
本文由 InfoQ 整理自云杉网络 DeepFlow 产品负责人向阳在 QCon 全球软件开发大会(北京站)2022 上的演讲分享。
大家好,我是向阳,我从清华大学毕业之后就来到了云杉网络,目前负责云原生可观测性产品 DeepFlow。这个产品其实有些年头了,它诞生于 2016 年,并且已经走进了上百个金融、能源、运营商行业的 500 强客户中。去年我们把产品的内核进行了开源,希望它能被更多其他行业、其他国家的用户所知晓。目前开源的时间还不长,7 月份刚有了第一个社区版的 Release,在这里也欢迎大家加入我们的开源社区。
前言
相信大家都有感受,eBPF 最近一年突然火了起来,特别是在可观测性领域。但实际上追溯起来,它的前身 BPF 技术已经有 30 年历史了。我们基于这项有着悠久历史的「新」技术,在它之上做出了一些非常令人激动人心的创新,特别是对 Distributed Tracing 问题给出了一种全新的解法。我相信即使是从世界范围上来讲,我今天分享的内容也能称得上是颠覆性的改变。
在准备这次的 QCon 演讲时,我还问了一下 ChatGPT,基于它更新到 2021 年的知识体系,我问它 eBPF 能否用于实现 Distributed Tracing?它像模像样地编了一大堆话,不过最终得出了否定的结论,并建议我使用 OpenTracing。
DeepFlow 希望利用以 eBPF 为代表的自动化技术,去降低实现可观测性的复杂度,为开发同学带来自由,促进开发和运维的和睦相处。今天我分享的主角是 eBPF,它带来的安全、灵活的内核可编程能力可以做很多事情,但本文会聚焦在如何利用它来创新的解决分布式追踪问题上。
在此之前,我会先回顾一下分布式追踪的历史,然后聚焦介绍 DeepFlow 利用 eBPF 做出的酷炫特性,即 AutoTracing,它不用修改任何代码就能实现分布式追踪,然后介绍我们如何将 eBPF 和 OpenTelemetry 这两项技术结合形成令人激动的全栈、全链路分布式追踪方案,最后简单看看 DeepFlow 作为一个可观测性平台的其它能力。
分布式追踪:回顾十四年历史,剖析云原生时代的新痛点
相信大家非常熟悉分布式追踪,追踪数据是可观测性三大支柱之一。
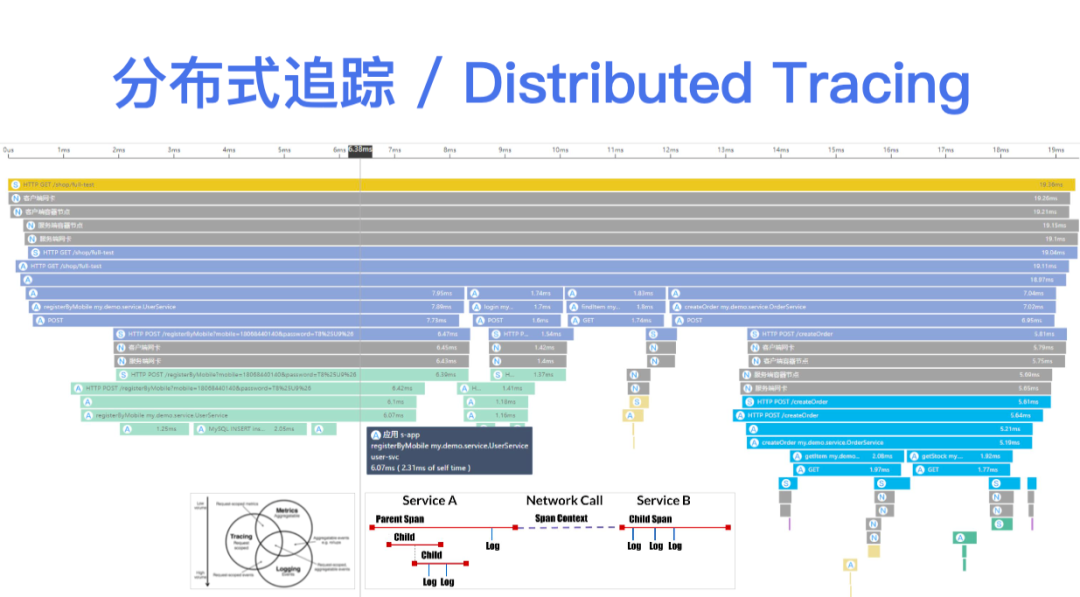
通过采集一个 Trace 在多个进程中的 Span,最终我们能得到这样一个火焰图,它有点类似于我们对单一进程做的 CPU Profile,区别在于分布式追踪是一个聚焦在单次业务请求上的、覆盖多个服务进程的全景火焰图。它从上到下描述了一个分布式应用在服务之间的远程调用关系、服务内部的函数调用关系,它能够快速帮助开发者,特别是由很多个跨团队的微服务开发同学快速确定问题发生的位置,找到对应的负责人。基于这样的火焰图,我们还可以从中聚合出一些应用性能指标,比如说每个服务的吞吐、时延、异常,以及服务之间的访问关系拓扑等。
分布式追踪的十四年

一般认为分布式追踪可以追溯到 Google 的 Dapper 论文上,这个论文是 2010 年发表的,论文里讲到 Google 从 2008 年开始做 Dapper 这个系统,解决 Google 内部微服务调用追踪的问题。受这篇论文启发,开源社区诞生了一批优秀的项目,例如非常火的 Apache SkyWalking 就是聚焦在这个问题上。再到最近几年,开发者们发现插桩这件事应该要标准化、自动化,因为它侵入了业务程序中,随着开发语言、微服务框架越来越多样化,开发者们不希望因为插桩这件事去太多修改业务代码,在这个驱动力之下诞生了 OpenTracing,进而发展为 OpenTelemetry。
云原生时代的痛:插码插不全

在云原生时代,分布式追踪这件事变得越来越迫切,也遇到越来越严峻的挑战。首先,随着服务拆成,单个微服务的业务代码会越来越简单,同时有一部分公共逻辑会逐渐的卸载到基础设施中,比如说通过服务网格或 API 网关实现。因此微服务会越来越轻,开发写的代码会越来越聚焦在业务逻辑方面,这是一个趋势。
另外一点是微服务技术栈的多样性,如果微服务变得越来越简单了,开发同学就会有越来越多的自由,可以选择自己比较喜欢的框架和语言。但是这会导致一个问题,分布式追踪在这种场景下越来越不容易全面覆盖。有一个以往我们很喜欢的东西 Java Agent,它可以做到无侵扰的插码,在对业务代码无修改的情况下实现一定程度上的分布式追踪能力。
但是,一方面注入 JavaAgent 还是需要重启业务进程,另一方面在其它语言中一般不存在类似的字节码注入机制,比如说对于 Golang。假设你是公司内部的基础设施开发团队,你负责开发维护 Golang 的 SDK 去做 Instrumentation,可以想象在 SDK 每发布一个新版本之后,都需要漫长的时间来让公司里众多业务部门将 SDK 更新到新版本,这个时间可能会长达半年甚至一年,是一个非常漫长非常无奈的过程。因此,大家几乎有一个共识,现有的依靠插码的分布式追踪,落地起来还是很有难度的,是一项需要协调所有业务开发部门的工作。
云原生时代的痛:链路追不全

云原生时代的另外一个趋势,通信路径的复杂性。以往服务之间的通信路径非常简单,最早的时候可能是两台服务器通过网线和交换机直接连起来,甚至是在同一台服务器上通过本地 Socket 直接通信。但在云原生时代,开发同学会发现两个服务之间可能跨越了千山万水,有 Pod 里面的 Service Mesh Sidecar、云服务器中的虚拟网桥、KVM 宿主机上虚拟交换机,还有大量的四七层网关、消息队列、中间件等等,通信路径非常复杂。
与此同时,几乎所有的分布式追踪机制其实都只聚焦在业务代码、框架 / 库函数两个层面,对服务之间的通信路径缺乏覆盖。然而,在微服务数量从 1 增长到 N 的过程中,服务之间通信路径的复杂度极端情况下可能增长了 N^2,复杂度的增长达到了几个数量级。造成的后果是,业务出现问题之后,依靠现有的分布式追踪能力开发同学往往找不到问题所在,越是聚焦在业务开发的同学,对于底层的这些云原生基础设施会了解地越少。我们发现经常会发生的经典故事是,开发难以回答到底是自己的问题、上下游服务的问题,还是基础设施的问题。由于分布式追踪无法覆盖云原生基础设施中的通信路径,这个问题往往无法回答,导致一个工单来回在不同团队之间无效流转。
