
1.引言
随着大数据技术的不断发展,数据实时性的需求变得越来越迫切,这对实时数据处理的基础架构提出了更高的要求。如何应对实时数据的流量变化,特别是突发流量,成为实时数据处理架构不得不面对的挑战性问题。对于 FreeWheel 这样一家服务全美 90%的主流电视媒体和运营商的视频广告投放和管理平台,对于突发流量的应对能力尤为重要。数据基础架构团队作为 FreeWheel 数据处理的载体,提供了公司级的实时和离线数据处理及查询服务。在本文中,我们将和大家分享我们在实时数据处理弹性伸缩方面的实践。
2.FreeWheel 实时数据平台架构
FreeWheel 数据基础架构基于大数据开源软件和部分自研软件构建,所有服务均部署在 AWS EC2 上。目前,整个数据平台为 Lambda 架构,并逐渐向流批一体的融合平台发展。其中,实时数据平台整体上主要分为四个部分:基于 Kafka 构建的消息队列,自研的消息处理中间件 Matcher,基于 SQL 开发方式的实时计算平台 SQL on Streaming(SOS)以及以 Druid 为主体构建的实时数据查询服务。
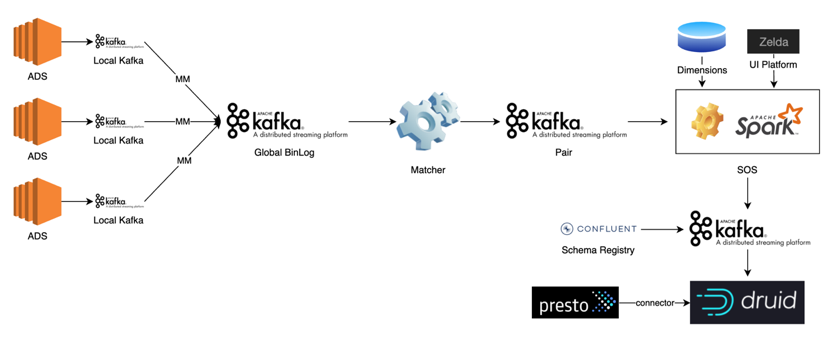
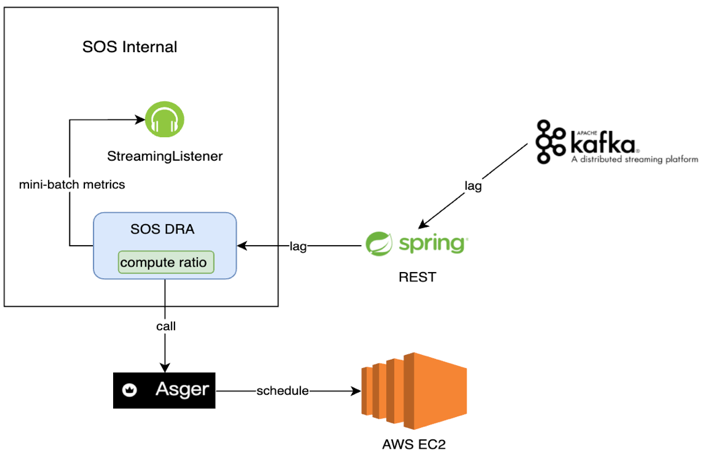
如上图所示,FreeWheel 的广告服务器 ADS 部署在美国不同地区的 11 个 Data Center,例如 NYC,ASH 等,并将日志数据以 PB 格式写入本地的 Kafka 服务(LocalKafka),然后通过 MirrorMaker 等服务将数据同步到部署在 AWS 的 Global Kafka。Matcher 是 FreeWheel 自研的消息处理中间件,主要用于匹配广告投放过程中的 Request 和 Ack,并进行必要的数据去重。SOS 基于 Spark Streaming 和 SparkSQL,对实时应用开发中依赖的数据读写进行抽象及封装,并支持消费端位点管理,Join 维度数据,写数据幂等,数据模型依赖,弹性伸缩等特性。用户只需关心读写端元信息及用 SQL 表达计算逻辑而无需关心其他细节,同时为了 方便用户使用,结合 CICD 等为用户构建功能,性能以及回归测试服务,使用户的使用尽量趋于自助化(Self-Service)。实时数据处理的下游是基于 Druid 构建的数据存储及查询服务,并自研针对 Druid Segment 小文件的合并工具,基于实际流量进行数据摄入自动伸缩容,用户不友好查询的追踪分析等周边服务,保障高服务质量。同时,对于数据 Join 需求较高的场景,通过实现 Presto Druid Connector 来覆盖这一部分的需求。
3.FreeWheel 实时计算弹性伸缩
