
对许多 API 来说,Webhooks 是一种辅助手段。有了 Webhook 系统,系统 B 可以通过注册来接收有关系统 A 某些更改的通知。当系统 A 发生更改时,它通常以发出 HTTP POST 请求的形式将更改推送到系统 B。
Webhook 旨在消除或减少不断轮询数据的需求。但根据我的经验,Webhooks 也带来了一些挑战。
一般来说,你不能只依靠 Webhooks 来保持两个系统的一致性。我曾参与开发的集成最后都得通过轮询来增强 Webhook,实现一致性。这种情况是由于一些缺陷造成的。
首先,系统故障时会存在风险。是的,发送方通常会重试未交付的 Webhook,并做一些指数回退。但这些保证往往是松散或不清晰的。从灾难中恢复后,你的系统可能最后要处理的就是大量备份的 Webhooks。
其次,Webhooks 是短周期的。它们太容易处理不当或丢失了。如果你在部署代码更改后意识到你对一个 JSON 字段进行了粗指处理并将 null 插入了到你的数据库中,你是没办法重播 Webhook 的。或者,你可以在管道带外处理这个 Webhook 请求——就像数据库插入一样。但这样你就要冒着失败并失去这个 Webhook 的风险。
为了缓解这两个问题,许多开发人员最后将 Webhooks 缓冲到像 Kafka 这样的消息总线系统上,这种妥协方法感觉太繁琐了。
考虑两方之间一个复杂的 Webhook 管道架构:
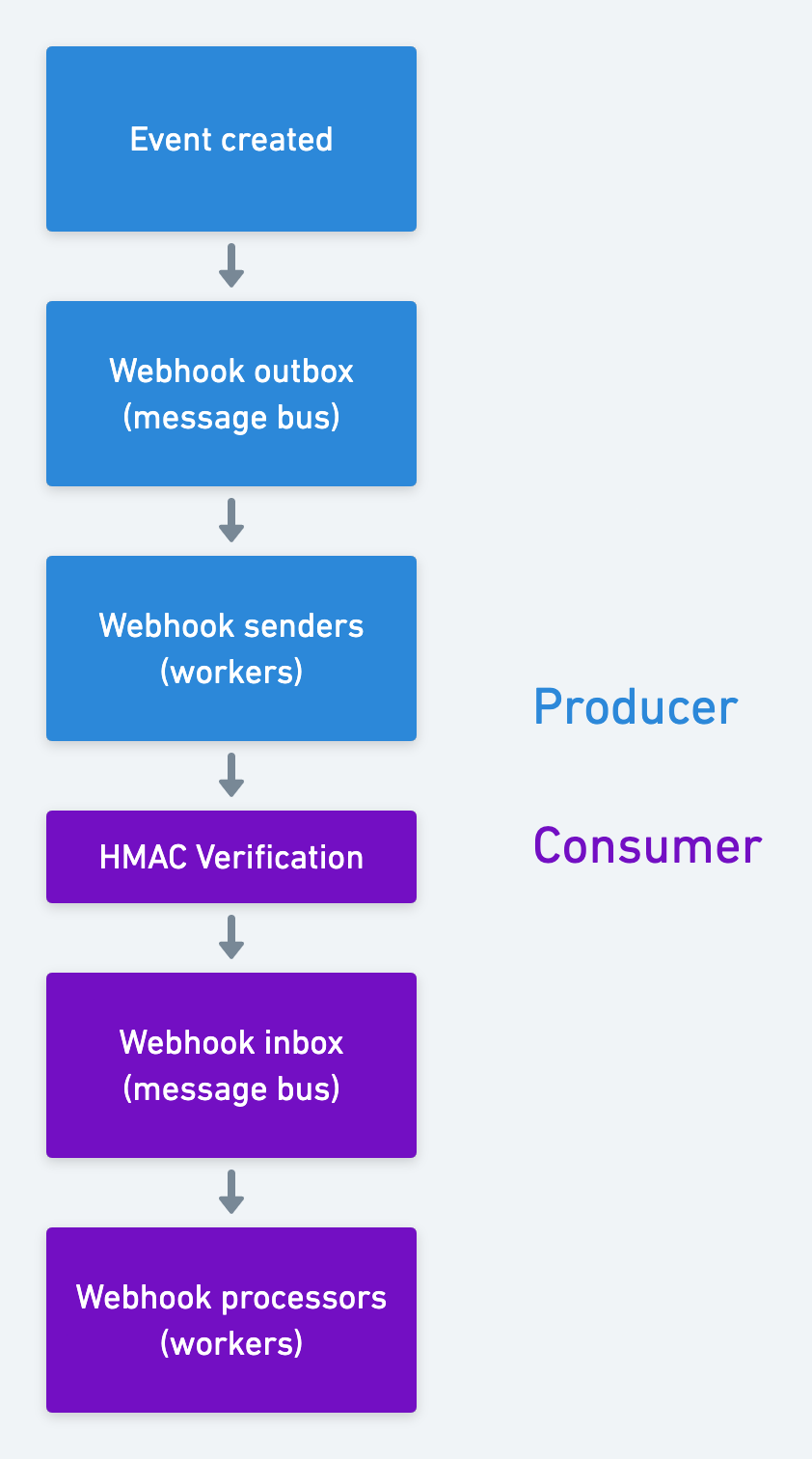
我们有两条消息总线,一条在发送端,一条在接收端。这里的复杂性是显而易见的,可能出错的阶段有很多。例如:在接收端,即使你的系统很稳定,你仍然会遇到发送方可传递性失败的情况。如果发送方的队列开始出现背压,Webhook 事件就会延迟,但你可能很难知道正在发生这种情况。
更复杂的是,两者之间的安全层通常是一些 HTTP 请求签名协议,如 HMAC。这些协议很健壮,并且减轻了管理密码的负担。但一般的开发人员并不熟悉这种协议,因此更容易出现混乱和错误。(我认为 HTTP 请求签名和验证就是那种人们很难搞明白,于是永远没法完全记住的任务。)
因此,Webhooks 不仅会让你面临最终不一致的情况,而且每个人都需要为此做更多的工作。
那么我们还能用什么来保持两个系统的同步呢?
/events 端点
为了让两个数据集保持和谐,我们只需要查看数据库即可。考虑 Postgres 的复制槽:你为每个 follower 数据库创建一个复制槽,follower 订阅这个复制槽以获取更新。
这里的两个关键组件分别是:
主数据库记录最近更改的所有内容
主数据库保留一个游标,用于跟踪每个 follower 数据库在更改日志中的位置
