共创作者:韩同阳,极越汽车大数据架构师 & SelectDB 内容团队
导读:极越是高端智能汽车机器人品牌,基于领先的百度 AI 能力和吉利 SEA 浩瀚架构生态赋能,致力于打造智能化领先的汽车机器人,以高阶智驾、智舱产品和创新数字化服务,为用户创造标杆级智能科技出行体验。随着全球汽车行业向电动化、智能化加速转型,对车端数据实时精准响应的需求也越来越高,经过对比选型,极越汽车选择 Apache Doris 作为实时数仓底座来升级 BI 分析平台和用户画像系统。截至目前,基于 Apache Doris 开发的数据智能服务体系 2.0 已经部署在多套生产集群,其优秀的读写性能、低成本数据接入流程和丰富的大数据生态支持,既提升了车端、云端的数据处理效率,又简化实时数据流架构,还能一定程度上节约计算和存储成本、简化运维。
近年来,全球汽车行业向电动化、智能化加速转型,随着技术的不断迭代,智能化能力已成为行业头部公司间互相比拼的重点。2023 年以来,中国汽车市场的新能源渗透率更是进一步提升,智能驾驶已成为影响用户购车的核心因素之一。极越汽车作为高端智能汽车机器人品牌,致力于打造智能化领先的汽车机器人,以高阶智驾、智舱产品和创新数字化服务,为用户创造标杆级智能科技出行体验。
与互联网行业相比,新能源汽车的数据来源更丰富,数据场景也更加多样化。为了满足客户端、车端、门店端等海量数据实时分析的需求,以数据驱动汽车智能化的演进,极越汽车选择 Apache Doris 作为数据底座来升级整体数据智能服务体系。截至目前,Apache Doris 已经在实时数仓、BI 多维分析、用户画像、车云中心(Serving)等多个业务场景中落地。
业务挑战和诉求
在实际运营过程中,新能源汽车每天都会产生海量的、对汽车全生命周期至关重要的复杂数据,这些数据来源主要包括:APP 与小程序、门店与工厂、车端数据、云端数据等。
为了充分发挥数据背后的价值,我们构建了多个业务平台来响应一线业务人员和经营管理者的分析系统,例如统一的实时/离线数据仓库体系、BI 多维分析引擎、用户画像 CDP 平台以及车辆中心云平台等。丰富多样的数据服务场景和高时效性的业务要求,其中所依赖的核心便是 OLAP 数据库,因此我们希望其具备以下能力:
支持多种数据分析场景:例如对于 APP 与小程序、门店与工厂以及车端等各种来源的复杂数据都能提供高效的数据支持,为业务决策赋能。
实时数据分析响应:在数据实时写入和更新的同时,支持快速及时的查询响应;
运维难度低:生态独立,不依赖其他技术栈,运维简单且利于上手。
OLAP 调研与技术选型
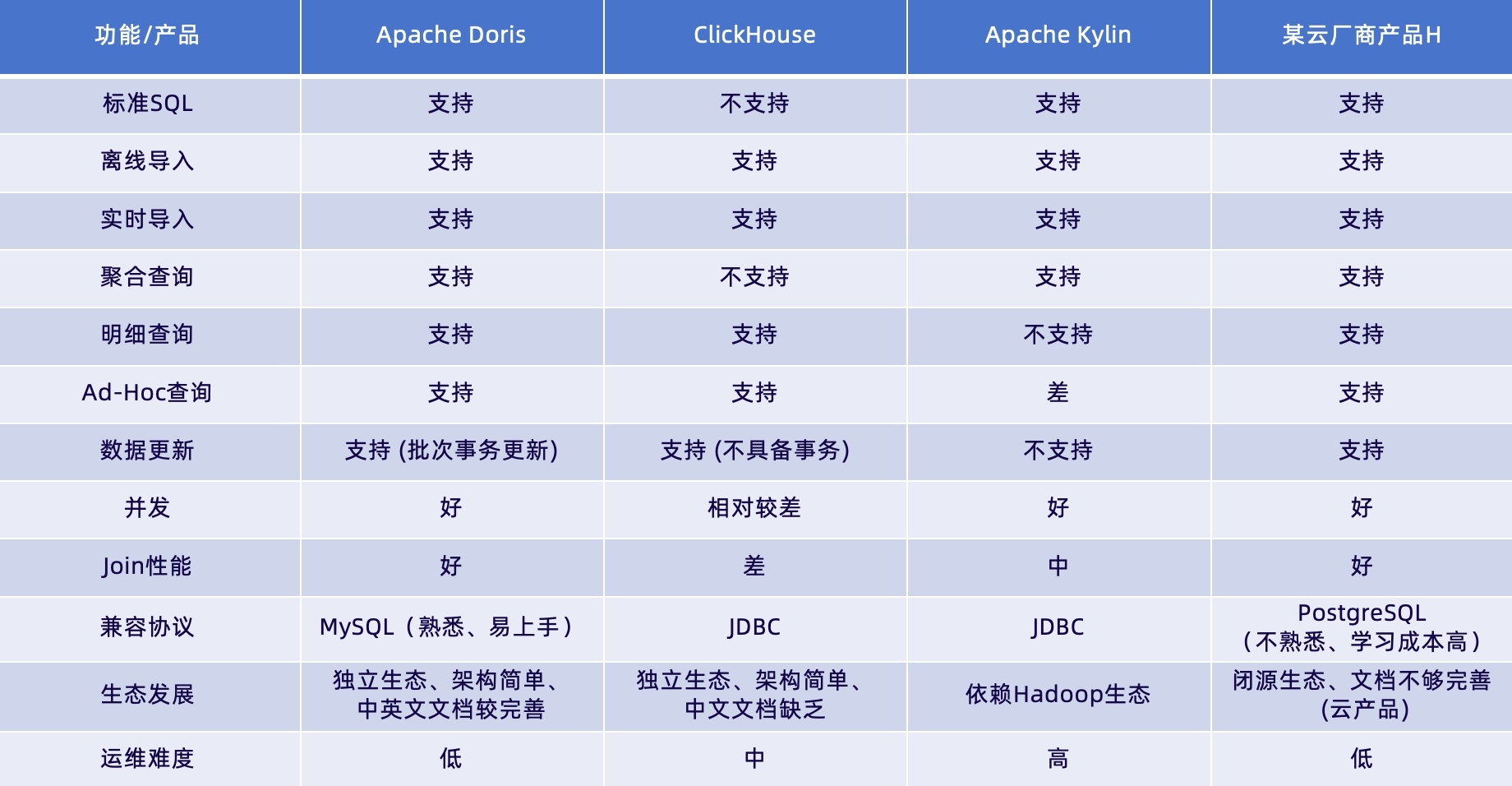
在选型调研阶段,我们深入考察了 Apache Doris、ClickHouse、Apache Kylin 和某云厂商产品 H 这四款 OLAP 数据库产品,主要从数据实时更新能力、多维数据分析和 JOIN 性能三个方面进行考察。
考虑实时数据更新能力和 Join 性能的高优先级需求,我们首先排除了 ClickHouse 和 Apache Kylin,再对比与某云厂商的产品,由于其产品非开源且产品生态较为封闭,综合对比下来 Apache Doris 与我们的目标诉求高度匹配:
多维数据分析能力强:在系统并发、Join 性能以及多个功能的易用性方面皆满足我们对数仓高效数据处理的要求;
数据更新及时:支持批次事务更新,有效实现数据的实时采集、处理和分析;
运维保障:可视化运维管控与可视化查询,运维简单,且官网中英文档较完善,易于上手。同时,由于 Doris 不依赖其他大数据生态,在生态发展方面更加独立,使用起来更加灵活。
实时数仓建设与实践优化
在引入 Apache Doris 之前,过去的实时数仓基于 Kafka 流式数据构建。由于 Kafka 对海量数据的存储能力比较有限,限制了长时间历史数据的查询和回溯。另外加工好的数据需要存放在不同的查询引擎,导致数据加工的成本比较高,且难以支持复杂的即席查询。
以 Apache Doris 升级实时数据仓库,可以充分有效解决我们目前面临的问题。因此,我们基于 Apache Doris 打造了统一的离线/实时数仓体系,实时响应业务需求。下图是引入 Apache Doris 后的实时数仓架构图,具体工作机制如下:
ODS 贴源层:主要用于存放未经处理的原始数据,通过 Flume 等实时采集工具,将数据湖中未经处理的原始日志以及告警数据统一汇集到 ODS 层,同时完全相同的数据也会被存入 HDFS 中一份,作为原始数据核查依据或进行数据回放。
DWD 明细层:该层为事实表,数据通过 Flink 计算引擎实时对生产数据及字段进行清洗、标准化、回填、脱敏之后写入 Kafka 。Kafka 中的数据还会对接到 Doris 中,以支持明细日志数据回溯查询、实时数据分析及其他业务。
DWS 汇总层:以 DWD 明细层数据为基础,通过动态规则引擎进行细粒度的聚合分析,为后续业务查询和 OLAP 分析做准备,同时大部分建模分析的结果也集中在 DWS 层。
ADS 应用层:该层主要使用 Doris 的 Aggregate Key 模型和 Unique Key 模型对以上三层的数据进行自动聚合或自动更新,以满足业务场景的具体分析需求。
DIM 维度层:主要存放维度数据,例如客户端数据、门店数据、车机数据、活动数据等,存放的数据最终将结合具体业务场景来使用。

初期阶段,我们也遇到了一些性能方面的挑战。下面结合两个具体应用场景,分享我们在使用过程中的性能调优经验。
01 高频 DDL Alter 优化
在离线/实时数仓 ETL 场景,每天凌晨 5 点常常出现 Doris DDL 频繁操作失败的情况。经过排查,原因如下:
线程池在重建过程中,默认的异步线程返回时间设置不当,导致超时。
跟踪源码发现,由于当前线程池规模相对较小,当多个 DDL 操作并行执行时线程资源不足,引发了线程等待,最终超时失败。
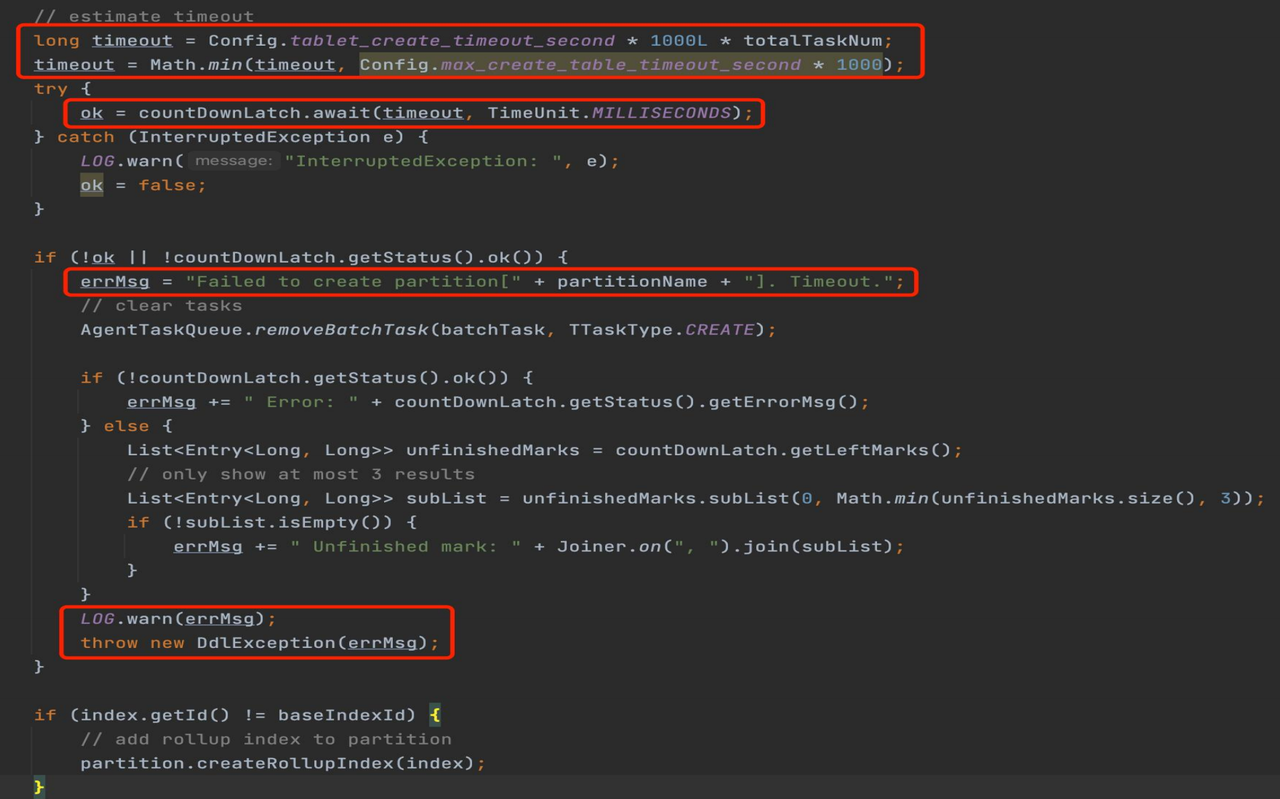
针对上述问题,我们调整了以下线程池参数:
单个 Tablet 超时参数从 1 改为 2:
tablet_create_timeout_second = 2创建 tablet 线程池参数,由 3 调整为 6:
create_tablet_worker_count = 6修改 tablet 线程池参数,由 3 调整为 6:
alter_tablet_worker_count = 6
调优后,操作失败率显著改善。相比于之前 90% 的失败率,现在的失败率仅有 10% 左右。
调整以上参数后,DDL 高频操作失败的问题暂时得以解决,但进一步了解业务场景后发现,为了将离线数据导入到 Doris ,前期我们进行了 Truncate 表操作和添加 Partition 操作,其中 Truncate 表操作会造成所有的 Tablet 重建,这个操作消耗了大量的内存,而且存在数据 GAP 时间(在 GAP 时间内,用户查询数据时得到的结果并非最新数据)。
针对这种场景,我们在 Doris 中有一个推荐的最佳实践方案:
非分区表:创建原表对应的临时表,写入数据到临时表中,然后进行表替换操作(表替换操作是原子性的);
分区表:创建原表分区对应的临时分区,写入数据到临时分区中,然后进行分区替换操作(分区替换是原子性的)。
02 Stream Load 写入性能调优
智能汽车在行驶过程中,系统会对驱动电机、能耗情况、通讯定位等数据全面监测,因此在离线和实时场景下,都需要写入大规模车辆数据。
为了提升 Stream Load 的写入性能,我们进行了多处参数调优:
提升单磁盘 Compaction 的频率,将任务线程由 2 增加到 4:
compaction_task_num_per_disk = 4增加 Compaction 线程总数,从默认 10 增加到 16:
max_compaction_threads compaction = 16减少 Compaction 合并任务量:
max_cumulative_compaction_num_singleton_deltas = 500 max_tablet_version_num = 1500 min_compaction_failure_interval_sec = 5更换海量日志存储场景修改表的压缩方式,将数据压缩算法从默认的 lz4 换成 zstd。在原 lz4 压缩格式下 230GB 的数据,改为 zstd 后只占用 150GB 的存储空间,压缩率提升了 35 %:
"compression" = "zstd"
另外,在大批量 Stream Load 导入的过程中容易遇到 -235 的问题,因为我们加入了 Stream Load 写入保护机制,具体为:
拥塞避免:当 Stream Load 写入数据返回 -235 异常时,写入线程进行休眠,初次休眠时间为 1 秒(后续每次休眠时间是上次休眠时间的 2 倍),等待休眠时间结束后再次重试写入,如果仍然失败则继续休眠,直至达到设置的休眠上限后(总休眠时间或者总次数),才将该次 Stream Load 写入请求置为失败。
慢恢复:当 Stream Load 写入数据返回 -235 异常时,如果在休眠之后的某次重试成功了,此时为了避免 Doris 有过大的写入压力,不直接进行下一次的 Stream Load 写入请求,而是将写入休眠时间进行指数级减少,直至 Doris 恢复正常写入速度。
这两个写入保护机制的引用,有效缓解了 Doris 写入大量数据时的压力,使得数据导入场景的任务成功率和吞吐率提升了 50%。
BI 分析平台实践及优化
BI 分析平台涵盖丰富的汽车数据业务场景,包括经营决策分析、市场趋势分析、销量预测、增长分析等。在数据分析模块,我们往往倾向于使用可视化查询分析引擎,为业务决策赋能。
01 早期业务痛点
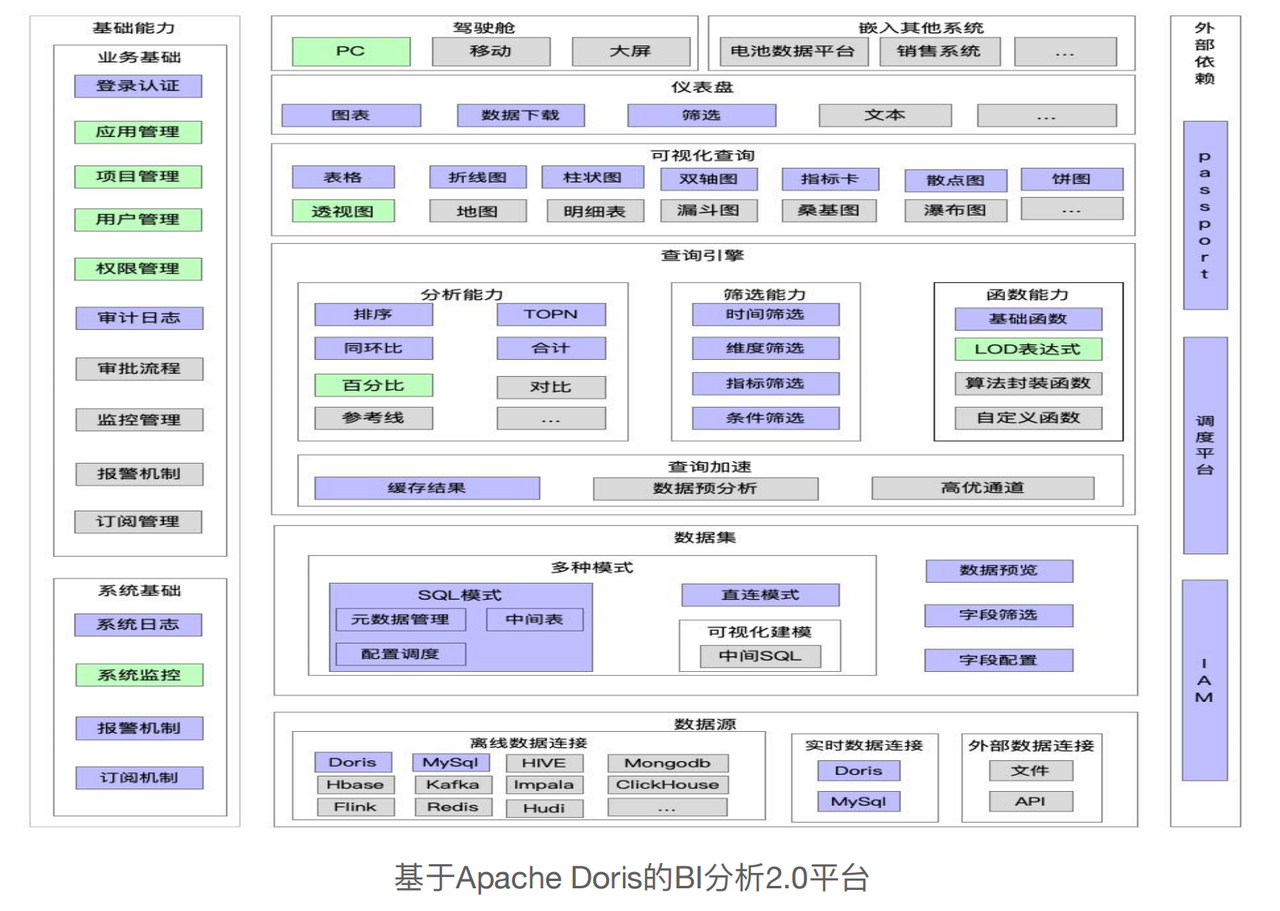
上图是 1.0 平台架构图,早期的业务十分依赖第三方引擎的数据处理能力, 由于构建成熟度低,系统性能瓶颈很快暴露出来,对业务支持带来严峻挑战:
诉求响应不够及时:第三方厂商查询引擎在客户访问量较大情况下,响应速率明显下降,无法满足智能汽车对实时数据分析处理的要求。
数据安全风险高:用户数据与车端数据面临信息泄露的风险,数据安全治理的问题亟待解决。
使用成本高:随着多方位的分析业务数据量增长,第三方产品的使用成本也越来越高
分析局限:对某些特殊场景的支持不够友好
技术兼容难度大:与内部的其他系统的技术兼容性差,数据互通面临庞大的开发成本。
02 BI 分析平台 2.0
面对双向复杂的数据架构环境,首要挑战是数据实时响应的压力,我们需要确保 BI 分析平台能够迅速、准确地应对各种车端及用户端数据变化,这也促使我们开始了 BI 分析平台 2.0 的改造计划。在整个 BI 分析平台的改造过程中,我们充分将业务需求与 Apache Doris 的各项优势相结合:
查询性能突出:Apache Doris 能支持多种复杂的业务场景,特别是在需要快速查询响应的场景中表现突出。例如在车端信号数据的实时响应中,能够实时接收和处理来自车辆的各种信号数据,为业务决策提供实时、准确的数据支持。
实时响应:在某些场景中对数据的时效性有着极其敏感的需求,以预知车辆抛锚情况为例,能够更快分析车辆运行数据、及时发现潜在的故障隐患、触发相应的预警机制,并规划相应的救援安排。
技术栈统一:原本实时和离线数据分别由多个不同数据库进行存储,在升级后通过 Apache Doris 实现离线数据和实时数据的统一处理,实现技术栈的统一。
成本节约:减少部署多个系统带来的硬件成本,且自身的易用性和可维护性也降低了运维成本。
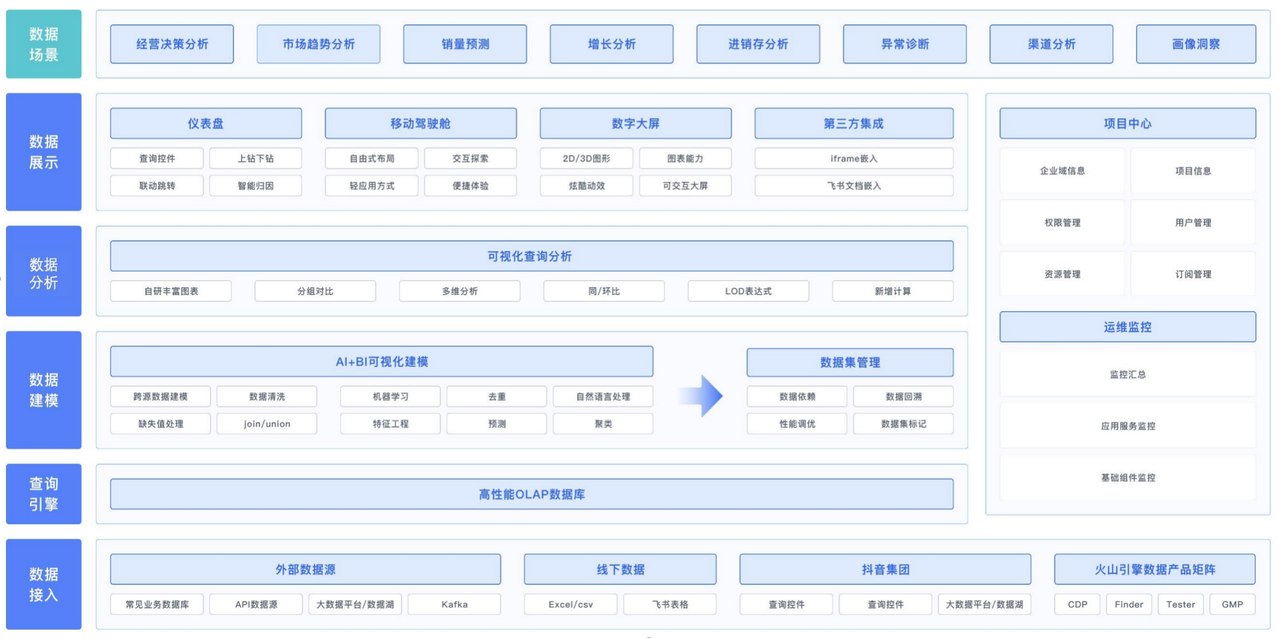
基于 Apache Doris 我们重新构造了 BI 分析平台 2.0,在数据处理、分析应用等方面进行了架构升级。在重构过程中,我们也积累了一些 Doris 性能优化的经验,与大家一同分享。
03 内存占用优化
在使用 BI 分析 2.0 平台时,部分用户反馈某页面图标无法展现,此时 Doris BE 内存占用率高达 99%,导致其他查询失败。经排查,某个 SQL 扫描了全表,而 Doris Session 级别和 Global 级别的内存保护机制均未生效。
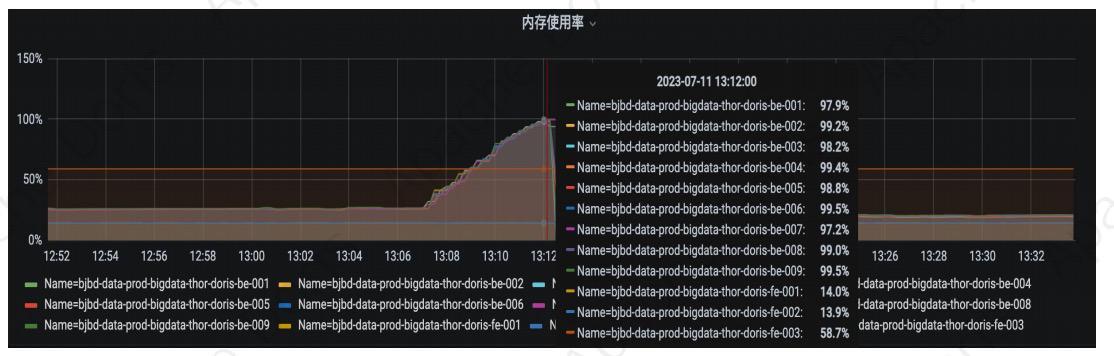
进一步排查发现,MemTracker 的两个参数 mem_tracker_cancel_query 、proc_meminfo_cancel_query 默认值都是 False ,当内存超过一定限制时拦截无法生效;改为 true 后,内存保护机制正常运行,问题得以解决。
1.2.x 版本后,这两个参数默认值已调整为 true。
点击 Memtracker 参考详情功能解析
04 BE Crash 问题定位
2.0 平台的某单个 Query 异常导致 BE 崩溃,这类问题需要第一时间定位到灾难场景,以便进行诊断与快速修复。在使用过程中,我们遇到了两个未产生 Query Id 的场景,审计日志、be.INFO 日志中都未发现目标 Query 。
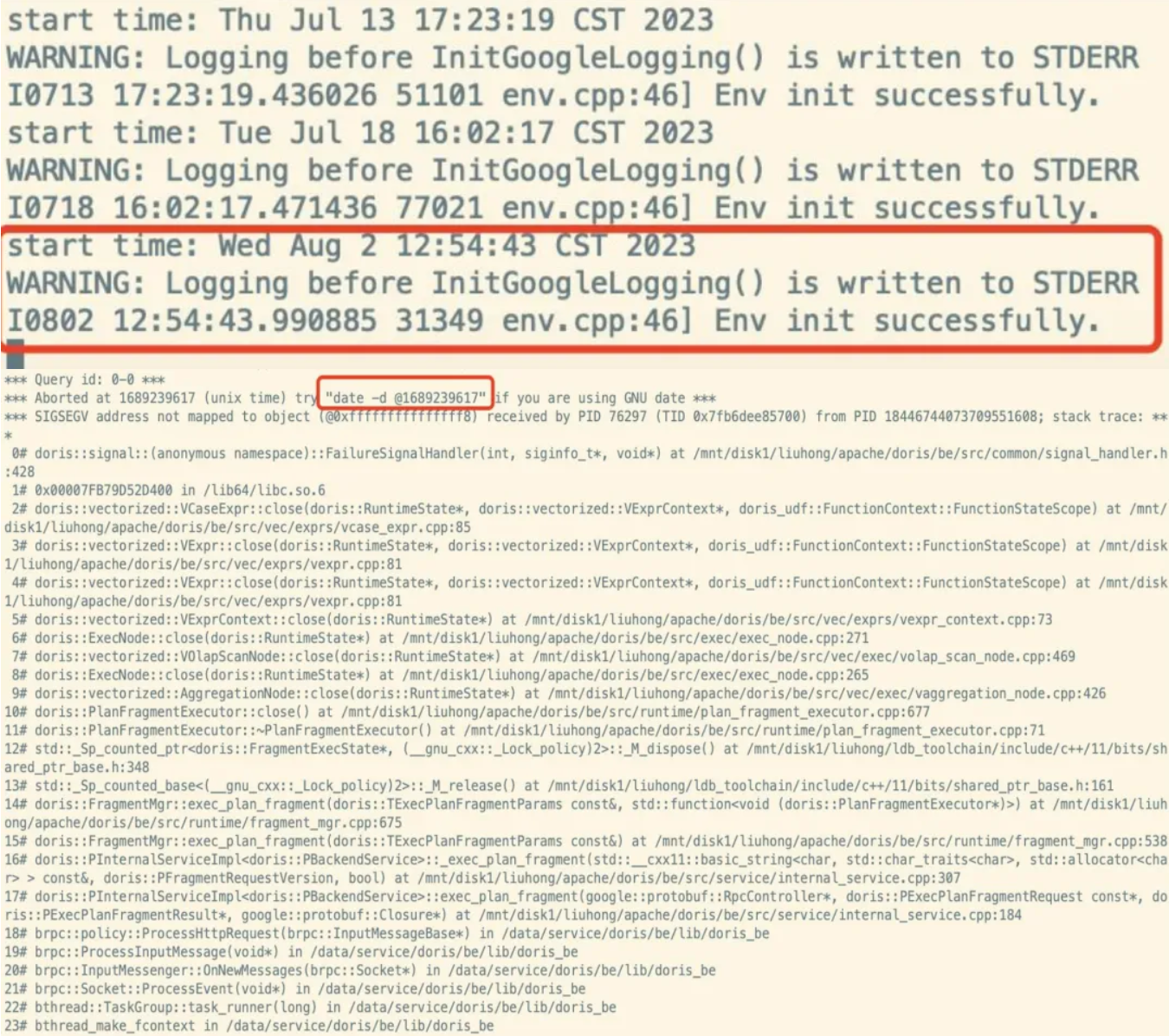
于是我们尝试以下 2 个方法进行问题定位:
查看 Core Dump 文件,未找到有效信息;
查看客户端日志,在 RPC Exception 的超时上下文部分中,定位到了目标 Query。
经分析,导致 Crash 的原因主要有以下两点:
客户使用不当触发 Bug:BI 分析 2.0 平台支持用户编写 SQL ,由于语法错误,触发了 Doris 1.1.5 版本 Bug,当前新版本已修复。
暴力使用的边界场景:平台未限制 where 条件的数量,当 OR 条件大于等于 218 时,SQL prepare 过程中的递归调用引发 Linux 线程栈内存溢出。
针对以上问题,我们也提出了相应的修复方案,主要包括:
调整 Linux 内核线程栈空间大小,防止内存溢出。
查找 Issues 及 PR,打 Patch 修复。
限制 where 条件,最高不可超过 100。
用户画像实践及优化
01 背景
用户画像包括用户画像 CDP 平台引擎,涵盖人群圈选、事件分析、路径分析等,为极越汽车的增长、销售、运营、售后等关键环节提供了统一全面的用户打标、人群圈选、用户画像分析以及用户行为分析的能力,从而帮助极越汽车更精准地把握用户需求,优化数据服务策略。