3.1 现状及需求
由于 FreeWheel 流量高低时段相对比较规律,因此最早我们结合 Jenkins Job,按时段规律定期的对 SOS 的应用进行伸缩。这种方式会以 Graceful 的方式重启应用,在相当一段时间里可以满足应用计算资源的按需增减以及节约整体计算成本(Cost Saving)的要求。然而随着平台的发展,有些问题开始逐渐凸显,主要有两个:一是对于突发的流量增长,仍需工程师介入进行手动处理;二是这种定时启停的方式会增加整个实时应用不可用的时间,对于实时数据这种 SLA 要求较高的系统并不友好。因此,使实时计算具备基于实际数据流量进行动态伸缩的能力成为我们必须要解决的问题,这也与 FreeWheel 数据系统 Self-Service 的理念保持一致。
3.2 Spark Streaming Dynamic ResourceAllocation
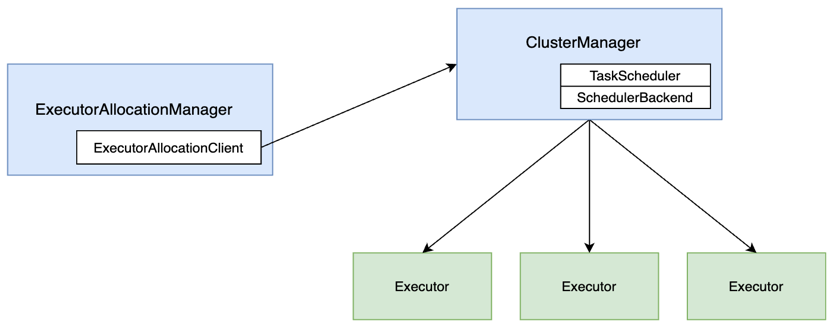
由于历史及技术栈的原因,SOS 基于 Spark 生态的技术构建并运行在 Yarn 上。对于 Spark 的动态资源调度,大家可能知道 Dynamic Resource Allocation,它的原理比较直观,在 ExecutorAllocationManager 组件中启动一个周期性任务监听 Executor 状态,如果 Executor 在一段时间内一直处于空闲状态,则杀掉该 Executor,如果 Executor 一直处于高负载的状态,则增加 Executor 数量。与此同时,为保障处理性能的稳定并且对 Executor 的增减进行约束,可以定义 Executor 数量的最大及最小值。Dynamic Resource Allocation 这个特性常常被应用在 Spark 离线计算中。而怎样杀死或者新增 Executor 呢?如下图所示,借助于内嵌在 ExecutorAllocationManager 中的 ExecutorAllocationClient,可以将计算出的 Executor 的新数量发送给 ClusterManager,由后者完成计算资源的重新调度。
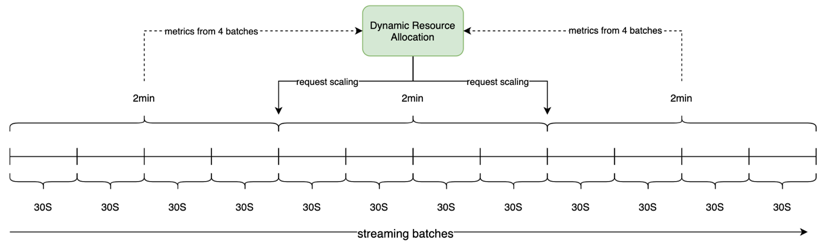
实际上,SparkStreaming 也有 Dynamic ResourceAllocation 的特性,不过在官方文档中鲜有提及。它的原理类似,在 Streaming 的 ExecutorAllocationManager 中同样启动一个周期运行的监听任务,它定时的判断当前计算资源是否充足,以此来计算是否要新增或者杀死 Executor,而判断的依据源于计算一个 Ratio 值,Ratio 值的计算依赖于 Spark 用于流式计算过程中收集 Metrics 的组件 StreamingListener。