
通过将 Kubernetes 集群扩展到 7500 个节点,我们为诸如GPT-3、CLIP和DALL-E这类大型模型建立了一个可扩展的基础设施,同时还支持诸如神经语言模型的缩放等迭代研究。将单个 Kubernetes 集群扩展到这样的规模是很少有人做的,这需要一些特殊的考虑,好处是机器学习团队可以在不更改代码的情况下更快地扩展。
自从我们上一篇关于扩展到 2500 个节点的文章发布之后,我们继续开发基础设施以满足研究人员的需要,在此过程中学到了更多的经验。本文总结了这些经验教训,使 Kubernetes 社区的其他成员可以从中受益,并在最后提出了我们仍然面临的问题,我们将在下一轮迭代中解决这些问题。
工作负载
描述一下我们的工作负荷,这对进一步深入研究非常重要。在 Kubernetes 中运行的应用程序和硬件与在典型的公司中遇到的情况非常不同。我们的问题和相应的解决方案可能不符合你自己的设置。
一个大型的机器学习作业跨越许多节点,在每个节点上都能访问所有硬件资源的情况下,其效率最高。这样,GPU 就可以使用NVLink进行直接的交叉通信,或者 GPU 可以使用GPUDirect与网卡进行直接通信。因此,对很多工作负载而言, pod 会占用整个节点。调度因素中没有 NUMA、CPU 或 PCIE 资源争夺。Bin-packing 或碎片化并不是常见的问题。当前的集群具有完全的对分带宽,因此我们也不需要考虑机架或网络拓扑。这就意味着,尽管我们有许多结点,但是对调度器的压力相对较小。
这就是说,kube-scheduler 压力非常大。一个新的作业可能包括同时创建数百个 pod,然后返回一个相对较低的流失率。
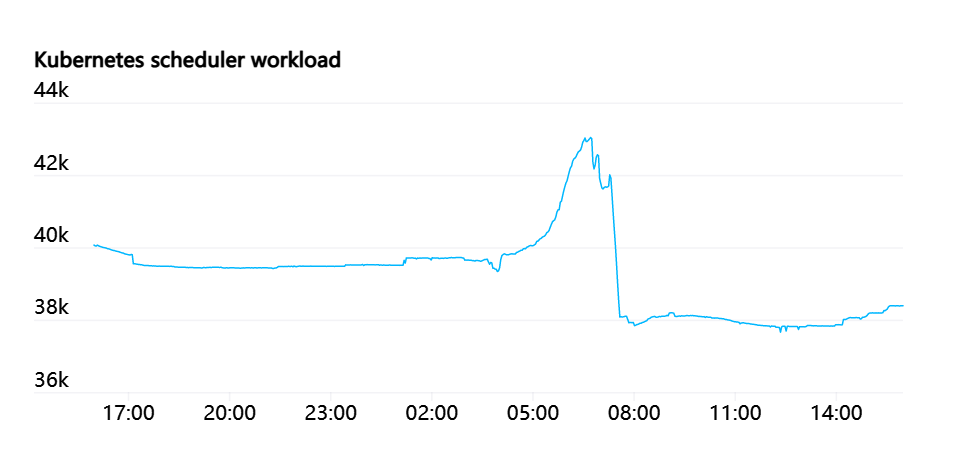
我们最大的作业运行 MPI,并且作业中的所有 pod 都参与 MPI 通信器。如果有任何 pod 被破坏,那么整个作业将停止,并且需要重新启动。这个作业定期设置检查点,并且在重新启动时从最后一个检查点恢复。所以我们认为 pod 是半静态的,被杀死的 pod 可以替换,作业可以继续,但是这样做会造成破坏,应该尽量减少。
在 Kubernetes,我们并不那么依赖负载平衡。HTTPS 流量很小,不需要 A/B 测试、蓝/绿部署或者金丝雀发布。Pod 通过 SSH,而非服务端点,与 MPI 直接在其 pod IP 地址上进行通信。对于服务的“发现”是有限制的;我们只需在作业开始时一次性查找参与 MPI 的 pod。
大多数作业都会与某种形式的 blob 存储进行交互。它们通常会直接从 blob 存储中流式传输数据集或检查点的一些碎片,或者把它们缓存在快速的本地临时磁盘上。在 POSIX 语义中,我们使用了一些 PersistentVolumes,但是 blob 存储具有更好的扩展性,并且不需要缓慢的分离/附加(detach/attach)操作。
最后,我们的工作性质从根本上来说就是研究,这就意味着工作负载本身是不断变化的。尽管超级计算团队致力于提供计算基础设施,我们将其视为 “产品”质量级别,但是在这个集群上运行的应用是短暂的,其开发人员需要快速迭代。随时有可能出现的新的使用模式挑战了我们关于趋势和恰当权衡的假设。当环境发生变化时,我们也需要一个可持续的系统来帮助我们快速应对。
