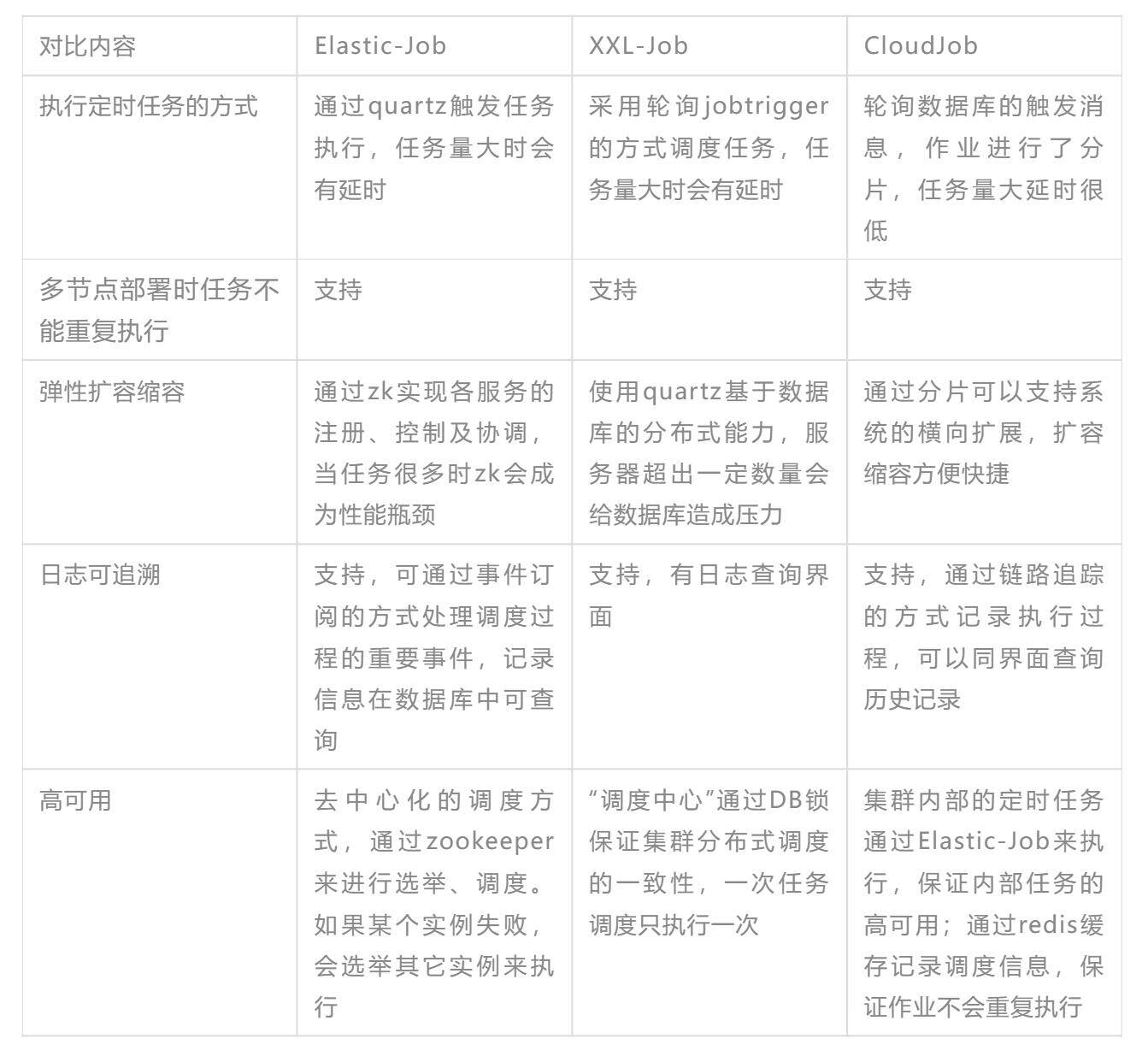
1.1 和开源产品对比
CloudJob 设计的初衷是为了支持海量任务同时调度,它和其它任务调度平台的对比如下:
1.2 CloudJob 的性能
在公司内部对 CloudJob 进行了多轮性能测试,通过对测试数据进行分析,CloudJob 的性能如下:
(1)低时延:CloudJob 在处理 TPS 为 50W 的作业调度时,99.11% 的作业调度延时在 1 秒以内; CloudJob 处理上亿次调度,最大调度延时不超过 2.4 秒。
(2)高性能:对比 Elastic-Job 的单个执行器执行上千个任务就会出现大量延时,CloudJob 的单个执行器处理上万个任务仍然可以保证毫米级调度任务而不超时。
(3)扩展能力强:性能测试场景 TPS 由 10 万增加到 50 万,系统只需要按比例增加执行器个数,依然可以保证作业正常调度而不出现严重超时。
(4)高可用:测试过程中将某个执行器宕机,该执行器的作业可以转移到其它设备调度,并且调度延时最大不超过 3 秒。
二、系统架构
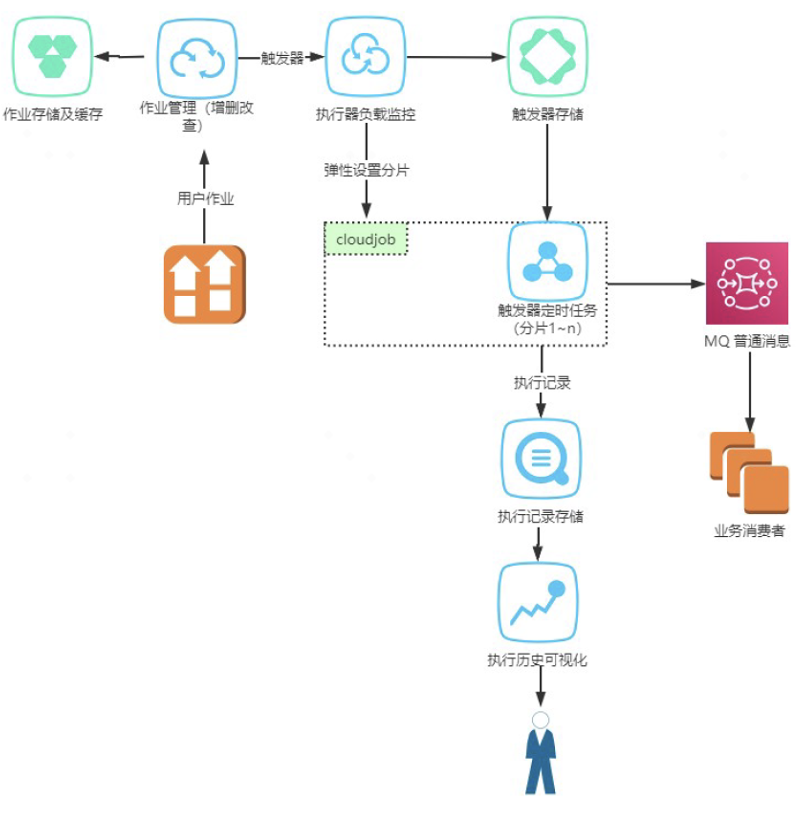
CloudJob 的总统架构如下:
2.1 名称解释
作业元数据:指作业执行的时间规则以及业务执行需要透传的参数,存在于 mongodb 数据库及缓存中。
作业触发消息:指作业按照时间规则计算出的产生触发执行动作的每一条记录,包含作业主键和执行绝对时间时间戳,比如每 5s 执行一次任务,第 5s 和第 10s 是两个触发器。
执行器:用于扫描符合条件的作业触发器的服务所在的容器。
分片:为了让系统可以横向扩展,需要将作业划分到不同的分组,每个分组就是一个分片,同时每个执行器设置一个分片属性(和作业的分片属性相对应),执行器只处理自己所在分片对应的作业。
定时任务执行周期:运行在执行器的定时任务每隔多久运行一次。本方案中该值的设置主要和触发器存储选型有关,应该设置合适的频率,避免过于频繁导致写入和存储触发器时延时较大,同时也不能因为过大,导致一些本应该执行的任务不能被及时获取,出现触发延迟太多。
时间窗口:定时任务扫描触发器的时间条件,选出将来一定时间范围内的数据。注意这个窗口最好不一定等于定时任务的执行周期。
2.2 服务模块组成
作业管理服务:负责作业增删改查,用户可以通过作业管理服务将作业注册到平台,平台将作业持久化到 mongodb 数据库并在 redis 中缓存。