借助于 StreamingListener,可以在 Spark Streaming 每个 Batch 结束后获取关于该 Batch 处理的一些 Metrics,例如调度延迟(SchedulingDelay),处理延迟(ProcessingDelay),处理条数(NumRecords)等。
假设当前 Spark Streaming 应用的 BatchDuration 是 30 秒,配置的周期性调度的时间是 2 分钟,那么每次调度时,我们可以拿到过去 4 个 Batch 的处理情况并计算出处理延迟的平均值,前边提到的 Ratio 值的算法就是用平均处理延迟除以 Batch 时间得到,如下图所示。假设过去 4 个 Batch 的平均处理延迟是 20 秒,我们可以估算出目前应用的处理能力大约还有三分之一的弹性空间。我们可以设置弹性伸缩相关的阈值 Scale Up 和 ScaleDown,那么当 Ratio 的值大于 Scale Up 阈值,应用会向 Spark 的 Cluster Manager 发送请求申请新增 Executor,当小于 Scale Down 阈值时,应用会从当前 Executor 中选择不包含 Receiver 的 Executor 并从中随机选取一个,然后发送请求杀死该 Executor。同样的,可以定义 Executor 数量的最大最小值。以上就是原生 Spark Streaming Dynamic Resource Allocation 的基本原理。需要注意的是,新增 Executor 时,需要保证运行应用的资源池资源足够,例如假设应用运行在 Yarn 上,此时需要保证应用所在的队列资源足够。
3.3 SOS Dynamic Resource Allocation
SOS DynamicResource Allocation(简称 SOS DRA)在继承原生特性的基础上,有几点定制化的实现。首先思考一个场景,假设 SOS 应用拉取 Kafka 数据的能力已接近瓶颈,基于当前的计算资源算出的平均处理延迟会趋于一个恒定值,假如此时数据生产的速度大于处理速度,那么整体来讲,SOS 消费数据的 Lag 仍在不断增长。因此,对于前文提到的 Ratio 值的计算,我们引入当前应用的消费 Lag,结合平均处理延迟来加权计算 Ratio。Ratio 的计算逻辑如下边公式所示:
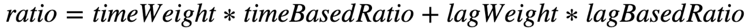
