
LevelDB 是一款十分优秀的存储引擎,具有极高的数据读写性能,尤其是写入性能,在笔者经历的多个项目中都有用到,因此本文打算结合 LevelDB 的部分源码对 LevelDB 进行介绍,首先会介绍 LevelDB 的整体架构,然后围绕数据读写流程和合并流程展开介绍,希望与大家一同交流。文章作者:唐文博,腾讯优图实验室高级研究员。
一、LevelDB 总体架构
LevelDB 是一款写性能极高、可靠的单机存储引擎,是 LSM-Tree 的典型实现,LSM-Tree 最主要的思想是牺牲部分读性能,最大化提升数据写入性能,因此 LevelDB 很适合被应用在写多读少的场景。
同时 LevelDB 还有数据在磁盘上按 key 顺序存储,支持按 snapshot 快照查询等特性。如下图所示,LevelDB 主要由驻于内存的缓存结构和存在于磁盘的物理文件组成。
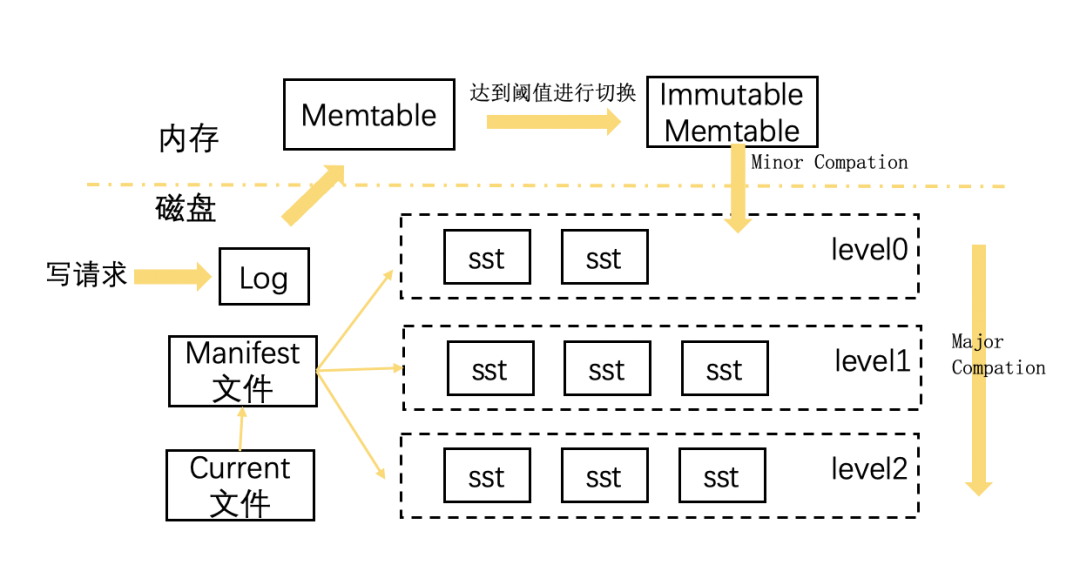
1. 内存缓存结构
Memtable:Memtable 可读可写,内部由 SkipList 实现,用于在内存中缓存写操作。
Immutable Memtable:内部同样由 SkipList 实现,但是只读,当 Memtable 的大小达到设定的阈值时,会变成 Immutable Memtable,后续由后台线程通过 compaction 操作将数据顺序落盘,变成 sstable 文件。
2. 磁盘文件
sstable:sstable 是磁盘上的存储文件,它将 key 有序存放,level0 层的 sstable 由内存中的 Immutable Memtable 直接持久化生成,因为没有和当前层的其他文件合并过,因此 level0 层的 sstable 里的 key 会发生重叠,其余层的 sstable 文件均由当前层和前一层的 sstable 文件归并而来。
Manifest:Manifest 文件是 sstable 的索引信息,用来记录每个 sstable 对应的 key range、文件 size 等信息。
Log:Log 文件主要是用于机器重启而不丢失数据,当向 LevelDB 写入一条数据时,它首先会向 Log 文件顺序写入一条操作日志,然后再向内存 Memtable 写入数据,这样即便机器掉电,也不会出现数据丢失的情况。
Current 文件:当机器重启时,LevelDB 会重新生成新的 Manifest 文件,所以 Manifest 文件可能存在多个,这里会使用 Current 文件记录当前使用的 Manifest 文件。
二、写入流程
LevelDB 对外提供的写入接口有 Put 和 Delete 两种,两者本质上对应同一种操作,实际上都会向 Memtable 及 Log 文件中追加一条新纪录。
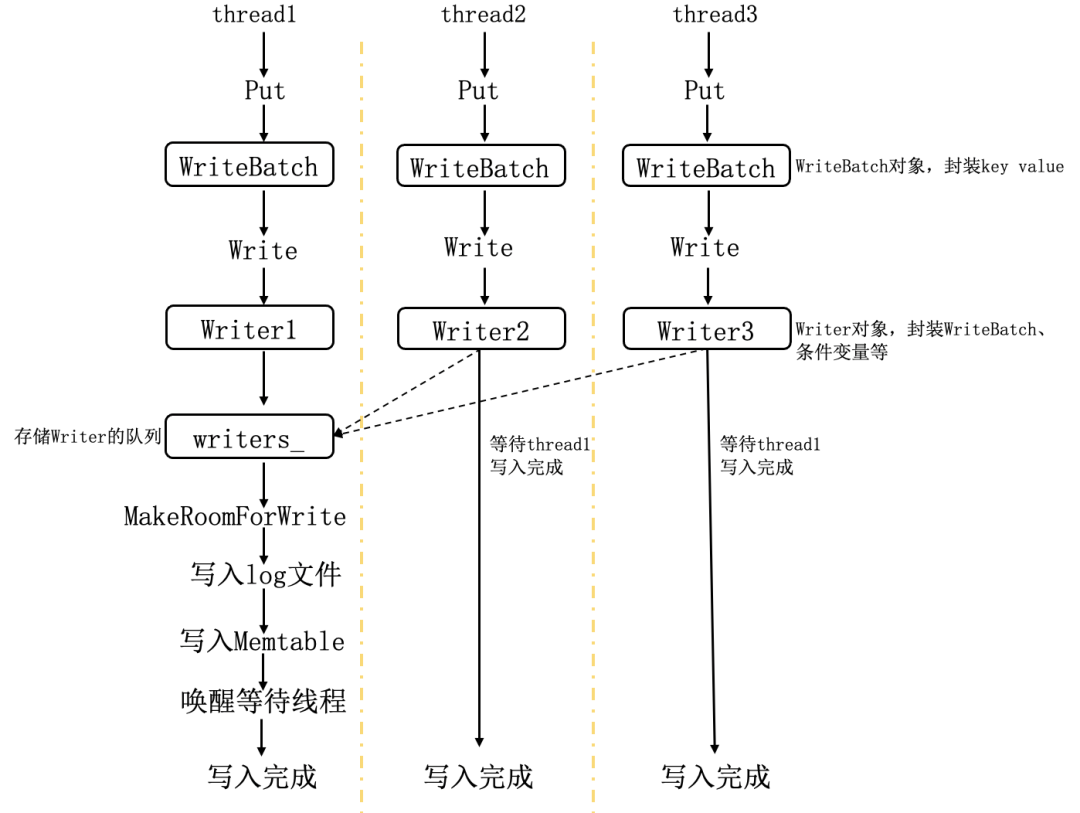
同时 LevelDB 支持调用端使用多线程并发写入数据,并且会使用写队列+合并写 &WAL 机制,将批量随机写转化成一次顺序写,从而提升写入性能。下边将结合部分源码来看看 LevelDB 具体是怎么实现的。
1. 具体写入流程
(1)封装 WriteBatch 和 Writer 对象
DB::Put 会把 key、value 方法封装到 WriteBatch 中,DBImpl::Write 方法会把 WriteBatch 对象封装到 Writer 对象中,此外 Writer 对象还封装了 mutex_,条件变量等用来实现等待通知。
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) { WriteBatch batch; batch.Put(key, value); //调用DBImpl::Write方法 return Write(opt, &batch);}struct DBImpl::Writer { Status status; WriteBatch* batch; bool sync; bool done; port::CondVar cv; explicit Writer(port::Mutex* mu) : cv(mu) { }};(2)Writer 串行化入队
