
编译 | 核子可乐、Tina
新的能力正在创造新的头衔:为了充分发挥 AI 的技术潜能,我们必须超越提示工程师、编写出真正的软件。
2013 年,企业如果想用 AI 来做些事情,那么就需要有一整支研究团队并投入数年时间。而十年后的现在,也许一位程序员通过阅读几份 API 文档,只需花费一个下午的时间即可完成。
这种变化也代表着一种新兴职业的崛起:不同于简单的“提示工程”,他需要既懂开发又懂 LLM,作为一位复合型人才,利用 LLM 快速构建产品。
这是一项无需博士学位和过多培训即可全职从事的工作,其共同点是在软件工程领域专门研究 AI 应用并有效运用各类新兴技术栈,即在全栈开发和 LLM 的交叉点上,将 LLM 转化为可供百万人使用的实际产品。
一位从业者说,市场已经发生了根本性的有利变化,目前这个领域的人才极其稀缺且昂贵,“我收到了 4 份能够任我挑选的 offer,仅仅是通过我的 Github 和 LLM 著作(publications),面试中没有任何 leetcode 环节。要知道以前这些公司会残酷地对我进行 leetcode!”
《The Coding Career Handbook》作者 Shawn 撰写了一篇文章,将它称之为“AI 工程师”。而网友们虽然赞同他的说法,但又觉得“AI 工程师”形容不够准确,于是纷纷给出了自己的定义:LLM 工程师、AI API 工程师、AI 集成工程师、AI 系统工程师、认知工程师、认知架构师、全范式工程师、AI 设计师......
前 Tesla 人工智能总监Andrej Karpathy对此评论说,这种职业的出现是因为 LLM 创建了一个全新的抽象和专业层,可以将这个职业称之为“提示工程师”,但“提示工程师”也有一定的误导性,因为它不仅仅是用自然语言进行“Prompt”,还需要做很多粘合代码/基础设施的工作。马斯克和 Yann LeCun 随即跟评:“提示工程师”确实是在用人类自然语言进行编程。
总之,这仍然是一个需要大量的软件知识、学习最新技能并了解其中相关性的职业,它也许在重新定义 AI 和软件工程之间的差别与边界,但总的发展趋势已经形成,并且很可能会在近十年成为市场需求最大的工程技术岗位。这也是 Shawn 的文章引起大量关注与评论的原因,我们将这篇文章翻译了出来以飨读者。
以下为原文翻译:
正在迅速崛起的 AI 工程师
在基础模型日渐强大、开源/API 不断涌现的当下,AI 应用正一步步走向新的代际拐点。十年之前,需要一整支研究团队耗时数年才能完成的各种 AI 任务,现如今也许只需要几份 API 文档加一个空闲的下午即可搞定。
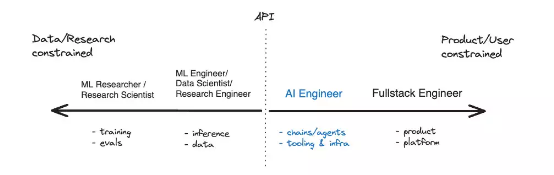
在上图当中,API 虚线分隔开了两大研究方向,但并非硬性割裂。AI 工程师们可以向左微调/托管模型,研究工程师同样能向右构建 API。他们各有相对优势,一方强调数据/研究,另一方则强调产品/用户。
“从数量上看,AI 工程师的数量可能会比机器学习工程师/大语言模型工程师多得多。人们无需接受任何培训,就有机会成为非常成功的 AI 工程师。”——Andrej Karpathy
但细节决定成败——要想在 AI 的评估、应用和产品化中取得成功,仍须面对无穷无尽的现实挑战:
模型:评估各类模型选项,从体量最大的 GPT-4 和 Claude,到规模更小的开源 Huggingface、LLaMA 等。
工具:从最流行的链接、检索和向量搜索工具(如 LangChain、LlamaIndex 和 Pincecone)到新兴的自主智能体领域(如 Auto-GPT 和 BabyAGI)均须涉猎。
资讯:除此之外,每天发表的论文、模型和技术数量也随关注度和投资的增加而呈指数级增长,单是跟进这些资讯就几乎需要全职投入。
没错,以上结论务实且认真。这就是一项需要全职从事的工作。相信软件工程即将迎来新的子学科,专门研究 AI 应用并有效运用各类新兴技术栈。而且这波变革,与之前的“站点可靠性工程师”、“开发运营工程师”、“数据工程师”和“分析工程师”一样,都是历史发展的阶段性产物。
没错,AI 工程师正是最新段下的最新角色。
几乎每一家初创企业都有自己的 AI 讨论频道。这些频道把一个个非正式团队转化为正式小组,具体载体则可能是 Amplitude、Replit 以及 Notion 等。成千上万的软件工程师致力于开发 AI API 与开源模型,他们把握业余时间和周末闲暇,积极参与公司内部频道和独立 Discords 中的讨论,而种种专业知识汇聚起来共同形成的就是 AI 工程师。在这个十年间,AI 工程师很可能成为市场需求最大的工程技术岗位。
如今,AI 工程师已经随处可见——上到微软、谷歌等科技巨头,下到 Figma(通过收购 Diagram)、Vercel(获得病毒式传播的 RoomGPT)和 Notion(Notion AI)等初创公司,还包括独立技术人 Simon Willison、Pieter Levels(来自 Photo/InteriorAI)和 Riley Goodside(现供职于 Sacle AI)。他们在 Anthropic 上参与提示词工程,每年赚取 30 万美元;同时也在 OpenAI 那边构建软件,拿着近百万美元的年薪。他们还会利用周末空闲时间在 AGI House 交流观点,并在/r/LocalLLaMA 上分享技术。他们的共同点是,几乎都在一夜之间就将 AI 技术进步转化为可供百万人使用的实际产品。
而这里面,并没有什么科班背景、博士学位。在 AI 产品的交付当中,我们需要的是工程师、而非学术研究人员。
AI 与 ML 工程师的对决
请注意,本文并不是想鼓动大家成就这波趋势;相反,趋势已经存在,我是在呼吁大家给予关注。Indeed 上的机器学习工程师职位数量目前是 AI 工程师职位数量的 10 倍,但后者更高的增长率令我大胆做出预测,相信这个比例在未来 5 年内即会出现逆转。

HN Who’s Hiring 每月职位趋势
这些职位名称虽不全面,但足够帮助我们了解目前的 AI 人才趋势。首先,我们不想陷入关于 AI 跟机器学习间的差异这类无休止的争论当中,而且常规“软件工程师”其实完全有能力参与 AI 软件的开发。但从最近 HN 上出现的、关于如何投身 AI 工程的开放问题,也说明市场在某些基本观念上仍然存在分歧:

2023 年 6 月的截屏:“如何投身 AI 工程”中得票最高的答案。
大多数人仍然觉得 AI 工程是机器学习或数据工程的一种形式,因此觉得必须要先掌握这些相关技能。但我可以向大家保证,文章开头提到的那些 AI 工程师们没有一位上过吴恩达的课程、不了解 PyTorch,甚至搞不清数据湖和智能湖仓有啥区别。在不久的将来,大家用不着研讨关于注意力机制的论文也能参与 AI 开发,就像大家没必要研究车辆构造图来学习驾驶一样。当然,熟悉基础知识和技术发展史也很重要,能帮助我们发现还没有被公众广泛意识到的思路和效率/能力提升路径。但这只是其中一种方式,单凭产品使用经验也完全能帮大家找到新的产品设计方向。
我并不指望对 AI 课程的盲目重视能在一夜之间就彻底扭转。毕竟人类的天性,就是要在自己的简历上和市场图谱中塞进更多貌似权威的深度内容,借此从竞争中脱颖而出。换句话说,在未来很长一段时间内,提示词工程和 AI 工程在硬核数据科学/机器学习面前都会有点自惭形秽。但我始终坚定相信,供需经济学才是决定一切的无形之手。
AI 工程师为什么会在当下兴起
基础模型成为“少样本学习者”,成功表现出了上下文学习、甚至是零样本迁移的能力,其泛化能力甚至超出了模型训练者的最初想象。换句话说,就连模型创建者自己也不完全清楚它们的能力。非大语言模型研究者只需要把更多时间投入到模型上即可,只要将成果应用到尚未受到重视的领域(例如 Jasper 的方案写作)中,就足以展现并运用其强大能力。
微软、谷歌、Meta 及各大基础模型实验室垄断了稀缺的研究人才,开始对外提供“AI 研究即服务”API。其他企业根本就没办法雇用这些精英,所以就只剩下租赁这一条路可走——前提是自己这边有知道如何跟对方合作的软件工程师。目前全球大语言模型研究人员共有约 5000 名,但软件工程师却高达 5000 万之巨。供应限制决定了必然要通过 AI 工程师这个“中间”阶层来满足旺盛的市场需求。
GPU 富集。虽然 OpenAI/微软一马当先,但 Stability AI 也在特定应用领域展现出优势,并凭借 4000 GPU 巨型集群拉开了大型企业和初创公司奋力争夺 GPU 的竞赛序幕。
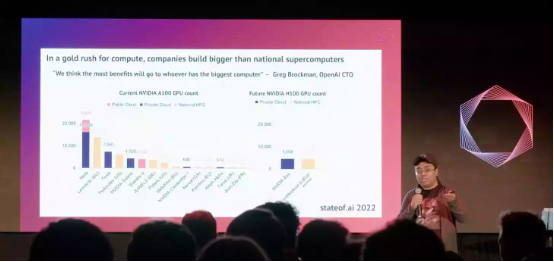
2022 年 10 月,正是这一切变革的开端。在此之后,Inflection(13 亿美元)、Mistral(1.13 亿美元)、Reka(5800 万美元)、Pools ide(2600 万美元)、Contextual(2000 万美元)等初创公司开始轮番筹集到巨额种子轮资金,毕竟想在 AI 领域试水的前提就是买得起大规模的昂贵硬件。Dan Gross 和 Nat Firedman 甚至宣布将打造 Andromeda,这是专为他们投资的初创公司所打造、价值 1 亿美元且算力高达 10 百亿亿次的 GPU 集群。疫情导致的全球芯片短缺也进一步加剧了对算力资源的争夺。而在 API 光谱的另一端,则是专司使用 AI 模型的 AI 工程师。相较于训练模型,市场对这类人才的需求同样极具热度。