其中, timeBasedRatio 为原始计算逻辑,lagBasedRatio 由当前消费 Lag 的值除以过去一轮 SOS DRA 调度中每个 Batch 处理的数据条数的平均值得到。timeWeight,lagWeight 分别为两种 Ratio 对应的权重。因为 SOS DRA 依赖外部服务,那么自然存在外部依赖不可用的情况。为保障服务的健壮性,我们对可能存在的异常场景进行针对处理。例如,当依赖的 Rest 服务出现问题而无法拿到消费 Lag 信息,SOS DRA 的调度算法将退化到只基于平均处理延迟计算 Ratio 值,即当 Rest 服务出现问题时,lagWeight 调整为 0,timeWeight 调整为 1。此时,整个表达式退化为原始计算逻辑。
其次,由于数据基础架构团队的软件服务都部署在 AWS EC2 上,因此 ScaleUp 和 Scale Down 会涉及 AWS EC2 资源的申请与释放。数据基础架构团队结合 AWS Auto Scaling Groups 自研 AWS EC2 资源服务 Asger。当涉及新增及删除 Executor 时,SOS DRA 会调用 Asger 服务,由后者完成 AWS EC2 资源的申请释放以及 SOS 应用所在 Yarn 队列的资源更新。第三,由于不想在 SOS DRA 中耦合更多逻辑,额外开发一个 Rest 服务,用于获取当前的 Lag 信息以及配置一些其他的调度规则等。第四,将每个调度周期计算的 Ratio 值及更新后 Executor 数量暴露到 JMX,这样这些信息最终会被采集并展现在基于 Datadog 构建的监控系统中用于实时追踪当前的调度情况。SOS DRA 的原理如下图。
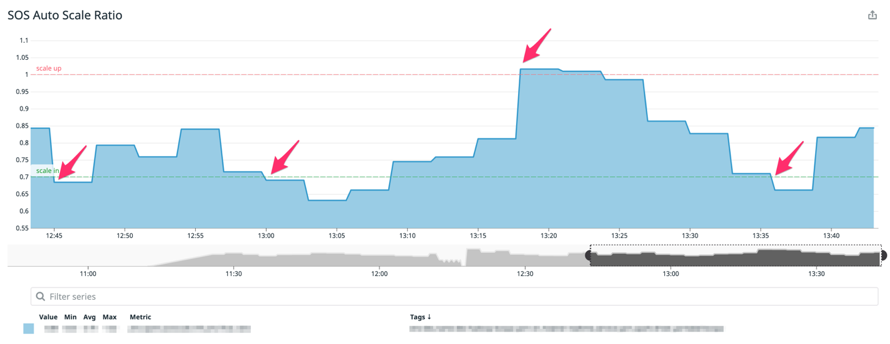
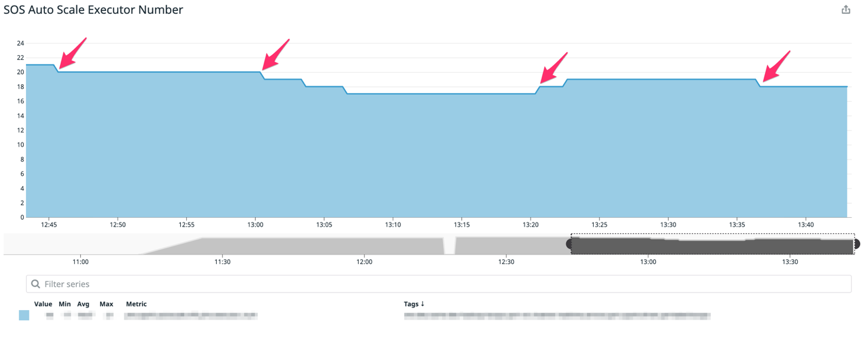
实际部署效果如下图示例,该示例中 SOS 应用启动时指定 20 台 Executor,并分别指定 ScaleUp 和 Scale Down 的阈值为 1.0 和 0.7。由下图一图二可见,分别在 12:45 左右,13:00 左右,当 Ratio 阈值小于 0.7 时,Executor 数量由 20 台逐渐缩减至 17 台。在接近 13:20,当遭遇突发流量波动,Ratio 值超过 1 时,Executor 数量由 17 台弹回至 19 台。当时间超过 13:35,Ratio 值再次小于 0.7 时,机器再次由 19 台缩减至 18 台。
4.Druid 实时数据摄入弹性伸缩
ApacheDruid 具备很多的优点,例如数据预聚合,低耦合架构,多种数据摄入方式,与大数据生态良好的亲和性等。因此结合广告业务特点,FreeWheel 实时数据系统下游选择 Druid 作为数据存储及查询的核心引擎。同时出于高可用性,维护友好等角度考虑,我们将 Druid 部署在 AWS EKS 上。