多个线程并行的写入操作,会通过抢锁串行化,线程将 Writer 放到写队列之后,会进入等待状态,直到满足如下两个条件:
其他线程已经帮忙把 Writer 写入;
抢到锁并且是写队列的首节点。
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { Writer w(&mutex_); w.batch = updates; w.sync = options.sync; w.done = false; MutexLock l(&mutex_); writers_.push_back(&w); //任务放到queue中,如果当前不是queue的头部则等待 //当某个线程将queue中自己对应的Writer写入磁盘时,可能也会将其他线程对应的Writer写入磁盘 while (!w.done && &w != writers_.front()) { w.cv.Wait(); } if (w.done) { return w.status; }(3)确认写入空间足够
处于写队列头部的线程会调用 MakeRoomForWrite 方法,MakeRoomForWrite 方法会检查 Memtable 是否有足够的空间写入,它会将内存占用过高的 Memtable 转换成 Immutable,并构造一个新的 Memtable 进行写入,刚刚形成的 Immutable 则交由后台线程 dump 到 level0 层。
Status DBImpl::MakeRoomForWrite(bool force) { //通过改变指针指向,将Memtable转换成Immutable imm_ = mem_; has_imm_.store(true, std::memory_order_release); //生成新的Memtable mem_ = new MemTable(internal_comparator_); mem_->Ref(); //触发compaction MaybeScheduleCompaction();}(4)批量取任务,进行合并写
处于写队列头部的线程进行完 MakeRoomForWrite 检查之后,便会从 writers_写队列里取出头部任务,同时会遍历队列中后面的 Writer 合并到自身,进行批量写,从而提高写入效率,最终多个 Writer 任务会先被写入 Log 文件,然后被写入内存的 MemTable。
//从队列中批量取任务 WriteBatch* write_batch = BuildBatchGroup(&last_writer);//将任务写入Log文件status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));//将任务写入Memtablestatus = WriteBatchInternal::InsertInto(write_batch, mem_);(5)唤醒正在等待的线程
线程写入完成后,会对写完的 Writer 出队,并唤醒正在等在的线程,同时也会唤醒写队列中新的头部 Writer 对应的线程。
