
导读:随着贝壳流量的日渐增长,贝壳商业化细分场景越来越丰富,公司对业务迭代和效果优化的效率有了更高的要求,贝壳商业化策略算法中台的架构也在不断的进行调整和升级。本文将围绕贝壳商业化策略算法中台的架构演进过程,介绍贝壳在商业化策略算法中台架构方面的探索和实践。重点探讨贝壳商业化算法模型落地、架构设计、服务治理以及性能优化方面的问题,以及如何增强系统的稳定性和扩展性。
贝壳商业化简介
1. 业务场景
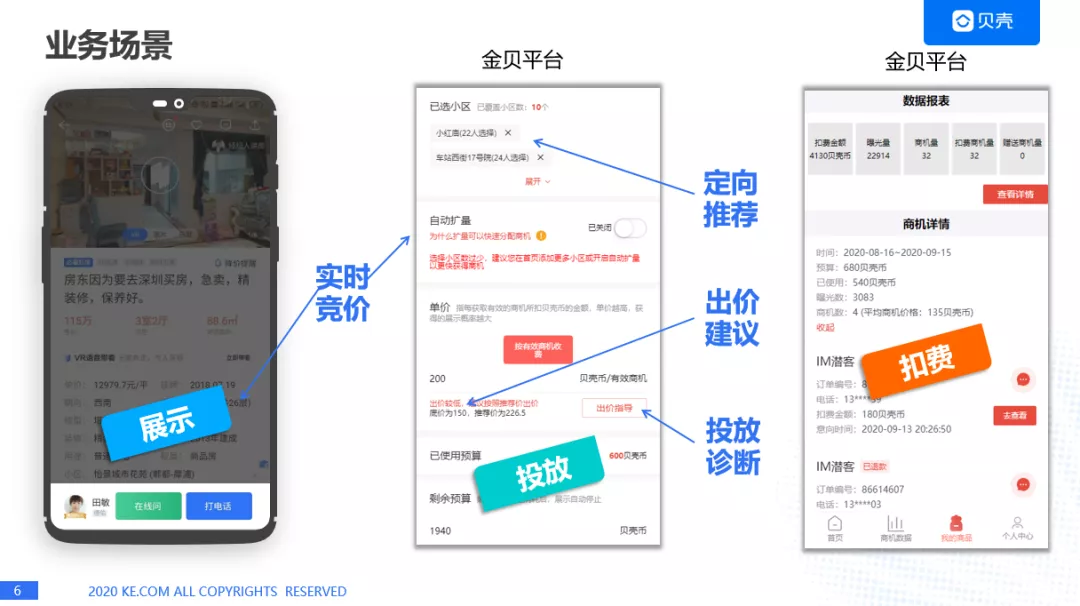
首先我们看一下业务场景,用户通过贝壳找房 APP 可以找到自己想买的房子,或者想要租的房子,在进入房源详情页的时候,房源详情页会有一个房源经纪人的展示,这个经纪人在后台实际上是通过实时竞价之后才会出现的,而实时竞价是各种经纪人,通过金贝平台,购买商业化产品的平台,去进行小区的投放,以及进行出价,形成订单,这个过程会由商业化这边会做一个定向推荐,出价建议,以及订单投放之后的投放诊断,当用户和经纪人发生 IM 对话时,也就是想要咨询房子的情况,我们就会对贝壳经纪人的贝壳币进行扣费,所以大家可以看出来,我们和一般互联网公司不一样的地方是广告主是经纪人。
2. 竞价排序

接下来我们看一下竞价排序的方法,这个和计算广告类似的,通过 eCPM 进行经纪人的排序的,eCPM 是通过经纪人的出价和 CVR 的转化进行预估,两者相乘得到一个 eCPM,这里 CVR 的话是预估未来 7 天商机转委托的概率,相信同学在之前的分享中听过商机这个词,用户和经纪人进行一次对话,我们称为一个商机,发生对话后,用户会把自己的电话委托给经纪人,让经纪人帮他/她找房子,这个过程我们称之为委托。所以我们预估就是未来 7 天商机转委托的概率。
3. 贝壳的商业化场景
为了让大家更好的理解贝壳的商业化场景,我这里举例来做一个对比。我们通过门户网站和贝壳进行对比:
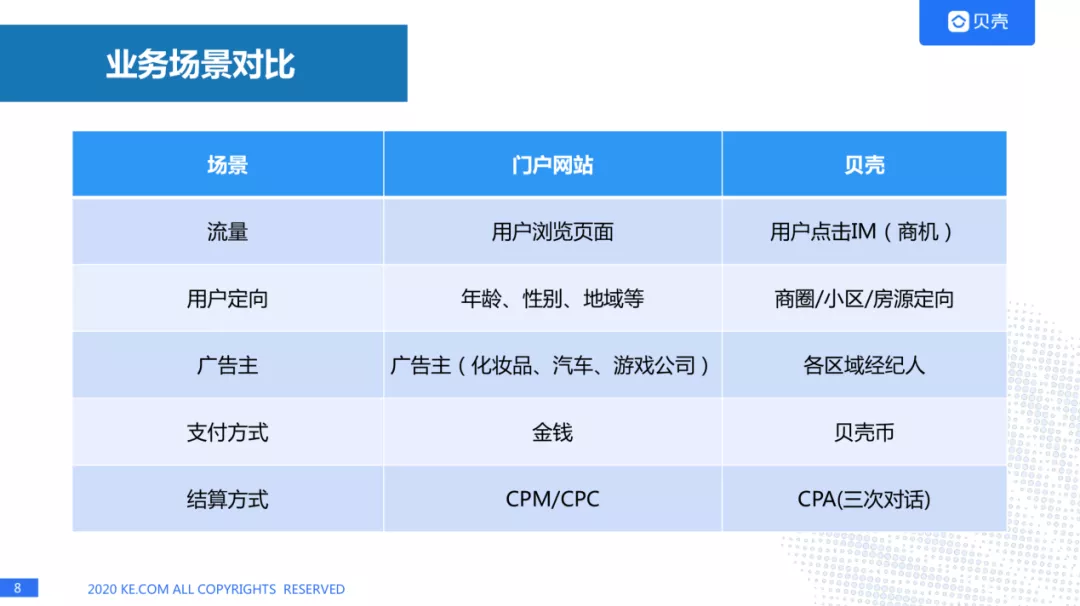
从流量角度来看,门户网站针对用户浏览页面,用户发生点击行为称为流量,而贝壳是用户点击 IM(商机)称为是流量。
从用户定向来看,一般的互联网公司在做用户定向的时候,对用户做各种分析,比如他/她的年龄、性别、地域等,而贝壳主要是针对用户感兴趣的房源进行定向,用户一般会看某套房子才会咨询经纪人,所以证明用户对这套房子是非常感兴趣的,用房源来做定向的话,可以说是非常精准的。