4.1 Druid 实时数据摄入原理
Druid 的数据摄入分为实时(Realtime)以及离线(Batch)两种,整体呈现 Lambda 架构,Druid 架构中 MiddleManager 角色负责启动 Peon 进程,由 Peon 来完成数据的真正摄入。实时数据的摄入主要针对上游是 Kafka,Kinesis 等消息队列的场景,Peon 集成的 Kafka Consumer Client 会 7*24 实时读取上游消息队列中的数据并保障 Exactly Once 的语义。离线数据导入主要针对将 HDFS,S3 上的数据批量导入 Druid 的场景。
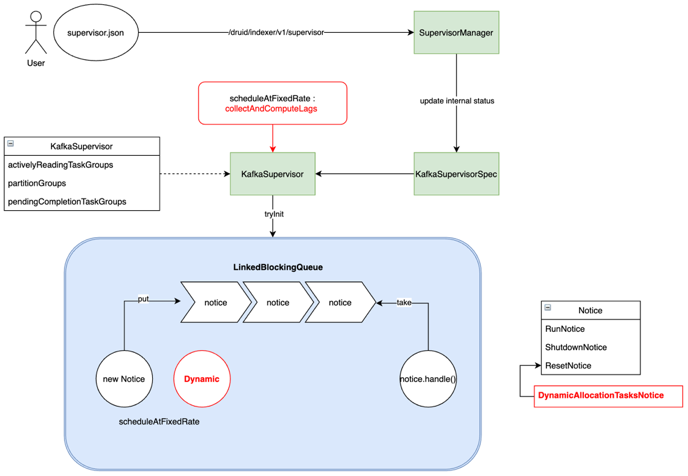
当需要将数据由 Kafka 导入 Druid 时,用户需要指定一个 Supervisor 任务,通过定义 Payload 文件以 Json 格式来描述需要导入的信息,并提交给 Overload 节点,由 Overload 节点通知 MiddleManager 启动 Peon 进程完成数据的摄入。任务提交后,交由 Overload 进程中的 SupervisorManager 对象处理,它对维护的 Supervisor 内部状态做必要的更新然后生成 KafkaSupervisorSpec 并交由 KafkaSupervisor 处理。KafkaSupervisor 负责管理 IngestTask 的生命周期,它接收 KafkaSupervisorSpec 作为输入,生成对应的 Tasks 并管理这些 Tasks 与 KafkaTopic 分区的映射关系。KafkaSupervisor 内部还包含一个处理线程,它不断的消费 Notice 队列的内容并调用对应的 handle 方法。Notice 是 Druid 中对 SupervisorOperation 的抽象表示,例如我们提交,暂停或者重置 Supervisor 时会分别对应 RunNotice,ShutdownNotice 和 ResetNotice。综上可见,我们要实现实时数据摄入的动态伸缩,本质上是要干预 Task 任务的生成。实时数据摄入的原理如下图,其中红色方框的部分为我们新增的部分,后文中将继续介绍。
4.2 FreeWheel 对 Druid 实时数据摄入弹性伸缩的改进
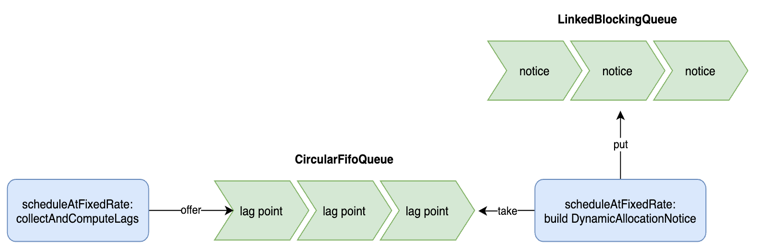