确实,上述就是我们的现状,微服务越来越多样,通信路径越来越复杂,导致了分布式追踪越来越重要,但又越来越难以追全。
AutoTracing:基于 eBPF,零代码修改实现分布式追踪
铺垫了这么多,下面介绍本文的主角,DeepFlow 基于 eBPF 做的一个非常酷的能力 AutoTracing,即零代码修改、零应用发布、零进程重启的分布式追踪能力。
上图是去年的截图,粘贴的是 Google 的搜索结果,如果今年再写 PPT 的话应该要贴 ChatGPT 的图了。从图中可以看到搜索 eBPF Tracing 有 10 万个结果,但这些结果中的 Trace 实际上都是指在一台单一的主机上去 Trace 函数调用、系统调用等行为,这些都是 eBPF 被大家所熟知的能力,然而他们并不是今天我们要谈论的 Distributed Tracing。
Istio Bookinfo 零插码追踪 Demo
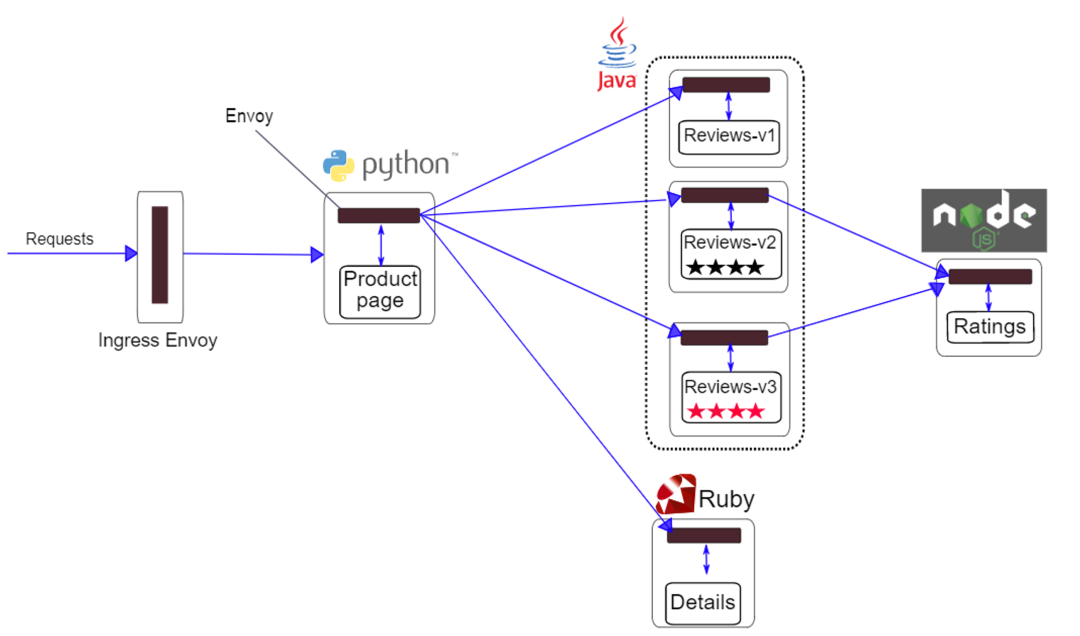
那到底 eBPF 能用于实现分布式追踪吗?我们先来看一下 DeepFlow 做到的效果,上图是一个基于 Istio 的热门 Demo,这个叫 Bookinfo 的 Demo 我相信有很多朋友都比较熟悉,这里有四五种语言实现的几个微服务,覆盖了 C++(Envoy)、Python、Java、Ruby 和 Node.js。当然熟悉的朋友会知道,Istio 这个 Demo 中官方是做了 OTel 插桩的,但接下来的所有结果都是基于关闭所有这些 OTel 插桩后得到的,下文将给大家展示一下 eBPF 能做到什么程度。

首先来确认手动插桩确实都关闭了,上图是 Jaeger 对 Bookinfo 的追踪效果。注意这一页并不是我忘记写内容了,而是想告诉大家离开了插桩 Jaeger 得不到任何追踪结果。
DeepFlow AutoTracing:零插码、全栈
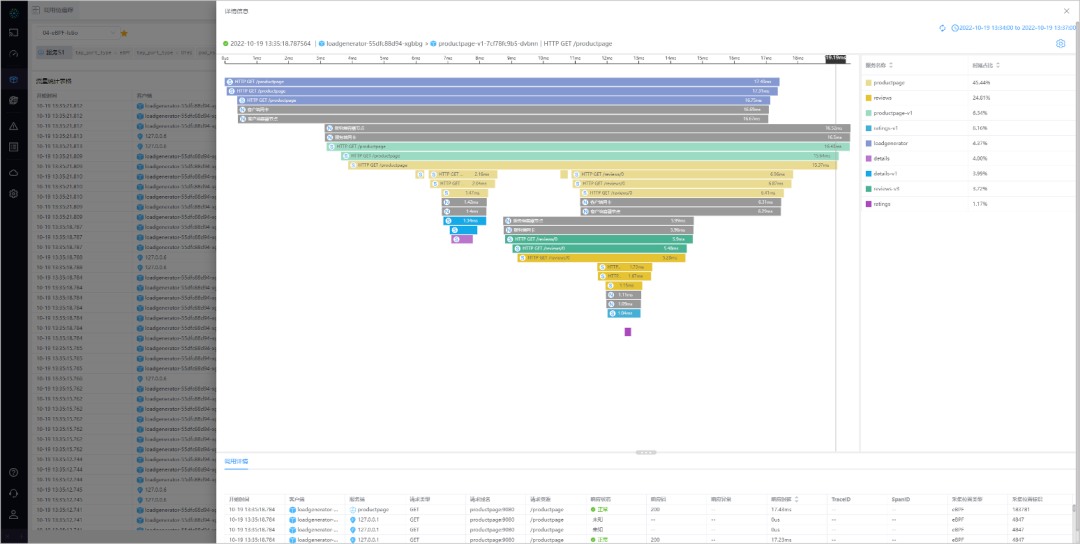
是时候让 DeepFlow 上场了!大家可以看到,没有任何代码修改、没有任何重编译重发布、没有任何进程重启的前提下,DeepFlow 得到了上图所示的分布式追踪火焰图,这就是 AutoTracing 的效果。这里的每一行作为一个 Span,表达了一个调用在特定位置上被 eBPF 捕获到的事件。从火焰图中我们可以发现 Demo 中涉及到的所有服务,包括各种语言实现的业务微服务如 Productpage、Reviews 等,包括基础设施服务如 Envoy Sidecar、K8s CNI 等,以及还包括客户端 curl 进程,一个云原生业务的全栈分布式调用路径被完整的追踪下来了。
上图中有两种 Span:彩色的是 DeepFlow 利用 eBPF kprobe/tracepoint/uprobe/USDT 从 Kernel 系统调用和 User 函数调用中采集到的系统 Span,灰色是利用 BPF(Classic BPF)从虚拟网络中每个网卡(即内核中的 IP 收发包函数)中采集到的网络 Span。基于这两种 Span 进行关联,然后绘制出一次业务请求背后整个分布式调用的火焰图画。现在这个图中只是给了大家一些直观上的体感,接下来我们把这个图稍微放大一点,看看它的一些细节效果,来进一步感受一下。
感受 DeepFlow 的 AutoTracing
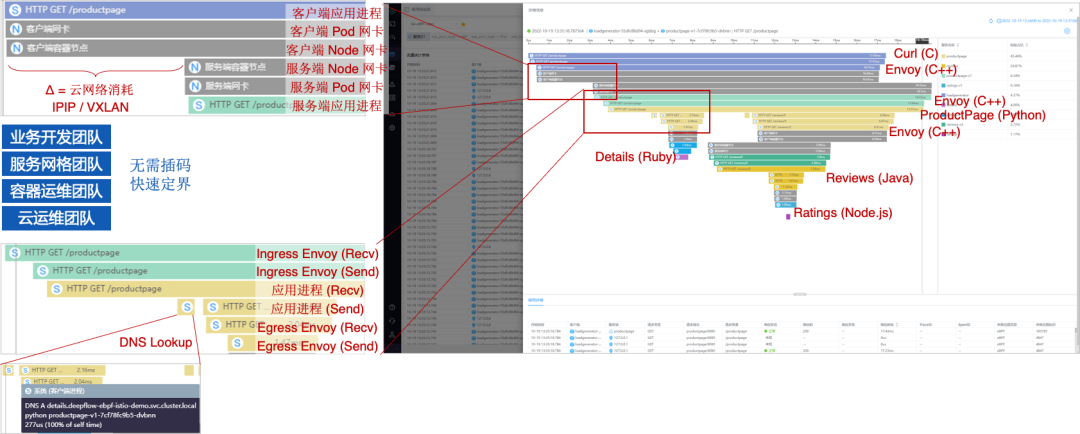
1.零插码:且无需向 HTTP 头注入 TraceID 或 SpanID
2.全链路:4 个调用、38 个 Span,分为 24 eBPF Span + 14 BPF Span
3.多语言:Java、Python、Ruby、Node.js 及 C/C++ (curl/envoy)
4.全栈:追踪两个微服务之间的网络路径,从 Pod 到 Node 到 KVM,IPIP、VXLAN、…
5.全栈:追踪微服务内从 Envoy Ingressjian 到 服务 到 DNS 到 Envoy Egress 全过程
案例:某互联网客户,使用 DeepFlow 5 分钟内定位客户端慢服务端不慢的经典扯皮问题。
首先,零代码修改。完成上图中的分布式追踪,DeepFlow 确实没有向调用中注入任何 TraceID 或 SpanID,同样也确实没有修改哪怕一行代码、没有重启任何一个进程。这个 Demo 中追踪火焰图覆盖到了所有 6 个进程,包括 C 语言实现的 curl、C++ 实现的 Envoy、Python 实现的 ProductPage、Ruby 实现的 Details、Java 实现的 Reviews、Node.js 实现的 Ratings;覆盖到了他们之间的所有 4 个调用,并采集到了 38 个 Span,其中包括 24 个 eBPF Span 和 14 个 BPF Span。
其次,再来看全栈追踪能力。举两个例子,第一个是上图中顶部蓝色的 curl 进程(在 loadgenerator Pod 中)调用下放绿色的 ProductPage 服务,我们会发现,从客户端 curl 进程、客户端 LoadGenerator Pod 虚拟网卡、客户端 K8s Node 物理网卡、服务端 K8s Node 物理网卡、服务端 ProductPage Pod 虚拟网卡、服务端 ProductPage 进程,这个调用经过的每一跳都看得非常清楚。图中的 Span 中,头部携带 S 标记的是 eBPF 获取到的系统 Span,携带 N 标记的是 cBPF 获取到的网络 Span。另外在实际的生产环境中,中间的网络路径还可能更复杂,比如会经过 NFV 网关的网卡、KVM 宿主机的网卡等,这些复杂的路径在 DeepFlow 中也能完整地追踪出来。具体到上图中的例子,我们发现这样的全栈追踪能力能快速地发现瓶颈发生的位置,图中两个 K8s Node 之间的云网络消耗了比较显著的时间。
