
本文详细介绍了如何将 Hive 里的数据快速稳定的写进 HBase 中。由于数据量比较大,我们采取的是 HBase 官方提供的 bulkload 方式来避免 HBase put api 写入压力大的缺陷。团队早期采用的是 MapReduce 进行计算生成 HFile,然后使用 bulkload 进行数据导入的工作。
因为结构性的因素,整体的性能不是很理想,对于部分业务方来说不能接受。其中最重要的因素就是建 HBase 表时预分区的规划不合理,导致了后面很多任务运行时间太过漫长,很多都达到了 4~5 个小时才能成功。
在重新审视和规划时,自然的想到了从计算层面性能表现更佳的 Spark。由它来接替 MapReduce 完成数据格式转换,并生成 HFile 的核心工作。
HiveToHBase 全解析
实际生产工作中因为工作涉及到了两个数据端的交互,为了更好的理解整体的流程以及如何优化,知道 ETL 流程中为什么需要一些看上去并不需要的步骤,我们首先需要简单的了解 HBase 的架构。
1. HBase 结构简单介绍
Apache HBase 是一个开源的非关系型分布式数据库,运行于 HDFS 之上。它能够基于 HDFS 提供实时计算服务主要是架构与底层数据结构决定的,即由 LSM-Tree (Log-Structured Merge-Tree) + HTable (Region 分区) + Cache 决定的:
LSM 树是目前最流行的不可变磁盘存储结构之一,仅使用缓存和 append file 方式来实现顺序写操作。其中关键的点是:排序字符串表 Sorted-String-Table,这里我们不深入细节,这种底层结构对于 bulkload 的要求很重要一点就是数据需要排序。而以 HBase 的存储形式来看,就是 KeyValue 需要进行排序!
HTable 的数据需要均匀的分散在各个 Region 中,访问 HBase 时先去 HBase 系统表查找定位这条记录属于哪个 Region ,然后定位到这个 Region 属于哪个 RegionServer,然后就到对应服务器里面查找对应 Region 中的数据。
最后的 bulkload 过程都是相同的,差别只是在生成 HFile 的步骤。这也是下文重点描述的部分。
2. 数据流转通路
数据从 Hive 到 HBase 的流程大致如下图:
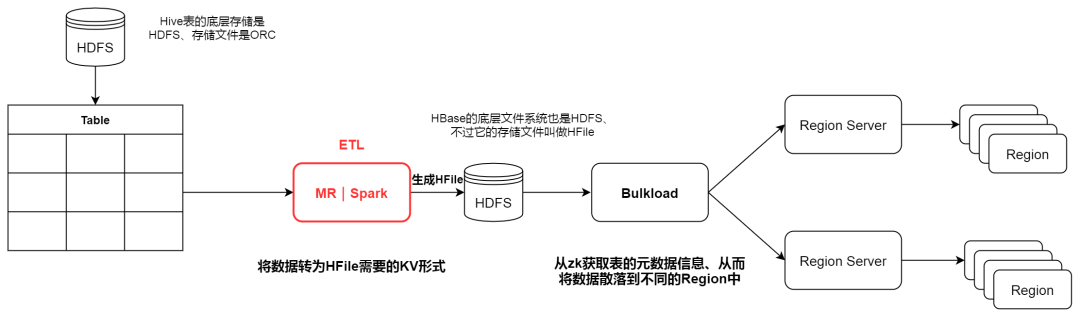
整个流程真正需要我们 cover 的就是 ETL ( Extract Transfer Load ) 部分,HBase 底层文件 HFile 属于列存文件,每一列都是以 KeyValue 的数据格式进行存储。
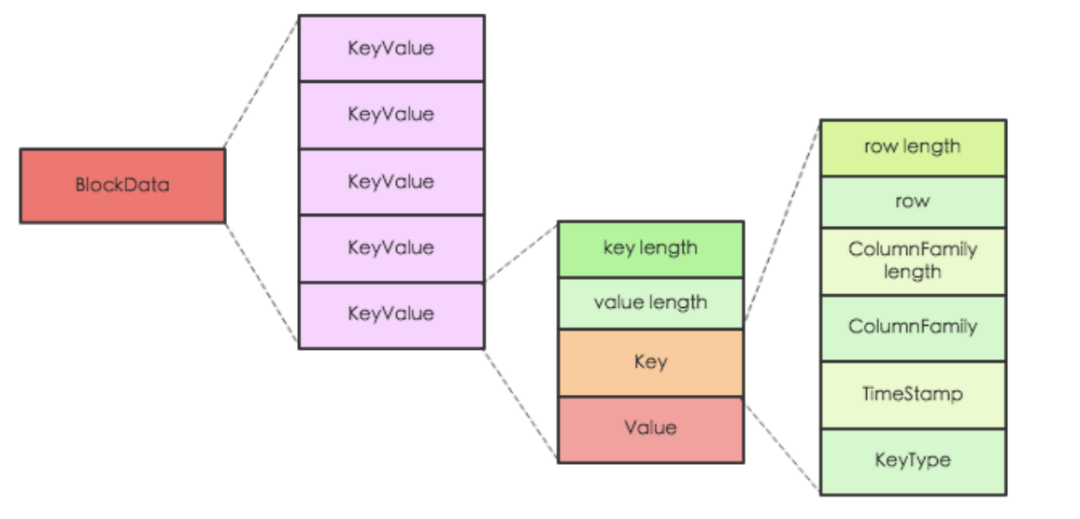
逻辑上真正需要我们做的工作很简单:( 为了简便、省去了 timestamp 版本列 )、HBase 一条数据在逻辑上的概念简化如下:
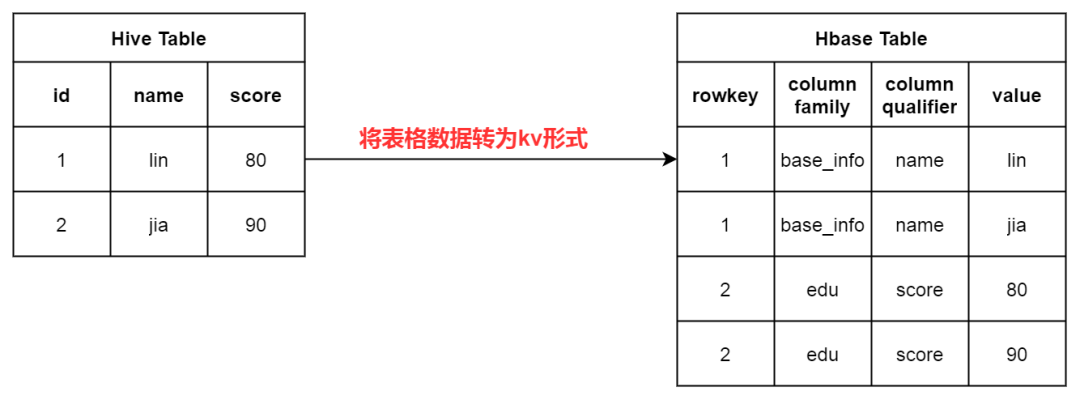
如果看到了这里,恭喜你已经基本明白本文的行文逻辑了。接下来就是代码原理时间:
MapReduce 工作流程
Map/Reduce 框架运转在键值对上,也就是说框架把作业的输入看为是一组键值对,同样也产出一组键值对做为作业的输出。在我们的场景中是这样的:
1. mapper:数据格式转换
mapper 的目的就是将一行数据,转为 rowkey:column family:qualifer:value 的形式。关键的 ETL 代码就是将 map 取得的 value,转成< ImmutableBytesWritable,Put>输出、进而交给 reducer 进行处理。
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ImmutableBytesWritable, Put>.Context context) throws IOException, InterruptedException { //由字符串切割成每一列的value数组 String[] values = value.toString().split("\\x01", -1); String rowKeyStr = generateRowKey(); ImmutableBytesWritable hKey = new ImmutableBytesWritable(Bytes.toBytes(rowKeyStr)); Put hPut = new Put(Bytes.toBytes(rowKeyStr)); for (int i = 0; i < columns.length; i++) { String columnStr = columns[i]; String cfNameStr = "cf1"; String cellValueStr = values[i].trim(); byte[] columbByte = Bytes.toBytes(columnStr); byte[] cfNameByte = Bytes.toBytes(cfNameStr); byte[] cellValueByte = Bytes.toBytes(cellValueStr); hPut.addColumn(cfNameByte, columbByte, cellValueByte); } context.write(hKey, hPut);}mapper 写完了,好像已经把数据格式转完了,还需要 reducer 吗?参考官方的资料里也没有找到关于 reducer 的消息,我转念一想 事情没有这么简单!研读了提交 Job 的主流程代码后发现除了输出文件的格式设置与其他 mr 程序不一样:
job.setOutputFormatClass(HFileOutputFormat2.class);还有一个其他程序没有的部分,那就是:
HFileOutputFormat2.configureIncrementalLoad(job,htable)故名思义就是对 job 进行 HFile 相关配置。HFileOutputFormat2 是工具包提供的,让我们看看里面到底干了什么吧!