执行器负载监控服务:在 CloudJob 平台中每个执行器会处理一个数据分片,执行器负载监控服务会将作业划分到不同分片,分片内作业数量将维持在合理的数量范围,保证作业按照时间规则发送而不延迟。该服务负责分片的作业容量管理以及分片扩缩容等功能。
触发器存储:支持可插拔的存储,提供高可用方案,保证数据零丢失。
触发器定时任务:执行器定时执行的操作,主要是扫描 mongodb 数据库,生成作业触发消息。
执行记录存储:记录发送到业务 MQ 的消息,核对是否有漏发送、发送是否有延迟等,发现系统可能存在的问题并及时对整个系统完善优化。
执行记录可视化:通过页面查看、查询作业的历史记录,查看作业是否超时,是否由漏执行。
通过对上面几个服务模块的说明,可以看出作业在系统中的流转过程如下:

用户先通过作业管理服务将作业注册到 mongodb 数据库中,并通过 redis 来缓存作业。执行器负载监控服务对新添加的作业设置分片,获取当前系统未饱和的最小分片,将这个分片的 id 设置为这个作业的分片,同时将分片对应的作业数量加 1。多个执行器会根据设置好的分片参数定时从 mongodb 数据库中扫描出符合条件的作业,然后根据作业的时间表达式生成作业触发消息,然后将触发消息写入到时间轮中,最后在作业达到执行时间时将作业的基本信息投送到消息队列中,让用户从消息队列取出消息并执行自己的业务逻辑,从而达到触发作业调度的目的。
三、数据流转举例
定时任务按照执行次数可以分为固定周期类型和固定延迟类型。固定周期类型是指作业按照一定的周期每隔一段时间执行,固定延迟类型是指会在延迟一段时间后,执行一次,随后就不会再执行。下面举例说明这两种类型的任务是如何流转的。
3.1 固定周期类型
用户创建了一个固定周期类型的任务,每隔 5s 执行一次,携带的参数为:
作业管理服务先投递到 MQ 普通消息。消费者持久化该条数据,获得主键 jobpk1,计算出来该定时任务后续的触发时间戳为 1612493460,存储到触发器的存储中,必要字段为:
执行器上的定时任务在做扫描时,扫描到了该条触发器数据,判断是否到了预期投递时间,如果已经到了直接投递到业务 MQ,否则将它压入内存时间轮中,时间轮中到了预期投递时间,再投递到业务 MQ。再计算下次触发时间戳为 1612493465,将 redis 中的数据修改为:
执行器上的本轮定时任务处理完毕后 1,处理下一轮:拉取到 1612493465 这一次时间戳,随后重复上面的逻辑,或者发送 MQ 消息或者压入时间轮,依次往下。
3.2 固定延迟类型
用户创建了一个固定延迟类型的任务,再 15s 钟之后执行,携带的参数如下:
作业管理服务先投递到 MQ 普通消息。消费者持久化该条数据,获得主键 jobpk1,计算出来该定时任务后续的触发时间戳为 1612493475,存储到触发器的存储中,必要字段为:
执行器上由 cloudjob 调度的定时任务在做扫描时,扫描到了该条触发器数据,判断是否到了预期投递时间,如果已经到了直接投递到业务 MQ,否则将它压入内存时间轮中,时间轮中到了预期投递时间,再投递到业务 MQ。由于是固定延迟,没有下次执行,将 redis 中的数据修改为:
执行器上的本轮定时任务处理完毕后,处理下一轮:拉取的时间戳要大于 0,则这个作业以后不会被扫描到。在异步记录任务时,会将该 redis 中为 0 的这个 member 删除,并把元数据该作业的状态设置为完结。
四、服务部署及实施流程
通过前面的介绍大家知道了 CloudJob 的工作原理,下面通过几个模块的部署来说明一下具体的实施过程。
4.1 作业初始化
业务的作业通过作业管理服务接口批量注册。作业管理接收到请求后发送到 MQ 普通消息,由消费者完成如下步骤:
由于作业总数百万级别,需要将作业划分到不同分片上,每一个作业在注册进来时需要获取到尚未饱和的分片。分片的数量是由执行器负载服务管理的。假设一个分片的负载容量为 1 万,在分片承载的作业没达到 1 万之前,作业都可以被分到这个分片上。如果达到这个阈值,分片被设置为饱和状态,需要分配新的分片,新的作业将被分配到新的分片上。具体过程如下:
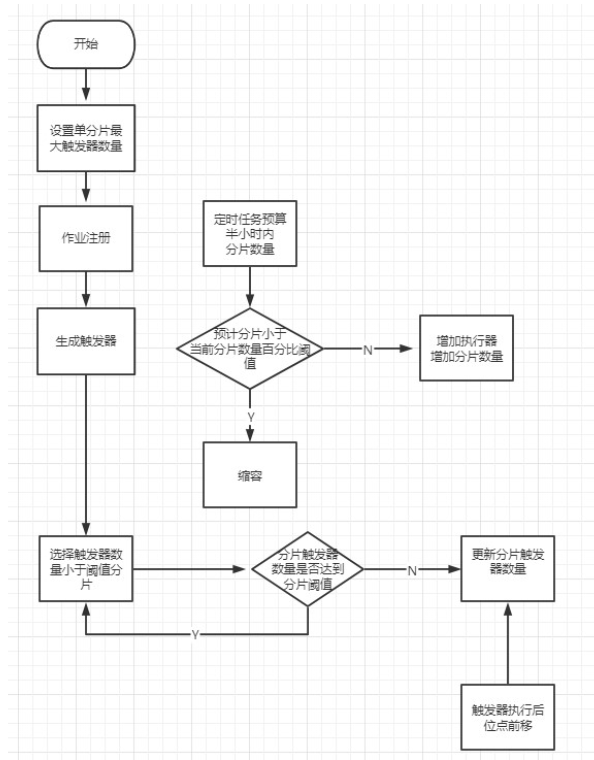
假设新增一个 5s 执行一次的作业时,获取到了 sharding1 分片,将会在 DB 中存储元信息同时缓存元信息。数据为:
Version0 表示该作业元信息是首次存入,以后每修改一次这个 version 递增。计算下次触发时间并在触发器缓存中存入如下数据:zset 名称 sharding1,member 为 jobpk1_0,是作业主键和 version 的组合,可以采用高位存主键,地位存版本号的方式。score 为下次触发时间戳 1612493460。
4.2 执行器高可用