再次,再从服务网格的角度看全栈。上图中放大了中间一块区域,这是一个调用从进入 ProductPage Pod 到继续请求上游服务的全过程。我们知道这个 Demo 是基于 Istio 的,从火焰图中也清晰地看到调用显示被 Envoy 劫持(收到并发出去),然后才被 ProductPage 进程接收到。这个服务为了完成下游的请求,它需要调用上游的 Details 和 Reviews 服务。在调用 Details 之前,我们看到火焰图上这个服务首先发起了一次 DNS 请求来查询 Details 服务的域名,然后调用 Details 服务,而这个调用也被 Pod 内的 Envoy 代理再一次劫持。我们会发现,在服务网格环境中的调用能被 DeepFlow 清晰的观测到全过程,我们能够快速的判断到底是哪个组件、哪一个基础设施服务、或者哪一个业务服务出现了瓶颈或故障,非常清晰。
到此为止,相信大家已经对 DeepFlow 基于 eBPF 的 AutoTracing 能力所叹服了,这个能力也已经帮助我们很多客户实现了云原生应用的快速故障排查。熟悉 OpenTelemetry/SkyWalking 的朋友们可能也发现了它的一个特点:在进程内部我们只为每个调用生成了一个 Span,并没有精细拆分为业务代码、框架代码、库代码等。一方面是因为业务代码粒度的追踪不具备普适性,使用 eBPF 去覆盖会有很大的实现复杂度和性能开销;另一方面也是因为这部分其实已经有各个语言的 Instrumentation 覆盖了,例如大家熟悉的 JavaAgent 的方式。下文将会解释这样取舍的原因,让 eBPF 发挥它擅长的能力,对基础设施服务、进程中的标准远程调用进行覆盖,从而实现对所有分布式调用的完整追踪能力。在实现全局覆盖以后,再选择使用语言的 Instrumentation 来增强局部。
AutoTracing 背后的关键洞察
下面的内容是本文的硬核部分,深入介绍 AutoTracing 机制的原理。DeepFlow 开源以来文档工作比较滞后,有很多小伙伴会问到你这是怎么追踪出来的,是不是骗人的。实际上 deepflow.io 上也有我们的在线 Demo,可以随时访问,而且也已经有很多社区用户和企业版客户在使用这个能力了。
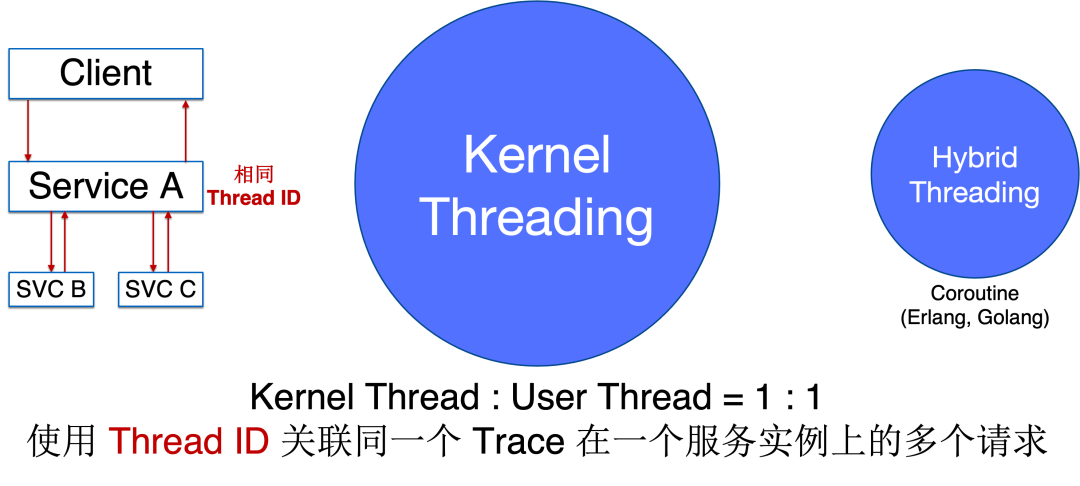
接着介绍一下 AutoTracing 背后的关键洞察,以及我们碰到的一些挑战。现在回顾起来其实关键洞察很简单,就像我们在用 JavaAgent 实现 Tracing 一样,我们会熟悉一个叫 ThreadLocal 的东西,我们时不时的往 ThreadLocal 里藏一些东西,这个时候就能将一个 Service 的入方向的调用和出方向的调用关联起来了。比如说以上图中的 Service A 为例,我们希望把 Client 请求服务 A 的调用以及 A 访问 B 和 C 的调用关联起来,当我们能做到这件事时就解决了单一服务上下游的追踪问题;如果说还能做到将 A 发起的调用和 B 收到的调用关联起来,也就解决了两个进程之间的追踪问题;当我们做完这两件事时,我们发现已经实现了对一个最基本的分布式应用的追踪能力,这就是我们非常初始的想法。
类似于在 Java 中利用 ThreadLocal 传输信息,在 eBPF 中我们可以利用 ThreadID 来对一个进程上下游的调用进行关联。但很不幸的是,真实世界非常复杂,我们并不能用一种简单的方法利用 eBPF 在内核中获取的信息感知到每种语言中的「线程」,但本着从简单问题入手的思路,我们发现实际上大部分语言都遵循 Kernel Threading Model,即内核态的线程和用户态的线程是 1:1 对应的,像 Java、C 等语言都是这种模型,此时我们可以直接用 Thread ID 来做调用之间的关联。除此之外也有非常少数的语言采用 Hybrid Threading Model,如 Golang、Erlang,它们是协程化的语言,这些语言中的协程 ID 和 eBPF 在内核中感知到的 ThreadID 并没有多大的关系,下文也会来解释我们如何解决这类场景。作为第一步尝试,我们先将问题简化,只考虑上图中央部分的大多数场景 —— Kernel Threading Model 下的分布式追踪问题。
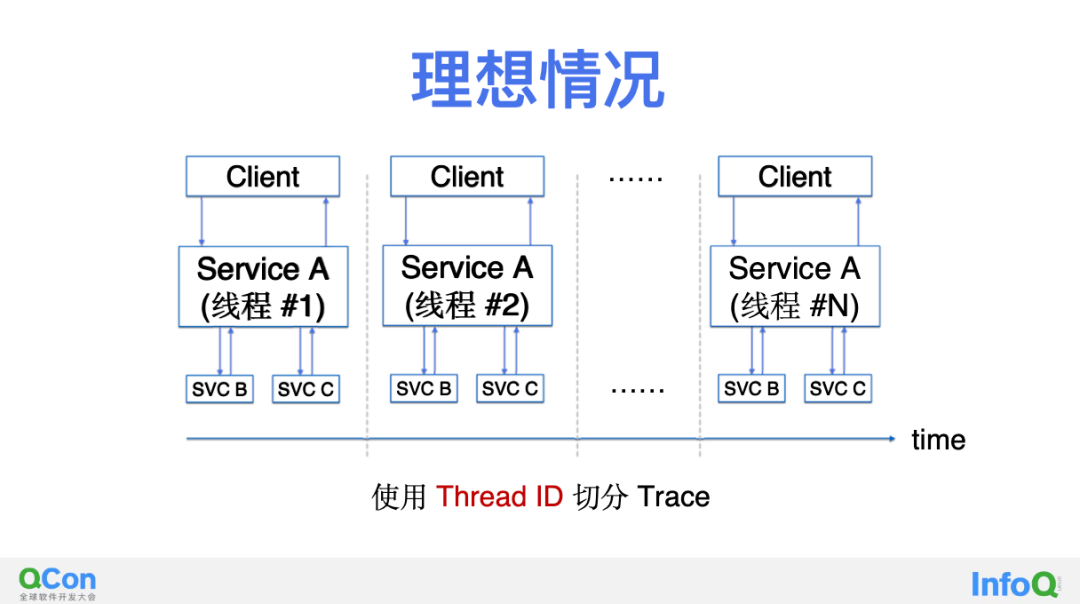
第零步,构造一个理想环境。在上图中服务 A 每接收到一个新的来自 Client 的请求都会使用一个全新的线程来处理它,并在这个线程中调用上游的服务 B 和 C,在完成并响应 Client 后关闭处理线程。我们以此为起点,首先希望能在一个理想环境下获得完美的效果。正如大家所看到的,这种情况下我们天然的可以通过 eBPF 获取到的 ThreadID 和调用进行关联,实现服务 A 上下游的调用的追踪。
从这个完美的起点出发我们能走多远呢?两年前刚开始做这件事时我们也不知道答案,甚至经常会面对不完美结果的打击,但现在回顾过来我们不断的探索过程非常精彩,接下来一一和你分享。
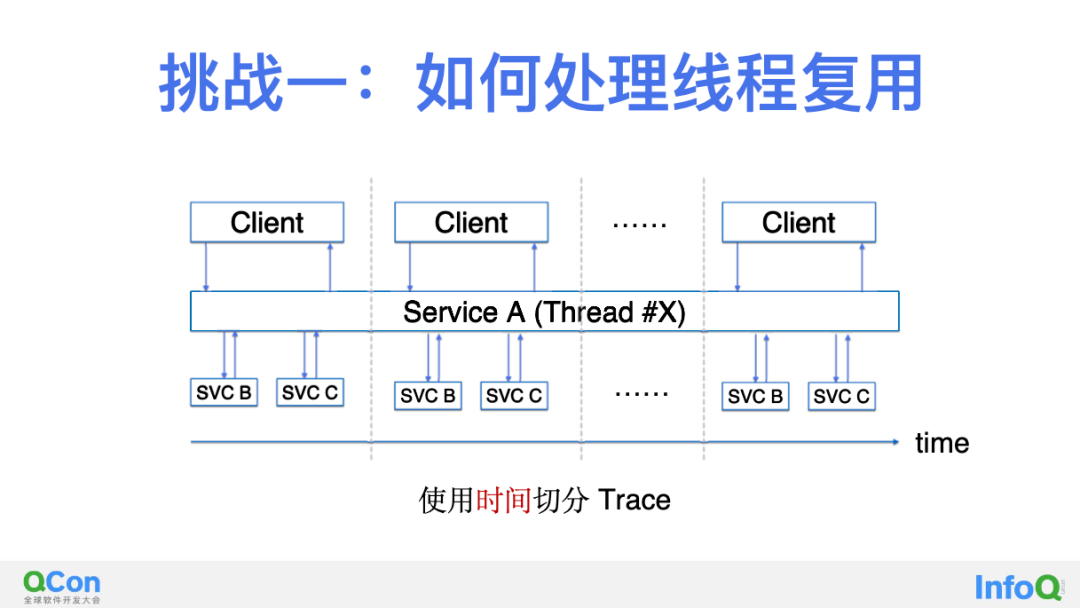
第一步,解决线程复用的问题。上图是一种阻塞调用场景下的最简单的线程复用场景,和我们的理想场景只有一个区别:处理调用的线程 X 在完成 Client 的请求之后并没有终结,他会被归还到一个线程池中,稍后就会继续服务于下一个请求。因此这种场景下我们不能简单的认为「关联至同一个 ThreadID 的调用是在一个 Trace 中」,这样会把时间轴上先后出现的不同 Trace 合并到一起。这种情况 DeepFlow 如何解决呢?实际上比较简单,我们只需要按照时间维度进行切分即可,当我们发现某个线程 X 已经完成了来自 Client 的调用的完整闭环时,我们认为一个 Trace 结束了。
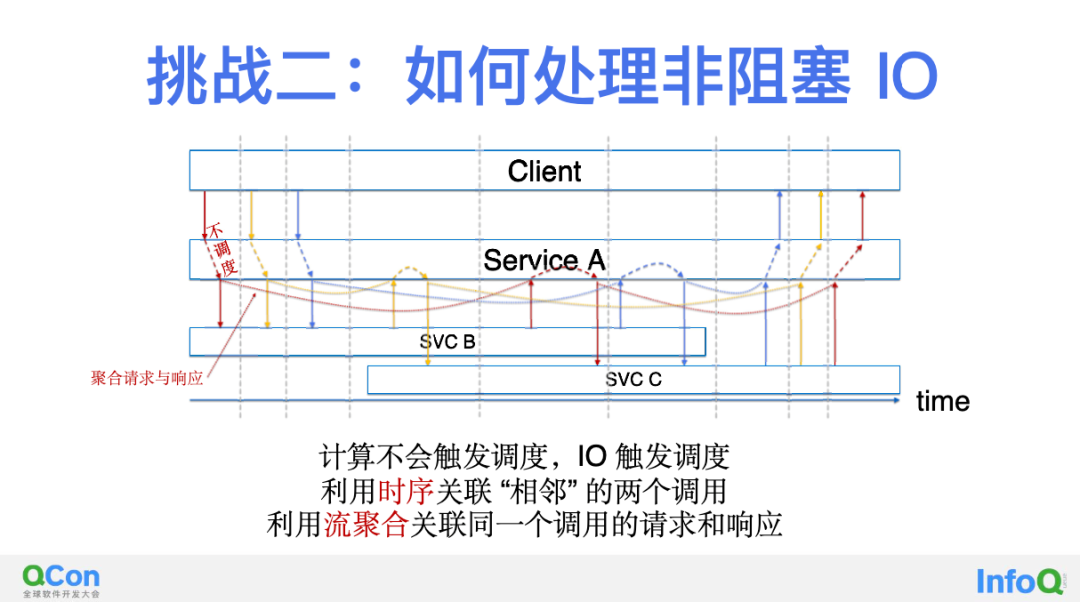