//last_writer指向writers_里合并的最后一个Writer //逐个遍历弹出writers_里的元素,并唤醒对应的正在等待的写线程,直到遇到last_writer while (true) { Writer* ready = writers_.front(); writers_.pop_front(); if (ready != &w) { ready->status = status; ready->done = true; ready->cv.Signal(); } if (ready == last_writer) break; } // 唤醒队列未写入的第一个Writer if (!writers_.empty()) { writers_.front()->cv.Signal(); }最后对写入步骤进行简单总结,如下图所示,三个写线程同时调用 LevelDB 的 Put 接口并发写入,三个线程首先会通过抢锁将构造的 Writer 对象串行的放入 writers_写队列,这时 Writer1 处于写队列头部,thread1 会执行批量写操作,不仅会把自己构造的 Writer 写入,还会从队列中取出 thread2、thread3 对应的 Writer,最后将三者一起写入 Log 文件及内存 Memtable,thread2、thread3 在 push 完之后则会进入等待状态。thread1 写入完成之后,会唤醒处于等待状态的 thread2 和 thread3。
三、读取流程
LevelDB 的读取流程相对简单,从其中读取一个数据,会按照从上而下 memtable -> immutable -> sstable 的顺序读取,读不到则从下一个层级读取,因此 LevelDB 更适合读取最新写入的数据。流程如下图:
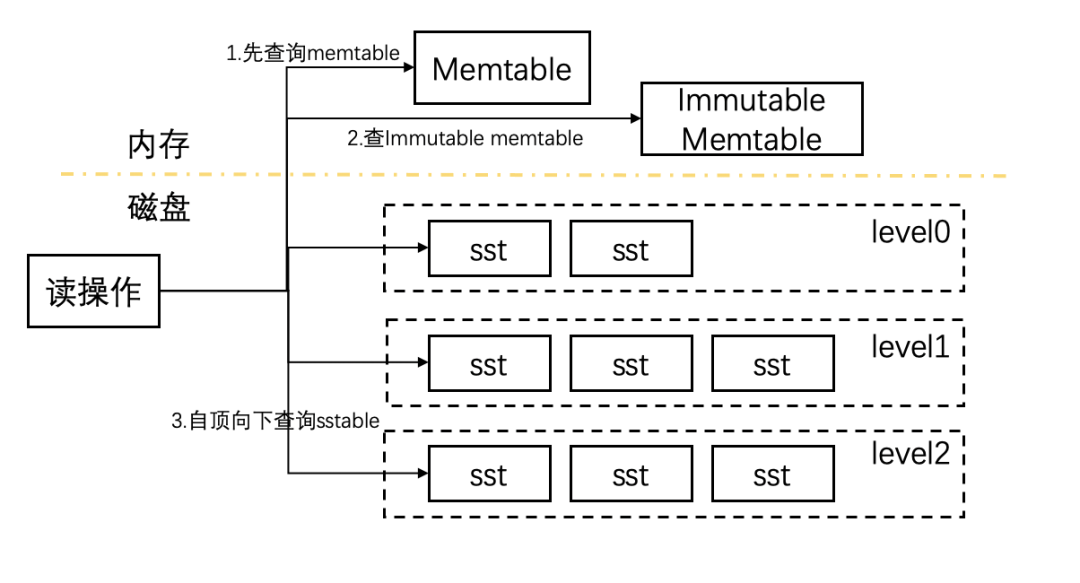
Level0 中的文件直接由 Immutable Memtable 通过 dump 产生,文件之间 key 可能相互重叠,所以需要对 level0 的每个文件依次查找。
对于其他层次,LevelDB 的归并过程保证了其中的 key 互相不重叠并且有序,因此可以直接使用二分方式进行数据查找。部分代码如下:
{ mutex_.Unlock(); // First look in the memtable, then in the immutable memtable (if any). LookupKey lkey(key, snapshot); //先查找memtable if (mem->Get(lkey, value, &s)) { //再查找immutable memtable } else if (imm != nullptr && imm->Get(lkey, value, &s)) { } else { //查找sstable s = current->Get(options, lkey, value, &stats); have_stat_update = true; } mutex_.Lock(); }四、Compaction 流程
Compaction 是 LevelDB 中相对比较复杂的操作,这里仅对其中比较主要的点进行介绍。compactcion 分为 2 种,一是 minor compaction,另一种是 major compaction。通过 compaction 操作可以达到以下几个效果:
将内存中的数据持久化到磁盘;
清理冗余数据,因为 LevelDB 的更新和删除操作具有延后性,两种操作实际上都会向 LevelDB 写入一条新记录,所以通过重新 compaction 整理数据,可以清理冗余数据,节省磁盘空间;
通过 compaction 使 level 0 以下的文件层中的数据保持有序,这样便可以通过二分进行数据查找,同时也可以减少待查找的文件数量,提升读效率。
1. minor compaction
minor compaction 相对简单,对应 Immutable 持久化到 level0 层的过程。但是如果这一步骤的处理耗时过长,那么就会导致内存中的 Memtable 无法写入但又没有办法及时转化成 Immutable,所以高性能持久化是对 minor compaction 最主要的要求。
为了提升数据持久化的速度,在对 Immutable 进行持久化时不会考虑不同文件间的重复和顺序问题,这样带来的问题是对读不够友好,读取数据时需要读取 level0 层的所有文件。
(1)触发 minor compaction 的时机
当内存中的 memtable size 小于配置的阈值时,数据都会直接更新到 memtable。超过大小后,memtable 转化为 Immutable,这时会由一个后台线程负责将 Immutable 持久化到磁盘成为 level0 的 sstable 文件。
(2)compaction 具体流程
将 Immutable memtable 落盘成 SSTable 文件
DBImpl::WriteLevel0Table 会将 Immutable memtable 落盘成 SSTable 文件,同时会将文件信息记录到 edit(用于存储文件的摘要信息,如 key range, file_size 等)中。值得注意的是,新生成的 SSTable 文件实际上并不总是被放到 Level0 层,如果新生成的 sstable 的 key 与当前 Level1 层所有文件都没有重叠,则会直接将文件放到 Level1 层。
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit, Version* base) { //生成sstable编号,用于构建文件名 FileMetaData meta; meta.number = versions_->NewFileNumber(); Status s; { mutex_.Unlock(); //更新memtable中的全部数据到xxx.ldb文件 //meta记录key range, file_size等sst信息 s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta); mutex_.Lock(); } int level = 0; if (s.ok() && meta.file_size > 0) { const Slice min_user_key = meta.smallest.user_key(); const Slice max_user_key = meta.largest.user_key(); if (base != nullptr) { //为新生成的sstable选择合适的level(不一定总是0) level = base->PickLevelForMemTableOutput(min_user_key, max_user_key); } //level及file meta记录到edit edit->AddFile(level, meta.number, meta.file_size, meta.smallest, meta.largest); }}(2)将 edit 信息记录到 version_
WriteLevel0Table 执行完成之后,会将新生成的 edit 信息记录到 version_(version_是整个 LevelDB 的元信息。每当因为 compaction 生成新的 sstable 时,version_就会随之改动)中,当前的 version_作为数据库的一个最新状态,后续的读写操作都会基于该状态。
//记录edit信息versions_->LogAndApply(&edit, &mutex_);//释放imm_空间imm_->Unref();imm_ = nullptr;has_imm_.Release_Store(nullptr);//清理无用文件DeleteObsoleteFiles();2. major compation