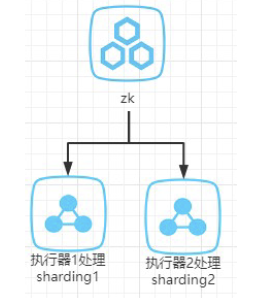
执行器会定时扫描 mongodb 数据库,从数据库中获取符合条件的任务,这个定时任务是由 Elastic-Job 来分配执行的,Elastic-Job 将分片分配到了各个执行器中,假设是下面这种分配模型:两个执行器均分了两个分片,执行器 1 只处理具有分片属性 sharding1 的触发器,执行器 2 同理。当执行器 1 出现宕机时,Elastic-Job 将会触发失效转移,分片 1 将会分配给执行器 2,此时执行器 2 会有两个线程分别处理分片 1 和分片 2。如果执行器后面启动成功,Elastic-Job 将会重新分片,两个执行器又会均分分片。
4.3 执行器线程模型
执行器在运行时内部有两种线程,一个是定时任务扫描线程,另一个是消息队列消费线程,它们的工作模型如下:
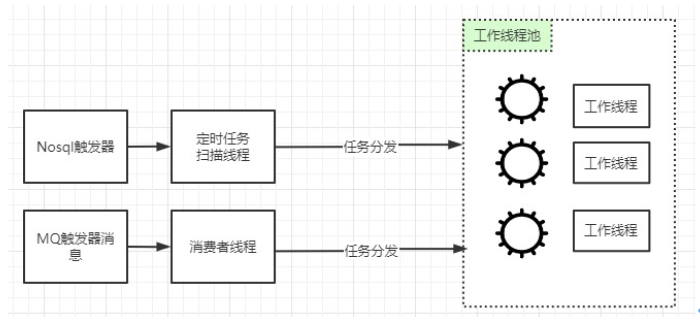
定时任务扫描线程:主要负责定时拉取触发器,随后均衡投递到对应时间轮中,一个时间轮由一个工作线程负责处理。如果出现工作线程处理时间轮中作业比较慢,出现大量堆积的情况,需要将对应分片属性设置为饱和状态,此时不会有新的作业被分配到该执行器,直到该分片重新恢复为非饱和状态。
消息队列消费线程:主要负责处理定时任务无法 cover 到的马上要执行的触发消息,比如定时任务的处理周期是 20s,现在用户提交了一个每隔 10s 执行一次的任务,这个时候系统就需要生成一个 10s 之后执行的触发消息并把它写入到消息队列中,执行器的消费线程就可以立即得到这个触发消息,及时加入到执行器的时间轮中,确保消息能够按时执行。
五、CloudJob 使用实践
在 CloudJob 分布式任务调度平台搭建好以后,用户就可以将任务部署到这个平台上。下面介绍一下用户在使用 CloudJob 过程中遇到的问题和优化方案。
5.1 集群隔离
相比与其它分布式任务调度框架,CloudJob 是一个“重量级”的调度平台,搭建一套 CloudJob 需要 MongoDB 数据库、redis 集群,消息队列以及多台主机作为执行器,如果用户的任务量非常少,这将会导致资源的浪费。所以可以采用集群隔离的方法,将各个部门的用户作业部署到一个 CloudJob 集群中,同时采用一种隔离方式让用户的作业互不影响,这样就可以合理的利用资源。