第二步,解决非阻塞 IO 的问题。在上一步中,我们假设了服务 A 的线程 X 在处理一个 Trace 的请求过程中,不会去处理另一个 Trace 的请求。这是一个非常强的假设,实际的环境中在服务 A 接收到一个来自 Client 的调用之后,很可能在同一个线程中还会处理其他的来自 Client 的调用。典型的对于一些单线程语言都会是这样的处理逻辑,否则自己会被卡死。那接下来思考一下非阻塞 IO 的场景是否能解决呢?上图中展示了 DeepFlow 的解决思路,我们利用了一点非常有意思的现象:服务 A 在接收到 Client 的请求之后会进行 CPU 计算,并会发起到服务 B 的请求,我们会发现在这段时间中是没有出让调度的机会的,也就是说在这两个时间点之间服务 A 没有机会再接收来自 Client 的请求。但是一旦服务 A 发起了到服务 B 的请求时,这个 IO 操作就给了 CPU 调度时机,这之后服务 A 无需等待服务 B 的返回,就有可能会收到来自 Client 的其他请求。
总结来看,我们可以利用 eBPF 采集到的读、写事件的时间关联性来讲两个属于同一个 Trace 的调用关联起来,例如上图中相邻的两个红色、黄色、蓝色调用,他们都属于各自的 Trace 中,他们穿插着出现在时间轴上,但通过事件的相邻关系我们能实现对他们所在的 Trace 的独立追踪。当然这里也做了一个假设,即两个 Socket 事件之间不会有其他调度点,但如果代码中有明确的 sleep 或 yield 等语句这个假设就不成立了。但这些情况是小概率事件,我们在探索的过程中先将他放在一边。
做完这些以后我们发现还是无法将所有红色的调用串联起来,例如上图中我们可以将红色的调用中的第 1-2、3-4、5-6 等三对事件分别关联为三组,但还没有将这三组串成一个大的 Trace。而这一步就依靠 DeepFlow 中的 Session 聚合能力了。我们从 eBPF 的 Function Call 里面提取到 Request 和 Response,并将它们正确的识别为一个调用。一般来讲应用协议有两种,串行协议和并行协议。比如例如 HTTP2/gRPC 就是一个并行协议,它的协议头中会有一个 StreamID 字段可以用于请求和响应的聚合。我们可以断定并行协议中一定会有类似的字段,否则业务进程自身是无法将响应于请求对应上的。
而例如 HTTP 大部分场景下就是一个串行协议,在收到响应之前不会有新的请求发出来。但也有一些特殊情况,比如 HTTP 1.1 中就实现了一种比较鸡肋的半并行协议,它允许一口气发送多个请求,并按顺序接收到这些请求的响应的回复,但这样的机制也是有明确的规律可循。对于 Session 的聚合是 DeepFlow 的拿手本事了,这里展开的话会非常复杂,但总的来讲完成这一步的挑战其实关注两个方面就行了:利用时序关联两个相邻的调用事件,利用流聚合关联同一个调用的请求和响应事件。
至此非阻塞 IO 的问题被我们解决了,感觉不错!
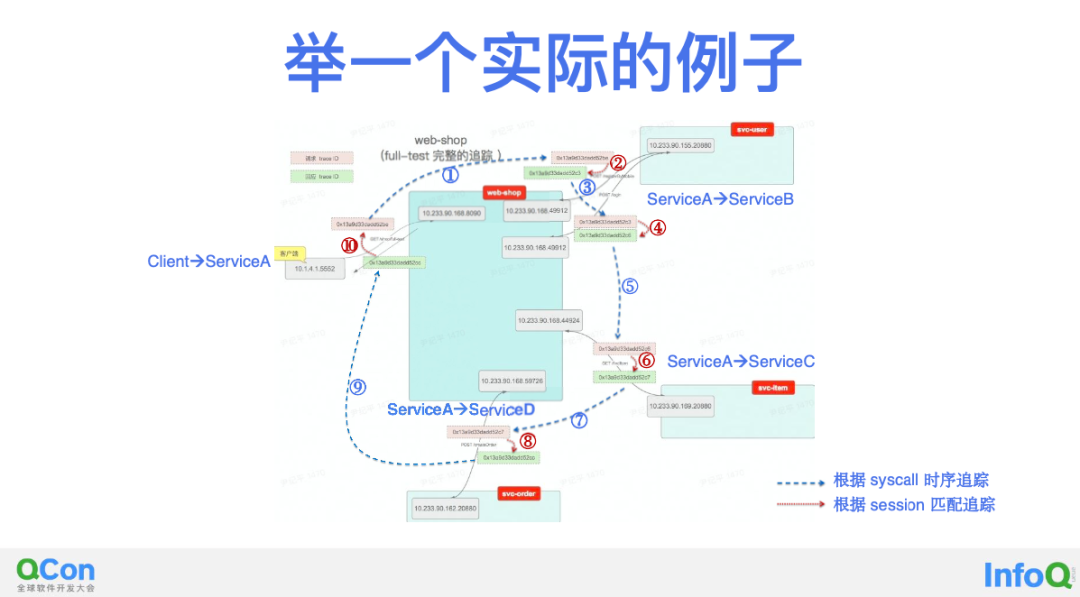
在解决前两个挑战之后,我们其实已经能在很多场景下实现对上下游调用的追踪能力了,依靠这个能力上图是一个实际的追踪例子,我们大致来感受下这个追踪的过程。图中的每一个正方形是一个服务,这也是 GitHub 上的一个微服务 Demo,中间的服务叫 web-shop,等会我们主要聚焦在它身上完成它的上下游调用的追踪。它左侧的 Client 请求 web-shop 以后,web-shop 依次调用两次 svc-user 完成注册和登录,然后调用一次 svc-item 完成购物,最后调用一次 svc-order 完成下单,之后返回 Client 完成此次下单的全流程。
图中在每个 eBPF 获取到的请求和响应事件上我们标记了一个 SyscallTraceID,标记橙色 ID 的是请求,标记绿色 ID 的是响应。根据 SyscallTraceID 的相等关系,我们可以将相邻两个调用关联起来(即图中的①③⑤⑦⑨)。通过将请求和响应聚合为 Session,我们可以将同一个调用中的两个 eBPF 事件关联起来(即图中的②④⑥⑧⑩)。
第三步,解决协程的问题。至此,Kernel Threading 这个占比非常大的场景我们已经有了非常好的解决方案。那是否可以去尝试一下 Hybrid Threading 场景呢?接下来我们以 Golang goroutine 为例来讲讲 DeepFlow 对协程语言的分布式追踪能力。实际上回顾下来刚才我们一直在做一件事情 —— 关联。那在协程的场景下如何实现关联呢?我们也用一张类似的图来解释:
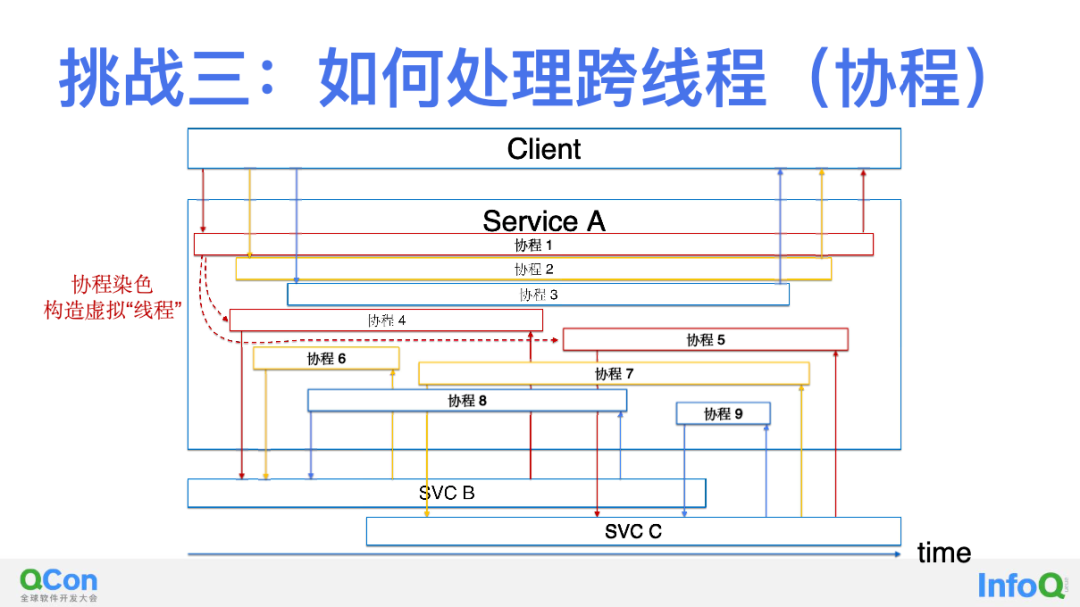
上图中红色、黄色、蓝色的调用依然组成了三个 Trace,不同点在于这些调用事件在 eBPF kprobe/tracepoint 中捕获时所在的 ThreadID 是混乱的,没有任何关联性,这是因为协程语言中的 coroutine 是动态绑定到内核线程中的,这完全是一个用户态程序的行为,内核无法进行控制。似乎我们已经走到死胡同了,在经历了一段时间的挫折之后我们终于找到了解决办法,也就是上图中称之为「协程染色」的机制。它背后的思想是源于对 Golang 中 API 调用处理,我们回忆一下一个 Golang 进程接收到一个 HTTP 请求时会在一个协程中处理该请求,当发现还需要继续请求上游其他服务时,Golang 的基础库会创建一个新的协程用于这个 HTTP 请求,这样做会避免每一个协程不要被卡死。仔细思考之后我们发现「协程的创建过程」其实就是我们要寻找的「关联性」。
通过 eBPF uprobe 我们获取一个 Golang 进程中的所有协程之间的创建关系,利用这样的创建关系(虚线)对协程进行染色,结果如上图所示,我们将所有协程染成了三组颜色,对应着三个 Trace。举例来讲,上图中的协程 1 创建了协程 4 和协程 5,DeepFlow 会将这三个协程染色为同样的颜色,并将这些协程中的调用关联在一个 Trace 中。简单来理解,我们可以认为染色后的同一个颜色的协程就类似一个我们在前面的场景中讨论的线程一样。
至此我们又攻克了一个难关,协程问题解决了!