从支付方式来看,广告主就是各区域的经纪人,支付方式的话,我们用的不是金钱,而是贝壳币,贝壳币是我们牵引经纪人完成任务的抓手,平时我们会给经纪人下发各种任务,经纪人完成任务之后会获得贝壳币,有了贝克币之后就可以购买我们的商业化产品了,对于经纪人来说,获得贝壳币来说就是获得商机,通过这种方式我们可以牵引经纪人去完成各种任务,更好的服务我们的客户。
从结算方式来看,很多门户网站都是通过 CPM/CPC 的方式进行结算的,而我们是通过 CPA 方式进行结算,我们对 CPA 也进行了加强,必须是用户和经纪人发生三次有效对话之后才会进行扣费,这样也是更好的保证经纪人的权益。
4. 商业化展示
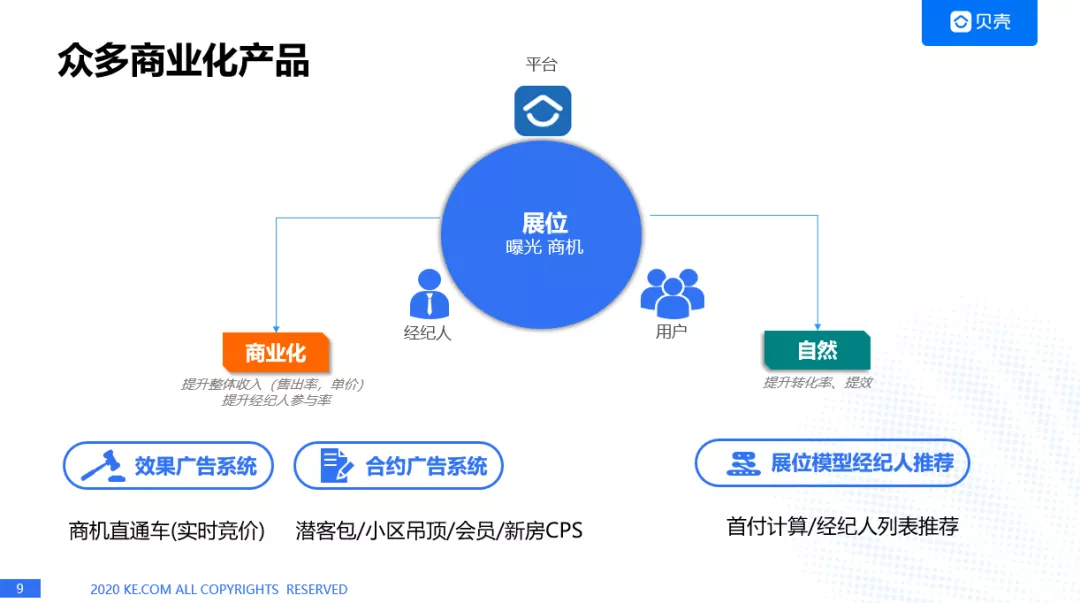
目前我们已经有了众多的商业化产品,因为我们最重要的一个展位就是在贝壳 APP 里面会有很多的曝光,曝光之后就会产生商机,我们重要的两个商业化产品:
效果广告,也称为商机直通车,其实跟淘宝直通车是非常类似的,也是通过实时竞价的方式进行投放,
合约广告系统,目前是有潜课包/小区吊顶/会员/新房 CPS 等。
当然了,我们也推出了自然流量,就是通过展位模型的方式给经纪人推荐,比如在首付计算/经纪人列表推荐等等,所以众多商业化产品的话,总结一点就是我们是给用户推荐经纪人的。
贝壳商业化架构演进历程
1. 贝壳商业化历史进程

2018 年,贝壳找房成立,启动 CPT 等合约广告产品开发。
2019 年,随着流量增大,对流量进行精细化分类,探索效果广告。
2020 年,我们已经有了众多的商业化产品,结算方式也有了 CPA/CPM/CPT/CPS 等等。
2018 年架构产品的业务形态
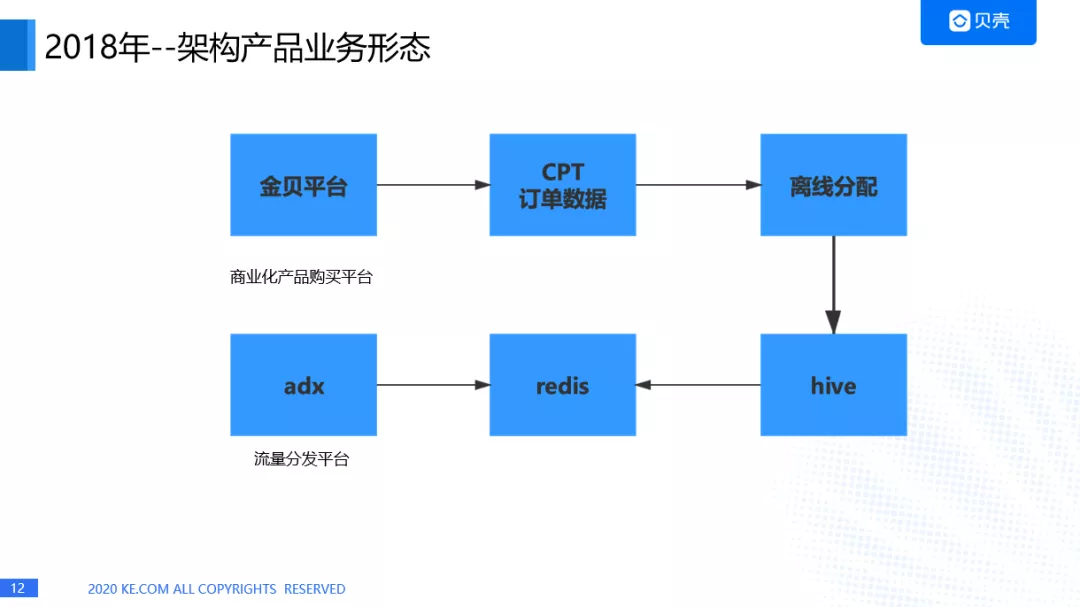
这时的架构是非常粗犷的,对接方主要有两个,一个是金贝平台,这是一个商业化产品购买平台,
另外一个是 adx,这是一个流量分发的平台,经纪人在金贝平台购买了商业化产品之后,会在 CPT 上产生订单数据,通过 mysql2hive 的方式进入 hive 表,然后就进行离线分配了。而 adx 的话,是通过 redis 数据库进行一个流量的获取,经纪人的推荐。
2019 年架构产品的业务形态
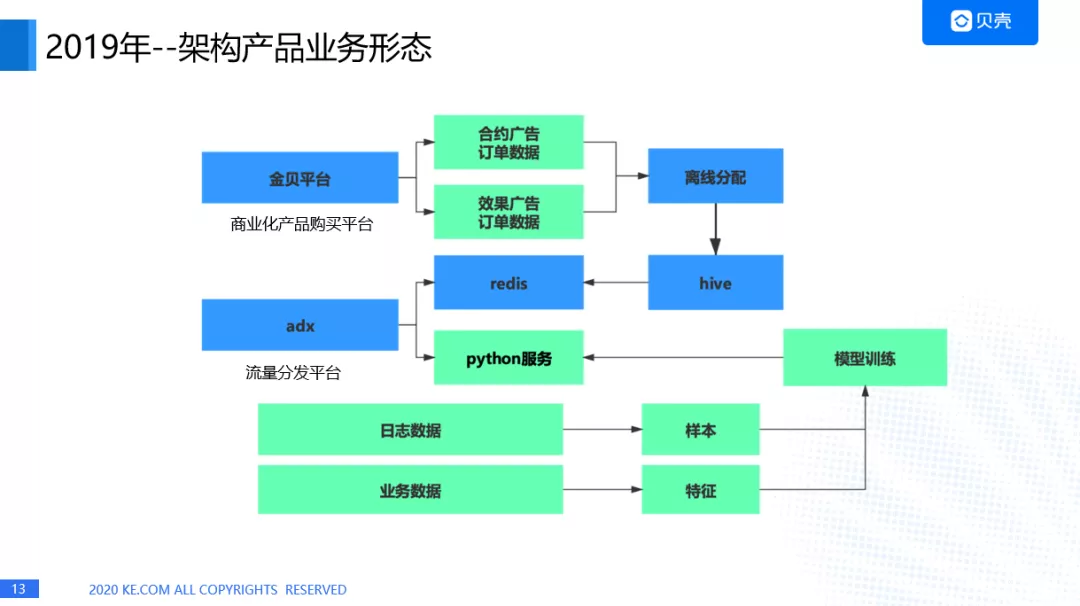
2019 年金贝平台开始售卖效果广告,所有金贝平台形成效果广告的数据,而 adx 的话,不仅对接到合约广告,还有实时竞价,所以我们起了一套 python 服务,这项服务因为需要对 CVR,也就是刚才提到的 eCPM 进行预估,因此我们要进行一个模型的训练,会去收集到日志数据,业务数据,形成样本和特征,经过模型训练,进行在线预估。Python 服务的话,我们考虑到开发效率,所以直接用了 python 的 tornado 来进行线上的 web 服务。