先开火、再瞄准。产品经理/软件工程师们并不需要像数据科学家/机器学习工程师那样,先立足单一领域训练特定模型,并在投入生产之前开展繁琐的数据收集和训练。相反,他们可以先向大语言模型输入提示词,再一步步用获取的数据做微调,逐渐建立并验证自己的产品设计思路。

假设产品经理/软件工程师的数量是数据科学家/机器学习工程师的 100 甚至 1000 倍,而用提示词操纵大语言模型这种“先开火、再瞄准”的探索在效率上能够达到传统机器学习的 10 到 100 倍。如此计算下来,就代表着 AI 工程师将能够以 1000 到 10000 倍的速度验证 AI 产品。这又是典型的瀑布式对敏捷式之争,而 AI 无疑会站在敏捷式这一头。
从 Python 到 JavaScript。传统上,数据/AI 向来以 Python 为中心。首批 AI 工程工具(如 LangChain、LlamaIndex 和 Guardrails 等)就诞生在这个社区。然而,JavaScript 开发人员在规模上至少不逊于 Python 开发者,所以现在的新兴工具正越来越多地迎合这部分广大受众。从 LangChain.js 到 Transformers.js,再到 Vercel 的全新 AI SDK,都是这种趋势的铁证。这部分潜在市场空间无疑巨大且仍在急剧扩张。
生成式 AI 对分类机器学习。“生成式 AI”已经逐渐失去热度,转而让位于“推理引擎”等其他表述。但人们仍在用它表达原有 MLOps 工具和机器学习从业者,同正在崛起的、新一波 AI 角色之间的差异。而生成式 AI 阵营的杰出代表,自然就是大语言模型和文本到图像生成器。原本的机器学习往往更多关注于欺诈识别、推荐系统、异常检测和特征存储,而 AI 工程师则更重视写作类应用、个性化学习工具、自然语言表格和可视化编程语言等。结合历史经验来看,每当出现一个拥有不同教育背景、使用不同表达语言、产出不同产品类型且选择不同实现工具的群体时,他们终将独立出来并形成自己的生态体系。而这,就是 AI 工程师群体的未来形态。
1+2=3: 代码角色在软件 2.0 到 3.0 过程中的演进
六年之前,Andrej Karpathy 曾写过一篇极具影响力的文章,描述了软件 2.0(即精确建模逻辑加手工编码的「经典技术栈」)同新型“机器学习”神经网络(强调近似逻辑)之间的差异。后一种所能解决的问题,显然要比人类可建模的问题多得多。他今年继续指出,未来最热门的编程语言将会是英语,这也最终填补原始文章图表中未加标记的灰色区域。
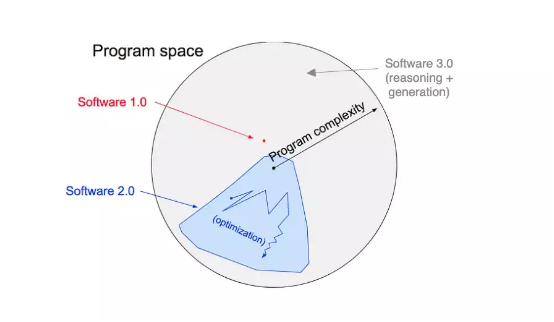
去年,随着人们开始将 GPT-3 和 Stable Diffusion 投入实际应用,提示词工程成为未来工作岗位变化的传播模因。人们开始嘲笑其他 AI 初创公司都是“OpenAI 打包商”,同时也为大语言模型极易受到提示词注入和逆向提示词工程的影响而感到焦虑。我们还有没有值得信赖、能够保护自己的护城河?
而短短一年不到,2023 年的核心议题就变成了如何重新确立人类在编码中的作用。因为事实证明,从价值超过 2 亿美元的新贵 Langchain,到英伟达支持的 Voyager,在语言模型在快速生成代码结果的同时,反而更加需要人类的协调和介入。

主架构之争:“智能之上的软件”与“智能软件”
提示词工程虽然被夸大了,但却仍将继续存在。而软件 1.0 范式在软件 3.0 应用中的重新出现,则标志着一片充满机会、但又颇为混沌的新空间——这里遍布荆棘,但同时也给初创企业提供了宝贵的施展舞台。
搞风险投资的,谁能没份市场图谱呢?
当然,这里要强调的不只是需要人继续编写代码。通过最近使用 smol-developer、gpt-engineer 以及其他代码生成智能体(包括 Codium AI、Codegen.ai 和 Morph/Rift)的感受,我意识到这些工具将逐步成为 AI 工程师技术储备中的一部分。随着人类工程师学会运用 AI,AI 也将越来越多地被纳入工程技术体系。也许在遥远未来的某一天,我们猛然抬头,却再也分辨不出 AI 和软件工程之间的差别与边界。
原文链接:




