
自增列(auto_increment)是数据库中常见的一项功能,它提供一种方便高效的方式为行分配唯一标识符,极大简化数据管理的复杂性。当新行插入到表中时,数据库系统会自动选取自增序列中的下一个可用值,并将其分配给指定的列,无需用户手动干预。这种自动化的机制不仅简化了数据管理的流程,更确保了标识符的唯一性,让数据库维护变得更加便捷和可靠。
自增列在多种场景中发挥着重要的作用:
字典编码: 在常见场景中,UserID 和订单 ID 通常被存储为 String 字符串类型,当需要进行精确去重查询时,直接对字符串去重可能效率不高。为了极致性能,常见的做法是先对字符串进行字典编码后构建 Bitmap 进行聚合运算。而自增列可以提高字典编码的效率,从而提高字符串精确去重以及查询的性能。
主键生成: 由于主键是唯一的,且不允许为空,因此自增列经常被用作表的主键。自增列可以确保每次插入新记录时自动生成唯一的标识符,有助于简化数据的管理和查询。
明细更新: 使用自增列为每条入库的记录分配了唯一 ID 作为主键之后,即可基于这些主键进行更新。从而解决了明细表不支持更新的问题。
高效分页: 在数据展示时,分页是一种常见的需求。传统的分页通常利用 SQL 中的
limit,offset+order by进行查询。当进行深分页(Offset 很大)时,该方式需对全量数据读取并排序,效率极低。而自增列可以为每行数据生成唯一标识,当进行分页查询时,可以记录上一页最大唯一标识,并将其作为下一页的查询条件。这样可以有效过滤大量非必需数据,显著减轻数据库压力,为用户提供高效的分页机制。......
在分布式数据库中,由于自增序列的可用值分配涉及全局事务,这使自增列的实现存在一定难度。然而, Apache Doris 在 2.1 版本中实现了高效的自增列功能,提供了创新性的自增序列预分配方案。当用户开启自增列之后,自增序列值分配所带来的写入损耗可以忽略不计。其次,为了实现最佳的写入效率,我们在自增列功能的设计上进行了调整,例如自增序列只保证唯一性,而不保证严格连续和递增等特性,以保证数据的高效写入。(我们将在后文“使用限制”一节进行详细介绍)
本文将从基本语法、使用示例、ID 预分配方案基本原理、使用限制等几个方面对自增列进行详尽的介绍,以帮助用户更好地理解和应用自增列功能。
自增列语法及使用介绍
在使用自增列时,需要在建表 CREATE-TABLE 时为对应的列添加AUTO_INCREMENT属性。 若要手动指定自增列起始值,可以在建表时通过AUTO_INCREMENT(start_value)语句指定,若未指定,则默认起始值为 1。
创建一个 Dupliciate 模型表,其中一个 Key 列为自增列
CREATE TABLE `demo`.`tbl` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `value` BIGINT NOT NULL) ENGINE=OLAPDUPLICATE KEY(`id`)DISTRIBUTED BY HASH(`id`) BUCKETS 10PROPERTIES ("replication_allocation" = "tag.location.default: 3");自增列也可以用于 Value 列,下方语句示例创建 Dupliciate 模型表,其中一个 Value 列是自增列
CREATE TABLE `demo`.`tbl` ( `uid` BIGINT NOT NULL, `name` BIGINT NOT NULL, `id` BIGINT NOT NULL AUTO_INCREMENT, `value` BIGINT NOT NULL) ENGINE=OLAPDUPLICATE KEY(`uid`, `name`)DISTRIBUTED BY HASH(`uid`) BUCKETS 10PROPERTIES ("replication_allocation" = "tag.location.default: 3");自增列支持 Duplicate Key 和 Unique Key 两种模型,Unique Key 模型的使用与 Duplicate Key 模型类似,在此不再赘述。
接下来,我们以下表为例,介绍自增列功能的具体使用:
CREATE TABLE `demo`.`tbl` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `name` varchar(65533) NOT NULL, `value` int(11) NOT NULL) ENGINE=OLAPUNIQUE KEY(`id`)DISTRIBUTED BY HASH(`id`) BUCKETS 10PROPERTIES ("replication_allocation" = "tag.location.default: 3");当使用 Insert Into 语句导入文件,并且不指定自增列id时,id列会被自动填充生成的值。