2020 年架构产品的业务形态
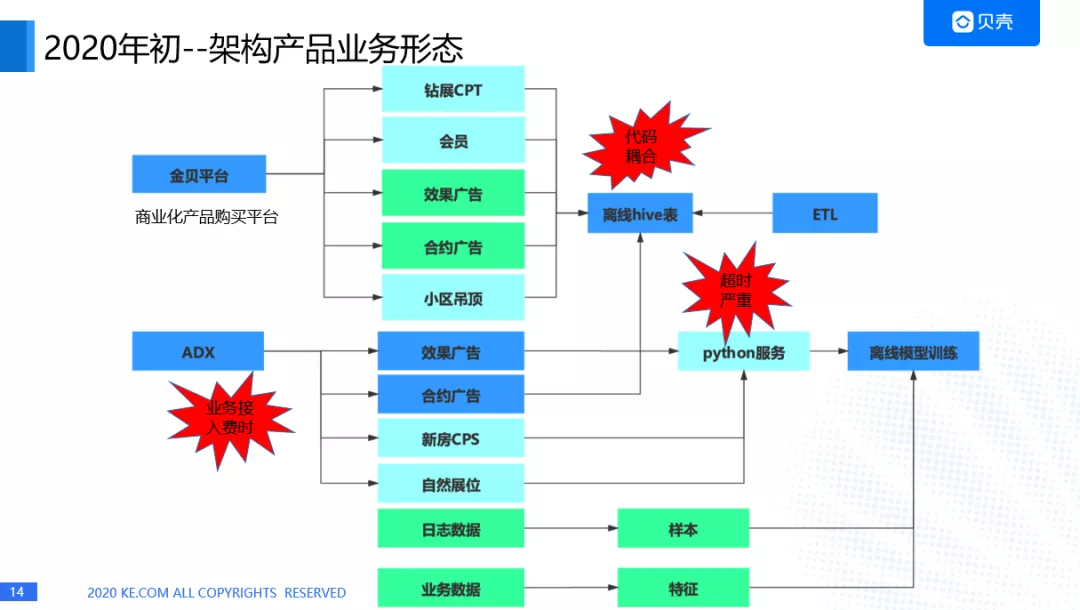
等到 2020 年的时候,我们的产品就已经非常多了,钻展 CPT,会员,效果广告,合约广告等等都接入我们的平台,ADX 不仅接入了效果广告,合约广告,也接入了新房 CPS,自然展位等众多的平台接入进来,还是通过 python 进行一个在线服务的提供,这时就暴露出几个问题,一个是 python 服务出现超时,而且超时越来越严重,第二个是 hive 表在进行离线计算的时候,代码都是耦合在一起的,第三个是我们在承接新的业务时,会出现业务接入费时的情况,我们算法的小伙伴都在进行业务的接入,而没有沉下心来对模型进行深入的探究。
2. 过程中的问题与解决方法
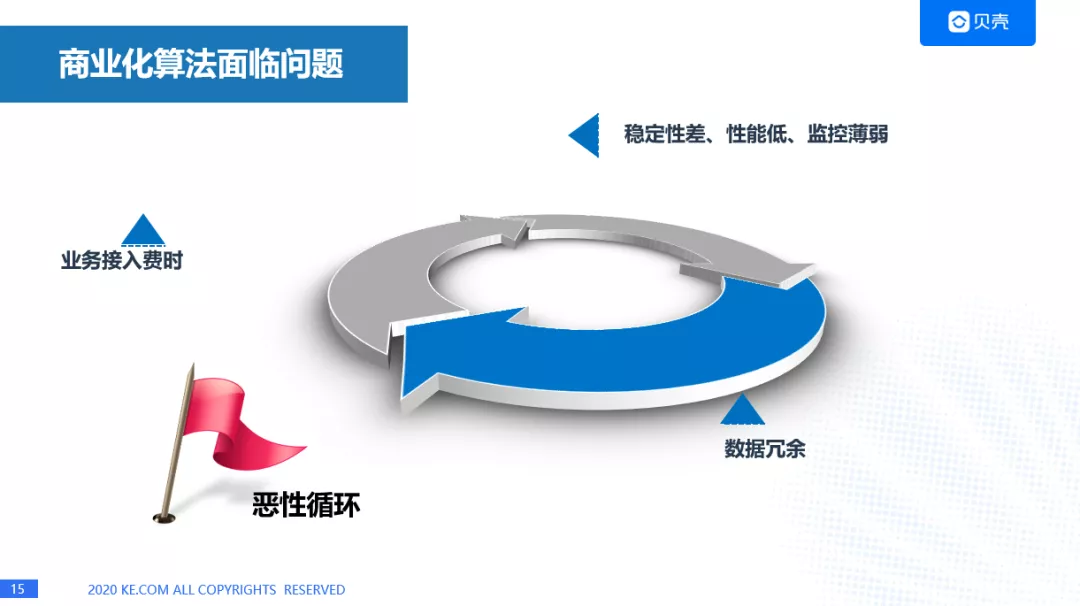
第一个是稳定性差,性能低,监控薄弱的问题。
第二个是数据冗余的问题。
第三个是业务接入费时的问题,随着这三个问题越来越严重,我们的产品接入方也越来越多,整个过程就形成了恶性循环。

这时系统重构迫在眉睫,于是,在年初的时候,我们就诞生了一个想法,对整个的系统架构进行重建,出现了商业化策略算法中台的架构。
贝壳商业化策略算法中台架构
1. 设计过程
既然要设计一个新的架构,肯定要把老的问题都解决掉:
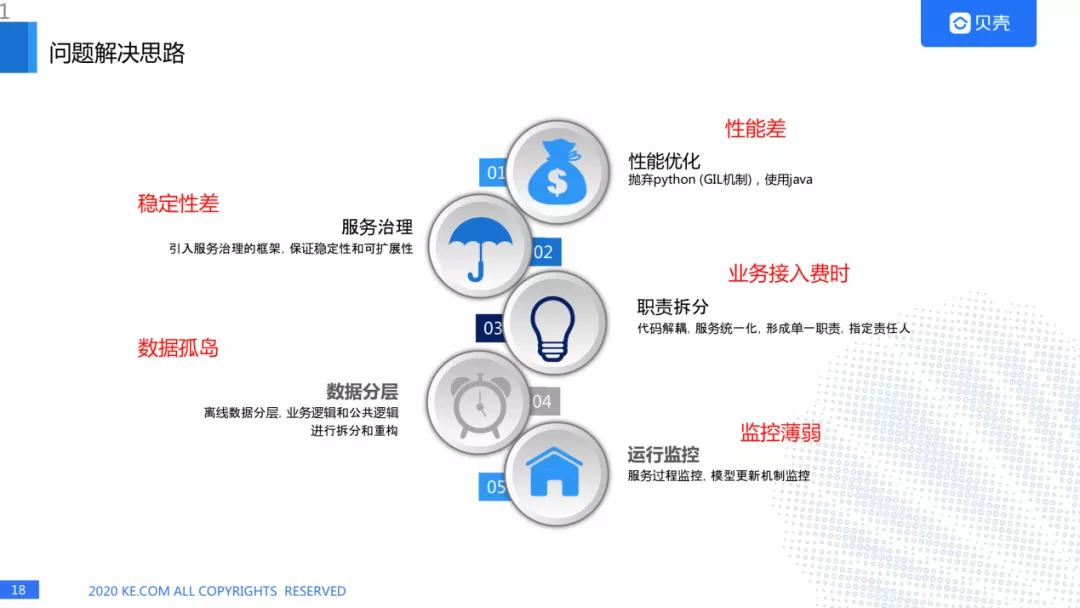
针对性能差的问题,我们抛弃了 python 的代码,而是使用 java 进行服务的构建,python 的 GIL 机制,导致 python 的多线程是一个伪多线程,而使用 python 进行多进程,我们知道进程的切换也浪费 CPU 资源的,所以我们干脆用 java 来进行服务的重构。
针对稳定性差的问题,我们打算引入服务治理的框架,引入服务治理的框架,保证稳定性和可扩展性。
针对业务接入费时问题,我们是对微服务拆分,代码解耦,服务统一化,形成单一职责,指定责任人。
针对数据孤岛问题,我们对离线数据分层,业务逻辑和公共逻辑进行拆分和重构。针对监控薄弱的问题,由于我们引入了服务治理的框架,因此可以对服务过程进行监控,模型更新机制监控。
2. 架构分层:
解决的以上这些问题之后,我们需要对架构进行分层,分层的好处就是各层次之间相互独立,通过接口调用。我们是把架构分成了三层:

在线服务层,主要是根据业务实际场景提供实时、高效、稳定的 http 接口,并灵活的进行 AB 测试。