网络
当群集中的节点和 pod 数量增加时,我们发现 Flannel 很难增加所需的吞吐量,于是转而在 Azure VMSSes 的 IP 配置和相关的 CNI 插件中,使用了原生 pod 网络技术。这样我们就可以在 pod 上获得主机级网络吞吐量。
使用基于别名的 IP 地址进行寻址的另一个原因是,在我们最大的集群中,任何时候都可能使用大约 20 万个 IP 地址。在对基于路由的 pod 网络进行测试时,我们发现对能够有效使用的路由数量有很大的限制。
不使用封装会增加对底层 SDN 或路由引擎的需求,但是可以简化网络的设置。可以不需任何附加适配器就添加 VPN 或隧道。不需要担心由于网络的某些部分具有较低的 MTU 而导致数据包碎片。网络政策和流量监测是直接的,数据包的来源和目的地都是明确的。
主机上的 iptables 标签用于跟踪每一个 Namespace 和 pod 的网络资源使用情况。这样研究人员就可以直观地看到他们的网络使用情况。具体来说,因为我们的许多实验都有不同的互联网和 pod 内部通信模式,所以能够研究出任何瓶颈可能出现的地方通常是有用的。
iptablesmangle规则可用于根据特定标准对数据包进行任意标记。以下是我们的规则,用于检测流量是内部还是互联网上的。FORWARD规则涵盖了来自 pod 的流量,以及来自主机的INPUT和OUTPUT流量:
iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"一旦被标记,iptables 就会启动计数器来跟踪符合此规则的字节和数据包的数量。通过使用iptables本身,你可以观察这些计数器。
% iptables -t mangle -L -vChain FORWARD (policy ACCEPT 50M packets, 334G bytes)pkts bytes target prot opt in out source destination....1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */使用一个名为iptables-exporter的开源 Prometheus 导出器,然后在我们的监视系统中进行跟踪。它是跟踪匹配各种不同类型条件的包的一种简单方法。
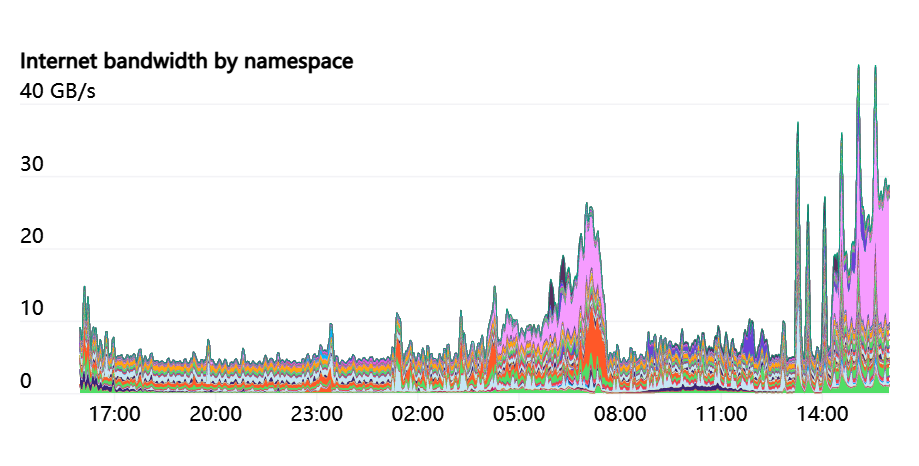
这个网络模型的一个独特之处是,我们向研究人员完全展示了节点、pod 和服务网络 CIDR 范围。我们建立了集线器和辐条网络模型,并使用本地节点和 pod CIDR 范围来路由该流量。研究人员连接到集线器,从集线器可以访问任何单个集群(辐条)。但是群集本身无法互相交流。这样就保证了集群隔离,没有跨集群的依赖性,可以中断故障隔离。
在服务网络 CIDR 范围内,使用“NAT”主机来转换来自集群外部的流量。这样的设置使得研究人员可以灵活地选择他们可以为实验选择的网络配置方式和配置类型。
API 服务器