mysql> insert into tbl(name, value) values("Bob", 10), ("Alice", 20), ("Jack", 30);Query OK, 3 rows affected (0.09 sec){'label':'label_183babcb84ad4023_a2d6266ab73fb5aa', 'status':'VISIBLE', 'txnId':'7'}mysql> select * from tbl order by id;+------+-------+-------+| id | name | value |+------+-------+-------+| 1 | Bob | 10 || 2 | Alice | 20 || 3 | Jack | 30 |+------+-------+-------+3 rows in set (0.05 sec)类似地,当使用 Stream Load 导入文件 test.csv ,并且不指定自增列id时,id列会被自动填充生成的值。
test.csv:Tom,40John,50curl --location-trusted -u user:passwd -H "columns:name,value" -H "column_separator:," -T ./test.csv http://{host}:{port}/api/{db}/tbl/_stream_loadselect * from tbl order by id;+------+-------+-------+| id | name | value |+------+-------+-------+| 1 | Bob | 10 || 2 | Alice | 20 || 3 | Jack | 30 || 4 | Tom | 40 || 5 | John | 50 |+------+-------+-------+5 rows in set (0.04 sec)自增列在典型场景的应用
字典编码
在 Doris 中, 通常采用 RoaringBitmap 实现 Bitmap 类型及相关聚合运算,如果字典编码后的值越稠密,RoaringBitmap 性能则越好。前文已提到,自增列功能在提升字典编码效率方面表现出色。为进一步展示这一功能在实际场景中的应用效果,我们以用户画像场景为例进行深入探讨。
我们以离线 PV 、UV 分析为例进行展示,首先使用以下用户行为表存放明细数据:
CREATE TABLE `demo`.`dwd_dup_tbl` ( `user_id` varchar(50) NOT NULL, `dim1` varchar(50) NOT NULL, `dim2` varchar(50) NOT NULL, `dim3` varchar(50) NOT NULL, `dim4` varchar(50) NOT NULL, `dim5` varchar(50) NOT NULL, `visit_time` DATE NOT NULL) ENGINE=OLAPDUPLICATE KEY(`user_id`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 32PROPERTIES ("replication_allocation" = "tag.location.default: 3");利用自增列创建如下字典表
CREATE TABLE `demo`.`dictionary_tbl` ( `user_id` varchar(50) NOT NULL, `aid` BIGINT NOT NULL AUTO_INCREMENT) ENGINE=OLAPUNIQUE KEY(`user_id`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 32PROPERTIES ("replication_allocation" = "tag.location.default: 3");将存量数据中的user_id导入字典表,并建立user_id到整数值的编码映射
insert into dictionary_tbl(user_id)select user_id from dwd_dup_tbl group by user_id;或者使用如下方式仅将增量数据中的user_id导入到字典表中。在实际场景中,也可以使用 Flink Connector 将数据写入到 Doris。
