
本文最初发布于 Stroobants 博客,经原作者授权由 InfoQ 中文站翻译并分享。
几乎所有人都在说不可变的微服务才是最好的,开发者社区也通过只读 Docker 镜像和 CI/CD 表达了对其的支持,但运营的世界似乎还是深陷手动配置的泥潭。原因呢?单纯是没有合适的工具罢了。当然,我们也可以通过部署让一部分基础设施不可变,但在没有内部 API、软件和相关认知的情况下,我们只能盼着上一位运维同事能写份完整的、能读懂的文档,或者祈求上苍希望上次写完文档之后没再改过东西了。
但尤其是在云环境中,随着 API 和 IaC 工具的崛起,我们还是可以梦想着有一天能跨过黑暗时代的。
为什么要部署基础设施即代码?
只要是报错,运维都可以通过重新部署解救问题。
但如果我们把一切都通过基础设施即代码(IaC)定义了呢?再遇到这种莫名其妙报错的时候,我们就可以直接销毁出问题的资源,并重新将其部署即可。我们再也不用浪费时间纠结于一个不可能的报错了,把所有的 debug 都延后再做,先让服务跑起来再说。
如果遇上超级大灾难,那就把运维放到另一个地域里重新部署
这大概是云供应商的第一大卖点了。假如有一天真的天降大灾于你的一处云区域里,除非你真的把所有东西都用 IaC 定义了一遍,否则你很难直接转移到另一个地域里。但如果你只是刚刚开始用 IaC 并结合一些其他的什么工具进行手动更改的化,那么你大概需要的就是速效救心丸了。因此,请开始尝试在 IaC 中定义所有,或者做好 RTO(恢复时间目标)增加的准备。
运维可以快速回退到先前状态
在过去,运维的眼里所有的变更都是永久性的,有的甚至不能回滚。但有了 IaC 之后,我们可以回滚了!如果不行至少还是可以回退到上一个状态的。有的 IaC 禁止回滚(Terraform)但是有“前进”(move-ahead)的策略。这二者各有各的优缺点,但我个人认为具体该用什么看团队的喜好就行。
版本控制和同行评审
当你在运维环境部署东西时,你的同事只会希望你所有都写对了。毕竟他们做不到蹲在你身边看着你干活,也不能在你完成后一步步重新检查所有东西,他们只是默认你没搞错。但如果有了 IaC,那就意味着我们终于有了一个版本控制工作流。同事们可以检查你要部署的东西,没问题的话就给通过。他们也可以清楚看到具体要部署的是什么,有问题的留下评论并和你一起修改。忘了启用加密?很容易检测,完全不用对所有的资源都来个年度大审查。
运维团队能用的工作流
这对运维团队来说尤其重要。如果把一个小萌新扔到一群运维老鸟之中,而这群老鸟们干起活来又各有各的方法,再加上似是而非的检测和平衡……团队的 leader 或许觉得一切都在正轨上,一切都很顺利。当然,大多数情况下确实如此。
但这对新员工来说可能就没有这么友好了。每位开发都有各自部署的方法,在向运维之神提交供奉的时候也都有各自的仪式。
一旦我们修正了 IaC 中的坏习惯,知识和代码的分享将变得更快更轻松,只需要最低级的限制即可。
管理一切的包
虽然和上一个点有些类似,但你的同事们终于可以只实现部署中必要的部分了。从公司的角度来看,轻松打包架构,让同事们可以在其基础上进行构建或优化是非常好的,而运维也可以充分利用互联网上的开源包进行开发工作。
我还记得当我第一次需要在亚马逊云科技上部署一个 EKS 时,发现Terraform注册表里的EKS包是多么的开心;一周的工作量瞬间缩减成了一天。
检测漂移
漂移是非常让人头疼的事情。如果业务有时间很紧的需求,那么就会引发漂移。一个要改架构的需求,但之前又完全没有文档可以参考,再加上执行请求的人又在休假……一切都散了架,而没人能解释清楚为什么。重置也没了作用,一切都乱了套以及这个见鬼的 Redis 实例是从哪冒出来的?
原因也很简单,糟糕的文档记录、被无视的流程手续等等,让你的环境已经从最初的架构漂移走了,而直到最后所有都散架了你才发现它其实已经漂了很多年。
但这对 IaC 来说小菜一碟,因为它可以让环境变得“不可变”。借助一些工具,我们可以检测到所有没有用 IaC 创建的资源,而没有使用 IaC 工具修改的资源也可以轻易被它检测到。
这样,我们的环境就像是个 Docker 的镜像,如果出了什么 bug,直接重新部署即可。
沙盒环境
如果你的环境是用 IaC 定义的,那么创建沙盒环境将会非常简单。要测试的东西需要改架构?没问题,搞一个沙盒账号然后把整个架构都部署进去就成,这个环境还可以测完就扔不用留念。
如果你有个开发环境(dev),那如果你想试试把整个开发环境都干掉后重新运行管道,测试看 IaC 代码还能不能跑也是可以的。最好的情况是,整个开发环境一小时后就回来了,但最糟糕的呢?又有新操作点需要解决了。
怎么才能让我的环境不变呢?
我会尝试在这里解释如何从架构的角度来,至少确保生产环境的不变性所需要的一般性建议。
环境
希望看到这里的你们真的有环境相关的策略,而不是搞什么“测试环境即开发环境”。对小公司来说,有测试到生产两个独立环境即可。大一些的公司就可以采用测试->暂存->生产流的策略。在本文中,我将以大公司的环境策略为例进行展示,但请记住,这个框架也不是一成不变的。

基础环境
测试环境
这里是你的沙盒。你的工作负载都部署在这里,但你的 DevOps 团队也有这个环境的管理员权限,虽然会有例外情况和一点点的限制条件,但不管怎么说,他们都是这个环境的老大。他们会在这个环境里练手、试验以及各种瞎搞,但你还是可以通过运行的管道回退环境到上一个状态的,并且创建在 IaC 之外资源也不会被销毁。
测试环境也可以用来测灾难恢复的性能。这种一年都难得发生一次的小概率事件现在可以每周都拎出来测一测了,具体操作方法也很简单,直接干掉整个环境,然后让管道跑就完事了。这套操作同样适用于被开发者们玩弄过后重置沙盒恢复稳定的情况。
暂存环境
这里是生产之前的预演,是生产环境的复制品,当然还是会有一些小区别的,比如为了优化成本,暂存环境里只跑了两个实例而不是生产里的五十个。这个环境也可以被称作是指示灯环境,只要你想,这个环境应该随时可以扩展到足以运行生产环境工作负荷的程度。DevOps 团队在这个环境里应有只读权限,方便他们随时查看日志、检查告警,修修 bug 之类的。但如果想要改架构上的东西,就必须要通过 IaC 进行了。同时,在这个环境里的所有部署也应要有 DevOps 团队的批准。
生产环境
正菜来了。这里是只有真正的用户才会涉足的地方,也就是为什么这个环境对开发来说是个黑盒,他们只有日权限以及一些常规的主页页面。根据我之前在金融和医疗行业干过的经验,登录到这个环境后会看到一些开发没权限随意查阅的用户个人信息。展示环境一切正常的主页页面没毛病,如果用户提了意见,授权给开发去看看是啥问题也 ok。但至于其他的?不好意思全部锁定。
与模拟环境一样,生产对开发来说也都是全部只读的。任何涉及这两个环境中的更改都应该通过 IaC 并且有管理层的审批。
但紧急情况下,还是应该给开发额外的权限进行更改的。

带权限的基础环境
IaC 管道
讲完了环境,下一步就是部署了。无论你用的是 GitHUb、Bitbucket、亚马逊云科技的 Codepipeline,还是任何的的 CI/CD 工具,它们大都有基础的认证和我们需要的工具。