2. job 的配置
挑选出比较相关核心的配置:
根据 mapper 的输出格式来自动设置 reducer,意味着我们这个 mr 程序可以只写 mapper,不需要写 reducer 了。
获取对应 HBase 表各个 region 的 startKey,根据 region 的数量来设置 reduce 的数量,同时配置 partitioner 让上一步 mapper 产生的数据,分散到对应的 partition ( reduce ) 中。
reducer 的自动设置
// Based on the configured map output class, set the correct reducer to properly// sort the incoming values.// TODO it would be nice to pick one or the other of these formats.if (KeyValue.class.equals(job.getMapOutputValueClass())) { job.setReducerClass(KeyValueSortReducer.class);} else if (Put.class.equals(job.getMapOutputValueClass())) { job.setReducerClass(PutSortReducer.class);} else if (Text.class.equals(job.getMapOutputValueClass())) { job.setReducerClass(TextSortReducer.class);} else { LOG.warn("Unknown map output value type:" + job.getMapOutputValueClass());}实际上上面三种 reducer 底层都是会将数据转为 KeyValue 形式,然后进行排序。需要注意的是 KeyValue 的排序是全排序,并不是以单个 rowkey 进行排序就行的。所谓全排序,就是将整个对象进行比较!
查看 KeyValueSortRducer 后会发现底层是一个叫做 KeyValue.COMPARATOR 的比较器,它是由 Bytes.compareTo(byte[] buffer1, int offset1, int length1, byte[] buffer2, int offset2, int length2)将两个 KeyValue 对象的每一个字节从头开始比较,这是上面说到的全排序形式。