由于 Druid 摄入 Kafka 数据是否及时可以根据消费 Lag 来直接判断,因此我们按固定间隔采集 Lag 信息,基于此新增一种 Notice 的实现 DynamicAllocationTaskNotice 并将它插入到 Notice 队列里。具体地,在 KafkaSupervisor 中增加记录 Lag 的定长队列 CircularFifoQueue,按固定间隔插入采集到的 Lag 信息。当弹性伸缩的调度服务被定时触发时,它会创建 DynamicAllocationTaskNotice。当 DynamicAllocationTaskNotice 的 handle 方法被调用时,它会判断定长队列里 Lag 的情况,当超过 Scale Up 阈值的点的比例超过设置的阈值,则按指定的步长进行 Scale Up,反之,当小于 Scale Down 阈值的点的比例小于设置的阈值,则按指定的步长进行 Scale Down。同时,通过设定 Task 数量的最大值和最小值,来保障单个数据源占用的资源在一定范围内。原理图如下:
在 Payload 文件中新增 dynamicAllocationTasksProperties 的配置模块,该特性的具体新增配置属性如下:
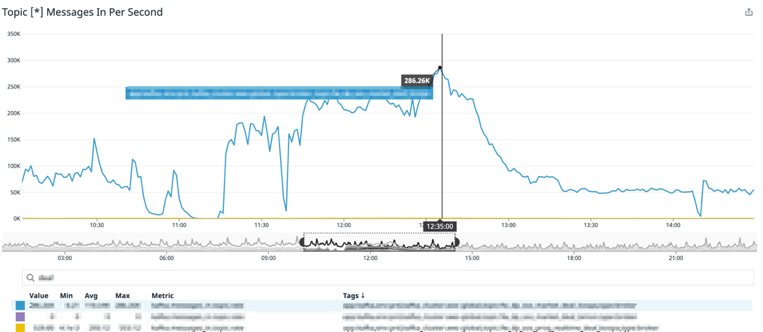
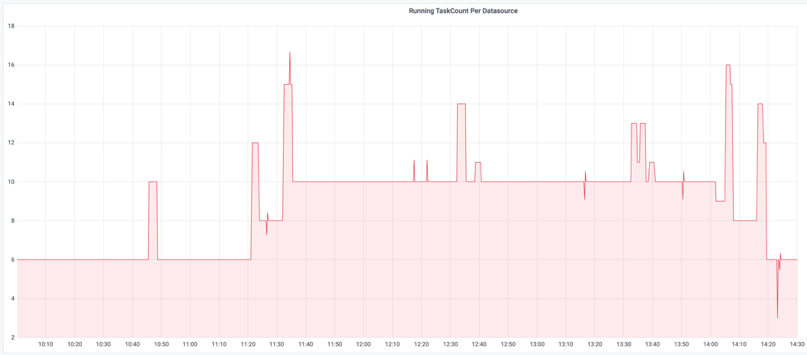
实际运行效果如下图所示,在美国大选期间的某一时间段,突发一流量高峰,从图一中可以看到某 Topic 在大约 11:20-13:20 之间流量从每秒不到 100K 条数据增长到最高值超过每秒 286K 条。图二为该 Topic 对应的 Druid 数据摄入的 Task 数量,如图中所示,大约在相同时间段,Task 数量从之前的 6 个自动扩展到 10 个,达到设定的最大值,在流量高峰过去后,自动缩回到之前 6 个的水平,整个过程无需工程师干预。
我们目前实现的实时数据摄入动态伸缩是基于当前 MiddleManager 所能提供的 Task 总容量进行的,可以满足线上需求。
5.未来计划
随着业务规模的不断扩大,对于状态需求较高的实时应用,例如支持 Late Data,SessionWindow 等,我们正在考虑为 SOS 支持 Flink 引擎。
整体架构层面,我们正在进行这几个方面的实践:构建流批融合的一站式平台,通过梳理指标规范模型进一步降低用户的开发成本,最大程度的支持整体平台的用户自助服务(Self-Service)。
作者介绍:
韩飞,Lead Software Engineer,FreeWheel。硕士毕业于清华大学软件学院,目前就职于 FreeWheel 数据基础架构团队,任实时数据系统研发负责人。拥有多年数据平台建设经验,主要研究领域包括实时计算、实时数仓,OLAP、数据交换等。
吕宪萃,FreeWheel 大数据基础架构与监控平台负责人,主导公司级数据平台与 Prometheus 观测体系的架构决策,支撑全球广告业务的稳定性与成本效率。