Kubernetes API 服务器和 etcd 是一个健康工作集群的关键组件,因此我们特别关注这些系统的压力。我们使用kube-prometheus提供的 Grafana 仪表盘,以及额外的内部仪表盘。对于 API 服务器上的 HTTP 状态 429(太多请求)和 5xx(服务器错误)的比率,我们发现用来提示问题的高级信号非常有用。
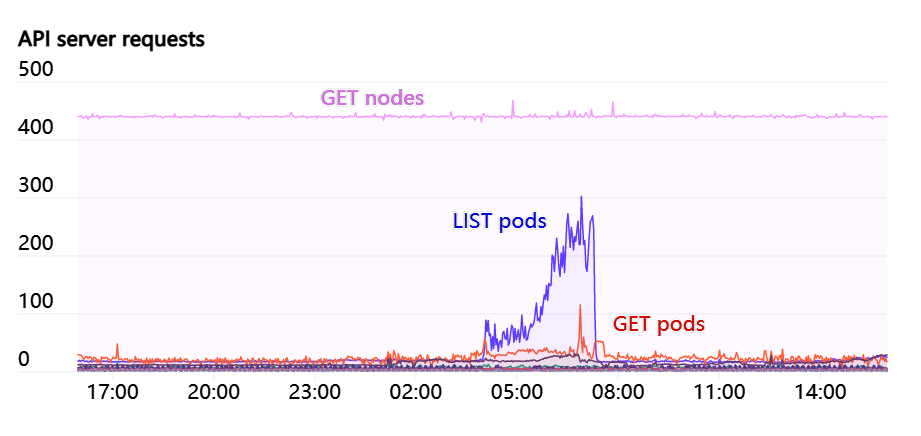
虽然有些人在 kube 内部运行 API 服务器,但我们总是在集群之外运行它们。etcd 和 API 服务器都运行在自己的专用节点上。为了分散负载,我们最大的集群运行了 5 个 API 服务器和 5 个 etcd 节点,当其中一个节点宕机时,影响最小。在之前的博客文章中,我们将 Kubernetes Events 分割为两个独立的 etcd 集群, etcd 并没有出现明显的问题。APIServers 是无状态的,通常在自愈实例组或 scaleset 中轻松运行。由于事件已经非常稀少,我们还没有尝试建立任何自修复自动执行的 etcd 集群。
API 服务器可能会占用相当多的内存,并且随着集群中节点数量的增加,内存将呈线性增长。在有 7500 个节点的集群中,我们观察到每个 API 服务器使用了高达 70 GB 的堆,所以幸运的是,这在未来应该会继续保持在硬件能力范围内。
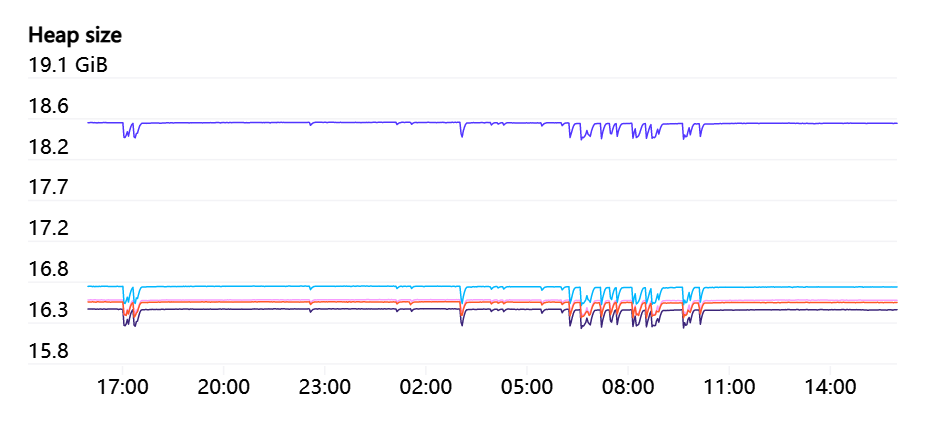
Endpoints 上的 WATCHes 是 API Servers 的一大压力。有一些服务,比如“kubelet”和“node-exporter”,集群中的每个节点都是其成员。该 WATCH 在节点将被添加或从集群中删除时启动。因为通常每个节点本身都是通过 kube-proxy 来监视kubelet
服务,所以这些响应中所需要的 # 和带宽将是 N(^2),并且数量庞大,有时甚至超过 1GB/s。Kubernetes 1.17 中推出的 EndpointSlices 是一个巨大的好处,让这个负载降低了 1000 倍。
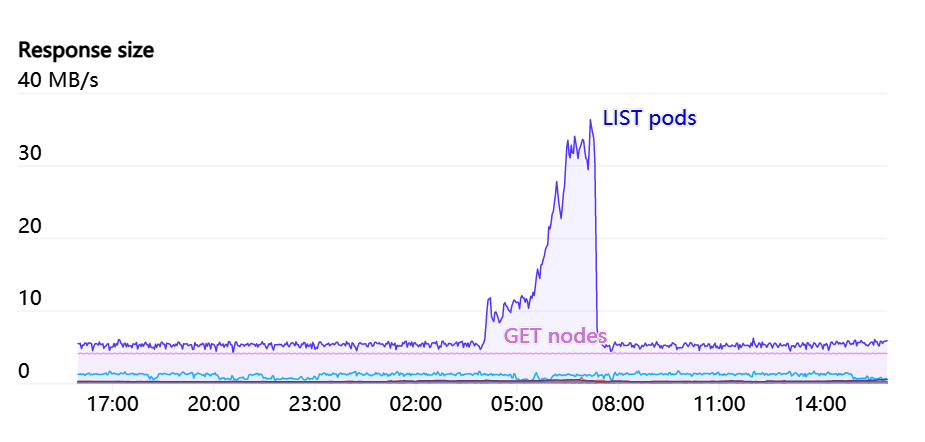
一般来说,我们非常注意任何随集群大小而扩展的 API 服务器请求。我们尽量避免让任何 DaemonSets 与 API Server 交互。如果的确需要对每个节点进行监控,那么引入Datadog Cluster Agent等中间缓存服务似乎是避免整个集群出现瓶颈的一种良好模式。
由于群集的发展,我们对群集的自动缩放的处理越来越少了。但如果一次自动扩展过度,我们就会偶尔遇到一些问题。一旦新节点加入集群,就会产生大量请求,同时增加数百个节点,使得 API 服务器的处理能力超负荷。即使只有几秒钟,平滑处理也有助于避免中断。
使用 Prometheus 和 Grafana 的时间序列指标
我们使用 Prometheus 收集时间序列指标,使用 Grafana 收集图形、仪表盘和警报。我们从部署 kube-prometheus 开始,然后收集各种指标和良好的可视化仪表盘。在过去的一段时间里,我们增加了很多仪表盘、指示器和警报。