近实时层,主要是进行模型训练、数据存储、订阅用户行为数据等,从而做到秒针级别用户兴趣捕捉和线上效果反馈。
离线计算层,从原始业务和日志数据进行 ETL,形成用户画像、经纪人画像、房源信息、训练数据等。
3. 各层特点与适合任务的相关规定

实时层,也就是在线服务层主要使用的是实时+非实时的数据,实时性是秒级,特点是响应速度快,数据实时性敏感,计算复杂度低,稳定性高时延低,适合的任务是在线请求。
近实时层使用的数据是实时+非实时,实时性是分钟级,特点是基于实时数据,计算复杂度适中,队列可缓冲数据,适合的任务是特征实时计算与更新,实时算法计算(相关性),模型在线更新,指标统计和计算,日志收集和分析。
离线计算层使用的数据是非实时的,实时性是小时级,特点是大数据批量计算,计算复杂度高,大容量存储,适合的任务是 ETL 任务(规则特征样本),模型的训练。
4. 各层架构的特点:
我们来看一下整体的架构情况,每个层都会有详细的模块与特有的特征。
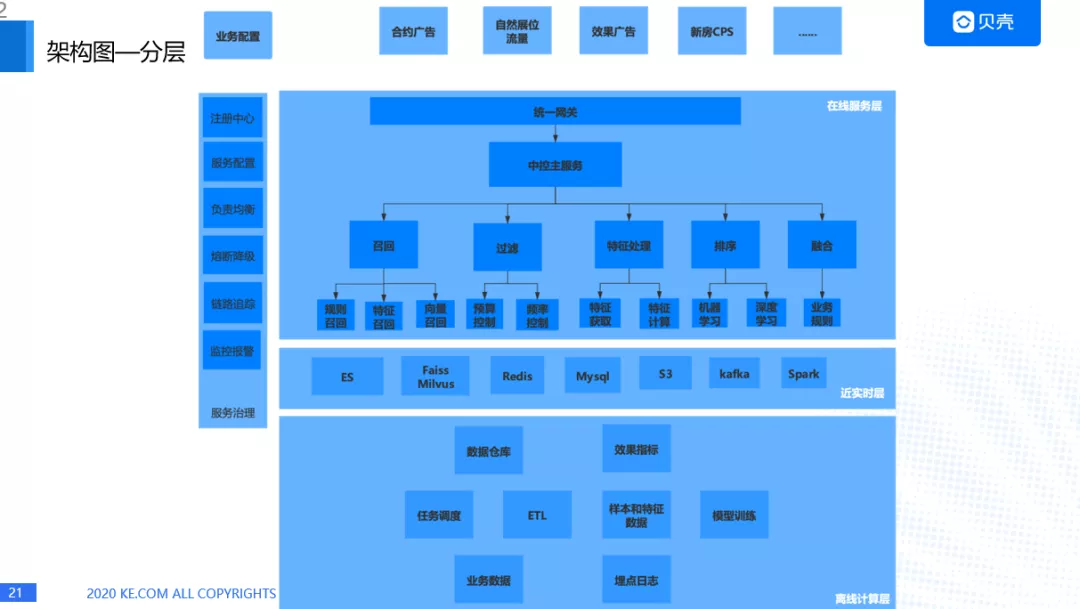
下面我们将为大家详细介绍下各层:
在线服务层
1. 在线服务层架构
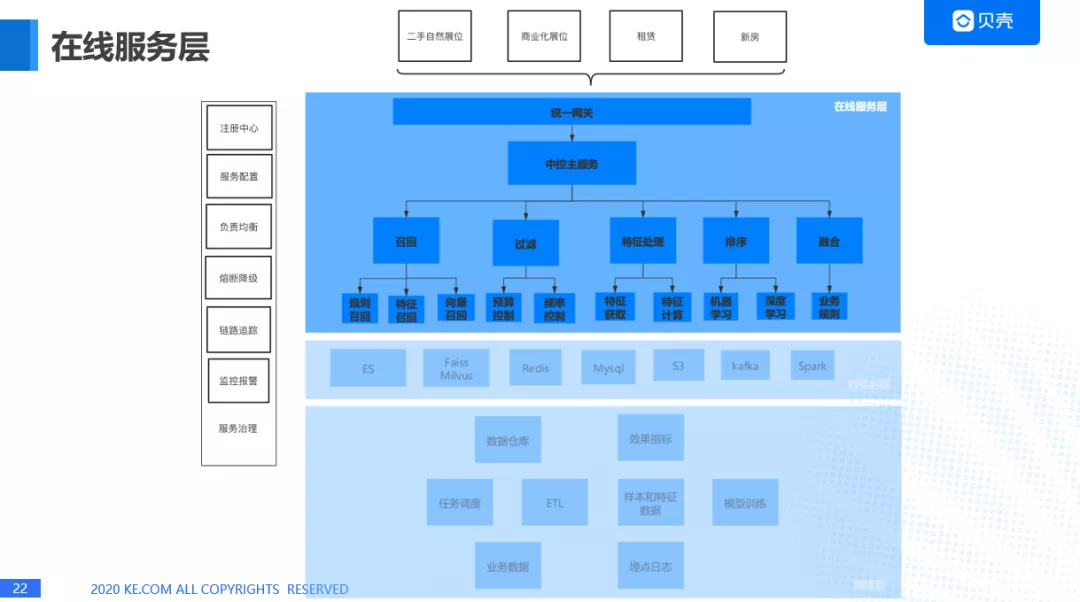
2. 在线服务层拆分

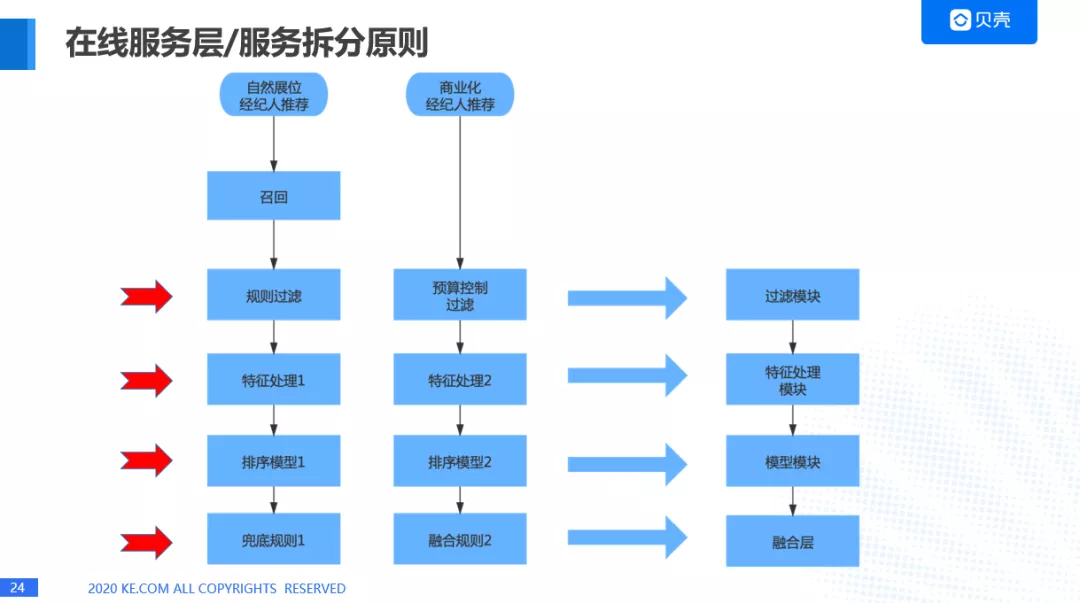
在线服务层我们要对业务进行拆分,引入服务治理的框架,不可避免的要对服务进行拆分,拆分主要有两个原则:
横向拆分,按照不同的业务域进行拆分,我们这里是拆分成了效果广告,合约广告和自然展位三个业务域。
纵向拆分,把一个业务功能里的不同模块或者组件进行拆分,从多个业务角度找共性,将服务进行抽离,确定各个服务边界,清晰职责。
这里我们看一个例子,这是两个主要的业务。一个是不走商业化流量的自然展位经纪人推荐,另外一个是商业化经纪人推荐。
自然展位经纪人推荐是要经过一个召回模块,规则过滤,特征处理,排序模型,兜底规则。商业化经纪人推荐是不走召回模块,因为它的业务主要是从前端传过来的,就是这个经纪人有订单了,就会直接召回,因为整个过程越激烈,对我们来说是越有好处的,召回完成之后,会进行预算控制,这是比较特殊的一点,后面会讲,其实就是对经纪人做一层过滤,然后进行特征处理,排序模型,融合规则,融合的话,会计算 eCPM。
这两个过程有很多相似的地方,所以我们对这两个过程其中的一些部分进行了抽离,比如说规则过滤和预算控制过滤,我们抽离成过滤模块,特征处理我们抽离成了特征处理模块,排序模型我们抽离成了模型模块,兜底规则和融合规则我们抽离成了融合层的服务。