集群隔离的具体思路是先搭建一套物理集群,用户在创建作业之前需要先创建一个逻辑集群(或者选择之前已经创建好的逻辑集群),在这个逻辑集群设置限流策略、超时机制,并与物理集群关联起来,用户之后将自己的任务注册到这个逻辑集群中,任务就可以被物理集群调度,任务的限流策略、超时机制等又是以逻辑集群为单位管理的,这样就实现了集群隔离。
5.2 链路追踪与作业历史可视化
在 CloudJob 集群中,一个任务从注册到最终执行需要经过多个处理流程,为了便于排查问题和进行作业历史统计,平台需要对任务流转的各个阶段进行链路追踪,同时需要将监控数据进行持久化,便于查询作业的历史记录。链路追踪与作业历史可视化的框架如下:
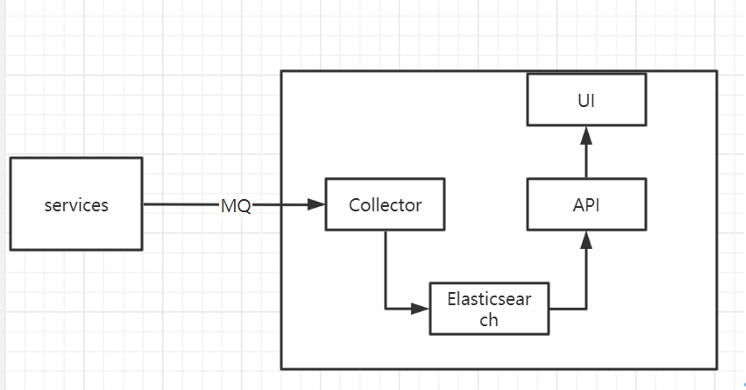
链路追踪的方案是通过埋点的方式,对系统中的主要处理流程进行记录,系统中的模块每进行一次处理就生成一条记录数据,记录数据通过消息队列定时发送到任务监控平台,任务监控平台将这些数据处理后存储到 Elasticsearch 中,为后续的统计、查询做准备。
同时平台提供了前端页面给用户进行作业历史可视化,用户可以在页面上查看作业的历史记录,查看每一次执行的调度情况,通过页面还可以查看到作业是否有漏发、严重超时。
六、 总结与展望
CloudJob 作为一个高性能、低延迟的分布式任务调度平台,通过将任务划分到不同的分片、每个执行器处理对应分片的任务,实现了系统的动态扩展和拥有海量任务调度的能力;使用定时任务扫描、时间轮、系统内部的消息队列来保证任务及时触发,保证了任务执行的低延迟;同时 CloudJob 通过 Elastic-Job 来执行系统内部的定时任务,保证执行器的高可用。
当然 CloudJob 还是有些不足,如果用户将任务部署到 CloudJob 平台上,还需要将自己的业务处理代码运行到自己的主机上,这会造成主机资源的浪费。后续 CloudJob 的演进方向就是将任务平台接入到 Serverless 平台,用户只需要在页面编辑自己的业务代码,然后点击保存,平台就会在 Serverless 中新建任务实例,将用户的代码运行在任务实例中等待接收触发消息,执行完任务后自动释放任务实例。这样既可以方便用户快速部署任务,又可以充分利用资源。
本文作者简介:
Xinchun,OPPO 高级后端工程师。目前负责分布式作业调度系统的开发,关注消息队列、redis 数据库、ElasticSearch 等中间件技术。