由于添加了越来越多的节点,我们正在为 Prometheus 收集大量的指标数据而烦恼。尽管 kube-prometheus 公开了许多有用的数据,但是我们实际上没有查看过其中一些数据,还有一些数据对于有效收集、存储和查询来说过于精细。我们使用Prometheus 规则将这些指标中的一些删除。
我们曾经一度试图解决 Prometheus 消耗更多内存的问题,直到最终导致一个内存不足的错误(Out-Of-Memory error,OOM)导致容器崩溃。即使在向应用程序投入了大量的内存容量之后,这种情况似乎也会发生。更有甚者,当它真的崩溃时,它需要在启动时花费大量时间重放预写式日志(write-ahead-log)文件,然后才能再次使用。
最终追踪到这些 OOMs 的来源是 Grafana 和 Prometheus 之间的交互,Grafana 会在 Prometheus 上使用/api/v1/seriesAPI,查询{le!=""}。(基本就是“给我所有的直方图指标”)。/api/v1/series的实现在时间和空间上都是无限的:对于一个有很多结果的查询,这将继续消耗越来越多的内存和时间。即便请求者放弃并关闭连接后,它也会继续增长。对我们来说,内存永远不够用,Prometheus 最终会崩溃。我们对 Prometheus 进行了修补,将这个 API 包含在 Context 中以强制超时,这就彻底解决了这个问题。
尽管 Prometheus 崩溃的频率已经很低了,但在我们确实需要重新启动它的时候,WAL 重放仍然是一个问题。通常,在 Prometheus 开始收集新的度量和服务查询之前,要重放所有的 WAL 日志需要花费许多小时。通过Robust Perception的帮助,我们发现GOMAXPROCS=24的应用得到了很大的改善。当 WAL 重放时, Prometheus 会尝试使用所有的核心,对于核心数量较多的服务器来说,而争用会扼杀所有性能。
我们正在探索新的选择,以提高我们的监测能力,在下面的“未解决的问题”部分有描述。
健康检查
有一个如此庞大的集群之后,我们需要依靠自动化来检测并从集群中移除行为不正常的节点。经过一段时间,我们已经建立了一些健康检查系统。
被动健康检查
有些健康检查是被动的,并且总是运行于所有节点。这类监控基本系统资源,例如网络可达性,坏盘或满盘,或 GPU 错误。GPU 中出现的问题有很多种,但是一个简单常见的问题就是“ ECC 错误无法修正”。Nvidia 的数据中心 GPU 管理器(Data Center GPU Manager,DCGM)工具可以很容易地查询这种错误和其他一些 “Xid”错误。追踪这些错误的一种方法是通过dcgm-exporter把指标输入到监视系统 Prometheus。它是一个DCGM_FI_DEV_XID_ERRORS指标,它被设置为最近的一个错误代码。另外,NVML 设备查询 API(NVML Device Query API)还公开了更多关于 GPU 运行状况的细节。
检测到错误后,通常可以通过重置 GPU 或系统来修复这些错误,虽然在某些情况下,这会导致需要物理替换底层 GPU。
另一种形式的健康检查是跟踪上游云供应商的维护事件。每个主要的云提供商都公开了一种方法,以了解当前的虚拟机是否应该参与最终导致中断的即将到来的维护活动。可能需要重启虚拟机以应用底层管理程序补丁,或将物理节点替换为其他硬件。