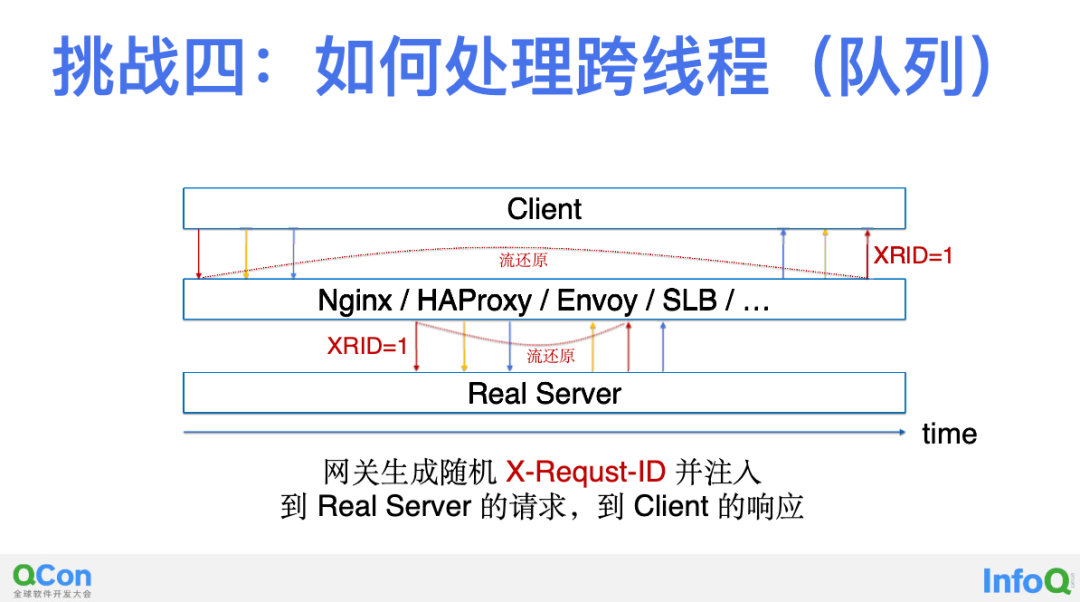
第四步,解决跨线程问题。我们继续往下走,还有一个迄今为止还没有解决的场景,跨线程。例如上图,在一个多线程的进程中,在处理来自 Client 的调用时同一个 Trace 中的上下游调用由不同的线程实现。由于缺少了关联信息,这件事情看起来又变得非常困难。得益于 DeepFlow 的 Session 聚合能力,如果一个调用的请求和响应位于两个线程中发生,对追踪是没有任何难度的,因为我们可以基于协议头部字段完成聚合。但如果一个 Trace 的不同调用位于两个线程中发生就比较困难了,比如进程中通过 Queue、Golang Channel 在不同线程之间传递 Task 信息,以及在不同线程中完成上游和下游的调用。
这其实是 DeepFlow 迄今为止唯一一个还没有完全解决的场景,但也有了一部分的解决方案,即图中展示的对于七层网关的解法。我们发现几乎任何七层网关都实现了一个非常标准化的能力,即向 HTTP Header 中注入 X-Request-ID 的能力。例如 Nginx、HAProxy、Envoy 等,他们都能为每个下游调用生成一个随机 ID,并将其注入到向上游发起的请求中,以及将其注入到回复给下游的响应中。于是我们通过提取调用中的该字段,可以将网关前后的两个调用关联起来。
注意整个过程我们都没有修改任何 Client 和 Real Server 的代码,只需要做一些网关的配置(有些网关是默认打开的,例如 Envoy),即可完成 X-Request-ID 信息的注入。
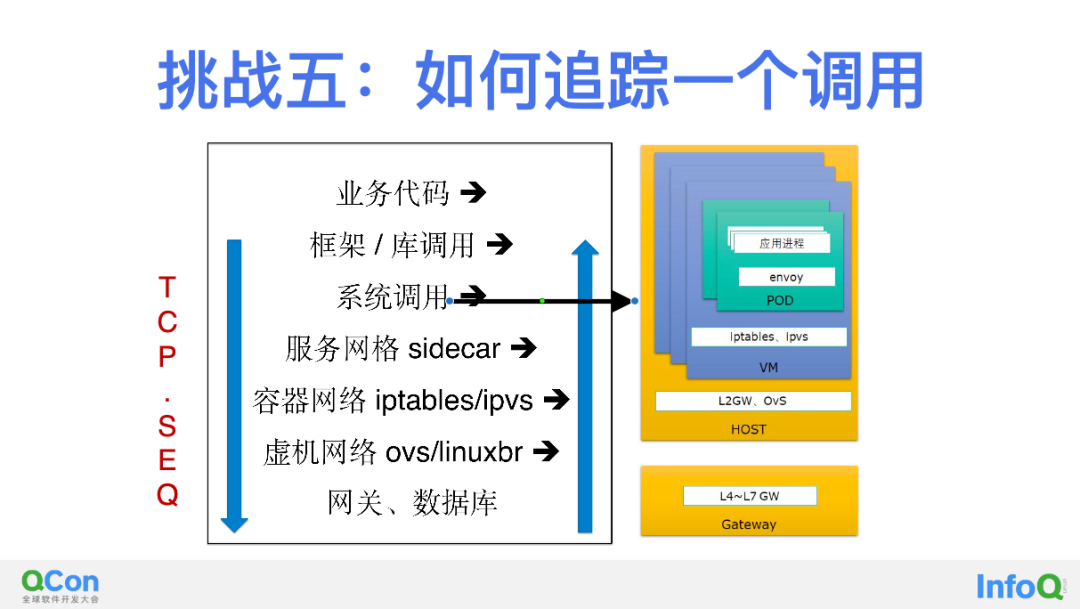
第五步,解决跨进程问题。其实前面四步都是在解决一个进程内部的上下游调用关联问题,接下来我们想把目光延展到两个服务进程之间。比如服务 A 调用服务 B,因为我们没有在请求 Header 中插入任何 TraceID 或 SpanID,如何能将很短一段时间内高频发生的成百上千次调用在两个不同节点、不同 Pod 之间观测到的 eBPF 事件关联起来呢?甚至还包括容器网络、云网络、NFV 网关等每一跳网络路径上发现的请求和响应事件,又怎么与 eBPF 采集的事件之间关联起来呢?