如果 follower 崩溃,当它恢复时,它可以在闲暇时浏览历史。用不着队列,也没有两端的 worker 试图将事件编成一个桶队列来传递。
API 也可以遵循这一模型。拿 Stripe 为例,他们有一个/events 端点,其中包含过去 30 天内对 Stripe 帐户的所有创建、更新和删除操作历史。每个事件对象都包含被操作实体的完整负载。以下是一个 subscription 对象的事件示例:
{ "id": "evt_1J7rE6DXGuvRIWUJM7m6q5ds", "object": "event", "created": 1625012666, "data": { "object": { "id": "sub_JgFEscIjO0YEHN", "object": "subscription", "canceled_at": 1625012666, "customer": "cus_Jff7uEN4dVIeMQ", "items": { "object": "list", "data": [ // ... ], "url": "/v1/subscription_items?subscription=sub_JgFEscIjO0YEHN" }, "start_date": 1623826800, "status": "canceled", } }, "type": "customer.subscription.deleted"},一些重要的特性:
每个事件都有一个 type,它告诉我们这个事件的类型。在上面这个例子中,我们看到一个客户的订阅已被删除。由于完整订阅的负载已经被包含进去了,所以我们可以更新数据库以反映诸如 cancelled_at 之类的字段及其新的 canceled status。
每个嵌入的对象都包含一个 object 字段,因此我们可以轻松地提取和解析它们。
事件对象自由嵌入了子对象,让我们无需轮询 API 即可全面了解发生更改的所有内容。
因此,我们可以轮询/events,而不是通过监听 Webhooks 来保持最新状态。我们只需要在本地保留一个游标,并在请求中使用它来向 Stripe 指示我们已经看到了哪些事件。
优势:
如果我们崩溃,我们不必担心 Webhooks 丢失这样的问题。当我们恢复时,我们可以按照自己的节奏回到正轨。
如果我们部署了一个错误处理事件的错误,不用担心。我们可以部署一个修复程序并将游标倒回/events,后者将重播它们。
我们的端点不需要消息总线。
我们不必担心 Stripe 的 Webhook 发送方延迟交付。速度是我们控制的。在我们和最新数据之间只有 API 层的缓存。
我们使用了一个简单的、基于令牌的身份验证方案。
我们拉取和处理事件的方式看起来与我们处理其他端点的方式是一样的。我们可以重用很多相同的 API 请求/处理代码。