这些被动的健康检查会在所有节点的后台将持续运行。如果健康检查开始失败,节点会自动被封锁,因此不会在节点上调度新的 pod。对于比较严重的健康检查失败,我们也会尝试“驱逐” pod,要求所有当前运行的 pod 立即退出。这还是由 pod 本身决定的,可以通过 pod 中断预算来配置,以决定是否要允许进行这样的“驱逐”。最终,不管是在所有 pod 终止之后,还是 7 天之后(我们 SLA 的一部分),我们 都会强制虚拟机终止。
主动 GPU 测试
遗憾的是,并非所有 GPU 问题都会在 DCGM 中显示为可见的错误代码。我们建立了自己的测试库,可以测试 GPU 来发现更多的问题,并确保硬件和驱动的性能与预期一致。无法在后台运行这些测试:它们需要独占一个 GPU 几秒钟或几分钟才能运行。
在启动的时候,首先在节点上运行这些测试,我们称之为“preflight”系统。加入集群时,“preflight”污点和标签被应用于所有节点。该污点会阻止节点上调度正常 pod。已配置了一个 DaemonSet,以使用该标签在所有节点上运行 preflight 测试 pod。当测试成功完成时,测试本身将清除污点和标签,然后节点可用于一般情况。
我们还将在节点的生命周期内定期运行这些测试。我们以 CronJob 的形式运行,允许它在集群中的任何可用节点上登陆。不可否认,对于哪些节点进行测试,这种方法有些随机且不可控,但是我们发现,它以最小的协调或干扰提供了足够的覆盖范围,并且随时间而变化。
配额和资源使用
当我们扩展集群时,研究人员开始发现自己难以获得全部分配的容量。常规的作业调度系统有许多不同的功能,它们可以在竞争团队之间公平地运行工作,而 Kubernetes 没有这些功能。经过一段时间,我们从这些作业调度系统中得到了启发,并且用 Kubernetes 原生的方式构建了一些功能。
团队污点
每个集群都有一个服务:“team-resource-manager”,该服务提供了多种功能。其数据源是 ConfigMap,它为特定集群中所有有能力的研究团队指定了元组(节点选择器、要应用的团队标签、分配数量)。通过使用openai.com/team=teamname:NoSchedule污染相应数量的节点,它将其与集群中的当前节点进行协调。
“team-resource-manager”还包括一项接纳 webhook 服务,这样在每一个作业提交的时候,都会根据提交者的团队成员身份进行相应的容忍(toleration)。使用污点(taints)可以让我们灵活地约束 Kubernetes pod 调度器,比如允许对优先级较低的 pod 进行 “任意”容忍,这样就可以让团队借用彼此的能力,而无需重量级的协调。
CPU & GPU balloons
除使用 cluster-autoscaler 来动态扩展我们的虚拟机支持集群之外,我们还使用它对集群中不健康的成员进行补救(删除并重新添加)。 实现方法是将集群的“最小大小”设置为零,并将“最大大小”设置为可用容量。但是,cluster-autoscaler 如果发现空闲的节点,就会尝试将其缩小到所需的容量。出于许多原因(虚拟机加速延迟、预分配成本、前面提到的 API 服务器影响),这种空闲缩放并不理想。