这里又要展示 DeepFlow 强大的网络基因了,这个事情其实非常简单,但也非常复杂。简单来讲,可以利用整个通信路径各处采集到的流量中的 TCP 包头特征信息将同一个调用关联起来,例如 TCP 包头中的 SEQ 信息,总共有 2x32=64 比特可以用于我们的关联,另外我们也还可以找到 IP 包头中的 ID 信息用于同样的目的。复杂的地方在于,虽然网络路径上都能采集到包,但在 eBPF 获取的系统调用和函数调用中并没有这个字段 —— 因为此时连 TCP 包都还没有(或者已经被拆开了),这个时候怎么将 eBPF 函数调用数据和 cBPF 网络流量数据关联呢?这里实际上只要能理解 TCP SEQ 的含义也容易想到解决方案,它表示的实际上是已经发送的字节的多少,了解这个背景之后我们就能轻松的在 eBPF 函数调用上下文中还原 Socket Data 将会(或刚刚)使用的 TCP SEQ 值了。
至此跨进程也被我们解决了。
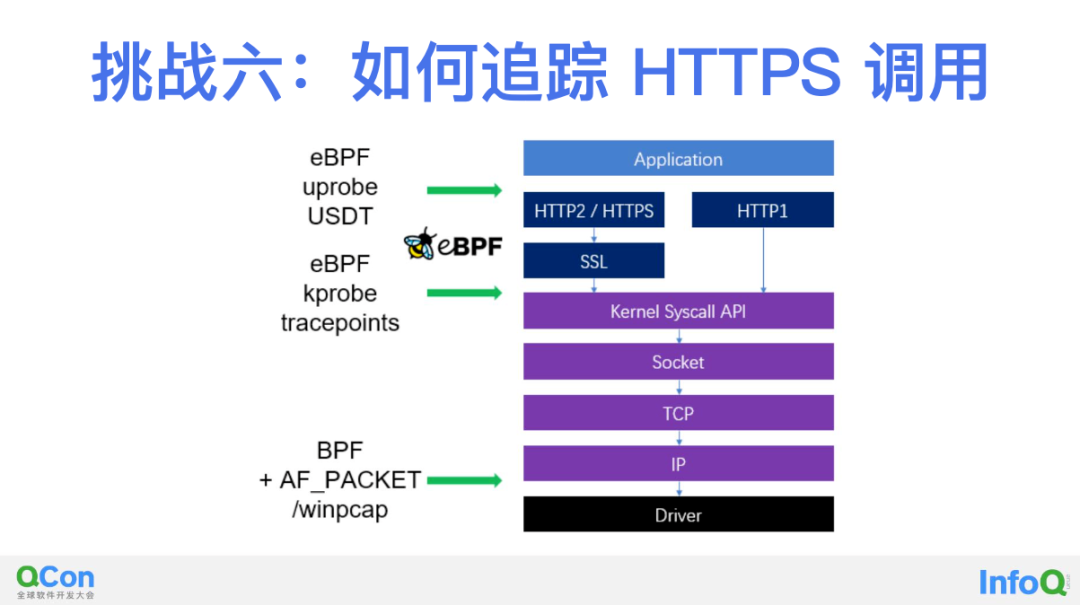
第六步,解决 SSL 加密的问题。这一点表面看起来很玄乎,实际上对于 eBPF 来讲也非常简单成熟。如上图所示通过 uprobe/USDT 我们可以在用户态函数调用中获取 HTTPS 加密之前的数据,例如通过挂载相对标准的 OpenSSL 以及 Golang 中的加密函数就能实现这一点。利用这样的思路同样也可解决 HTTP2 中的包头压缩问题,将压缩之前的包头信息完整的拿到。
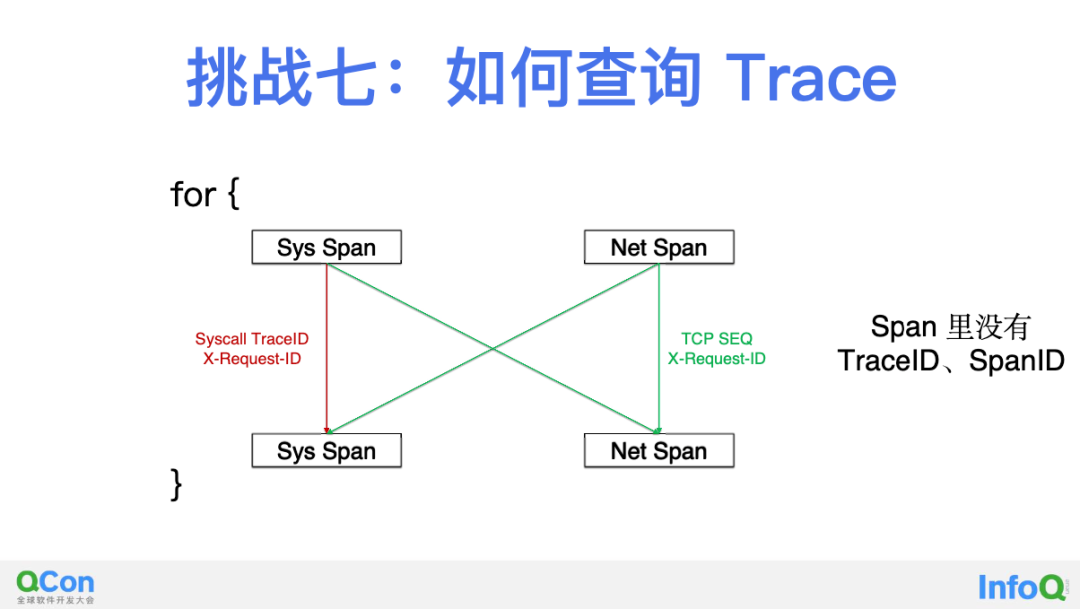
第七部,解决 Trace 组装问题。我们没有向任何 Span 中注入 TraceID 或 SpanID,那如何将这些 Span 组装为一个 Trace 呢?上图是 DeepFlow 中 Trace 查询过程的一个简化,我们可以从任何一个 eBPF Sys Span 出发,来查询与之相关的在一个 Trace 中的其他 eBPF Sys Span 和 cBPF Net Span。每当找到新的 Span 以后,循环迭代可以继续,直到无法发现更多 Span 为止。简单来讲,eBPF Span 之间可以使用 SyscallTraceID 进行关联查询,其他 Span 之间可以用 TCP SEQ 进行关联查询,另外所有 Span 之间都可以使用 X-Request-ID 进行关联查询。
到这里为止,我们从一个理想国,克服了七重困难,终于实现了一个比较美好的状态,实现了最初基于 Istio Bookinfo Demo 展示的超能力 —— 零代码修改实现分布式追踪。相信下文的描述会让你真切感受到它的漂亮。
让追踪无盲点:结合 OpenTelemetry,实现全栈、全链路的分布式追踪
没有银弹,AutoTracing 很美,但正如我刚才所说它「目前为止」还没有很好的解决跨线程的问题,以及我们没有让他去追踪进程内部的两个函数之间的调用关系。这个世界上没有一招鲜的银弹,但是有好基友能搞 CP,我们发现的 CP 就是 eBPF 和 OpenTelemetry:eBPF 是从内核中成长起来的零侵扰的应用观测方法,而 OTel 是从大量业务实践中成长起来的标准化代码注入方法,一个偏向基础设置另一个偏向业务逻辑,听起来就绝配。在 DeepFlow 中我们也实现了他们二者的完美结合。
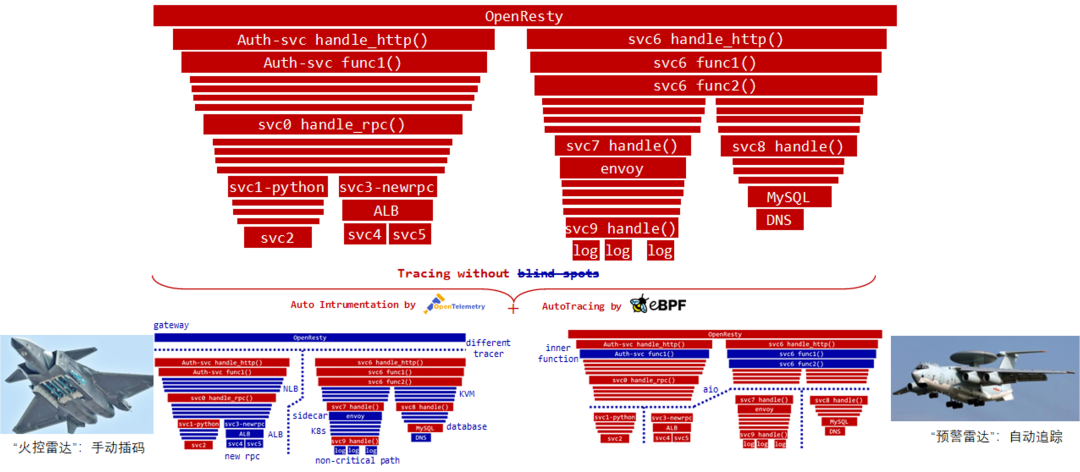
首先从另一个角度理解一下这两种追踪能力的区别。对于我们业务代码中生成的 Span,它就像战斗机上装配的火控雷达一样,它的目标性非常明显,是定点打击,在某一个方向上是可以非常纵深、非常精确,但它无法做到全覆盖,特别是对位于视野之外的基础设施服务、网络路径没有任何覆盖。而 eBPF 的追踪方式其实像预警机的预警雷达一样,它能覆盖所有的微服务,能解锁「地图全开」的技能,但有些点,比如说在进程内部函数调用的追踪、以及跨线程的调用场景无法完美覆盖到。我们很难想象现代战争中缺少了预警机还能打赢,当然缺少了战斗机也没发开打。从这个类似上我们发现,将二者的能力结合是如此的自然。
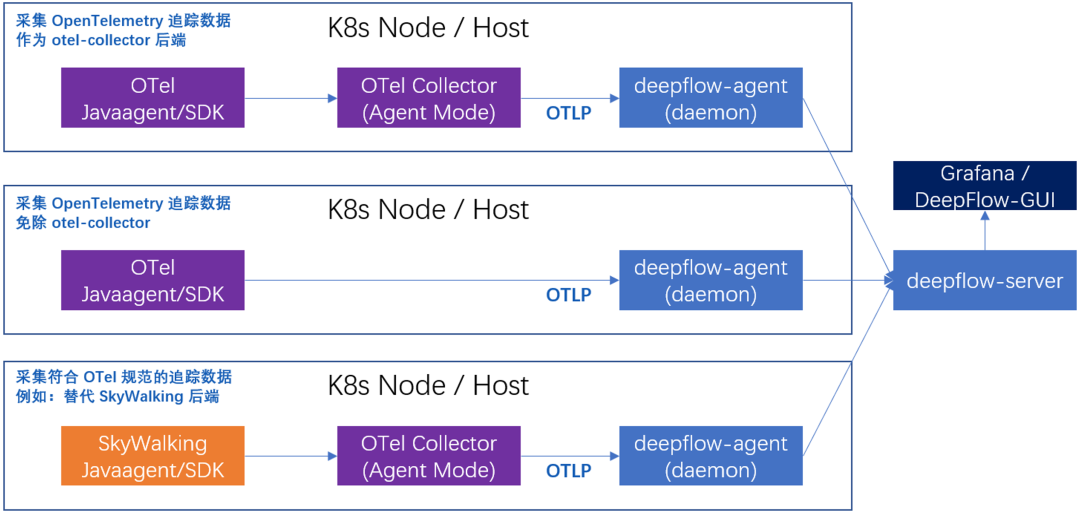
DeepFlow 是怎么做的?我们通过 OTel/SkyWalking 的 JavaAgent 或 SDK 采集代码中的 Span,并通过 OTel Collector 中转(或者直接发送)至 deepflow-agent 进行收集,并与 eBPF Sys Span 和 cBPF Net Span 进行关联。这里我们也给 OpenTelemetry 和 SkyWalking 社区做了一些贡献,实现了 OTel Collector 中的 SkyWalking Receiver。
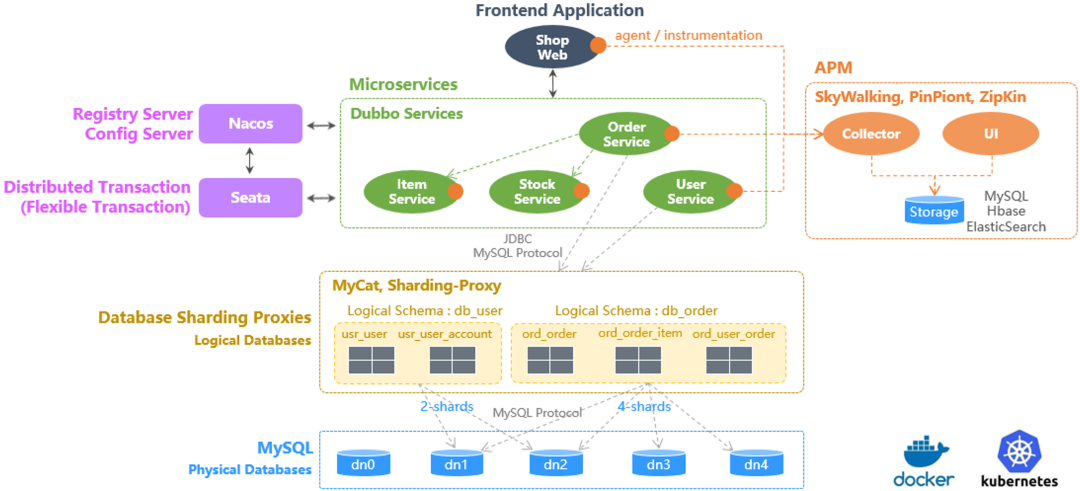
来看看实际的效果,上图中的 Sprint Boot Demo 应用,它包含四五个微服务,以及 MySQL 作为数据库。
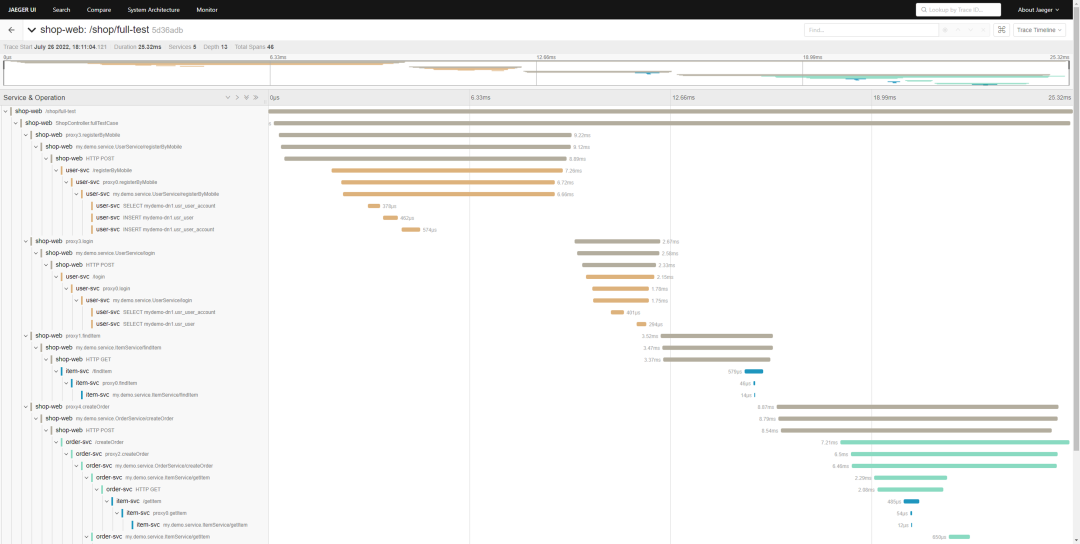
上图是大家所熟悉的 OTel 加 Jaeger 的效果,追踪出了有 40 多个 Span。
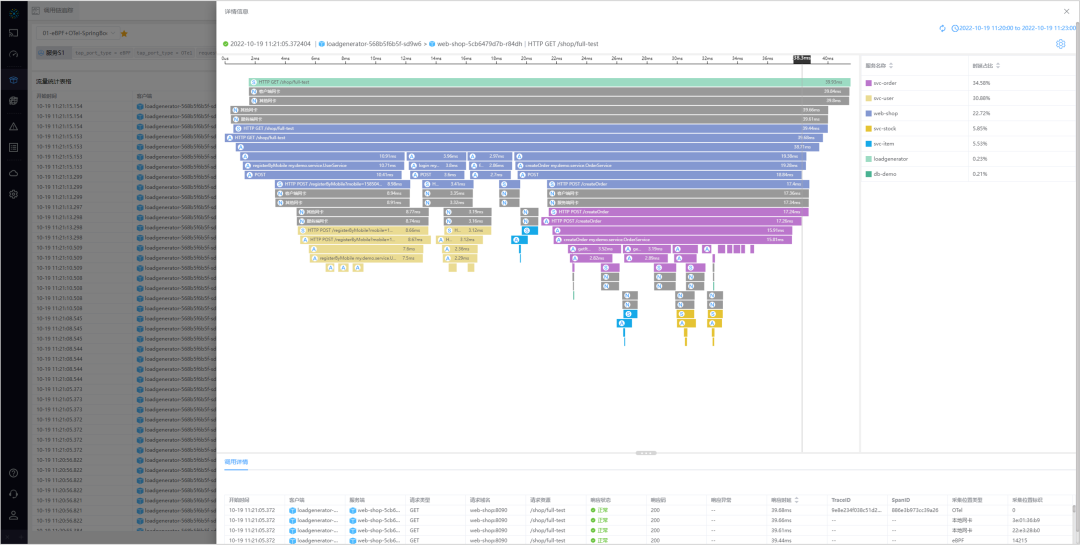
DeepFlow 的效果如何?一个直观的感受是 Span 的数量 Double 了,有 90 多个 Span,这里有 OTel 采集到的、以 A 开头的 Application Span,也有 eBPF Sys Span 和 cBPF Net Span。
接下来,会细致地分析一下这张追踪火焰图。

上图中有两个放大的区域。第一个区域是调用链中深蓝色服务调用浅蓝色服务的过程,可以看到我们将追踪过程从业务代码,到框架代码,再到系统进程、沿途的网络接口等全部追踪了下来。另外一个区域是图中对 MySQL 调用过程的放大,从 MySQL 事务的开始到事务的结束,能清晰地看到时间到底是消耗在 ORM 框架上,还是网络传输上,或者是 MySQL 服务端。图中客户端业务代码等待时间很长而 eBPF 采集到的时延很短,我们推断应该是 ORM 处理抵消导致。除了这两个区域以外,我们发现 eBPF 的追踪结果除了能基于 OTel 的追踪补足基础设施路径以外,还能将整个火焰图上下延展,例如图中客户端 locust 进程、数据库 MySQL 进程都没有插码,但都出现在了火焰图中。
相信你看到上面的结果之后能快速意识到一点:这个火焰图实际上已经将各个不同的岗位统一到一个频道上来了!包括业务开发团队、框架开发团队、服务网格团队、容器运维团队、云运维团队、数据库运维团队。所有这些信息结合起来,我们可以回答很多各个层面的人的问题,到底 A 调用 B 的时候是谁的问题?我调用别人慢是我的问题吗?是他的问题吗?还是基础设施的问题?这些都能够快速回答出来。
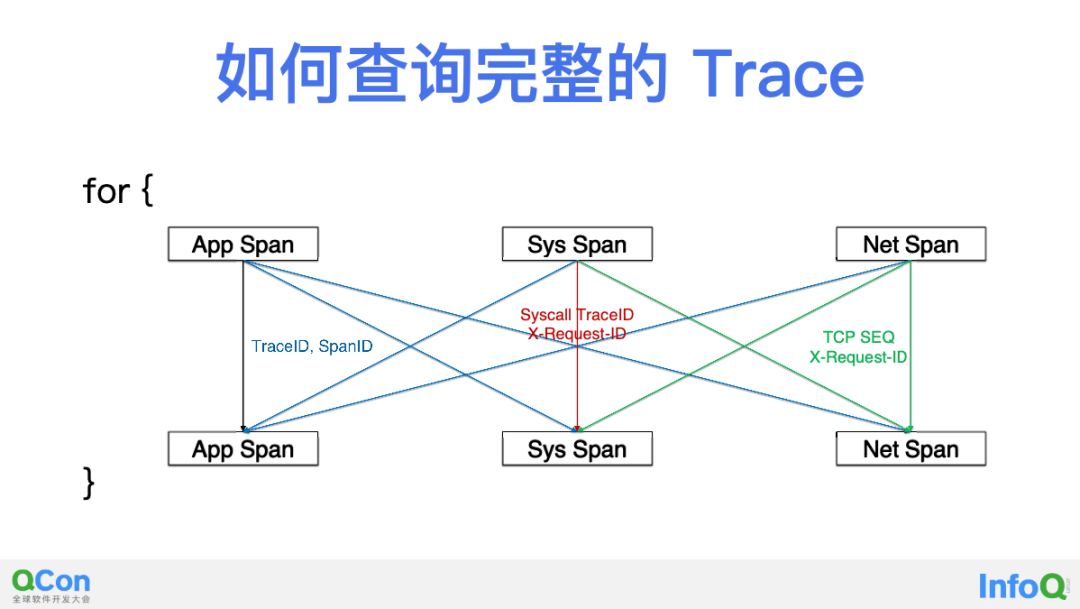
实现 eBPF 和 OTel 数据的融合其实并不困难。从 eBPF 和 cBPF 中采集到的 Span 中,我们解析出来了 HTTP/Dubbo 等协议头中的 TraceID 和 SpanID 字段,如上图所示可以轻松的实现和 App Span 的关联。
展望未来:开源共建,开启高度自动化的可观测性新时代
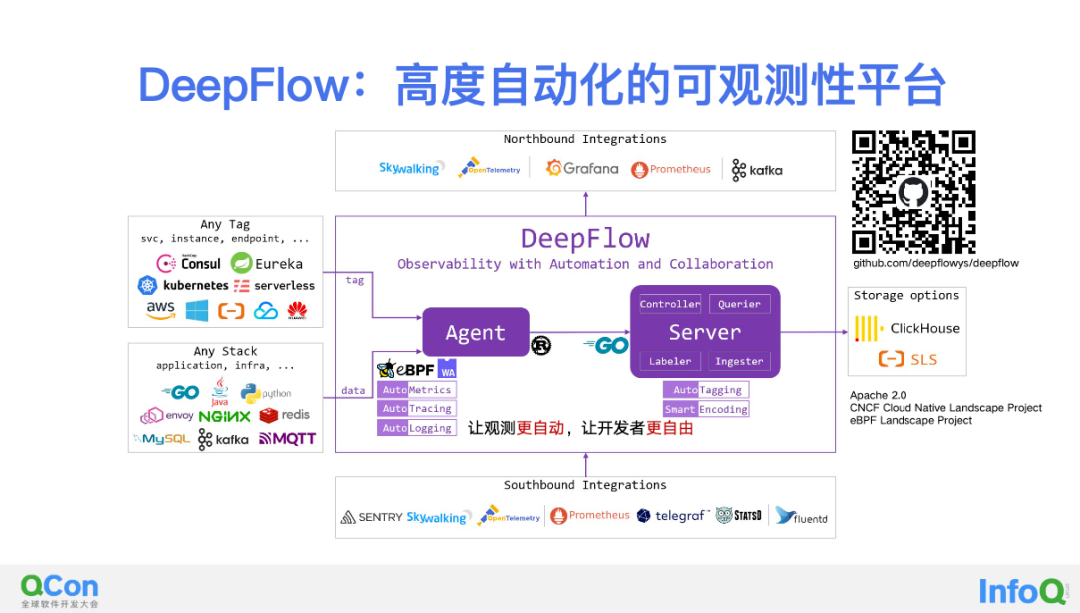
DeepFlow 这个项目它是我们开源的一个零代码修改实现云原生应用可观测性的软件。它的软件架构非常简单,主要由 Agent 和 Server 组成,我们分别使用 Rust 和 Golang 实现了这两个组件。上图右上角是 DeepFlow 的 GitHub 的 Link,欢迎大家 Star!