major compaction 负责将磁盘上的 sstable 进行合并,每合并一次,sstable 中的数据就落到更底一层,数据慢慢被合并到底层的 level。
这种设计带来的一个明显的好处是可以清理冗余数据,节省磁盘空间,因为之前被标记删的数据可以在 major compaction 的过程中被清理。
level0 中数据文件之间是无序的,但被归并到 level1 之后,数据变得有序,这使读操作需要查询的文件数就会变少,因此,major compaction 带来的另一个好处是可以提升读效率。
(1)触发 major compaction 的时机
level 0 层:sstable 文件个数超过指定个数。因为 level0 是从 Immutable 直接转储而来,所以用个数限制而不是文件大小。
level i 层:第 i 层的 sstable size 总大小超过(10^i) MB。level 越大,说明数据越冷,读取的几率越小,因此对于 level 更大的层,给定的 size 阈值更大,从而减少 comaction 次数。
对于 sstable 文件还有 seek 次数限制,如果文件多次 seek 但是一直没有查找到数据,那么就应该被合并了,否则会浪费更多的 seek。
(2)compaction 流程
选择合适的 level 及 sstable 文件用于合并
筛选文件会根据 size_compaction 规则(level0 层的 sstable 文件个数或当前 level 的 sstable size 总大小)或者 seek_compaction 规则(文件空 seek 的次数)计算应当合并的文件。
对于 size_compaction,leveldb 首先为每一层计算一个 score,最后会选择 score 最大的 level 层的文件进行合并:
level 0 层的 score 计算规则为:文件数 / 4;
level i 层的计算规则为:整个 level 所有的 file size 总和/(10^i)。
void VersionSet::Finalize(Version* v) { // Precomputed best level for next compaction int best_level = -1; double best_score = -1 for (int level = 0; level < config::kNumLevels - 1; level++) { double score; //对于level 0使用文件数/4计算score if (level == 0) { score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger); } else { //对于非0层,使用该层文件的总大小 // Compute the ratio of current size to size limit. const uint64_t level_bytes = TotalFileSize(v->files_[level]); score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level); } if (score > best_score) { best_level = level; best_score = score; } } //使用compaction_level_记录需要合并的层,使用compaction_score_记录合并分数 v->compaction_level_ = best_level; v->compaction_score_ = best_score;}对于 seek_compaction,会为每一个新的 sstable 文件维护一个 allowed_seek 的初始阈值,表示最多容忍多少次 seek miss,当 allowed_seeks 递减到小于 0 了,那么会将对应的文件标记为需要 compact。