概览
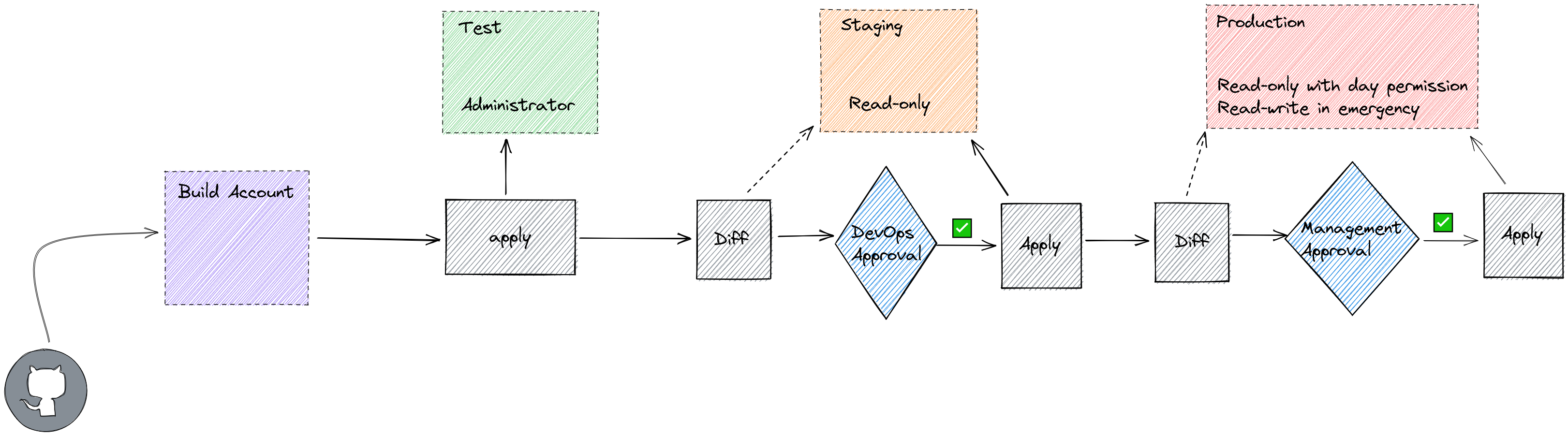
IaC 管道
构建账号
这里构建的账户是拥有访问其他所有账户权限的总账户。但你还可以给每个工作流、每个部门、每个组都建一个账户,只要你能确保这些账户的安全性,并且管道有几乎所有其他账号的管理员权限。
构建的账号会包含有操作系统以及服务等一系列的镜像,而其他的账户也应能与其进行交互和利用。
差异阶段
这个阶段是我们能看到将要发生的一切。CloudFormation 管这个阶段叫 ChangeSet,Terraform 有plan命令,CDK 有diff。其实这个阶段什么也不会发生,这只是 IaC 的工具在检查当前阶段和变更的地方。类似 Terraform 的 IaC 工具会通过调用 API 来检查阶段是否仍然与实际情况相符,CloudFormation 会用笨一点的方法,直接在后台检查阶段文件。
审批阶段
可能你也注意到了,我们部署到 DEV 环境是不需要审批的。有的团队可能会需要,但这完全要看团队内部是如何决定的。
部署到暂存环境是需要另外的 DevOps 来审计变更条目的。暂存虽说还不是生产环境,但我们要在这里运行所有的环境测试,再加上暂存其实是为模拟生产环境……任何较大的中断都需要一定的沟通交流。
生产部署最好也让管理层给出审批。这是为了能让管理能够跟得上项目变更的速度,方便与其他部门沟通,并在这个时间空窗运行他们自己的变更。
实施阶段
见证魔法的时间到了,在架构上真正动工地方。这也是为什么说暂存环境非常重要了,根据我多年的经验来看,无论是 plan、ChangeSet,还是 diff,有时候总会忘掉点什么。这部分已经不再局限于理论了,它更实际,开发能够更直观地看到中断需要的时长,应用所有变更所需要的时间等等各种在生产之前都应该了然于心的关键信息。
至于生产环境的实施阶段,请准备好你向运维之神祈祷的祷文,并在手边备好速效救心丸。
时间
越短越好。但别忘了在继续部署之前先跑几个自动化测试。与开发和暂存之间的关系相比,暂存和生产之间的区别要小上很多,请继续保持,如果暂存有变更,完全可以直接在暂存的下次变更之前直接将这次的部署到生产之中。
至于为什么,可以想象一下,如果你在配置数据库、前端服务器、缓存服务器等等一系列的设备,你会按照第一天配数据库,第二天配缓存服务器,第三天配前端服务器的顺序一步步走。看起来都没什么问题后,你决定开始上生产,砰,一切都挂了。