eBPF 主要的优势在于零侵扰,无需修改业务代码既能自动化的实现可观测性。除了本文所说的非常酷炫的 AutoTracing 以外,DeepFlow 中还用 eBPF 实现了很多其他能力。
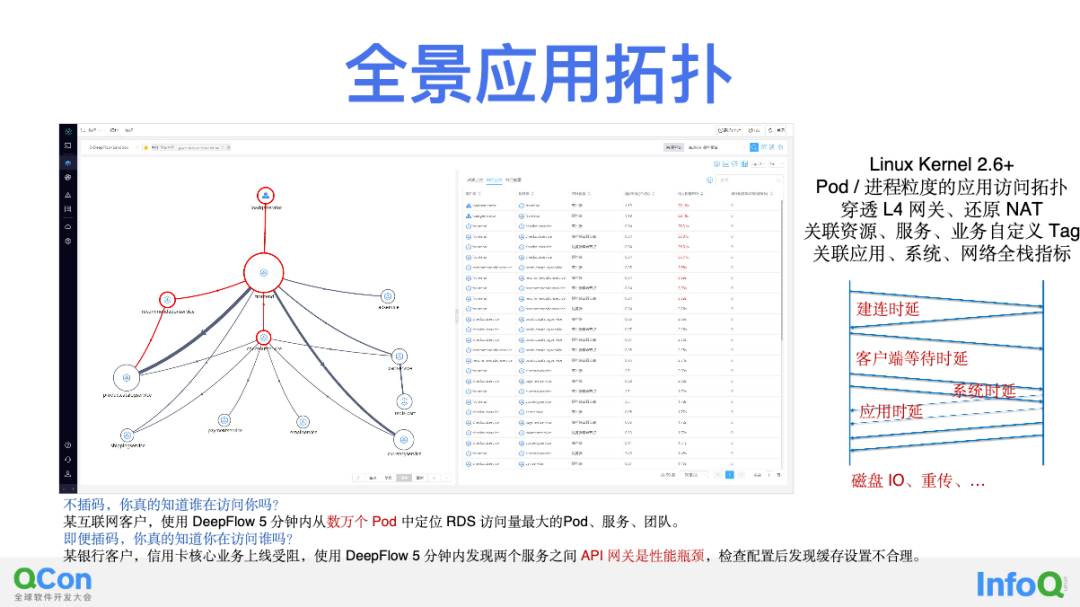
比如说 DeepFlow 有一个全景应用拓扑(Universal Application Topology)能力,这也是用 eBPF/cBPF 零代码修改情况下绘制出来的。简单来说,即可以支持在 Linux Kernel 2.6 以上内核版本的运行环境中,自动绘制任何 Pod、任何进程之间的访问关系拓扑图。这样的拓扑以往需要通过插码获取 Span 以后聚合生成,现在使用 DeepFlow 无需做任何改动,也不需要利用 Service Mesh 机制间接支持,一条命令五分钟部署 DeepFlow 以后整个全景拓扑就出来了。另外支撑拓扑的是我们通过 eBPF/cBPF 计算出的丰富的性能指标,这些指标覆盖到了从网络传输性能、网络协议栈性能、应用 RED 黄金指标等各个层面。
举个例子,承载一个 HTTP 调用的 TCP 连接,它的建连消耗了多少时间、客户端等待了多长时间、系统协议栈的 ACK 回复是否及时、期间是否有网络包重传、真正的应用请求和响应之间的耗时是多少等等,我们都能看到。
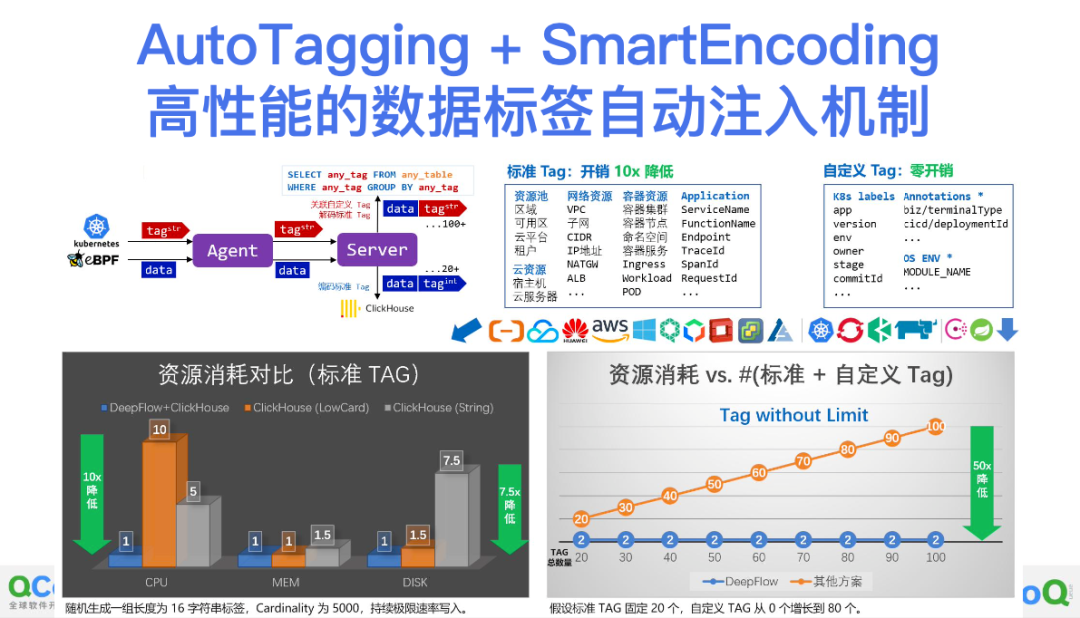
DeepFlow 中的另一个亮眼能力是支持丰富的、自动化的标签注入,我们用了一种指标和标签分离、标签预压缩的方式,可以把标准标签注入的开销降低 10 倍,并通过查询时的自定义标签关联实现了 Tag without Limit 的能力。你可以从 GitHub 上拉下来代码实际压测一下,非常扎实的性能提升,丰富到吃惊的标签能力。这些能力也就是一条命令部署五分钟就能体验到,也可登录 deepflow.io 查看我们的在线 Demo。
最后是 DeepFlow 一些未来的演进点,比如说我们的 AutoTracing 怎样去解决跨线程的问题;文件读写怎样关联到 Trace 上面;我们应该去解析更多的应用协议,现在我们支持将十余种协议。我们会引入 WASM 和 LUA 插件机制解锁可编程能力,因为肯定有很多私有协议需要用户自己手动实现解析,而且也会有很多业务字段藏在标准协议中,这些都是可编程能力的用武之地。
以上,就是本文的全部内容。希望 DeepFlow 能让观测更自动,让开发者更自由!
作者介绍
向阳,云杉网络研发 VP。清华大学博士,毕业后加入云杉网络,现负责 DeepFlow 产品。最近我们将 DeepFlow 进行了开源(Apache 2.0 License),不久前刚发布了第一个社区版 Release。DeepFlow 致力于为云原生开发者提供一个高度自动化的可观测性平台,让观测更自动,让开发者更自由!
活动推荐
5 月 26 日 -5 月 27 日,QCon 全球软件开发大会即将落地广州,从稳定性即生命线、出海的思考、现代数据架构、AGI 与 AIGC 落地、下一代软件架构、研发效能提升、DevOps vs 平台工程、新型数据库、数据驱动业务、数智化效率革命、金融分布式核心系统、大前端技术探索、编程语言实战等角度与你探讨,欢迎你来现场打卡交流~
点击此处直达大会官网,现在购票享 8 折优惠,组团购票还有更多折扣,感兴趣的同学联系票务经理:15600537884(电话同微信)。