insert into dictionary_tbl(user_id)select dwd_dup_tbl.user_id from dwd_dup_tbl left join dictionary_tblon dwd_dup_tbl.user_id = dictionary_tbl.user_id where dwd_dup_tbl.visit_time '2023-12-10' and dictionary_tbl.user_id is NULL;假设统计维度为dim1, dim3, dim5,创建聚合表来存放聚合结果
CREATE TABLE `demo`.`dws_agg_tbl` ( `dim1` varchar(50) NOT NULL, `dim3` varchar(50) NOT NULL, `dim5` varchar(50) NOT NULL, `user_id_bitmap` BITMAP BITMAP_UNION NOT NULL, `pv` BIGINT SUM NOT NULL ) ENGINE=OLAPAGGREGATE KEY(`dim1`,`dim3`,`dim5`)DISTRIBUTED BY HASH(`dim1`) BUCKETS 32PROPERTIES ("replication_allocation" = "tag.location.default: 3");将数据聚合运算后的结果存放至聚合结果表中
insert into dws_agg_tblselect dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5, BITMAP_UNION(TO_BITMAP(dictionary_tbl.aid)), COUNT(1)from dwd_dup_tbl INNER JOIN dictionary_tbl on dwd_dup_tbl.user_id = dictionary_tbl.user_idgroup by dwd_dup_tbl.dim1, dwd_dup_tbl.dim3, dwd_dup_tbl.dim5;使用以下语句进行 UV、PV 查询
select dim1, dim3, dim5, bitmap_count(user_id_bitmap) as uv, pv from dws_agg_tbl;明细更新
在 Doris 中,Unique Key 模型适用于具备明确主键、数据频繁更新的场景;Duplicate Key 模型适用于明细数据存储、不支持数据更新的场景。
在实际应用中,用户有时也需要对明细数据进行更新操作,但这些明细数据可能并没有能保证唯一性的主键列,也不方便将这些明细数据转存到 Unique Key 表进行更新。而使用自增列作为主键来存储明细数据,可以完美的解决明细数据更新的问题。
我们以金融场景用户借款数据为例,展示如何使用自增列支持明细数据的更新。例如用户有如下的 Duplicate Key 表来记录用户的借款行为,一个用户可能存在多条借款记录。
CREATE TABLE loan_records ( `user_id` VARCHAR(20) DEFAULT NULL COMMENT '用户ID', `loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT '借款金额', `interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT '借款利率', `loan_start_date` DATE DEFAULT NULL COMMENT '借款开始日期', `loan_end_date` DATE DEFAULT NULL COMMENT '借款结束日期', `total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT '欠款总额') DUPLICATE KEY(`user_id`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 10PROPERTIES ( "replication_allocation" = "tag.location.default: 3");假设该金融机构正在举办一个优惠活动,老用户的利率打 9 折,并希望更新表中的interest_rate字段和total_debt字段值,但由于 Duplicate Key 表不支持更新,无法进行该操作。
要解决该问题,用户可以使用支持更新的 Unique Key 表,并将自增 ID 设为主键:
CREATE TABLE loan_records ( `auto_id` BIGINT NOT NULL AUTO_INCREMENT, `user_id` VARCHAR(20) DEFAULT NULL COMMENT '用户ID', `loan_amount` DECIMAL(10, 2) DEFAULT NULL COMMENT '借款金额', `interest_rate` DECIMAL(10, 2) DEFAULT NULL COMMENT '借款利率', `loan_start_date` DATE DEFAULT NULL COMMENT '借款开始日期', `loan_end_date` DATE DEFAULT NULL COMMENT '借款结束日期', `total_debt` DECIMAL(10, 2) DEFAULT NULL COMMENT '欠款总额') UNIQUE KEY(`auto_id`)DISTRIBUTED BY HASH(`auto_id`) BUCKETS 10PROPERTIES ( "replication_allocation" = "tag.location.default: 3");我们向该表导入几条贷款记录数据,如下是示例 SQL 语句(注意这里不需要写入 auto_id 字段)
INSERT INTO loan_records (user_id, loan_amount, interest_rate, loan_start_date, loan_end_date, total_debt) VALUES('10001', 5000.00, 5.00, '2024-03-01', '2024-03-31', 5020.55),('10002', 10000.00, 5.00, '2024-03-01', '2024-05-01', 10082.56),('10003', 2000.00, 5.00, '2024-03-01', '2024-03-15', 2003.84),('10004', 7500.00, 5.00, '2024-03-01', '2024-04-15', 7546.23),('10005', 3000.00, 5.00, '2024-03-01', '2024-03-21', 3008.22),('10002', 8000.00, 5.00, '2024-03-01', '2024-06-01', 8100.82),('10007', 6000.00, 5.00, '2024-03-01', '2024-04-10', 6032.88),('10008', 4000.00, 5.00, '2024-03-01', '2024-03-26', 4013.70),('10001', 5500.00, 5.00, '2024-03-01', '2024-04-05', 5526.37),('10010', 9000.00, 5.00, '2024-03-01', '2024-05-10', 9086.30);使用select * from loan_records 查询可以看到已经为每条记录分配了一个唯一 ID:
mysql> select * from loan_records;+---------+---------+-------------+---------------+-----------------+---------------+------------+| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |+---------+---------+-------------+---------------+-----------------+---------------+------------+| 1 | 10001 | 5000.00 | 5.00 | 2024-03-01 | 2024-03-31 | 5020.55 || 4 | 10004 | 7500.00 | 5.00 | 2024-03-01 | 2024-04-15 | 7546.23 || 2 | 10002 | 10000.00 | 5.00 | 2024-03-01 | 2024-05-01 | 10082.56 || 3 | 10003 | 2000.00 | 5.00 | 2024-03-01 | 2024-03-15 | 2003.84 || 6 | 10002 | 8000.00 | 5.00 | 2024-03-01 | 2024-06-01 | 8100.82 || 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 || 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 || 9 | 10001 | 5500.00 | 5.00 | 2024-03-01 | 2024-04-05 | 5526.37 || 5 | 10005 | 3000.00 | 5.00 | 2024-03-01 | 2024-03-21 | 3008.22 || 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |+---------+---------+-------------+---------------+-----------------+---------------+------------+10 rows in set (0.01 sec)接下来我们执行如下两条 SQL 来分别更新老用户的优惠利率和贷款余额
update loan_records set interest_rate = interest_rate * 0.9 where user_id <= 10005;update loan_records set total_debt = loan_amount + (loan_amount * (interest_rate / 100) * DATEDIFF(loan_end_date, loan_start_date) / 365);再次查询,可以看到数据顺利的实现更新
mysql> select * from loan_records order by auto_id;+---------+---------+-------------+---------------+-----------------+---------------+------------+| auto_id | user_id | loan_amount | interest_rate | loan_start_date | loan_end_date | total_debt |+---------+---------+-------------+---------------+-----------------+---------------+------------+| 1 | 10001 | 5000.00 | 4.50 | 2024-03-01 | 2024-03-31 | 5018.49 || 2 | 10002 | 10000.00 | 4.50 | 2024-03-01 | 2024-05-01 | 10075.21 || 3 | 10003 | 2000.00 | 4.50 | 2024-03-01 | 2024-03-15 | 2003.45 || 4 | 10004 | 7500.00 | 4.50 | 2024-03-01 | 2024-04-15 | 7541.61 || 5 | 10005 | 3000.00 | 4.50 | 2024-03-01 | 2024-03-21 | 3007.40 || 6 | 10002 | 8000.00 | 4.50 | 2024-03-01 | 2024-06-01 | 8090.74 || 7 | 10007 | 6000.00 | 5.00 | 2024-03-01 | 2024-04-10 | 6032.88 || 8 | 10008 | 4000.00 | 5.00 | 2024-03-01 | 2024-03-26 | 4013.70 || 9 | 10001 | 5500.00 | 4.50 | 2024-03-01 | 2024-04-05 | 5523.73 || 10 | 10010 | 9000.00 | 5.00 | 2024-03-01 | 2024-05-10 | 9086.30 |+---------+---------+-------------+---------------+-----------------+---------------+------------+10 rows in set (0.01 sec)高效分页
使用传统分页进行深分页查询时(offset 很大时),即使需要的数据行很少,依然会将全部数据读取到内存中进行全量排序后再进行处理,处理效率很低。
为解决深分页查询效率低的问题,我们可以通过自增列为每行数据添加唯一值。 在查询时通过记录上一页面unique_value列最大值max_value,并使用 where unique_value > max_value limit rows_per_page 下推谓词提前过滤大量数据,从而实现更高效地分页。
我们以下方业务表为例,在开启自增列之后,将为表中的每行数据赋予唯一标识:
CREATE TABLE `demo`.`records_tbl` ( `user_id` int(11) NOT NULL COMMENT "", `name` varchar(26) NOT NULL COMMENT "", `address` varchar(41) NOT NULL COMMENT "", `city` varchar(11) NOT NULL COMMENT "", `nation` varchar(16) NOT NULL COMMENT "", `region` varchar(13) NOT NULL COMMENT "", `phone` varchar(16) NOT NULL COMMENT "", `mktsegment` varchar(11) NOT NULL COMMENT "", `unique_value` BIGINT NOT NULL AUTO_INCREMENT) DUPLICATE KEY (`user_id`, `name`)DISTRIBUTED BY HASH(`user_id`) BUCKETS 10PROPERTIES ( "replication_allocation" = "tag.location.default: 3");在分页展示中,每页展示 100 条数据,使用以下方式获取第一页的数据:
select * from records_tbl order by unique_value limit 100;通过程序记录返回结果中unique_value中的最大值,假设为最大值为 99,则可使用以下方式查询第 2 页数据:
select * from records_tbl where unique_value > 99 order by unique_value limit 100;如果想要直接查询靠后页面中内容,例如直接获取第 101 页的内容,此时不方便直接获取之前页面数据中unique_value的最大值,则可以使用如下方式进行查询:
select user_id, name, address, city, nation, region, phone, mktsegmentfrom records_tbl, (select unique_value as max_value from records_tbl order by unique_value limit 1 offset 9999) as previous_datawhere records_tbl.unique_value > previous_data.max_valueorder by unique_value limit 100;自增列实现原理
传统 OLTP 数据库一般通过事务机制进行中心化的逐个自增 ID 匹配,但在基于 MPP 架构的分布式数据库中,该方式会严重限制数据导入的性能。因此,Apache Doris 2.1 版本对自增 ID 的实现进行了创新,当每个导入协调者 BE 需要分配自增 ID 时,将批量向 FE 申请 ID 区间,且 FE 可保障每个 BE 分配的 ID 区间不重叠,这样就可以保证 ID 的唯一性。
结合下方示意图来说明,下表存在自增列。当 StreamLoad 1 选中 BE1 作为协调者时,BE1 会找 FE 申请一批 ID 区间(1-1000)并缓存在本地,当 1000 个 ID 分配完后,BE1 将继续找 FE 申请下一批。与此同时,StreamLoad 2 选中 BE3 作为协调者,BE3 也会找 FE 申请 ID,由于 1-1000 已经分配给了 BE1,因此 FE 将 1001 - 2000 分配给 BE3 。
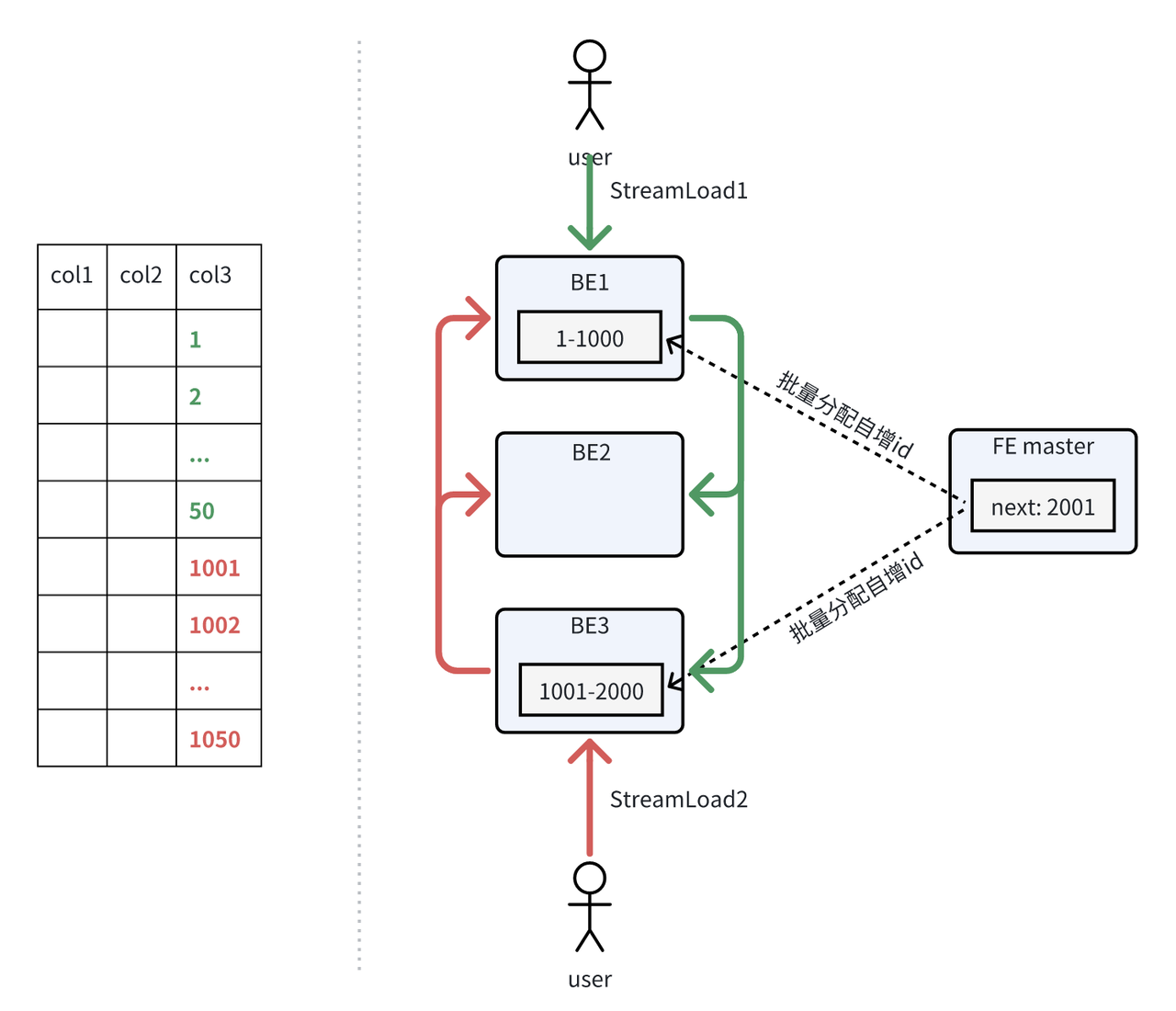
此外,如果 StreamLoad 1 和 StreamLoad 2 分别写了 50 条数据,那么这两批导入产生的自增 ID 范围分别为 1-50 和 1001-1050。如果还存在 StreamLoad3,且也选中 BE1 作为协调者,那么 BE1 会从 51 开始分配 ID。虽然 StreamLoad3 在 StreamLoad2 之后写入,但可能出现 StreamLoad3 写入的数据分配到了更小的自增 ID。
注意事项
在 Apache Doris 中,自增列的使用受到一些严格的语法限制,这些限制确保了数据的完整性和一致性。具体来说:
自增列只支持 Duplicate Key 模型和 Unique Key 模型
每张表有且只能包含一个自增列
自增列的类型必须是 BIGINT 类型,且该列不能为 NULL
手动指定的自增列起始值必须大于等于 0
此外,在使用自增列时,还需要注意以下语义限制:
唯一性保证范围: Doris 保证了自增列上生成的值在表内具有唯一性,但仅限于 Doris 自动填充的值,如果用户通过显式指定自增列的方式插入值,Doris 则无法保证该值的唯一性。
值的稠密性与连续性:Doris 可保证自增列自动生成的值是稠密的,但出于性能考虑,无法保证导入时自动填充的自增列值是完全连续的。这意味着在导入过程中,自增列的值可能出现跳跃现象。此外,由于 BE 会缓存预先分配的自增列值,且值之间互不相交,因此无法根据自增列的值的大小来判断数据导入的先后顺序。
结束语
自增列的实现,使得 Apache Doris 可以在处理大规模时展示出更高的稳定性和可靠性。通过自增列,用户能够高效进行字典编码,显著提升了字符串精确去重以及查询的性能。使用自增列作为主键来存储明细数据,可以完美的解决明细数据更新的问题。同时,基于自增列,用户可以实现高效的分页机制,轻松应对深分页场景,有效过滤掉大量非必需数据,从而减轻数据库的负载压力,为用户带来了更加流畅和高效的数据处理体验。