bool Version::UpdateStats(const GetStats& stats) { FileMetaData* f = stats.seek_file; if (f != nullptr) { f->allowed_seeks--; if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr) { file_to_compact_ = f; file_to_compact_level_ = stats.seek_file_level; return true; } } return false;}根据 key 重叠情况扩大输入文件集合
根据 key 重叠情况扩大输入文件集合的基本思想是:所有有重叠的 level+1 层文件都要参与 compact,得到这些文件后,反过来看下,在不增加 level+1 层文件的前提下,能否继续增加 level 层的文件。具体步骤如下:
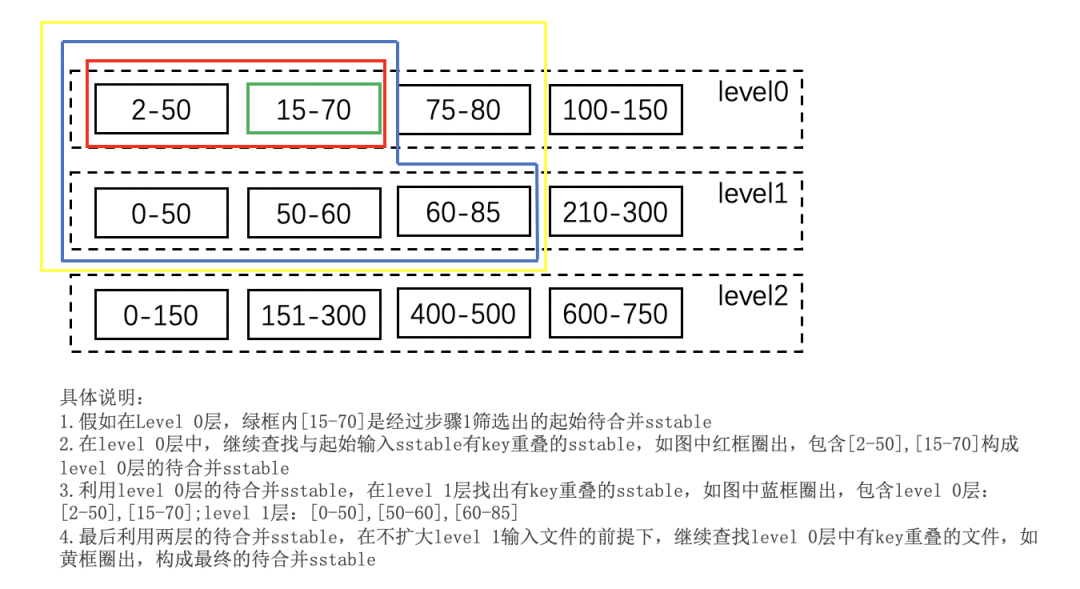
多路合并
多路合并会将上一步骤选出来的待合并 sstable 中的数据按序整理。如下,代码中 VersionSet::MakeInputIterator 函数返回了一个迭代器对象,通过遍历该迭代器对象,则可以得到全部有序的 key 集合。
Iterator* VersionSet::MakeInputIterator(Compaction* c) { const int space = (c->level() == 0 ? c->inputs_[0].size() + 1 : 2); // list存储所有Iterator Iterator** list = new Iterator*[space]; int num = 0; for (int which = 0; which < 2; which++) { if (!c->inputs_[which].empty()) { //第0层 if (c->level() + which == 0) { const std::vector<FileMetaData*>& files = c->inputs_[which]; // Iterator* Table::NewIterator for (size_t i = 0; i < files.size(); i++) { list[num++] = table_cache_->NewIterator( options, files[i]->number, files[i]->file_size); } } else { // Create concatenating iterator for the files from this level list[num++] = NewTwoLevelIterator( // 遍历文件列表的iterator new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]), &GetFileIterator, table_cache_, options); } } }参考链接:
[1] https://leveldb-handbook.readthedocs.io/zh/latest/basic.html
[2] https://draveness.me/bigtable-leveldb/
[3] https://izualzhy.cn/start-leveldb
头图:Unsplash
作者:唐文博 - 腾讯优图实验室高级研究员
原文:LevelDB原理解析:数据的读写与合并是怎样发生的?
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