在用户画像的构建过程中,我们通常会对数据进行离散化处理,转化为 KV 格式后,利用 Bitmap 高效存储,确保用户画像的精准性和实时性。用户画像业务架构图如下:
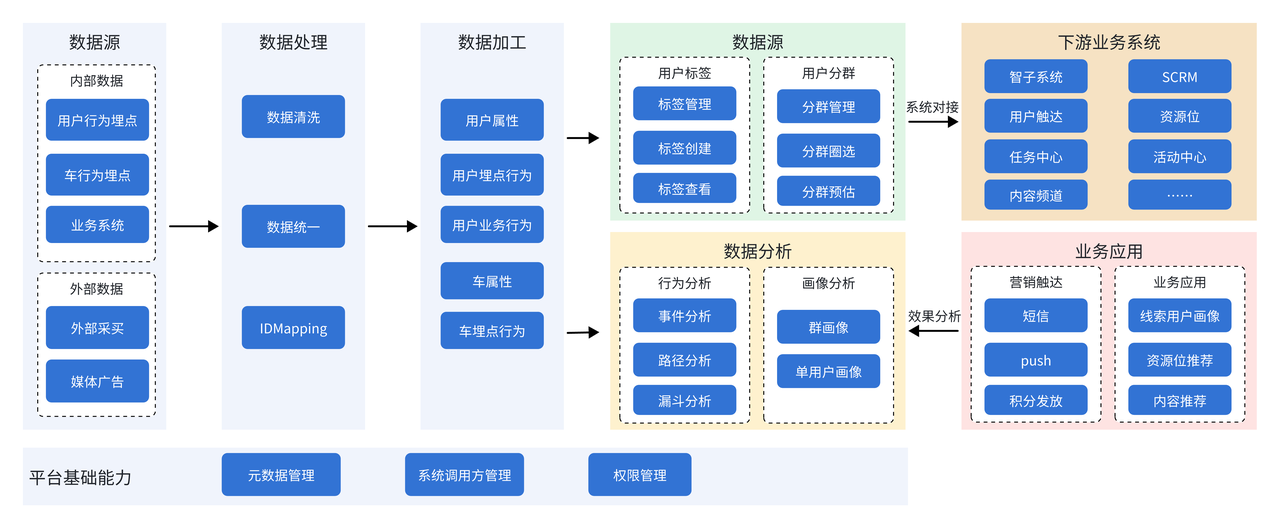
根据图中所示,数据服务和数据分析两个模块充分利用了 Doris 强大的多维分析能力。数据分析师或者业务运营同学通过 CDP 平台在用户属性、行为数据、业务数据等基础上建立人群圈选的规则之后,规则可直接转换为 Doris SQL 进行计算,计算后的圈选结果(数据集)通过 Bitmap 的方式存入到 Doris 并供下游服务。
02 查询问题定位
下图是用户标签管理模块的 tag_ser_Bitmap 表,其中, user_ID 的数据类型是 Bitmap。在生产环境(5 BE)下,查询 user_ID 为 1 的所有用户标签时,执行时间长达 19 秒之多,执行时间远超预期,而此时数据量只有 5000 多行。基于此,我们开始探索 Bitmap 快速查询问题所在。
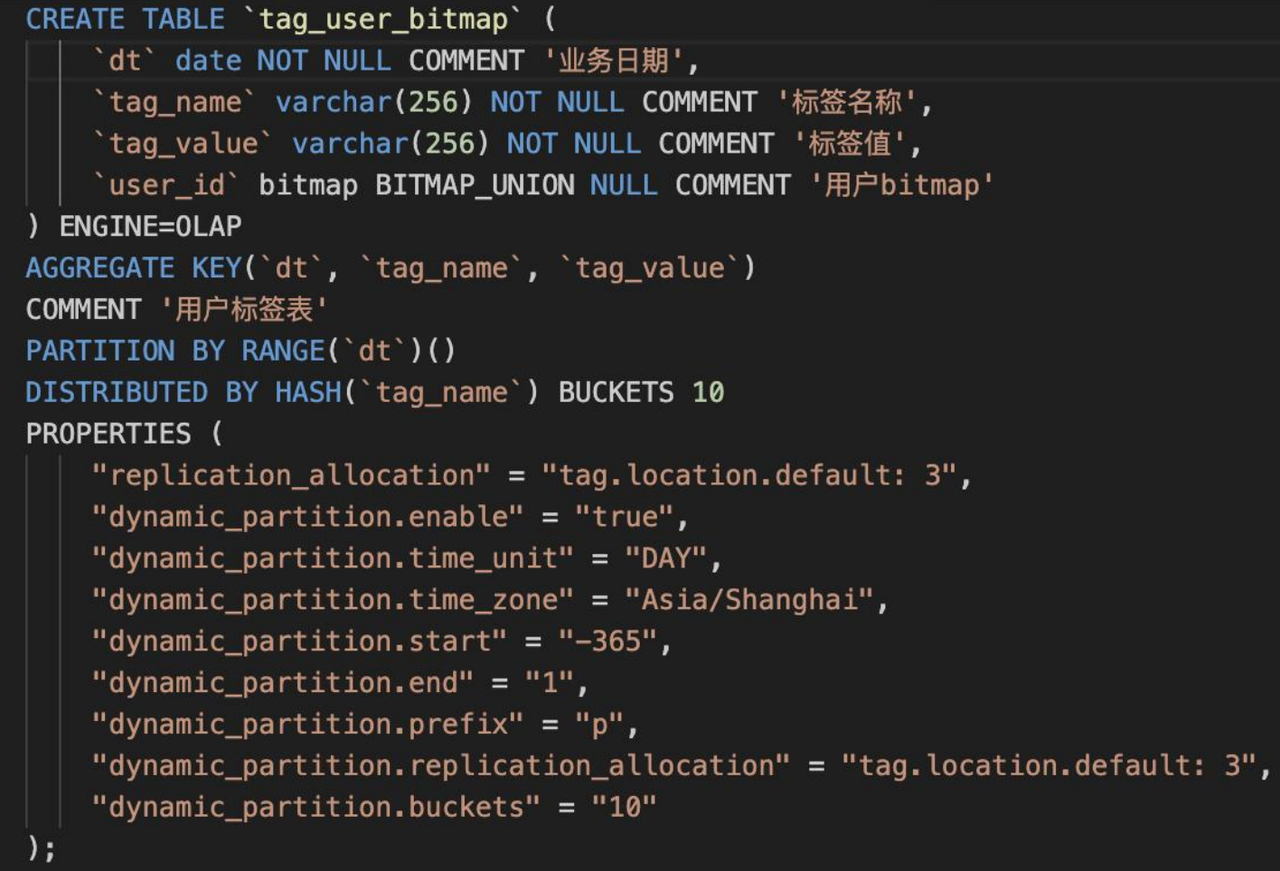
Profile
一开始我们尝试从 Profile 入手,先是对比了 1.1.5 和 1.2.5 两个版本的核心参数:CompressedBytesRead、Uncompressed BytesRead、RawRowsRead 和 BlockLoadTime。
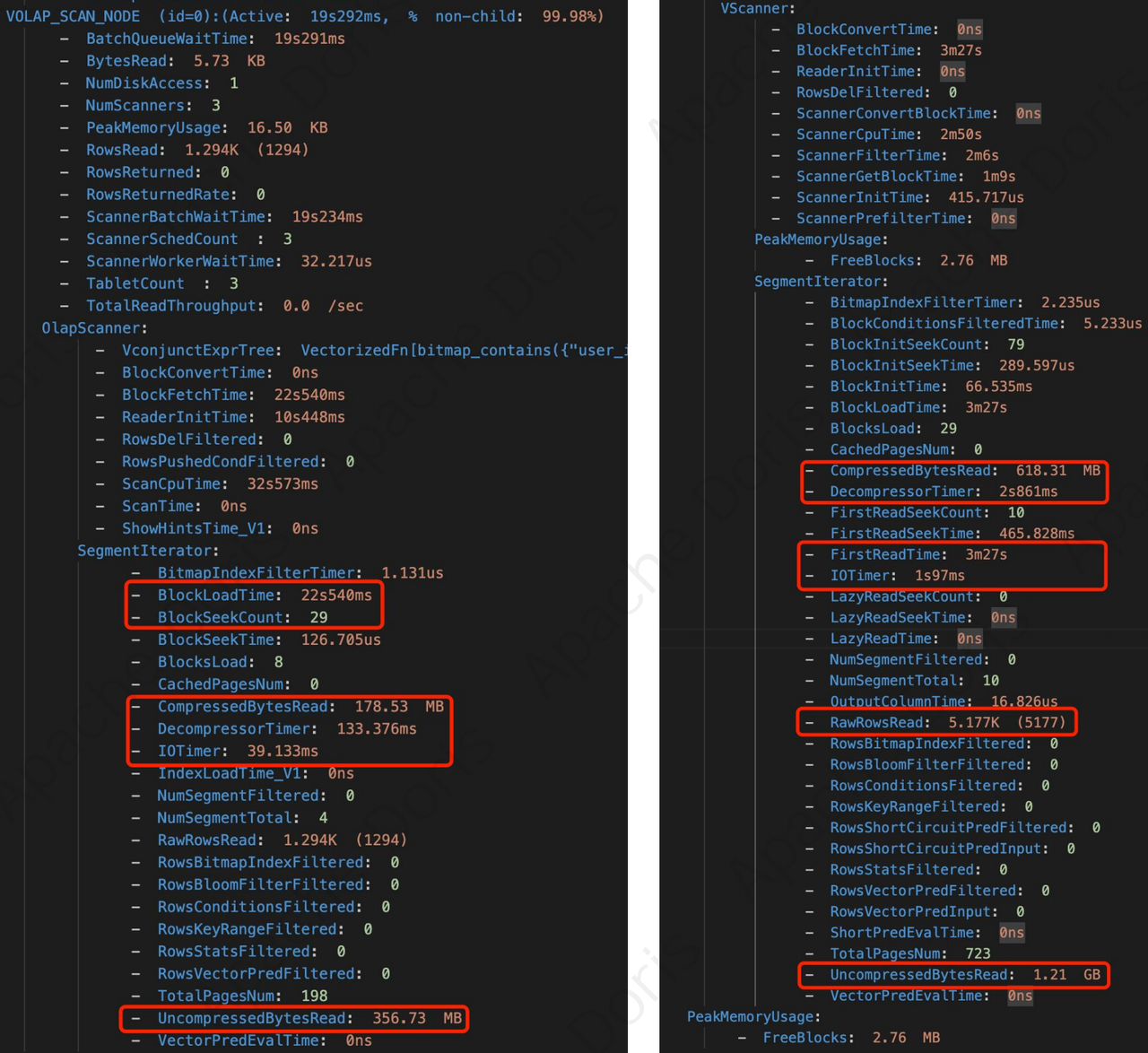
经测试,在测试和生产环境中,读取数据量都存在解压缩情况,数据体积膨胀约 1 倍多;IOtimer 时间较短,但 BlockLoadTime 时间很长,这说明读的过程存在明显的数据倾斜,猜测是 BlockLoadTime 出现了性能瓶颈。针对以上问题,我们改善了对应数据分布:
将表的 Buckets 分桶数从 10 改为 48;
将标签分布从 name 改成 name + value;
优化后,查询结果从 19 秒 缩短到 5 秒,查询速度提升 3.4 倍,但仍未达到一秒返回查询结果的要求。
Bitmap
随后我们尝试从 Bitmap 入手,猜测慢查询是 BlockLoadtime 运行过程中 Segmentlteror 读取迭代源码时磁盘 IO、反序列化较慢导致的,随后进行了验证操作:
只读取非 user ID 列,响应速度非常快。
只读取 user ID,查询速度较慢,并且与是否使用函数、是否聚合无关。
验证结果表明,问题在于 Bitmap Value 的存储结构存在序列化和 IO 瓶颈问题。由于 Bitmap 底层由 Roaring Bitmap 构建,存储方面不存在资源浪费的问题,因此我们继续关注 Bitmap 底层的工作原理。通过进一步探索发现:
仅有 30 多个高基数列 Bitmap Value,剩下的 Bitmap Value 基数均不超过 100 万。(通过 bitmap_count 发现)