在生产者侧,为了支持/events,你需要围绕对创建/更新/删除操作的监控添加和 Webhooks 相同的那些东西。只是这里不需要构建交付管道,你只需要将记录插入到仅附加的数据库表中即可。
在消费者侧,你需要设置一些轮询基础设施。这比处理带内所有内容的基础 Webhook 处理端点更麻烦些。但我敢打赌,构建一个不错的轮询系统并不比构建强大的 Webhook 处理系统(例如消息总线)更难。你将获得更好的一致性保证。
让/events 变得更好
/events 端点有一个明显的效率低下之处:为了尽可能保持实时性,你必须非常频繁地轮询。我们每个帐户每 500 毫秒轮询一次 Stripe/events 端点。
这些请求是轻量级的,除了最活跃的 Stripe 帐户之外,其他响应通常都是空的。但是作为程序员,我们希望要寻找一种方法来进一步提高效率。
Stripe 等 API 平台想出了一个办法:支持长轮询!
在长轮询中,客户端发出标准 HTTP 请求。如果服务器没有任何新信息要交付给客户端,则服务器会将请求保持在打开状态,直到有新信息要交付为止。
在我们与 Stripe 的集成中,如果我们可以请求/events 并附带一个表明我们想要长轮询的参数,那就太好了。给定我们发送的游标,如果有新事件创建,Stripe 会立即返回这些事件。但如果没有,Stripe 可以将请求保持在打开状态,直到新事件被创建。当请求完成时,我们只需重新打开它并重复循环即可。这不仅意味着我们可以尽快获取事件,而且还可以减少整体的网络流量。
长轮询相比 Websockets 的优势是代码重用和简单性。大多数集成无论如何都涉及某种形式的轮询,无论你是回填数据还是重放错误处理的事件。通过单个参数就能从回填切换到实时侦听新事件这样的能力是很大的优势。
我该如何选择?
对于 API 消费者来说,如果你需要在轮询/events 或使用 Webhooks 之间做出选择,那么具体选哪个就取决于你的一致性需求。Webhooks 可以更快地入门,尤其是当你只关心少数 API 对象时。另外对于某些工作流来说,Webhooks 被删除也没有关系,例如你向一个 Slack 频道发布一个“新订阅者”公告。
但是,当一个集成变得越来越重要,并且需要确保不丢失任何内容时,我们认为轮询/events 是更好的选择。
对于 API 生产者来说,支持/events 不仅是给你的 API 消费者的一大礼物。/events 很容易成为接下来提供 Webhooks 的一种基础。你的 events 表可以作为 Webhook 发送方出站工作的“队列”。事实上,events 可以提供一些人们急需的 Webhook 功能,例如允许你的 Webhook 消费者重播或重置其 Webhook 订阅的位置。