一通调查之后,你发现,第一个部署上的是前端服务器,而它在试图链接还不存在的数据库和缓存服务器失败后开始尝试中断链接。崩溃导致 IaC 工具在收到错误信息后同样开始停止工作,导致数据库和缓存服务器都没能部署上。
所以,请让暂存环境离生产环境近一点。
抓住漂移
搞定环境之后,我们还得确定它真的是不可变的才行。
IaC 工具的好伙伴:plan
环境不可变的第一步操作是检查 IaC 部署的资源是否发生了任何漂移。这一点可以通过 IaC 工具中的内置命令来快速检查。以 Terraform 为例,我们可以创建一个每晚触发的 plan,如果有检测到任何漂移,直接告警或进行修正。具体操作取决于你的团队的喜好,但就我个人来说,我从来都只见过实施的告警,从来没修 ajsifas……
对于 CDK 或者 CloudFormation 来说,我们可以通过运行drift命令来检测漂移。但要注意,这个命令不一定对所有资源都有效,非常的烦人。
检查是否有不对劲的资源创建
IaC 创建的资源很好说,它自己就会检查是否有被修改到无法控制的情况。但对于那些未经过 IaC 创建的,它们就束手无策了。黑客可以部署 20 个加密货币采矿实例,而 IaC 只会淡定地告诉你“我这边一切正常”,当然这也不能怪它们,毕竟这确实不在它们的责任范围内。为了解决这种情况,我们可以使用其他工具,比如一些云供应商提供的原生工具,检查标签之类,不过头脑清醒的黑客一般都会注意到这一点。有的工具则是来自第三方的,比如[driftctl。
从安全账号开始,我们可以在生产环境中应用aws-nuke一类的脚本,让环境非常接近不可变,直接杀死黑客塞进去的、未经 IaC 定义的资源。
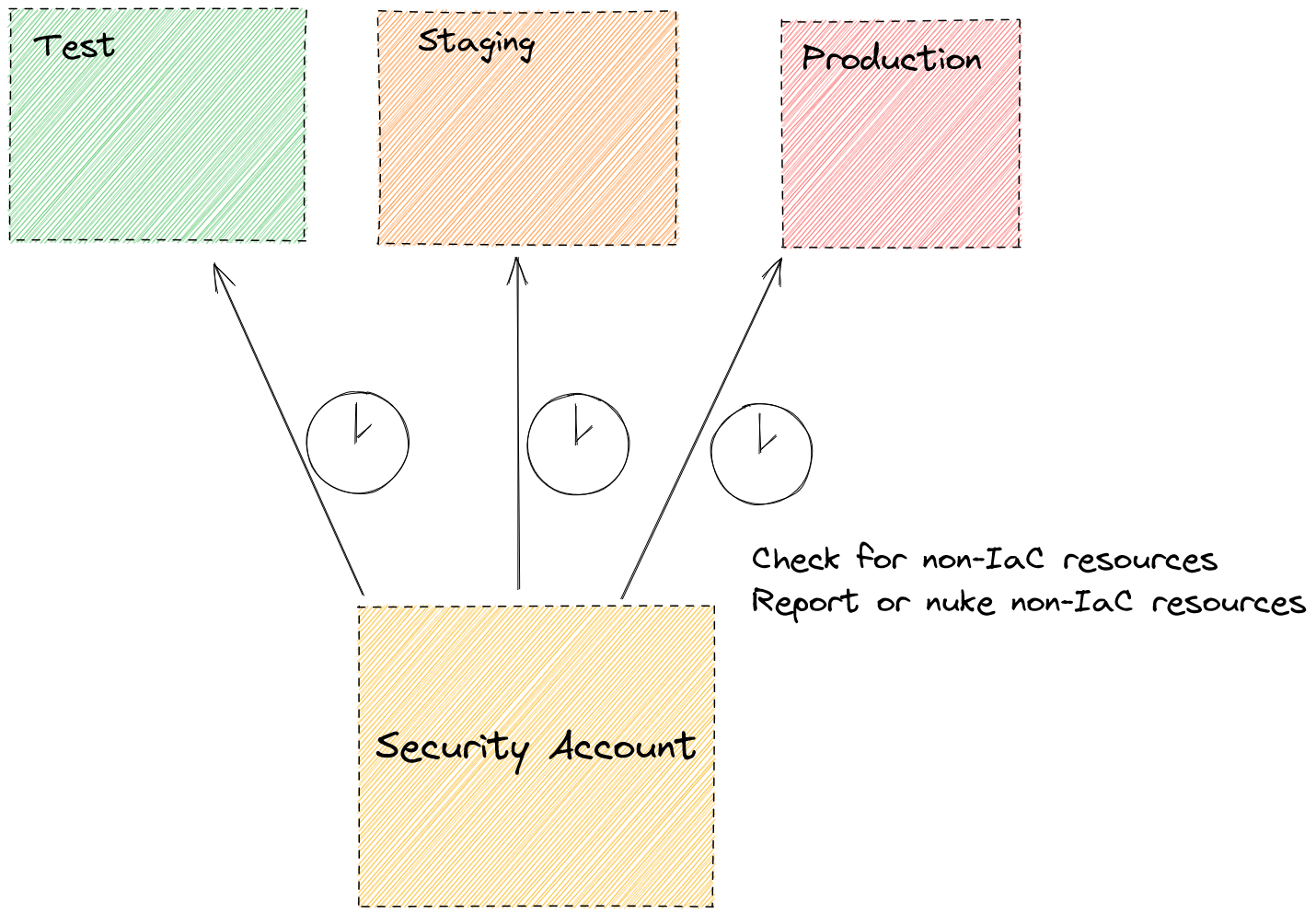
消灭漂移
历史审计报警
另一种检查资源是否在创建时用了 IaC 的方法是,直接在亚马逊云科技的 CloudTrail 里筛找写操作的例子。如果看到有在管道角色之外的写,直接报警。虽然这种方法不是百分百的保险,黑客还是可以通过管道角色攻击你环境的。
现在再来回答为什么说你的基础架构应该是不变的这个问题:
会更安全;
让你的团队步伐一致;
帮你在关键时刻 debug 并解决问题;
让团队新成员更易明白你使用的环境;
减少你的 RTO;
可能还有别的原因我忘了提。