存入 Bitmap 的数据高达 19 位,超过了 32 位整数范围最大值。(通过 bitmap_min 和 bitmap_max 发现)
结合 Bitmap32 和 Bitmap64 的存储原理:
Bitmap32 使用 Roaring Bitmap 存储,高 16 位决定分桶,低 16 位包含三个 container 并根据容量决定桶的存储方式:
Array Container :存入 Bitmap 个数小于或等于 4096;
Bitmap Container:存入 Bitmap 个数超过 4096;
Run Container:利用步长来压缩数字,降低 Bitmap 存储。
Bitmap64 使用红黑树+ Roaring Bitmap 存储:
高 32 位决定在红黑树 Key 节点;
低 32 位时 Roaring Bitmap 会存储在红黑 Value 中。
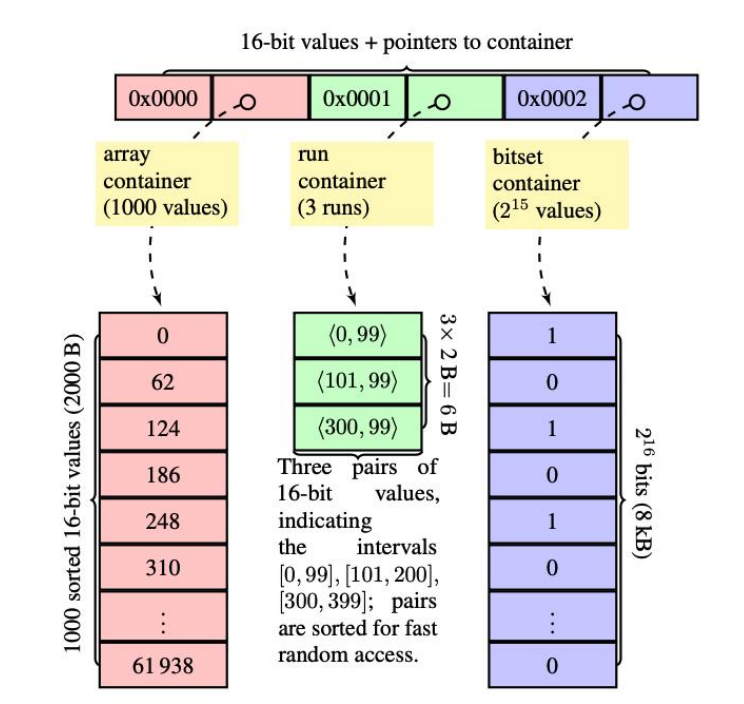
针对该用户标签管理场景,user ID 为 64 位,存储方式是红黑树 + Roaring Bitmap,这就会产生两个问题:
反序列化:红黑树每个 key 对应 value 都是 Roaring Bitmap,反序列化时会涉及多个 roaring Bitmap 32。
User ID 分布稀疏:产生多个节点,相当于内存中查询 IO 开销增加,造成网络传输中的 IO time 值偏大。
03 优化方案
基于以上分析,我们提出了 2 种优化方案:
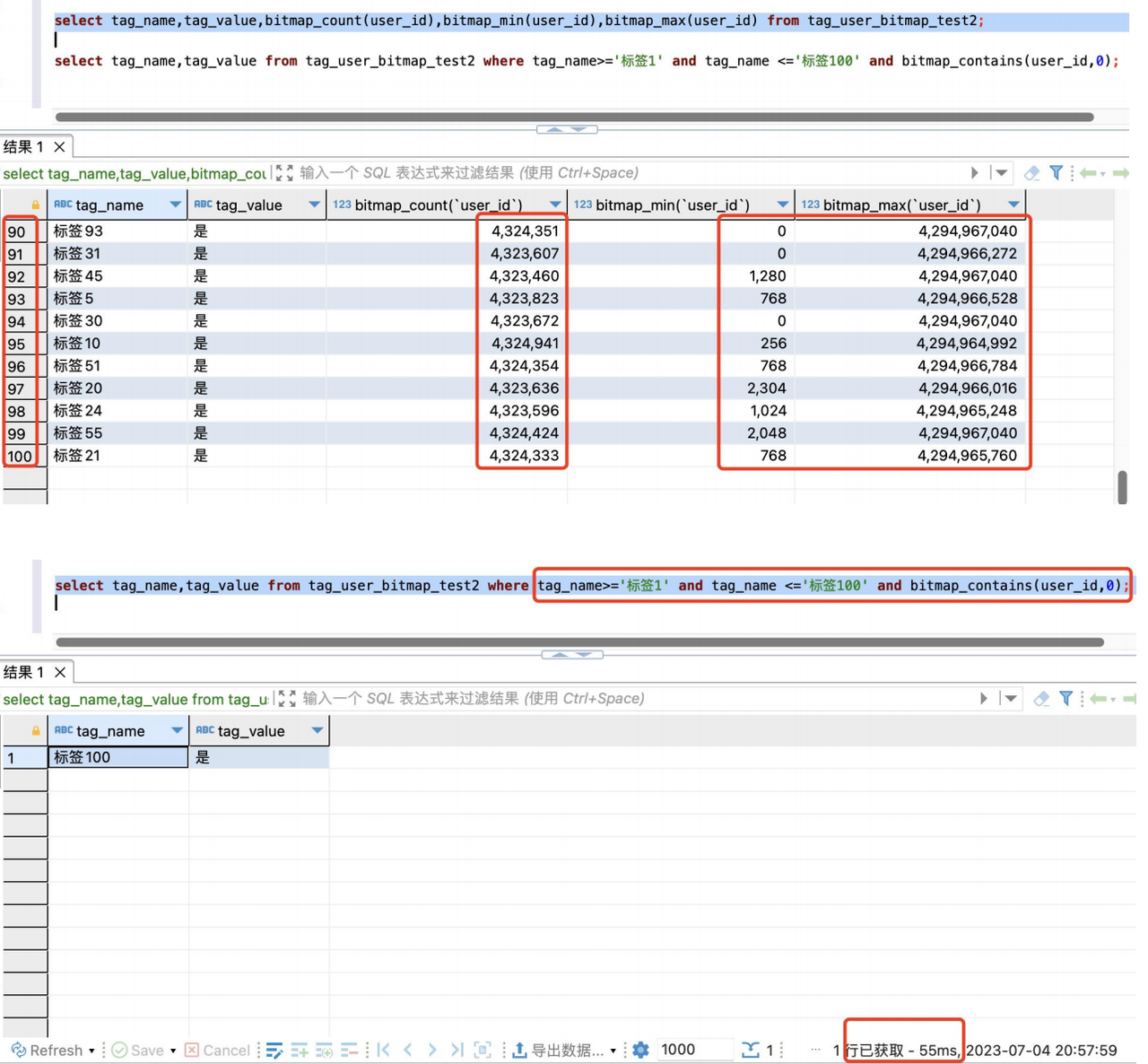
1. 利用 IdMapping 服务将 user_id 转换成 Bitmap 32:Bitmap 32 最高可达到 46 亿用户量,满足业务系统的数据存储需求。
测试时,我们加入了 100 个测试标签,每个标签值内(Bitmap Value)的基数达 400 多万个。全部转化成 32 位 Bitmap 后,查询结果仅需 55 毫秒,查询效率提升近百倍。
2. 正交 Bitmap:将高 32 位拆成额外一列(例如:user_id_prefix)存储中,不同的高 32 位膨胀到不同的行中每次查询和写入都通过高 32 位查询判断哪些行存在 Roaring Bitmap。
04 问题排查小结
经过上述实践,我们简单总结了问题排查思路与具体步骤,与大家分享一下:
日志探查与分析
从服务端查询数据,包括 BE 日志、审计日志和 Query Profile,BE 日志通常包括执行查询时的详细信息和可能的错误信息,审计日志记录了所有数据库操作的历史、有助于追踪问题的来源,而 Profile 提供了查询执行的详细统计信息,如扫描行数、执行时间等,是调优和诊断性能问题的关键。
当服务端没有目标数据时,考虑从客户端定位嫌疑 SQL。
问题复现与反馈