我们输出的文件格式是 HFileOutputFormat2,它在我们写入数据的时候也会进行校验 check 每次写入的数据是否是按照 KeyValue.COMPARATOR 定义的顺序,要是没有排序就会报错退出!Added a key not lexically larger than previous。
reduce 数量以及 partitioner 设置
为什么要根据 HBase 的 region 的情况来设置我们 reduce 的分区器以及数量呢?在上面的小节中有提到,region 是 HBase 查询的一个关键点。每个 htable 的 region 会有自己的【startKey、endKey】,分布在不同的 region server 中。
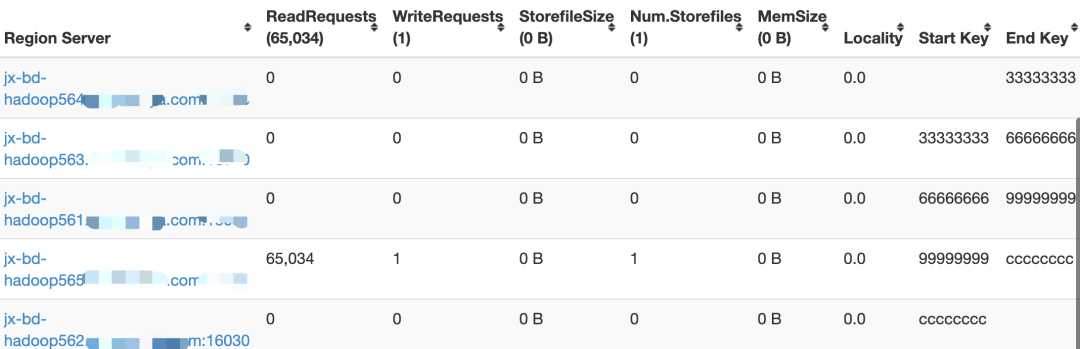
这个 key 的范围是与 rowkey 匹配的,以上面这张表为例,数据进入 region 时的逻辑场景如下:
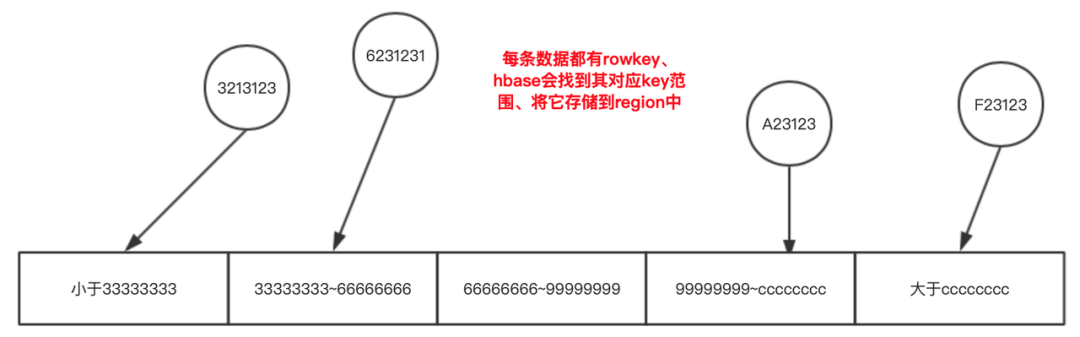
也正是因为这种管理结构,让 HBase 的表的 rowkey 设计与 region 预分区 ( 其实就是 region 数量与其 [starkey,endkey]的设置 ) 在日常的生产过程当中相当的重要。在大批量数据导入的场景当然也是需要考虑的!
HBase 的文件在 hdfs 的路径是:
/HBase/data/<namespace>/<tbl_name>/<region_id>/<cf>/<hfile_id>通过并行处理 Region 来加快查询的响应速度,所以会要求每个 Region 的数据量尽量均衡,否则大量的请求就会堆积在某个 Region 上,造成热点问题、对于 Region Server 的压力也会比较大。
如何避免热点问题以及良好的预分区以及 rowkey 设计并不是我们的重点,但这能够解释为什么在 ETL 的过程中需要根据 region 的 startkey 进行 reduce 的分区。都是为了贴合 HBase 原本的设计,让后续的 bulkload 能够简单便捷,快速的将之前生成 HFile 直接导入到 region 中!
这点是后续进行优化的部分,让 HiveToHBase 能够尽量摆脱其他前置流程 ( 建 htable ) 的干扰、更加的专注于 ETL 部分。其实 bulkload 并没有强制的要求一个 HFile 中都是相同 region 的记录!