所以我们为 CPU-only 和 GPU 主机引入了一个气球式 Deployment。该 Deployment 包含一个具有 “最大尺寸”数目的低优先级 pod 的 ReplicaSet。 那些 pods 在节点内占用资源,因此 Autoscaler 不会 将其视为空闲。但是因为它们的优先级很低,所以调度器可以立即将它们驱逐,为实际的工作腾出空间。(我们选择使用 Deployment 代替 DaemonSet 来避免认为 DaemonSet 是节点上的空闲工作负载)。
值得注意的是,我们使用 pod 反亲和性(anti-affinity)来确保 pod 将均匀地分布在各个节点上。Kubernetes 早期版本的调度程序使用 podanti-affinity 时存在 O(N(^2))性能问题,这是因为 pod 反亲和性。从 Kubernetes1.18 开始,这个问题就被解决了。
组调度
我们的实验经常涉及一个或多个 StatefulSets,每个 StatefulSets 操作不同部分的训练工作。对于优化器来说,研究人员需要 StatefulSet 的所有成员都被调度好,然后才能进行任何训练(因为我们经常使用 MPI 来协调优化器成员之间的工作,而 MPI 对组成员的变化很敏感)。
但是,默认情况下, Kubernetes 并不一定优先满足来自一个 StatefulSet 的所有请求。举例来说,如果两个实验分别请求集群 100% 的处理能力,那么 Kubernetes 可能不会为一个实验或另一个实验调度所有请求,而只调度每个实验的一半 pod,导致死锁,无法继续运行。
我们尝试了一些需要自定义调度器的东西,但是遇到一些与正常 pod 的调度方式相冲突的边缘情况。以 Kubernetes 1.18 为核心的 Kubernetes 调度器引入了插件架构,使得原生添加这样的功能变得更加容易。最近我们登陆了 Coscheduling 插件,是解决这个问题的好办法。
未解决的问题
在我们扩大 Kubernetes 集群规模的过程中,仍有许多问题有待解决。一些这样的问题包括:
指标
就我们的规模而言,遇到了很多困难, Prometheus 内建的 TSDB 存储引擎并且每次重启时都需要长时间重放预写式日志。查询还容易导致“查询处理加载过多样本”的错误。我们正在迁移到不同的 Prometheus 兼容的存储和查询引擎的过程中。
Pod 网络流量整形
随着我们集群规模的扩大,每个 pod 都被计算出有一定的互联网带宽可用。人均对互联网带宽的总需求已经变得相当庞大,我们的研究人员现在能够无意中给因特网上其他地方如下载数据集和安装软件包等造成巨大的资源压力。
结语
我们发现 Kubernetes 是一个非常灵活的平台,能够满足我们的研究需求。可以对其进行扩展,以满足我们放在上面的要求最高的工作负载。但仍有许多地方需要改进, OpenAI 的超级计算团队将继续探索如何扩展 Kubernetes。
作者介绍:
本文作者为 Benjamin Chess 和 Eric Sigler,OpenAI 超级计算团队成员。
原文链接:




