
写在前面
在 CTR(Click Through Rate)点击率预估的推荐算法场景,TensorFlow Feature Column 被广泛应用到实践中。这一方面带来了模型特征处理的便利,另一方面也带来了一些线上推理服务的性能问题。为了优化推荐业务性能,提升线上服务效率,爱奇艺深度学习平台团队在实践中总结了一些性能优化方法。
经过这些优化,推荐业务的线上推理服务性能效率可以提升一倍以上,p99 延迟降低达到 50%以上。
背景介绍
Feature Column 是 TensorFlow 提供的用于处理结构化数据的工具,是将样本特征映射到用于训练模型特征的桥梁。它提供了多种特征处理方法,让算法人员可以很容易将各种原始特征转换为模型的输入,来进行模型实验。
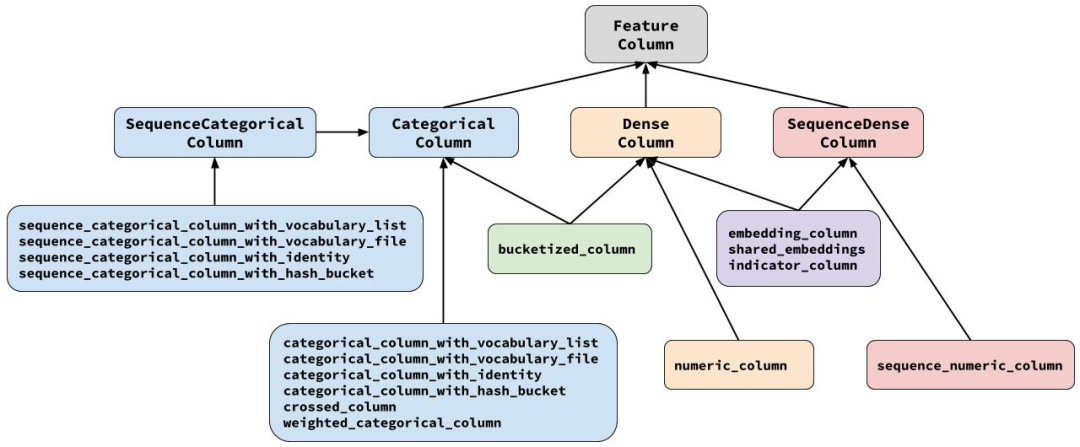
如上图所示,所有 Feature Column 都源自 FeatureColumn 类,并继承了三个子类 CategoricalColumn、DenseColumn 和 SequenceDenseColumn,分别对应稀疏特征、稠密特征、序列稠密特征。算法人员可以按照样本特征的类型找到对应的接口直接适配。
而且 Feature Column 和 TF Estimator 接口有很好的集成,通过定义好对应的特征输入就可以直接在预定义的 Estimator 模型中使用。TF Estimator 在推荐算法的使用非常普遍,特别是它封装了分布式训练的功能。
下图是一个使用 Feature Column 处理特征,进入到 Estimator DNN Classifier 的示例:
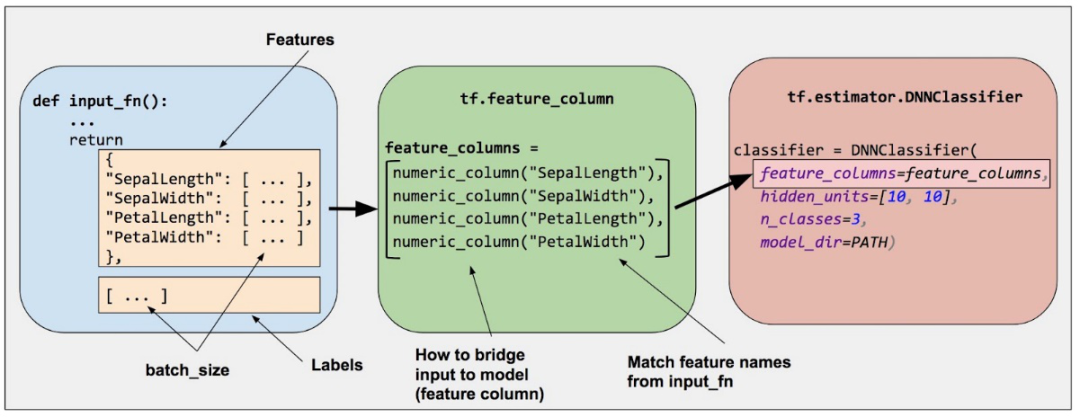
虽然 Feature Column 使用起来很方便,模型代码编写比较快,但是在爱奇艺推荐类业务的线上服务落地过程中,一些性能问题逐渐凸显,下面将逐个介绍我们在实际中碰到的一些问题,以及如何优化。
整型特征哈希优化
推荐类模型通常都会将 ID 类特征哈希到一定数量的 bucket 分桶,然后转换成 Embedding 再作为神经网络的输入,比如视频类 ID 特征,用户 ID 特征,商品 ID 特征等。示例如下:

在` categorical_column_with_hash_bucket `的文档[2]里面说到:对于 String 类型的输入,会执行`output_id = Hash(input_feature_string) % bucket_size`做哈希操作,而对于整数类型的输入会先转成 String 类型然后再进行同样的哈希操作。通过查看源代码[3]可以看到这样的逻辑:
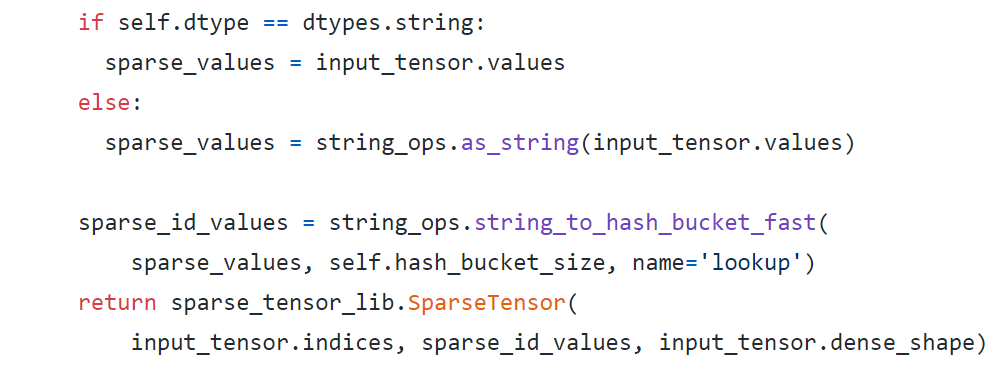
在推荐业务中,通常这类 ID 都是已经过某种方式的哈希,形成 64bit 的整型特征放到样本里面,因此必然要执行整型转化成 String 的操作。但是在 TensorFlow 的 Timeline 中可以看到函数`as_string`所对应的 TF 内部的`AsString` OP 其实是一个比较耗时的操作,经过分析对比发现`AsString` OP 的耗时通常是后面的哈希操作的 3 倍以上,如下图所示:

进一步分析`AsString` OP 内部的代码,可以发现这个 OP 内部还涉及到了内存分配和拷贝操作,因此比纯哈希计算慢就可以理解了。
很自然,团队考虑去掉相关操作来做优化,因此专门编写了一个给整型做哈希的函数来做优化,示例代码如下:

经过这样做区分类型的哈希方式,完全优化了原先耗时长的类型转换操作。这里需要注意的是新加的哈希函数对应的新 OP 同样需要加到 TF Serving 中。
定长特征转换优化
定长特征是指使用接口`tf.io.FixedLenFeature`来解析的特征,比如用户的性别,年龄等,这类特征的长度通常都是定长的,并且固定为 1 维或多维。这类特征经过接口`tf.io.parse_example` 解析成 Dense Tensor,然后经过 Feature Column 处理,再进入到模型的输入层。常见的代码示例如下:

以上面的代码为例子,举例解析一下 TensorFlow 内部的 Tensor 转换逻辑。如下图所示,两个样本 user_name 分别为 bob 和 wanda,经过样本解析成 shape 为 2 的 Dense Tensor,然后经过`categorical_column_with_vocabulary_list`转换,查找词表分别转成 0 和 2,再经过`indicator_column`转换成 One hot 编码的 Dense 输入。

从上面的样本处理来看没有什么问题,然后再来看一下 Feature Column 代码内部的转换处理逻辑:
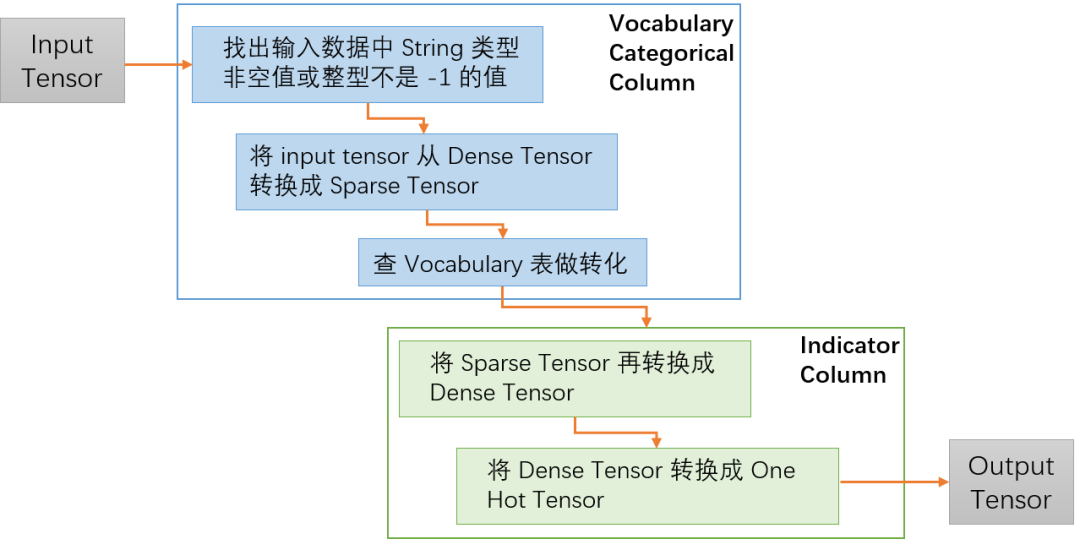
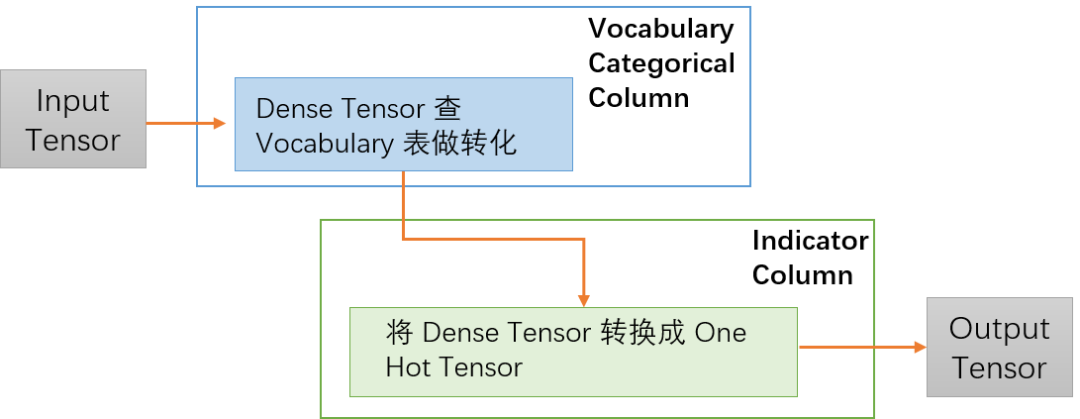
如上图所示,在代码中 Vocabulary Categorical Column 会先去除掉一些非法值,然后把输入的 Dense Tensor 转换成 Sparse Tensor,在 Indicator Column 中会再次把 Tensor 从 Sparse 转成 Dense,最后转成需要的 One Hot Tensor。
先来思考一下上面两个转换操作的目的,一方面是为了去除样本数据中一些异常的值,另外一方面是这样的处理其实是同时兼顾了输入是 Sparse Tensor 的情况,如果输入是 Spare Tensor 就直接做 Vocabulary 词表查找,然后再转成 Dense Tensor。这样转换虽然达到代码复用的作用,但是在性能上却有损失。如果能直接将原始的 Input Tensor 转换成 One Hot Tensor,就可以省去两个转换过程,而且 Sparse Tensor 和 Dense Tensor 之间的转换其实是非常耗时的操作。
再回到定长特征的原始性质,对于这类定长特征来讲,在样本处理的时候如果没有值,会被填充成默认值,而且在生成样本的时候都会被保证不会出现有空值或者 -1 的情况,因此异常值的处理其实是可以被省略的。最后优化后的内部转换逻辑如下图,省去了两次 Sparse Tensor 和 Dense Tensor 之间的转换。
除了上面的 Vocabulary Categorical Column,还有别的类似 Feature Column 也有同样的问题,因此针对这类特征,平台专门开发了一套优化的 Feature Column 接口提供给业务使用,优化性能效果还不错。
用户特征去重优化
推荐类算法模型都有个很典型的特点,那就是模型中会包含用户侧特征和要推荐的 Item 侧特征,比如视频的特征、商品的特征等。模型在线上服务部署的时候,会给一个用户推荐多个视频或商品,模型会返回这多个视频或商品的打分,然后按照打分的大小推荐给用户。由于是给单个用户做推荐,这个时候该用户的特征会根据推荐 Item 的数量重复多次,再发送给模型。如下是一个典型的推荐算法排序模型线上推理的示意图:
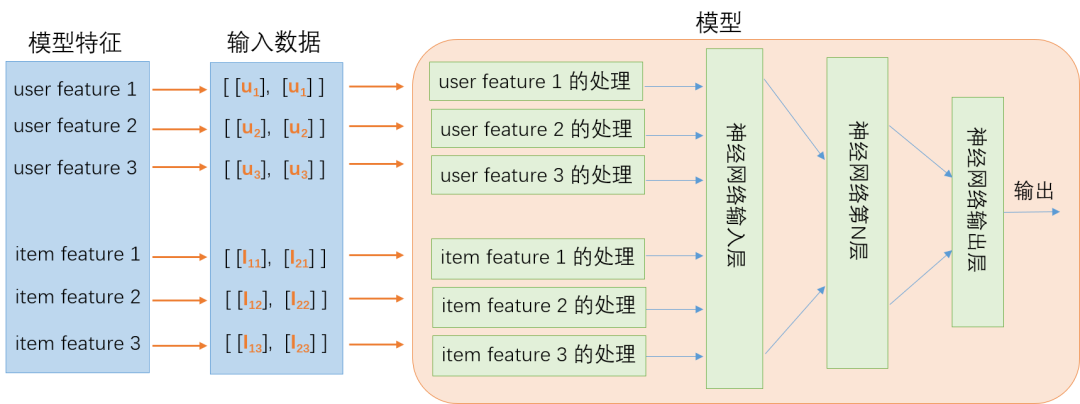
图示的模型输入有 3 个 User 特征,3 个 Item 特征,假定在对某个用户做推荐,该用户的 3 个特征分别对应为 u1,u2 和 u3。这时要对两个不同的 Item 做推荐评分请求,也就是一个请求里面有两个 Item,这两个 Item 分别为 I1 和 I2,这两个 Item 分别有三个特征,I1 对应 I11,I12,I13,以此类推,这样构成一个 batch size 为 2 的推理请求。从图中可以看到,因为是给同一个用户推荐两个不同的 Item,Item 侧的特征是不同的,但是用户的特征被重复了两次。
上面的例子只以 2 个 Item 为例,但是实际线上的服务一个推理请求会带 100 个 Item 甚至更多,因此用户的特征也会被重复 100 次甚至更多,重复的用户特征不仅增加了传输的带宽,而且增加了特征处理时的计算量,因此业务非常希望能解决这个问题。
这个问题的本源要从 TensorFlow 的模型训练代码说起。TensorFlow 训练时的每一条样本是某个用户对某个 Item 的行为,然后经过 shuffle 和 batch 后进入到训练模型,这时候一个 batch 里面的数据肯定包含了多个用户行为的样本,这个和线上推理服务的输入数据格式是完全不同的。
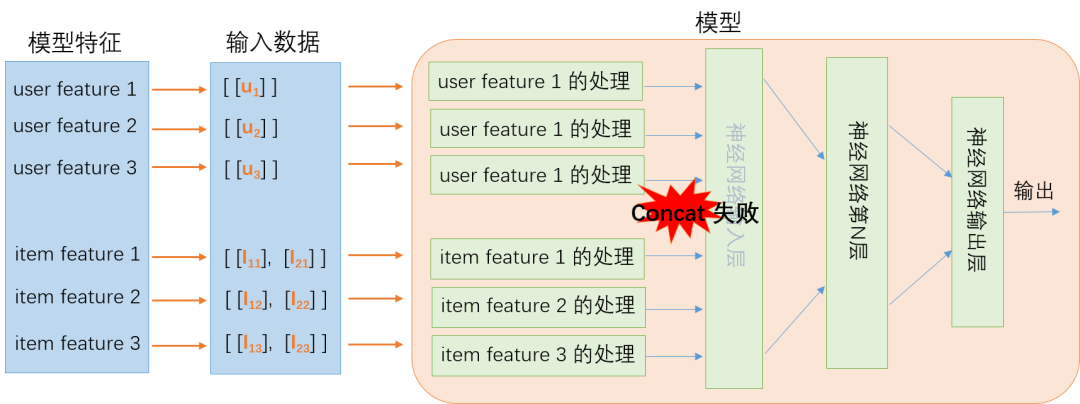
如何解决这个问题?最简单的想法,如果在线上服务就只发送一条用户特征会怎么样?快速的尝试就可以知道特征数据进入到模型输入层的时候会 concat 失败。这是因为 Item 特征的 batch size 是多个,而用户特征的 batch size 只有 1,示例如下:
为了解决 concat 失败的问题,单纯先从模型的角度来看,可以考虑在进入到输入层之前把用户特征还原到和 Item 特征同样的 batch size,如下图所示。
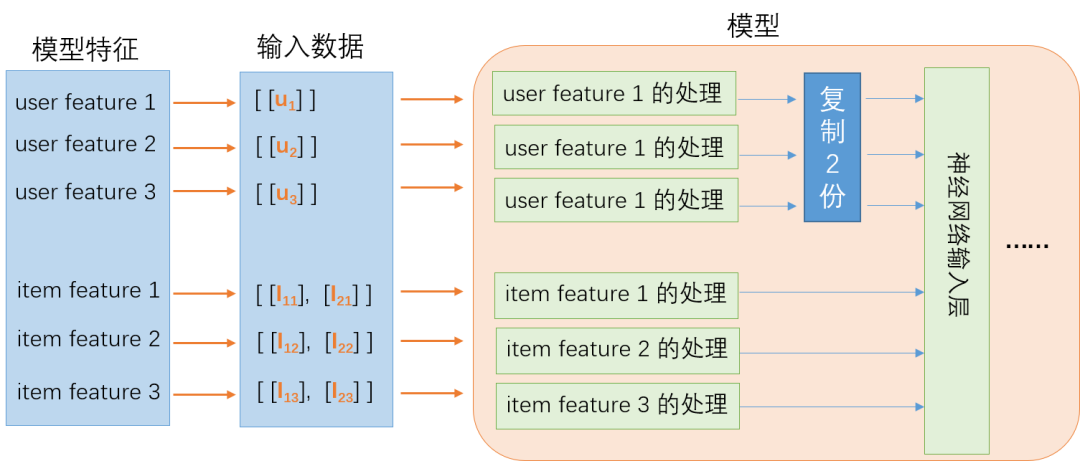
显然这个从数学模型上是可行的,接下来就是怎么在 TensorFlow 的代码里面实现这个想法。这里需要注意的是复制的操作只能在线上服务的模型里面,不能在训练的模型里面。
目前 TF Estimator 接口在推荐类算法的应用比较常见,而 Estimator 接口提供了很好的模型区分方法,通过判断 ModeKeys 为`tf.estimator.ModeKeys.PREDICT`时是线上的服务模型,ModeKeys 为`tf.estimator.ModeKeys.TRAIN`时是训练模型,下面是示例代码:

在实际的模型上,需要将 User 和 Item 的 feature column 区分开来分别传入,这个对原来的模型代码改动比较大,batch size 的获取可以通过判断 Item 特征的长度来获取,这里不再赘述。
在实际的上线过程中,团队经历了两个阶段,第一个阶段是只对算法模型代码做修改,在处理用户特征时只取第一维,但是实际发送的推理请求还是会把用户特征重复多次;第二个阶段才把发送的推荐请求优化成只发送一份用户特征,这个时候模型代码不需要再做修改,已经自动适配。
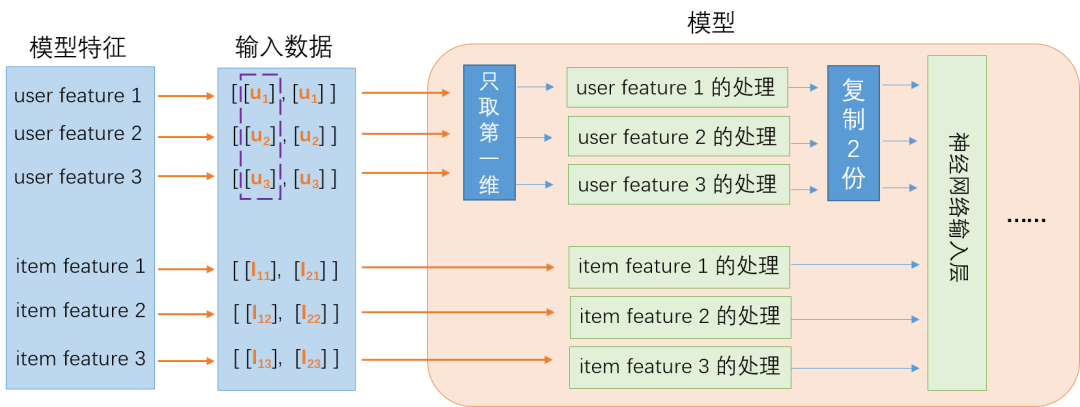
如上图所示,第一阶段的时候用户特征的输入还是重复多次,在模型中,对用户特征只取第一维再进行特征处理,示例代码如下:
上面的模型代码可以同时适配推理请求发送重复的用户特征,或者只发送一条用户特征。因此在第二阶段的时候,不需要再修改模型代码,只需要优化发送推理请求的引擎侧代码。
经过这样的优化,线上推理服务不需要重复发送用户特征,不仅节约了带宽,而且减少了序列化的消耗。对一个 batch 中的用户特征只做一份数据的 Feature Column 转换,然后做复制操作,复制消耗的时间远远小于转换的时间。
这里其实还可以做进一步的优化,将复制操作延后到第一层神经网络的矩阵乘后面,这样可以减少第一个矩阵乘的部分计算消耗。如果用户特征的维度占比比较高,优化的效果会比较明显。
总结
本文介绍了爱奇艺深度学习平台在实践过程中总结的一些 TensorFlow Feature Column 优化。经过这些优化,线上的推理服务性能效率提升一倍以上,p99 延迟降低达到 50%以上。而且相比较于做 op fuse,模型图修改等优化,这些优化在业务实际中也比较容易去落地。
最后,我们还是要肯定 TensorFlow Feature Column 给推荐类算法带来的特征处理便利性,它将整个特征的处理抽象出来,算法只要稍微适配一下样本特征就可以很快的做迭代和实验。
参考文献
1. https://www.tensorflow.org/tutorials/structured_data/feature_columns
2. https://www.tensorflow.org/api_docs/python/tf/feature_column
3. https://github.com/tensorflow/tensorflow
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