3. 执行 bulkload、完成的仪式感
讲到这里我们开头讲的需要 cover 的重点部分就已经完成并解析了底层原理,加上最后的 job 提交以及 bulkload,给整个流程加上结尾。
Job job = Job.getInstance(conf, "HFile Generator ... ");job.setJarByClass(MRMain.class);job.setMapperClass(MRMapper.class);job.setMapOutputKeyClass(ImmutableBytesWritable.class);job.setMapOutputValueClass(Put.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(HFileOutputFormat2.class);HFileOutputFormat2.configureIncrementalLoad(job, htable);//等待mr运行完成job.waitForCompletion(true);LoadIncrementalHFiles loader = new LoadIncrementalHFiles(loadHBaseConf);loader.doBulkLoad(new Path(targetHtablePath), htable);4. 现状分析
讲到这里 HiveToHBase 的 MapReduce 工作细节和流程都已经解析完成了,来看一下实际运行中的任务例子,总数据 248903451 条,60GB 经过压缩的 ORC 文件。
痛点
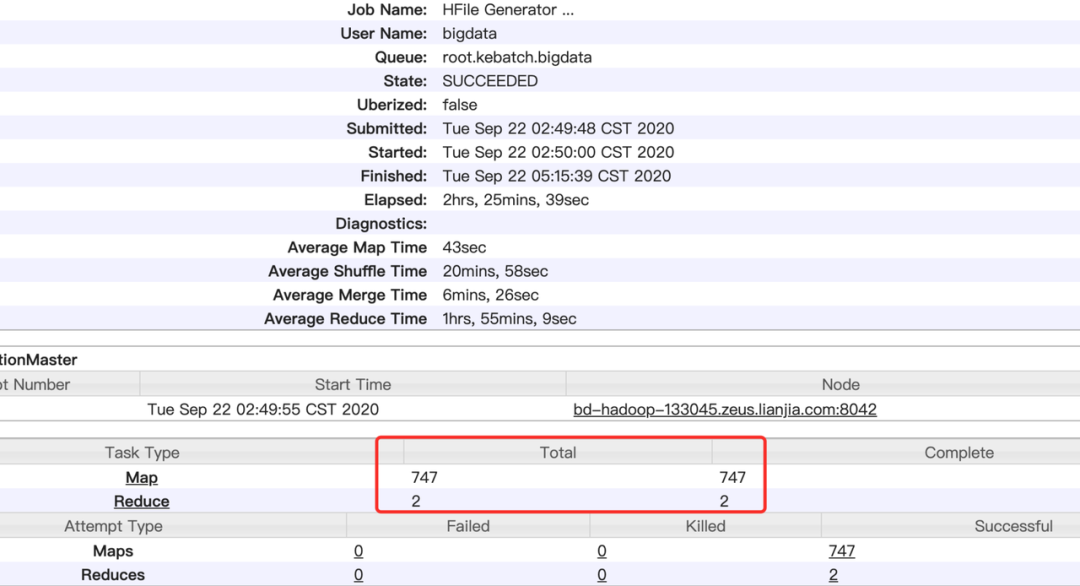
因为历史的任务 HBase 建表时预分区没有设置或者设置不合理,导致很多任务的 region 数量只有几个。所以历史的任务性能卡点基本都是在进行 reduce 生成 HFile 的时候,经查验发现 747 个 Map 执行了大约 4 分钟,剩下两个 Reduce 执行了 2 小时 22 分钟。
而平台整体 HiveToHBase 的 HBase 表 region 数量分布如下:
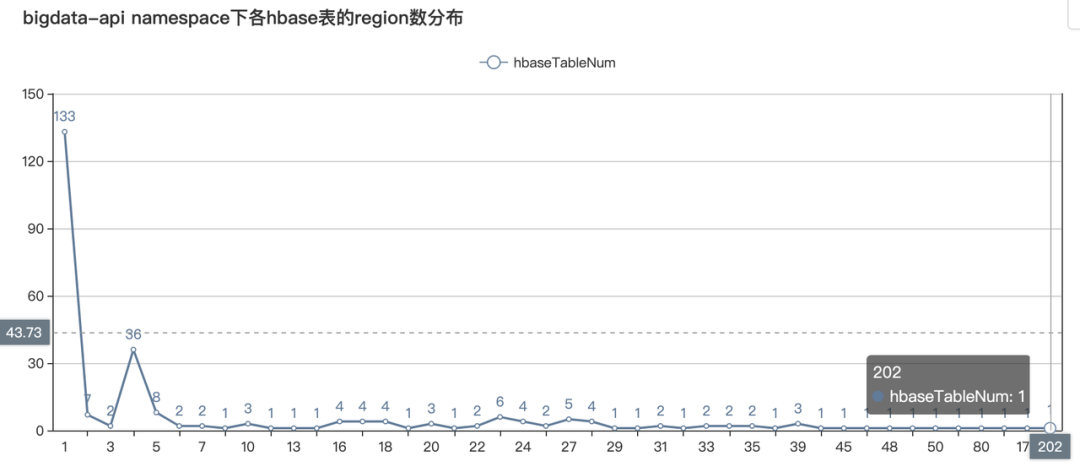
可以看到大部分的 HBase 表 region 数量都只有几个,在这种情况下如果沿用之前的体系进行分区。那么整体的性能改变可以预想的不会太高!
而且由于历史原因 HiveToHBase 支持用户写 sql 完成 Hive 数据的处理,然后再导入 HBase 中。mr 是不支持 sql 写法的,之前是先使用 tez 引擎以 insert overwrite directory + sql 的方式产生临时文件,然后将临时文件再进行上述的加工。
解决方案
经过综合的考量,决定采用 Spark 重写 HiveToHBase 的流程。现在官方已经有相应的工具包提供,也有样例的 scala 代码 ( Apache HBase ™ Reference Guide、中文版:HBase and Spark-HBase 中文参考指南 3.0 ),让我们可以像写 MR 一样只写 mapper,不需要管分区和排序。
但是这样解决不了我们的痛点,所以决定不借助的官方工具箱,这也正是我们分析 mr 的 job 配置的最大原因,可以根据自己的需求进行定制开发。
还记得上文中说过,其实 bulkload 并没有强制的要求一个 HFile 中都是相同 region 的记录 吗?所以我们是可以不按照 region 数量切分 partition 的,摆脱 htable region 的影响。HBase bulkload 的时候会 check 之前生成的 HFile,查看数据应该被划分到哪个 Region 中。
如果是之前的方式提前将相同的前缀 rowkey 的数据聚合那么 bulkload 的速度就会很快,而如果不按照这种方式,各个 region 的数据混杂在一个 HFile 中,那么就会对 bulkload 的性能和负载产生一定的影响!这点需要根据实际情况进行评估。
使用 Spark 的原因:
考虑它直接支持 sql 连接 hive,能够优化掉上面提到的步骤,整体流程会更简便。
spark 从架构上会比 mr 运行快得多。
最后的预期以上述例子为示意 如下图:
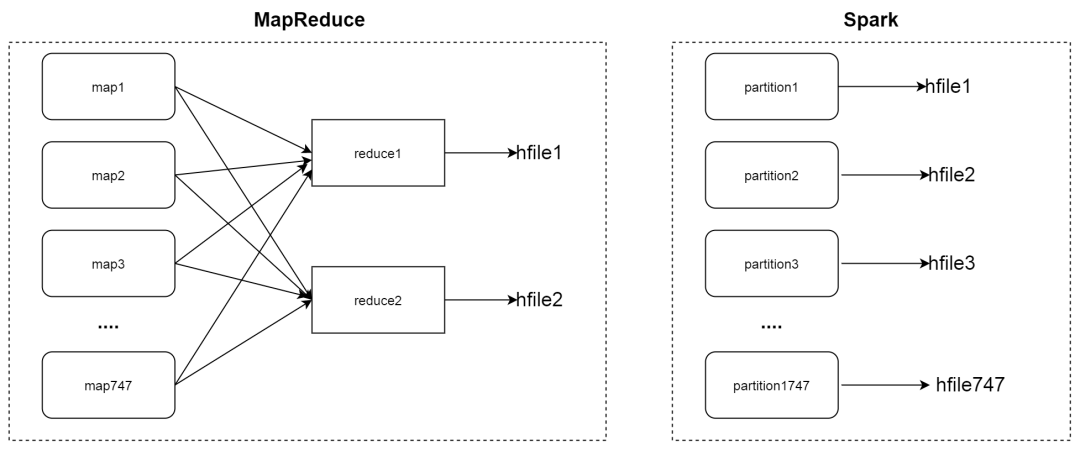
Spark 工作流程
核心流程代码:与 MR 类似,不过它采用的是 Spark 将 RDD 写成磁盘文件的 api。需要我们自己对数据进行排序工作。
1. 排序
构造一个 KeyFamilyQualifier 类,然后继承 Comparable 进行类似完全排序的设计。实际验证过程只需要 rowkey:family:qualifier 进行排序即可。
public class KeyFamilyQualifier implements Comparable<KeyFamilyQualifier>, Serializable { private byte[] rowKey; private byte[] family; private byte[] qualifier; public KeyFamilyQualifier(byte[] rowKey, byte[] family, byte[] qualifier) { this.rowKey = rowKey; this.family = family; this.qualifier = qualifier; } @Override public int compareTo(KeyFamilyQualifier o) { int result = Bytes.compareTo(rowKey, o.getRowKey()); if (result == 0) { result = Bytes.compareTo(family, o.getFamily()); if (result == 0) { result = Bytes.compareTo(qualifier, o.getQualifier()); } } return result; }}2. 核心处理流程
spark 中由于没有可以自动配置的 reducer,需要我们自己做更多的工作。下面是工作的流程:
将 spark 的 dataset 转为这部分是我们处理 ETL 的重点。
将按照 KeyFamilyQualifier 进行排序,满足 HBase 底层需求,这一步使用 sortByKey(true) 升幂排列就行,因为 Key 是上面的 KeyFamilyQualifier!
将排好序的数据转为,HFile 接受的输入数据格式。
将构建完成的 rdd 数据集,转成 hfile 格式的文件。
SparkSession spark = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate();Dataset<Row> rows = spark.sql(hql);JavaPairRDD javaPairRDD = rows.javaRDD() .flatMapToPair(row -> rowToKeyFamilyQualifierPairRdd(row).iterator()) .sortByKey(true) .mapToPair(combineKey -> { return new Tuple2(combineKey._1()._1(), combineKey._2()); });Job job = Job.getInstance(conf, HBaseConf.getName());job.setMapOutputKeyClass(ImmutableBytesWritable.class);job.setMapOutputValueClass(KeyValue.class);HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator); //使用job的conf,而不使用job本身;完成后续 compression,bloomType,blockSize,DataBlockSize的配置javaPairRDD.saveAsNewAPIHadoopFile(outputPath, ImmutableBytesWritable.class, KeyValue.class, HFileOutputFormat2.class, job.getConfiguration());3. Spark:数据格式转换
row -> rowToKeyFamilyQualifierPairRdd(row).iterator() 这一 part 其实就是将 row 数据转为< KeyFamilyQualifier, KeyValue>
//获取字段<value、type> 的tupleTuple2<String, String>[] dTypes = dataset.dtypes();return dataset.javaRDD().flatMapToPair(row -> { List<Tuple2<KeyFamilyQualifier, KeyValue>> kvs = new ArrayList<>(); byte[] rowKey = generateRowKey(); // 如果rowKey 为null, 跳过 if (rowKey != null) { for (Tuple2<String, String> dType : dTypes) { Object obj = row.getAs(dType._1); if (obj != null) { kvs.add(new Tuple2<>(new KeyFamilyQualifier(rowkey,"cf1".getBytes(),Bytes.toBytes(dType._1)),getKV(param-x)); } } } else { LOGGER.error("row key is null ,row = {}", row.toString()); } return kvs.iterator();});这样关于 HiveToHBase 的 spark 方式就完成了,关于 partition 的控制我们单独设置了参数维护便于调整:
// 如果任务的参数 传入了 预定的分区数量if (partitionNum > 0) { hiveData = hiveData.repartition(partitionNum);}分离了 partition 与 sort 的过程,因为 repartition 也是需要 shuffle 有性能损耗,所以默认不开启。就按照 spark 正常读取的策略 一个 hdfs block 对应一个 partition 即可。如果有需要特殊维护的任务,例如加大并行度等,也可以通过参数控制。
二者对比
上述例子的任务换成了新的方式运行,运行 33 分钟完成。从 146 分钟到 33 分钟,性能整整提升了 4 倍有余。由于任务迁移和升级还需要很多前置性的工作,整体的数据未能在文章撰写时产出,所以暂时以单个任务为例子进行对比性实验。(因为任务的运行情况和集群的资源紧密挂钩,只作为对照参考作用)
可以看到策略变化对于 bulkload 的性能来说是几乎没有变化的,实际证明我们这种策略是行得通的:

还有个任务是原有 mr 运行方式需要 5.29 小时,迁移到 spark 的方式 经过调优 ( 提高 partition 数量 ) 只需要 11 分钟 45 秒。这种方式最重要的是可以手动进行调控,是可灵活维护的。本身离线任务的运行时长就是受到很多因素的制约,实验虽然缺乏很强的说服力,但是基本还是能够对比出提升的性能是非常多的。
限于篇幅,有很多未能细讲的点,例如加盐让数据均匀的分布在 region 中,partition 的自动计算,spark 生成 hfile 过程中导致的 oom 问题。文笔拙略,希望大家能有点收获。
最后感谢开发测试过程中给予笔者很多帮助的雨松和冯亮,还有同组同学的大力支持。
参考文章:
1. 20 张图带你到 HBase 的世界遨游【转】 - sunsky303 - 博客园
https://www.cnblogs.com/sunsky303/p/14312350.html
2. HBase 原理-数据读取流程解析
http://HBasefly.com/2016/12/21/HBase-getorscan/?aixuds=6h5ds3
3. Hive、Spark SQL 任务参数调优
https://www.jianshu.com/p/2964bf816efc
4. Spark On HBase 的官方 jar 包编译与使用
https://juejin.cn/post/6844903961242124295
5. Apache HBase ™ Reference Guide
https://hbase.apache.org/book.html#_bulk_load
6. HBase and Spark-HBase 中文参考指南 3.0
https://www.cntofu.com/book/173/docs/17.md
本文转载自:DataFunTalk(ID:dataFunTalk)