确认版本号,是否为当前社区主要推荐的稳定版本,建议根据社区的发版节奏进行升级。当前社区主要维护的版本为 2.0.x 和 2.1.x ,建议选择三位版本数字最大的版本。
定位嫌疑 SQL 后,确保问题可复现,并主动查阅 Doris 文档。
前往 Doris 社区积极反馈,可以提交 GitHub Issue 或者向 dev@doris.apache.org 社区开发者邮件组发送邮件。在反馈时提供尽可能多的信息,如版本号、复现步骤、错误日志等,便于社区可以快速解决问题,也可以与社区伙伴共同学习进步。
源码分析与调试
阅读并 Debug 源码,注意关闭 O2 和 O3 的优化,避免部分源码在编译时被忽略。
如果进程崩溃并生成了 Core Dump 文件,可以使用 GDB 等调试工具来分析 Core Dump 文件,以准确定位导致崩溃的代码行和堆栈信息。
总结与展望
截至目前,基于 Apache Doris 的数据智能服务体系已经部署了近十套生产集群,节点规模已经接近百台,存储的数据总量达数百 T,覆盖了实时数仓、BI 多维分析、用户画像、车云中心(Serving)、日常分析等多个业务场景。从业务侧来看,Apache Doris 为极越汽车在提升客户用车体验、实时监测车辆信息、保障安全驾驶等方面提供了更全面、更准确的业务洞察和决策支持,有力推进了极越汽车创新数字化服务的步伐。从技术侧看,Doris 优秀的读写性能、低成本数据接入流程和丰富的大数据生态支持,既提升了车端、云端数据处理效率,又简化实时数据流架构,还能一定程度上节约计算和存储成本、简化运维。
未来,我们计划在以下几个方面继续升级和优化:
版本升级:Doris 版本从 1.1.x 升级至 1.2.x 或 2.x 稳定版本(截至发稿前生产环境多个集群已经全部升级至 1.2.7.1 及 2.0.1 以上版本),进一步提升查询性能。同时,计划引入 2.1.x 版本的基于 WorkGroup 的资源隔离特性,降低多租户使用过程中的相互干扰,提升稳定性。
Doris 可视化治理:引入 Doris Manager,接管多个集群,集成可视化慢查询分析,实现降本增效。
数据湖分析加速:在多 Catalog 场景下,引入 Hive/Paimon Catalog 并集成 Ranger 统一权限管理,加速湖仓一体落地。
车云中心平台版本尝鲜:
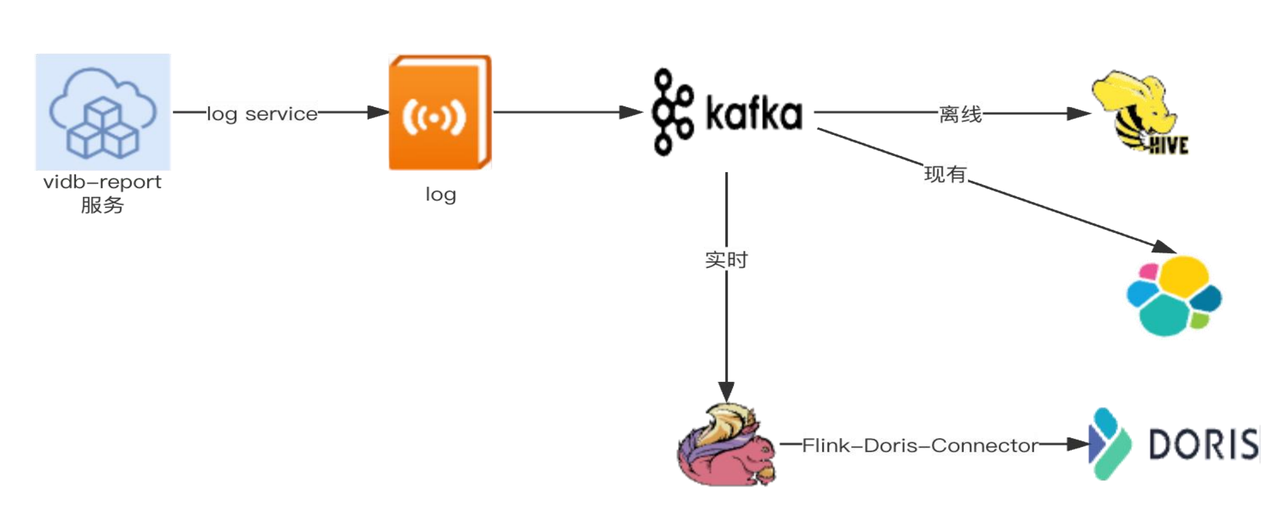
车辆中心云平台实现了车端静态数据的周期性上报和动态事件触发上报,涉及到数据的存储和在线实时分析。vidb-report 通过 log service 将数据传到 log 中,再上报到 Kafka 层,对离线和实时数据进行存储。
目前云平台使用 Elasticsearch 分析日志,在性能方面存在一些瓶颈,经过大量测试验证后,我们计划上线 Doris 2.1 版本来替代 Elasticsearch。
在 Join 性能优化、Rollup 与物化视图等方面持续积极探索。