在线服务层拆分原则:
我们来看一下在线服务层拆分前和拆分后的状态。中控主服务主要包括策略配置,召回阶段,特征处理,排序阶段,融合阶段。
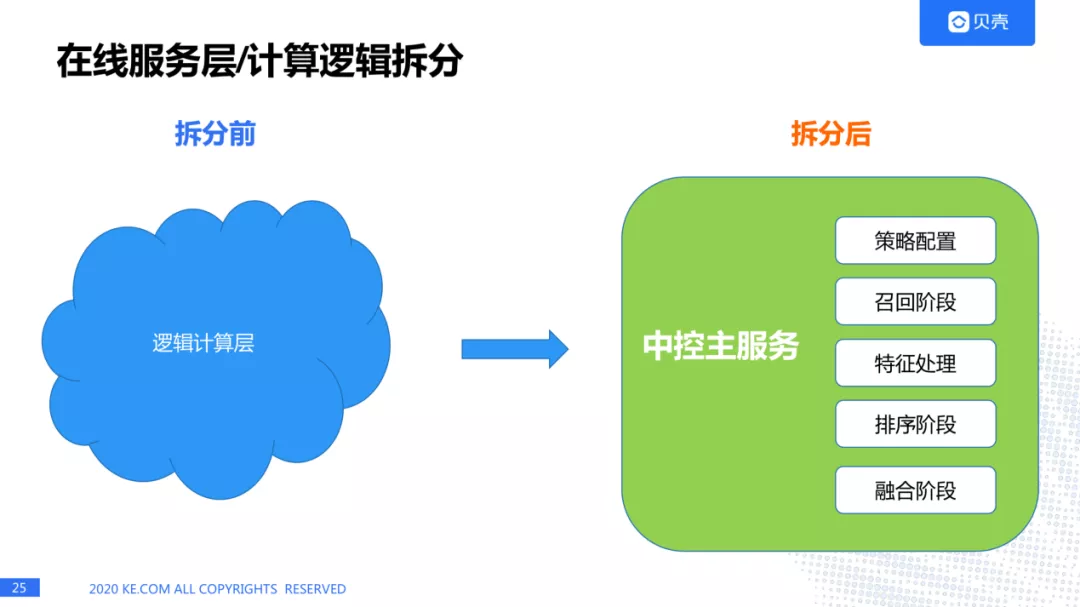
在线服务层拆分形态和调用流程:
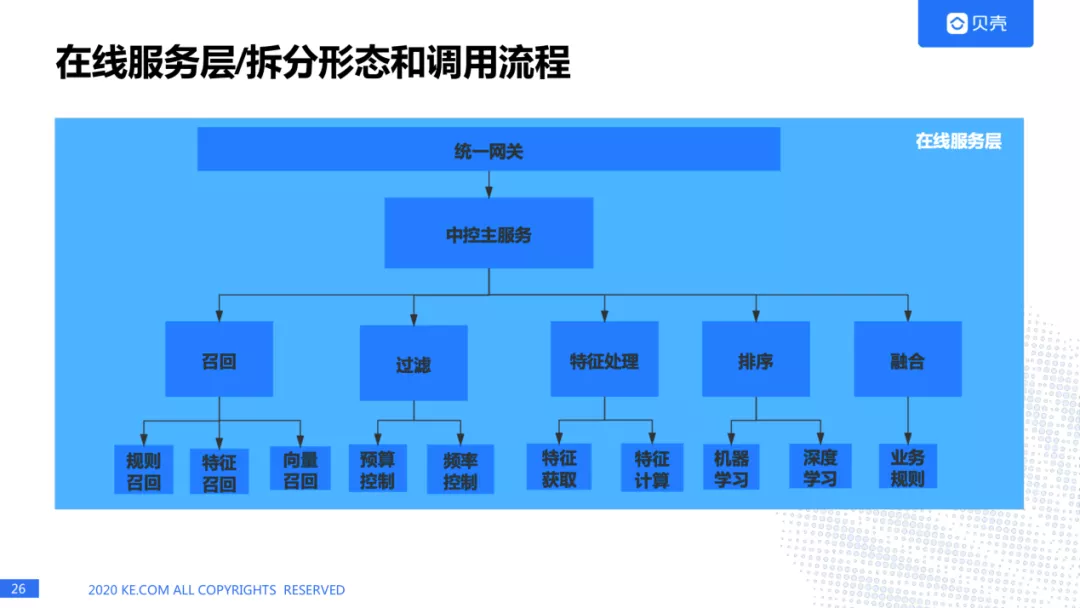
我们来详细看一下在线服务层的各个部分。请求会通过统一网关进入中控主服务,中控主服务会调用下面的各个子服务,比如召回,过滤,特征处理,排序,融合。召回里面有很多召回的方式,过滤里面也会有很多过滤的方式。接下来我会介绍一下每个服务里面设计的特点。
3.中控主服务,主要功能:
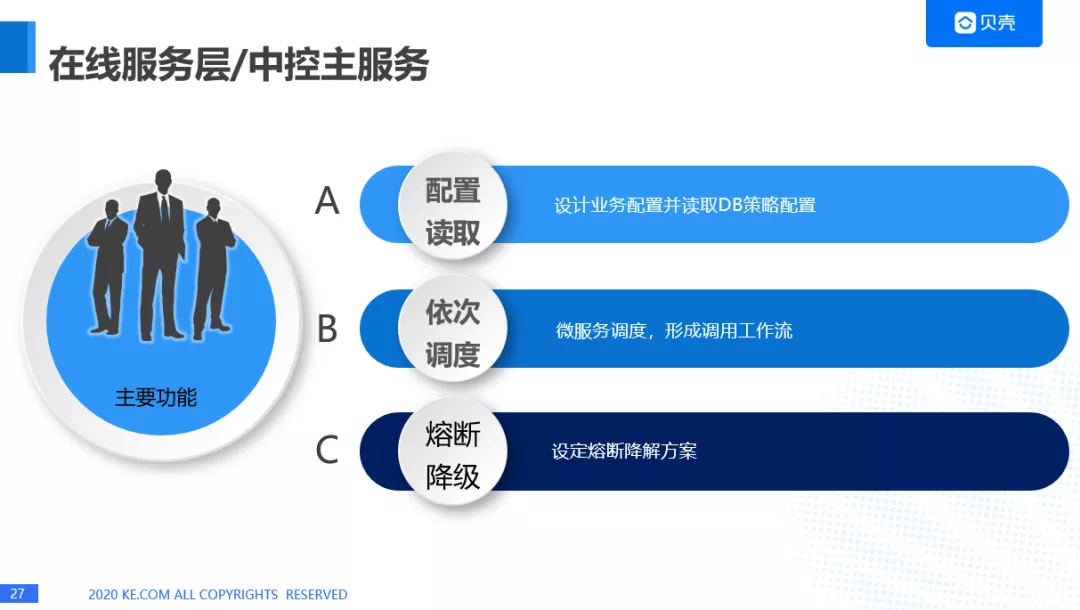
配置读取,我们会对每个要调用的服务进行配置化,有些业务需要一种召回方式,有些业务需要多种方式进行召回,我们都可以通过配置的方式进行更新。
读取配置后,需要对微服务进行依次调度,形成调用工作流。
会对熔断降解方案的设定。
4. 策略配置设计的过程
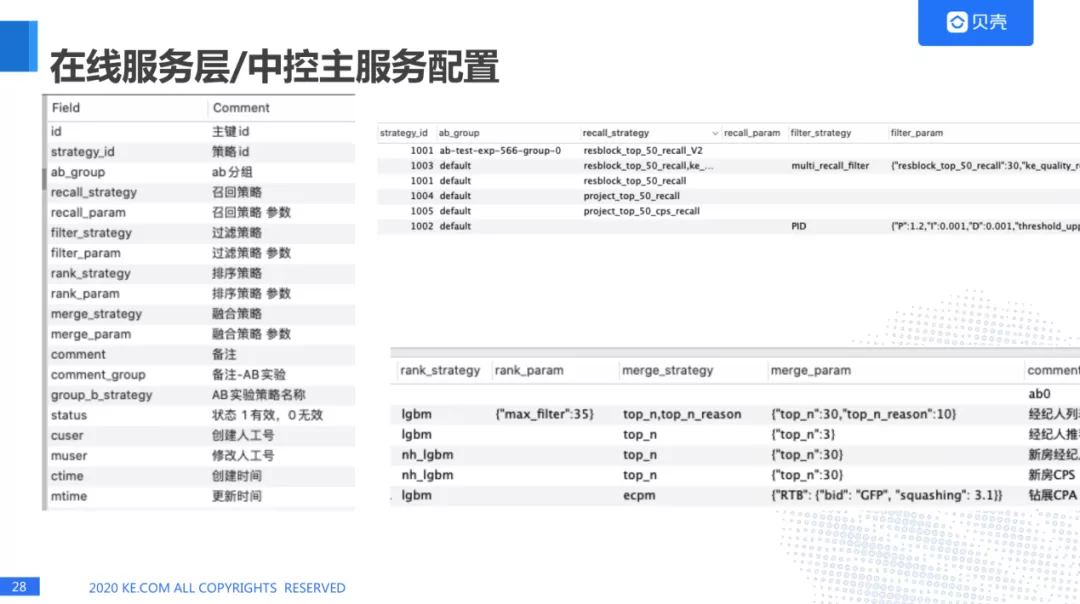
左边是一张 mysql 的表,我们可以看到这里的字段有召回策略,过滤策略,排序策略,融合策略等,针对每个策略,我们都可以设定召回策略的参数,排序策略的参数等等。举个例子比如这里有个展位,我们可以设定它的召回策略,过滤策略,排序策略以及融合策略。
5. 中控主服务的特点:

对外提供 HTTP 服务,对内微服务调用使用 RPC 或者 HTTP。
各微服务调用时间使用动态设置,一般各模块实际超时时间=Min(该模块最大超时时间,剩余时间)。
尽量不包含业务逻辑,减少迭代。
6. 在线服务层中召回模块
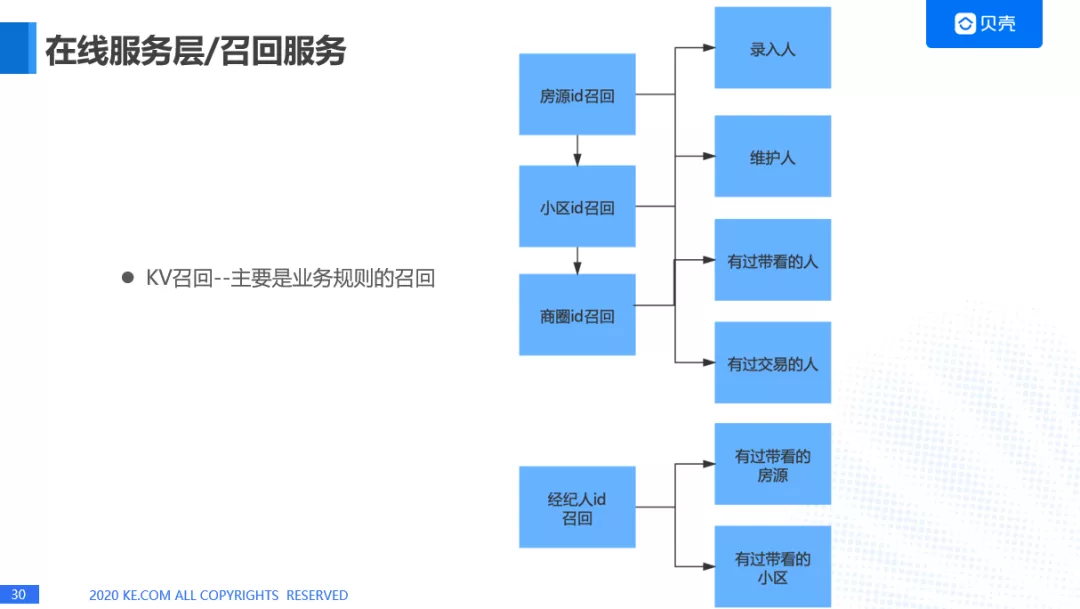
第一个我们会做 KV 召回—主要是业务规则的召回。把计算好的数据放在 KV 数据库里面,比如用户来了之后,点了某一套房子,然后我们通过房源召回录入人,维护人,有过带看的人,有过交易的人,这样就可以把经纪人召回来,如果这个小区没有数据的话,就再往上一层,分别来做兜底,小区没有的话就从商圈的维度去召回经纪人。还有一种就是从经纪人 id 进行召回,这个主要是金贝平台,我们需要给经纪人推荐他/她感兴趣的小区,她/他(经纪人)肯定会选择看有过带看的房源,有过交易的房源。
ES 召回
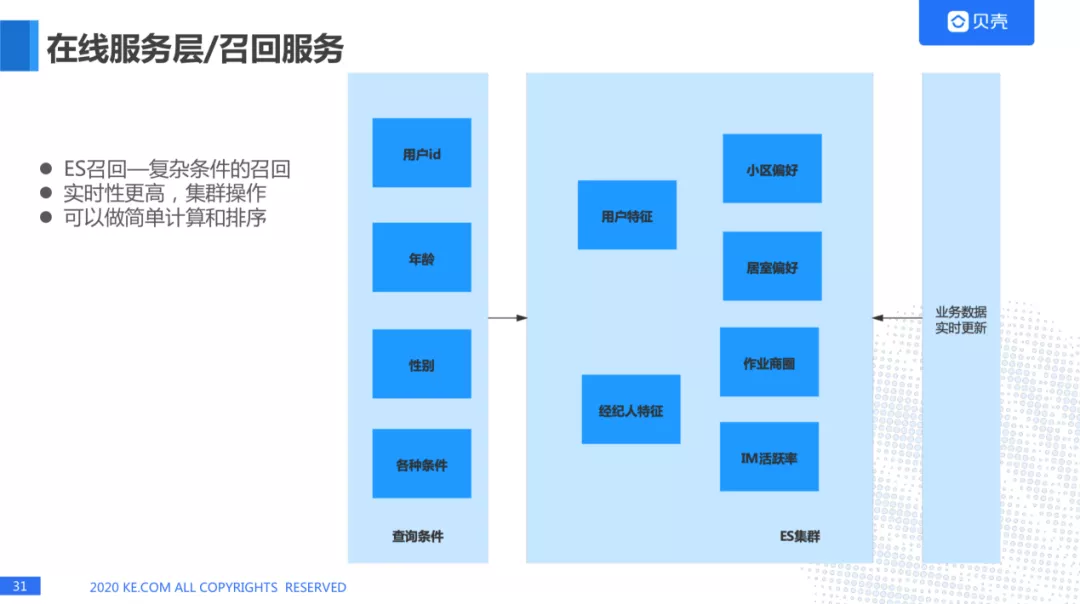
ES 召回有一些复杂的召回,比如用户 id,年龄,性别,各种条件的查询条件适用于冷启动的问题。ES 集群还有一些用户特征,经纪人特征,是从 DMP 平台获取的。ES 的好处是实时性更高,集群操作,可以做简单计算和排序。ES 里面也支持向量召回,效果也不错,我们有一些场景用到了 ES 的向量召回。
向量召回
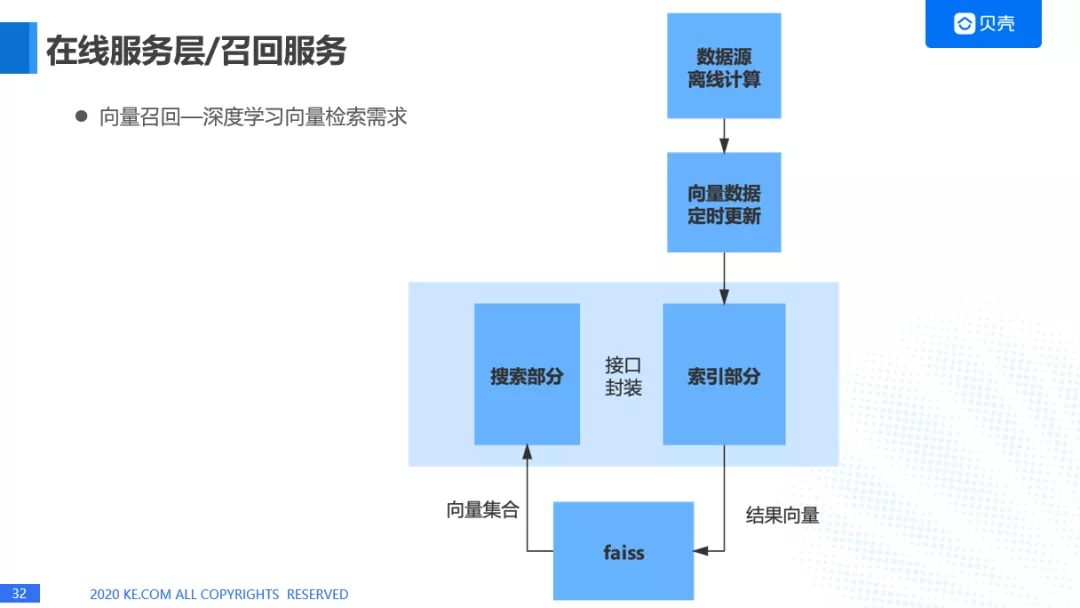
这个在深度学习向量检索的需求非常大,我们之前使用的 Facebook 开源的一个工具 faiss. 将数据源离线计算后,向量数据定时更新,通过一个接口索引部分,将结果向量送入 faiss. 另外一个接口是通过 faiss, 把向量集合送入到搜索部分。
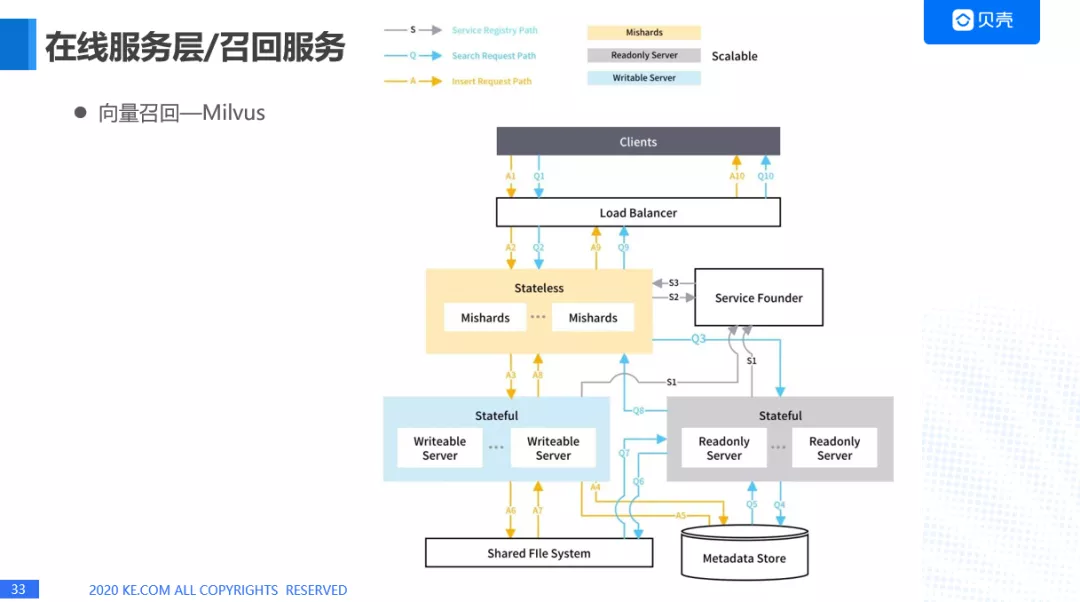
但是 faiss 有一个缺点它是单机部署,没有分布式,所以我们使用了另外一个比较火的向量召回的框架叫 Milvus,上面这个是我从官网上截的一张图,它的底层架构也是基于 faiss 的,它是使用了负载均衡,服务发现,对底层的数据进行分片,来保证稳定性和高性能。
embedding 向量生成的原理
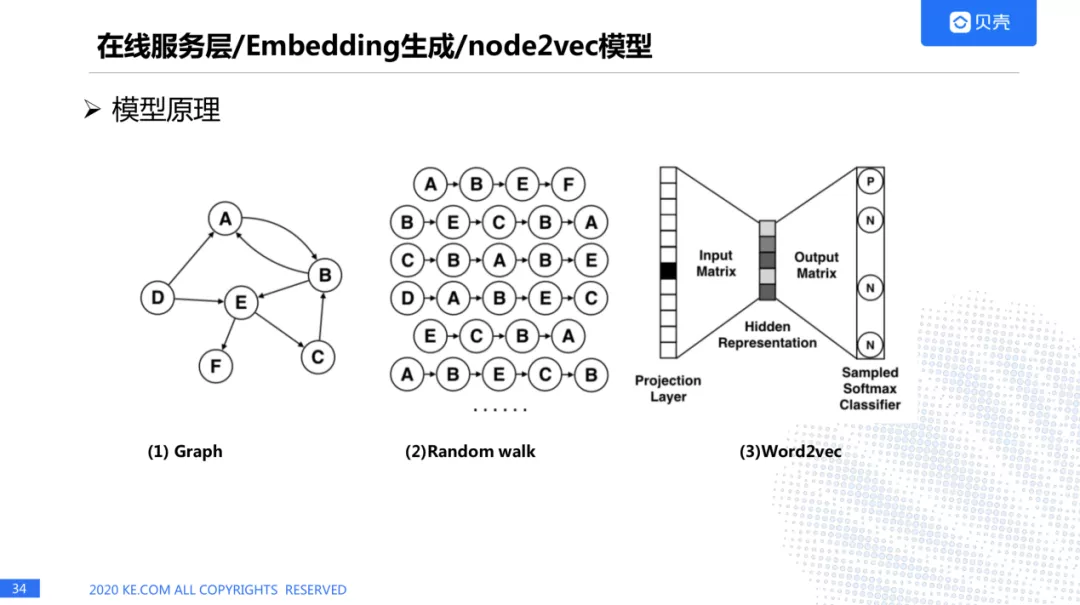
这里我们有多种模型生成 embedding,主要是通过 node2vec。也就是说用户在浏览 APP 的时候,会生成很多的房源序列,根据房源序列我们可以抽象出一张图,这跟我们使用的 word2vec 是非常类似的,生成一张图之后,会做随机游走,之后将结果输入到 word2vec,生成 embedding 的向量。
7. 如何去做线上的 serving
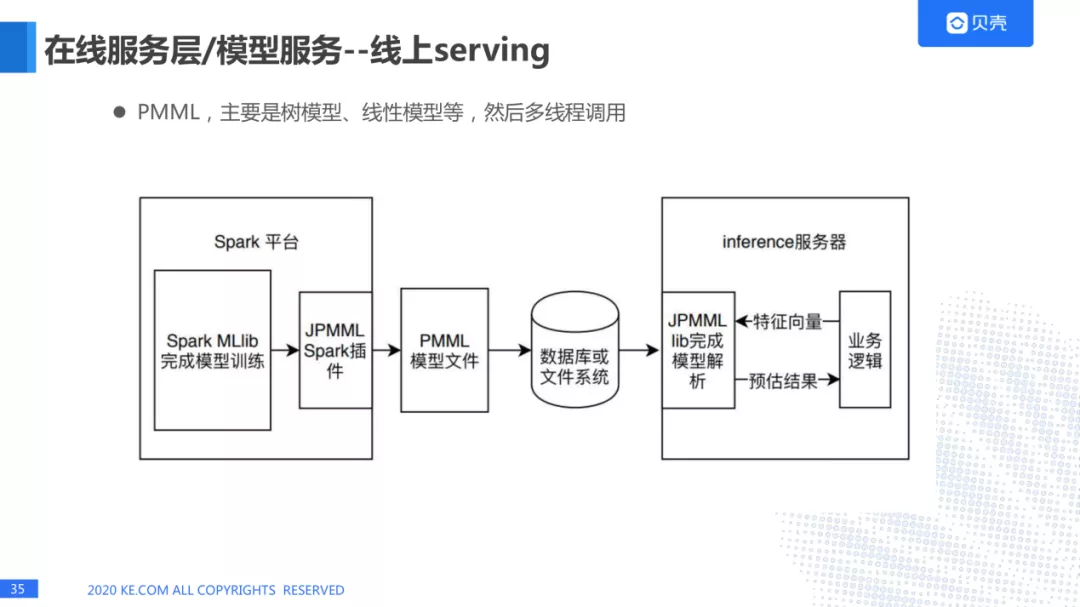
线上 serving 目前没有比较好的开源的解决方案,公司都会有一套线上自己的 serving 服务。而我们主要有两种方式,一种是 PMML 格式的文件进行线上 serving, 这个主要用在一些比较简单的模型,比如树模型、线性模型进行多线程的调用,这里主要是用 spark 平台,python 平台,我们可以通过模型训练之后,使用 JPMML 插件,形成 PMML 模型文件,然后把这种文件放在数据库或文件系统中,最后可以通过 java 服务进行线上推断。
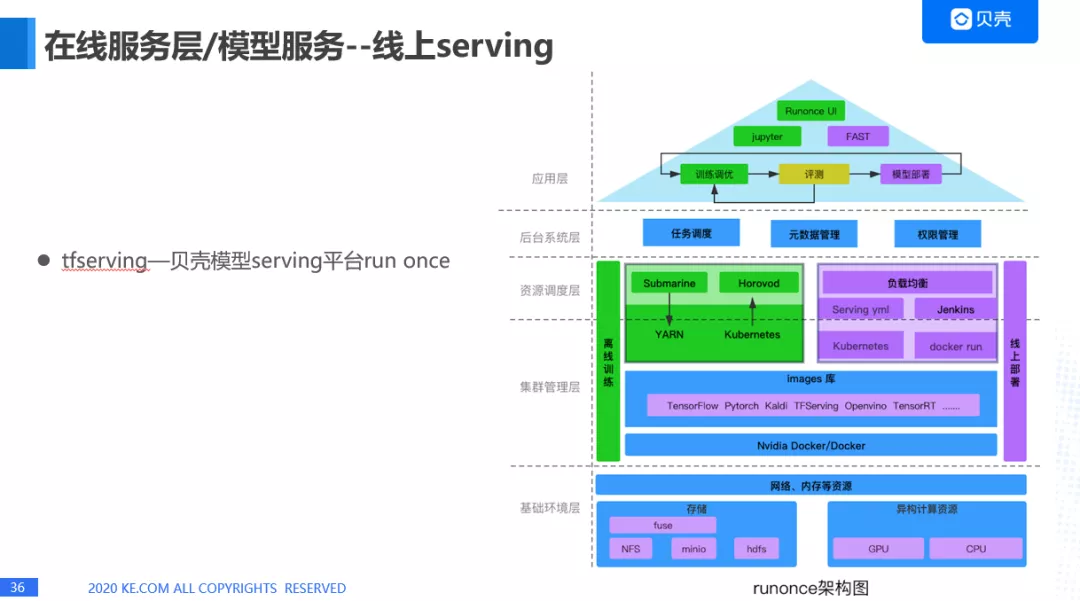
另外一种在线服务的方式,tfserving---贝壳模型 serving 平台 run once。上面是一个架构图。支持比如说 Tensorflow, Pytorch 等一些在线 serving。
过滤服务

预算控制,经纪人会在金贝平台生成订单,然后他/她会先把钱充到账户里面,那么我们肯定需要平稳的对经纪人的预算进行消耗。
频率控制,我们不想让用户看到同样的广告次数太多,我们会对这些广告进行过滤,但是我们这里会对广告主进行频率控制,也就是经纪人作业经历有限,如果我们一次给他/她的商机也就是用户太多的话,她/他会处理不过来,所以我们会对经纪人的频率进行控制。
业务方规则,可以通过 RPC 的方式调用业务方的接口进行过滤。
微服务的技术选型
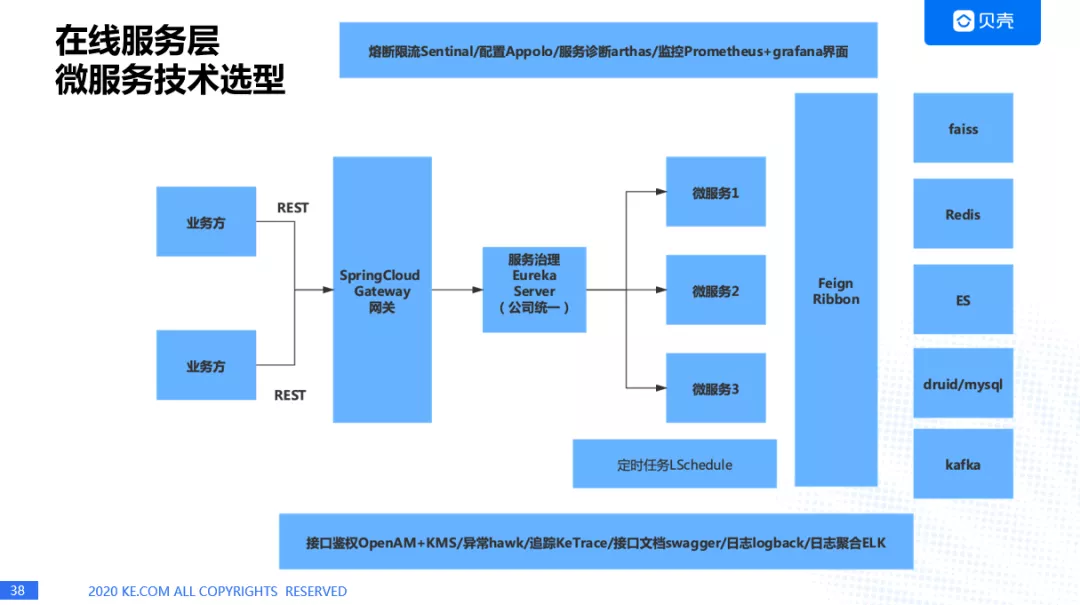
业务方会通过 SpringCloud Gateway 进入到服务里面,公司的服务会统一到 Eureka 平台进行注册,每个微服务是通过 Feign 进行通信,通过 Ribbon 进行服务的负载均衡,中间也用到很多开源的组件,比如接口鉴权(OpenAM),异常诊断(hawk),链路追踪(KeTrace),熔断限流(Sentinal),配置(Appolo),服务诊断(arthas),监控 Prometheus+grafana 界面来实时监控。
近实时层
1. 近实时层架构图
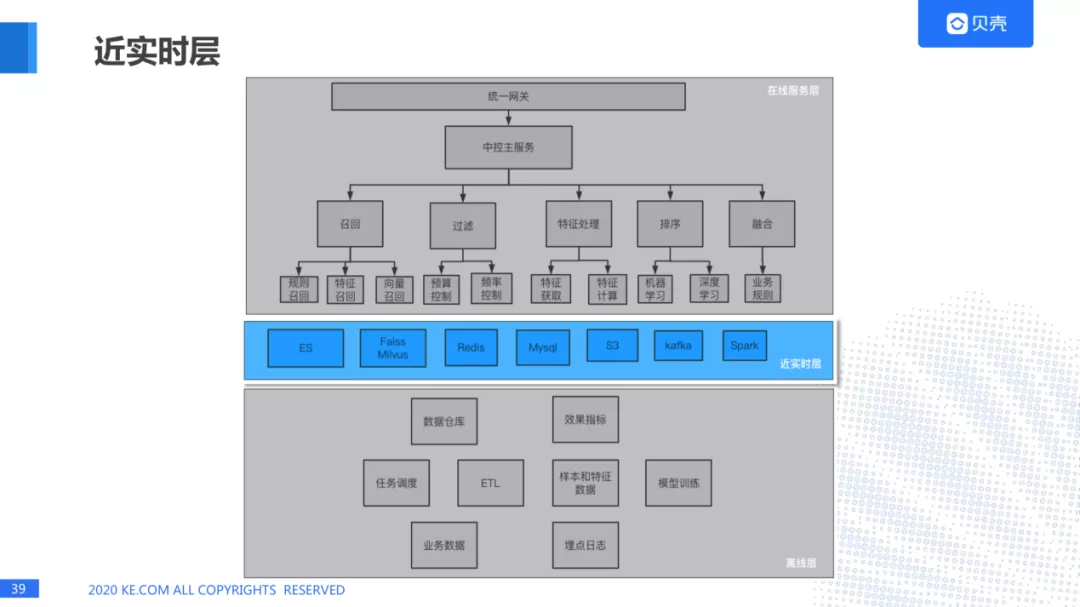
2. 近实时层数据收集
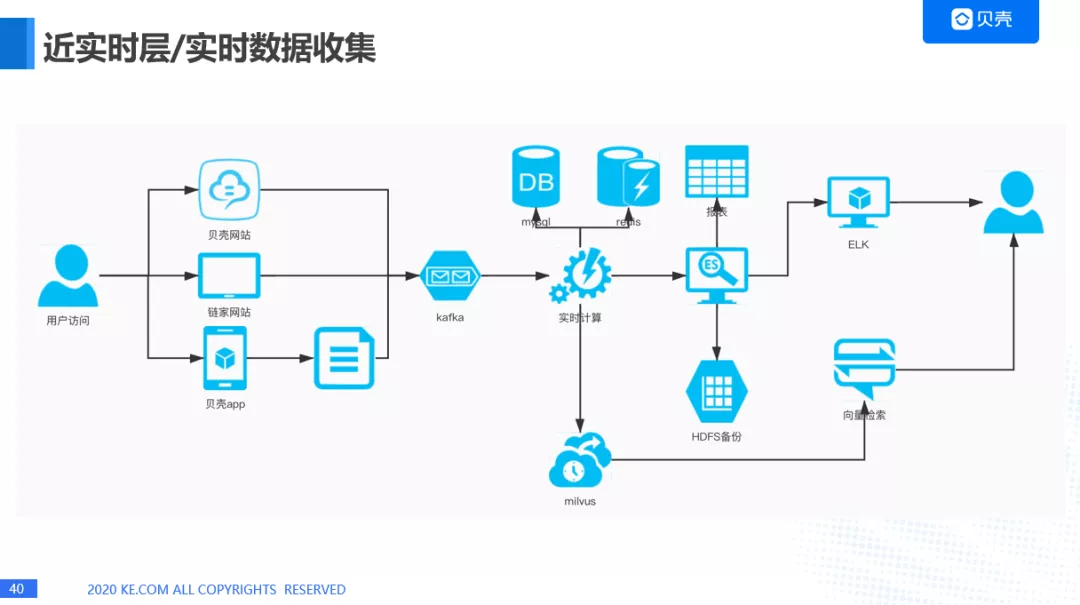
近实时层大多数公司的架构可能差不多。我们这里主要是会存储各种各样的数据,比如 mysql 数据,redis 数据,向量数据,另外一个就是会对实时数据进行收集,比如用户访问贝壳网站,链家网站,贝壳 App 之后,会留下数据,后台会进行埋点,然后通过 kafka 进入实时计算的模块,最后会计算出一些规则的数据,记录到 mysql,redis,进行一些向量的计算,进入 milvus,进行向量搜索,我们也会把数据进入到 ES 里面做一些报表,还有做一些 ELK 的分析,以及 HDFS 的备份。
离线层
1. 离线层架构图
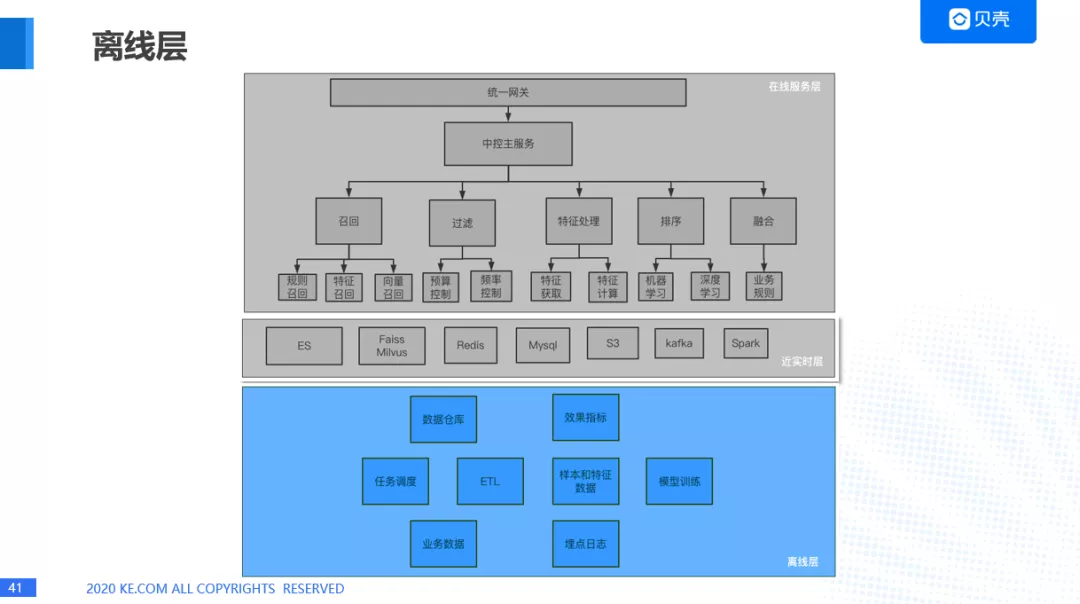
2.离线层分层:
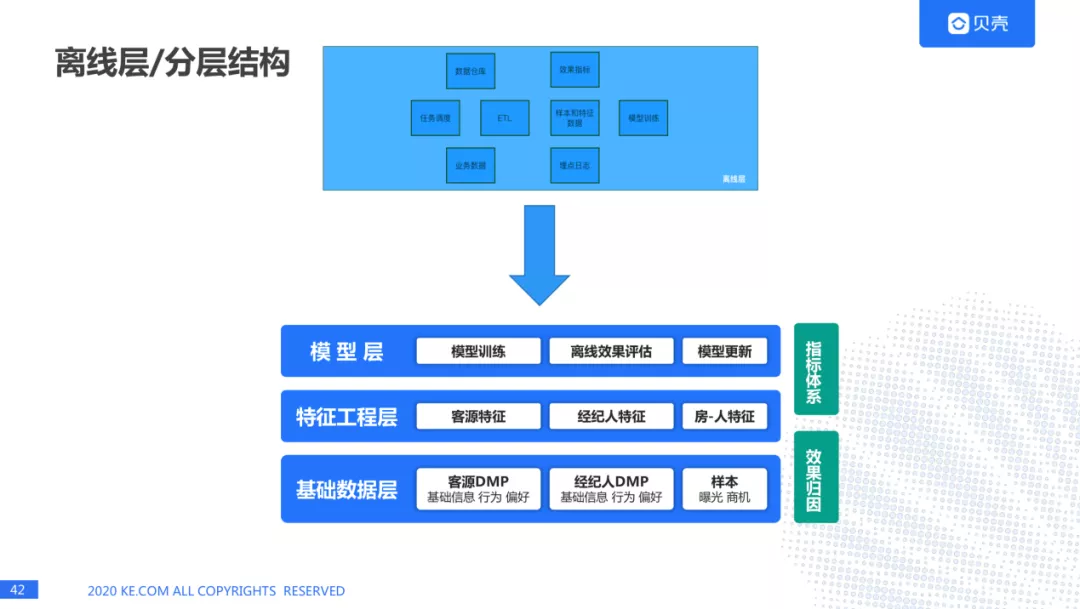
离线层在这个框架里面是一些功能,但是我们也对离线层进行了分层:基础数据层、特征工程层、基础数据层。
基础数据层,我们会从 DMP 平台获取到用户的画像,经纪人画像和业务数据(样本,曝光,商机等),在这之上会生成客源特征,经纪人特征,房-人特征,我们这里主要是给用户推荐经纪人,所以在使用的过程中我们发现使用房的特征做推荐对房的成交量作用并不大,我们就弱化了房的特征,关注经纪人特征和人的特征,因为我们发现用户在看这套房子,和最后成交的房子关系并不大,而经纪人和用户建立联系之后,经纪人会给用户推荐各种各样的房子,最后成交的并不一定是这个用户看的,再上面一层是模型层,包括模型训练,离线效果评估,以及模型更新。
3. 离线训练部分
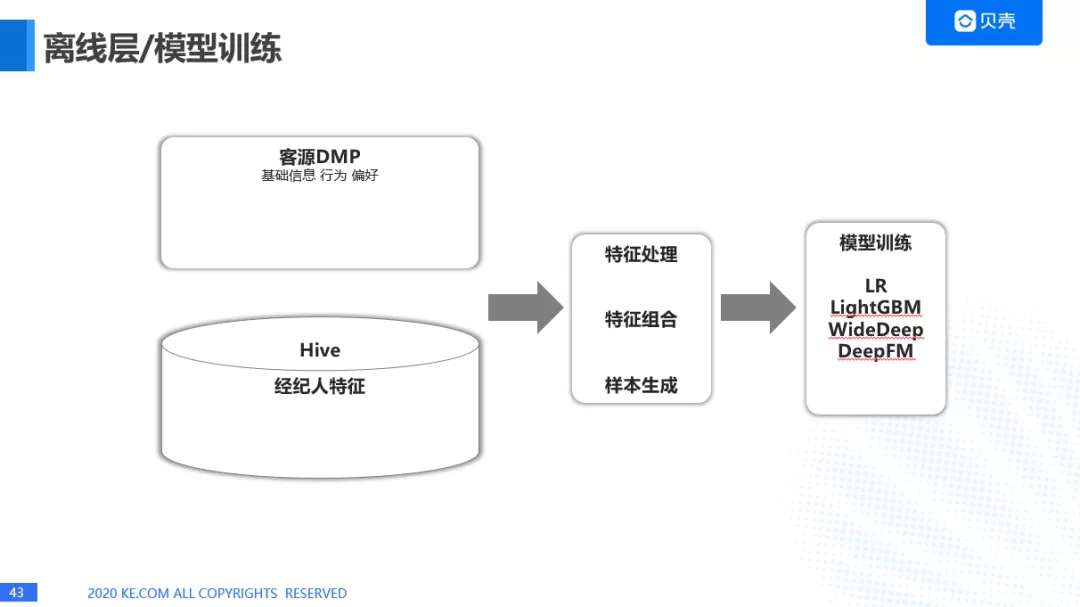
这是离线训练的部分。主要是使用特征进行离线模型训练,我们用到了 LR,Li ghtGBM, WideDeep, DeepFM 等等。
4. 架构重构之后的效果:
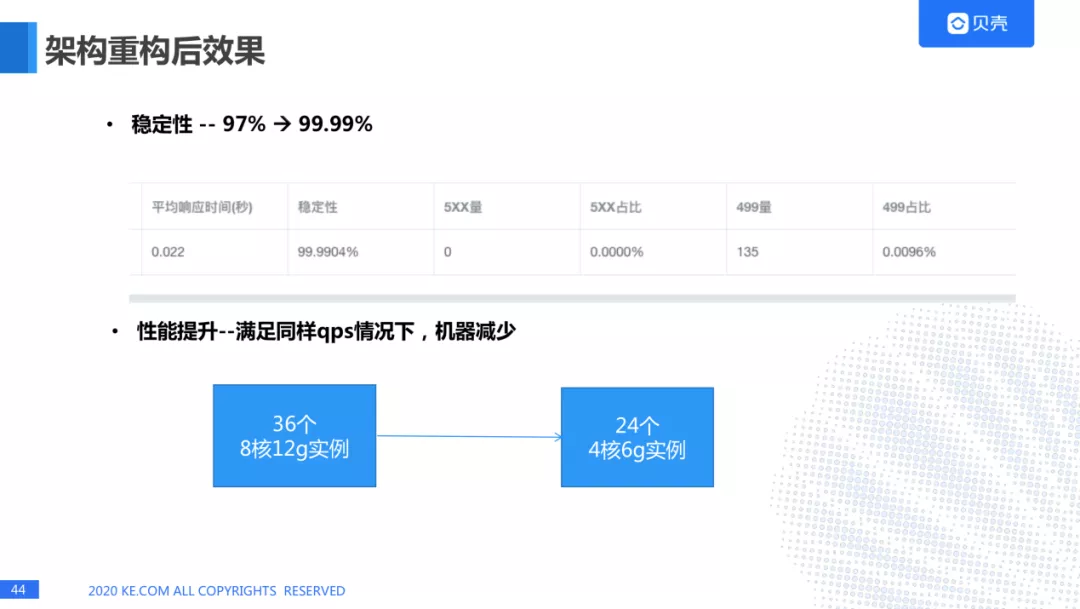
稳定性,由 97%升高到 99.99%。
性能提升—满足同样 QPS 情况下,机器由原来的 36 个 8 核 12g 实例减少到 24 个 4 核 6g 实例。成本上有了大的减少。
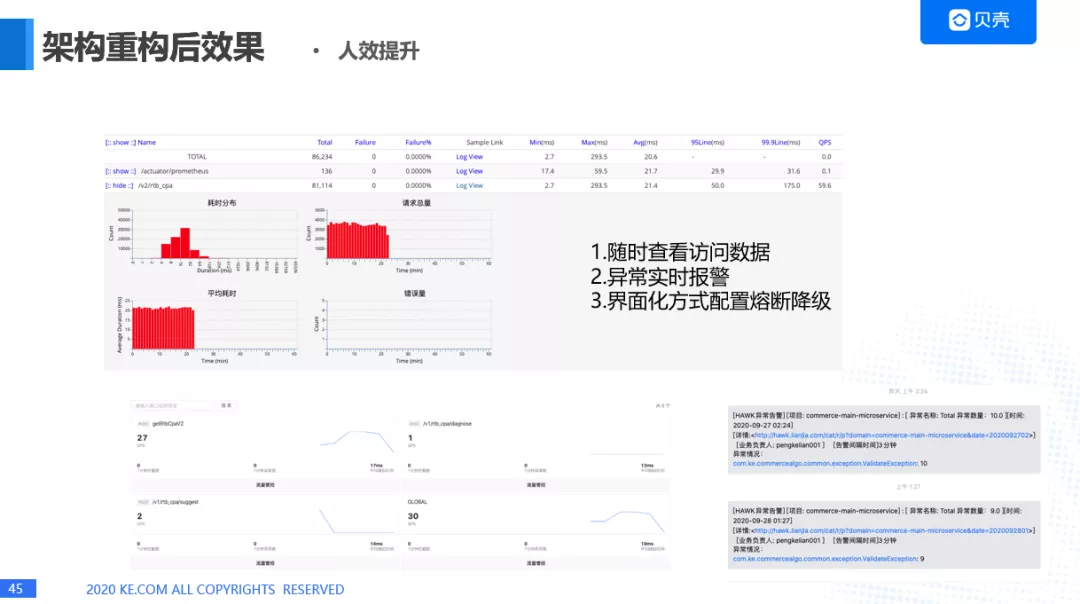
人效方面的提升,可以通过 hawk 随时查看访问数据,异常实时报警,通过 IM 告知给具体的责任人,通过界面化方式配置微服务的熔断降级方案。
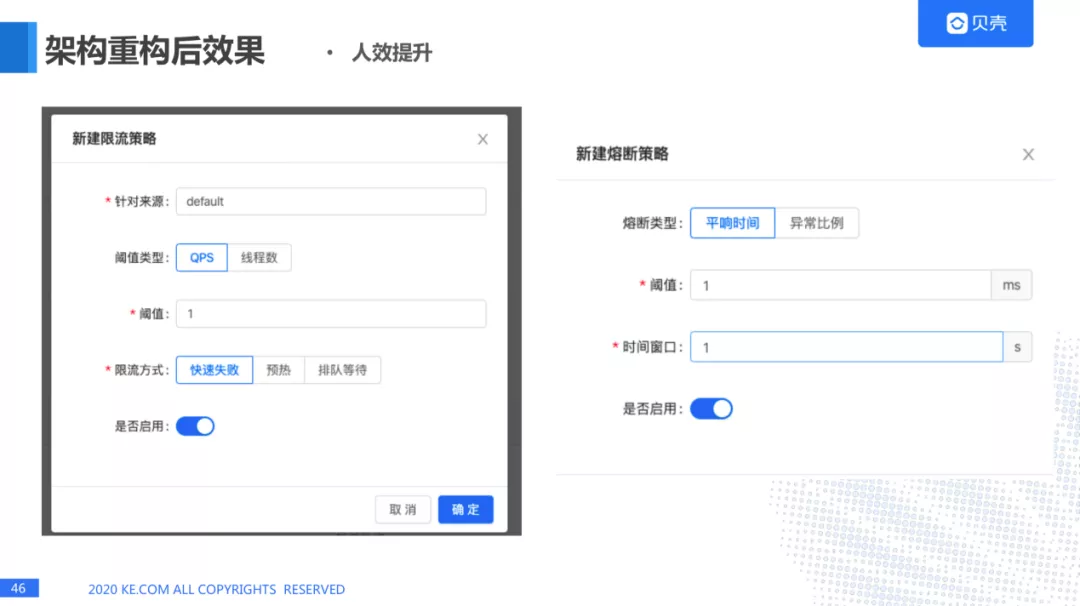
这里是我们通过界面的方式配置熔断限流策略,微服务的熔断策略,之前要修改这些配置需要改代码,现在需要界面就可以了。

当有新的接入方,我们可以打开城市、策略配置,做 AB 实验/各模块策略的配置,也可以对业务进行召回,过滤,排序等一些策略的设定,策略灵活设置,分钟级上线、生效。
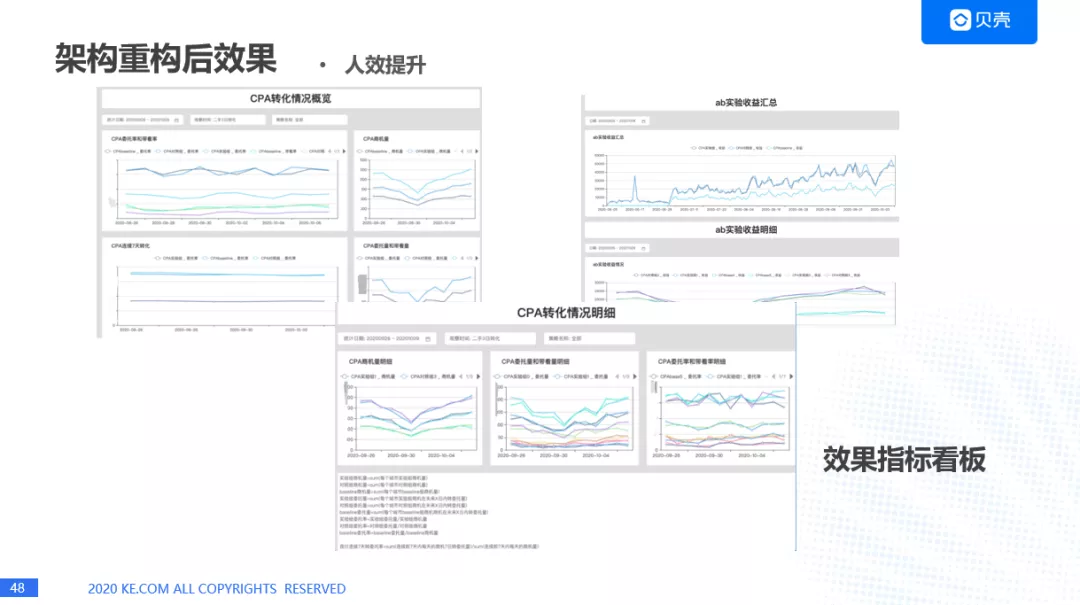
这是一个效果的指标看板。可以看到 CPA 转化情况,商机的情况,转委托的情况,也能看到 AB 实验的结果,就是具体每个策略的转化结果是什么样的,这里也能看到详细的情况。
总结与展望

主要有四个方面:
贝壳商业化平台计划要打造 AI 算法中台,容纳更多业务。不局限于商业化的业务,还会有图像,估价之类的。
兼容多语言。之前有些系统可能是 python, go 语言,我们都可以去对接他们的业务。
服务性能优化,使用性能更高的 RPC 框架,进一步提升内部性能。
探索更多模型。比如在深度学习方面更多的模型以及线上的部署。
本文转载自: DataFunTalk(ID:datafuntalk)
原文链接:贝壳商业化算法中台架构实践




